






1.1 因特网
因特网是“Internet”的中文译名,它起源于美国的五角大楼,它的前身是美国国防部高级研究计划局
(ARPA)主持研制的ARPAnet。20世纪50年代末,正处于冷战时期。当时美国军方为了自己的计算机网
络在受到袭击时,即使部分网络被摧毁,其余部分仍然能保持通信联系,便由美国国防部的高级研究计
划局(ARPA)建设了一个军用网,叫做“阿帕网(ARPAnet)”。
因特网始于1969年的美国,首先用于军事连接,后将美国西南部的加利福尼亚大学洛杉矶分校、斯坦
福大学研究学院、UCSB(加利福尼亚大学)和犹他州大学的四台主要的计算机连接起来。这个协定由马萨
诸塞州剑桥的BBN科技参与执行,BBN构建了IMP(接口信息处理机),那是一种定制的霍尼韦尔小型
机(Honeywell DDP-516 Minicomputer)。在经过BBN对软件设计,路由,流量控制及网络控制的设
计和构建后,它们被分配到各个站点充当接入ARPANET的网关。BBN在1969年8月30号到年底间陆续制
造了4台IMP,并开始联机。
另一个推动 Internet 发展的广域网是NSF网,它最初是由美国国家科学基金会资助建设的,目的是连接
全美的5个超级计算机中心,供100多所美国大学共享它们的资源。NSF网也采用 TCP/IP协议,且与
Internet 相连。
ARPA网和NSF网最初都是为科研服务的,其主要目的为用户提供共享大型主机的宝贵资源。随着接入主
机数量的增加,越来越多的人把Internet作为通信和交流的工具。一些公司还陆续在Internet上开展了
商业活动。随着Internet的商业化,其在通信、信息检索、客户服务等方面的巨大潜力被挖掘出来,使
Internet有了质的飞跃,并最终走向全球。1.2 Internet与中国
北京时间 1987 年 9 月 14 日,物理研究员钱天白建立起一个网络节点,通过电话拨号连接到国际
互联网,向他的德国朋友发出来自中国的第一封电子邮件:Across the Great Wall we can reach
everycorner in the world,自此,中国与国际计算机网络开始连接在一起。
1990 年 10 月,钱天白教授代表中国正式在国际互联网络信息中心的前身 DDN-NIC 注册登记了我
国的顶级域名 CN,并且从此开通了使用中国顶级域名 CN 的国际电子邮件服务。由于当时中国尚未正
式连入Internet,所以委托德国卡尔斯鲁厄大学运行 CN 域名服务器。
1993 年 3 月 2 日,中国科学院高能物理研究所租用 AT&T(美国电话电报)公司的国际卫星信道
接入美国斯坦福线性加速器中心(SLAC)的 64K 专线正式开通,专线开通后,美国政府以 Internet
上有许多科技信息和其他各种资源,不能让社会主义国家接入为由,只允许这条专线进入美国能源网而
不能连接到其他地方。尽管如此,这条专线仍是我国部分接入 Internet 的第一根专线。
1994 年 4 月 20 日,中国通过一条 64K 的国际专线全功能接入国际互联网,成为国际互联网大家
庭中的第 77 个成员,正式开启了互联网时代。随后,中科院高能物理研究所推出第一个 WWW 网站和
第一套网页。
1994 年 5 月 21 日,在钱天白教授和德国卡尔斯鲁厄大学的协助下,中国科学院计算机网络信息中
