






一、引言
在当今大数据时代,Hadoop已经成为了处理海量数据的标配工具。Hadoop以其分布式存储和计算的能力,为大数据处理提供了强大的支持。本文将探讨Hadoop集群的搭建以及映射(Map)阶段的原理,帮助读者更好地理解Hadoop的工作机制。
二、Hadoop集群概述
Hadoop集群是一个由多台计算机组成的分布式系统,用于存储和处理大规模数据集。Hadoop集群主要包括两个核心组件:Hadoop Distributed File System(HDFS)和MapReduce。HDFS提供了高容错性的系统,能够存储海量的数据,而MapReduce则用于大规模数据集的并行处理。
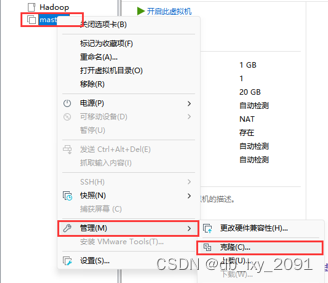
首先在Linux虚拟机上要有一个主机,这里我命名为master,通过“右键虚拟机--管理--克隆”的方式创建三个克隆机,修改名字为slave1,slave2,slave3,并修改安装路径。
在虚拟机使用超级用户对slave1,slave2,slave3进行配置,通过以下命令修改网络配置文件,修改后的ip和hosts文件的主机映射ip、域名保持一致。
vi /etc/sysconfig/network-scripts/ifcfg-ens33修改后重启网络服务
service network restart在master主机用ping命令,验证映射后的虚拟机是否互通(Ctrl+c停止ping的过程)
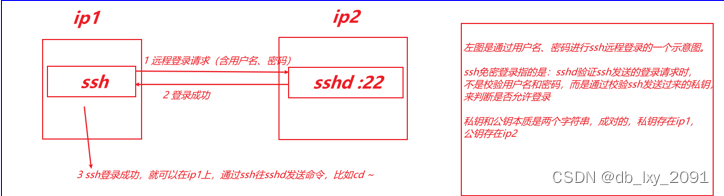
接着去远程连接SSH对slave1、slave2、slave3做免密登录。
免密登录说明图:
Hadoop集群通常由一个NameNode和多个DataNode组成。NameNode负责管理文件系统的命名空间和客户端对文件的访问,而DataNode则负责存储实际的数据。当客户端发起数据读写请求时,NameNode会根据数据的存储位置信息,将数据读写请求转发给相应的DataNode进行处理。
