







版本说明
Centos: CentOS-7-x86_64-DVD-2009
JDK: jdk-8u291-linux-x64
Hadoop: hadoop-2.7.7
1. 准备工作
- 设置静态IP
- 关闭防火墙
- 安装JDK
- 配置环境变量
- 服务器克隆
- 修改主机名
- 设置IP和主机名映射
- SSH免密登录
1.1 设置静态IP
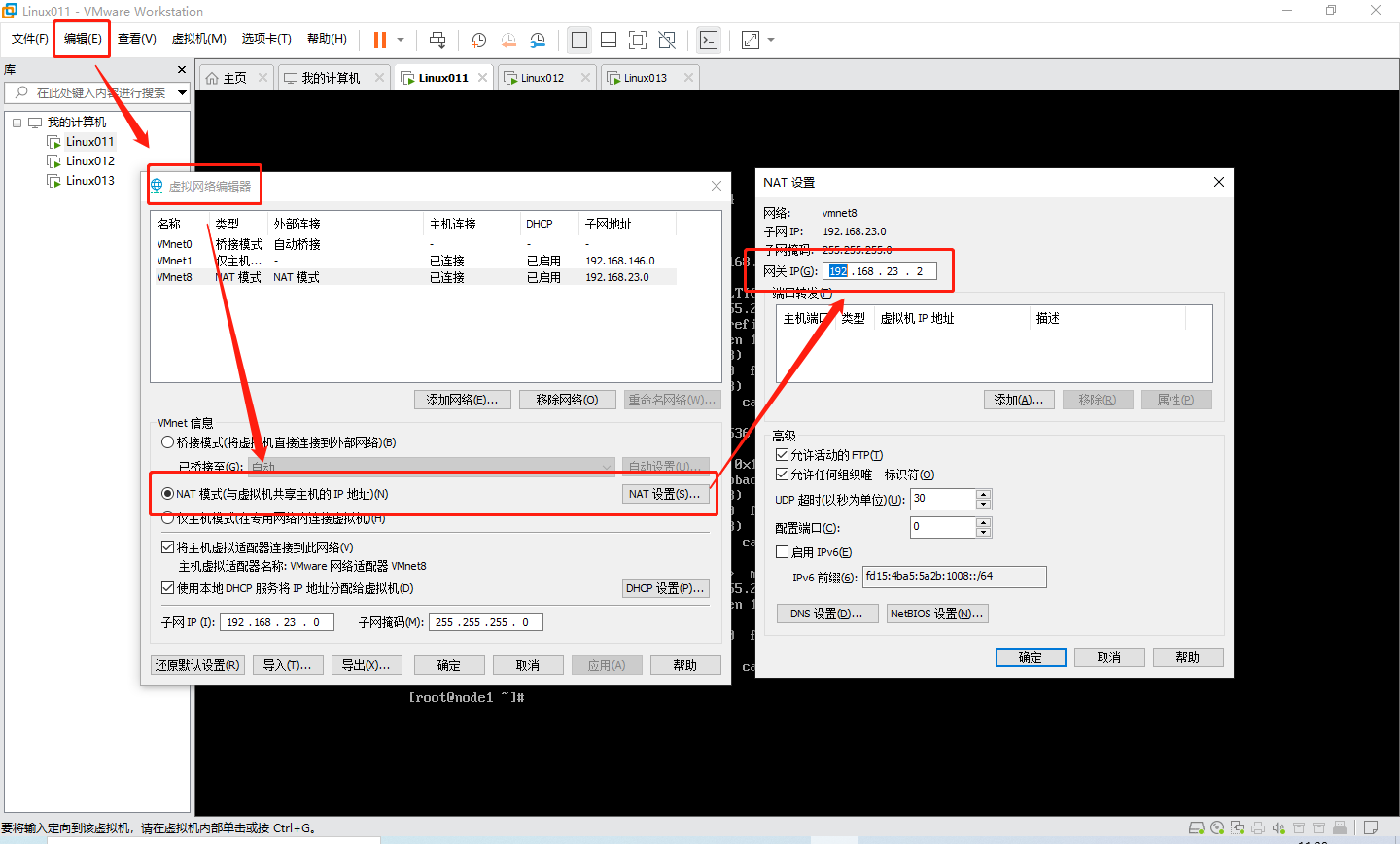
1️⃣ Step1:在 VMware中网络配置为NAT模式,查看网关地址,编辑 --> 虚拟网络编辑器
2️⃣ Step2:进入网卡配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
3️⃣ Step3:文件内容如下
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none # 网卡启动方式,设置为none或static;若设置为dhcp,则每次重启都将重新分配IP
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=no
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=d37c19ce-6c0b-43ea-ae96-2e378dbc0d28
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.23.11 # 本机IP,前三位与网关一致,第四位不是网关的就行
PREFIX=24
GATEWAY=192.168.23.2 # 网关地址
DNS1=192.168.23.2 # 配成网关地址或114.114.114.114
4️⃣ Step4:修改后重启网络
systemctl restart network
1.2 关闭防火墙
1️⃣ Step1:查看防火墙状态
systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: active (running) since 二 2021-11-16 12:41:30 CST; 12s ago
Docs: man:firewalld(1)
Main PID: 2081 (firewalld)
Tasks: 2
CGroup: /system.slice/firewalld.service
└─2081 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid
2️⃣ Step2:关闭防火墙
systemctl stop firewalld
3️⃣ Step3:关闭防火墙开机自启
systemctl disable firewalld
4️⃣ Step4:再一次查看防火墙状态
# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
1.3 安装JDK
1️⃣ Step1:上传压缩包到 Linux 的 opt 目录,使用 XFTP 或 MobaXterm