心完成了中国国家顶级域名 CN 服务器的设置,改变了中国 CN 顶级域名服务器一直放在国外的历史。
1995 年 5 月 17 日,第 27 个世界电信日,邮电部正式宣布,向国内社会开放计算机互联网接入服务1.3 HTTP超文本传输协议
1.3.1 HTTP相关概念
互联网:是网络的网络,是所有类型网络的母集。
因特网:世界上最大的互联网网络。
即因特网概念从属于互联网概念。习惯上大家连接在因特网的计算机都称为主机。
万维网:WWW(world wide web)万维网并非某种特殊的计算机网络,是一个大规模的、联机式的信
息贮藏库,使用链接的方法能非常方便地从因特网上的一个站点访问另一个站点(超链接技术),
具有提供分布式服务的特点。万维网是一个分布式的超媒体系统,是超文本系统的扩充,
基于 B/S 架构实现。(browser/server)
URL/Uniform Resource Locator:万维网使用统一资源定位符来标志万维网上的各种文档,并使每个
文档在整个因特网的范围内具有唯一的标识符 URL。
HTTP/HyperText Transfer Protocol:即超文本传送协议:
HTTP是处于应用层的协议,使用 TCP 传输层协议进行可靠的传送。
因此,需要特别提醒的是,万维网是基于因特网的一种广泛因特网应用系统,且万维网采用的是
HTTP(80/TCP)和 HTTPS(443/TCP)的传输协议,但因特网还有其他的网络应用系统
(如:FTP、SMTP等)。
HTML/HyperText Markup Language:万维网使用超文本标记语言,使得万维网页面的设计者可以很
方便地使用链接从页面的某处链接到因特网的任何一个万维网页面,并且能够在自己的主机屏幕上将这
些页面显示出来。HTML 与 TXT 一样,仅仅是一种文档,不同之处在于:这种文档传供于浏览器上为浏
览器用户提供统一的界面呈现的统一规约。且具备结构化的特征,这是 TXT 所不具备的强制规定。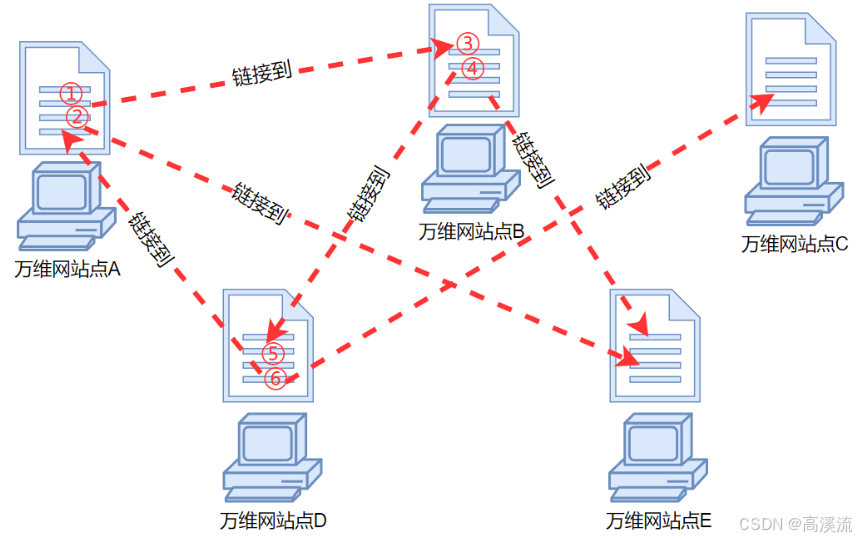
1.3.2 HTTP通信协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是一种用于分布式、协作式的
超媒体信息系统的应用层协议。
HTTP 是万维网的数据通信的基础设计,最初的目的是为了提供一种远距离共享知识的方
式,借助多文档进行关联从而实现超文本,连成相互参阅的 WWW(world wide web,万维网)
HTTP 的发展是由蒂姆▪伯纳斯▪李(Tim Berners-Lee)于1989 年在欧洲核子研究组织(CERN)
所发起。
HTTP 的标准制定由万维网协会(World Wide Web Consortium,W3C)和互联网工程任务组
(Internet Enginering Task Force,IETF)进行协调,最终发布了一系列的 RFC,其中最著名
的是 1999年 6 月公布的 RFC 2616,定义了 HTTP 协议中现今广泛使用的一个版本——HTTP1.1 版本
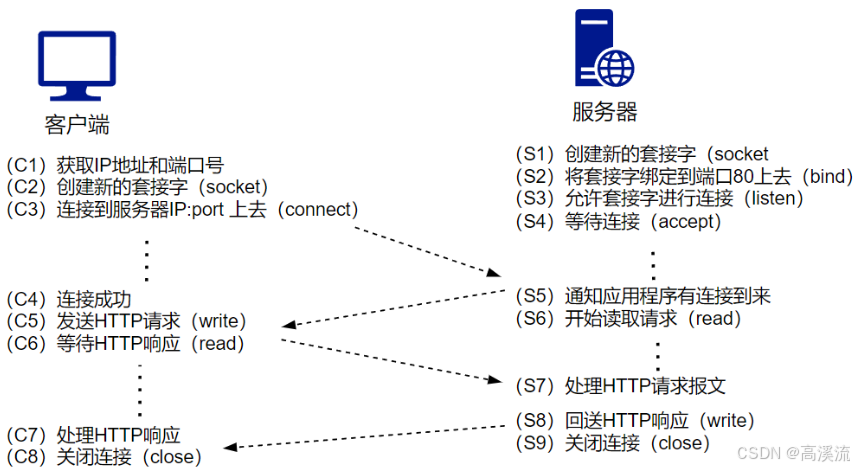
网页:https://www.rfc-editor.org/rfc/rfc791 查看IP等协议定义格式!HTTP 服务通信过程:
