



1. 介绍
1.1 kubernetes 简介
- 在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应用了很多年
- Borg系统运行管理着成千上万的容器应用。
- Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
- Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
-
自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
-
弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
-
服务发现:服务可以通过自动发现的形式找到它所依赖的服务
-
负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
-
版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
-
存储编排:可以根据容器自身的需求自动创建存储卷
1.2 K8S各个组件用途
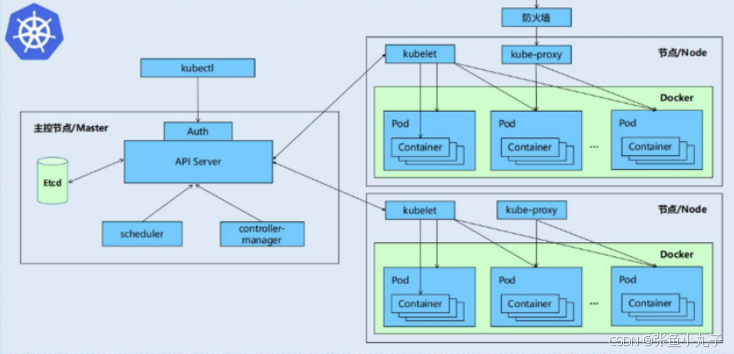
一个kubernetes集群主要是由控制节点(master)、工作节点(node)构成,每个节点上都会安装不同的组件
1 master:集群的控制平面,负责集群的决策
-
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
-
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
-
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
-
Etcd :负责存储集群中各种资源对象的信息
2 node:集群的数据平面,负责为容器提供运行环境
-
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
-
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
-
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
K8S 各组件之间的调用关系
当我们要运行一个web服务时
1. kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中
2. web服务的安装请求会首先被发送到master节点的apiServer组件
3. apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个node节点上
在此时,它会从etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告知apiServer
4. apiServer调用controller-manager去调度Node节点安装web服务
5. kubelet接收到指令后,会通知docker,然后由docker来启动一个web服务的pod
6. 如果需要访问web服务,就需要通过kube-proxy来对pod产生访问的代理K8S 的 常用名词感念
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
NameSpace:命名空间,用来隔离pod的运行环境
k8S的分层架构
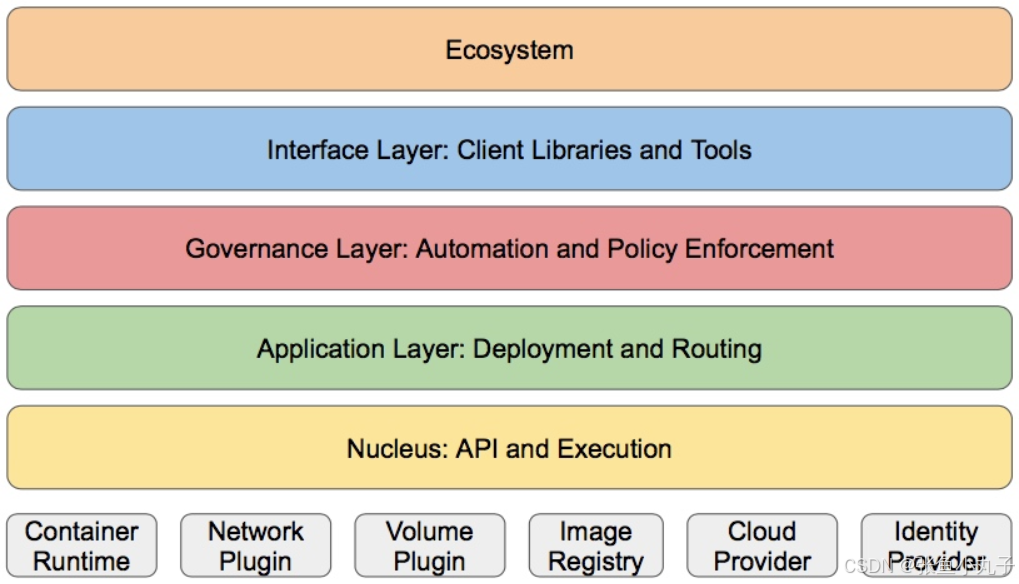
-
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
-
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
-
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
-
接口层:kubectl命令行工具、客户端SDK以及集群联邦
-
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
-
Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
-
Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
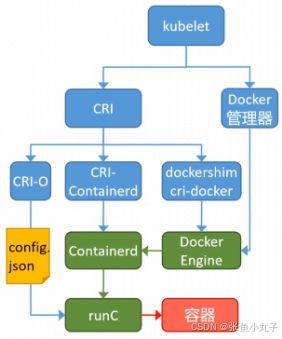
k8s中容器的管理方式
K8S 集群创建方式有3种:
centainerd
默认情况下,K8S在创建集群时使用的方式
docker
Docker使用的普记录最高,虽然K8S在1.24版本后已经费力了kubelet对docker的支持,但时可以借助cri-docker方式来实现集群创建
cri-o
CRI-O的方式是Kubernetes创建容器最直接的一种方式,在创建集群的时候,需要借助于cri-o插件的方式来实现Kubernetes集群的创建。
2. 环境配置
需要4台虚拟机
harbor:172.25.254.200
master:172.25.254.100
k8s-node1:172.25.254.10
k8s-node2:172.25.254.20
2.1 先配置harbor
安装docker
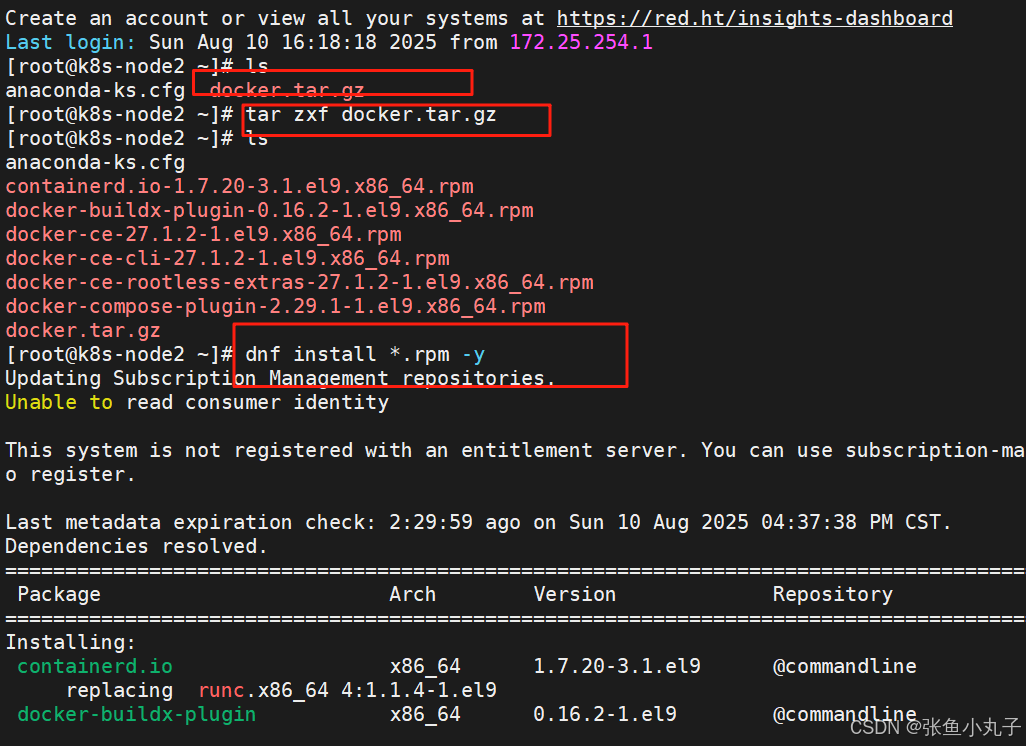
编辑配置文件
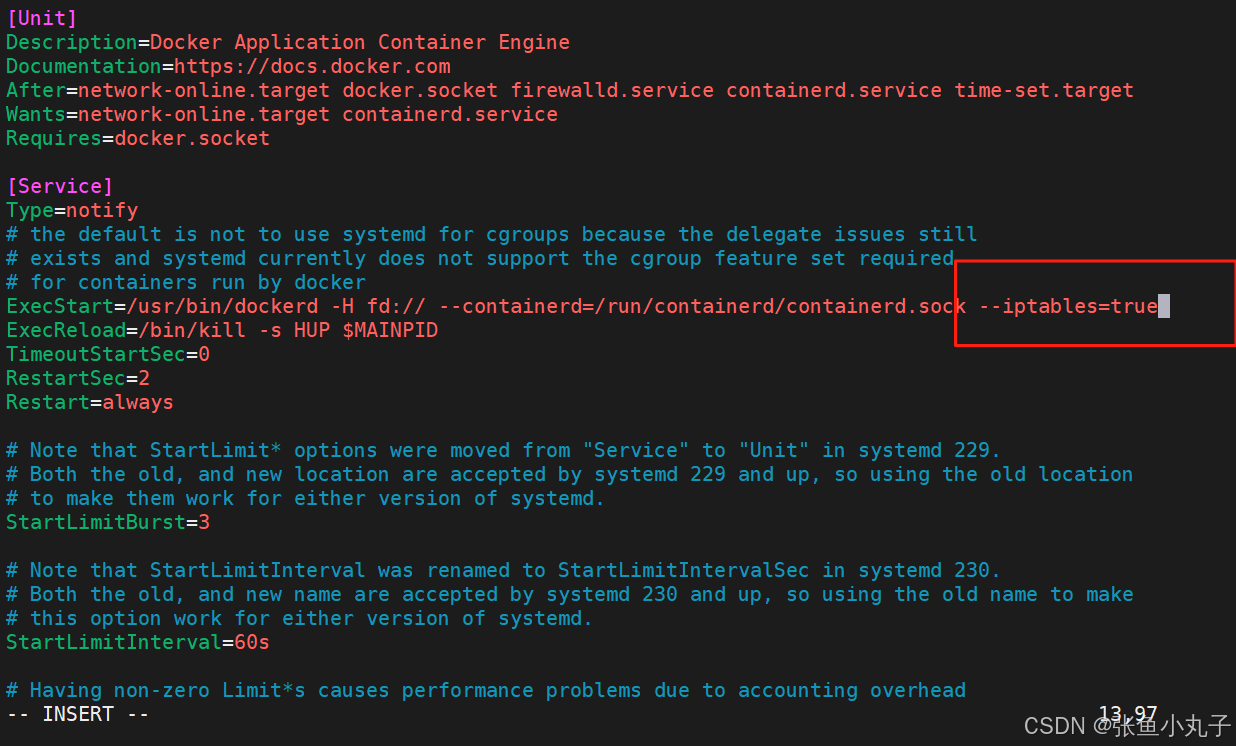
[root@k8s-node2 ~]# vim /lib/systemd/system/docker.service
启动服务

安装harbor,生成认证证书
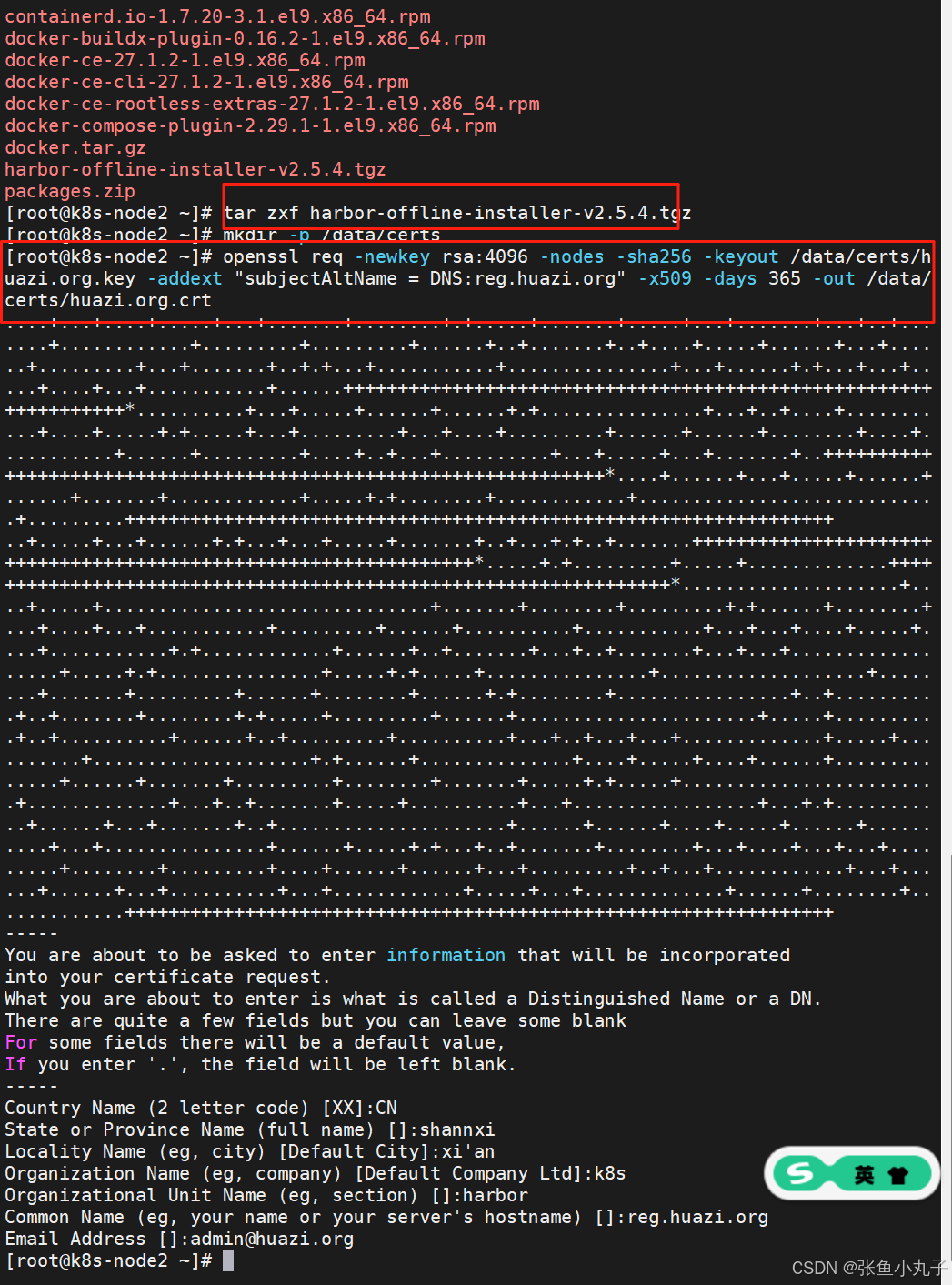
修改名字密码

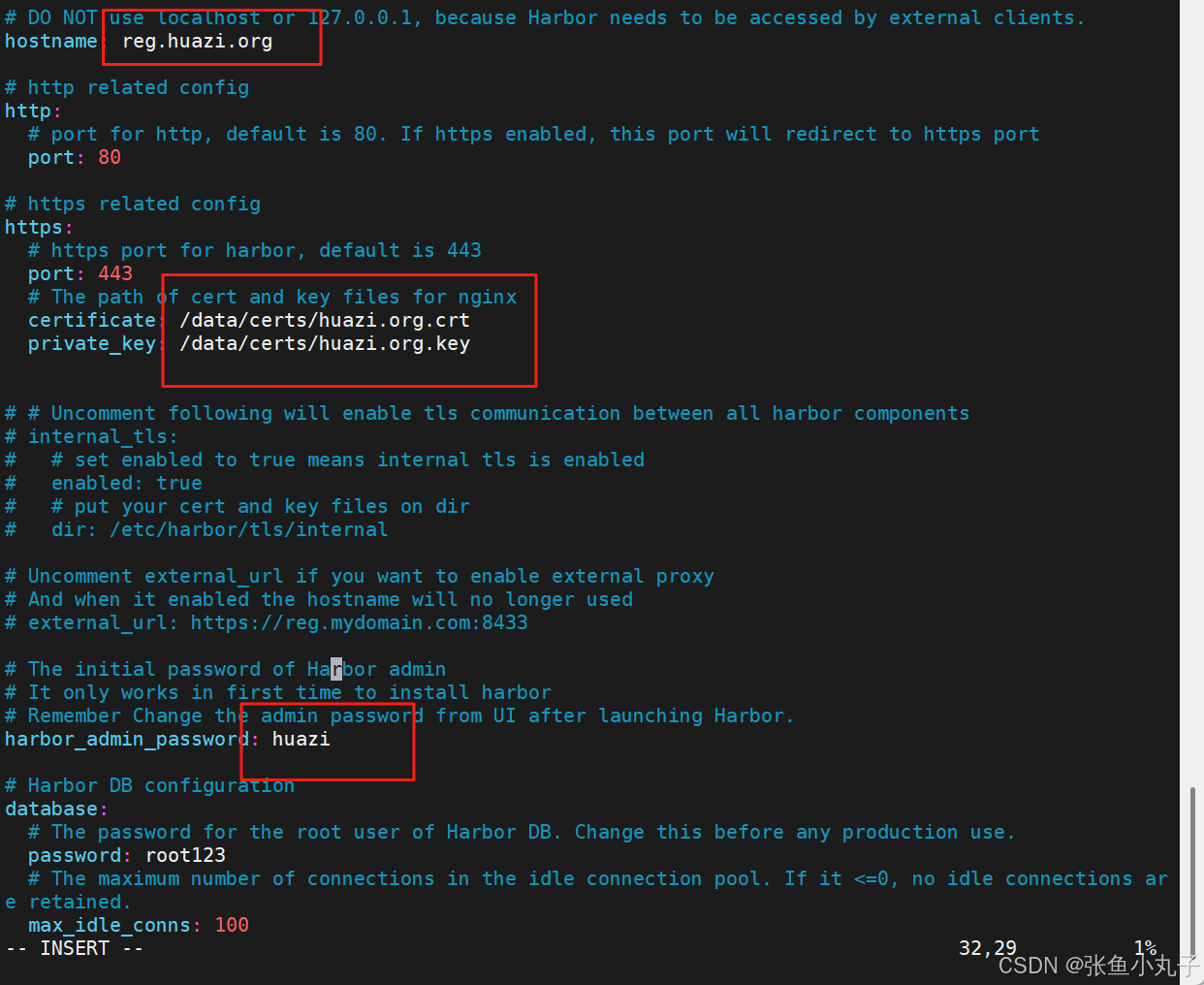
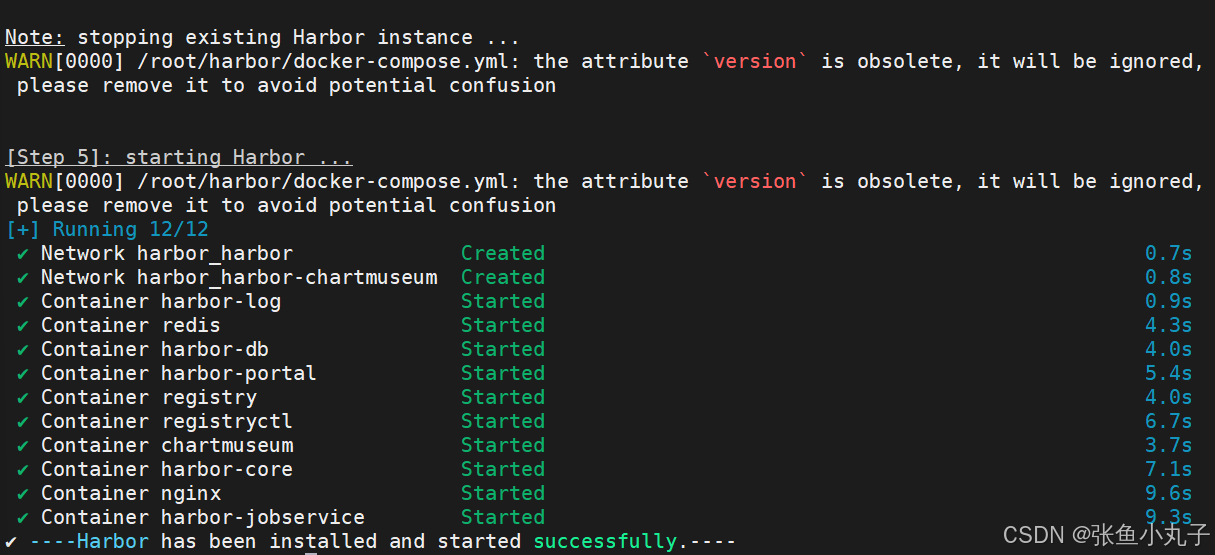
生成加载,成功即可
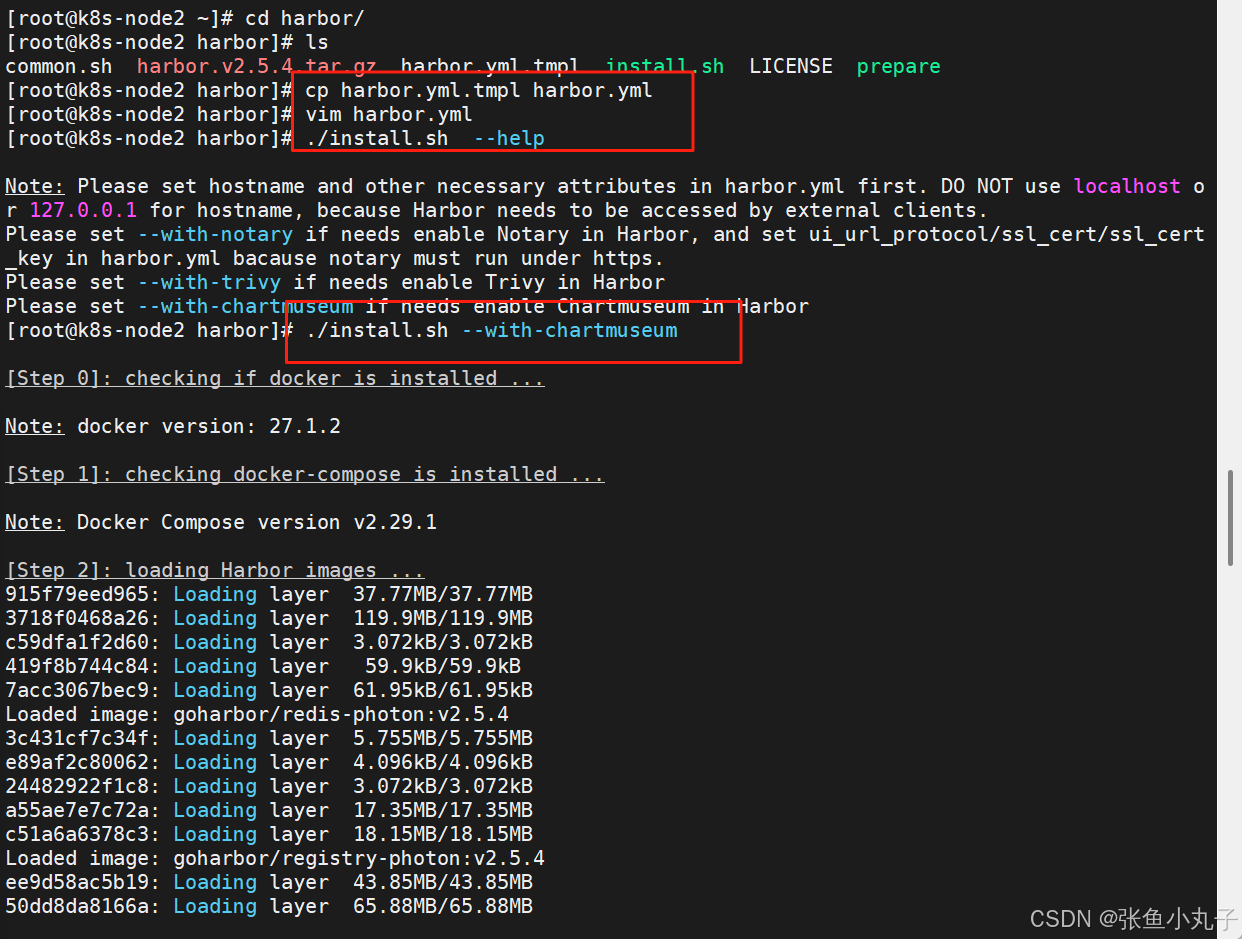
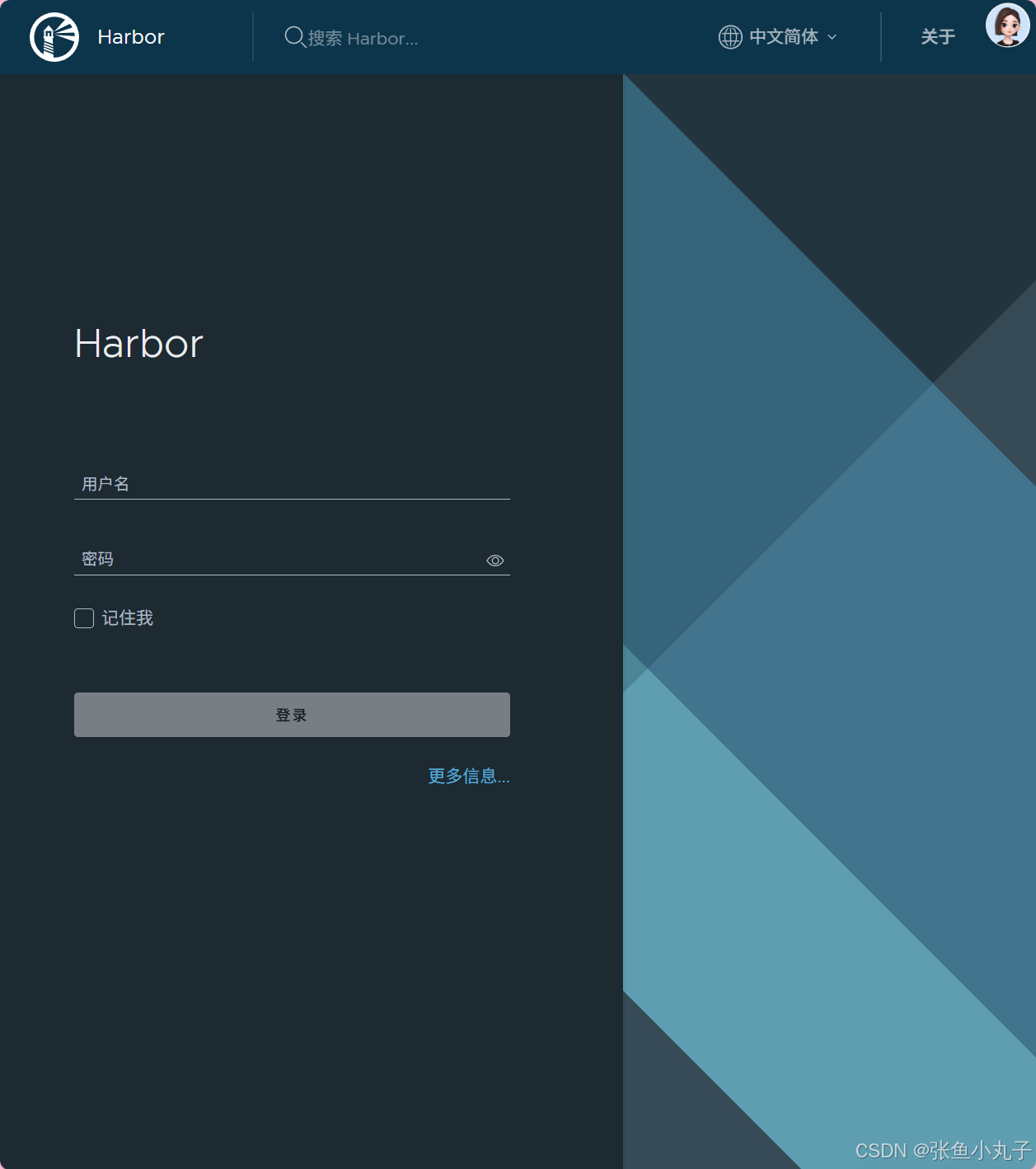
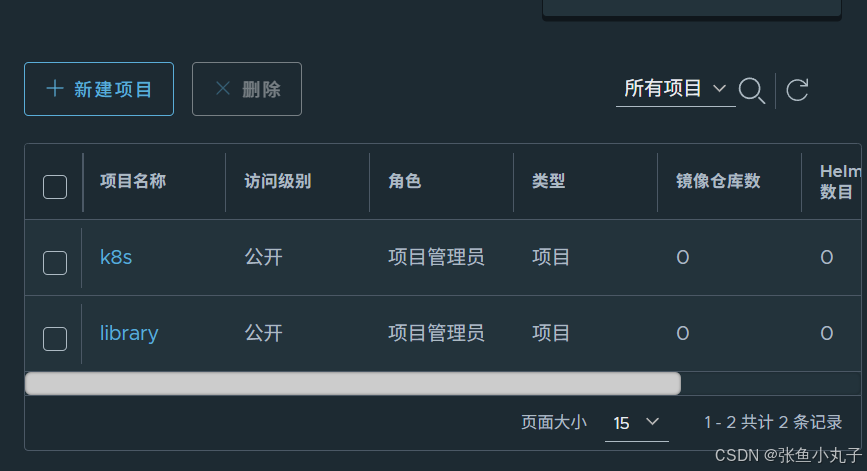
访问测试
2.2 master配置
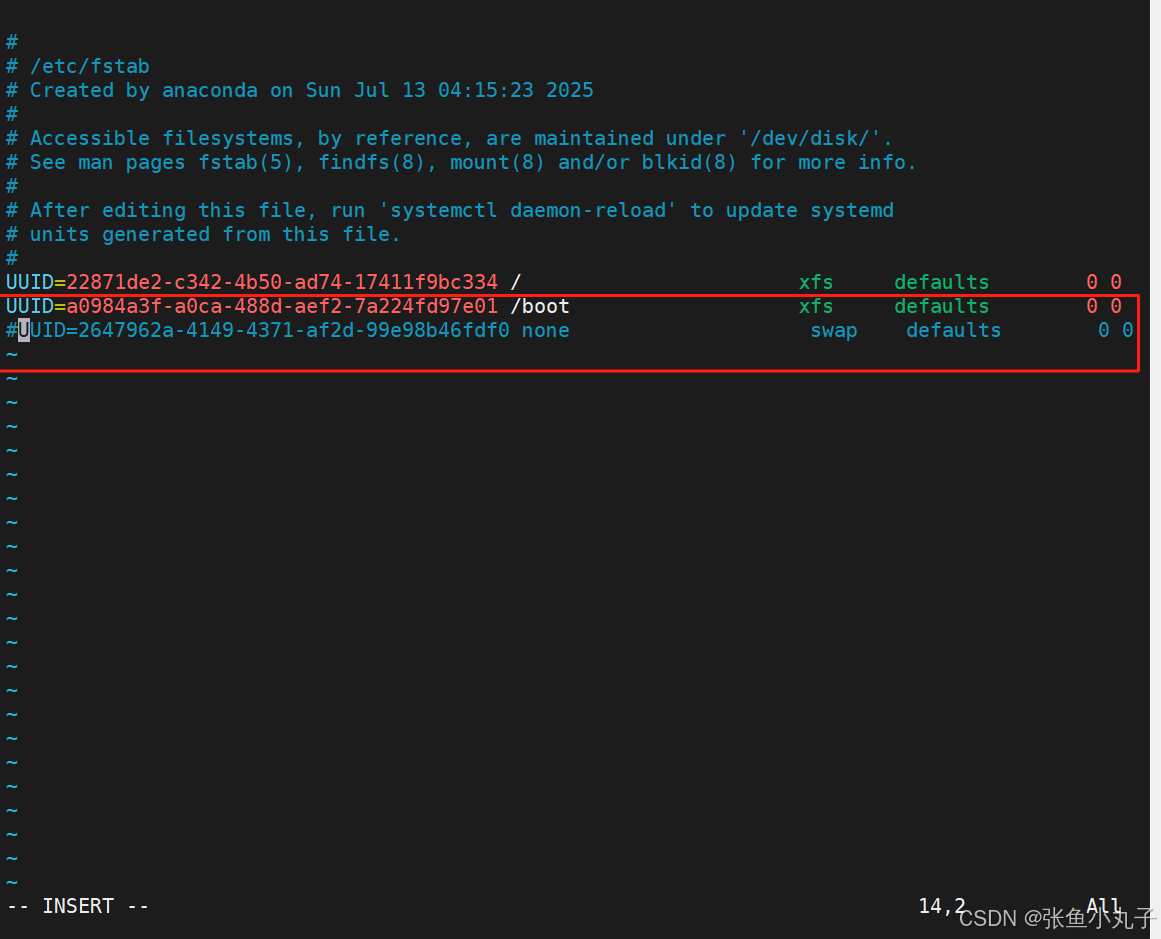
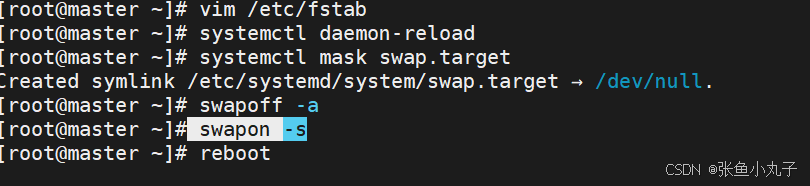
关闭swap分区,三台主机都要
[root@master ~]# vim /etc/fstab
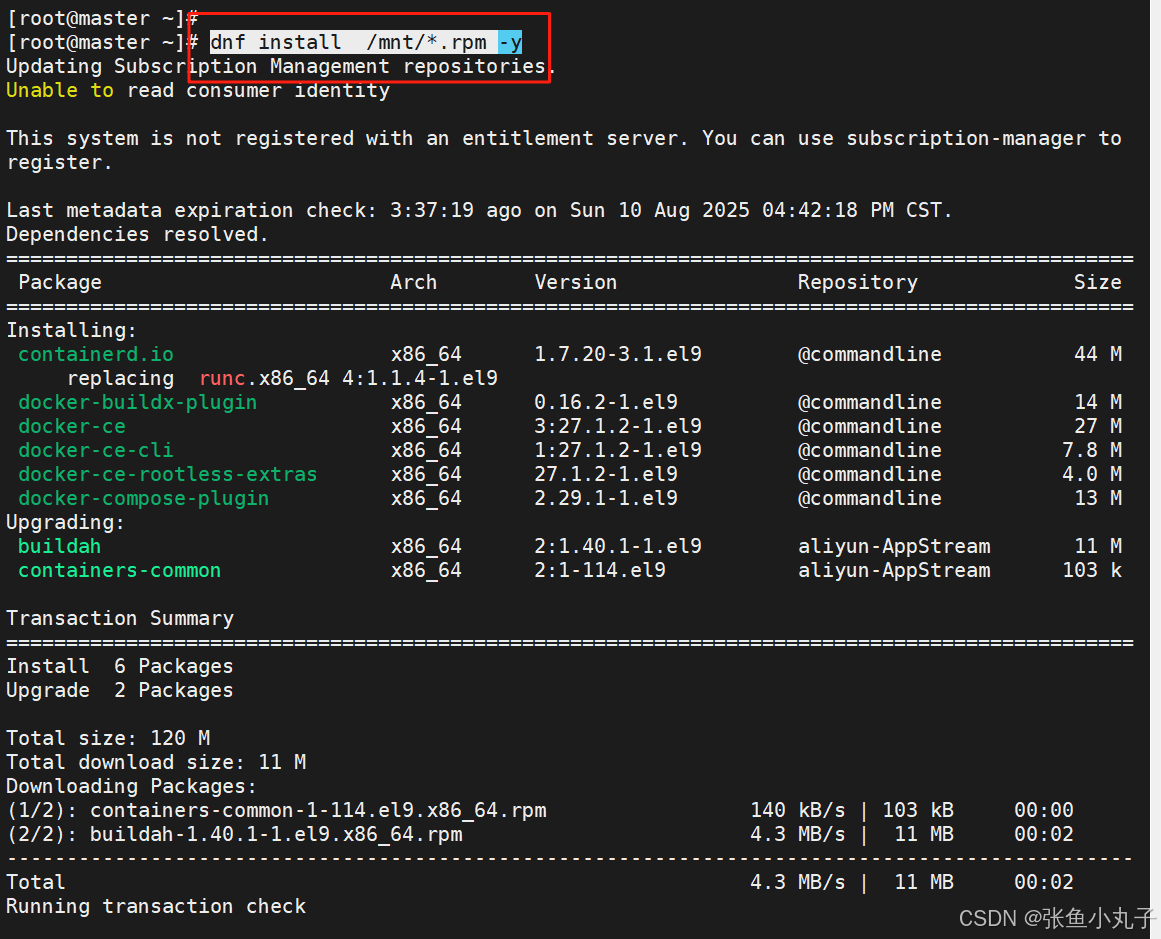
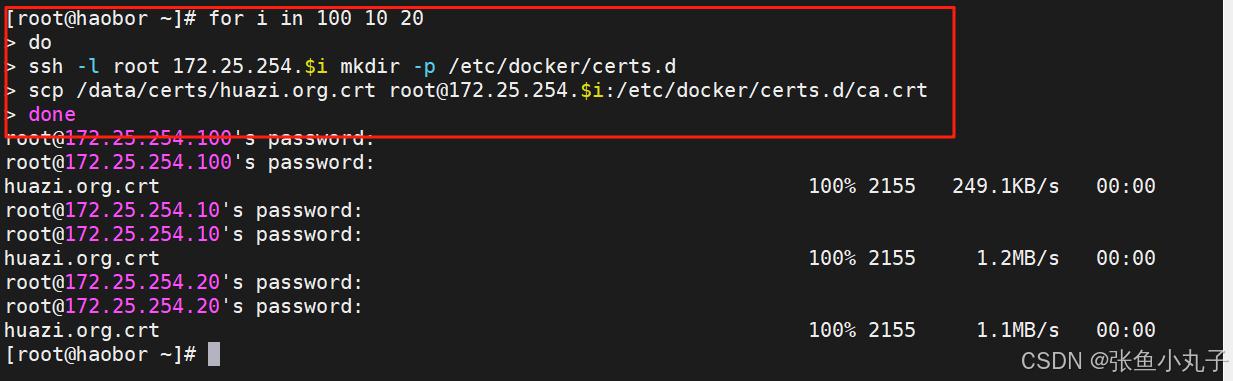
安装docker,把200复制过来就行,10和20命令一样
安装,三台都要
编辑配置文件
[root@master ~]# vim /lib/systemd/system/docker.service
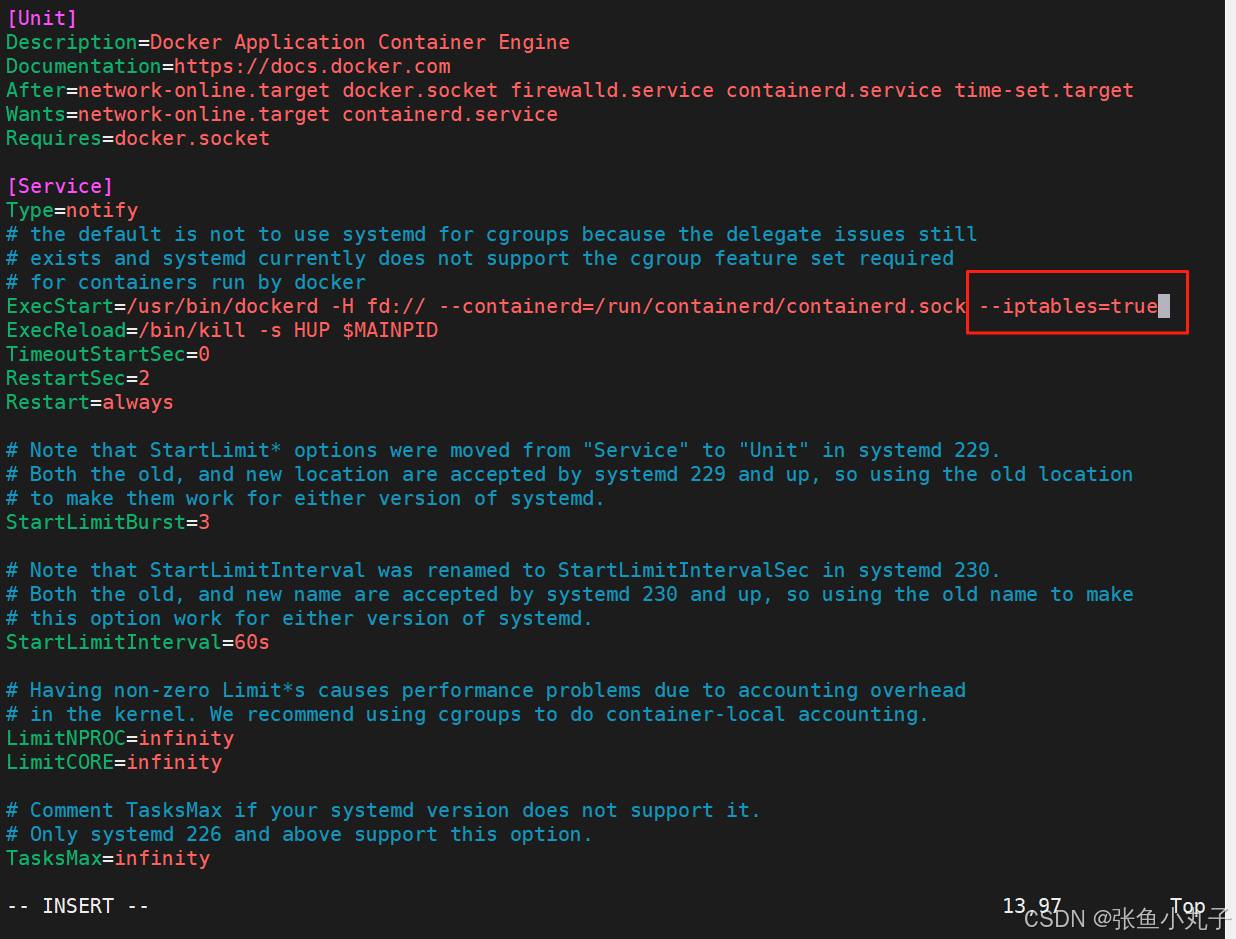
复制到10和20