2️⃣ Step2:查看当前 JDK 压缩包
# ls
jdk-8u291-linux-x64.tar.gz
3️⃣ Step3:解压当前 JDK 压缩包
tar -zxvf jdk-8u291-linux-x64.tar.gz # 选项的横杠可省略
4️⃣ Step4:更改解压后的文件名
mv jdk1.8.0_291 jdk1.8
1.4 配置环境变量
1️⃣ Step1:打开配置系统环境变量的文件
vim /etc/profile
2️⃣ Step2:添加 JDK 环境变量
export JAVA_HOME=/opt/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
3️⃣ Step3:更新该文件
source /etc/profile
1.5 服务器克隆
1️⃣ Step1:服务器关机,在 VMware 左侧的列表中右键当前虚拟机,管理 --> 克隆
2️⃣ Step2:克隆出两台,并启动当前服务器及克隆版服务器
1.6 修改主机名
1️⃣ Step1:查看当前服务器主机名
[root@joel ~]# hostname
joel
2️⃣ Step2:修改当前主机名
hostnamectl set-hostname 主机名
3️⃣ Step3:三台全部修改
三我将台主机名分别修改为node1、node2、node3
1.7 设置IP和主机名映射
1️⃣ Step1:设置克隆版服务器的静态 IP,比如:
192.168.23.11 # node1,前三位对应自己的网关
192.168.23.12 # node2
192.168.23.13 # node3
2️⃣ Step2:设置主机名映射,先打卡文件
vim /etc/hosts
3️⃣ Step3:添加 IP 及对应的主机名
192.168.23.11 node1
192.168.23.12 node2
192.168.23.13 node3
4️⃣ Step4:三台都要配置
1.8 SSH免密登录
1️⃣ Step1:删除原有的 .ssh 文件
rm -rf ~/.ssh
2️⃣ Step2:生成新的密钥
ssh-keygen -t rsa # 一路回车
3️⃣ Step3:分发密钥
ssh-copy-id node1
yes
node1 root密码
ssh-copy-id node2
yes
node2 root密码
ssh-copy-id node3
yes
node3 root密码
4️⃣ Step4:三台都要配置
2. Hadoop 部署
- 上传并解压
- 修改配置文件
- 分发安装包
- 配置环境变量
- Namenode格式化
- 启动集群
2.1 上传并解压
1️⃣ Step1:上传 Hadoop 压缩包至 opt 目录
2️⃣ Step2:解压
tar -zxvf hadoop-2.7.7.tar.gz
3️⃣ Step3:查看解压后的文件
[root@node1 opt]# ls
hadoop-2.7.7 jdk1.8
2.2 修改配置文件
⚠️ 注意:配置文件在 Hadoop 目录的 etc/hadoop 目录中!