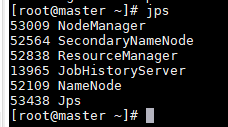
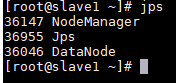
查看NameNode和DataNode只之前,我们要先打开集群,可以使用命令:strat-all.sh,这个命令将四台机器的集群全部开启(停止集群则反之:stop-all.sh)
打开集群后可以用给jps查看
三、Hadoop映射(Map)原理
MapReduce是Hadoop的核心计算框架,它将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce。其中,Map函数负责将输入数据拆分成多个键值对(key-value pairs),为后续的Reduce阶段提供数据。 在映射阶段,Mapper会读取输入数据(通常是HDFS中的文件),并将每一行输入数据转换成一个或多个键值对。这个过程是高度并行的,每个Mapper可以独立处理输入数据的一个子集。Mapper的输出会被排序并划分为多个分区,每个分区对应一个Reducer。
做好映射我们可以监控Hadoop集群。监控Hadoop集群对于确保集群的稳定运行、优化性能、预防故障以及及时响应问题至关重要,监控可以实时跟踪Hadoop集群的状态,包括各个组件(如HDFS、YARN、MapReduce等)的健康状况。当系统出现潜在问题时,监控工具可以立即发出警报,从而允许管理员在问题影响集群性能或导致数据丢失之前采取行动。
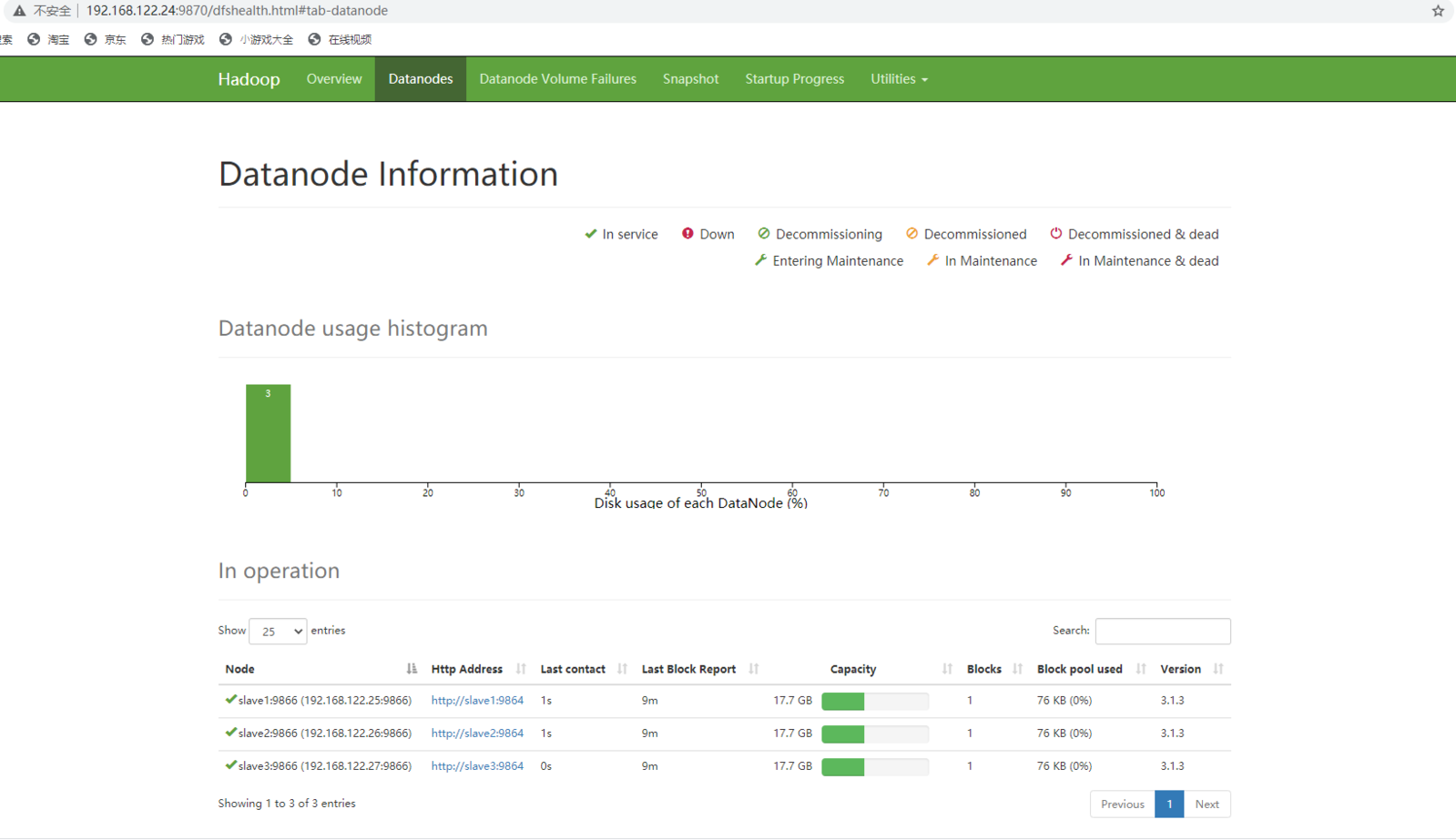
如果做了映射可以通过http:masster:9870/进入HDFS监控,如果没做可以通过http://192.168.122.24:9870/进入(192.168.122.24为主机ip)
HDFS监控:
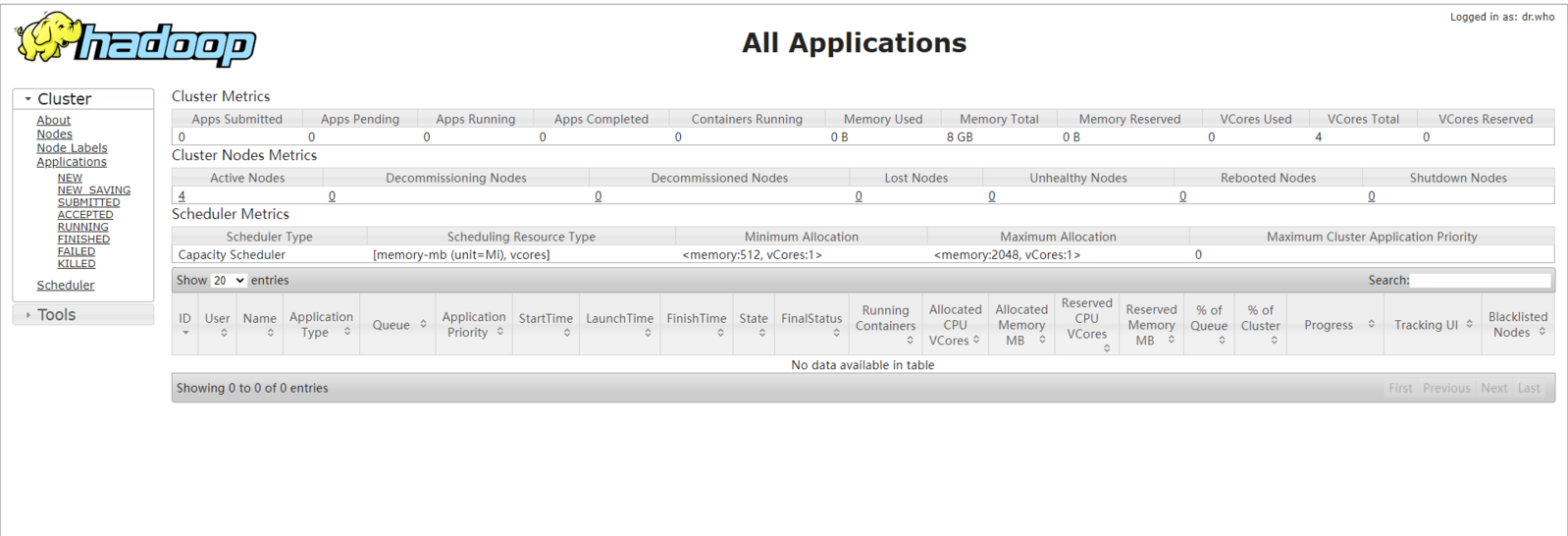
Yarn监控:(http:masster:8080/或者http://192.168.122.24:8080/)
日志监控:(http:masster:19888/或者http://192.168.122.24:19888/)
四、Hadoop集群与映射的优化
为了提高Hadoop集群的性能和映射阶段的效率,可以采取以下优化措施:
-
数据本地化:尽量将数据存储在离计算节点近的位置,以减少数据传输的延迟。Hadoop会尽量将数据块分配到离其最近的DataNode上进行计算,从而实现数据本地化。
-
调整Mapper的数量:Mapper的数量会影响到映射阶段的并行度和处理速度。通过调整Mapper的数量,可以找到一个平衡点,使得处理速度和资源利用率达到最优。
-
优化Mapper的实现:Mapper的实现方式会直接影响到映射阶段的性能。可以通过减少不必要的操作、优化数据结构和使用更高效的算法来提高Mapper的执行效率。
-
使用压缩技术:在Hadoop中,数据传输的开销通常很大。使用压缩技术可以减少数据传输量,从而提高整体性能。Hadoop支持多种压缩算法,如Gzip、Snappy等。
五、总结
Hadoop集群以其强大的分布式存储和计算能力,为大数据处理提供了有力的支持。映射作为MapReduce计算框架的关键阶段之一,其性能和效率直接影响到整个计算过程的快慢。通过深入了解Hadoop集群和映射的原理,我们可以更好地优化Hadoop作业,提高处理速度和资源利用率。
在未来的大数据时代,Hadoop将继续发挥重要作用。掌握Hadoop集群和映射的原理及优化方法,对于数据科学家、工程师和研究人员来说至关重要。希望本文能为您在Hadoop的学习和实践中提供有益的参考和帮助。















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