复制crt过去
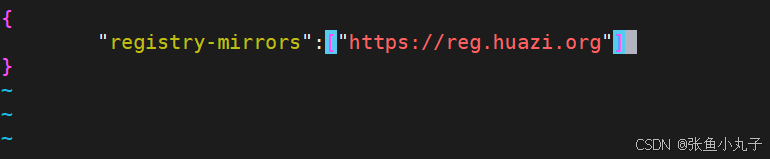
把200作为默认库
[root@master docker]# vim daemon.json

验证一下
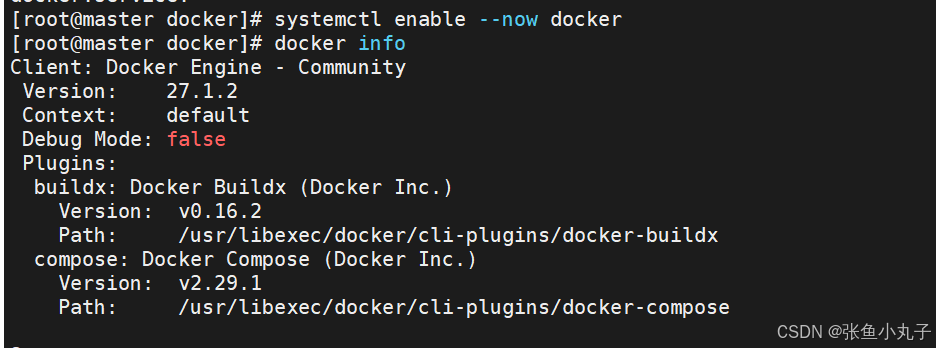
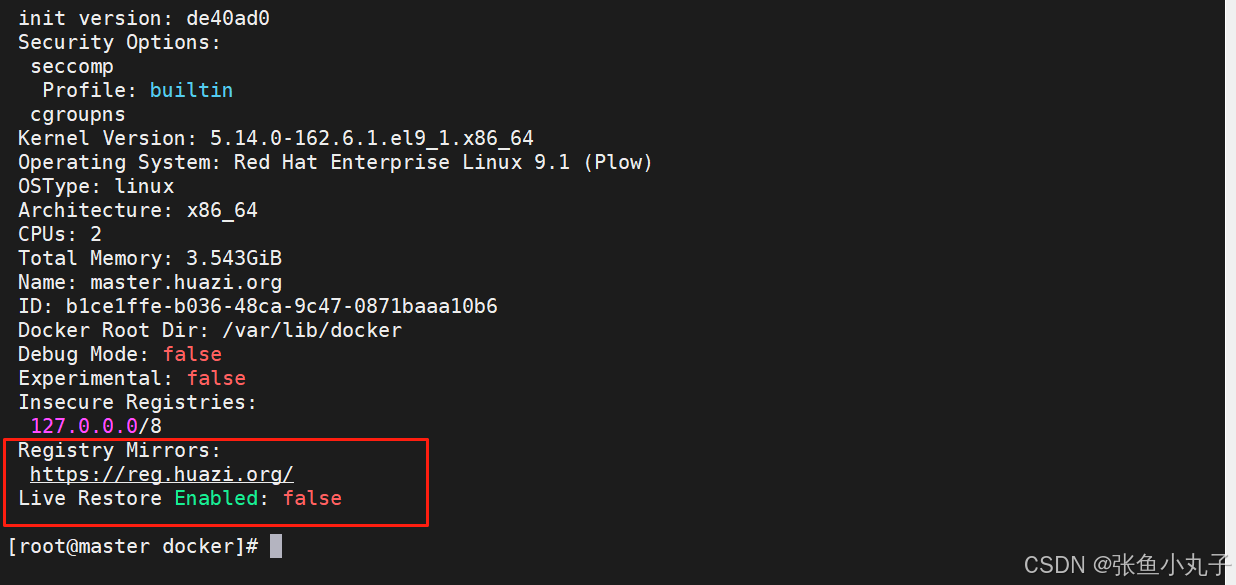
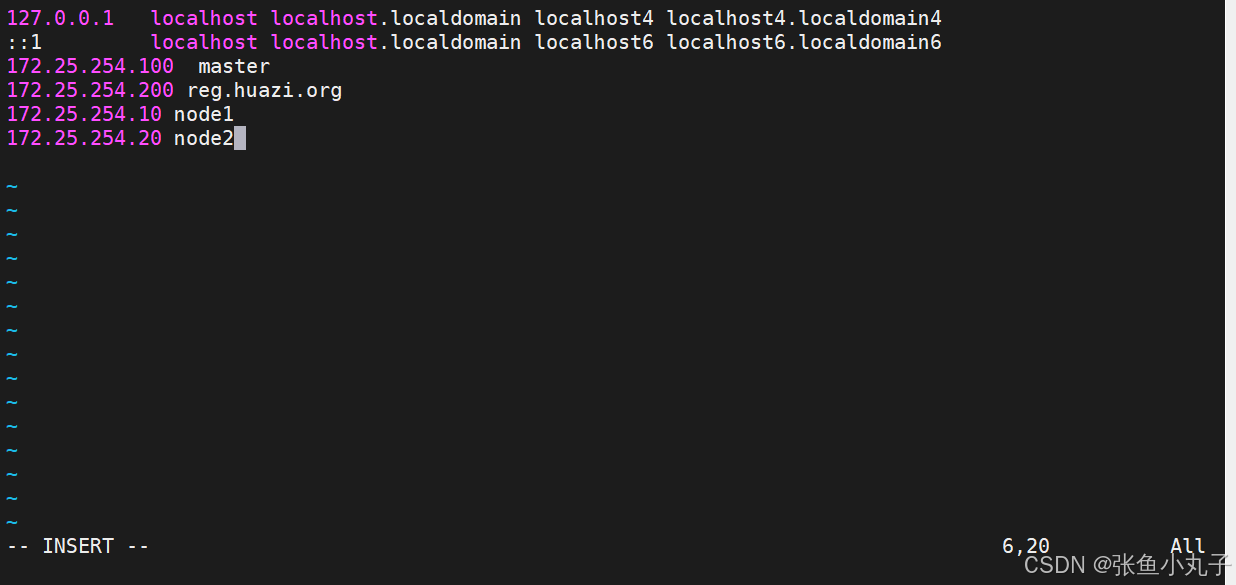
增加
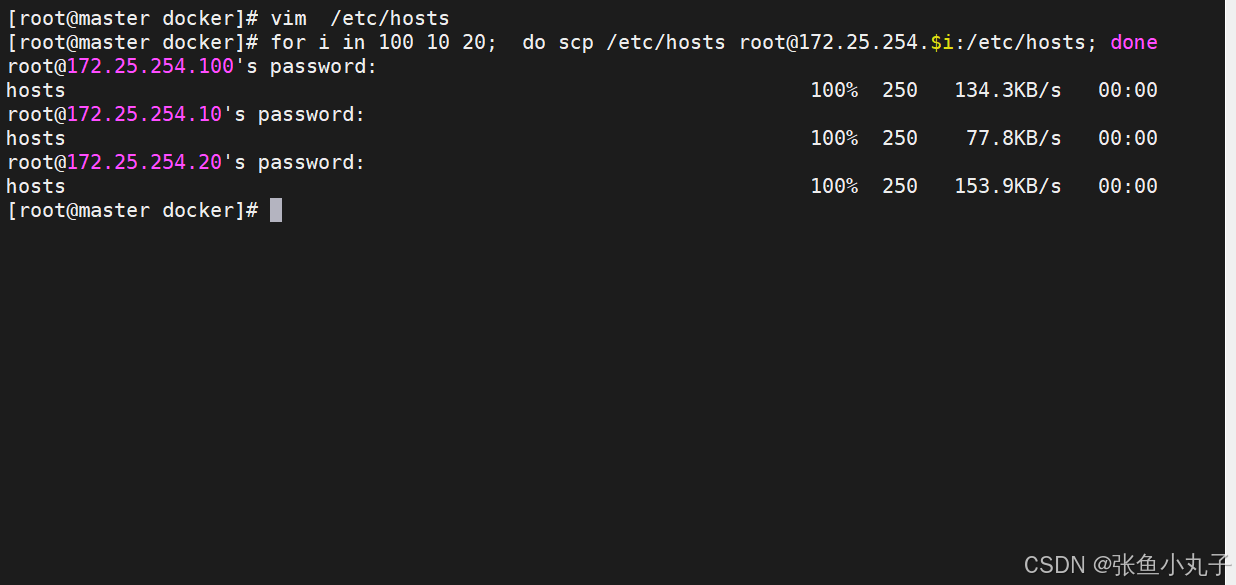
[root@master docker]# vim /etc/hosts
测试登录

安装k8s
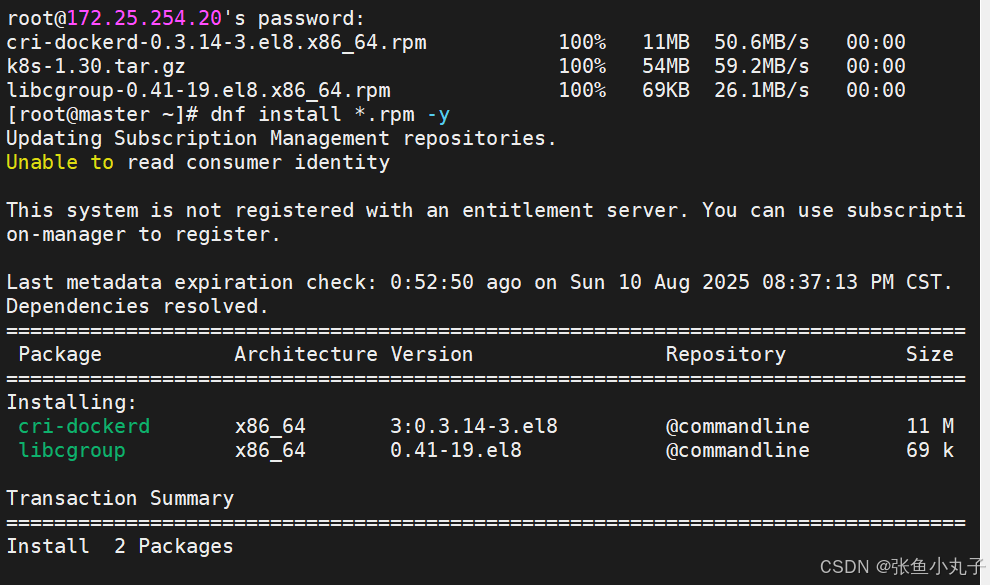
修改配置文件
[root@master ~]# vim /lib/systemd/system/cri-docker.service
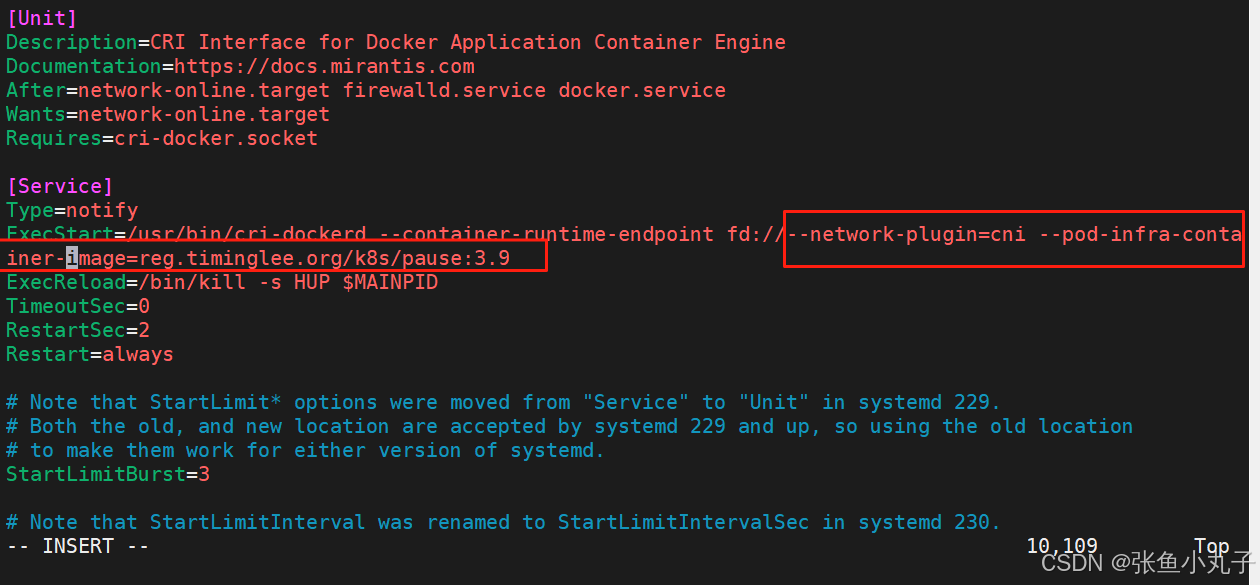
 解压k8s并安装
解压k8s并安装
补齐功能

加载
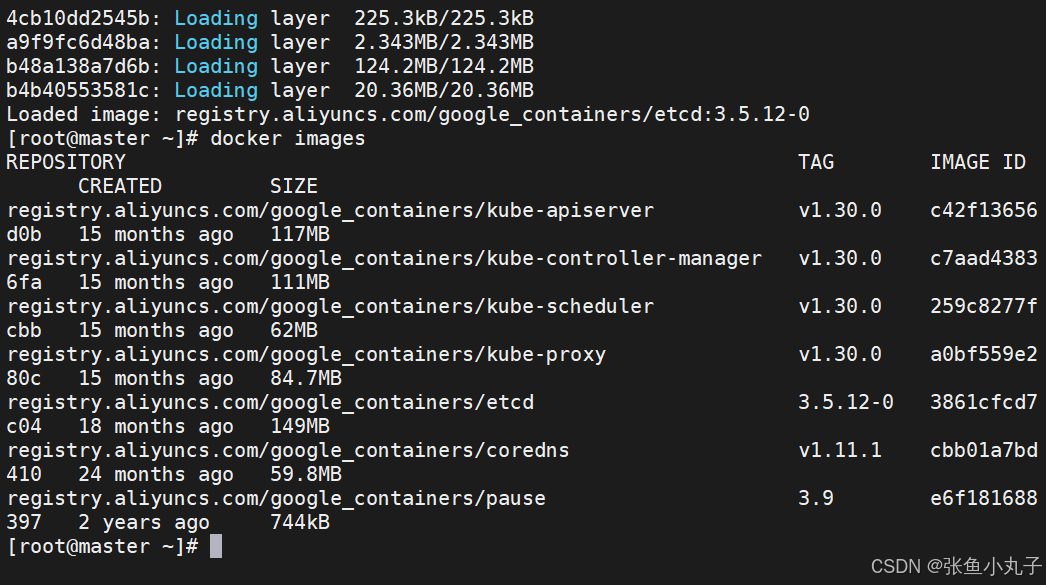
上传到harbor仓库
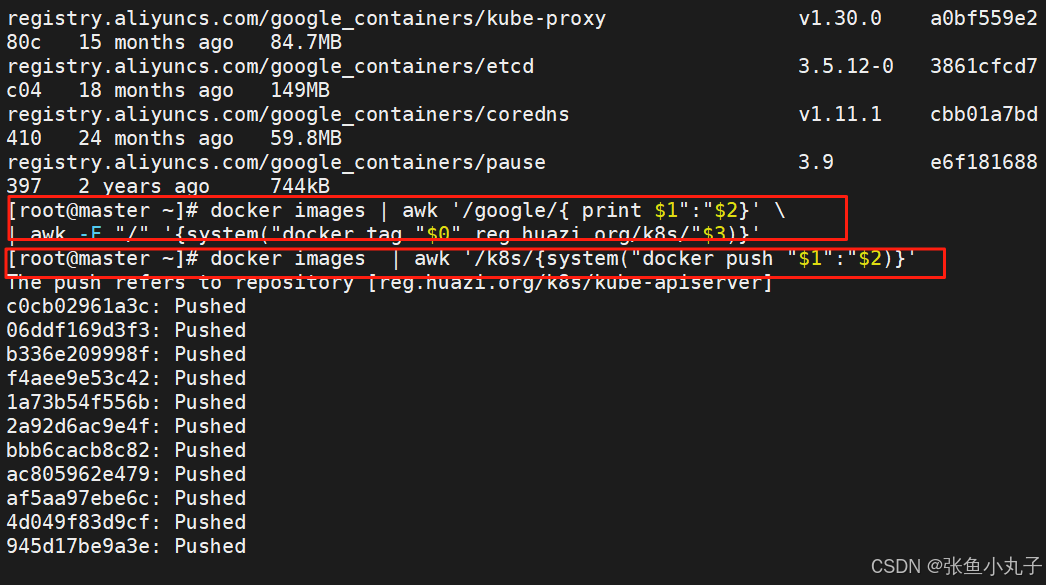
查看
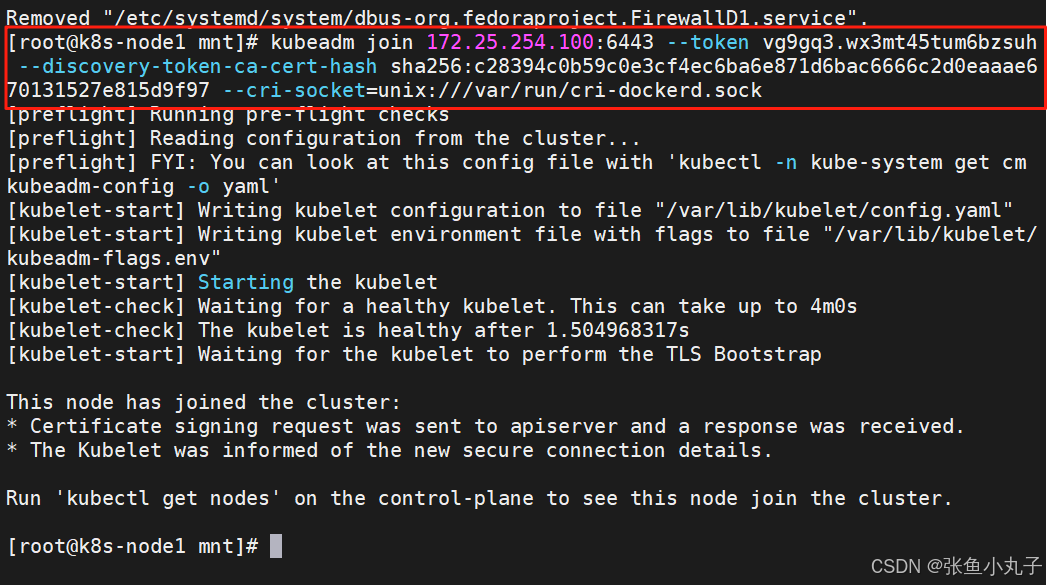
2.3 集群初始化
启动服务,所有主机都要打开

执行初始化命令
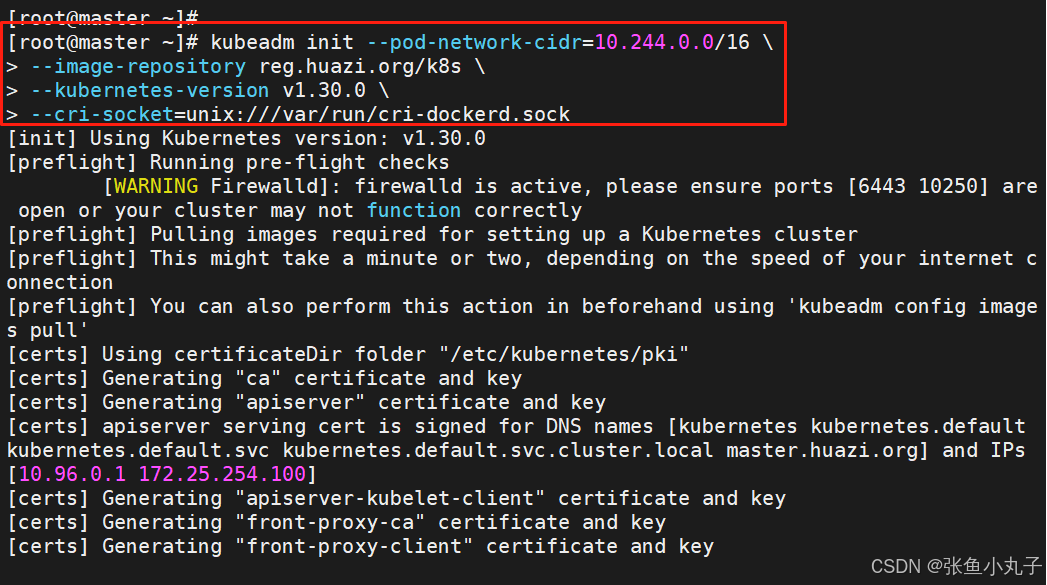
指定集群配置文件变量


安装网络插件

上传上去
编辑配置文件
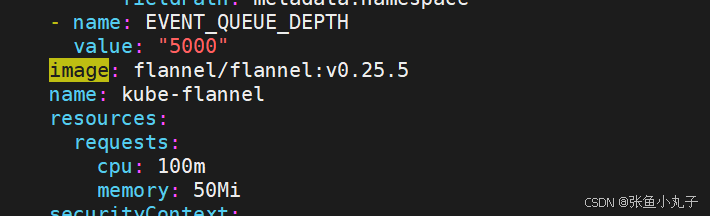
[root@master ~]# vim kube-flannel.yml
都修改成这种,把前面去掉
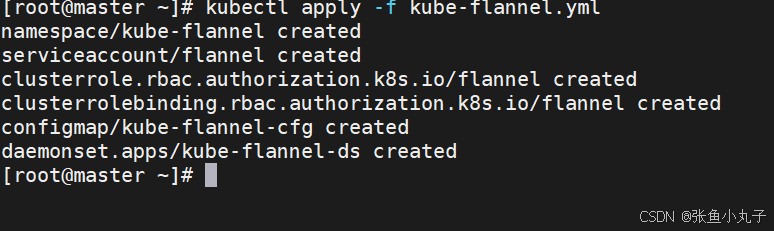

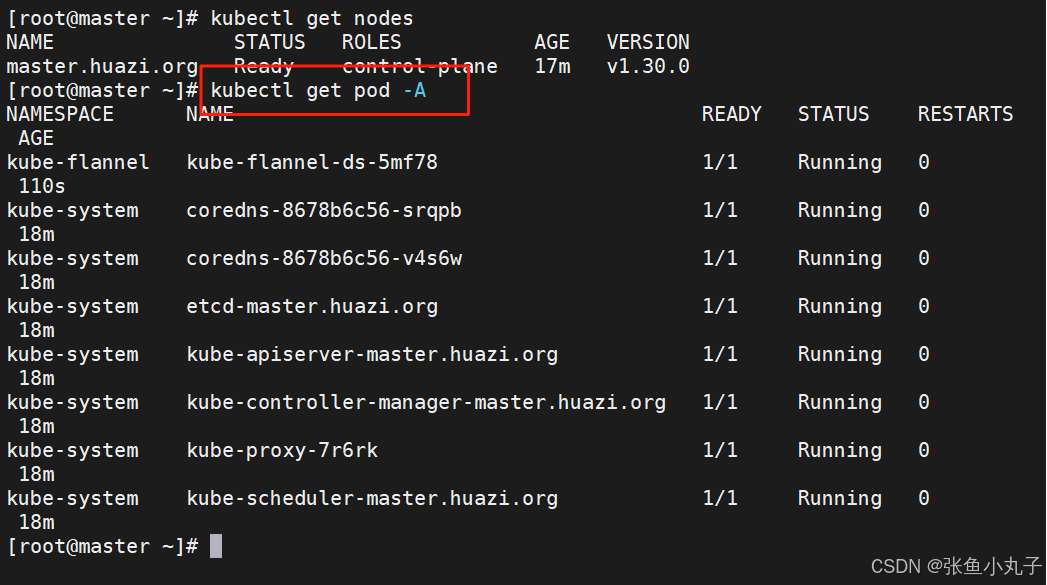
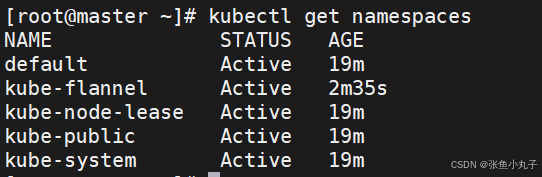