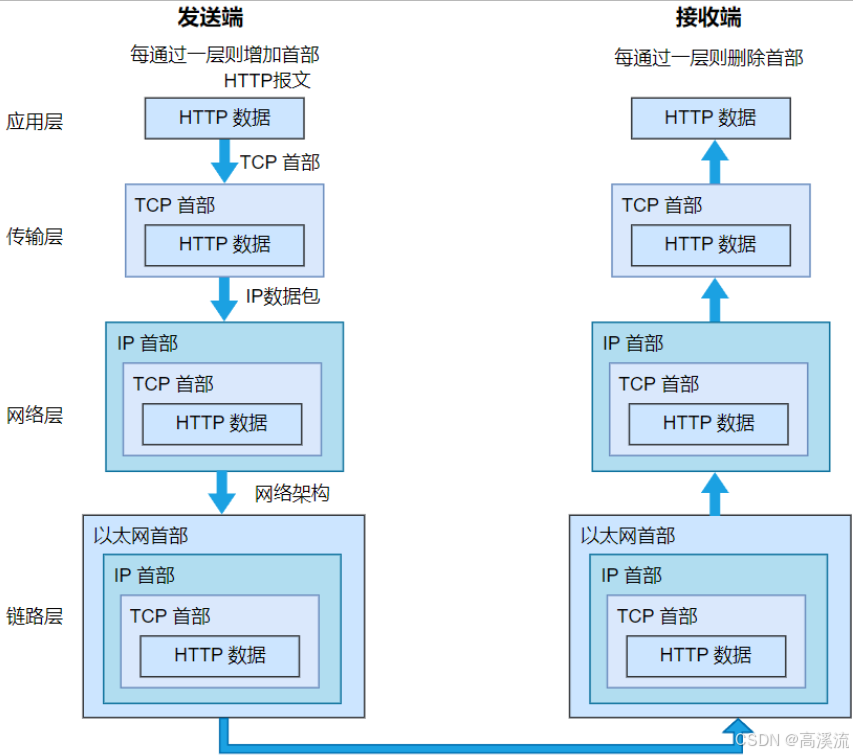
HTTP协议分层:
1.3.3 HTTP相关技术
1.3.3.1 Web开发语言
http:Hyper Text Transfer Protocol 应用层协议,默认端口:80/tcp
web前端开发语言:
html css javascript1.3.3.2 MIME
MIME:Multipurpose Internet Mail Extensions,多用途因特网邮件扩展
(浏览器默认接收和传输文本数据,当传输其他类型数据时需要给予标识/定义告知浏览器数据类型)
文件:/etc/mime.types,来自于 mailcap 包
MIME格式:type/subtype txt html jpg bmp,如:
text/plain txt asc text pm el conf log
text/html html htm
text/css
image/jpeg jpg jpeg
image/png
video/mp4
application/javascript1.3.3.3 URI和URL
URI:Uniform Resource Identifier,统一资源标识,分为 URL 和 URN
URN:Uniform Resource Naming,统一资源命名
如 P2P 下载使用的磁力链接就是 URN 的一种实现:
magnet:?xt=urn:btih:2d2a66e12ec4f61a5a8f5e8fdfed89d2f70859fb
URL:Uniform Resource Locator,统一资源定位符,用于描述某服务特定资源位置
两者区别:URN 如同一个人的名称,找资源时不必知晓资源地址,直接搜名称就行
URL 代表一个人的住址,通过地址找到人
换言之,URN 定义某事物的身份,而URL 提供查询该事物的方法URL示例:

URL组成:

<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
scheme:方案,访问服务器以获取资源时要使用哪种协议
user:用户,某些方案访问资源时需要的用户名
password:密码,用户对应的密码,中间用冒号(:)分隔
Host:主机,资源宿主服务器的主机名或IP地址
Port:端口,资源宿主服务器正在监听的端口号,很多方案有默认端口号
path:路径,服务器资源的本地名,由一个/将其与前面的URL组件分隔
params:参数,指定输入的参数,参数为名/值对,多个参数用逗号(,)分隔
query:查询,传递参数给程序,如数据库,用?分隔,多个查询用&分隔
frag:片段,一小片或一部分资源的名字,此组件在客户端使用,用#分隔
1.3.3.4 网站访问量
网站访问量统计的重要指标
IP:即 Internet Protocol,指独立IP数,一天内来自相同客户机 IP 地址只计算一次,
记录远程客户机 IP 地址的计算机访问网络的次数,是衡量网站流量的重要指标。
PV:即 Page View,页面浏览量或点击量,用户每次刷新被计算一次,PV 反映的是浏览某网站的
页面数, PV 与来访者的数量成正比,PV 并不是页面的来访者数量,而是网站被访问的页面数量。
UV:即 Unique Visitor,访问网站的一台电脑为一个访客。一天内相同的客户端只被计算一次。可
