







1. scrapy基本使用
电子资料:https://book.apeland.cn/details/438/

2. scrapy数据解析
# -*- coding : utf-8 -*-
import scrapy
from qiubaiPro.items import QiubaiproItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
# 终端命令持久化存储
# def parse(self, response):
# # 解析作者名称+段子内容
# div_list = response.xpath('//div[@class="col1 old-style-col1"]/div')
# all_data = []
# for div in div_list:
# author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
# author = author.strip()
# content = div.xpath('./a[1]/div/span//text()').extract()
# content = ''.join(content)
# content = content.strip()
# dic = {
# 'author': author,
# 'content': content
# }
# all_data.append(dic)
# return all_data
# 管道存储
def parse(self, response):
# 解析作者名称+段子内容
div_list = response.xpath('//div[@class="col1 old-style-col1"]/div')
all_data = []
for div in div_list:
author = div.xpath('./div[1]/a[2]/h2/text()')[0].extract()
author = author.strip()
content = div.xpath('./a[1]/div/span//text()').extract()
content = ''.join(content)
content = content.strip()
item = QiubaiproItem()
item['author'] = author
item['content'] = content
# 将item提交给了管道
yield item
3. scrapy数据存储

4. 全站数据爬取
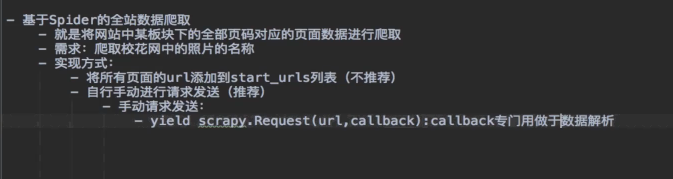
5. 图片数据爬取

6.在setting.py中启动并设置User-Agent

7.使用Item封装数据
由于字段拼写容易出错且无法检测到这些错误,返回的数据类型无法确保一致性,不便于将数据传递给其他组件
定义item和Field

在items.py文件中,声明字段
在爬虫程序中,首先导入,QingdianHotItem模块
生成Item对象item,用来保存一部小说名字
运行保存。
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from qingdian_hot.items import QingdianHotItem
from scrapy.loader import ItemLoader
class QidianSpiderPySpider(Spider):
name = 'qidian_spider.py'
# allowed_domains = ['www.xxx.com']
# start_urls = ['https://www.qidian.com/rank/yuepiao']
page = 1
def start_requests(self):
url = 'https://www.qidian.com/rank/yuepiao'
yield Request(url, callback=self.qidian_parse)
def qidian_parse(self, response):
list_selector = response.xpath('//*[@id="rank-view-list"]/div/ul//li')
print(len(list_selector))
for book in list_selector:
name = book.xpath('./div[2]/h4/a/text()').extract()[0]
item = QingdianHotItem()
item["name"] = name
yield item
self.page += 1
if self.page <= 5:
next_url ='https://www.qidian.com/rank/yuepiao?page=%d'%(self.page)
yield Request(next_url,callback=self.qidian_parse)
8.ItemLoader填充容器
当我们爬取的数据字段较多,项目很大。
我们可以通过填充容器,配置Item中各个字段的提取规则。
1.导入ItemLoader类
2. 实例化ItemLoader对象
3. ItemLoader提供了3种重要的方法将数据填充进来
add_xpath():使用XPath选择器提取数据
add_css():使用CSS选择器提取数据
add_value():直接传值
4.给Item对象赋值
当提取的数据被填充到ItemLoader后,还需要调用load_item()方法给Item对象赋值
5.进一步处理数据
使用输入处理器(input_processor)和输出处理器(output_processor)对数据的输入和输出进行解析
下面来看一个例子:
在item.py中实现这个功能。
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
from scrapy.loader.processors import TakeFirst
def name_convert(name):
n = name[0]
return n[0]
class QingdianHotItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field(input_processor=name_convert,output_processor=TakeFirst())
9.使用Pipeline处理数据
前面写了对数据的爬取和数据封装,下面将对数据的处理。
使用Item Pipeline来处理数据。
Item Pipeline的作用:
清理数据
验证数据的有效性
查重并丢弃
将数据按照自定义的格式存储到文件中
将数据保存到数据库中
1.编写自己的Item Pipeline
进入pipelines.py,编写自己的Item Pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class QingdianHotPipeline:
def process_item(self, item, spider):
if item["form"] == "连载":
item["form"] = "LZ"
else:
item["form"] =["WJ"]
return item
启用Item Pipeline

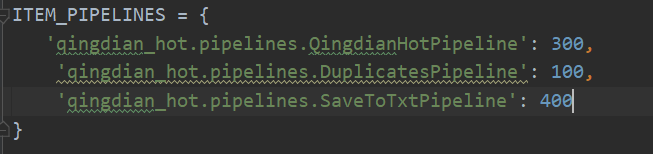
10.多个Item Pipeline
class DuplicatesPipeline(object):
def __init__(self):
#定义一个保存小说名的集合
self.name_set = set()
def process_item(self,item,spider):
if item['name'] in self.name_set:
#抛弃重复的Item项
raise DropItem("查找到重复小说名:%s"%item)
else:
self.name_set.add(item['name'])
return item

优先级设置要小,小的优先执行
11保存为其他类型文件
1.在pipelines.py中,定义一个保存数据的Item Pipeline类SaveToTxtPipeline
class SaveToTxtPipeline(object):
file_name = "hot.txt"
file = None
#Spider开启时,执行打开文件操作
def open_spider(self,spider):
#以追加形式打开文件
self.file = open(self.file_name,"a",encoding="utf-8")
def process_item(self,item,spider):
#获取item中的各个字段,将其连接成一个字符串
# 字段之间用分号隔开
# 字符串末尾要有换行符\n
novel_str = item['name']+";"+ \
item["form"]+"\n"
#将字符串写入文件中
self.file.write(novel_str)
return item
def close_spider(self,spider):
self.file.close()















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