在10和20中
在100中查看

3. kubernetes 中的资源
资源调用
上传资源到libirary中
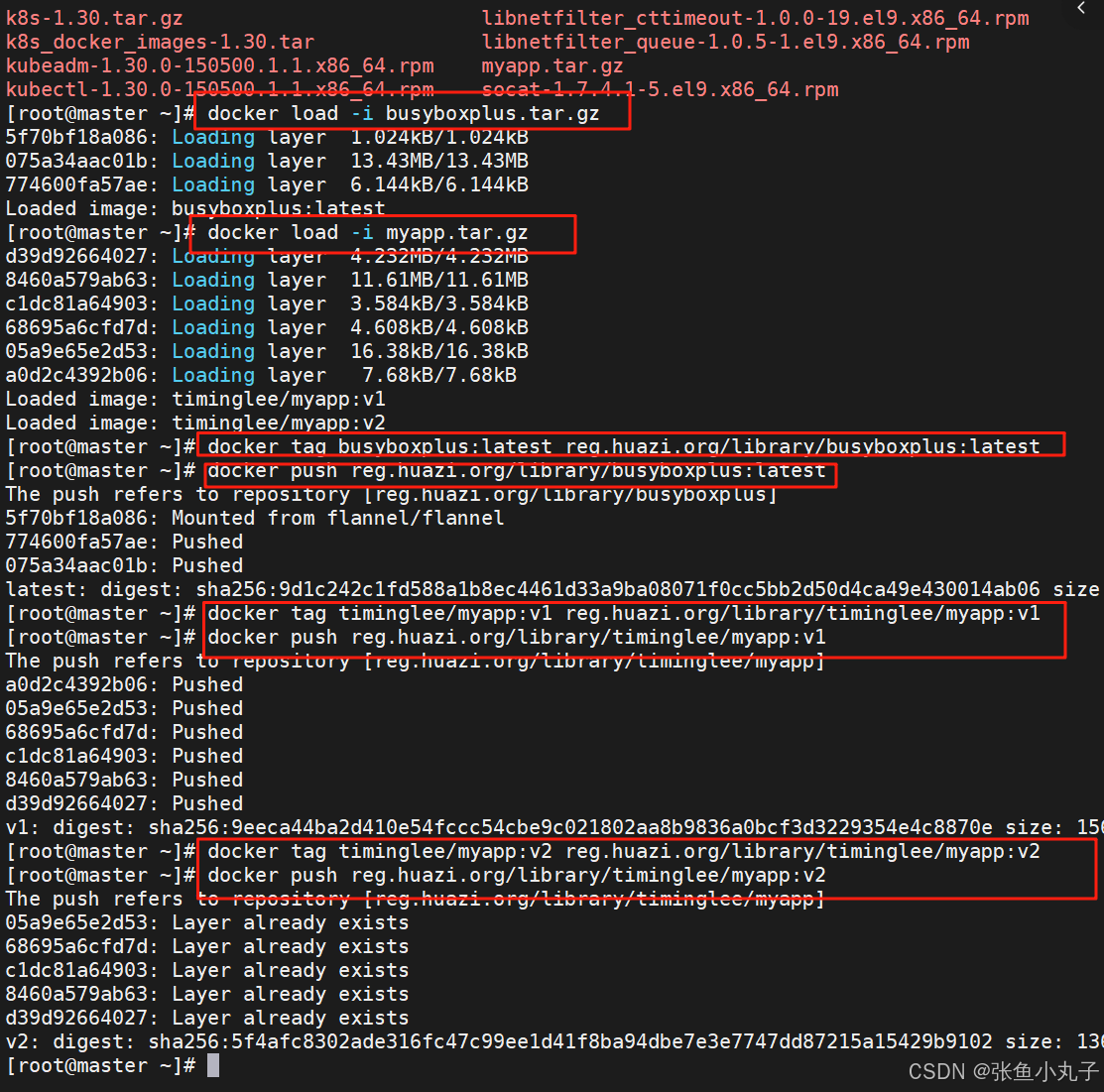
查看
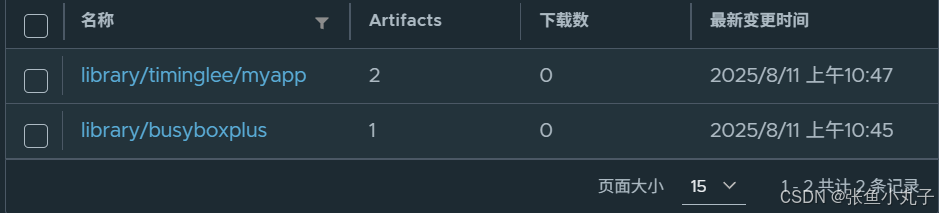
上传成功
资源管理方式
命令式对象管理:直接使用命令去操作kubernetes资源
kubectl run nginx-pod --image=nginx:latest --port=80命令式对象配置:通过命令配置和配置文件去操作kubernetes资源
kubectl create/patch -f nginx-pod.yaml声明式对象配置:通过apply命令和配置文件去操作kubernetes资源
kubectl apply -f nginx-pod.yaml
| 类型 | 适用环境 | 优点 | 缺点 |
|---|---|---|---|
| 命令式对象管理 | 测试 | 简单 | 只能操作活动对象,无法审计、跟踪 |
| 命令式对象配置 | 开发 | 可以审计、跟踪 | 项目大时,配置文件多,操作麻烦 |
| 声明式对象配置 | 开发 | 支持目录操作 | 意外情况下难以调试 |
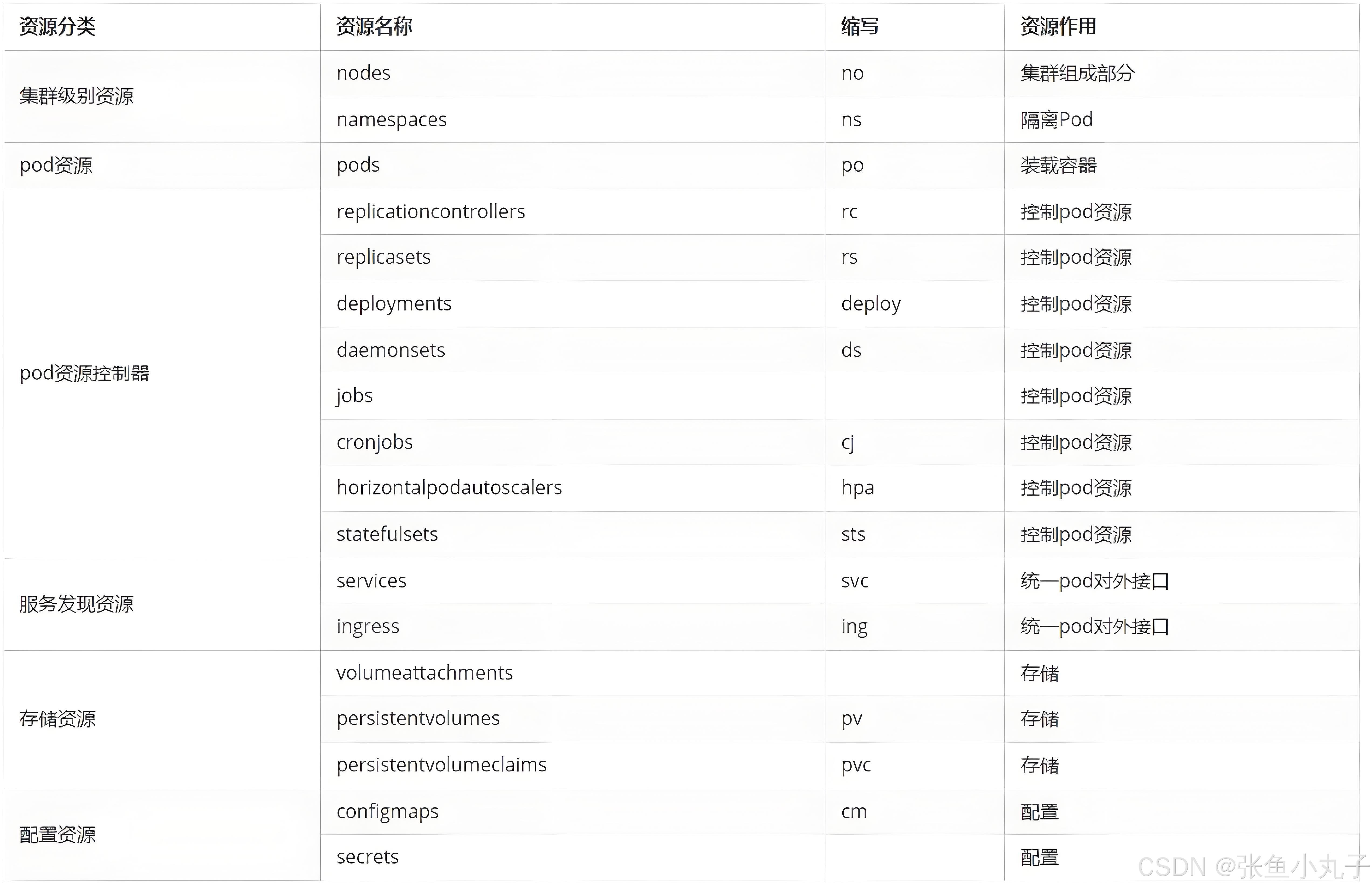
常用资源类型
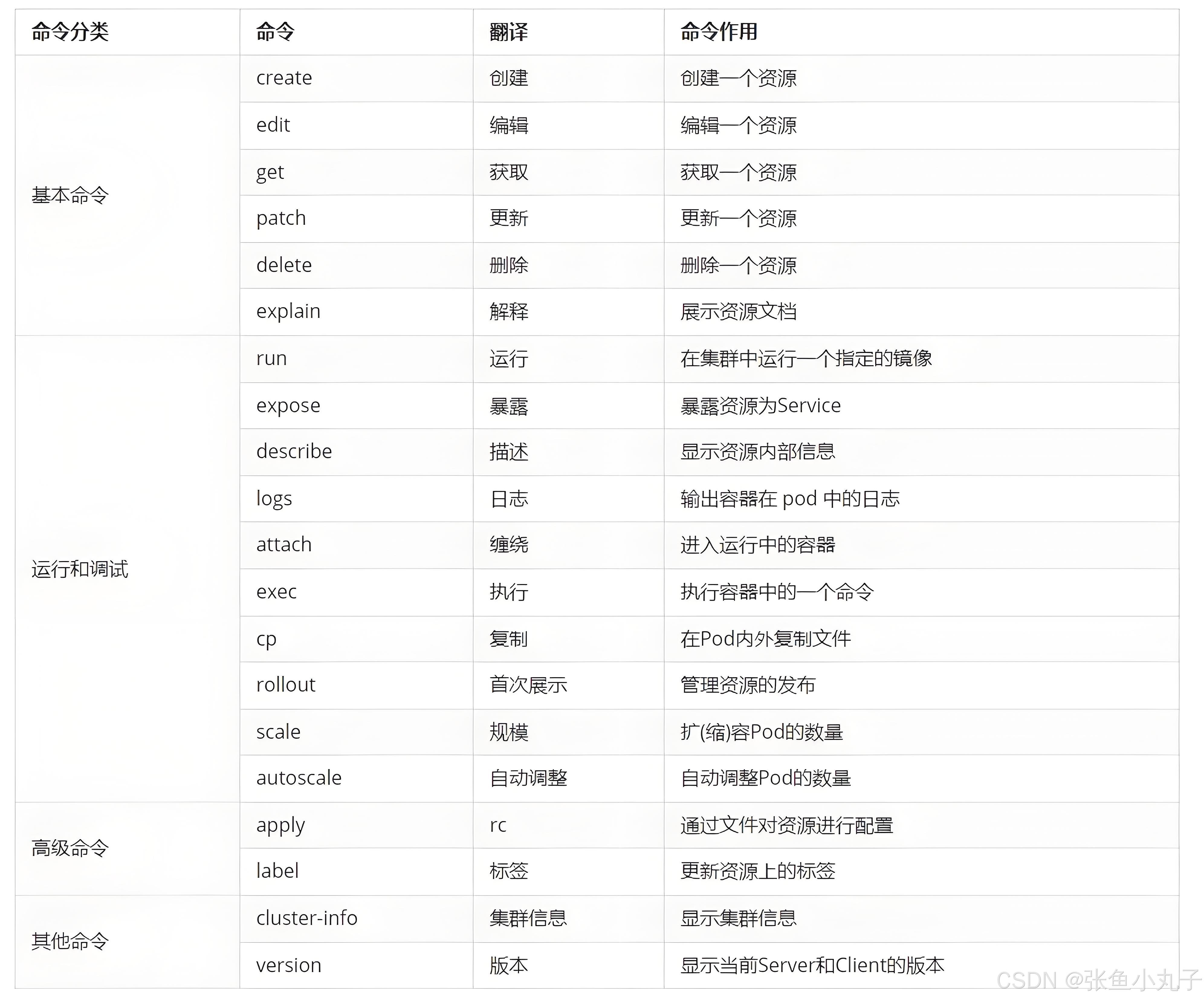
kubectl 常见命令操作
4. pod
-
Pod是可以创建和管理Kubernetes计算的最小可部署单元
-
一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip。
-
一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker)
-
多个容器间共享IPC、Network和UTC namespace。
4.1 创建自主式pod (生产不推荐)
优点:
灵活性高:
可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
学习和调试方便:
对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
适用于特殊场景:
在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
管理复杂:
如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
缺乏高级功能:
无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
可维护性差:
手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。

4.2 利用控制器管理pod(推荐)
高可用性和可靠性:
自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。
回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。
期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。
流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
建立控制器并自动运行pod

添加扩容
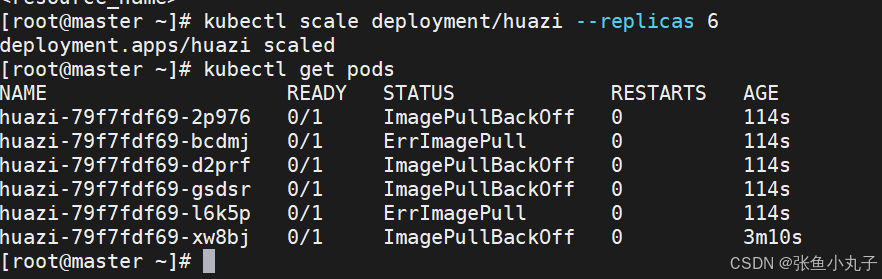
4.3 利用yaml文件部署应用
声明式配置:
-
清晰表达期望状态:以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。
-
可重复性和版本控制:配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。
-
团队协作:便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
-
丰富的配置选项:可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。
-
组合和扩展:可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
-
与 CI/CD 流程集成:可以将 YAML 配置文件与持续集成和持续部署(CI/CD)工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。
-
命令行工具支持:Kubernetes 的命令行工具
kubectl对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
资源清单参数
参数名称 类型 参数说明 version String 这里是指的是K8S API的版本,目前基本上是v1,可以用kubectl api-versions命令查询 kind String 这里指的是yaml文件定义的资源类型和角色,比如:Pod metadata Object 元数据对象,固定值就写metadata metadata.name String 元数据对象的名字,这里由我们编写,比如命名Pod的名字 metadata.namespace String 元数据对象的命名空间,由我们自身定义 Spec Object 详细定义对象,固定值就写Spec spec.containers[] list 这里是Spec对象的容器列表定义,是个列表 spec.containers[].name String 这里定义容器的名字 spec.containers[].image string 这里定义要用到的镜像名称 spec.containers[].imagePullPolicy String 定义镜像拉取策略,有三个值可选: (1) Always: 每次都尝试重新拉取镜像 (2) IfNotPresent:如果本地有镜像就使用本地镜像 (3) )Never:表示仅使用本地镜像 spec.containers[].command[] list 指定容器运行时启动的命令,若未指定则运行容器打包时指定的命令 spec.containers[].args[] list 指定容器运行参数,可以指定多个 spec.containers[].workingDir String 指定容器工作目录 spec.containers[].volumeMounts[] list 指定容器内部的存储卷配置 spec.containers[].volumeMounts[].name String 指定可以被容器挂载的存储卷的名称 spec.containers[].volumeMounts[].mountPath String 指定可以被容器挂载的存储卷的路径 spec.containers[].volumeMounts[].readOnly String 设置存储卷路径的读写模式,ture或false,默认为读写模式 spec.containers[].ports[] list 指定容器需要用到的端口列表 spec.containers[].ports[].name String 指定端口名称 spec.containers[].ports[].containerPort String 指定容器需要监听的端口号 spec.containers[] ports[].hostPort String 指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) spec.containers[].ports[].protocol String 指定端口协议,支持TCP和UDP,默认值为 TCP spec.containers[].env[] list 指定容器运行前需设置的环境变量列表 spec.containers[].env[].name String 指定环境变量名称 spec.containers[].env[].value String 指定环境变量值 spec.containers[].resources Object 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) spec.containers[].resources.limits Object 指定设置容器运行时资源的运行上限 spec.containers[].resources.limits.cpu String 指定CPU的限制,单位为核心数,1=1000m spec.containers[].resources.limits.memory String 指定MEM内存的限制,单位为MIB、GiB spec.containers[].resources.requests Object 指定容器启动和调度时的限制设置 spec.containers[].resources.requests.cpu String CPU请求,单位为core数,容器启动时初始化可用数量 spec.containers[].resources.requests.memory String 内存请求,单位为MIB、GIB,容器启动的初始化可用数量 spec.restartPolicy string 定义Pod的重启策略,默认值为Always. (1)Always: Pod-旦终止运行,无论容器是如何 终止的,kubelet服务都将重启它 (2)OnFailure: 只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它 (3) Never: Pod终止后,kubelet将退出码报告给Master,不会重启该 spec.nodeSelector Object 定义Node的Label过滤标签,以key:value格式指定 spec.imagePullSecrets Object 定义pull镜像时使用secret名称,以name:secretkey格式指定 spec.hostNetwork Boolean 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机 上启动第二个副本
单个容器
[root@master ~]# vim pod.yml
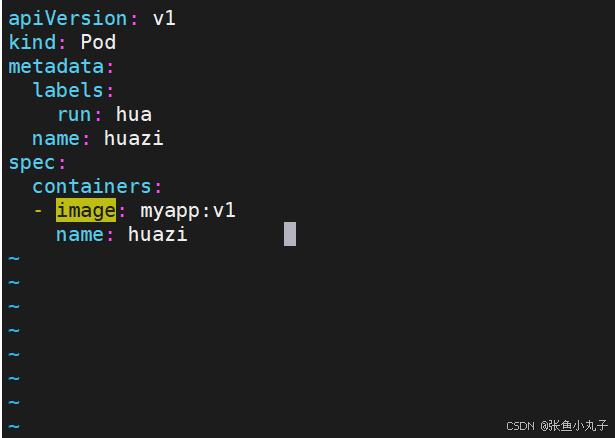
多个容器
如果多个容器运行在一个pod中,资源共享的同时在使用相同资源时也会干扰,比如端口
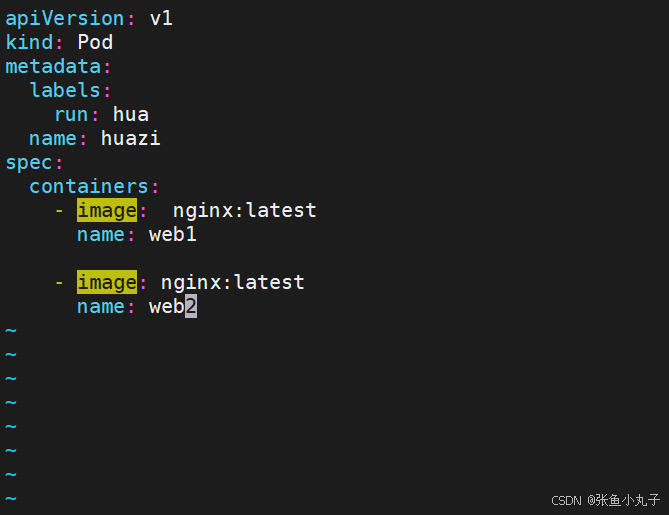
保证彼此互不打扰
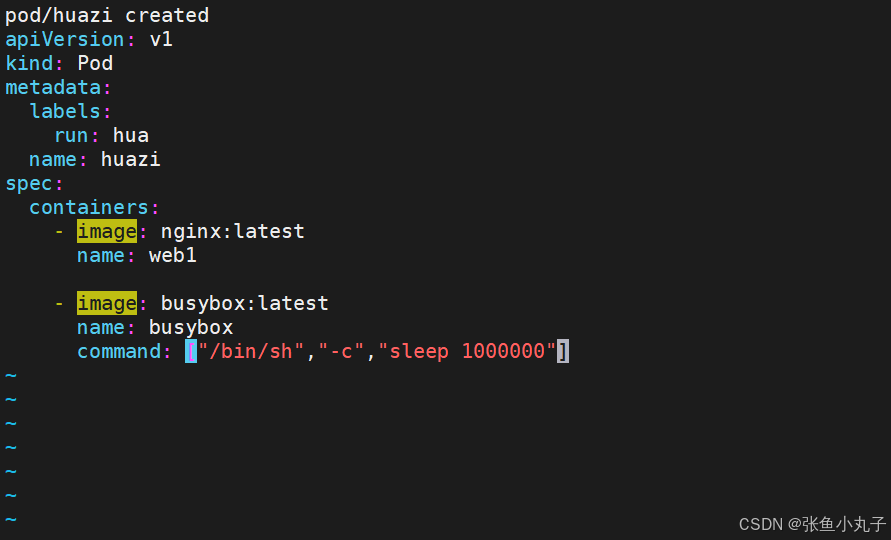
网络整合
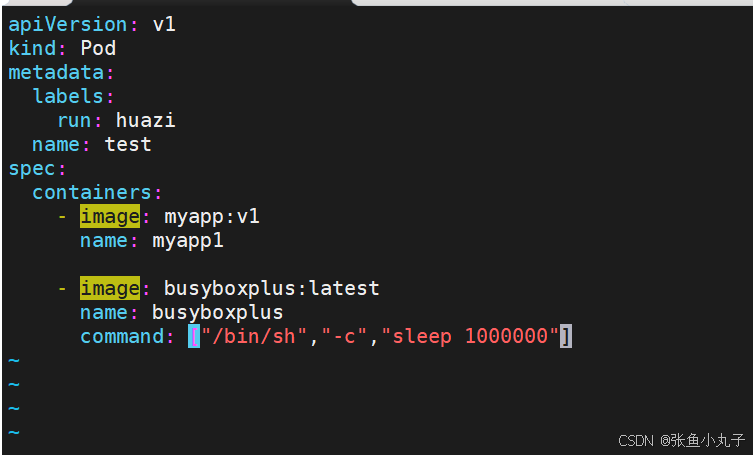
端口映射 ,修改配置文件即可
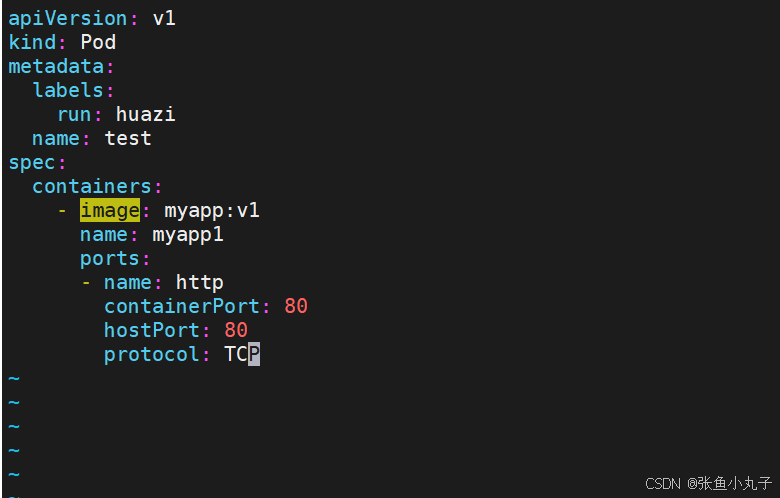
设定环境变量
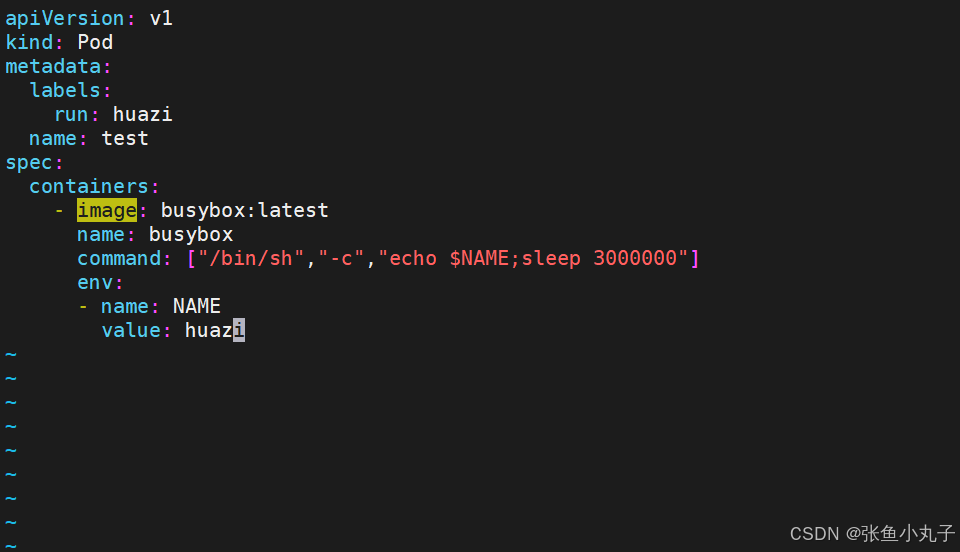
资源限制
资源限制会影响pod的Qos Class资源优先级,资源优先级分为Guaranteed > Burstable > BestEffort
| 资源设定 | 优先级类型 |
|---|---|
| 资源限定未设定 | BestEffort |
| 资源限定设定且最大和最小不一致 | Burstable |
| 资源限定设定且最大和最小一致 | Guaranteed |
[root@master ~]# kubectl apply -f pod.yml
[root@master ~]# kubectl get pods
5. pod生命周期
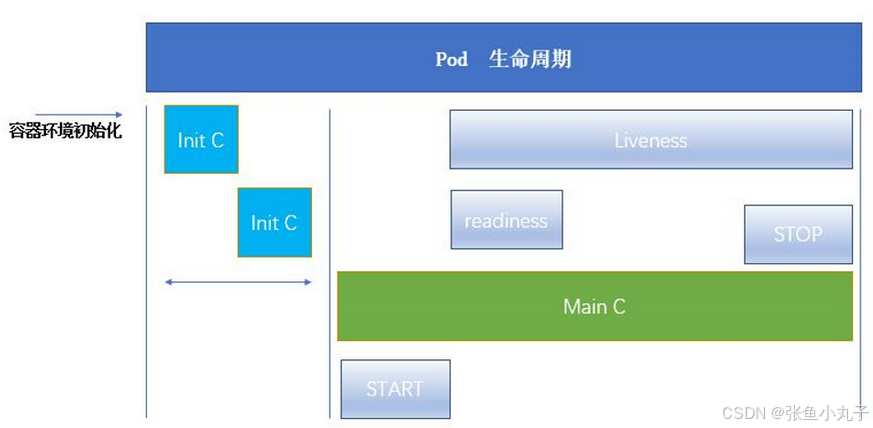
5.1 int容器
官方文档:Pod | Kubernetes生产级别的容器编排系统![]() https://kubernetes.io/zh/docs/concepts/workloads/pods/
https://kubernetes.io/zh/docs/concepts/workloads/pods/
-
-
Pod 可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
-
Init 容器与普通的容器非常像,除了如下两点:
-
它们总是运行到完成
-
init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成,每个 Init 容器必须运行成功,下一个才能够运行。
-
-
如果Pod的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。但是,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动。
INIT 容器的功能
Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。
Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
Init 容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问 Secrets 的权限,而应用容器不能够访问。
由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
把busybox上传到harbor仓库中
加载busybox

打包并上传

查看
[root@master ~]# vim pod.yml
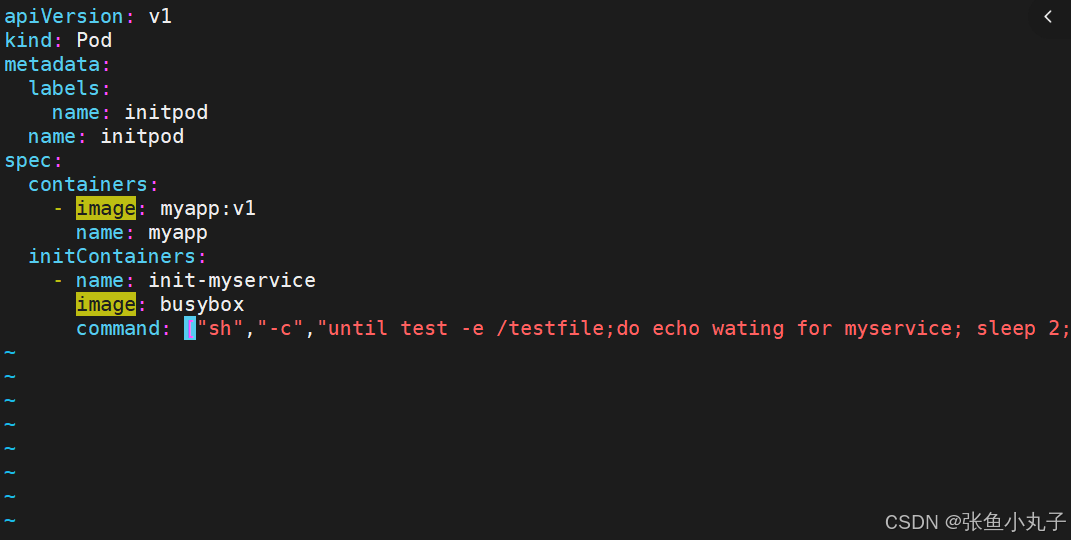
[root@master ~]# kubectl apply -f pod.yml
[root@master ~]# kubectl get pods
[root@master ~]# kubectl logs pods/initpod init-myservice
[root@master ~]# kubectl exec pods/initpod -c init-myservice -- /bin/sh -c "touch /testfile"
5.2 探针
探针是由 kubelet 对容器执行的定期诊断:
-
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
-
HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
-
成功:容器通过了诊断。
-
失败:容器未通过诊断。
-
未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
-
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
-
readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
-
startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
ReadinessProbe 与 LivenessProbe 的区别
-
ReadinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
-
LivenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施
StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
-
如果三个探针同时存在,先执行 StartupProbe 探针,其他两个探针将会被暂时禁用,直到 pod 满足 StartupProbe 探针配置的条件,其他 2 个探针启动,如果不满足按照规则重启容器。
-
另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而 StartupProbe 探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
编辑配置文件
[root@master ~]# vim pod.yml
配置文件如下:
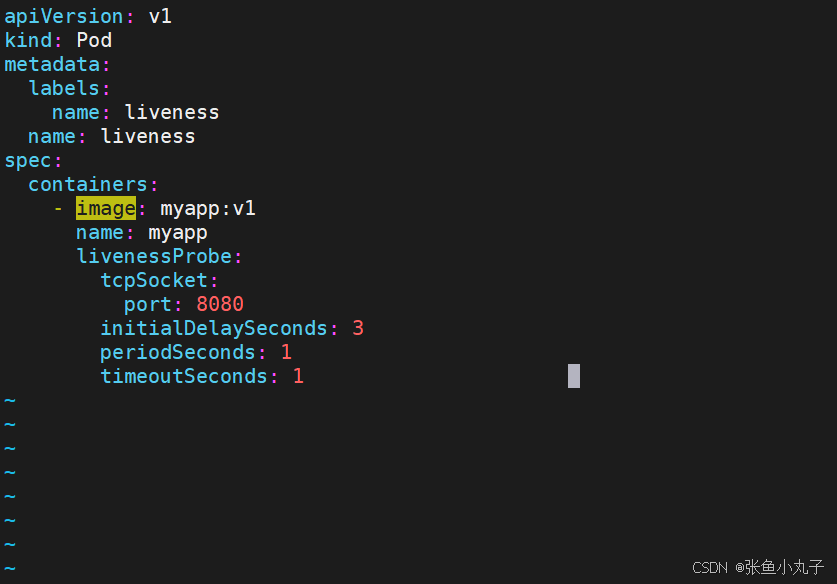
应用探针
[root@master ~]# kubectl apply -f pod.yml
[root@master ~]# kubectl get pods
[root@master ~]# kubectl describe pods
就绪探针编辑配置文件
[root@master ~]# vim pod.yml
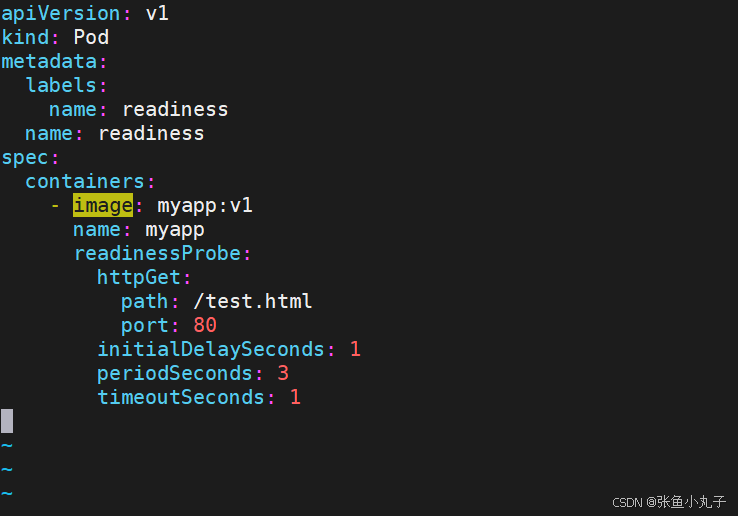
测试
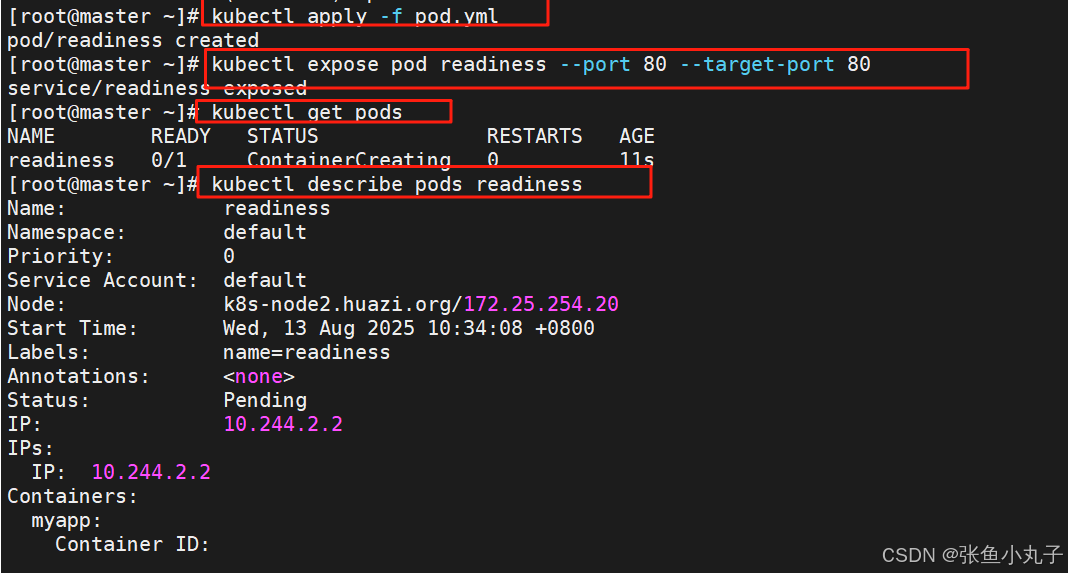
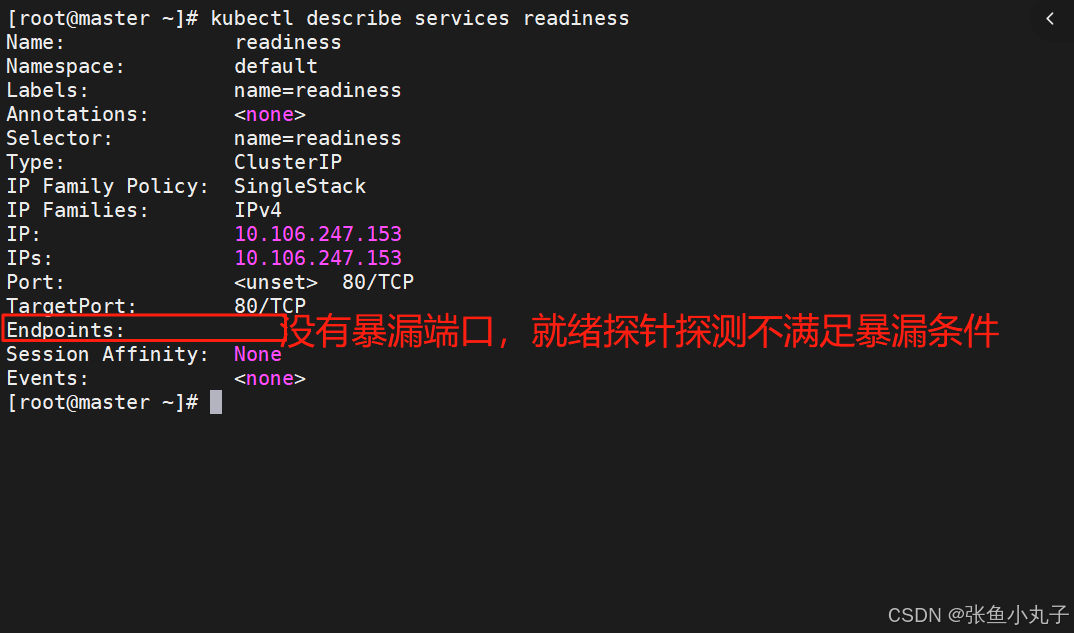
6. 控制器
官方文档:
控制器也是管理pod的一种手段
-
自主式pod:pod退出或意外关闭后不会被重新创建
-
控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
6.1 控制器类型
| 控制器名称 | 控制器用途 |
|---|---|
| Replication Controller | 比较原始的pod控制器,已经被废弃,由ReplicaSet替代 |
| ReplicaSet | ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行 |
| Deployment | 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力 |
| DaemonSet | DaemonSet 确保全指定节点上运行一个 Pod 的副本 |
| StatefulSet | StatefulSet 是用来管理有状态应用的工作负载 API 对象。 |
| Job | 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束 |
| CronJob | Cron Job 创建基于时间调度的 Jobs。 |
| HPA全称Horizontal Pod Autoscaler | 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放 |
6.2 replicaset控制器
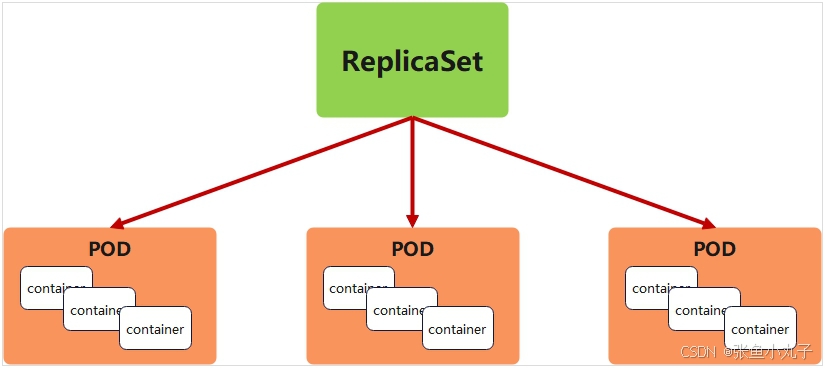
replicaset功能
ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet
ReplicaSet和Replication Controller的唯一区别是选择器的支持,ReplicaSet支持新的基于集合的选择器需求
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制
replicaset参数说明
参数名称 字段类型 参数说明 spec Object 详细定义对象,固定值就写Spec spec.replicas integer 指定维护pod数量 spec.selector Object Selector是对pod的标签查询,与pod数量匹配 spec.selector.matchLabels string 指定Selector查询标签的名称和值,以key:value方式指定 spec.template Object 指定对pod的描述信息,比如lab标签,运行容器的信息等 spec.template.metadata Object 指定pod属性 spec.template.metadata.labels string 指定pod标签 spec.template.spec Object 详细定义对象 spec.template.spec.containers list Spec对象的容器列表定义 spec.template.spec.containers.name string 指定容器名称 spec.template.spec.containers.image string 指定容器镜像
生成yum文件

