







嗨害嗨,总算是搞定这个了,这几天总是报错(令人头秃),也找过别人的资料了,发现不是想要的,也挺苦恼的,后面才发现是爬取的小说网站,它是带有反爬的,真是要“笑”死(哐哐撞大墙)
于是我选择放弃爬取,转战别处,就ok了
只是这个下载没有那么快,满足不了批量的,但它能用欸,我因此很满足,安息!!!
以下是源代码:
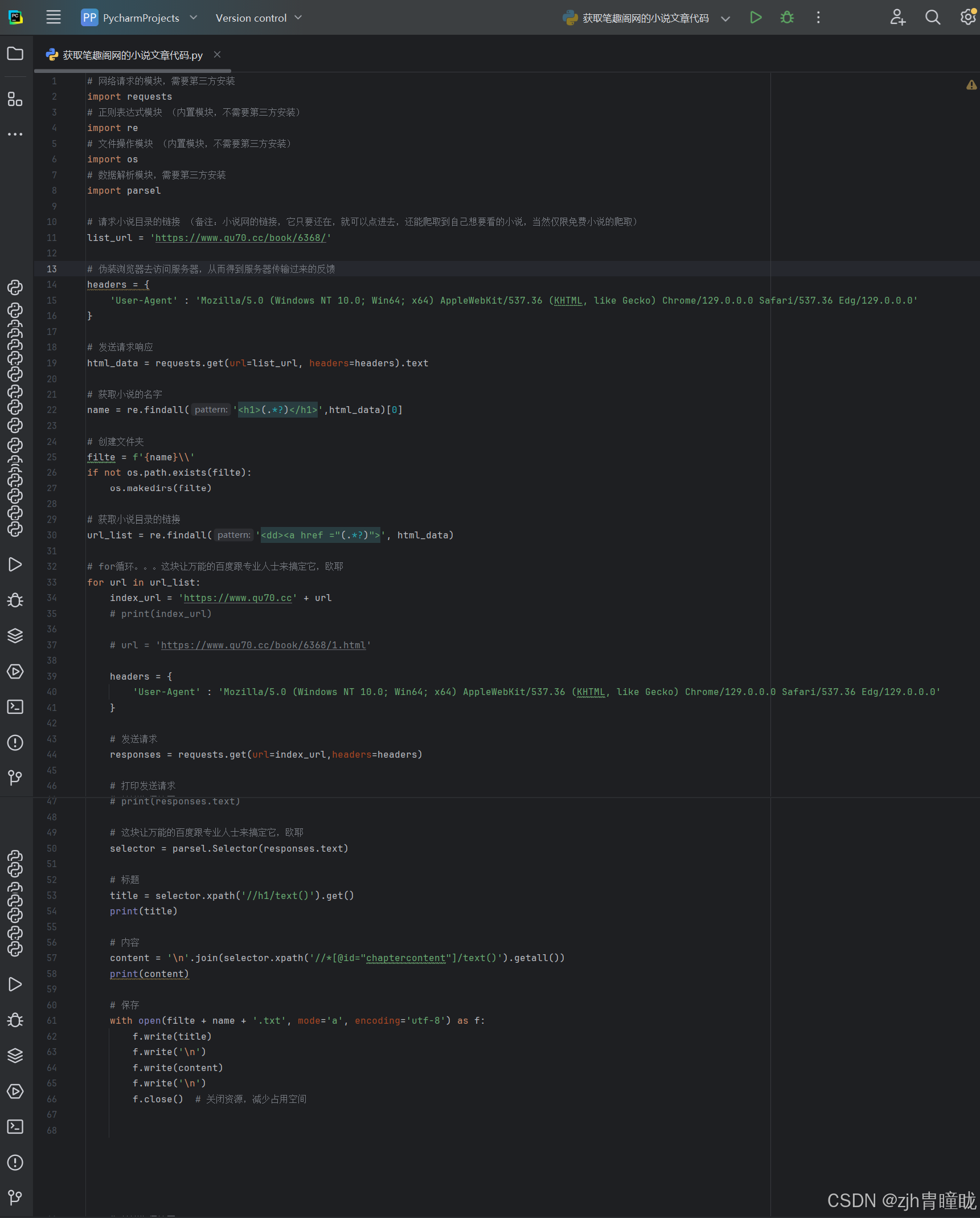
# 网络请求的模块,需要第三方安装
import requests
# 正则表达式模块 (内置模块,不需要第三方安装)
import re
# 文件操作模块 (内置模块,不需要第三方安装)
import os
# 数据解析模块,需要第三方安装
import parsel
# 请求小说目录的链接 (备注:小说网的链接,它只要还在,就可以点进去,还能爬取到自己想要看的小说,当然仅限免费小说的爬取)
list_url = 'https://www.qu70.cc/book/6368/'
# 伪装浏览器去访问服务器,从而得到服务器传输过来的反馈
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 发送请求响应
html_data = requests.get(url=list_url, headers=headers).text
# 获取小说的名字
name = re.findall('<h1>(.*?)</h1>',html_data)[0]
# 创建文件夹
filte = f'{name}\\'
if not os.path.exists(filte):
os.makedirs(filte)
# 获取小说目录的链接
url_list = re.findall('<dd><a href ="(.*?)">', html_data)
# for循环。。。这块让万能的百度跟专业人士来搞定它,欧耶
for url in url_list:
index_url = 'https://www.qu70.cc' + url
# print(index_url)
# url = 'https://www.qu70.cc/book/6368/1.html'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 发送请求
responses = requests.get(url=index_url,headers=headers)
# 打印发送请求
# print(responses.text)
# 这块让万能的百度跟专业人士来搞定它,欧耶
selector = parsel.Selector(responses.text)
# 标题
title = selector.xpath('//h1/text()').get()
print(title)
# 内容
content = '\n'.join(selector.xpath('//*[@id="chaptercontent"]/text()').getall())
print(content)
# 保存
with open(filte + name + '.txt', mode='a', encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(content)
f.write('\n')
f.close() # 关闭资源,减少占用空间
希望你们有帮助哇,臣退了

















 4301
4301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









