






一、第一次爬虫
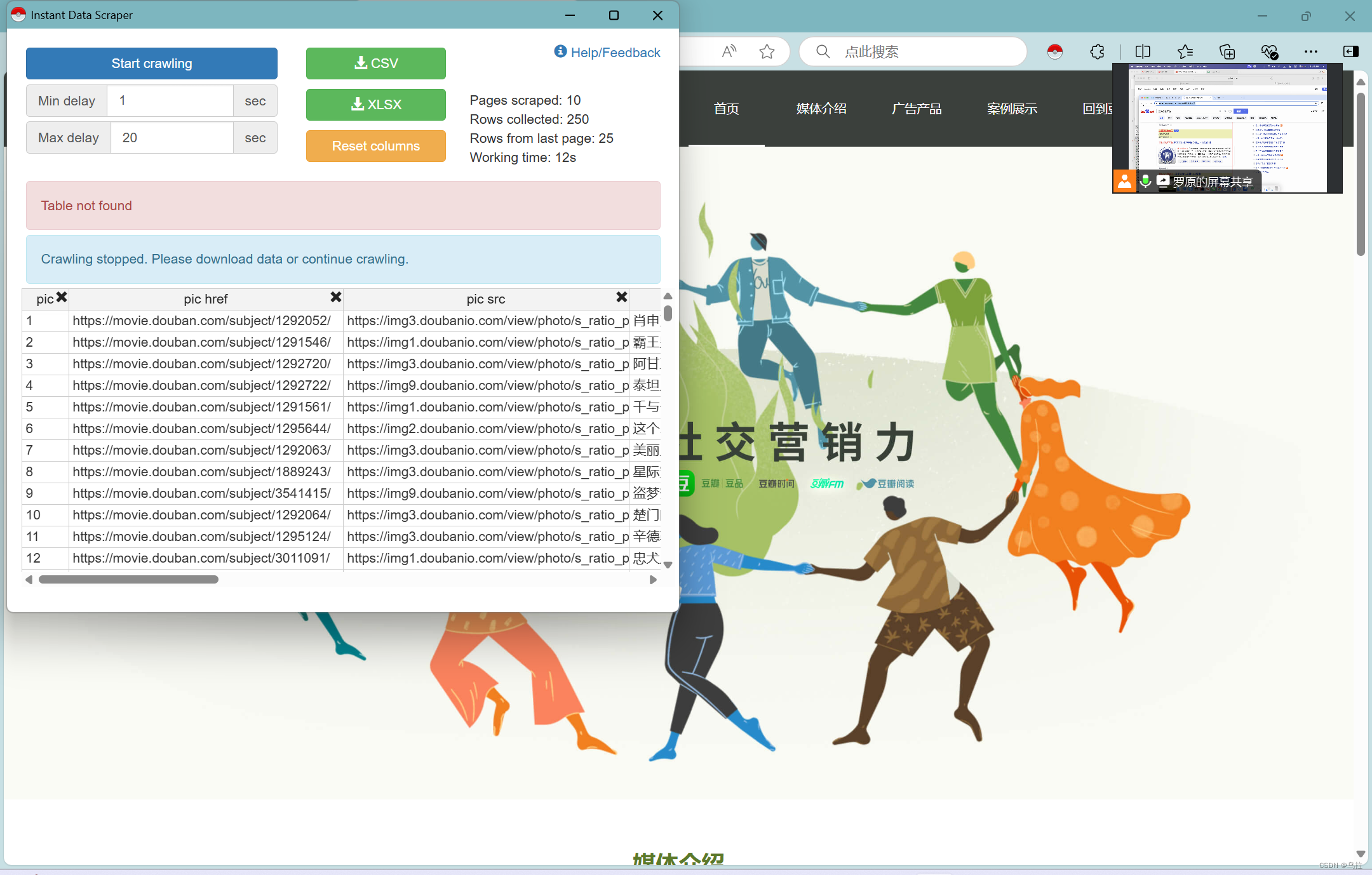
操作步骤如下:
- 第一次爬虫需要添加浏览器的扩展程序Instant Data Scraper
- 打开一个你想要获取数据的网站,双击程序图标打开对话框
- 再点击按钮,接着点击网页中的下一页,告诉程序下一页的按钮位置