编辑配置文件
[root@master replicaset]# vim replicaset.yml
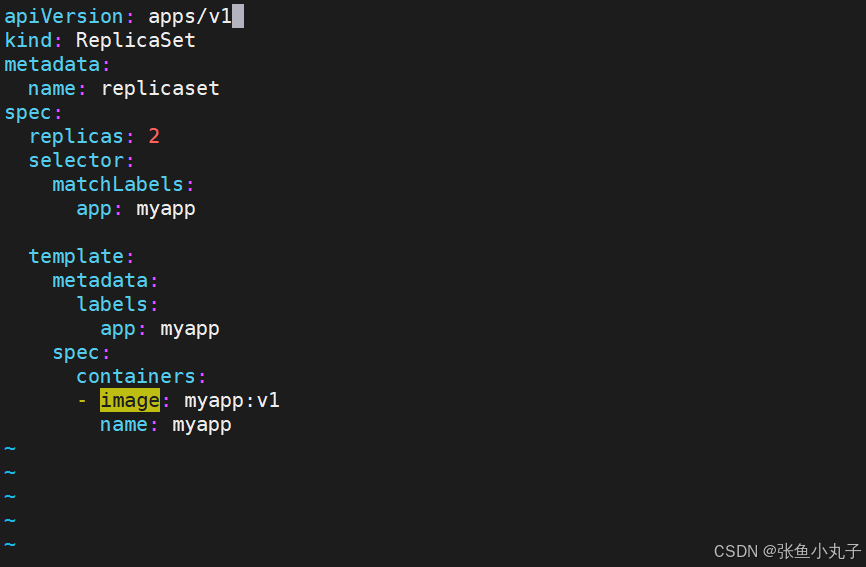
应用并查看
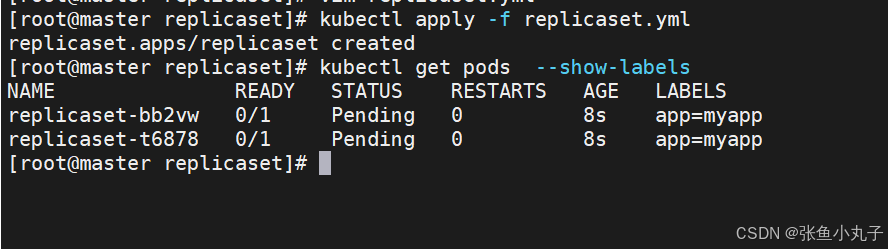
replicaset是通过标签匹配pod
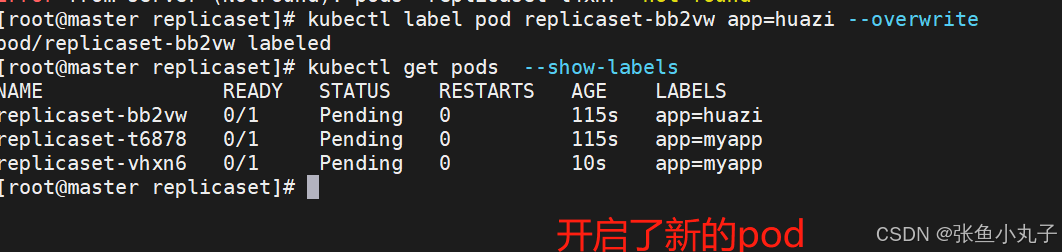
恢复标签
[root@master replicaset]# kubectl label pod replicaset-example-q2sq9 app-
replicaset自动控制副本数量,pod可以自愈,最后回收资源即可

6.3 deployment 控制器
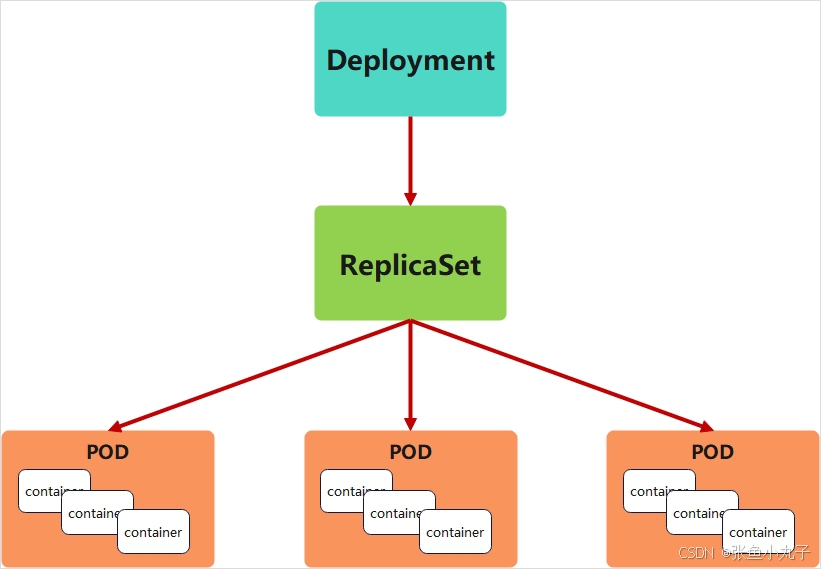
为了更好的解决服务编排的问题,kubernetes在V1.2版本开始,引入了Deployment控制器。
Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
Deployment管理ReplicaSet,ReplicaSet管理Pod
Deployment 为 Pod 和 ReplicaSet 提供了一个申明式的定义方法
在Deployment中ReplicaSet相当于一个版本
典型的应用场景:
用来创建Pod和ReplicaSet
滚动更新和回滚
扩容和缩容
暂停与恢复
生成yaml文件

编辑配置文件
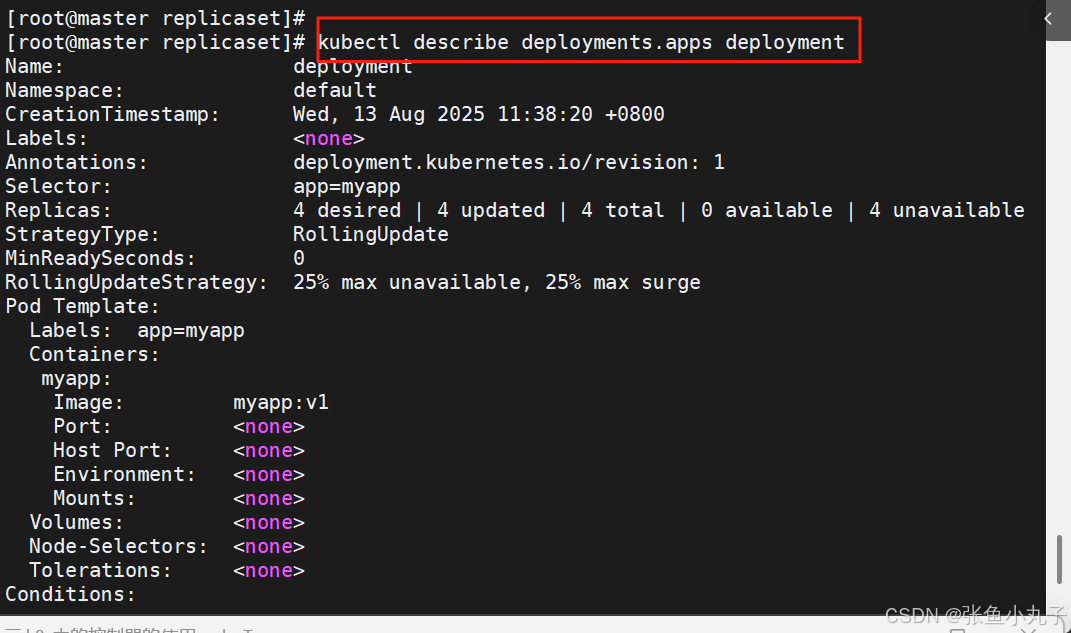
[root@master replicaset]# vim deployment.yml
建立pod

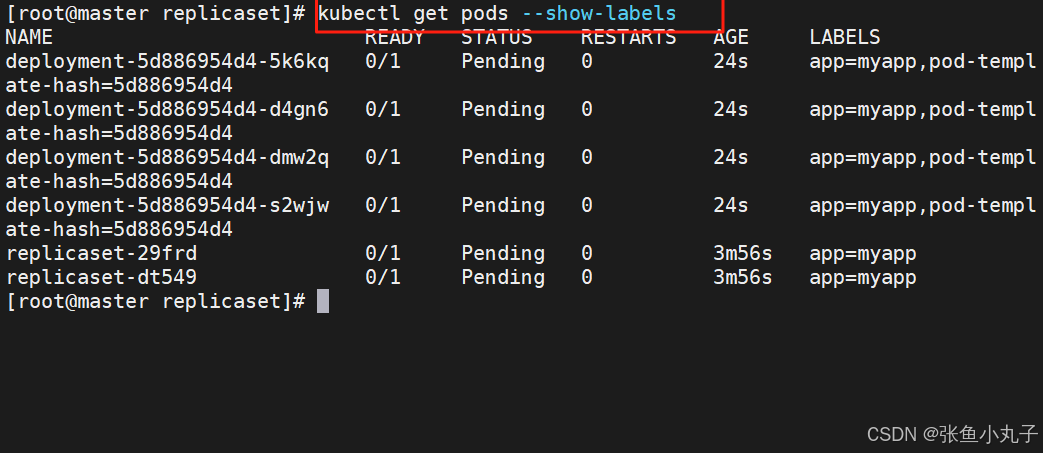
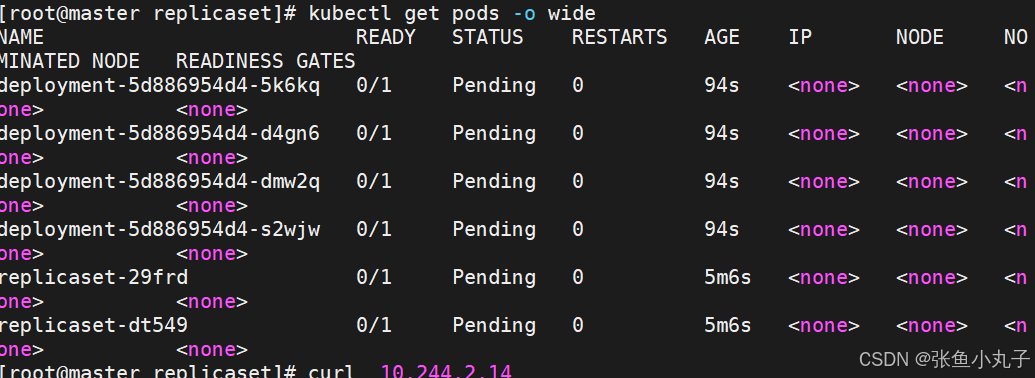
查看是否建立
版本迭代、回滚
查看
pod运行容器版本为v1
更新容器运行版本
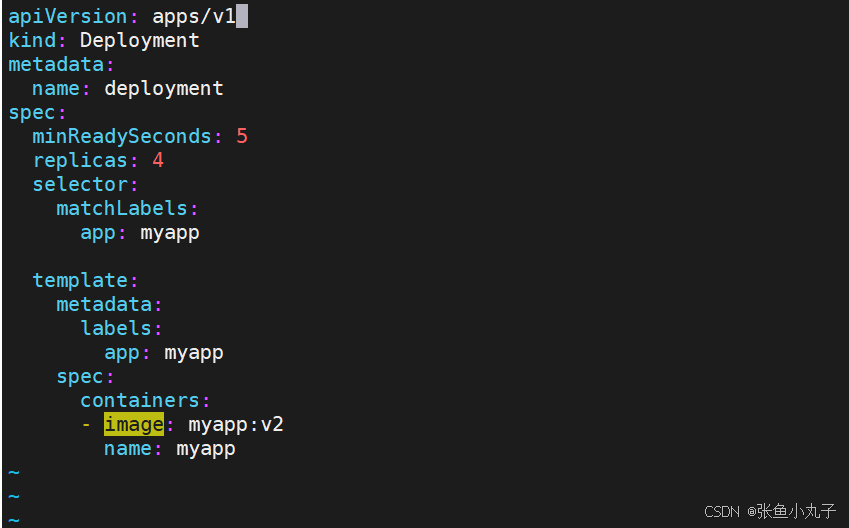
[root@master replicaset]# kubectl apply -f deployment-example.yamll
[root@master replicaset]# watch - n1 kubectl get pods -o wide
更新
回滚也是先编辑配置文件
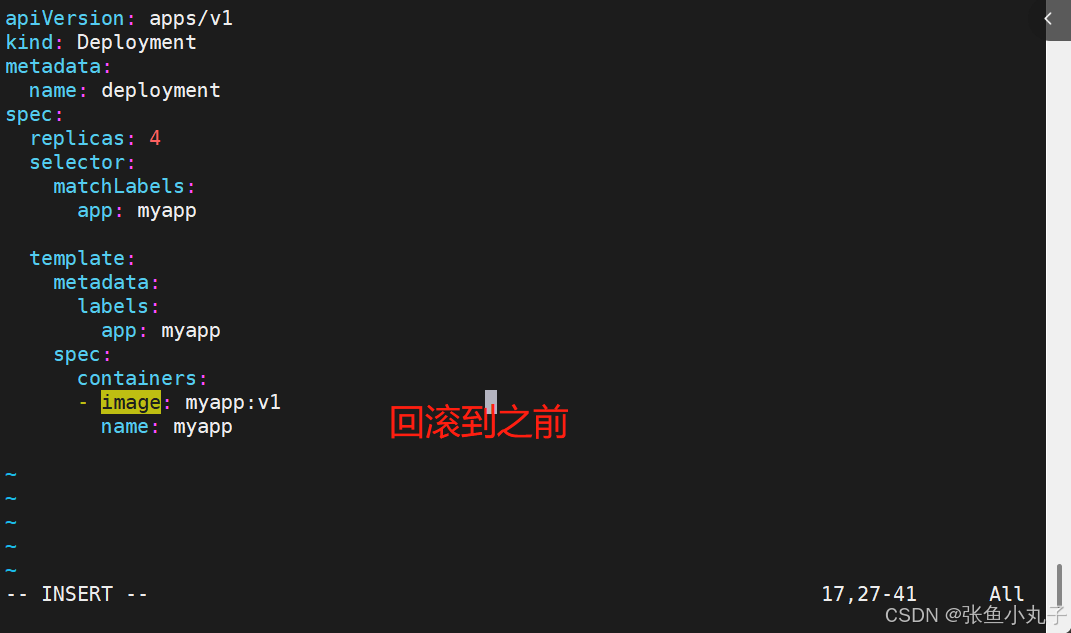
应用

查看
7. daemonset控制器
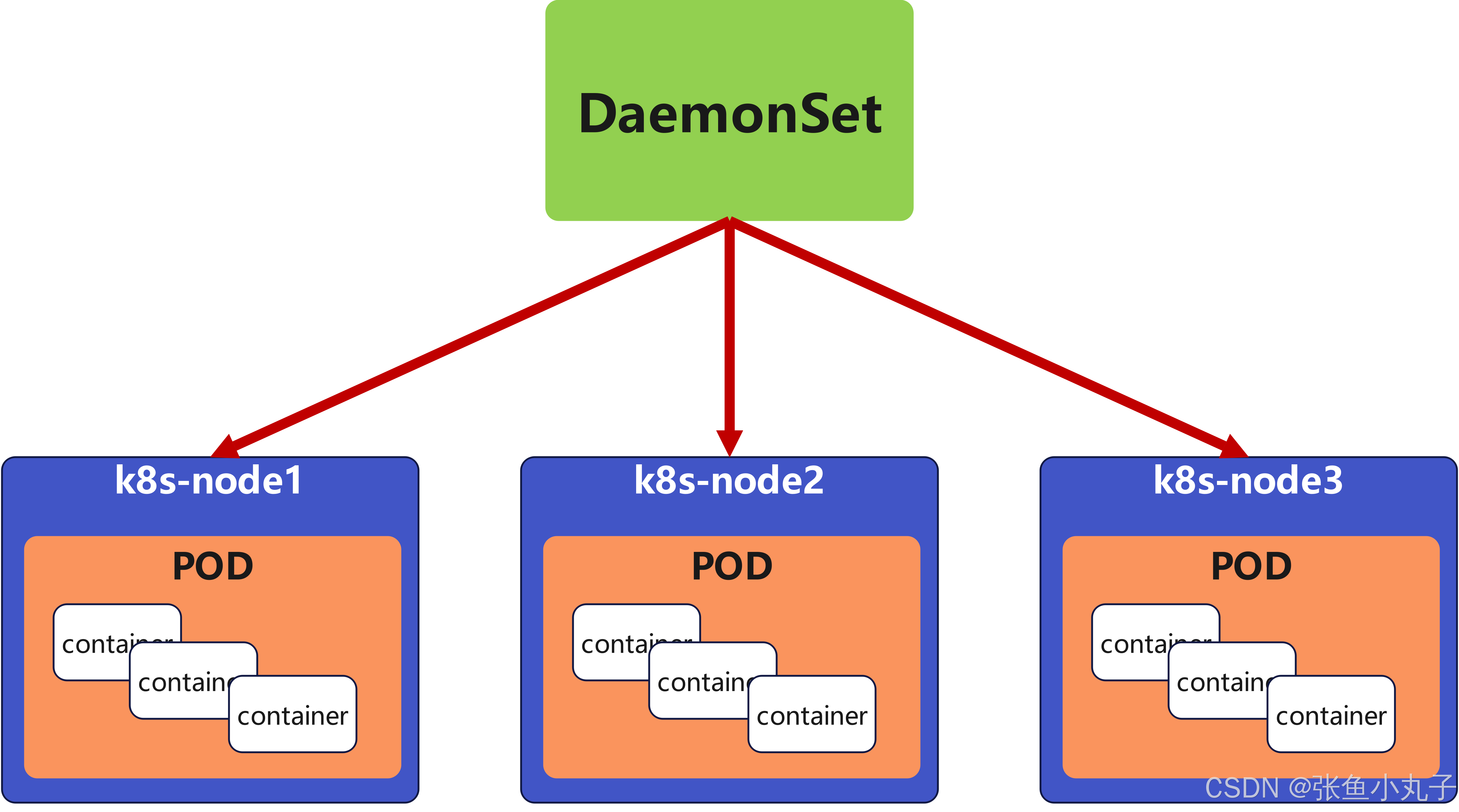
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod ,当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
DaemonSet 的典型用法:
-
在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
-
在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
-
在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent等
-
一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用
-
一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求
编辑配置文件
[root@master replicaset]# vim daemonset-example.yml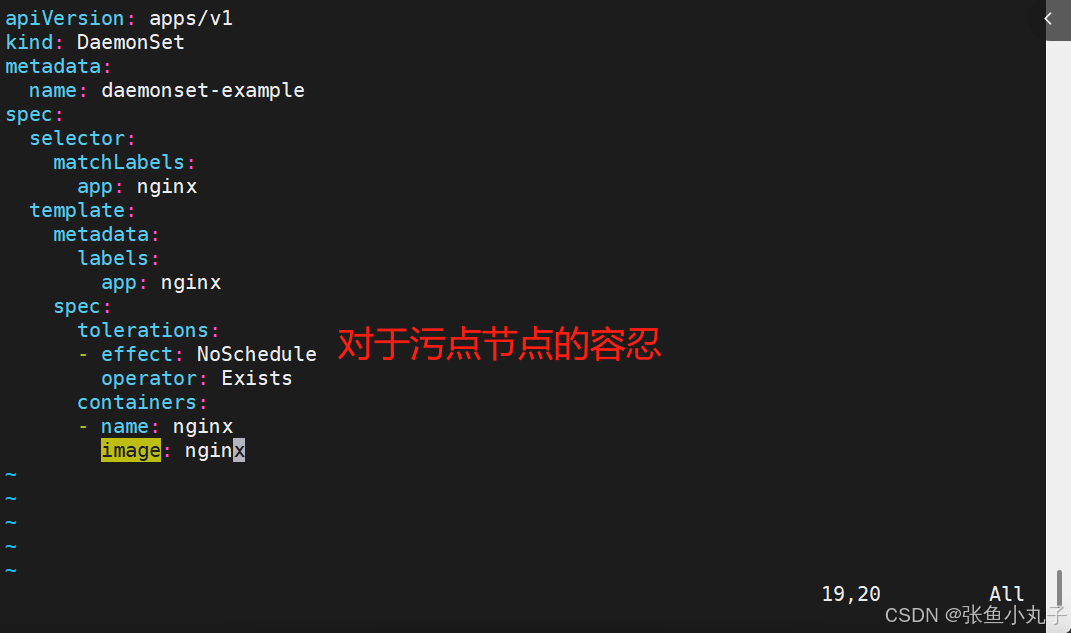
8. job 控制器
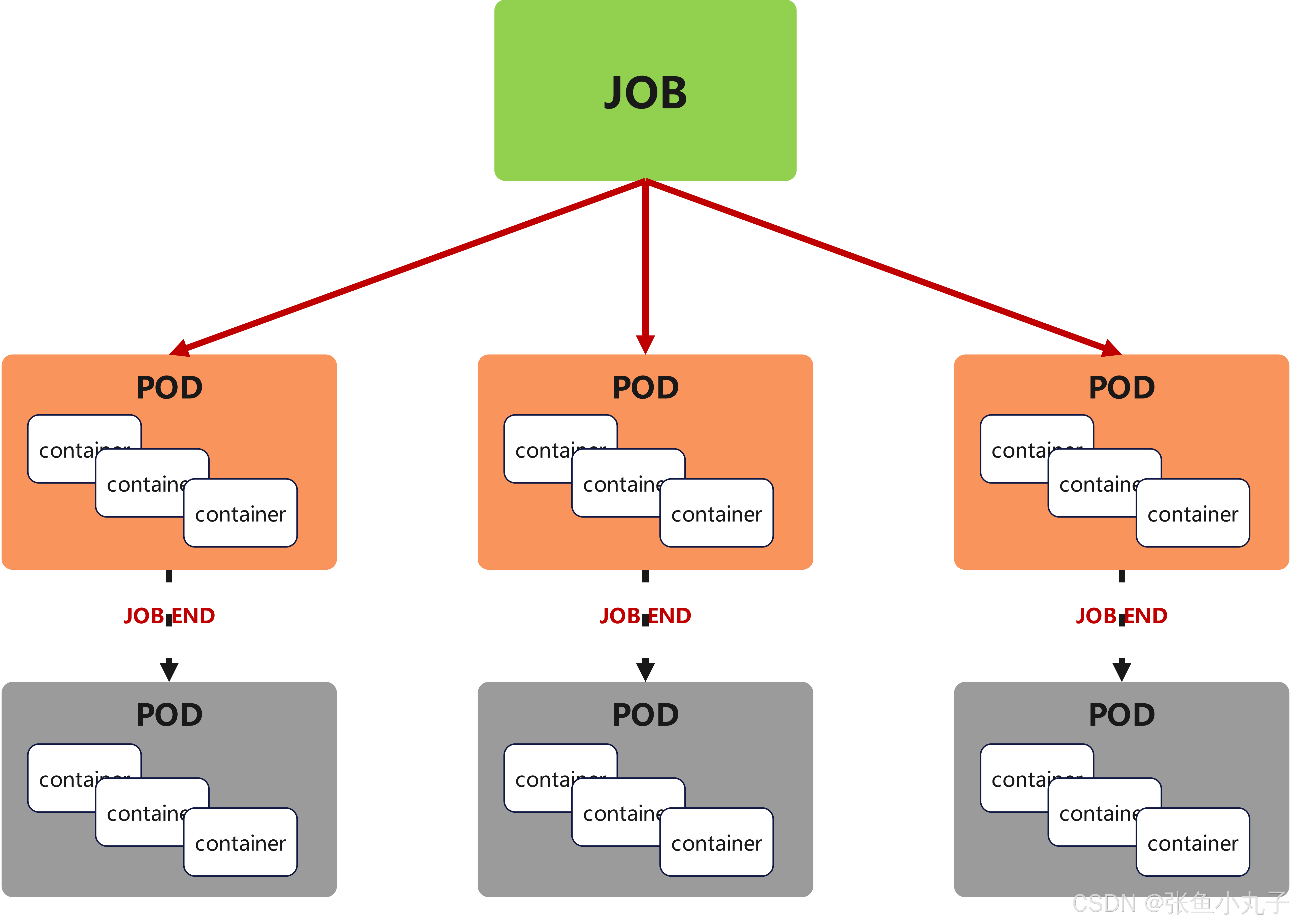
Job,主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务
Job特点如下:
当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
当成功结束的pod达到指定的数量时,Jobasd
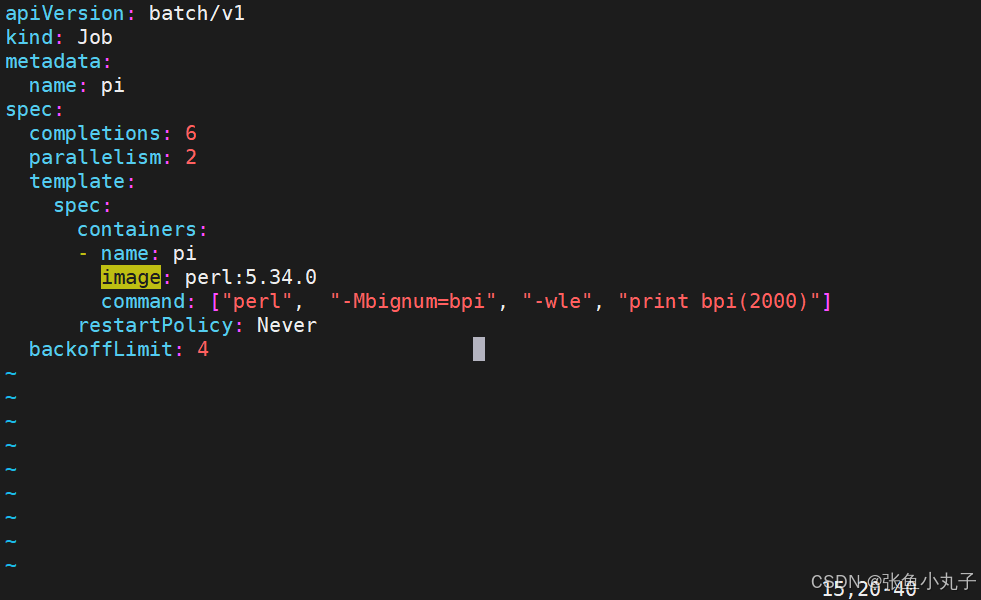
应用即可
[root@master replicaset]# kubectl apply -f job.yml关于重启策略设置的说明:
如果指定为OnFailure,则job会在pod出现故障时重启容器
而不是创建pod,failed次数不变
如果指定为Never,则job会在pod出现故障时创建新的pod
并且故障pod不会消失,也不会重启,failed次数加1
如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了
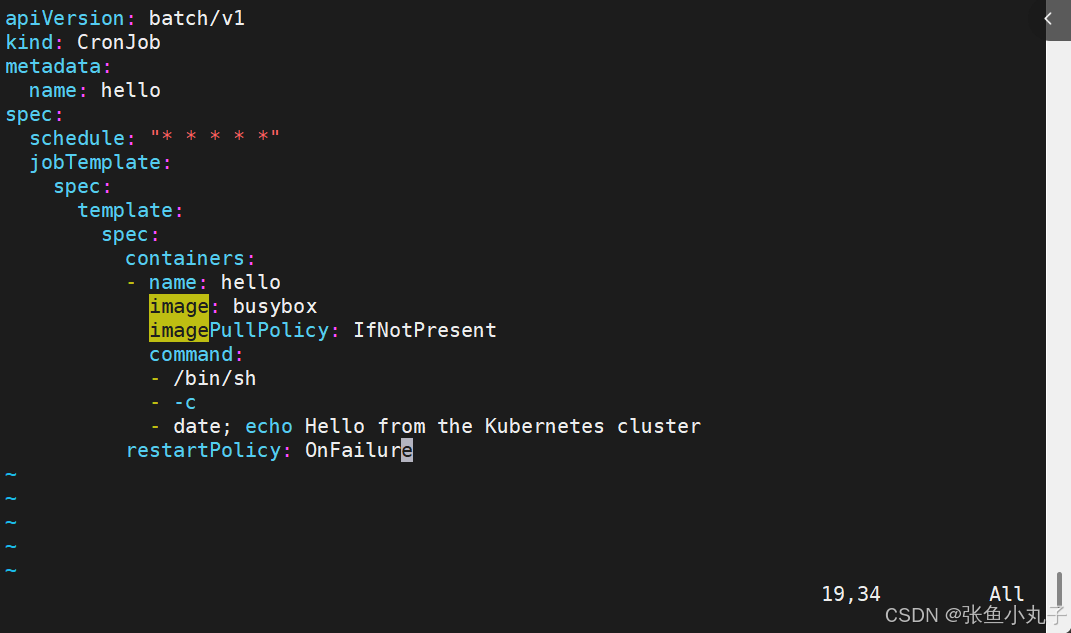
9. cronjob 控制器
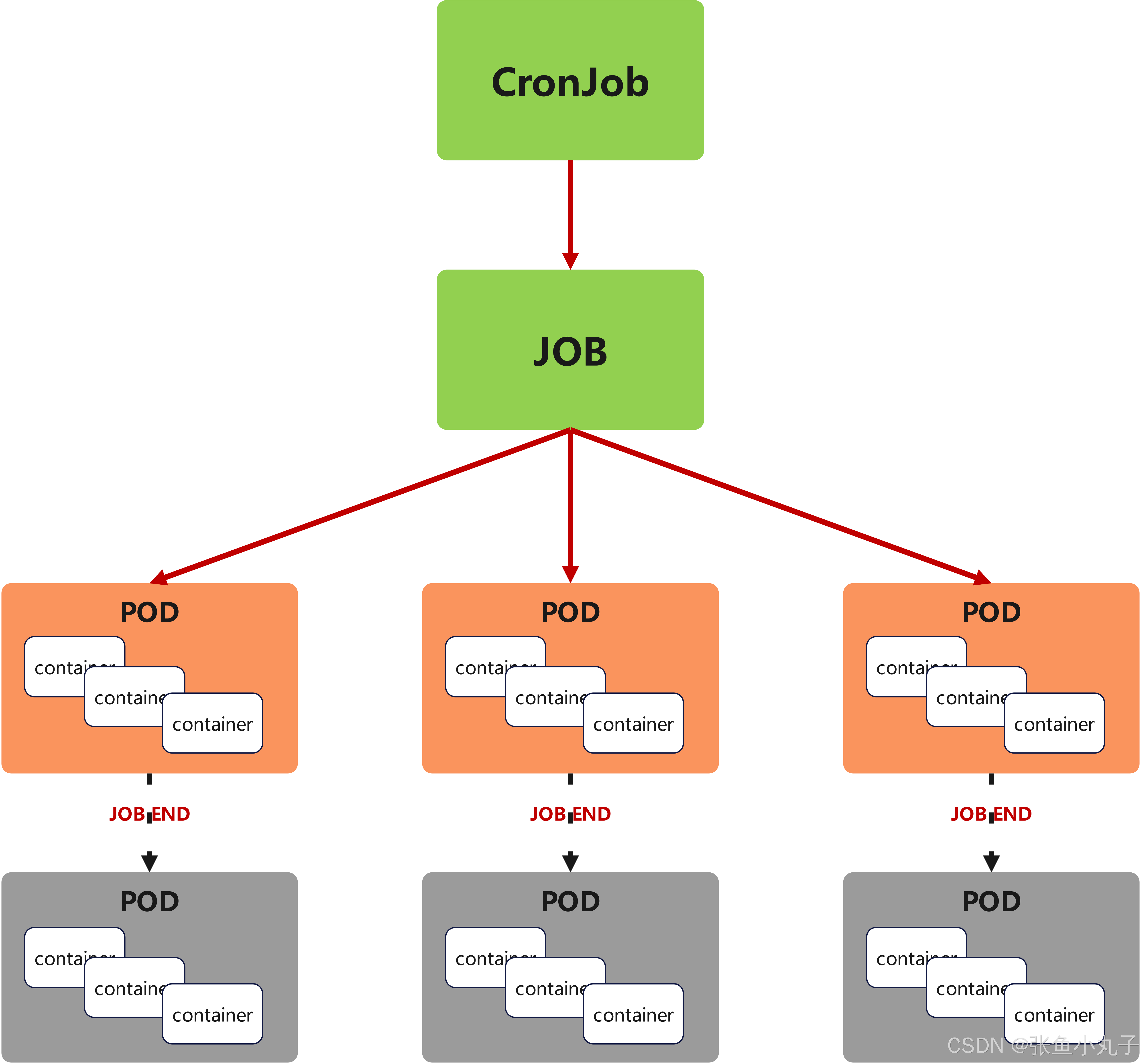
-
Cron Job 创建基于时间调度的 Jobs。
-
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象,
-
CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。
-
CronJob可以在特定的时间点(反复的)去运行job任务。
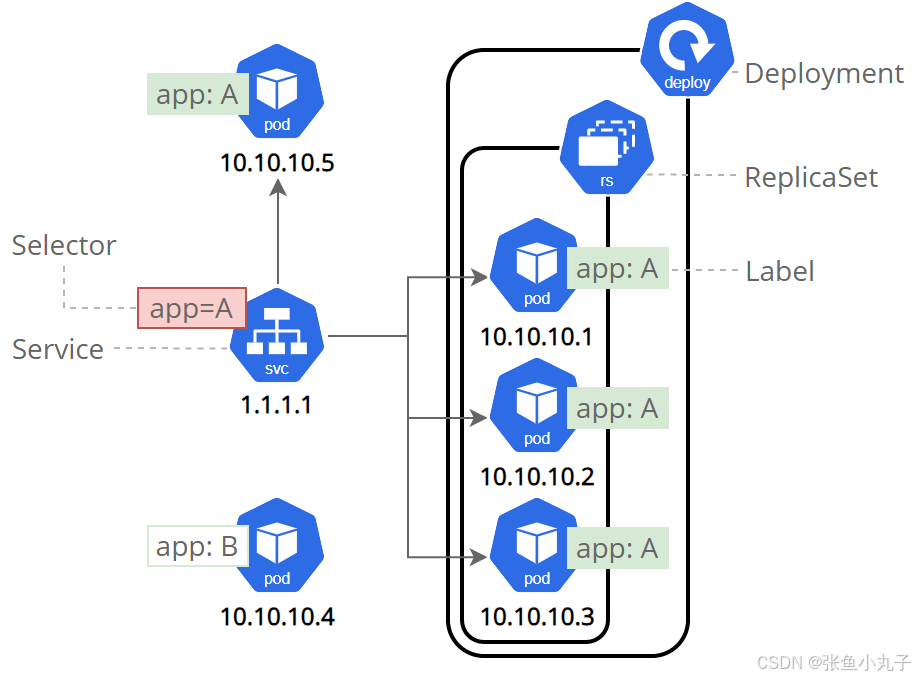
10. 微服务
用控制器来完成集群的工作负载,那么应用如何暴漏出去?需要通过微服务暴漏出去后才能被访问
-
Service是一组提供相同服务的Pod对外开放的接口。
-
借助Service,应用可以实现服务发现和负载均衡。
-
service默认只支持4层负载均衡能力,没有7层功能。(可以通过Ingress实现)
微服务的类型
微服务类型 作用描述 ClusterIP 默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问 NodePort 将Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到ClusterIP LoadBalancer 在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort,此模式只能在云服务器上使用 ExternalName 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定
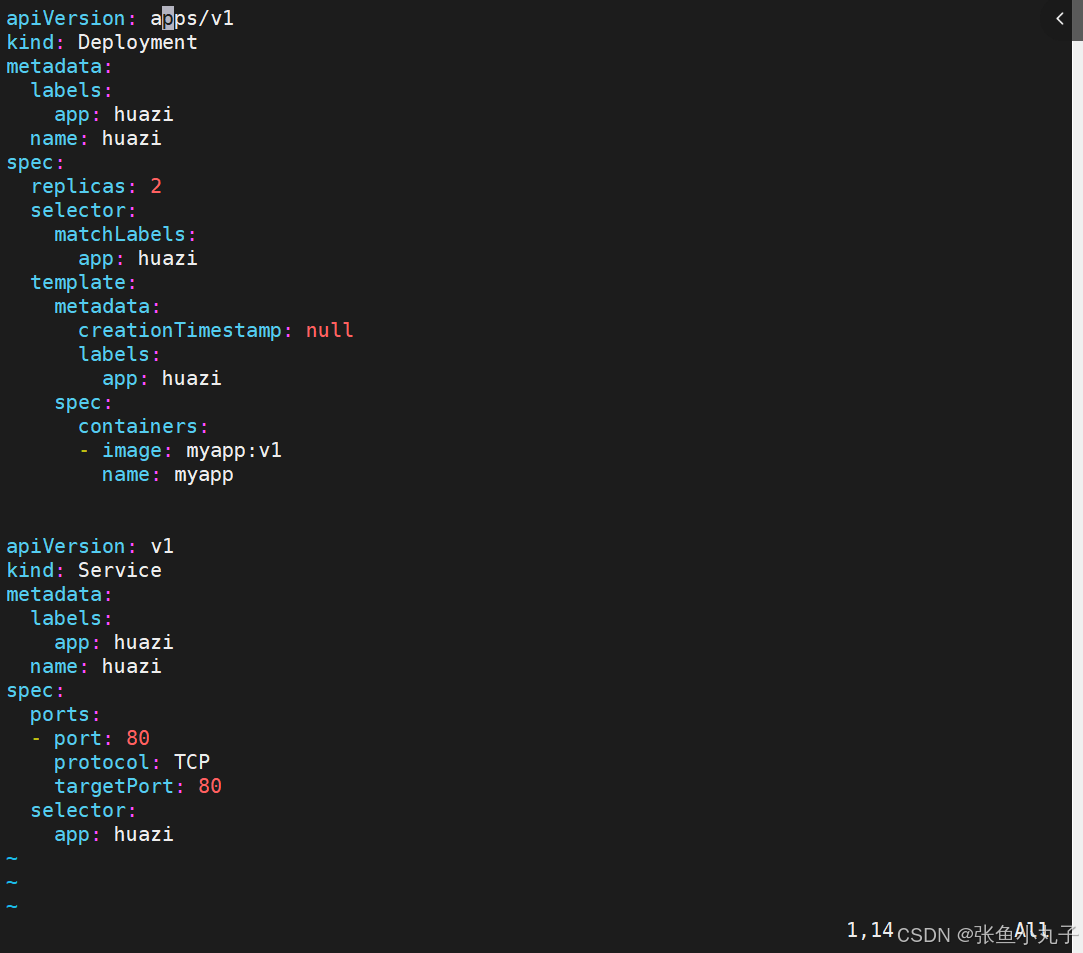
生成控制器