以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过 coolies 实现的。如果更换了
IP 后但不清楚 Cookies,再访问相同的网站,该网站的统计中 UV 数不变。1.3.4 HTTP工作机制
一次事务包括:
http请求:http request
http响应:http responsewed资源:web resource,一个网页由多个资源(文件)构成,打开一个页面,通常会有多个资源展示出来,但是每个资源都要单独请求。因此,一个 Web 页面通常并不是单个资源,而是一组资源的集合。
资源类型:
静态文件:无需服务端做出额外处理,服务器端和客户端的文件内容相同。
常见文件后缀:.html、.txt、.jpg、.js、.css、.mp3、.avi 等
动态文件:服务端执行程序,返回执行的结果,服务端和客户端的文件内容不相同。
常见文件后缀:.php、.jsp、.asp、.py、.go 等HTTP连接请求:
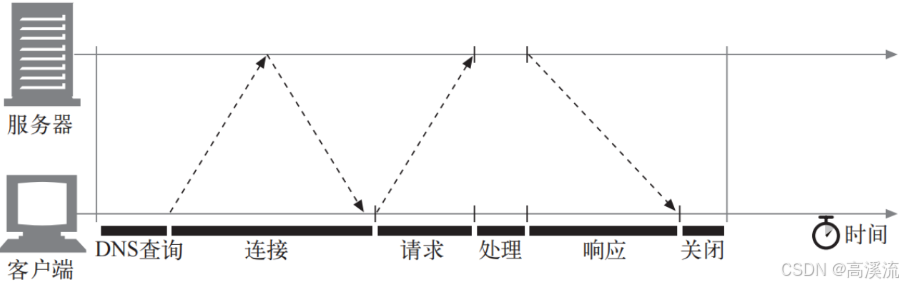
1.3.5 HTTP协议版本
1.3.5.1 HTTP 1.x协议
http/0.9
1991,原型版本,功能简陋只有一个命令 GET。GET /index.html,服务器只能回应 HTML 格式
字符串,不能回应别的格式。http/1.0
1996 年 5 月,支持 cache,MIME,method每个 TCP 连接只能发送一个请求,发送数据完毕,
连接就关闭,如果还要请求其他资源,就必须再新建一个连接。引入 POST 命令和 HEAD 命令,
头信息是 ASCII 码,后面数据可为任何格式。服务器回应时会告诉客户端,数据是什么格式,
即 Content-Type 字段的作用。这些数据类型总称为 MIME(多用途互联网邮件扩展),每个值
包括一级类型和二级类型,预定义的类型,也可以自定义类型。常见 Content-Type 值有:
text/html、image/jpge、audio/mp3 等。http/1.1
1997 年 1 月,引入持久连接(persistent connection),即 TCP 连接默认不关闭,可以
被多个请求复用,不用声明 Connection: keep-alive。对于同一个域名,大多数浏览器允许
同时建立 6 个持久连接。同时还引入了管道机制,即在同一个 TCP 连接中,客户端可以同时
发送多个请求,进一步改进了 HTTP协议的效率。
新增方法:PUT、PATCH、OPTIONS、DELETE同一个 TCP 连接里,所有的数据通信是按次序进行的
服务器只能顺序处理回应,前面的回应慢,会有许多请求排队,造成“队头堵塞(Head-of-line
Blocking)”。为避免上述问题,有两种方法:一是减少请求数;二是同时多开持久连接。
网页优化技巧,如合并脚本和样式表、将图片嵌入 CSS 代码、域名分片(domain sharding)等
HTTP 协议不带有状态,每次请求都必须附上所有信息。请求的很多字段都是重复的,浪费带宽,影响
速度。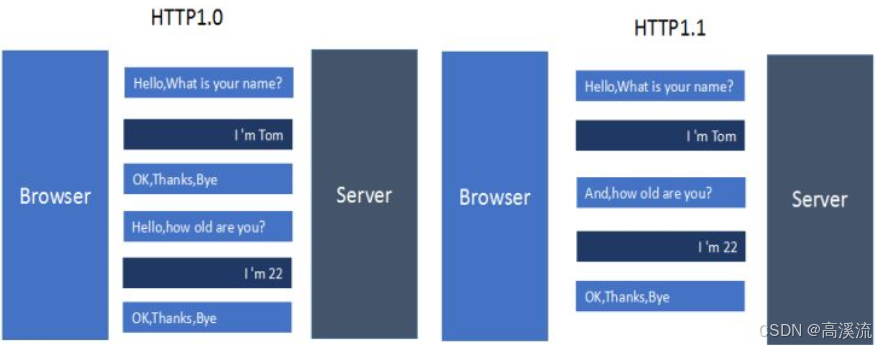
1.3.5.2 HTTP 2.0协议
SPDY协议