- 点击start crawling,开始爬虫,最后的结果可点击对应按钮进行下载
二、查看网站的请求头信息
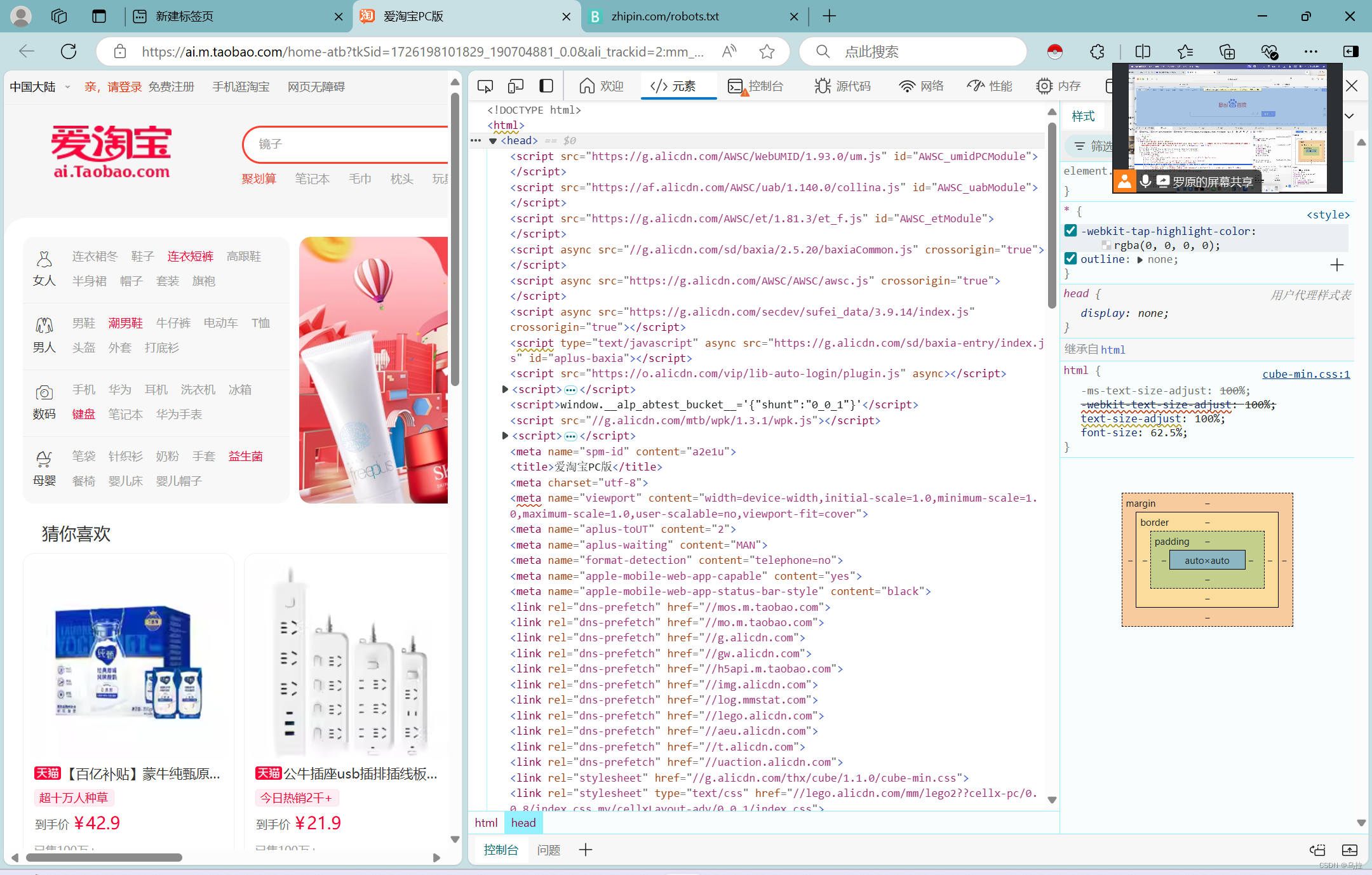
操作步骤如下:
- 打开一个你想要查看的网站,在空白处单击右键,点击检查,出现新的对话框,此时对话框里是空白的
- 再次在网页空白处单击右键刷新,找到head,即可查看
三、查看网站的robots协议