追加到yaml中

编辑配置文件

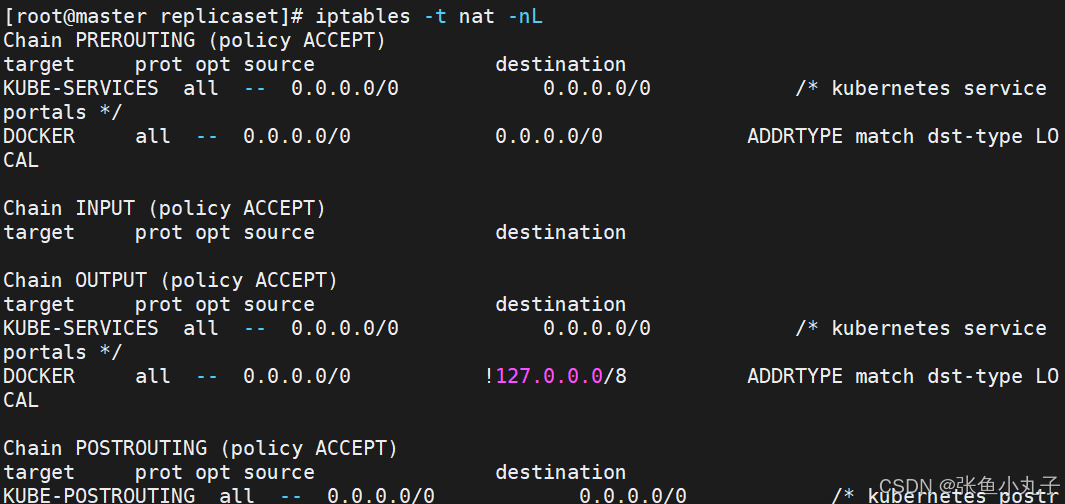
在火墙中查看到策略信息
11. ipvs模式
-
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
-
kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的 iptables 规则,如果宿主机有大量的Pod,不断刷新iptables规则,会消耗大量的CPU资源
-
IPVS模式的service,可以使K8s集群支持更多量级的Pod
三台主机都需安装ipvsadm
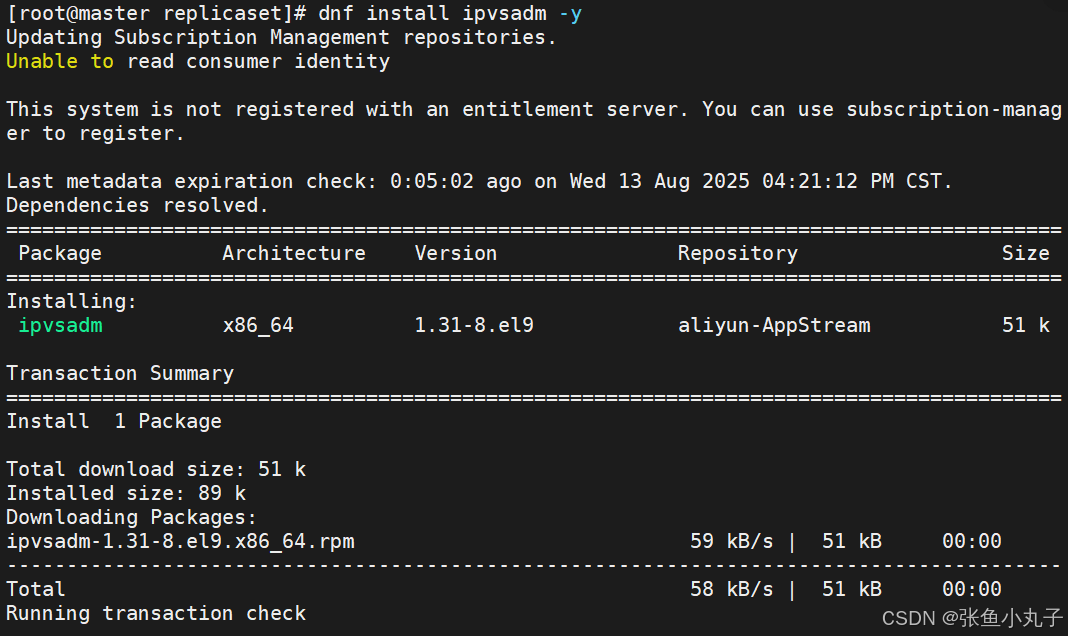
修改节点代理配置
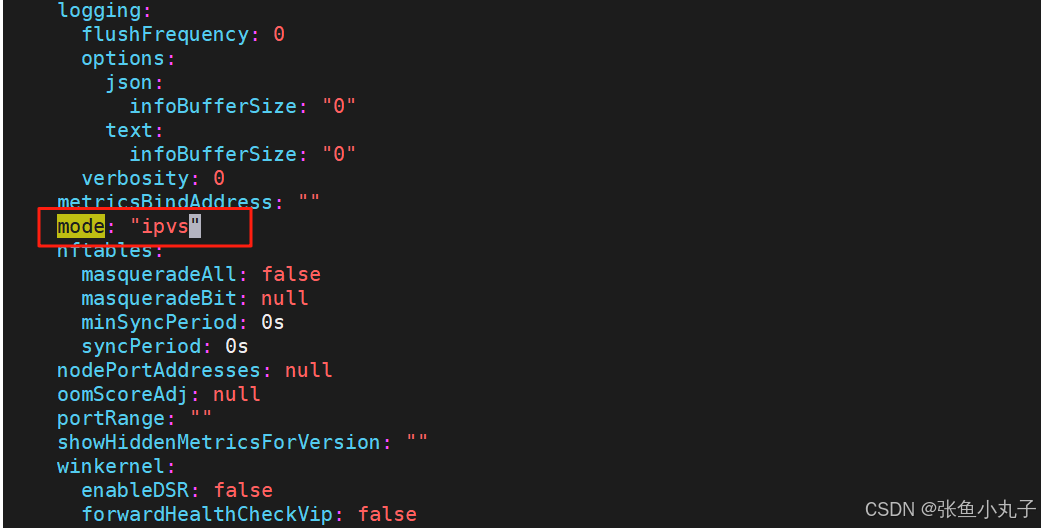
重启pod,在pod运行时配置文件中采用默认配置,当改变配置文件后已经运行的pod状态不会变化,所以要重启pod
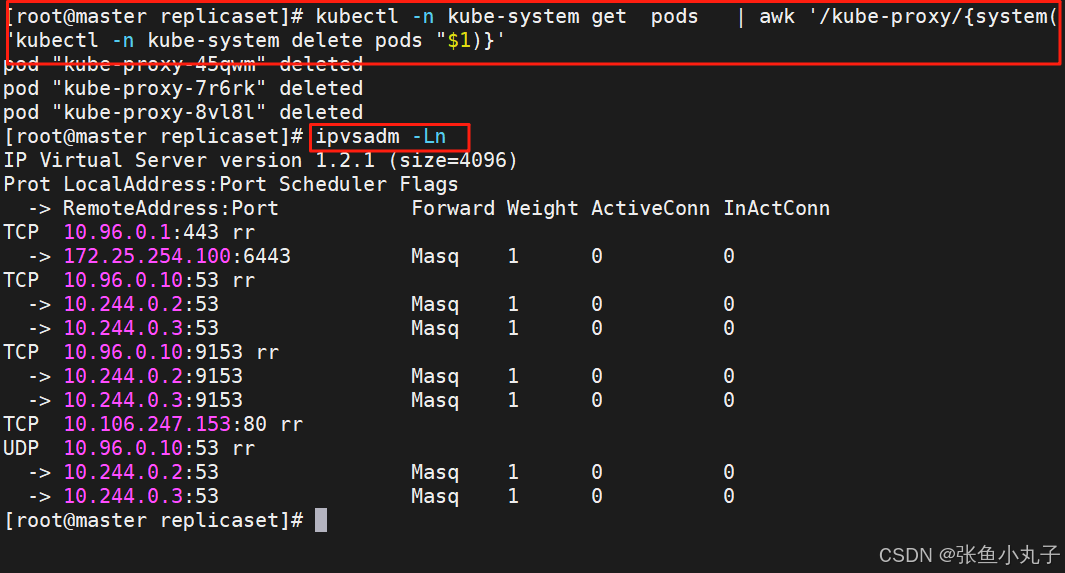
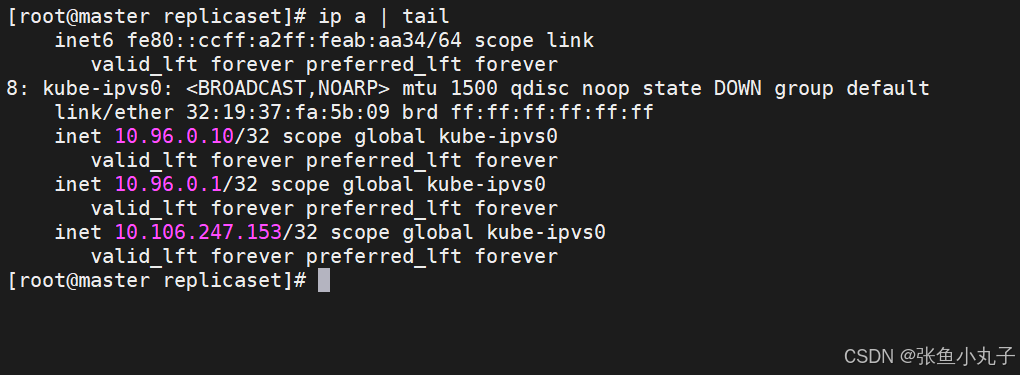
切换ipvs模式后,kube-proxy会在宿主机上添加一个虚拟网卡:kube-ipvs0,并分配所有service IP
12. 微服务类型详解
12.1 clusterip
特点:
clusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功
编辑配置文件
[root@master replicaset]# vim myapp.yml
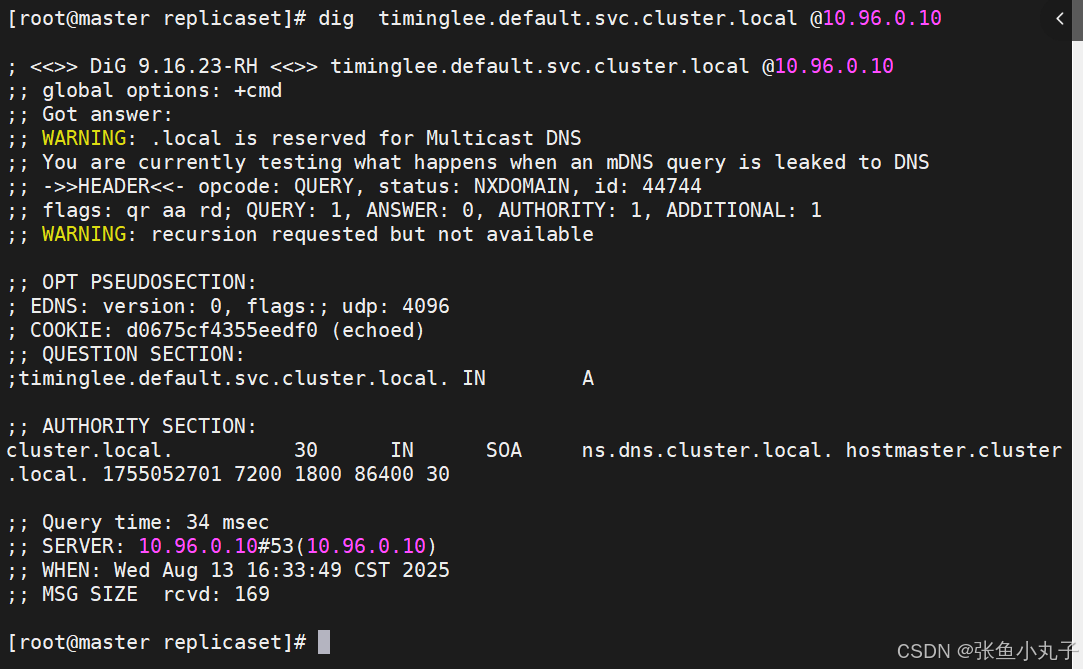
service创建后集群DNS提供解析
12.2 ClusterIP中的特殊模式headless
headless(无头服务)
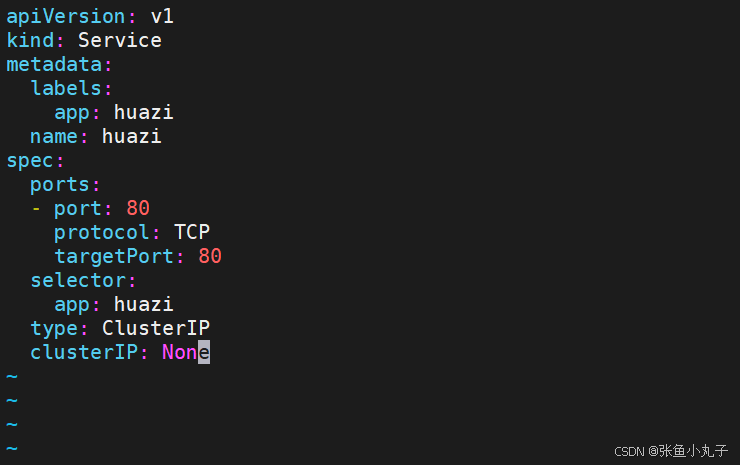
对于无头
Services并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度有dns单独完
修改配置文件
[root@master replicaset]# vim hauzi.yaml
应用
[root@master replicaset]# kubectl apply -f timinglee.yaml![]()
测试
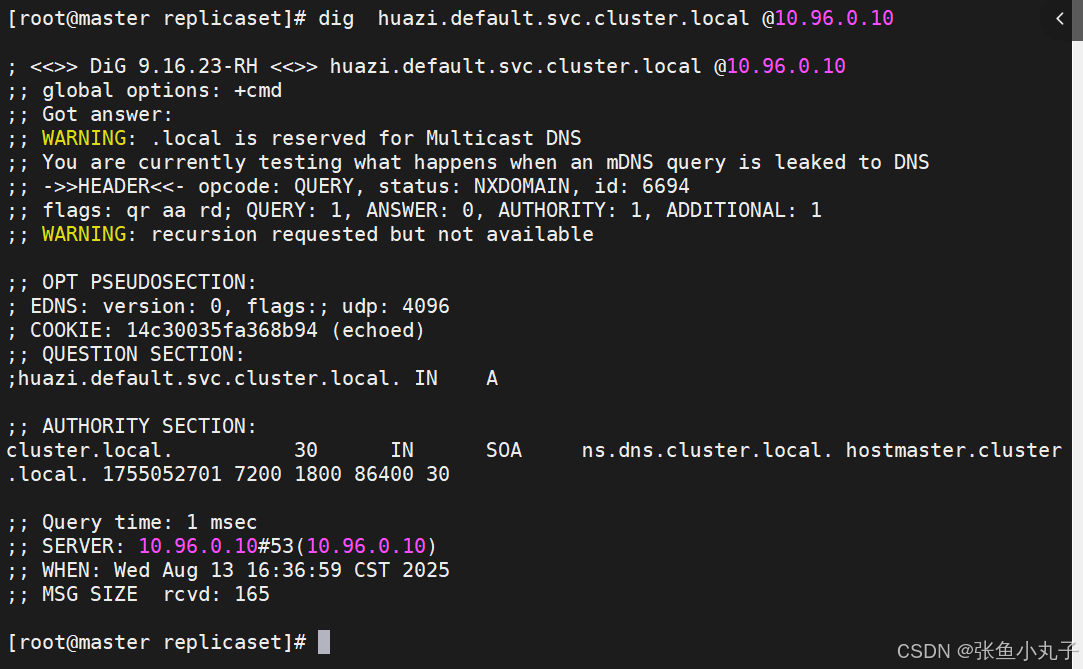
12.3 nodeport
通过ipvs暴漏端口从而使外部主机通过master节点的对外ip:<port>来访问pod业务
其访问过程为:
编辑配置
[root@master replicaset]# kubectl apply -f huazi.yaml
[root@master replicaset]# kubectl get services huazi-service12.4 loadbalancer
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配
![]()
改配置文件
应用
[root@master replicaset]# kubectl apply -f myapp.yml
默认无法分配外部访问IP
LoadBalancer模式适用云平台,裸金属环境需要安装metallb提供支持

12.5 metalLB
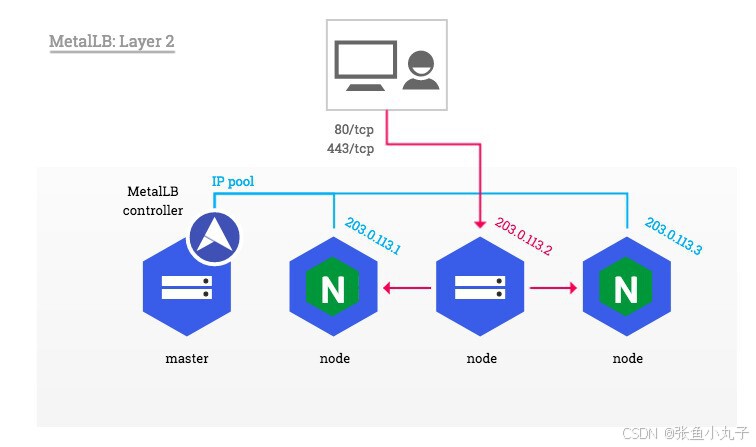
metalLB功能:为LoadBalancer分配vip
设置ipvs模式

上传harbor仓库
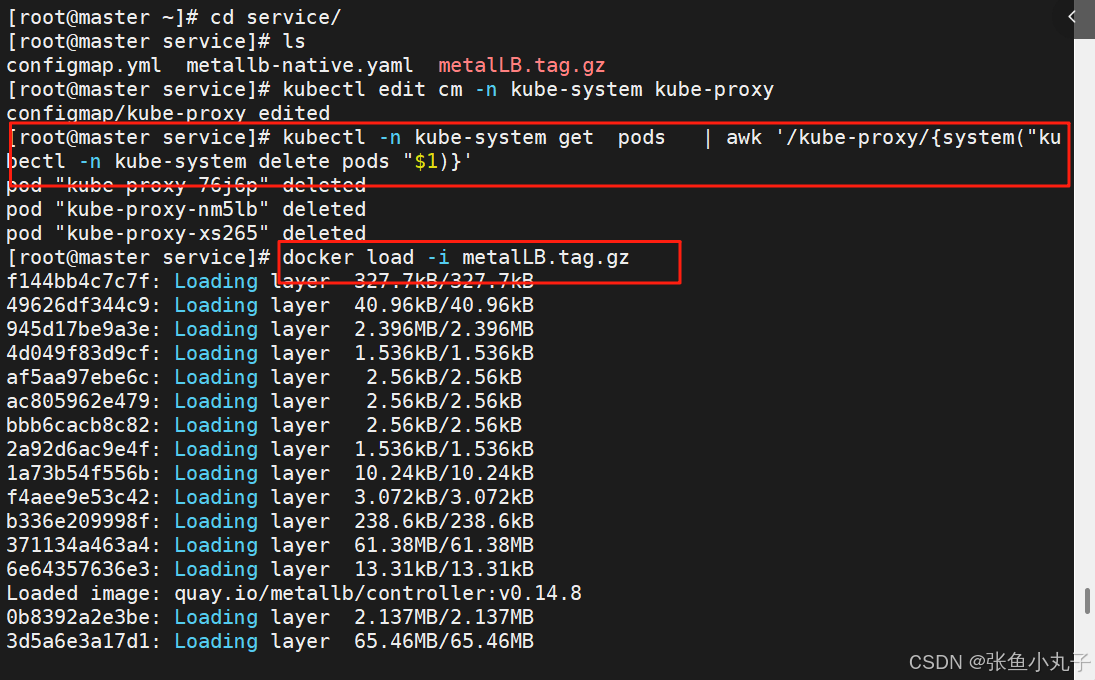
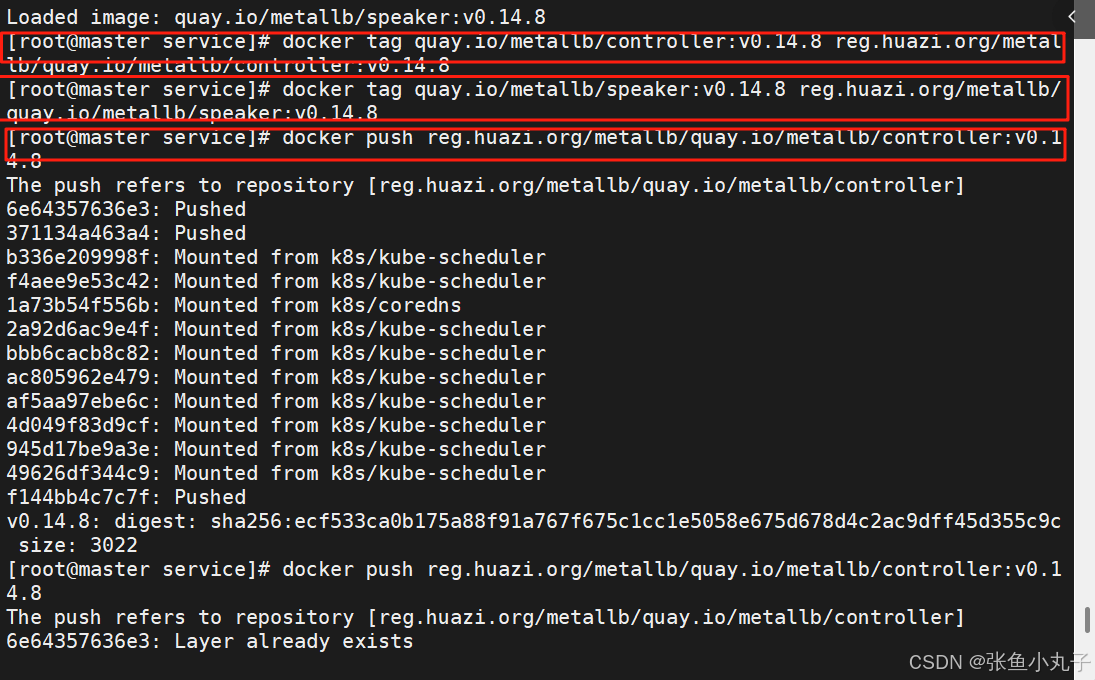
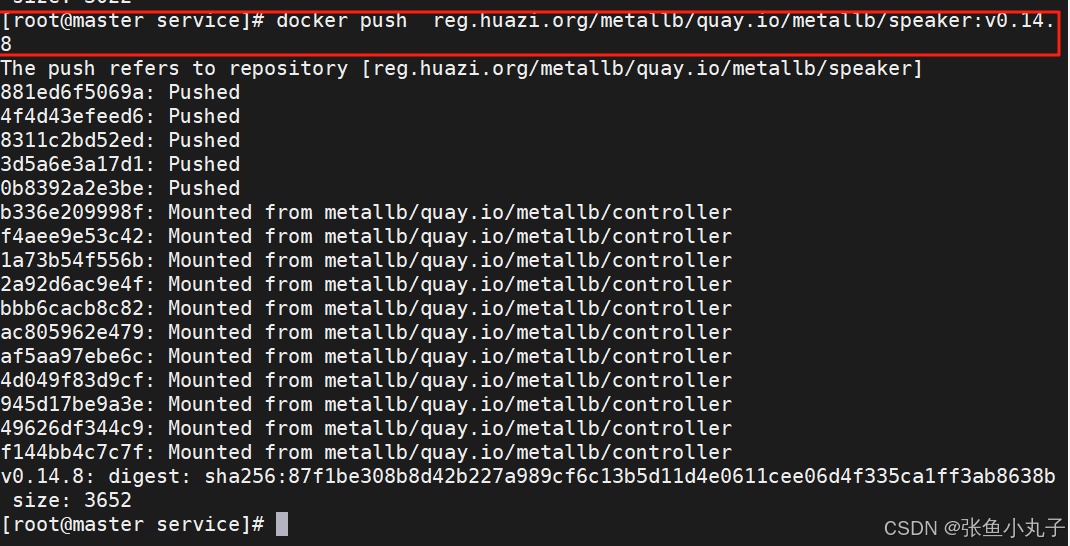
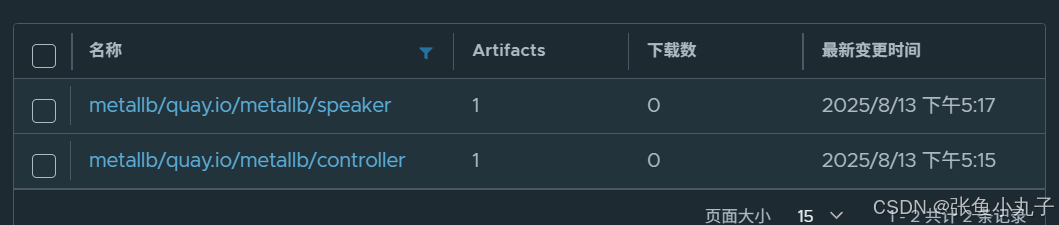
部署服务
配置分配地址段
[root@master service]# vim configmap.yml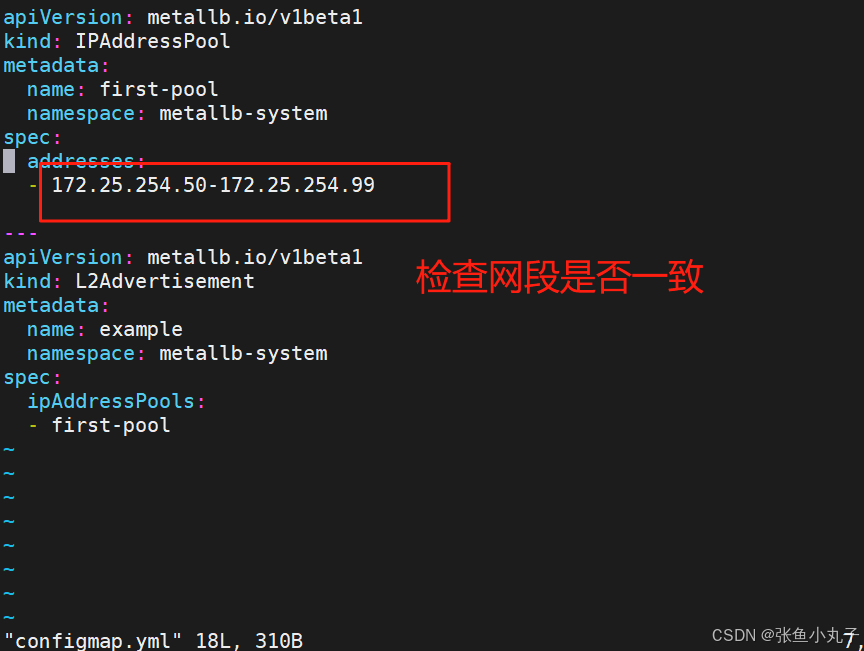
12.6 externalname
-
开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
-
一般应用于外部业务和pod沟通或外部业务迁移到pod内时
-
在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
-
集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
修改配置文件
[root@master ~]# vim huazi.yaml
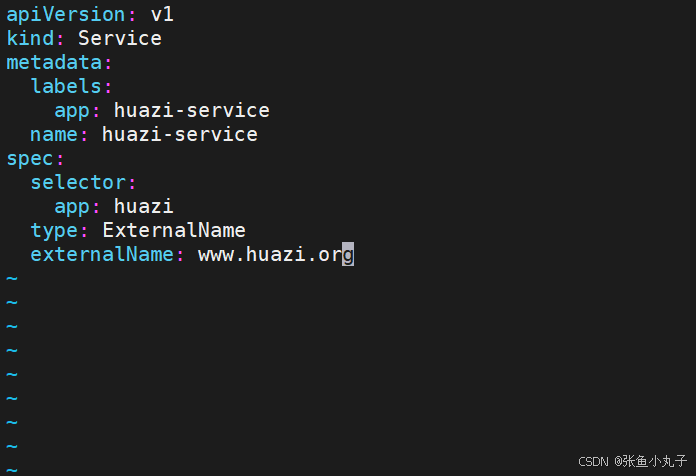
[root@master ~]# kubectl apply -f huazi.yaml
[root@master ~]# kubectl get services huazi-service
13. Ingress-nginx
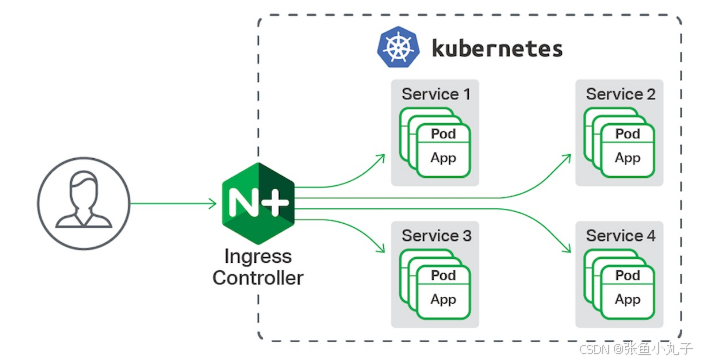
-
一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
-
Ingress由两部分组成:Ingress controller和Ingress服务
-
Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
-
业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
13.1 安装
上传镜像
查看
安装ingress
查看