SPDY:2009 年谷歌研发,综合 HTTPS 和 HTTP 两者优点于一体的传输协议,主要特点:
1.降低延迟:针对 HTTP 高延迟的问题,SPDY 优雅的采用了多路复用(Multiplexing)。多路复用通过多个请求 stream 共享一个 tcp 连接的方式,解决了 Head-of-line blocking 的问题,降低了延迟同时提高了带宽的利用率。
2.请求优先级(Request Prioritization):多路复用带来一个新的问题是:在连接共享的基础上有可能会导致关键请求被阻塞。SPDY 允许给每个 request 设置优先级,重要的请求会优先得到响应。比如浏览器加载首页。
3.Header压缩:HTTP 1.x 的 header 很多时候都是重复多余的,选择合适的压缩算法可以减少包的大小和数量。
4.基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
5.服务端推送(Server push),采用了 SPDY 的网页,如网页有一个 style.css 的请求,在客户端收到 style.css 数据的同时,服务端会将 style.js 的文件推送给客户端,当客户端再次尝试获取 style.js时就可以直接从缓存中获取到,不用再发请求了。
HTTP2协议
http/2.0:2015年发布,HTTP2.0是 SPDY 的升级版
1.头信息和数据体都是二进制,称为头信息帧和数据帧
2.复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求和响应,且不用按顺序响应,避免了“队头堵塞”,此双向的实时通信称为多工(Multiplexing)
3.引入头信息压缩机制(Header Compression),头信息使用 gzip 或 compress 压缩后再发送;客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,不发送同样字段,只发送索引号,提高速度。
4.HTTP/2 允许服务器有新数据时未经请求,主动向客户端发送资源,而无需客户端拉取,即服务器推送。
HTTP2.0和SPDY区别
HTTP2.0 支持明文 HTTP 传输,而 SPDY 强制使用 HTTPS
HTTP2.0 消息头的压缩算法采用 HPACK,而 SPDY 采用 DEFLATE1.3.6 HTTP请求访问的完整过程
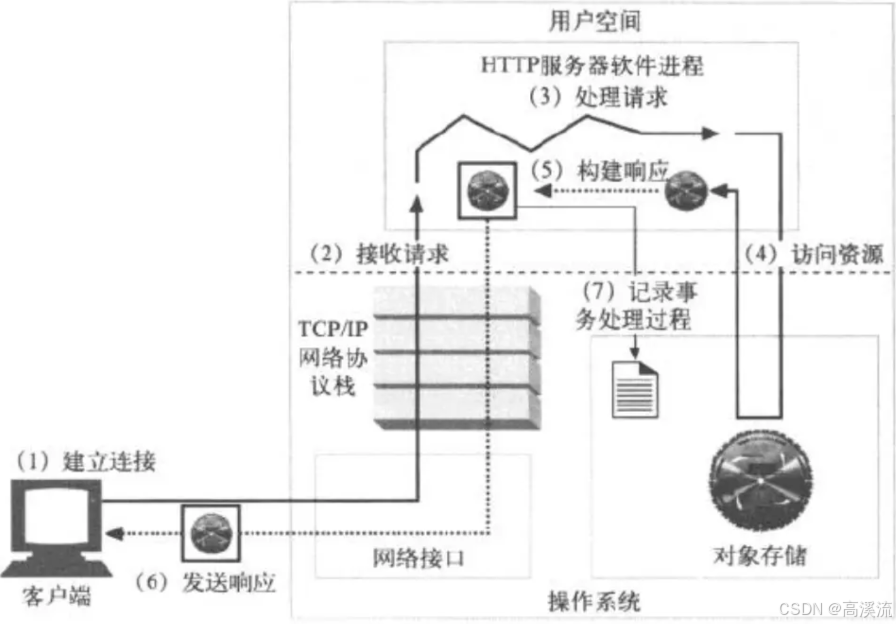
一次完整的HTTP请求过程:
1.建立连接:接收或拒绝连接请求
2.接收请求:接收客户端请求报文中对某资源的一次请求的过程
3.处理请求:
服务器对请求报文进行解析,并获取请求的资源及请求方法等相关信息,根据方法、资
源、首部和可选的主体部分对请求进行处理。常用请求Method:GET、POST、HEAD、PUT、
DELETE、TRACE、OPTIONS4.访问资源
服务器获取请求报文中请求的资源web服务器,即存放了web资源的服务器,负责向请求
者提供对方请求的静态资源,或动态运行后生成的资源5.构建响应报文
一旦Web服务器识别除了资源,就执行请求方法中描述的动作,并返回响应报文。响应报文中包含有响
应状态码、响应首部,如果生成了响应主体的话,还包括响应主体
