







图生图
图生图(img2img)是让AI参照现有的图片生图,源自InstructPix2Pix技术。例如:上传一张真人照片,让AI把他改绘成动漫人物;上传画作线稿,让AI自动上色;上传一张黑白照,让AI把它修复成彩色相片。
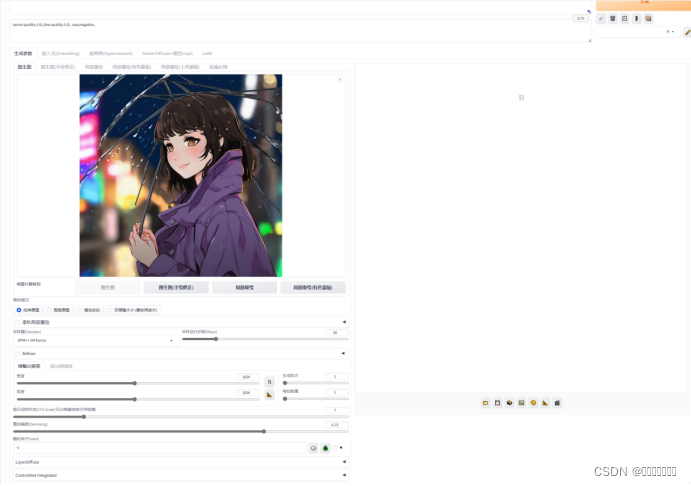
可以通过文生图下的小按钮将图片,提示词以及其他参数整体传递到图生图选项
原始图生图相较于文生图,其上传的图片也相当于参与到提示词中,对ai生成的画面进行限制。其中图生图重要的部分更多的是“局部重绘”,上传蒙版也算是局部重回的一种。
其中“批量处理”有时可以用作ai动画生成的一种方式。
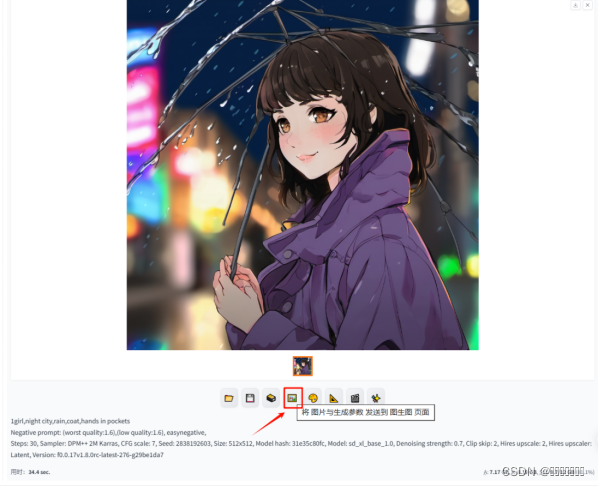
- 图生图(手绘)
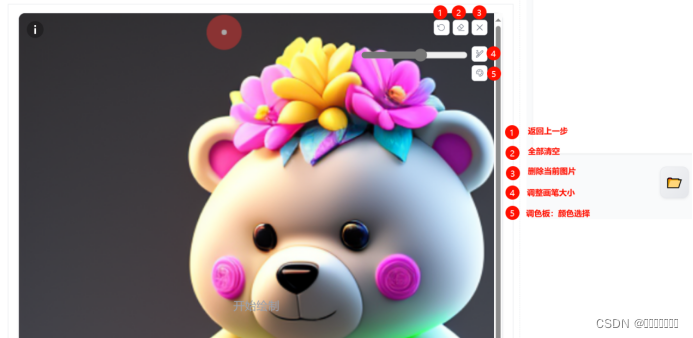
涂鸦工具的参数项和图生图完全相同,唯一区别是上传图像后右上角多了画笔工具,支持我们对图像进行涂抹。涂鸦工具相当于增加了我们传统的手绘过程,在图片上涂抹色块后再进行全图范围的图生图,同时配合提示词可以实现更加多样的重绘效果。
需要注意的是通过涂鸦工具来重绘图像时,由于重绘幅度的影响,画面中未被涂鸦的部分也会发生变化,因此涂鸦工具是针对画面整体进行重绘。
- 局部重绘
当你借助ai生成了一张不错的图片的时候,往往会有一个硬伤,那就是准确性。扩散算法对ai绘画带来无数的可能性,但也带来了各种BUG,例如四肢混乱,景观错误,坏手坏脚等各种问题。当我们抽出了一张不错的图片的时候,却发现~~,而局部重绘就是为了解决类似问题出现的。
局部重绘就是在图像中设定一块区域,在图生图过程中只针对该区域部分进行重绘,而其他部分保持不变,从而实现精准控制改变图像特定部分的效果。该功能通常用于对画面大部分内容都基本满意,但需要调整部分细节元素的场景。
对于局部重绘的参数。蒙版即涂抹部分。其中缩放模式中“潜空间放大”对显存占用较大,一般不建议选用。