修改微服务为loadbalancer

查看

在ingress-nginx-controller中看到的对外IP就是ingress最终对外开放的ip
生成yaml文件

[root@master ingress]# vim huazi-ingress.yml
建立ingress控制器
[root@master ingress]# kubectl apply -f huazi-ingress.yml
13.2 ingress 的高级用法
13.2.1. 基于路径的访问
建立用于测试的控制器myapp


[root@master ingress]# vim myappv1.yaml
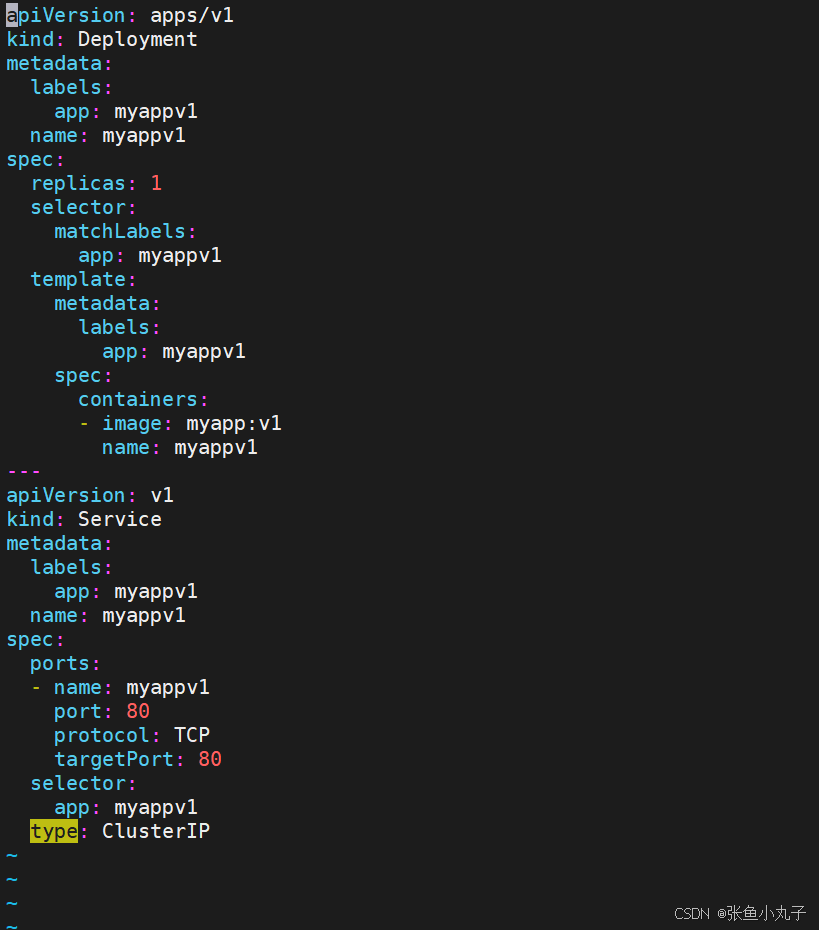
[root@master ingress]# vim myappv2.yaml
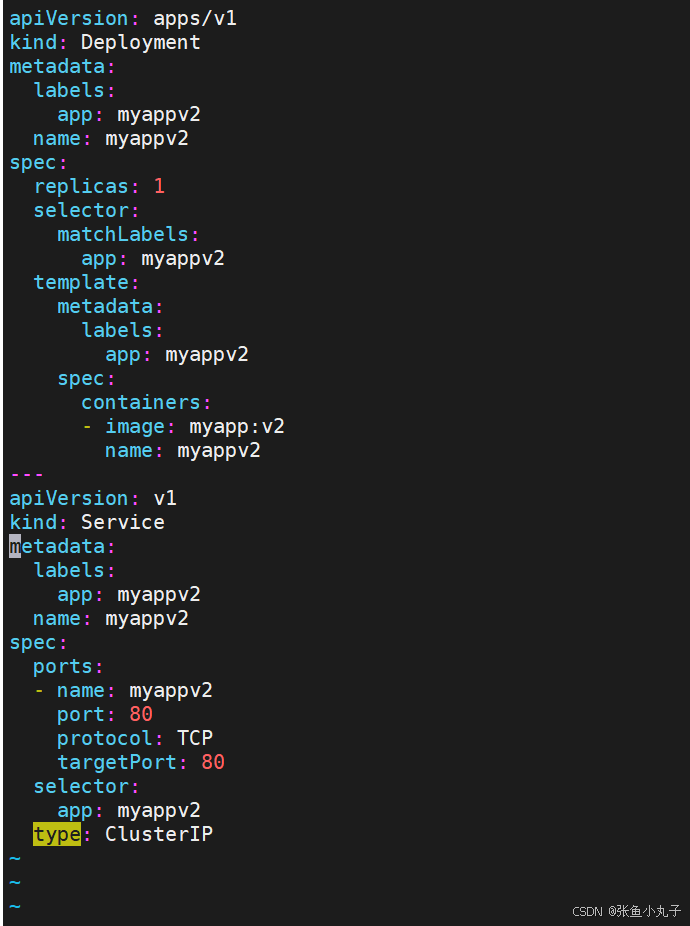
应用

暴露端口


建立ingress的yaml
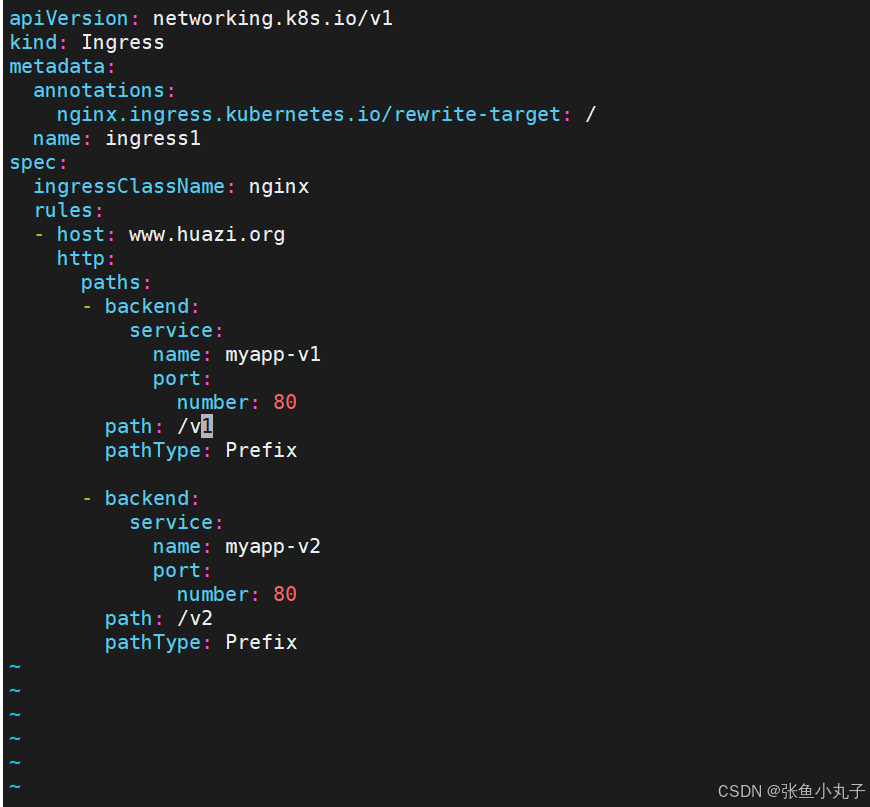

13.2.2. 基于域名的访问
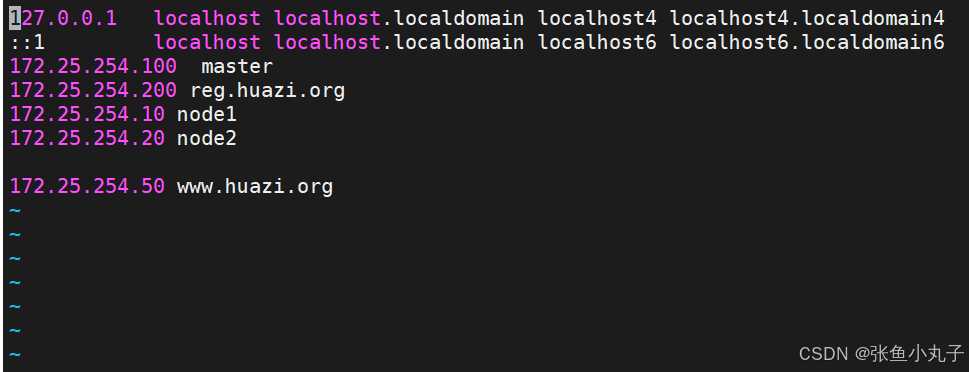
在主机中设定解析
[root@master ingress]# vi /etc/hosts
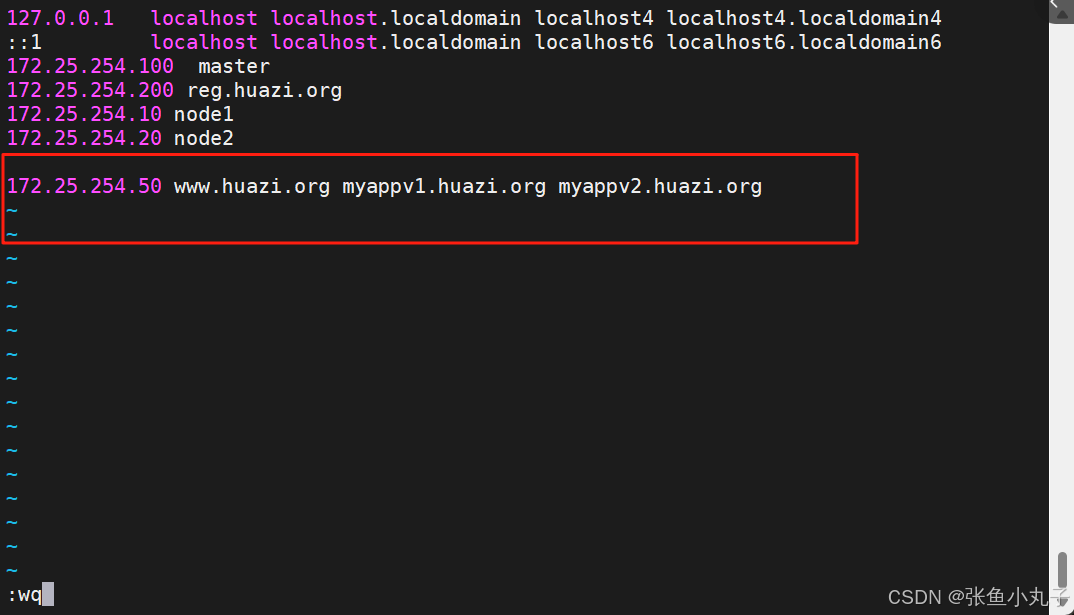
建立基于域名的yml文件
[root@master ingress]# vim ingress2.yml
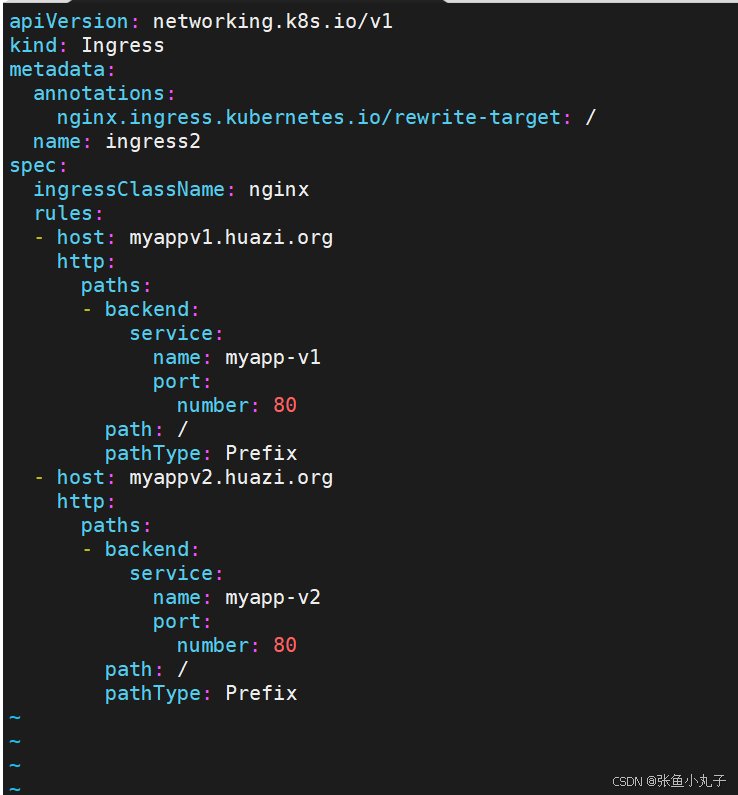
建立ingress
[root@master ingress]# kubectl apply -f ingress2.yml
[root@master ingress]# kubectl describe ingress ingress2
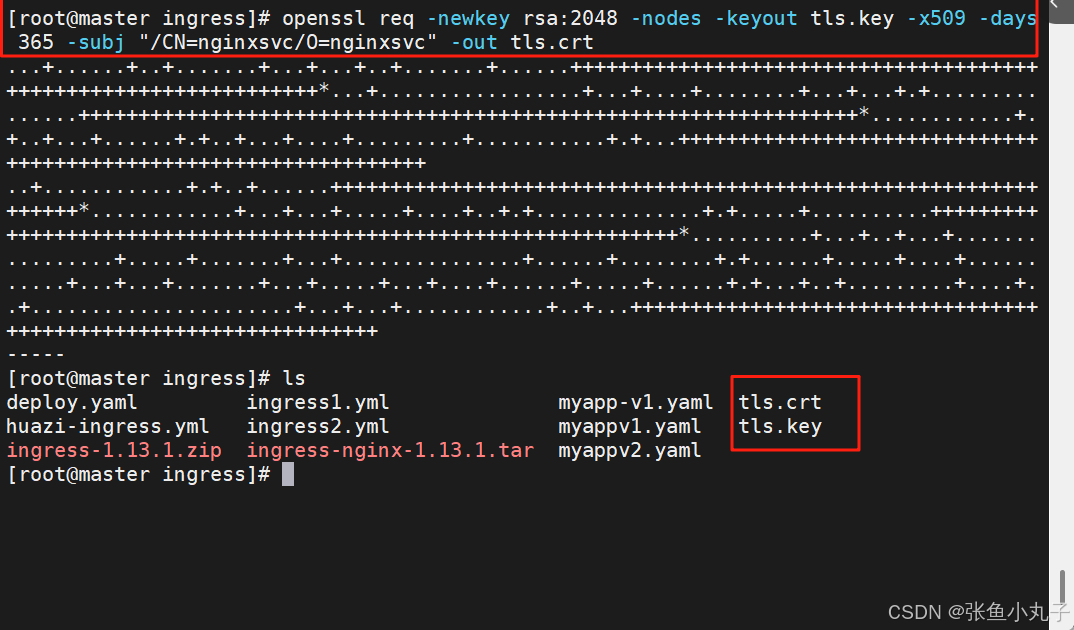
13.2.3 建立tls加密
建立证书
创建加密资源类型secret
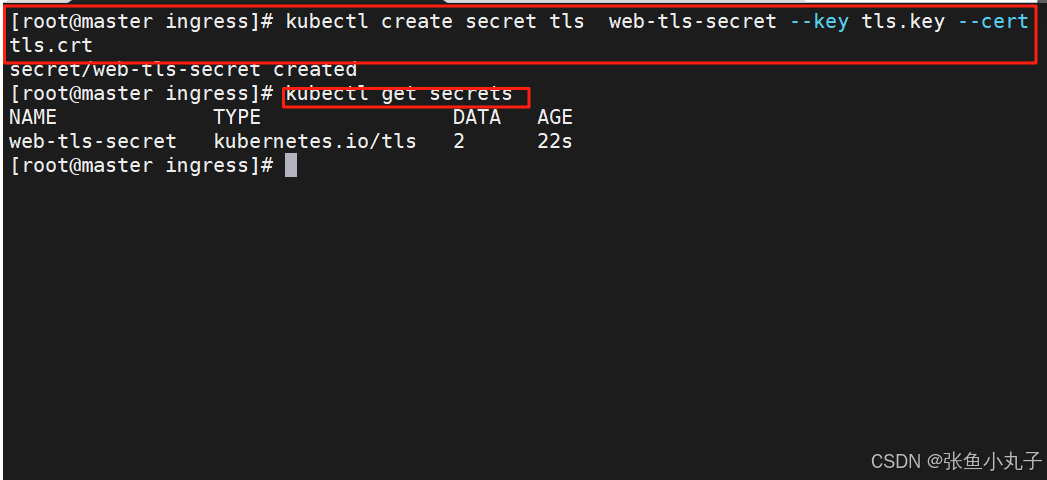
secret通常在kubernetes中存放敏感数据,他并不是一种加密方式
建立ingress3基于tls认证的yml文件
[root@master ingress]# vim ingress3.yml
[root@master ingress]# curl -k https://myapp-tls.huazi.org13.2.4 建立auth认证
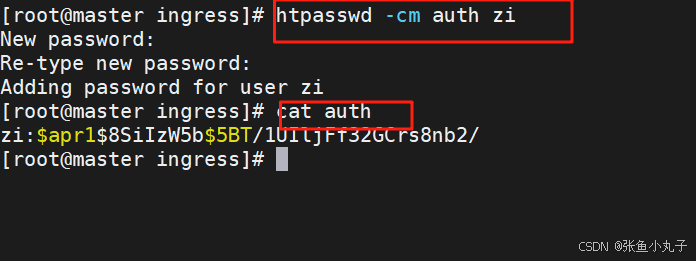
建立认证文件
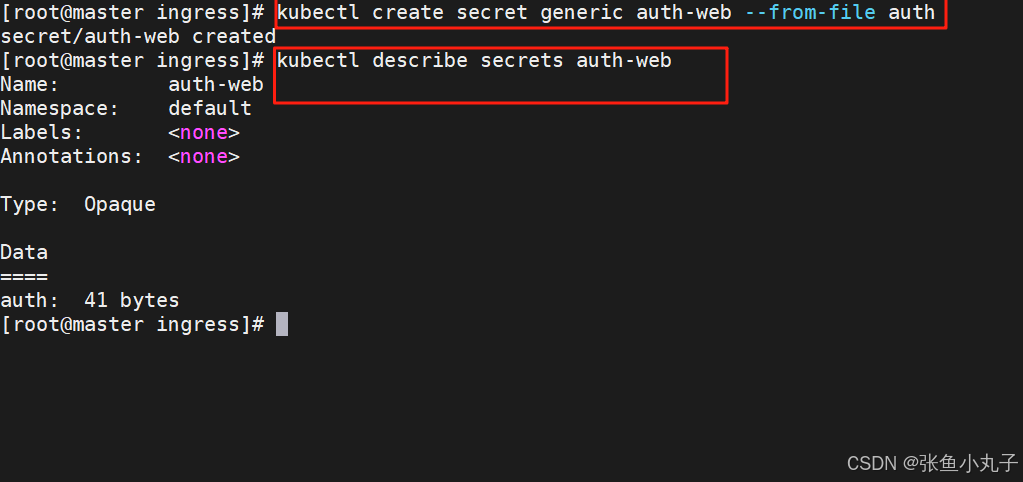
建立认证类型资源
创建ingress4基于用户认证的yaml文件
[root@master ingress]# vim ingress4.yml
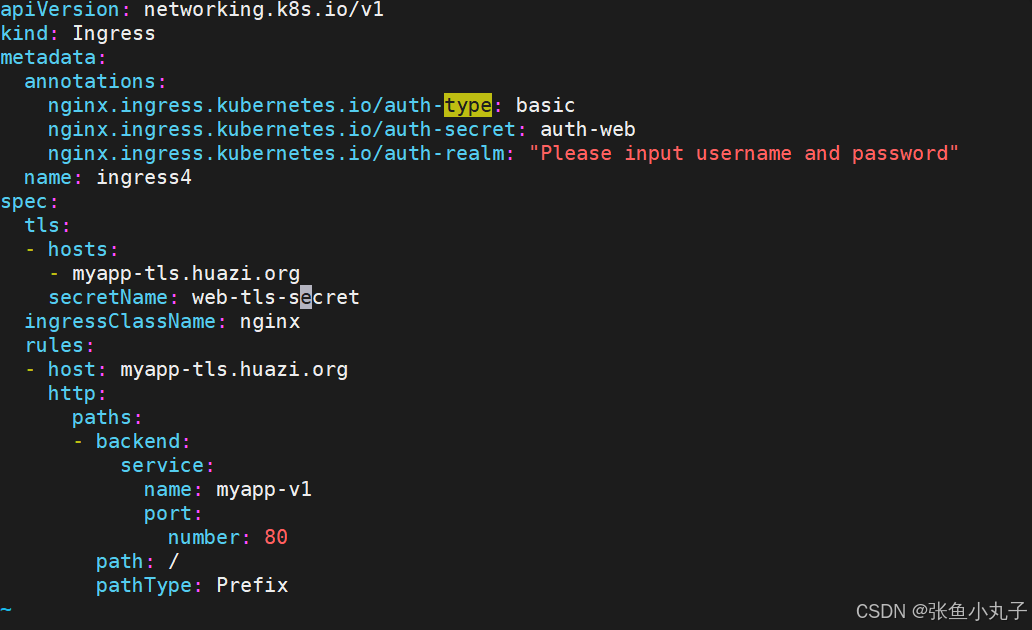
建立ingress4
[root@master ingress]# kubectl apply -f ingress4.yml
[root@k8s-master app]# kubectl describe ingress ingress4
Name: ingress4
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
TLS:
web-tls-secret terminates myapp-tls.huazi.org
Rules:
Host Path Backends
---- ---- --------
myapp-tls.huazi.org
/ myapp-v1:80 (10.244.2.31:80)
Annotations: nginx.ingress.kubernetes.io/auth-realm: Please input username and password
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-type: basic
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 14s nginx-ingress-controller Scheduled for sync13.2.5 rewrite重定向
指定默认访问的文件到hostname.html上
[root@master ingress]# vim ingress5.yml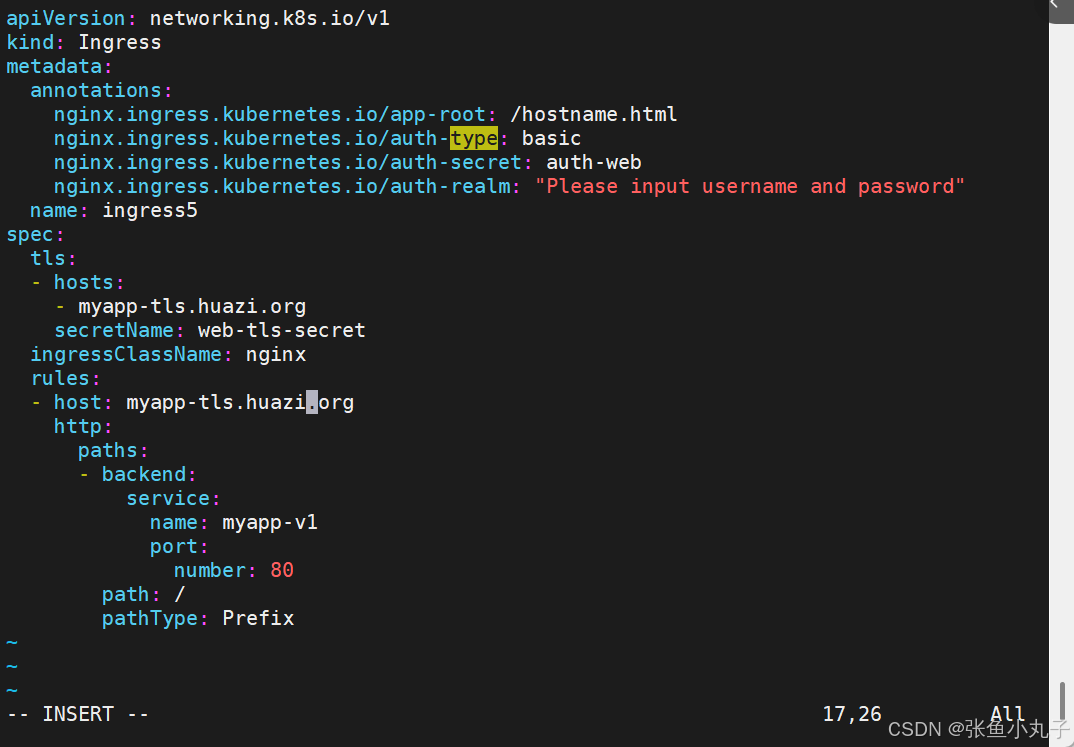
[root@master ingress]# kubectl apply -f ingress5.yml
[root@master ingress]# kubectl describe ingress ingress5
Name: ingress5
Labels: <none>
Namespace: default
Address: 172.25.254.10
Ingress Class: nginx
Default backend: <default>
TLS:
web-tls-secret terminates myapp-tls.huazi.org
Rules:
Host Path Backends
---- ---- --------
myapp-tls.timinglee.org
/ myapp-v1:80 (10.244.2.31:80)
Annotations: nginx.ingress.kubernetes.io/app-root: /hostname.html
nginx.ingress.kubernetes.io/auth-realm: Please input username and password
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-type: basic
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 2m16s (x2 over 2m12s) nginx-ingress-controller Scheduled for sync14. Canary金丝雀发布
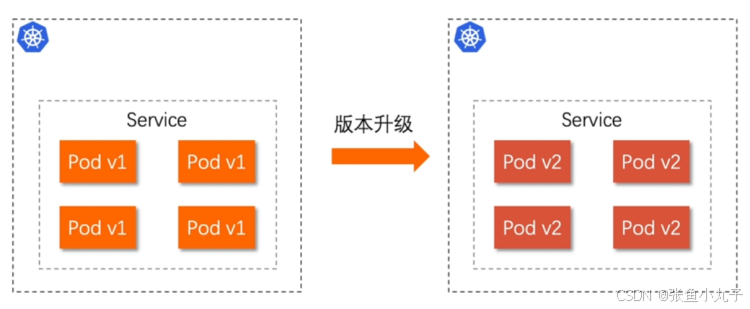
什么是金丝雀发布?
金丝雀发布(Canary Release)也称为灰度发布,是一种软件发布策略。
主要目的是在将新版本的软件全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证,以降低因新版本引入重大问题而对整个系统造成的影响。
是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
Canary发布方式
其中header和weiht中的最多
14.1 基于header(http包头)灰度
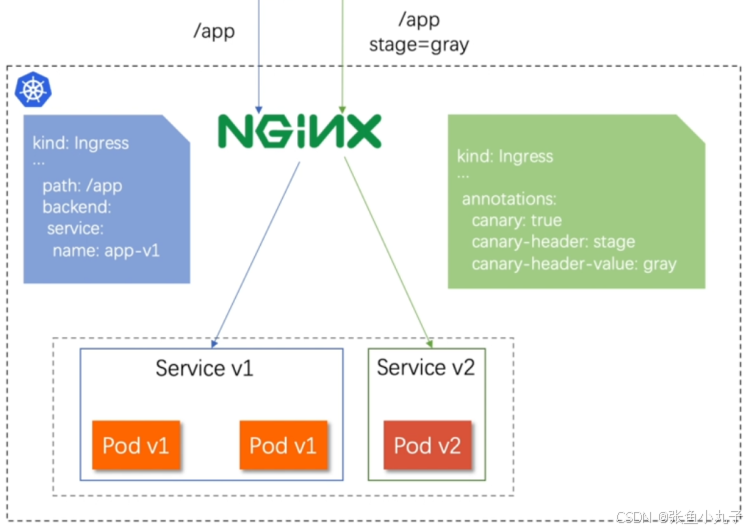
-
通过Annotaion扩展
-
创建灰度ingress,配置灰度头部key以及value
-
灰度流量验证完毕后,切换正式ingress到新版本
-
之前我们在做升级时可以通过控制器做滚动更新,默认25%利用header可以使升级更为平滑,通过key 和vule 测试新的业务体系是否有问题。
编辑配置文件
[root@master ingress]# vim ingress7.yml
[root@master ingress]# kubectl describe ingress myapp-v1-ingress
Name: myapp-v1-ingress
Labels: <none>
Namespace: default
Address: 172.25.254.10
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
myapp.huazi.org
/ myapp-v1:80 (10.244.2.31:80)
Annotations: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 44s (x2 over 73s) nginx-ingress-controller Scheduled for sync编辑header的配置文件
[root@master ingress]# vim ingress8.yml
[root@master ingress]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created
[root@master ingress]# kubectl describe ingress myapp-v2-ingress
Name: myapp-v2-ingress
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
myapp.huazi.org
/ myapp-v2:80 (10.244.2.32:80)
Annotations: nginx.ingress.kubernetes.io/canary: true
nginx.ingress.kubernetes.io/canary-by-header: version
nginx.ingress.kubernetes.io/canary-by-header-value: 2
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 21s nginx-ingress-controller Scheduled for sync14.2 基于权重的灰度发布
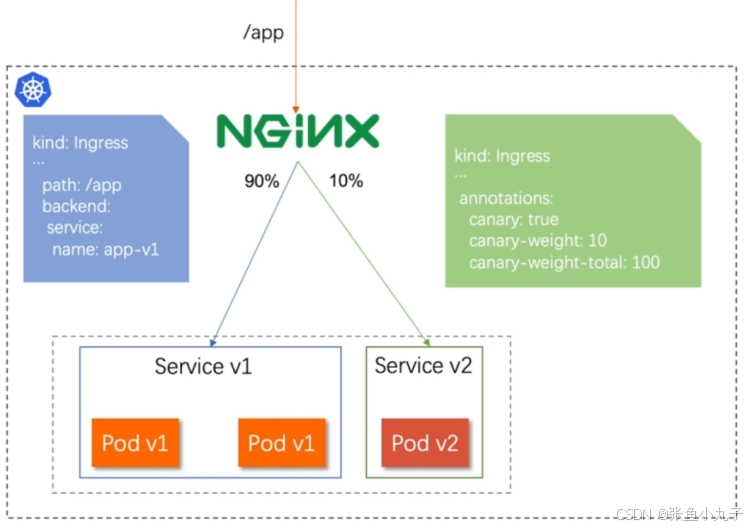
-
通过Annotaion拓展
-
创建灰度ingress,配置灰度权重以及总权重
-
灰度流量验证完毕后,切换正式ingress到新版本
编辑权重灰度发布的配置文件
[root@master ingress]# vim ingress8.yml
编写一个测试脚本
[root@master ingress]# vim check_ingress.sh
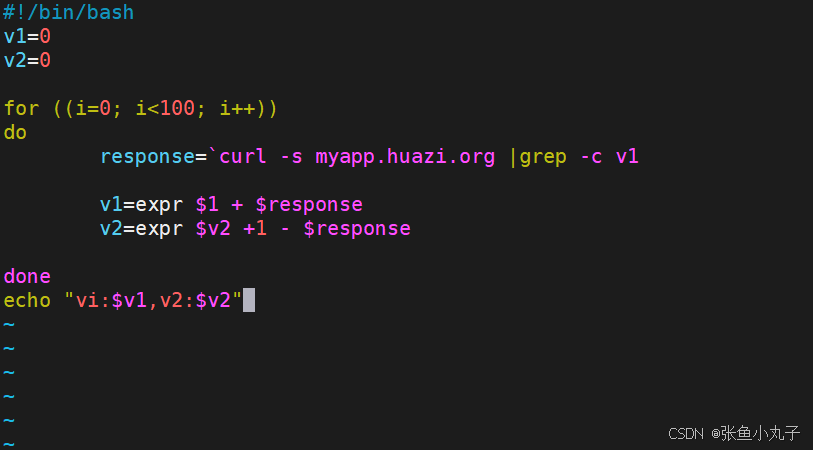
[root@master ingress]# sh check_ingress.sh
v1:90, v2:10更改完毕权重后继续多次测试可观察不同变化
14.3 无头服务
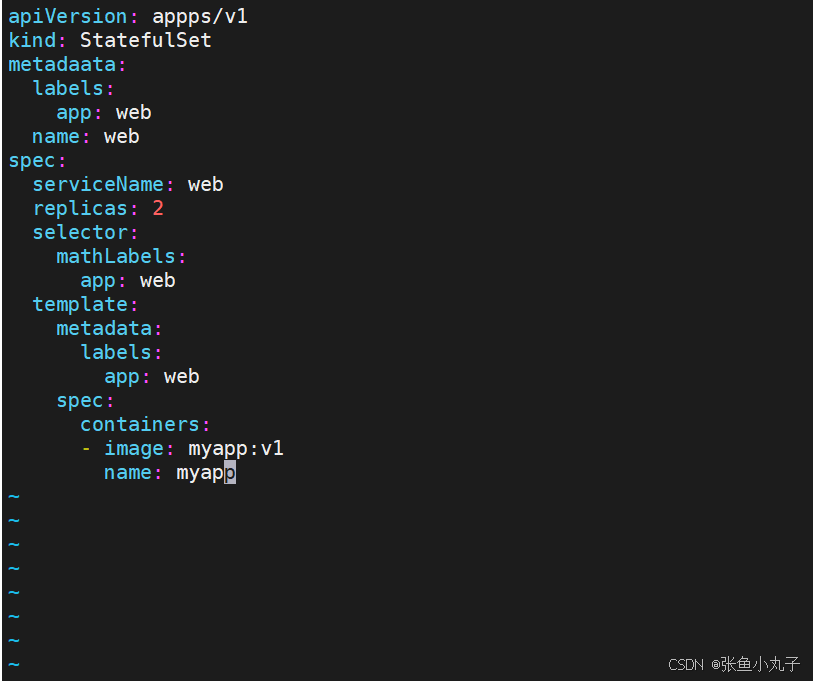
statefulset控制器
[root@master ~]# vim web.yml
无头服务配置文件
[root@master ~]# vim service.yml
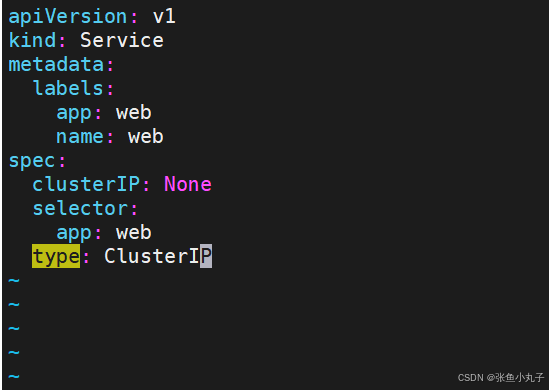
(reverse-i-search)`dig`: `dig web-0.web.default.svc.cluster.local. @10.96.0.10`
`pod名称` 指向 `web-0` 、`微服务名` 指向 `web` 、`命名空间` 指向 `default` 、`服务类型` 指向 `svc` ,整体域名格式遵循 Kubernetes 集群内部服务发现的规范 ,`cluster.local` 是集群默认域名后缀 15. configmap
configmap的功能
configMap用于保存配置数据,以键值对形式存储。
configMap 资源提供了向 Pod 注入配置数据的方法。
镜像和配置文件解耦,以便实现镜像的可移植性和可复用性。
etcd限制了文件大小不能超过1M
configmap的使用场景
填充环境变量的值
设置容器内的命令行参数
填充卷的配置文件
15.1 configmap创建方式
15.1.1 字面值创建
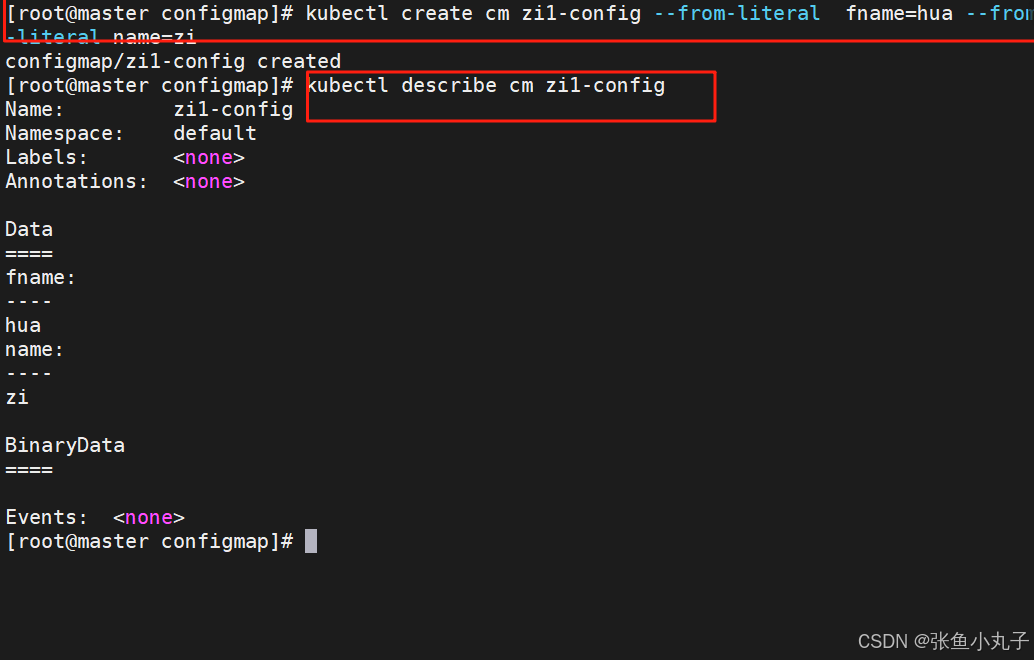
15.1.2 通过文件创建
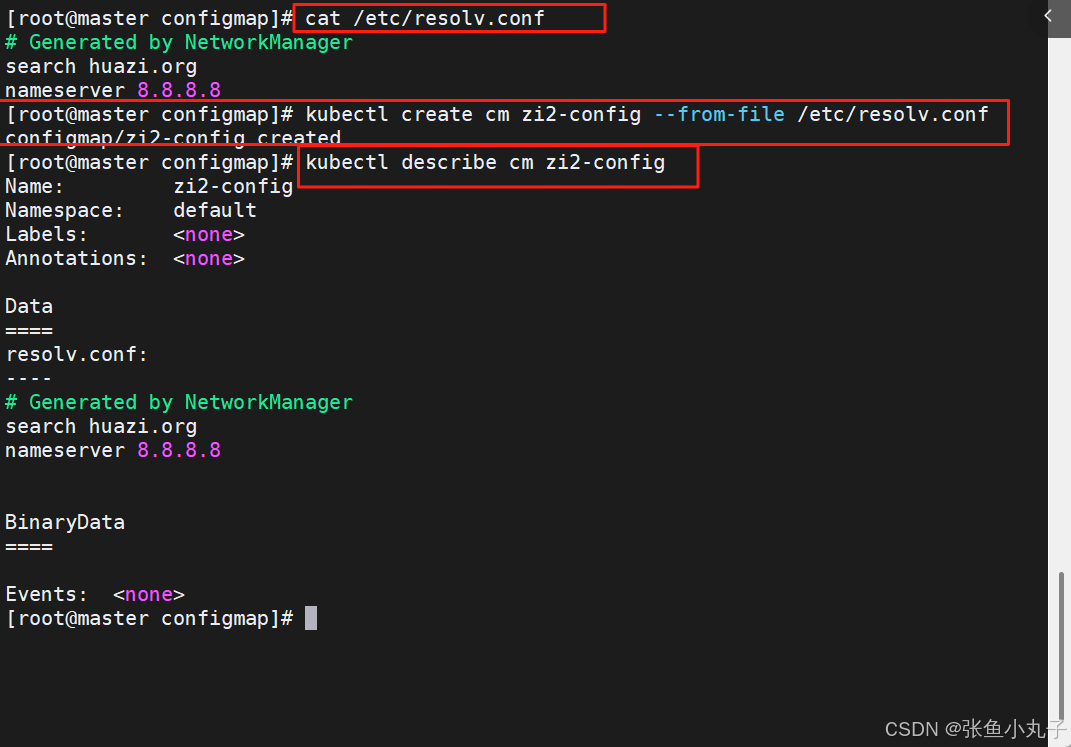
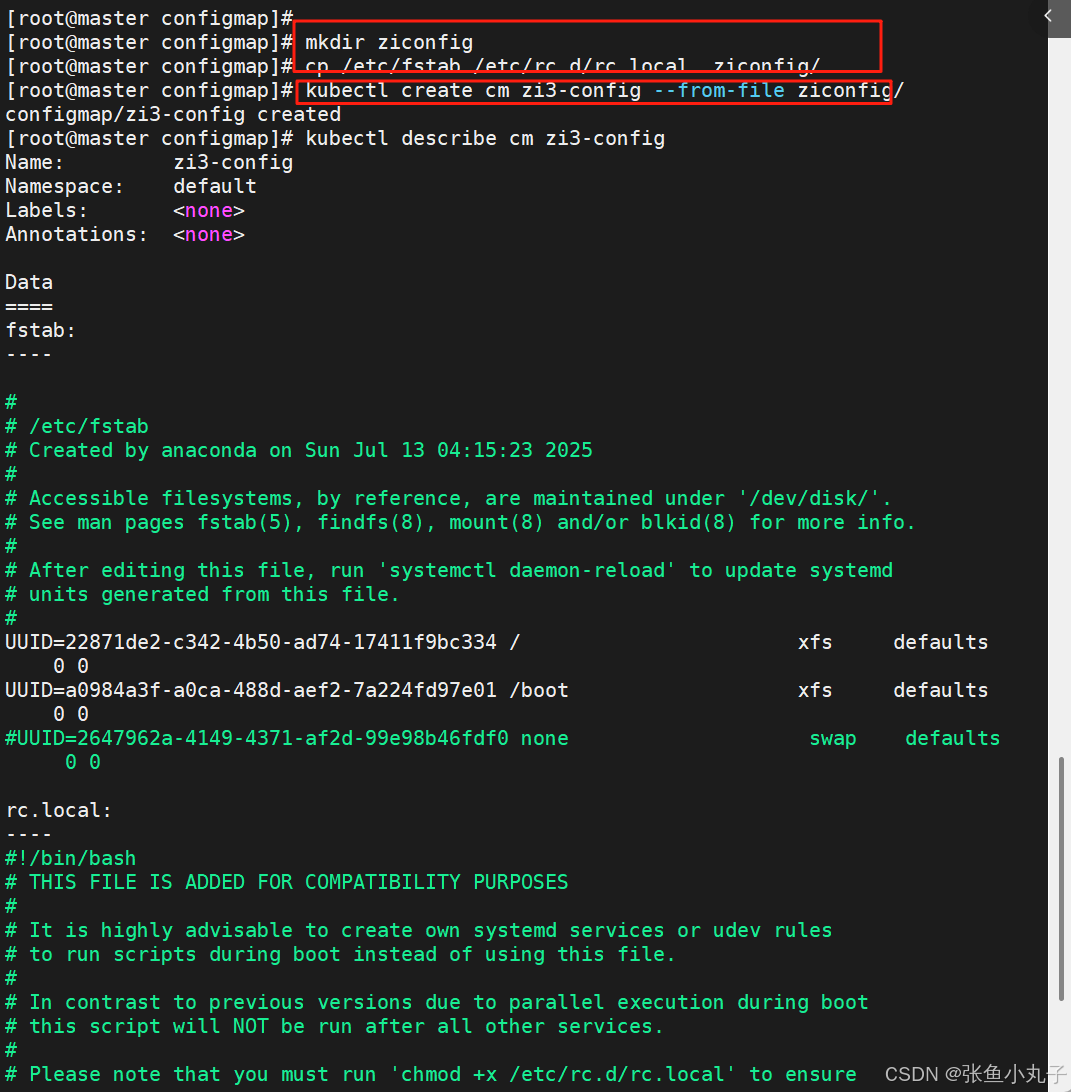
15.1.3 通过目录创建
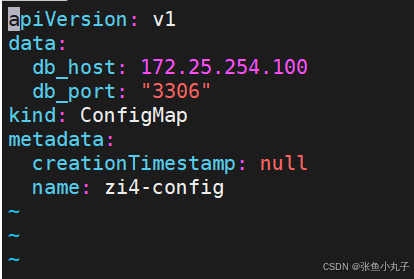
15.1.4 通过yaml文件创建

