






面试题
- 一、spring相关
- Spring
- 1.1 spring框架中的单例bean是线程安全的吗
- 1.2 *什么是AOP?
- 1.3 Spring中事务失效的场景有哪些
- 1.4 Spring的常见注解
- 1.5 *请说一说springboot自动配置原理
- 1.6 *谈一谈对IoC的理解
- 二、Mysql相关
- 优化
- 1.1 如何定位慢查询
- 1.2 那这条SQL语句执行很慢,如何分析
- 1.3 *了解索引吗—索引的底层数据了解吗
- 1.4 *什么是聚簇索引什么是非聚簇索引
- 1.5 知道什么是覆盖索引吗
- 1.6 MySql超大分页怎么处理
- 1.7 索引创建原则有哪些
- 1.8什么情况下索引会失效
- 1.9 *谈一谈你对sql优化的经验
- 事务
- 2.1 *事务的特性是什么,详细说一下
- 2.2 *怎么解决并发事务问题
- 2.3 undo log和redolog的区别
- 2.4 事务中的隔离性如何保证(解释MVCC)
- 2.5 主从同步原理
- 2.6 了解分库分表嘛?
- Mybatis
- 3.1 Mybatis执行流程
一、spring相关
Spring
1.1 spring框架中的单例bean是线程安全的吗
不是线程安全的
Spring框架中有一个@Scope注解,默认值就是singleton,单例的
因为一般在spring的bean中都是注入无状态的对象,没有线程安全问题,如果bean中定义了可修改的成员变量,是需要考虑线程安全问题的。

1.2 *什么是AOP?
什么是AOP
面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取公共模块复用,降低耦合
你们项目中有没有用到AOP
- 记录操作日志,缓存,spring实现的事务
核心是:使用aop中的环绕通知+切点表达式(找到要记录日志的方法)通过环绕通知的参数获取请求方法的参数(类、方法、注解、请求方式等),获取到这些参数以后,保存到数据库
Spring中的事务是如何实现的
其本质是通过AOP功能,对方法前后进行拦截,在执行方法之前开启事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
1.3 Spring中事务失效的场景有哪些
- 异常捕获处理,自己处理了异常,没有抛出,解决:手动抛出
- 抛出检查异常,配置rollbackFor属性为Exception
- 非public方法导致的事务失效,改为public
1.4 Spring的常见注解
| 注解 | 说明 |
|---|---|
| @component、@Controller、@Service、@Repository | 使用在类上用于实例化Bean |
| @Autowired | 使用在字段上用于根据类型依赖注入 |
| @Qualifier | 结合@Autowired一起使用用于根据名称进行依赖注入 |
| @Scope | 标注Bean的作用范围 |
| @Configuration | 指定当前类是一个 spring 配置类,当创建容器时会从该类上加载注解 |
| @ComponentScan | 用于指定Spring在初始化容器时要扫描的包 |
| @Bean | 使用在方法上,标注将该方法的返回值存储到Spring容器中 |
| @lmport | 使用@Import导入的类会被Spring加载到I0C容器中 |
| @Aspect、@Before、@After、@Around、@Pointcut | 用于切面编程(AOP) |
| 注解 | 说明 |
|---|---|
| @RequestMapping | 用于映射请求路径,可以定义在类上和方法上。用于类上,则表示类中的所有的方法都是以该地址作为父路径 |
| @RequestBody | 注解实现接收http请求的json数据,将json转换为java对象 |
| @RequestParam | 指定请求参数的名称 |
| @PathViriable | 从请求路径下中获取请求参数(/user/{id}),传递给方法的形式参数注解 |
| @ResponseBody | 实现将controller方法返回对象转化为json对象响应给客户端 |
| @RequestHeader | 获取指定的请求头数据 |
| @RestController | @Controller+@ResponseBody |
| 注解 | 说明 |
|---|---|
| @SpringBootConfiguration | 组合了- @Configuration注解,实现配置文件的功能 |
| @EnableAutoConfiguration | 打开自动配置的功能,也可以关闭某个自动配置的选 |