@1.蒙版模糊
该参数用于设置重绘区域和原图的融合程度,效果可以简单理解为 PS 中的选区羽化。边缘模糊度太小会导致边缘衔接过于生硬,而数值太高会削弱蒙版的区域限制效果,导致蒙版不精确或直接失效。默认情况下数值是 4,我们可以根据图像的融合效果来进行适度调节。
@2.重绘蒙版区域」表示重绘涂抹过的蒙版区域,「重绘非蒙版区域」表示涂抹区域不变,而是重绘画面中的其他区域。
@3.重绘参考内容,一般原图即可
@4.外部填充:在默认情况下局部重绘会参考全图进行绘制,并且被涂抹的范围并不代表都会发生变化,所以通常我们会在目标区域基础上对外再涂抹一部分区域,以保证重绘后更好的融合效果,而提高边缘预留像素也是同样的原理。
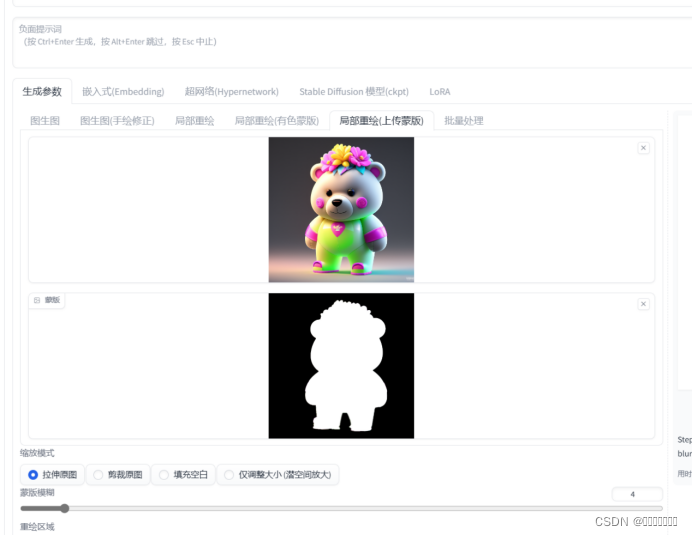
- 蒙版上传
对于有着PS或其他图像处理软件的朋友,他能让你更加精确的控制重绘的区域范围。
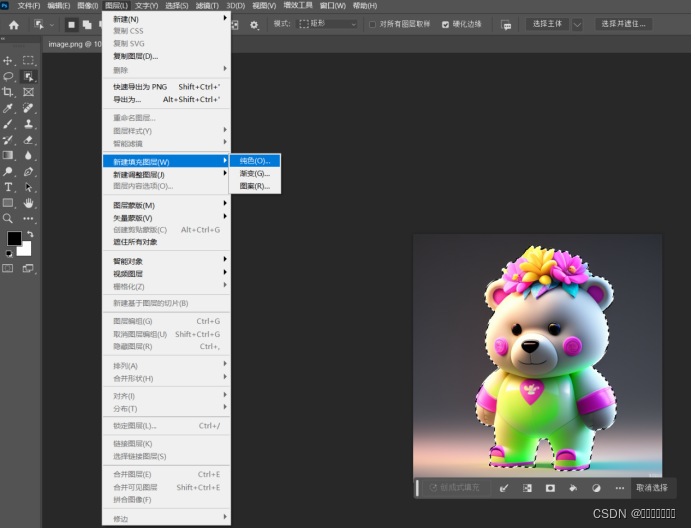
首先获取蒙版。讲图片导入PS进行“选区”
 选中以后:图层--新建填充图层--纯色,
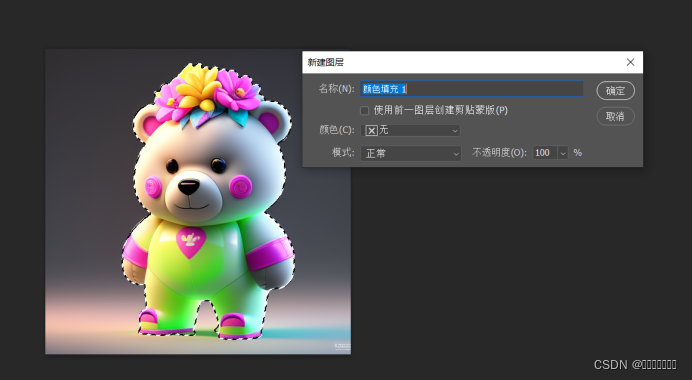
选中以后:图层--新建填充图层--纯色,
- 在拾色器中将颜色定义为白色,
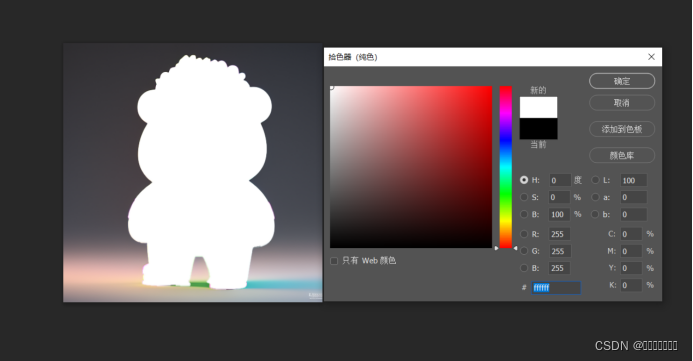
- 选中右下角的白色图层,Ctrl+J复制一个图层
- 双击复制出来的偏左的方框,在拾色器中选为黑色。
- 点击选中偏右的长方形。Ctrl+I交换蒙版区域
这样就得到一张黑白的蒙版图像了。最后点击--文件--存储副本,保存为jpg或png都可以。
5.最后把这张蒙版放入到webUI里面就可以啦。

















 1623
1623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