15.1.5 configmap的使用方式
-
通过环境变量的方式直接传递给pod
-
通过pod的 命令行运行方式
-
作为volume的方式挂载到pod内
把三个压缩包上传到mnt下面

加载
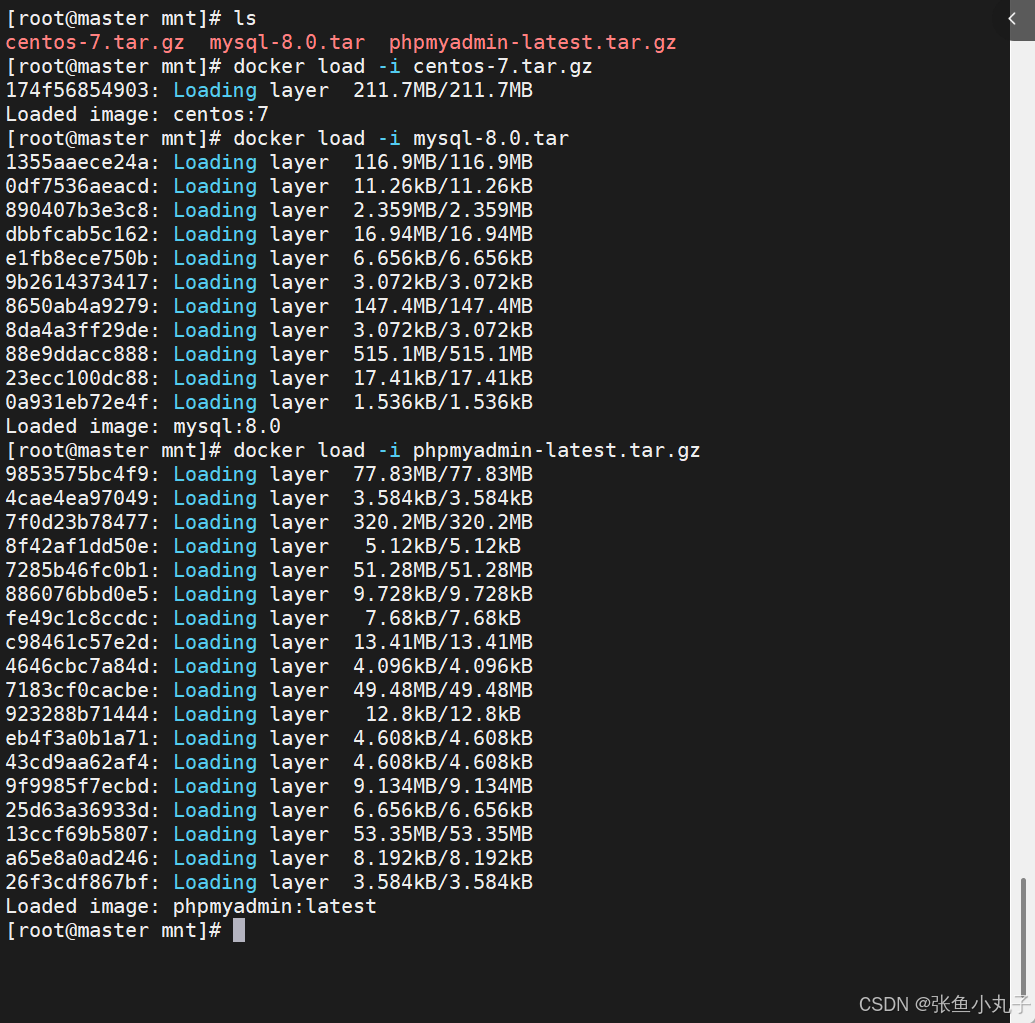
把他们上传到harbor仓库中

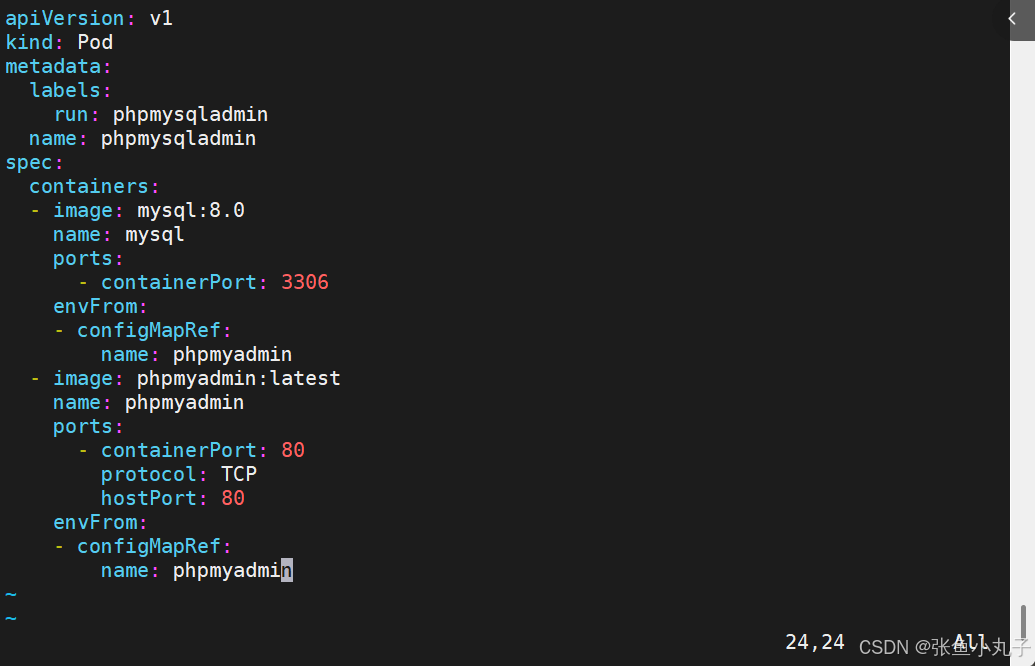
编辑配置文件
[root@master configmap]# vim phpmyadmin.yml
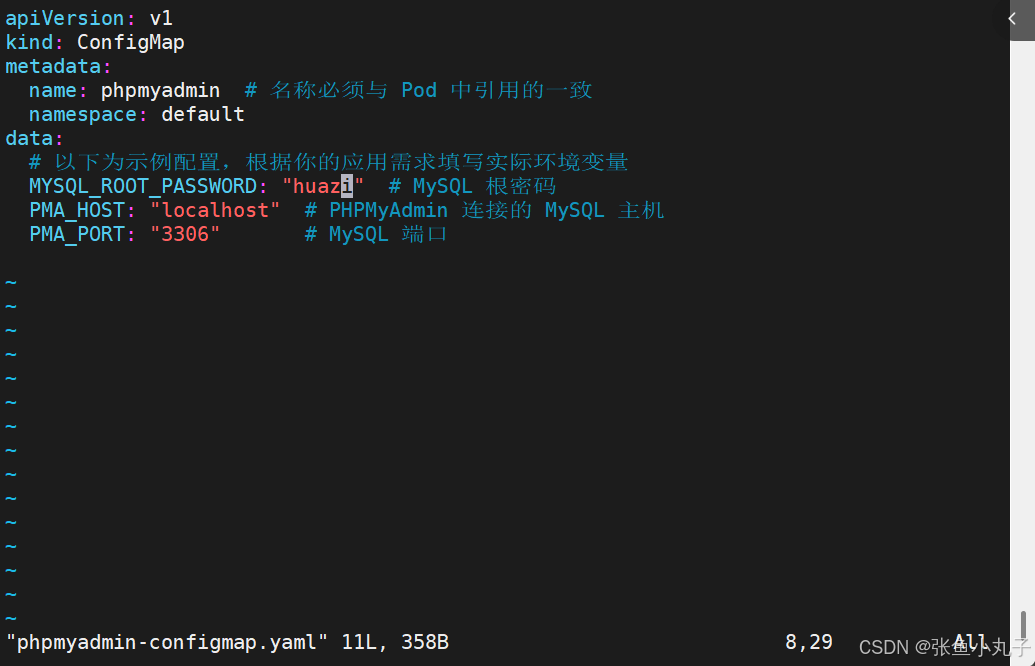
编辑configmap的配置文件
[root@master configmap]# vim phpmyadmin-configmap.yaml
应用
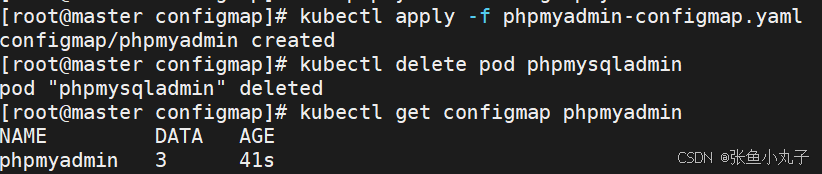
查看日志
为 phpmysqladmin 创建 Service 暴露端口
创建一个yaml文件
[root@master configmap]# vim phpmyadmin-svc.yaml
应用 Service 配置

获取映射的节点端口

访问 phpmyadmin 服务
在浏览器访问phpMyAdmin![]() http://172.25.254.20:32017/
http://172.25.254.20:32017/
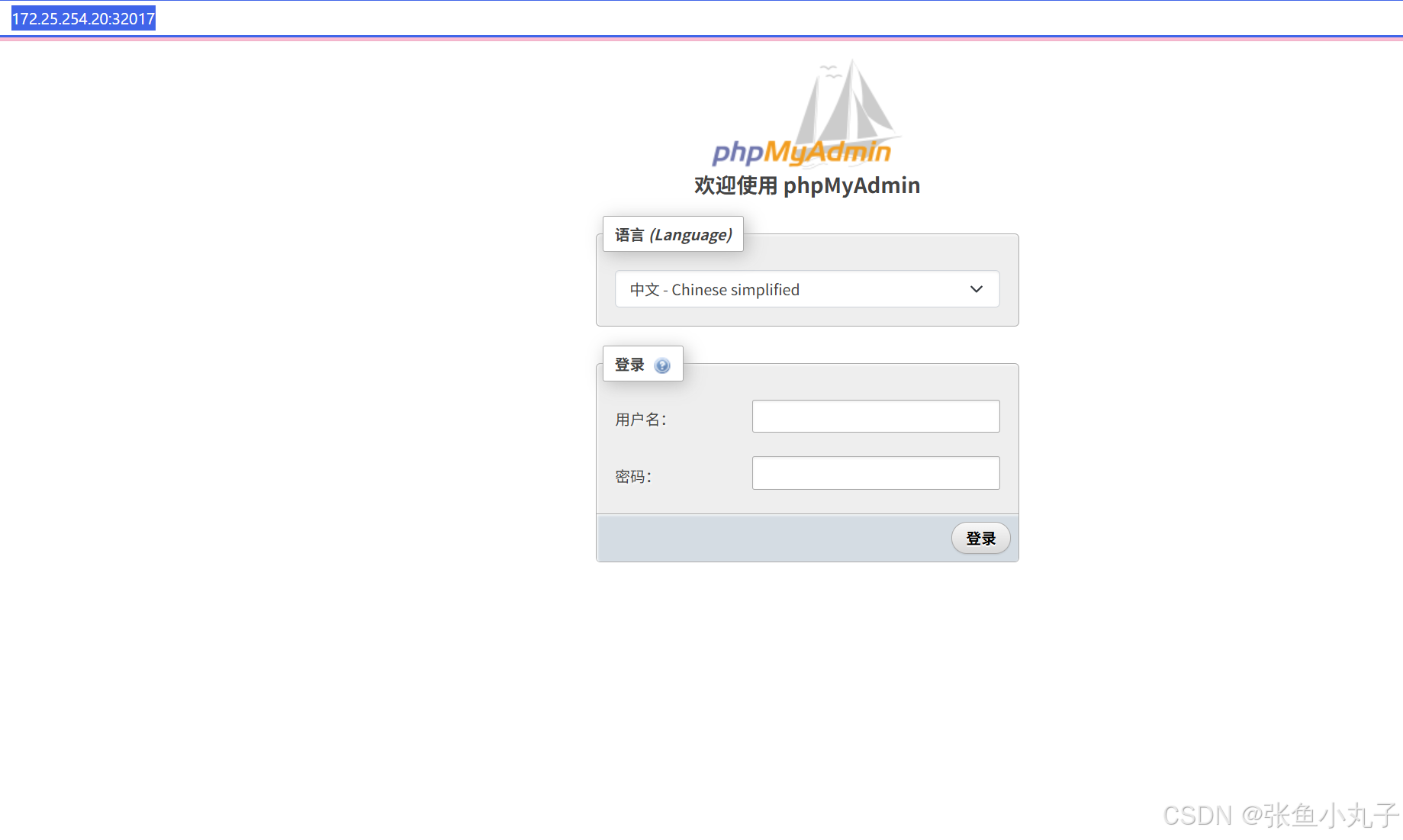
查看密码,用户名一般是root(超级用户)
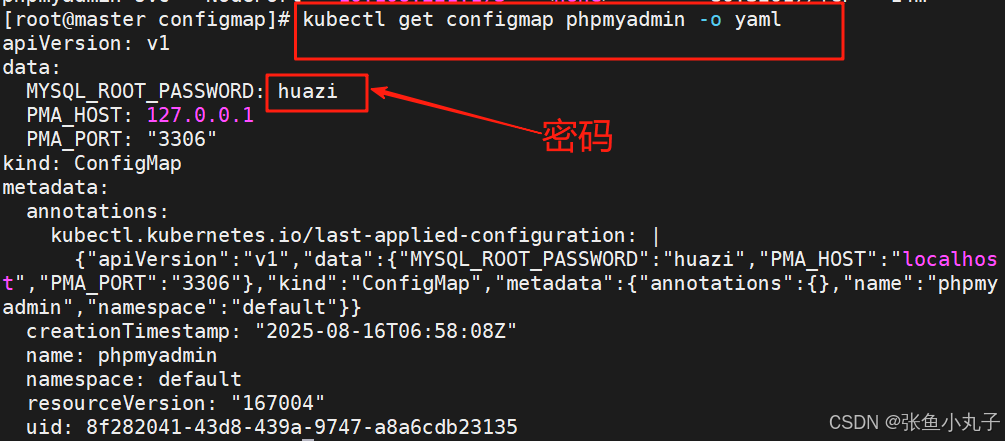
输入登录即可
利用configMap填充pod的配置文件
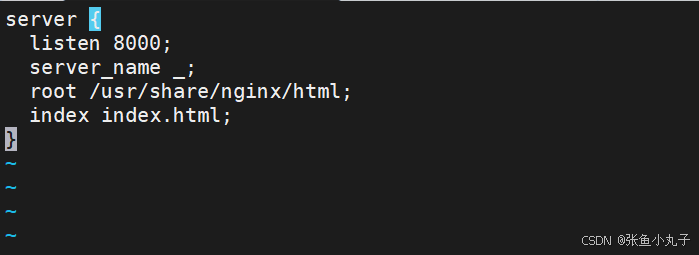
建立配置文件模板
[root@master configmap]# vim nginx,conf
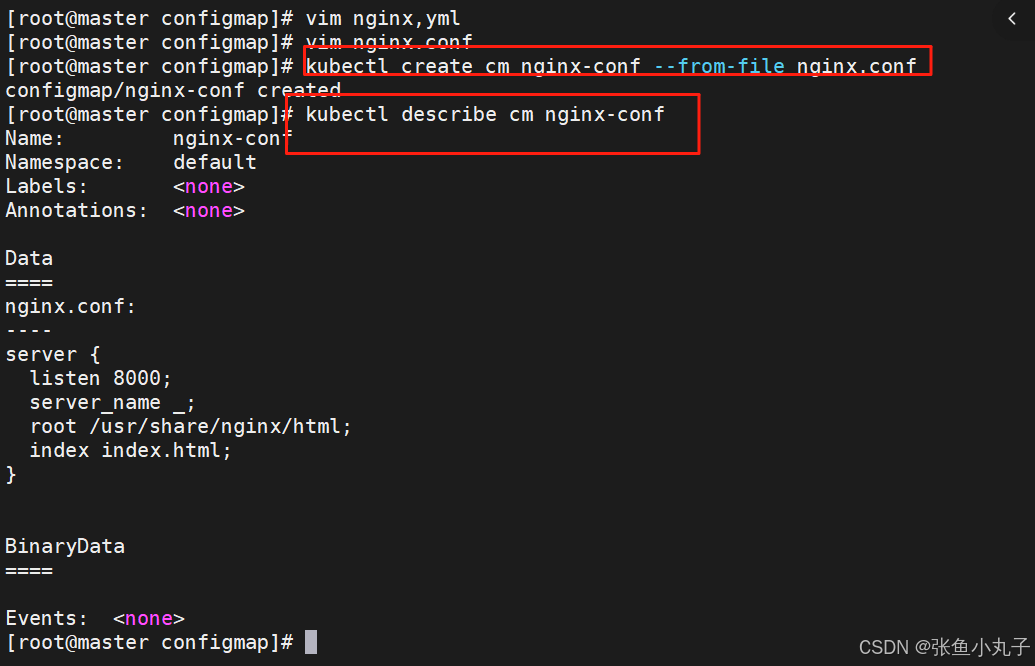
利用模板生成cm
建立nginx控制器文件

设定nginx.yml中的卷
[root@master configmap]# vim nginx.yml
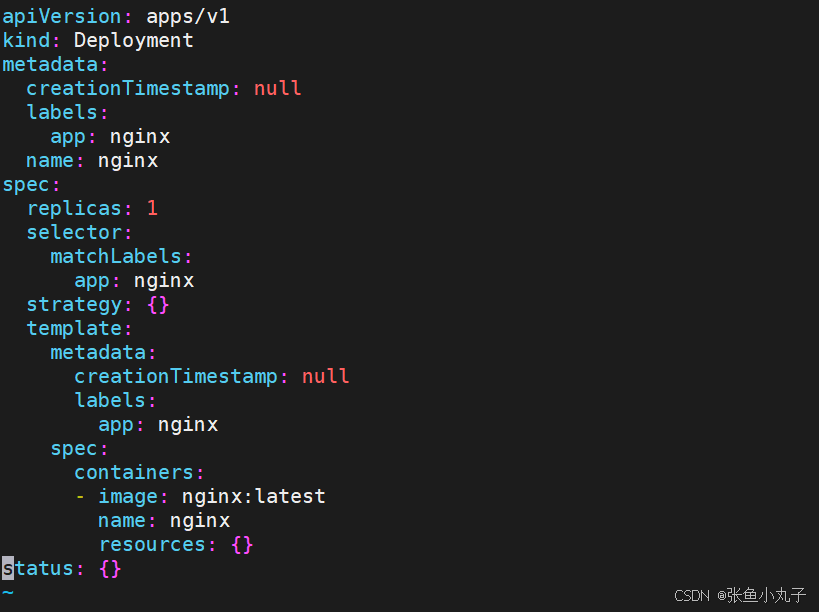
16. secrets配置管理
ecrets的功能介绍
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 ssh key。
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活
Pod 可以用两种方式使用 secret:
作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里。
当 kubelet 为 pod 拉取镜像时使用。
Secret的类型:
Service Account:Kubernetes 自动创建包含访问 API 凭据的 secret,并自动修改 pod 以使用此类型的 secret。
Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,因此安全性弱。
kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息
16.1 secrets创建
从文件创建
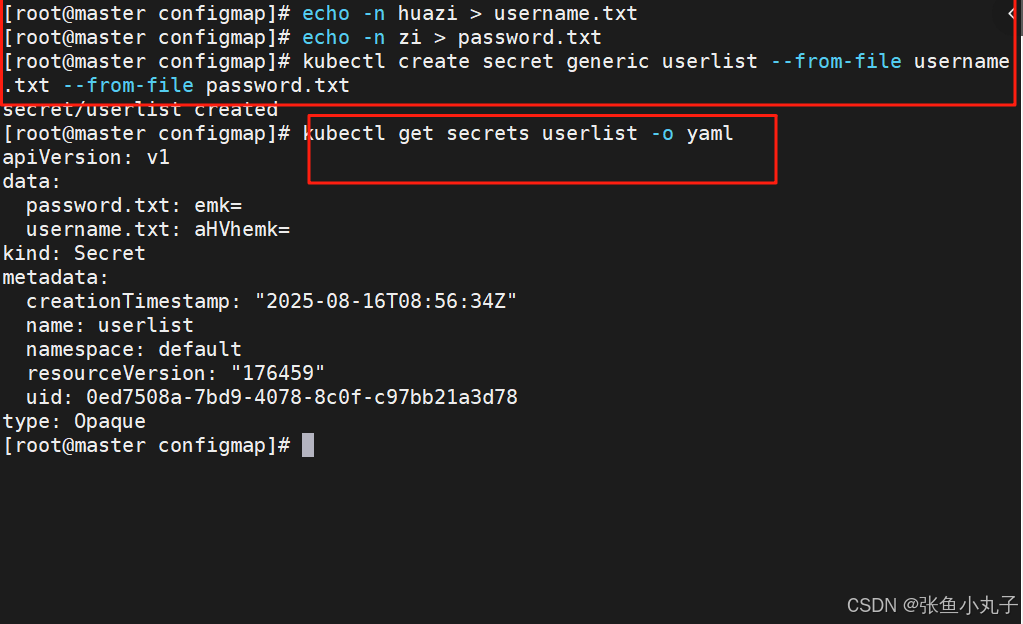
[root@master configmap]# echo -n huazi > username.txt
[root@master configmap]# echo -n zi > password.txt
[root@master configmap]# kubectl create secret generic userlist --from-file username.txt --from-file password.txt
secret/userlist created
[root@master configmap]# kubectl get secrets userlist -o yaml
apiVersion: v1
data:
password.txt: emk=
username.txt: aHVhemk=
kind: Secret
metadata:
creationTimestamp: "2025-08-16T08:56:34Z"
name: userlist
namespace: default
resourceVersion: "176459"
uid: 0ed7508a-7bd9-4078-8c0f-c97bb21a3d78
type: Opaque
编写yaml文件