1)响应实体:如果事务处理产生了响应主体,就将内容放在响应报文中回送过去。响应报文中
通常包括:
描述了响应主体MIME类型的Content-Type首部
描述了响应主体长度的Content-Length
实际报文的主体内容
2)URL重定向:web服务构建的响应并非客户端请求的资源,而是资源另外一个访问路径
3)MIME类型:Web服务器要负责确定响应主体的MIME类型。多种配置服务器的方法可将MIME类型与
资源管理起来
魔法分类:Apache web服务器可以扫描每个资源的内容,并将其与一个已知模式表(被称为魔法
文件)进行匹配,以决定每个文件的MIME类型。这样做可能比较慢,但很方便,尤其是文件没有标准扩
展名时
显式分类:可以对Web服务器进行配置,使其不考虑文件的扩展名或内容,强制特定文件或目录
内容拥有某个MIME类型
类型协商:有些Web服务器经过配置,可以以多种文档格式来存储资源。在这种情况下,可以配
置Web服务器,使其可以通过与用户的协商来决定使用哪种格式(及相关的MIME类型)最好"6.发送响应报文
Web服务器通过连接发送数据时也会面临与接收数据一样的问题。服务器可能有很多条到各个客户端的
连接,有些是空闲的,有些在向服务器发送数据,还有一些在向客户端回送响应数据。服务器要记录连
接的状态,还要特别注意对持久连接的处理。对非持久连接而言,服务器应该在发送了整条报文之后,
关闭自己这一端的连接。对持久连接来说,连接可能仍保持打开状态,在这种情况下,服务器要正确地
计算Content-Length首部,不然客户端就无法知道响应什么时候结束7.记录日志
最后,当事务结束时Web服务器会在日志文件中添加一个条目来描述已执行的事务(记录6个月)
1.4 HTTP协议报文头部结构
http协议:http/0.9,http/1.0,http/1.1,http/2.0
http协议:stateless 无状态,服务器无法持续追踪访问者来源(服务器不记载客户端信息)
解决http协议无状态方法:
cookie 客户端存放
session 服务端存放
http事务:一次访问的过程
请求:request
响应:response
http报文结构:
协议查看或分析的工具:tcpdump,wireshark,tshark1.4.1 HTTP请求报文
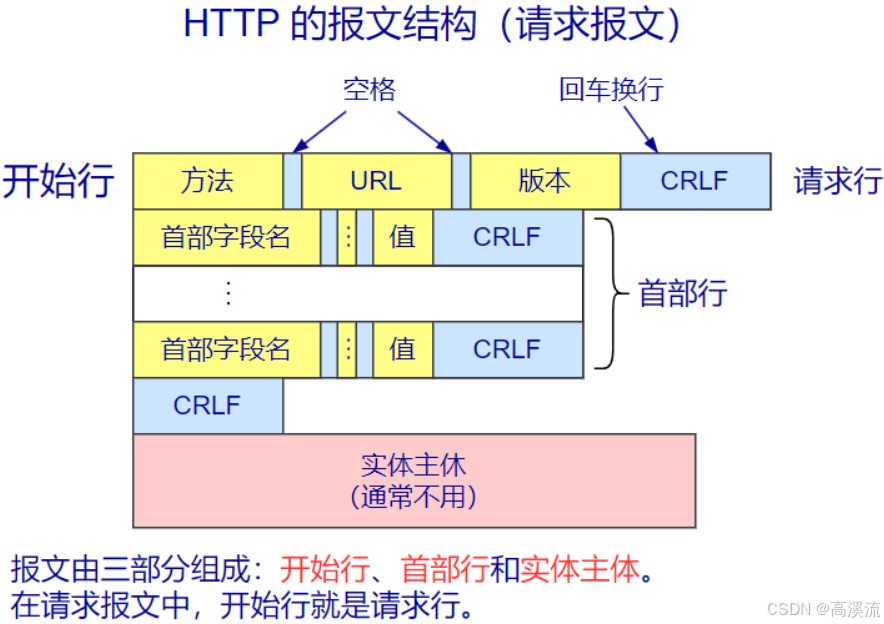
文字内容展示:
GET / HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: www.baidu.com
User-Agent: Httpie/0.94请求字段说明:
Host :客户端端请求的域名。
Connection :告诉服务端,处理完本请求后,是否关闭连接。
User-Agent :客户端使用的浏览器或APP 类型/版本。
Accept :客户端支持哪些类型的文档。
Accept-Encoding :客户端支持的编码类型。
Accept-Language :客户端支持的语言类型。
Referer :客户端从哪个网页过来的。
Cache-Control :指定缓存机制。在Linux中通过如下命令来查看:
[root@localhost ~]# curl -v http://www.baidu.com
* Trying 183.2.172.185:80...