| @ComponentScan | Spring组件扫描 |
1.5 *请说一说springboot自动配置原理
自动配置:
遵循***约定大于配置***的原则,在起步依赖中的一些bean对象会自动注入到ioc容器管理中
面试问题:请说一说spring boot自动配置原理?
回答的关键:
- 约定大于配置
- 自动扫描
- 本质就是spring的脚手架
- @EnableAutoConfiguration
- spring.factories
- 条件注解
在主启动类上添加了SpringbootApplication注解,这个注解组合了EnableAutoConfiguration注解
EnableAutoConfiguration注解又组合了Import注解,导入AutoConfigurationImportSelector类
这个类实现了selectImports方法,这个方法经过层层调用,最终会读取META-INF目录下的后缀名为imports的文件
文件里里面配置了很多自动配置的全类名,springboot读取到全类名之后,会解析注册条件,也就是@Condtional及其衍生注解,把满足注册条件的bean对象自动注入到IOC容器中
1.6 *谈一谈对IoC的理解
Ioc
两方面回答
ioc的理解
ioc怎么实现
Ioc本质就是 对象的创建
以及 对象依赖
Spring中的loC(Inversion of Control)是一种设计原则,通过该原则,对象的创建和依赖关系的管理被转移到了容器中,从而降低了对象之间的耦合性。我对Spring中的loC的理解如下:
- 控制反转:传统的对象创建和依赖关系的管理由程序员手动完成,而在IoC中,这些工作被交给了容器来完成.
- 容器:loC的核心是容器,它负责创建和管理对象。容器通过读取配置文件或注解来了解对象之间的依赖关系,并根据这些信息创建对象,并将它们注入到其他对象中。
- 依赖注入:容器通过依赖注入的方式来实现对象之间的解耦。依赖注入可以通过构造函数、setter方法或注解来完成。通过依赖注入,对象只需要关注自己的业务逻辑,而不需要关心如何获取依赖对象。
- 松耦合:IoC使得对象之间的依赖关系变得松耦合,对象只需要依赖抽象而不依赖具体实现。这使得代码更加灵活和可维护,可以方便地普换依赖的对象。
- 可测试性:IoC使得代码更容易进行单元测试。由于对象的依赖关系被注入,可以方便地使用模拟对象来进行测试,减少了对外部资源的依赖。
可以从比较粗的角度介绍写loc中的核心对象的作用:
Beanpefinition:BeanDefinition是Spring中定义Bean的元数据信息的接口。它包含了Bean的类名、属性、构造函数参数等信息,通过BeanDefinition可以告诉容器如何创建和配置Bean。BeanpefinitionRegistry: BeanDefinitionRegistry提供了对BeanDefinition的管理和操作功能,是SpringloC容器中用于注册和管理Bean的核心接口。
。BeanFactory:BeanFactory是SpringloC容器的核心接口,负责实例化、配置和管理应用中的对象(Bean)。它是loC容器的基础,提供了一种获取Bean的机制,可以通过Bean的名称或类型来获取Bean的实例。Appiicationcontext:ApplicationContext是BeanFactory的子接口,它是Spring中更高级的loC容器。除了提供BeanFactory的功能外,它还提供了更多的企业级功能,例如国际化支持、事件发布、资源加载等。BeanPostProcessor:BeanPostProcessor是Spring中的一个扩展接口,用于在Bean实例化和依赖注入的过程中对Bean进行增强处理,通过实现BeanPostProcessor接口,可以在Bean的初始化前后对Bean进行自定义操作。BeanWrapper:BeanWrapper是Spring中对Bean对象的一种封装,提供了对Bean属性的访问和设置的方法。BeanWrapper可以对Bean的属性进行类型转换和验证等操作。
二、Mysql相关
优化
1.1 如何定位慢查询
以下是慢查询的可能:
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
表象:页面加载过慢,接口压测响应时间过长 (超过1s)
回答:
1.介绍当时产生问题的场景(我们当时的一个接口测试的时候非常的慢,压测时间大概是5s左右)
2.我们系统中当时采用了运维工具(Skywalking),可以检测到哪个接口,最终是因为sql的问题
3.当时在调试阶段中开启了MySQL的慢日志服务查询,我们设置的值是两秒,一旦sql执行时间超过两秒就会被记录到日志中。

