







嗨害嗨,我又回来分享了,耶。
Look Look Look me !!!
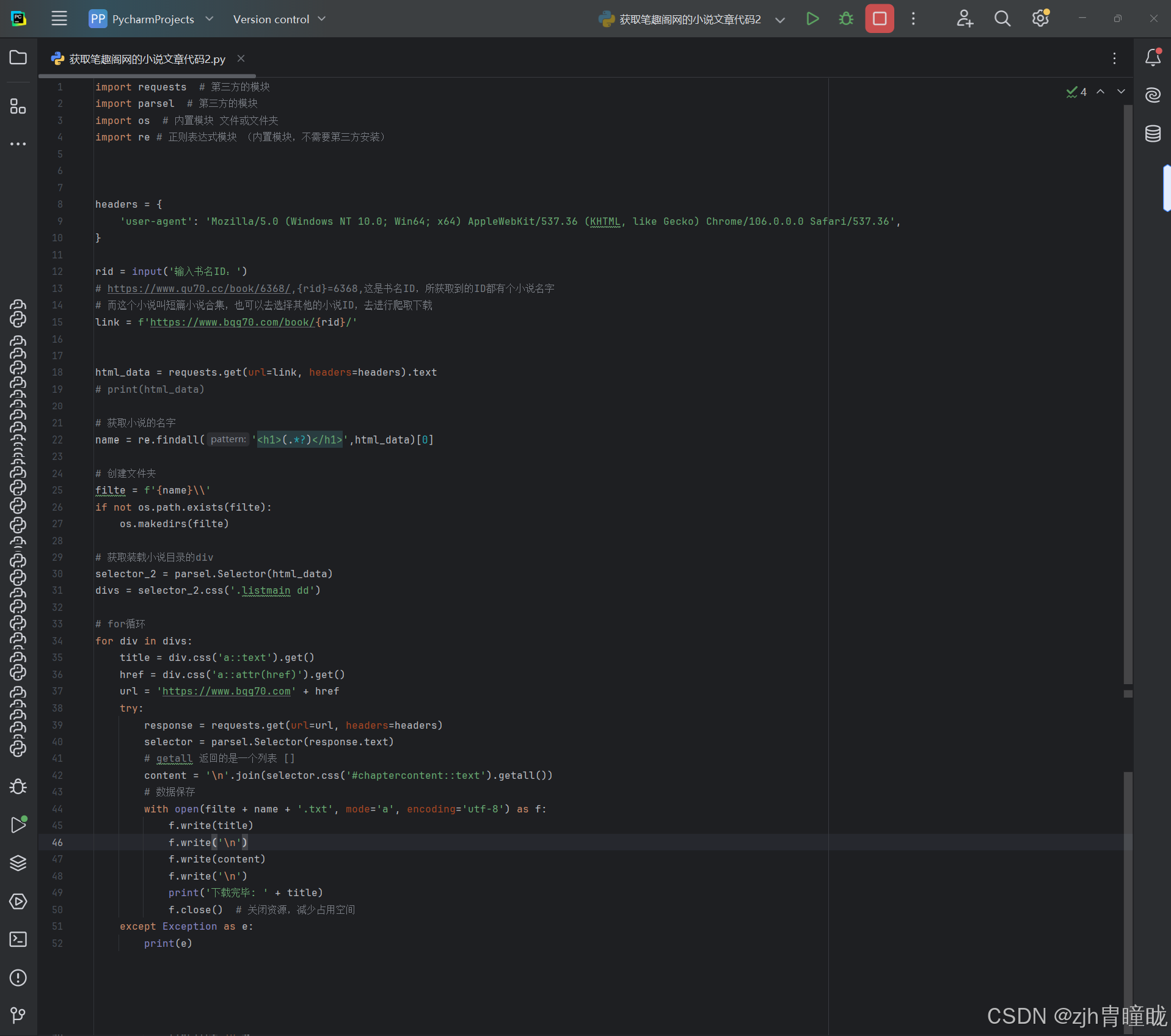
import requests # 第三方的模块
import parsel # 第三方的模块
import os # 内置模块 文件或文件夹
import re # 正则表达式模块 (内置模块,不需要第三方安装)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
rid = input('输入书名ID:')
# https://www.qu70.cc/book/6368/,{rid}=6368,这是书名ID,所获取到的ID都有个小说名字
# 而这个小说叫短篇小说合集,也可以去选择其他的小说ID,去进行爬取下载
link = f'https://www.bqg70.com/book/{rid}/'
html_data = requests.get(url=link, headers=headers).text
# print(html_data)
# 获取小说的名字
name = re.findall('<h1>(.*?)</h1>',html_data)[0]
# 创建文件夹
filte = f'{name}\\'
if not os.path.exists(filte):
os.makedirs(filte)
# 获取装载小说目录的div
selector_2 = parsel.Selector(html_data)
divs = selector_2.css('.listmain dd')
# for循环
for div in divs:
title = div.css('a::text').get()
href = div.css('a::attr(href)').get()
url = 'https://www.bqg70.com' + href
try:
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
# getall 返回的是一个列表 []
content = '\n'.join(selector.css('#chaptercontent::text').getall())
# 数据保存
with open(filte + name + '.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
print('下载完毕: ' + title)
f.close() # 关闭资源,减少占用空间
except Exception as e:
print(e)天色已晚,该是睡觉的时候了,臣已入“棺”。
挥挥手 !!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