1️⃣ Step1:配置 hadoop-env.sh,设置 Java Home
export JAVA_HOME=/opt/jdk1.8
2️⃣ Step2:配置 core-site.xml
<configuration>
<property>
<!-- 设置Hadoop用来存储数据的目录,设置到Hadoop安装目
录中 -->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.7/data</value>
</property>
<property>
<!-- 设置HDFS使用的默认连接url -->
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
</configuration>
3️⃣ Step3:配置 hdfs-site.xml
<configuration>
<property>
<!-- 配置SecondaryNameNode启动的机器 -->
<name>dfs.namenode.secondary.http-address</name>
<value>node3:50090</value>
</property>
</configuration>
4️⃣ Step4:salves,设置启动 DataNode 服务的节点
node1
node2
node3
2.3 分发安装包
向其他两台服务器分发配置好的安装包
语法格式:scp -rq 本地文件夹 目标主机:目标路径
scp -rq /opt/hadoop-2.7.7 node2:/opt
scp -rq /opt/hadoop-2.7.7 node3:/opt
2.4 配置环境变量
1️⃣ Step1:打开配置系统环境变量的文件
vim /etc/profile
2️⃣ Step2:添加 Hadoop 环境变量
echo export HADOOP_HOME=/opt/hadoop-2.7.7
echo export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
3️⃣ Step3:更新该文件
source /etc/profile
4️⃣ Step4:三台都要配置
2.5 Namenode格式化
只在 node1 中执行一遍
hdfs namenode -format
2.6 启动集群
在 node1 (主节点)中启动集群
start-dfs.sh