1.2 那这条SQL语句执行很慢,如何分析
以下原因:
- 聚合查询 :新增一个临时表
- 多表查询:试着优化SQL语句的结构
- 表数据量过大查询:添加索引
- 深度分页查询
如果还是不行,可以关注**SQL执行计划**(找到慢的原因)
回答:
可以采用Mysql自带的分析工具
- 通过key和key_len检查是否命中了索引(索引本身存在是否存在有失效的情况)
- 通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
- 通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或者修改返回字段来修复

1.3 *了解索引吗—索引的底层数据了解吗
了解索引吗?
- 索引(index)是帮助MySQL高效获取数据的数据结构(有序)
- 提高数据检索的效率,降低数据库的I0成本(不需要全表扫描)
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
索引的底层数据了解吗?
MySQL的InnoDB引擎采用的B+树的数据结构来存储索引
- 阶数更多,路径更短
- 磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- B+树便于扫库和区间查询,叶子节点是一个双向链表

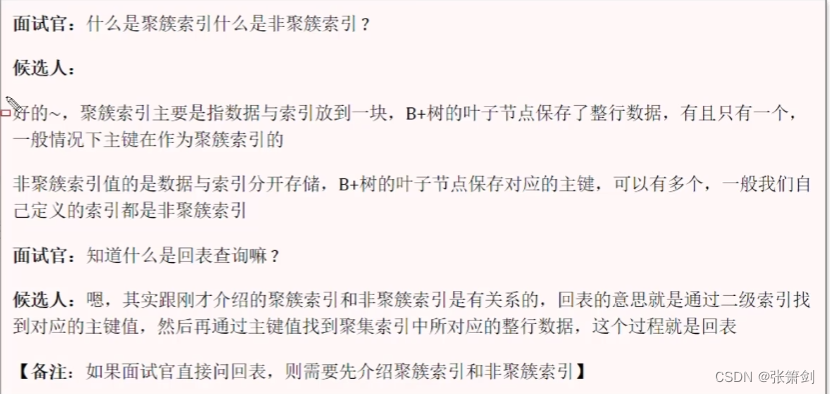
1.4 *什么是聚簇索引什么是非聚簇索引
也可能会问:
什么是聚集索引,什么是非聚集索引索引(二级索引)?
什么是回表?
- 聚簇索引(聚集索引):数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个
- 非聚簇索引(二级索引):数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多
聚集索引底层存储的是一整行的数据
非聚集(二级)索引存储的是主键id
然后会问:
知道什么是回表查询吗?
回表查询:select * from user where name = 'Tom'
- 通过二级索引找到对应的主键值,到聚集索引中查找整行数据,这个过程叫做回表查询
先进行一次查询Tom,获得Tom的主键id,然后用id查找Tom的全部信息——回表查询
1.5 知道什么是覆盖索引吗
覆盖索引:是指查询使用了索引,返回的列,必须在索引中全部能够找到:
- 使用id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
- 如果返回的列中没有创建索引,有可能会触发回表查询,尽量避免使用select*
1.6 MySql超大分页怎么处理
问题:在数据量比较大时,limit分页查询,需要对数据进行排序,效率低

1.7 索引创建原则有哪些
- 数据量较大,且查询比较频繁
- 常作为查询条件,排序,分组的字段
- 尽量联合索引
- 要控制索引的数量

1.8什么情况下索引会失效
- 违反最左前缀法则
- 范围查询右边的列,不能使用索引
- 不要在索引列上进行运算操作,索引将失效字符
- 不加单引号,造成索引失效。(类型转换)
- 以%开头的Like模糊查询,索引失效

1.9 *谈一谈你对sql优化的经验
表的设计优化:
- 比如设置合适的数值(tinyintint bigint),要根据实际情况选择
- 比如设置合适的字符串类型(char和varchar)char定长效率高,varchar可变长度,效率稍低
SQL语句优化:
- SELECT语句务必指明字段名称(避免直接使用select*)
- SQL语句要避免造成索引失效的写法
- 尽量用union all代替union,union会多一次过滤,效率低避免在where子句中对字段进行表达式操作
- 避免在where子句中对字段进行表达式操作
- Join优化 能用innerjoin 就不用left join right join,如必须使用 一定要以小表为驱动,内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边。leftjoin 或 rightjoin,不会重新调整顺序
主从复制、读写分离:
如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响 可以采用读写分离的架构。
读写分离解决的是,数据库的写入,影响了查询的效率。

事务
2.1 *事务的特性是什么,详细说一下
ACID是什么?可以详细说一下吗?
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(lsolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。

2.2 *怎么解决并发事务问题
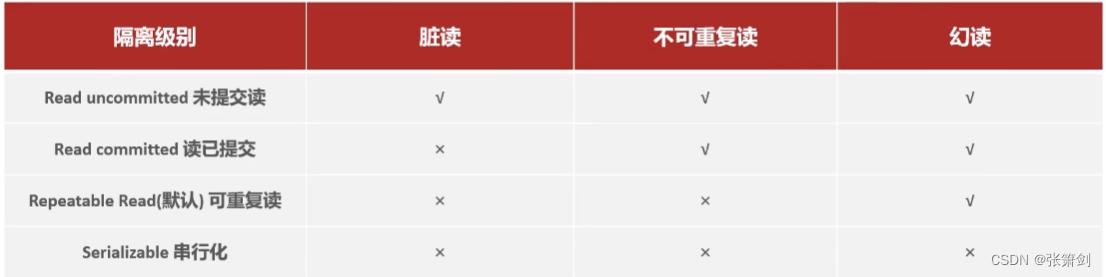
并发事务问题
- 脏读:一个事务读到另外一个事务还没有提交的数据。
- 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
- 幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了”幻影”。
怎么解决并发事务的问题呢?
- READ UNCOMMITTED 未提交读
- READ COMMITTED 读已提交
- REPEATABLE READ 可重复读
- SERIALIZABLE 串行化

2.3 undo log和redolog的区别
undo log和redolog的区别
- redolog:记录的是数据页的物理变化,服务宕机可用来同步数据
- undo log:记录的是逻辑日志,当事务回滚时,通过逆操作恢复原来的数据
redo log保证了事务的持久性,undolog保证了事务的原子性和一致性

2.4 事务中的隔离性如何保证(解释MVCC)

2.5 主从同步原理
MySQL主从复制的核心就是二进制日志binlog(DDL(数据定义语言)语句和 DML(数据操纵语言)语句
- 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
- 从库重做中继日志中的事件,将改变反映它自己的数据

2.6 了解分库分表嘛?
- 水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题
- 水平分表,解决单表存储和性能的问题
- 垂直分库,根据业务进行拆分,高并发下提高磁盘I0和网络连接数
- 垂直分表,冷热数据分离,多表互不影响














 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