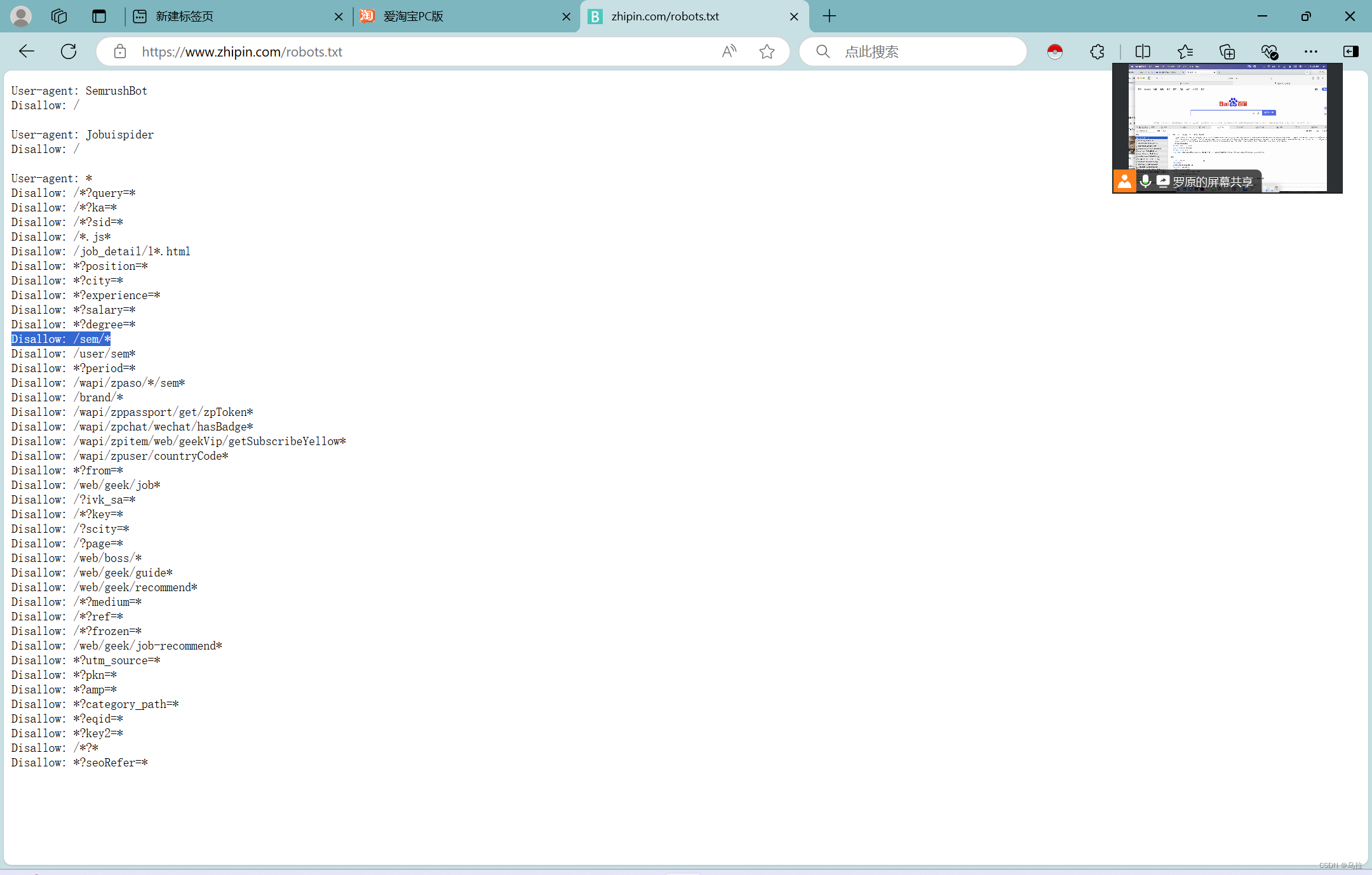
操作步骤如下:
- 打开任意一个你想要查看的网站,在网址链接里,输入/robots.txt,即可查看robots协议

















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