结果:
Starting namenodes on [node1]
node1: starting namenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-namenode-node1.out
node2: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-node2.out
node3: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-node3.out
node1: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-node1.out
Starting secondary namenodes [node3]
node3: starting secondarynamenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-node3.out
3. 写在最后
3.1 查看网页
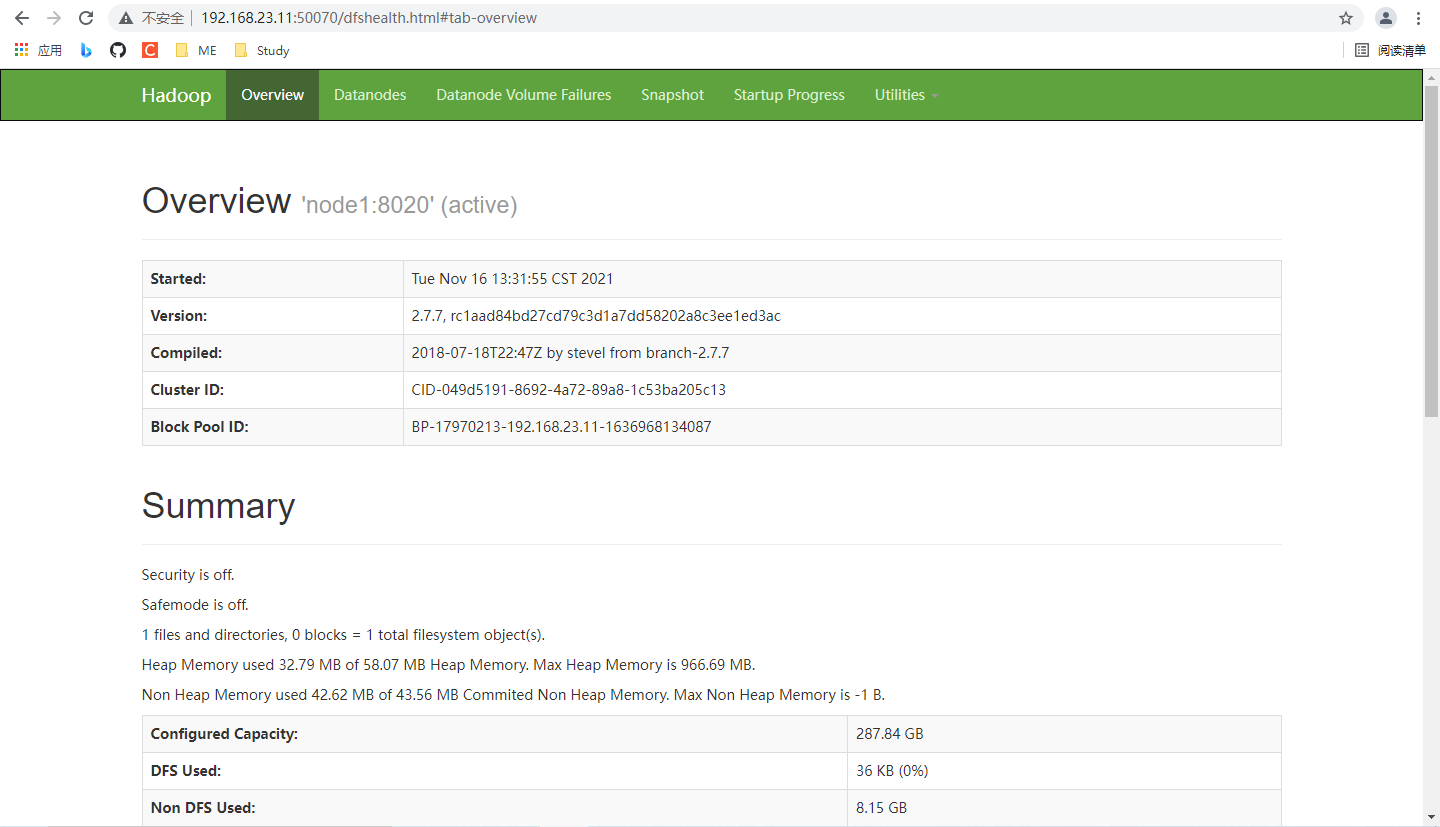