* Connected to www.baidu.com (183.2.172.185) port 80 (#0)
> GET / HTTP/1.1
> Host: www.baidu.com
> User-Agent: curl/7.76.1
> Accept: */*1.4.2 HTTP响应报文
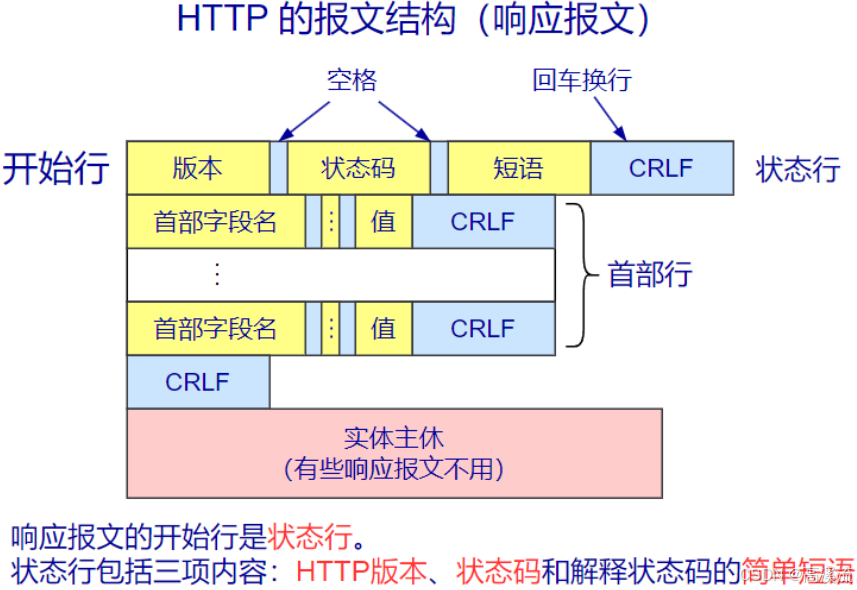
文字内容展示:
HTTP/1.1 200 OK
Cache-Control: max-age=3, must-revalidate
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html; charset=UTF-8
Date: Thu, 07 Nov 2023 03:44:14 GMT
Server: Tengine
Transfer-Encoding: chunked
Vary: Accept-Encoding, Cookie响应字段说明:
Allow :表明服务器支持哪些请求方法,如GET,POST 等。
Content-Encoding :响应内容编码方法。
Content-Type :响应内容属于什么MIME 类型。
Content-Length :响应内容的长度。
Date :当前GMT 时间。
Expiress :响应内容过期时间,过期后将不再缓存内容。
Last-Modified :文档的最后改动时间。
Location :告诉客户端到哪里获取文档,一般用于重定向
Refresh :浏览器在多少秒后刷新文档。
Server :服务器名字
Set-Cookie :设置和页面关联的Cookie。
Date :表示消息发送时间在Linux中通过如下命令来查看:
[root@localhost ~]# curl -I www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 277
Content-Type: text/html
Date: Mon, 04 Nov 2024 06:10:00 GMT
Etag: "575e1f71-115"
Last-Modified: Mon, 13 Jun 2016 02:50:25 GMT
Pragma: no-cache
Server: bfe/1.0.8.181.4.3 HTTP报文格式详解
1.4.3.1 Method方法
请求方法,标明客户端希望服务器对资源执行的动作,包括如下:
| 请求方法 | 说明 |
| GET | 从服务器获取一个资源 |
| POST | 向服务器输入数据,通常会再由网关程序继续处理 |
| HEAD | 只从服务器获取文件的响应头部 |
| PUT | 将请求的主体部分存储在服务器中,如上传文件 |
| DELETE | 请求删除服务器上指定的文档 |
| TRACE | 追踪请求到达服务器中间经过的代理服务器 |
| OPTIONS | 请求服务器返回对指定资源支持使用的请求方法 |
| CONNECT | 建立一个由目标资源标识的服务器的隧道 |
| PATCH | 用于对资源应用部分修改 |
1.4.3.2 status状态码
服务器在向客户端返回内容时会带着一个:HTTP Status Code(状态码),用于告诉客户端返回状态
HTTP状态码分为5种类型,由三位十进制数字组成:
第一个数字(1-5)代表状态码的分类,后两位是其含义。| 状态码类型 | 说明 |
| 1xx | 表明服务器已经收到请求 |
| 2xx | 表明服务器已经成功接收并处理请求 |
| 3xx | 表明请求的资源已重定向到其他地方 |
| 4xx | 表明客户端请求出错 |
| 5xx | 表明服务端出现错误 |
常见状态码:
| 状态码 | 说明 |
| 100 | 客户端应继续其请求 |
| 200 | 请求成功,一般用于GET和POST请求 |
| 301 | 请求的资源已被永久重定向到新地址 |
| 302 | 请求的资源已被临时重定向到新地址 |
