






介绍:
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。
流程:
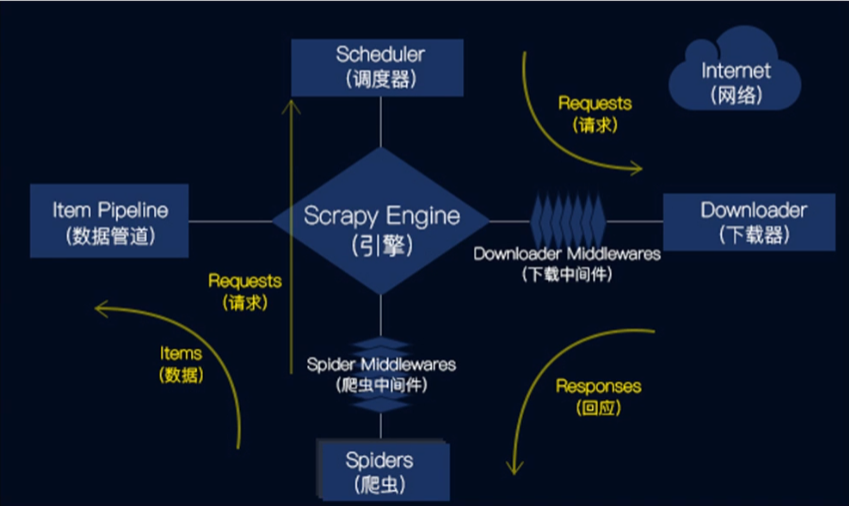
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
安装—创建
安装:pip install Scrapy ,下载内容比较多,建议清华源(安装遇到问题,首先检查下PIP版本)
安装好了的话,在终端里输入scrapy就是这样子
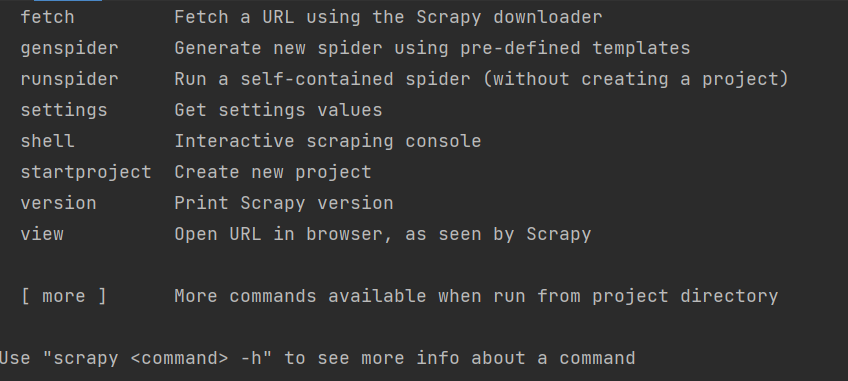
下面有一句话使用“scrapy <command> -h”查看命令的更多信息
创建:scrapy startproject 项目名字,这个写终端里,你终端的位置就是建立的位置, 想换位置的话可以
cd 文件夹\文件夹\文件夹
cd | 进入指定路径 |
cd ../ | 返回上一级 |
比如我建立一个jaychou的项目,终端:scrapy startproject jaychou 运行

建立成功,这里能看到你的项目路径,建立在哪里了,然后下面提示你可以干什么
此时呢项目文件里会有两个jaychou的文件夹第二个下面有个spiders,我们需要在这个文件夹下面建立个爬虫文件
首先cd jaychou\jaychou\spiders 运行
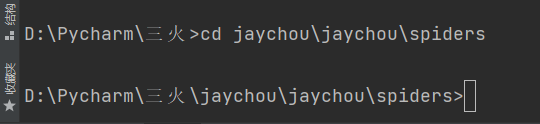
路径成功来到spiders,然后继续输入scrapy genspider 爬虫文件名称 目标网站
比如杰伦的百度百科页面,这里链接不需要放那么长取主要域名就行,主要是呢不要跟项目名称重复就好
scrapy genspider zhoujielun https://baike.baidu.com/

spiders里的爬虫文件
打开文件,start_urls 这里放目标网站的全部地址
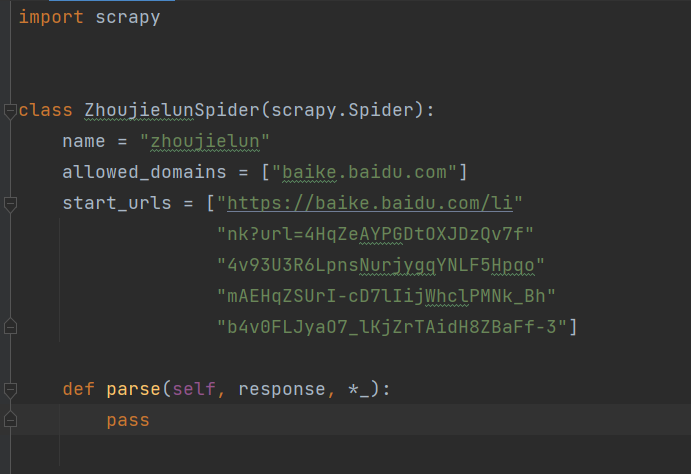
start_urls 这里放目标网站的全部地址
然后我们在parse 里面就可以写我们的爬虫了,response是深色的,因为继承数量不一样,后面加个*-就可以了,不管它也没事,强迫症写法
比如爬第一句为例

我这里的代码就写好了
首先是把items文件引入:from ..items import JaychouItem(你的项目名后面+Item,注意首字母大写)
然后是item = JaychouItem()
这个标注的变量的数据传输位置,我要把数据送到JaychouItem。
数据获取了要yield item,返回数据(写在spiders里的爬虫文件)如果不返回获取到数据也不会在管道里传输,更不会保存写入。
items文件
打开items文件可以看到

这里是数据规范,我可以定义数据的规范性,避免出现垃圾数据,像字典一样键值对
要在变量后面加一个 = scrapy.Field(),变量名字就是这个

有多少数据就写多少 = scrapy.Field(),前提是想规范它。items文件下面也要写item = JaychouItem() 表示item是你这个项目的item。
settings文件
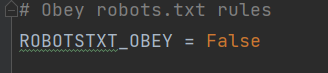
settings里需要改的地方是三个
协议的遵守要False
要自己添加一个user_agent,注意字典格式

优先级要打开

pipelines文件
管道文件是保存文件的地方,比如可以以文件的方式保存

保存数据库的话也是写这里: 要链接数据库,然后导入,重新定义个class写数据库的代码就好了
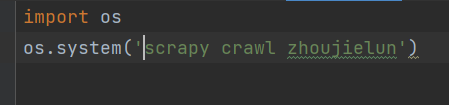
启动文件
我们要自己添加一个启动文件,用os 命令去运行而不是直接在spiders里的爬虫文件运行,内容如下:
尾声
代码可以运行,文章不能报错,发现问题请各位动动小手留言指出,谢谢支持哦~希望文章能够有帮助!
















 2531
2531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