若启动成功,则可以通过 node1 的 IP + 端口号,在 Win 下访问网页
192.168.23.11:50070
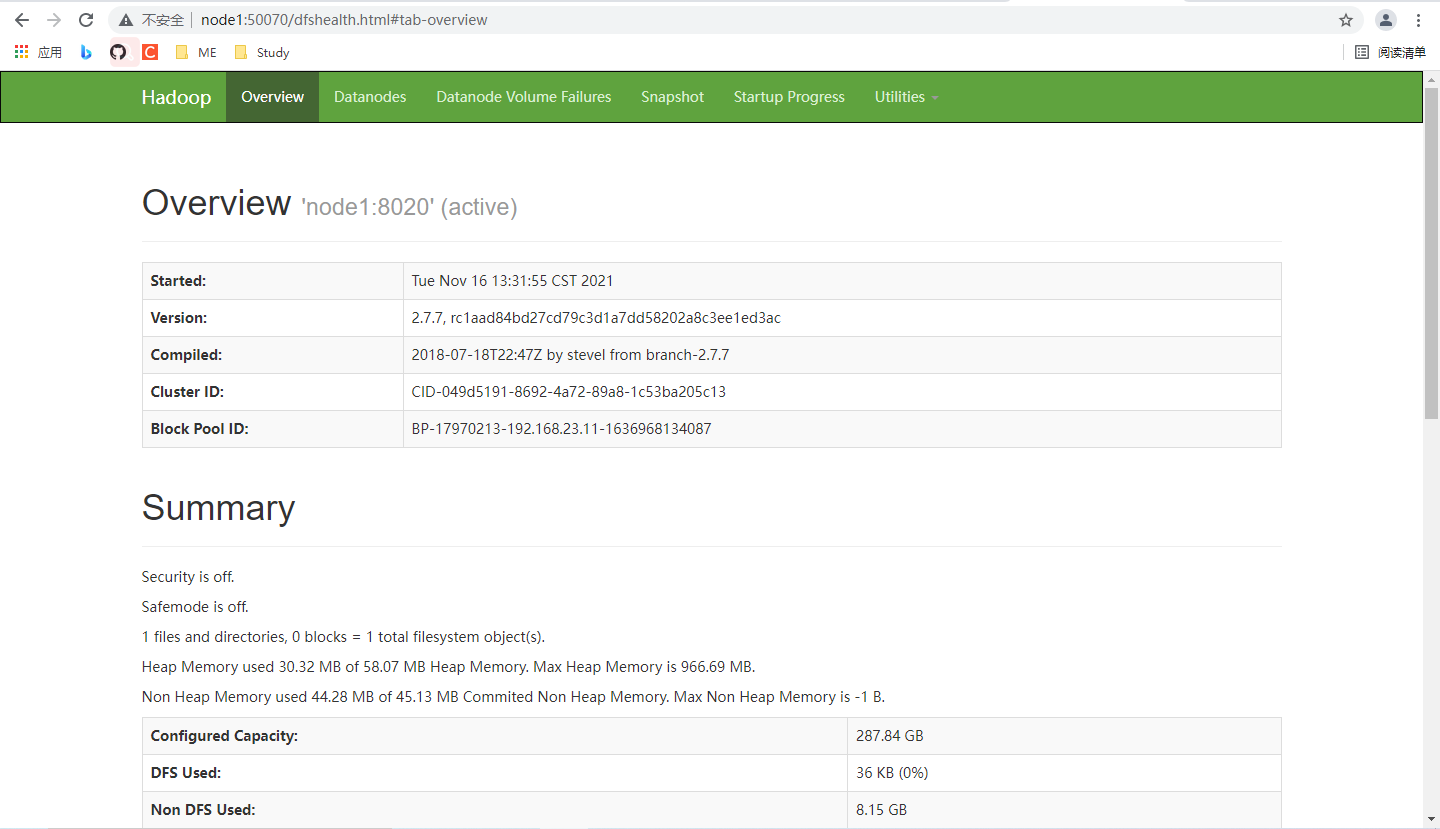
若想通过node1的主机名代替 IP,则需要在 Win 的 c:\windows\system32\drivers\etc\hosts 添加和 Linux 的 /etc/hosts 中咱们加入内容。
192.128.23.11 node1
192.128.23.12 node2
192.128.23.13 node3
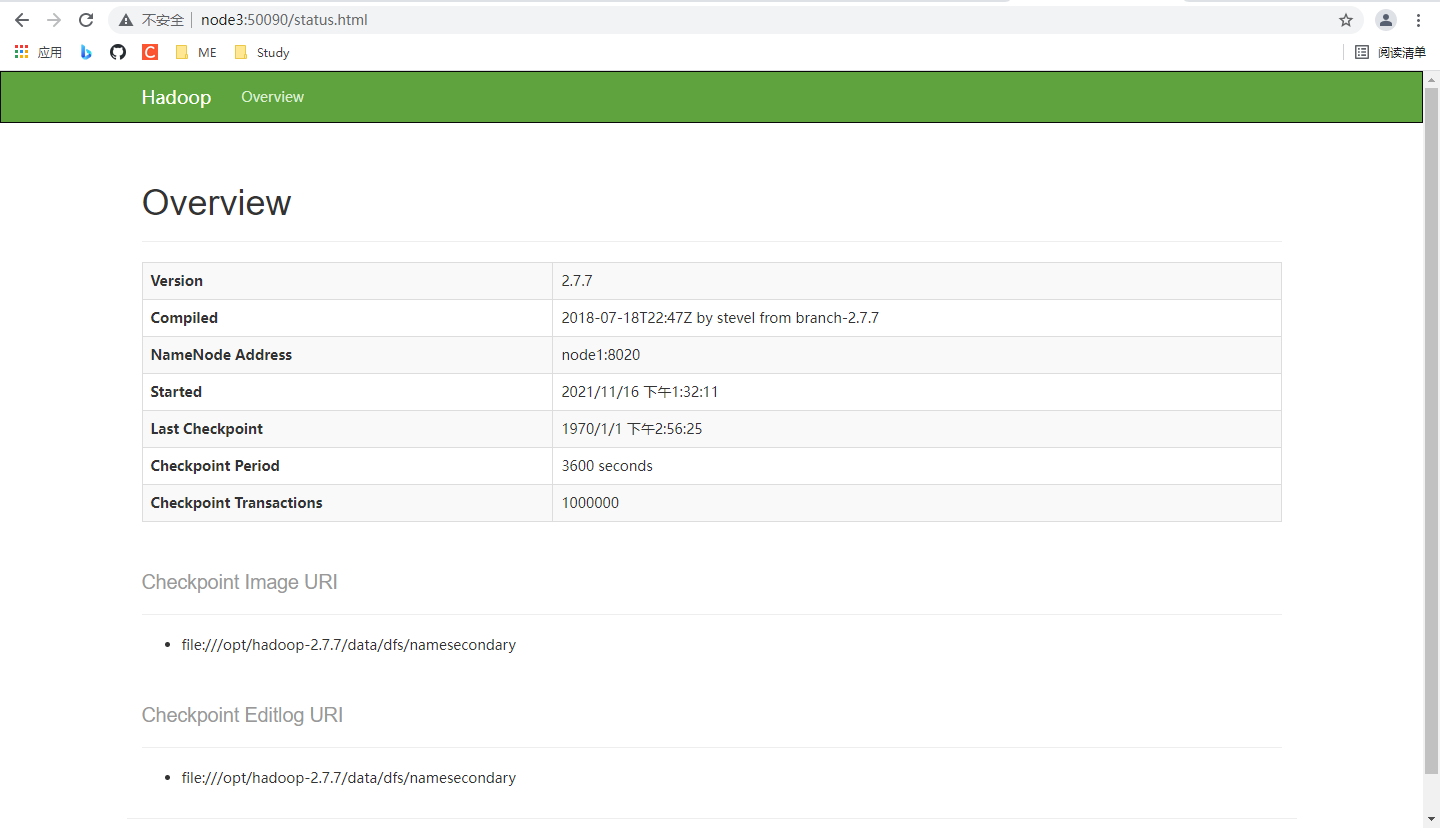
另外,咱们配置50090端口的是node3,那不妨用node3的端口试试。网页内容些许不同
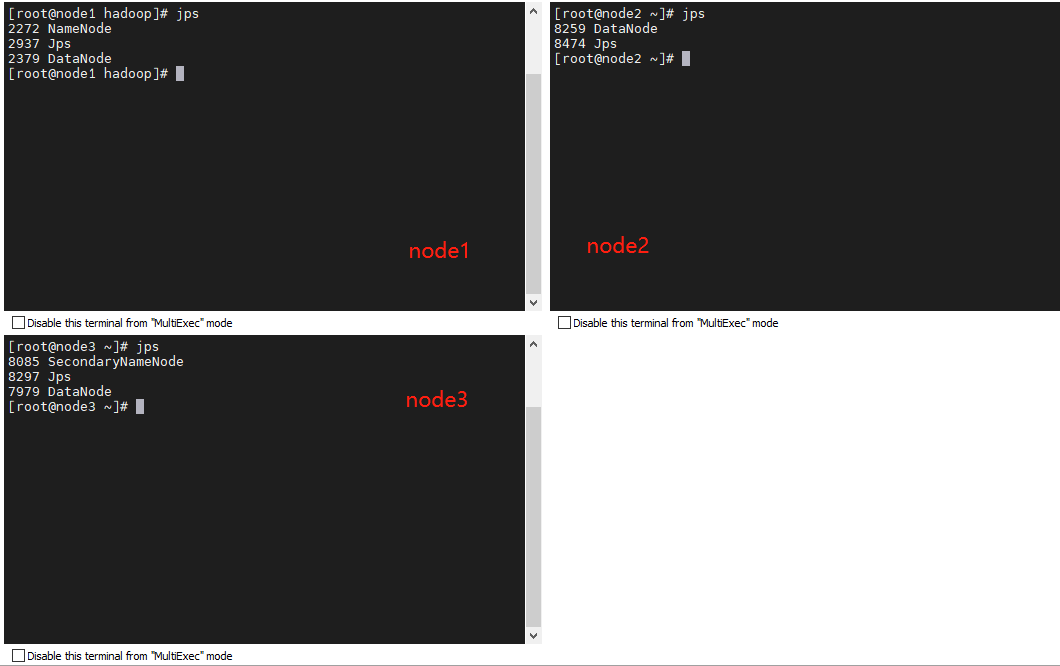
3.2 查看进程
ps 命令可以查看 Linux 中的进程,Hadoop 是 java 进行,所以我们可以使用 jps 查看相关进程
















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