| 304 | 客户端访问的内容未修改,应从缓存中获取内容 |
| 400 | 客户端请求有误 |
| 401 | 请求要求客户端进行身份认证 |
| 403 | 服务端拒绝客户端访问 |
| 404 | 客户端请求的资源服务端不存在 |
| 405 | 客户端请求的方法被禁止 |
| 500 | 服务器内部错误 |
| 501 | 服务器不支持该请求 |
| 502 | 服务器宕机 |
| 503 | 服务器过载,暂时不可用 |
| 505 | 客户端使用的HTTP版本,服务端不支持 |
1.4.3.3 reason-phrase原因短语
状态码所标记的状态的简要描述
1.4.3.4 headers首部头字段
首部字段包含的信息最为丰富,首部字段同时存在于请求和响应报文内,并涵盖HTTP报文相关的内容
信息。使用首部字段是为了给客户端和服务器提供报文主体大小、所使用的语言、认证信息等内容。
首部字段是由首部字段名和字段值构成的,中间用冒号(:)分隔的字段值对应,即key/value键/值对
单个 HTTP 首部字段可以有多个值。1.4.3.5 entity-body实体
请求时附加的数据/响应时附加的数据:
eg:登录网站时的用户名和密码、博客的上传文章、论坛上的发言等。1.5 Web相关工具
1.5.1 wget
[root@localhost ~]# wget --help
Usage: wget [OPTION]... [URL]...
1.5.2 curl
[root@localhost ~]# curl --help
Usage: curl [options...] <url>
1.6 Web服务介绍
Netcraft 公司于 1994 年底在英国成立,多年来一直致力于互联网市场以及在线安全方面的咨询服务,其中在国际上最具影响力的当属其针对网站服务器、域名解析/主机提供商,以及SSL市场所做的客观严谨的分析研究。
https://www.netcraft.com/blog/february-2024-web-server-survey/
1.6.1 Apache 经典的Web服务端
Apache起初由美国的伊利诺大学香槟分校的国家超级计算机应用中心开发,目前经历了两大版本,分别是1.x和2.x,其可以通过编译安装实现特定的功能。官方网站:http://www.apache.org
MPM(multi-processing module)三种工作模式:
1.6.1.1 Apache prefork模型
1.6.1.2 Apache worker模型
1.6.1.3 Apache event模型
1.6.2 Nginx高性能的 Web 服务端
Nginx 是由俄罗斯国立莫斯科鲍曼科技大学在 1994 年毕业的学生为俄罗斯 rambler.ru 公司开发的,开发工作最早从 2002 年开始,第一次公开发布时间是 2004 年 10 月 4 日,版本号是 0.1.0。
2019 年 3 月 11 日 F5 与 Nginx 达成协议,F5 将收购 Nginx 的所有已发行股票,总价值约为 6.7 亿美元,约合人民币 44.97 亿,而 Nginx 核心模块代码长度 198430(包括空格和注释),所以一行代码约为 2.2 万人民币。
官网地址:https://nginx.org/
Nginx 历练十几年的迭代更新,目前功能已经非常完善且运行稳定,分为社区版和商业版。另外 Nginx的社区版分为开发版(奇数)、最新稳定版(偶数)和过期版。Nginx 以功能丰富著称,它即可以作为http 服务器,也可以作为反向代理服务器或者邮件服务器。能够快速的响应静态网页的请求,支持FastCGI/SSL/Virtual Host/URL Rwrite/Gzip/HTTP Basic Auth/http 或者 TCP 的负载均衡等功能,并且支持第三方的功能扩展。
天猫、淘宝、京东、小米、163、新浪等一线互联网公司都在用 Nginx 或者进行二次开发。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