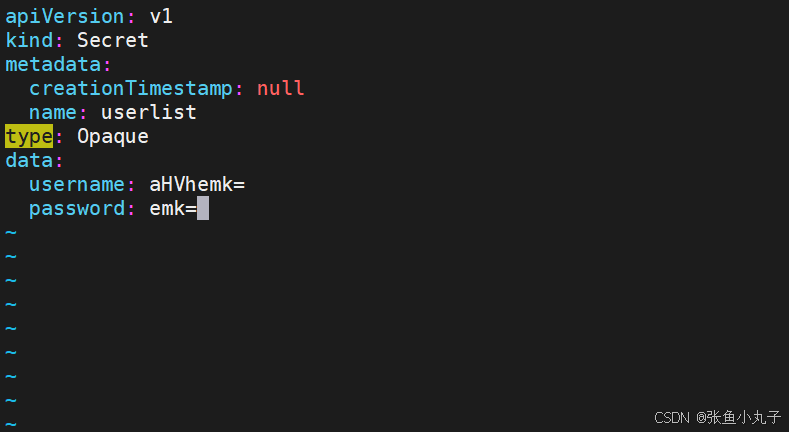
应用文件
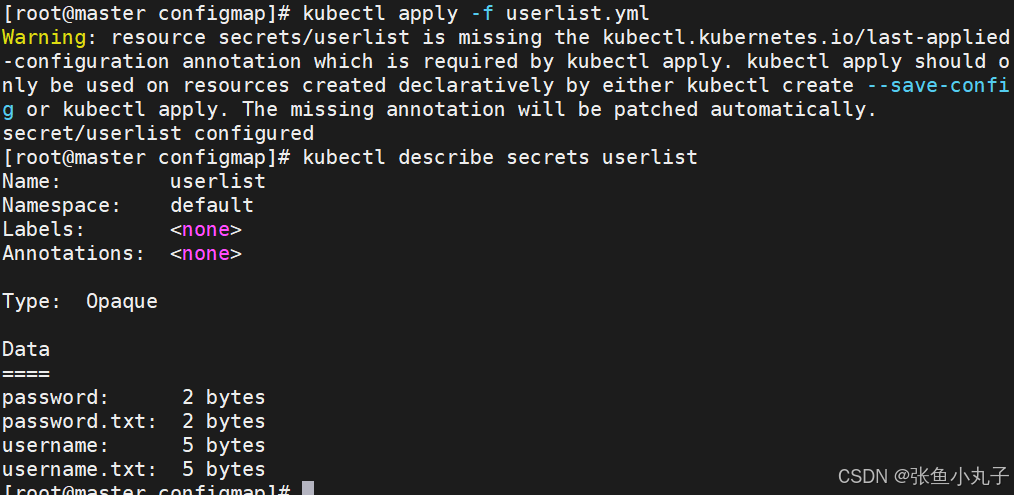
16.2 Secret的使用方法
将Secret设置为环境变量
[root@master configmap]# vim pod3.yaml
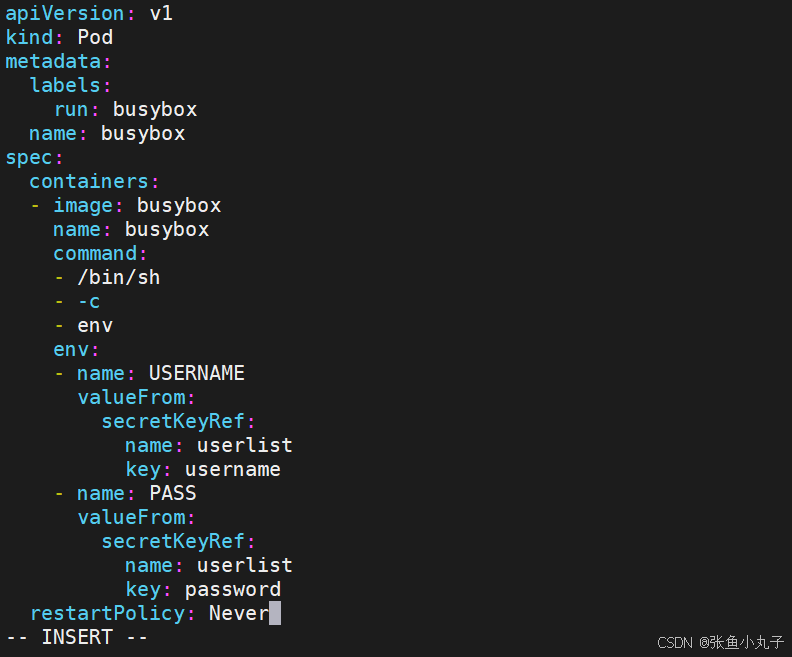
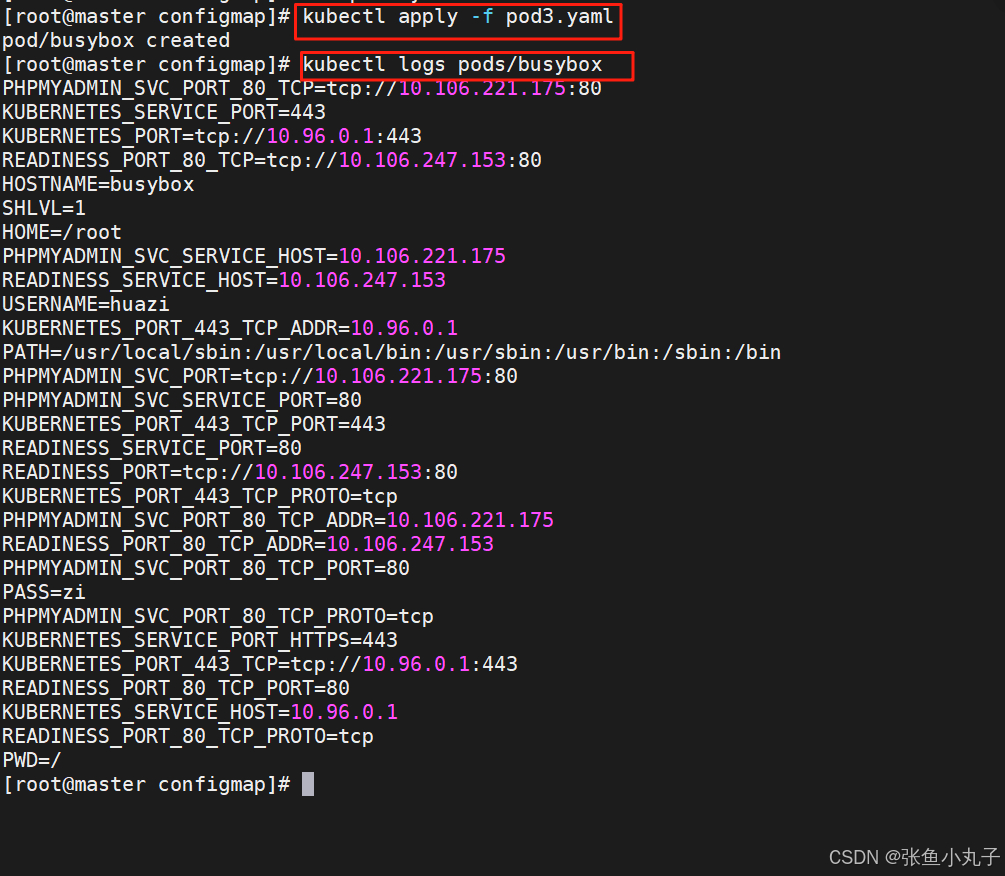
将Secret挂载到Volume中

向固定路径映射
[root@master configmap]# vim pod1.yaml
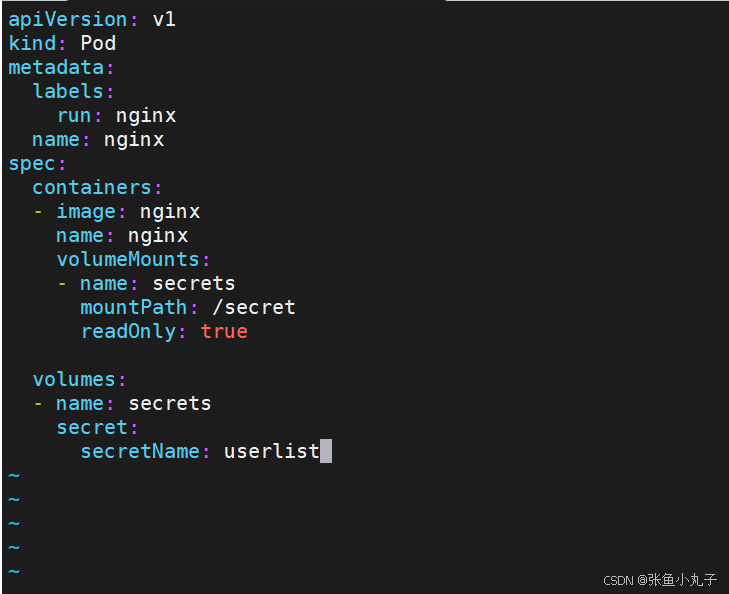
向指定路径映射 secret 密钥
向指定路径映射
[root@master configmap]# vim pod2.yaml
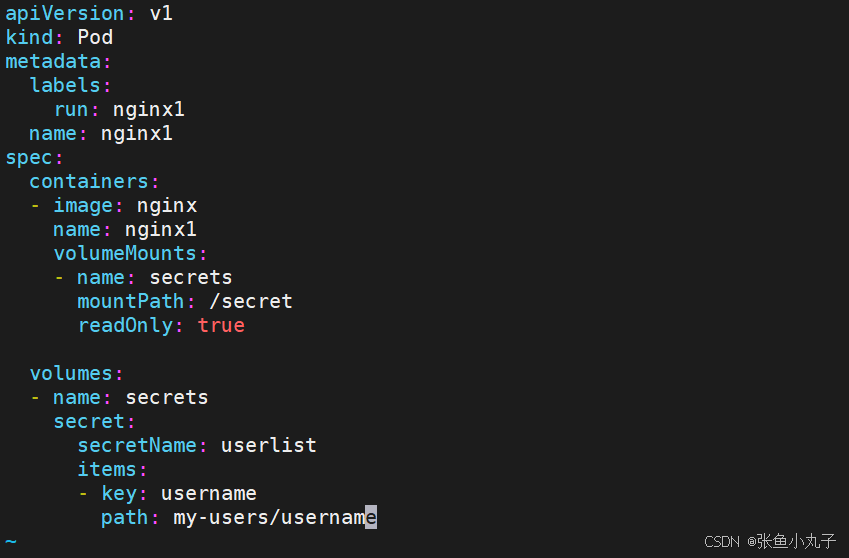

存储docker registry的认证信息
建立私有仓库并上传镜像

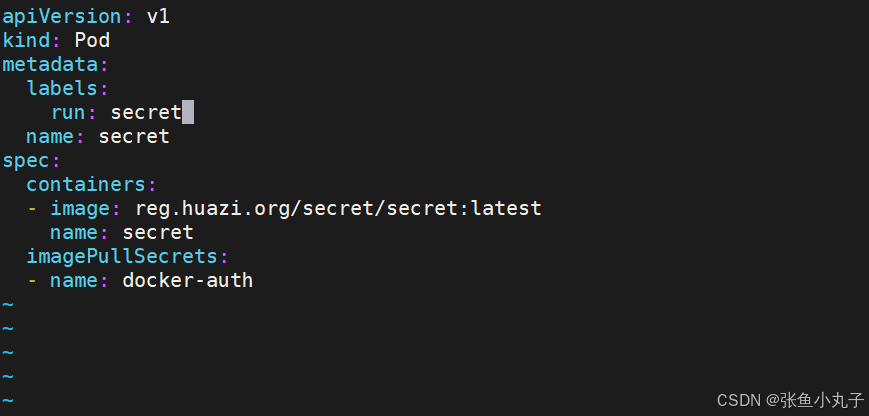
17. volumes配置管理
-
容器中文件在磁盘上是临时存放的,这给容器中运行的特殊应用程序带来一些问题
-
当容器崩溃时,kubelet将重新启动容器,容器中的文件将会丢失,因为容器会以干净的状态重建。
-
当在一个 Pod 中同时运行多个容器时,常常需要在这些容器之间共享文件。
-
Kubernetes 卷具有明确的生命周期与使用它的 Pod 相同
-
卷比 Pod 中运行的任何容器的存活期都长,在容器重新启动时数据也会得到保留
-
当一个 Pod 不再存在时,卷也将不再存在。
-
Kubernetes 可以支持许多类型的卷,Pod 也能同时使用任意数量的卷。
-
卷不能挂载到其他卷,也不能与其他卷有硬链接。 Pod 中的每个容器必须独立地指定每个卷的挂载位置。
kubernets支持的卷的类型
k8s支持的卷的类型如下:
awsElasticBlockStore 、azureDisk、azureFile、cephfs、cinder、configMap、csi
downwardAPI、emptyDir、fc (fibre channel)、flexVolume、flocker
gcePersistentDisk、gitRepo (deprecated)、glusterfs、hostPath、iscsi、local、
nfs、persistentVolumeClaim、projected、portworxVolume、quobyte、rbd
scaleIO、secret、storageos、vsphereVolume
17.1 emptyDir卷
功能:
当Pod指定到某个节点上时,首先创建的是一个emptyDir卷,并且只要 Pod 在该节点上运行,卷就一直存在。卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会永久删除
emptyDir 的使用场景:
缓存空间,例如基于磁盘的归并排序。
耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
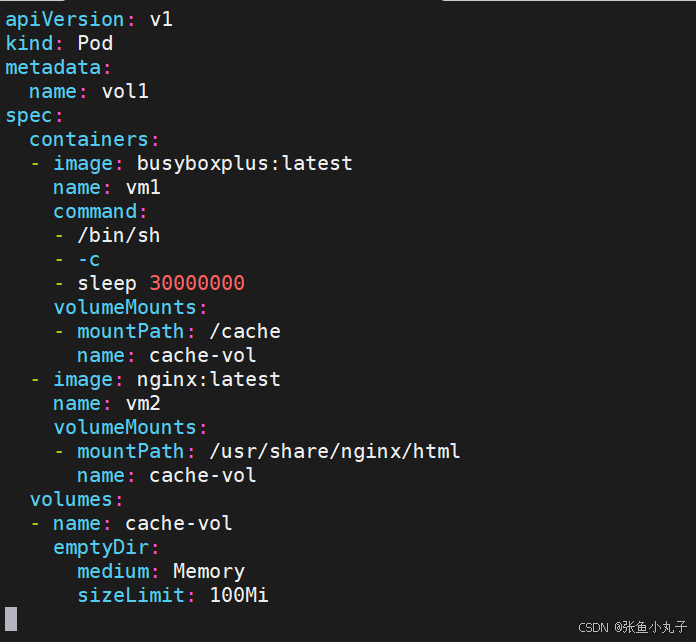
编写配置文件
[root@master volumes]# vim pod1.yml
应用卷

查看pod中卷的使用情况
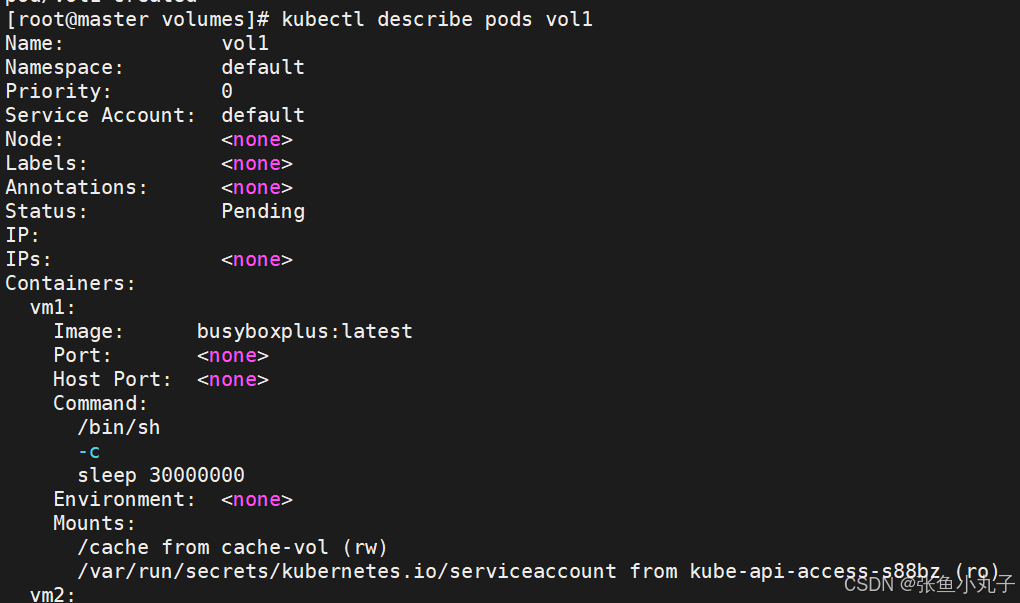
![]()
17.2 hostpath卷
功能:
hostPath 卷能将主机节点文件系统上的文件或目录挂载到您的 Pod 中,不会因为pod关闭而被删除
hostPath 的一些用法
运行一个需要访问 Docker 引擎内部机制的容器,挂载 /var/lib/docker 路径。
在容器中运行 cAdvisor(监控) 时,以 hostPath 方式挂载 /sys。
允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在
hostPath的安全隐患
具有相同配置(例如从 podTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为。
当 Kubernetes 按照计划添加资源感知的调度时,这类调度机制将无法考虑由 hostPath 使用的资源。
基础主机上创建的文件或目录只能由 root 用户写入。您需要在 特权容器 中以 root 身份运行进程,或者修改主机上的文件权限以便容器能够写入 hostPath 卷。
编写配置文件
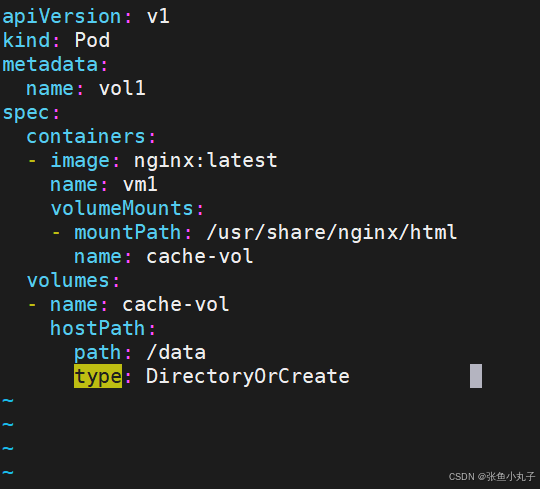
当/data目录不存在时自动建立
17.3 nfs卷
NFS 卷允许将一个现有的 NFS 服务器上的目录挂载到 Kubernetes 中的 Pod 中。这对于在多个 Pod 之间共享数据或持久化存储数据非常有用
例如,如果有多个容器需要访问相同的数据集,或者需要将容器中的数据持久保存到外部存储,NFS 卷可以提供一种方便的解决方案。
部署一台nfs共享主机并在所有k8s节点中安装nfs-utils

编辑配置文件
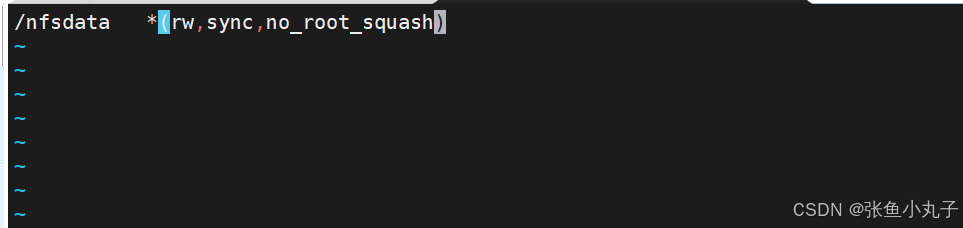
[root@haobor harbor]# vim /etc/exports

在所有主机中安装nfs-utils
部署nfs卷
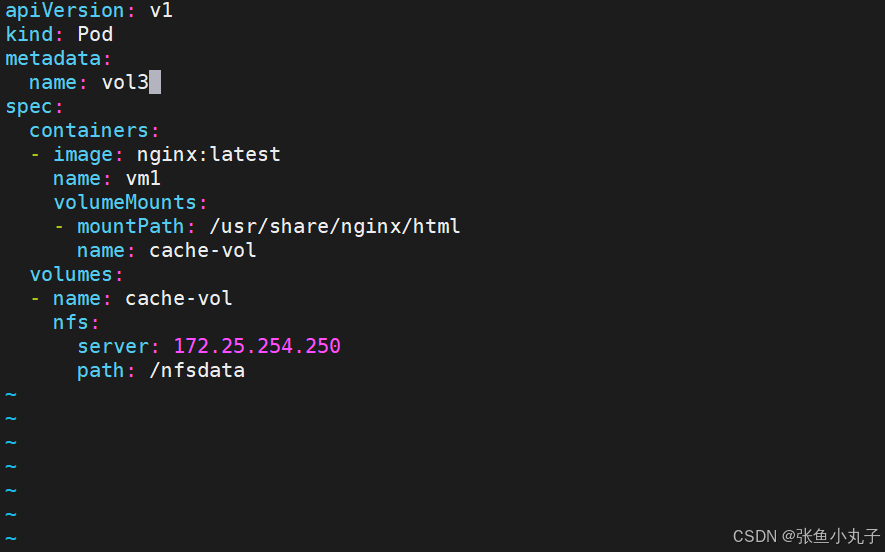
[root@master volumes]# vim pod3.yml
应用

查看状态
17.4 PersistentVolume持久卷
PersistentVolume(持久卷,简称PV)
pv是集群内由管理员提供的网络存储的一部分。
PV也是集群中的一种资源。是一种volume插件,
但是它的生命周期却是和使用它的Pod相互独立的。
PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节
pv有两种提供方式:静态和动态
静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,它们存在于Kubernetes API中,并可用于存储使用
动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass
PersistentVolumeClaim(持久卷声明,简称PVC)
是用户的一种存储请求
它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源
Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式持久卷配置
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态
volumes访问模式
ReadWriteOnce -- 该volume只能被单个节点以读写的方式映射
ReadOnlyMany -- 该volume可以被多个节点以只读方式映射
ReadWriteMany -- 该volume可以被多个节点以读写的方式映射
在命令行中,访问模式可以简写为:
RWO - ReadWriteOnce
ROX - ReadOnlyMany
RWX – ReadWriteMany
volumes回收策略
Retain:保留,需要手动回收
Recycle:回收,自动删除卷中数据(在当前版本中已经废弃)
Delete:删除,相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除
注意:
[!NOTE]
只有NFS和HostPath支持回收利用
AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷支持删除操作。
volumes状态说明
Available 卷是一个空闲资源,尚未绑定到任何申领
Bound 该卷已经绑定到某申领
Released 所绑定的申领已被删除,但是关联存储资源尚未被集群回收
Failed 卷的自动回收操作失败
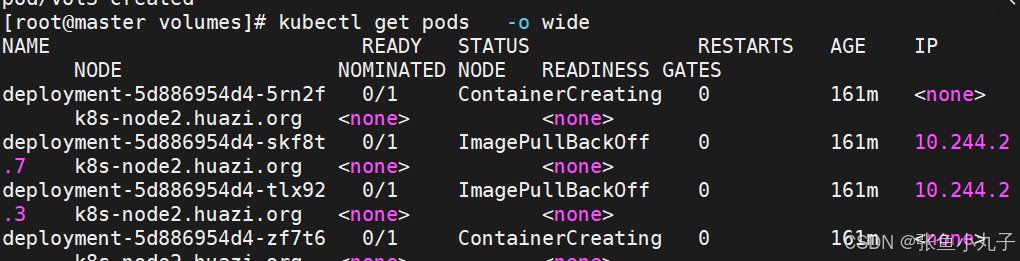
在harbor中创建实验目录
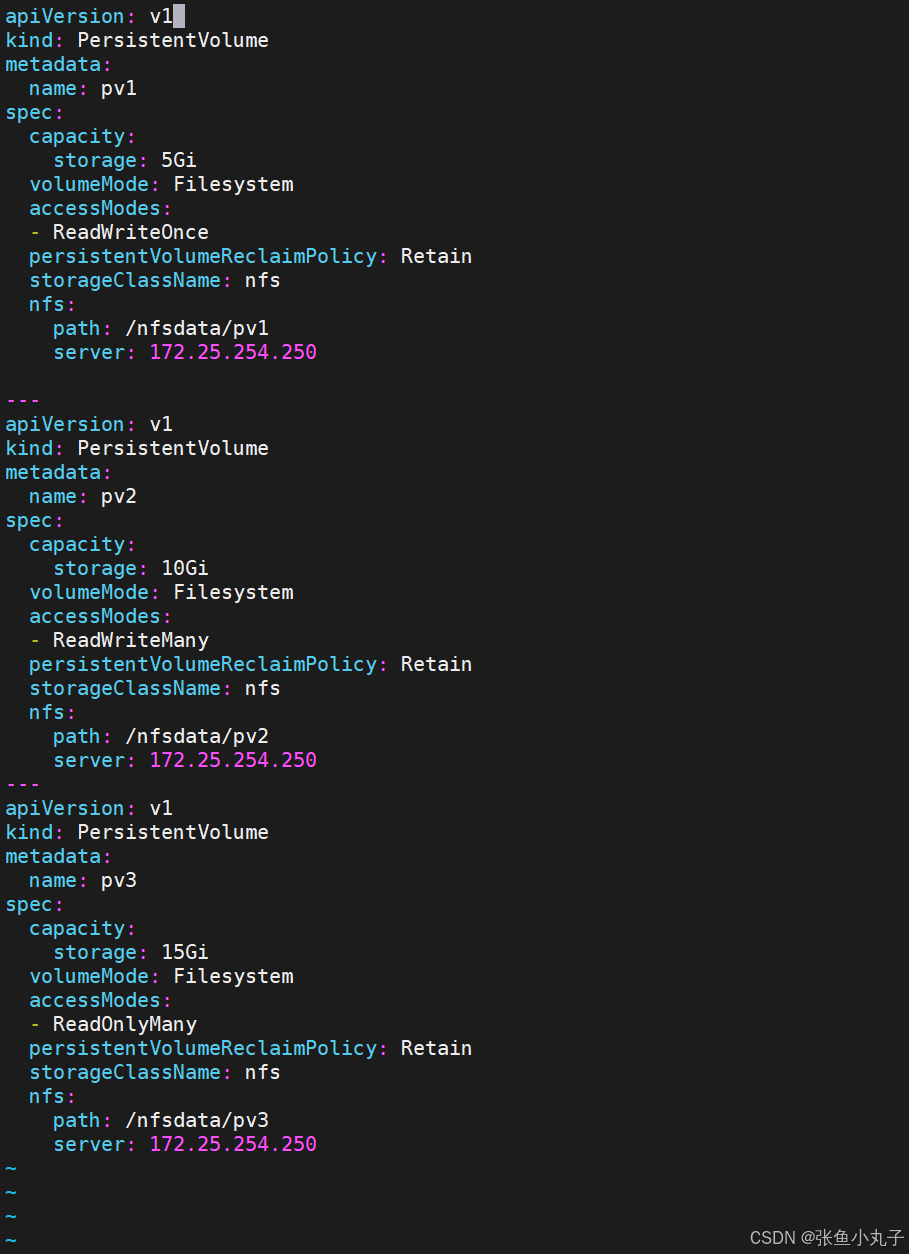
编写创建pv的yml文件(pv是集群资源,不在任何namespace中)
[root@master pvc]# vim pv.yml
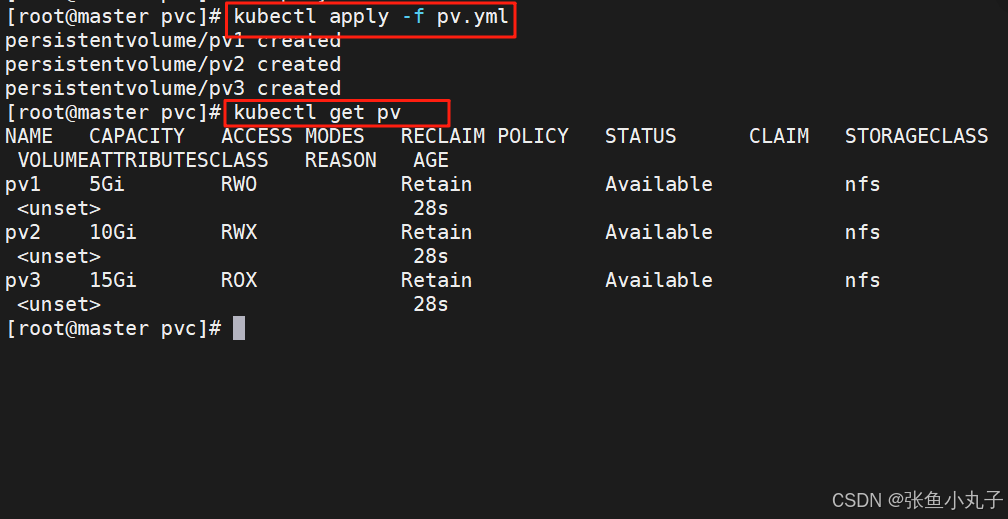
运行yml文件并查看
建立pvc,pvc是pv使用的申请,需要保证和pod在一个namesapce中
[root@master pvc]# vim pvc.yml
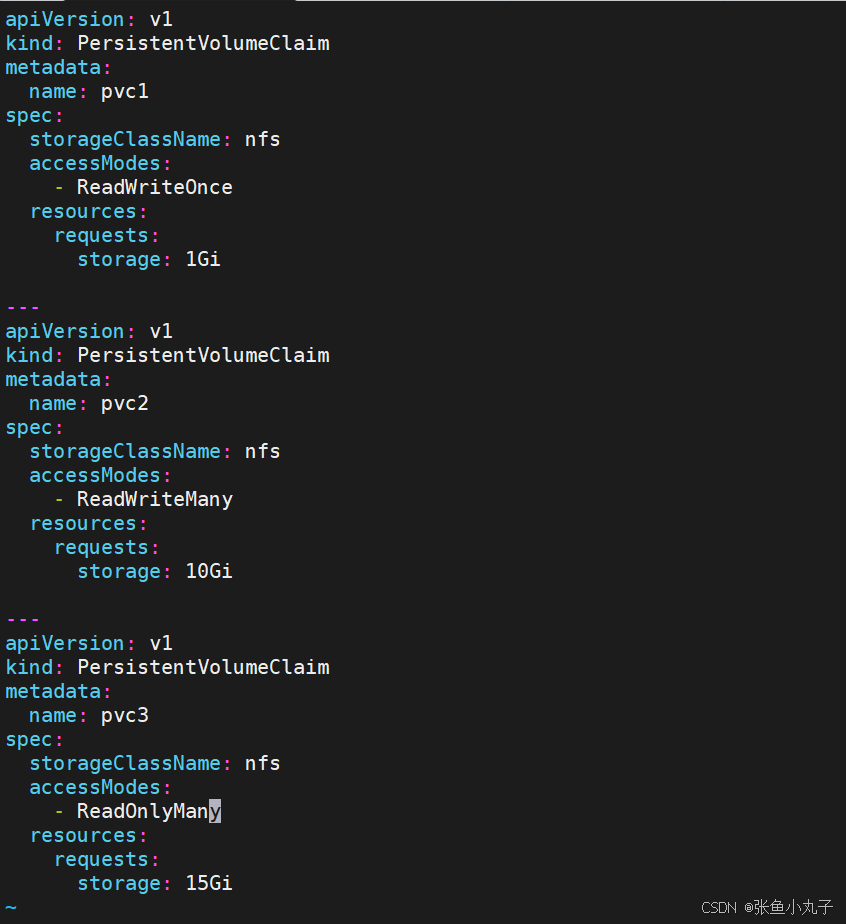
应用并查看
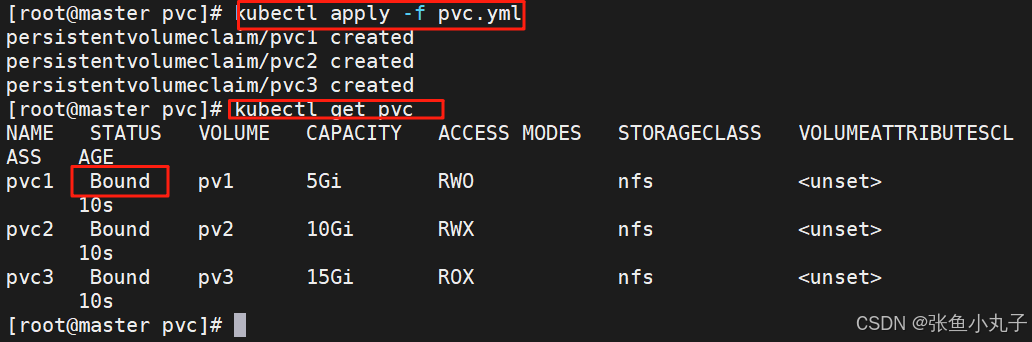
在其他namespace中无法应用

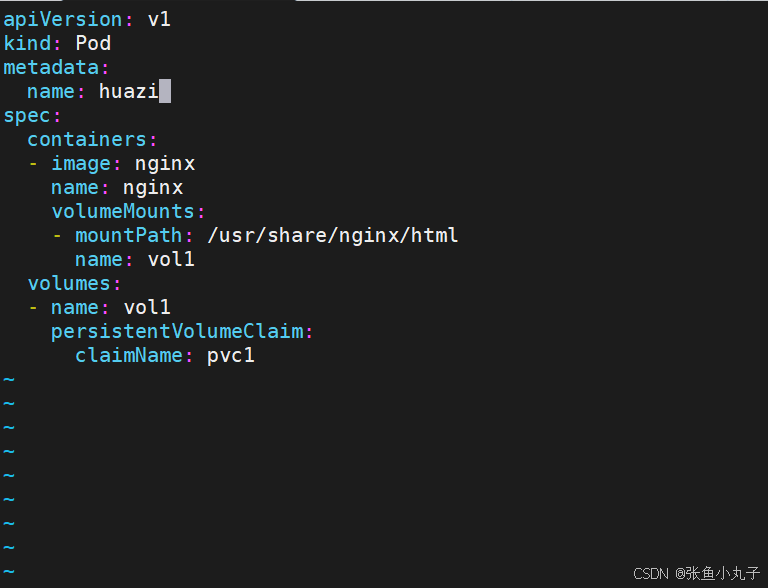
在pod中使用pvc
编写配置文件
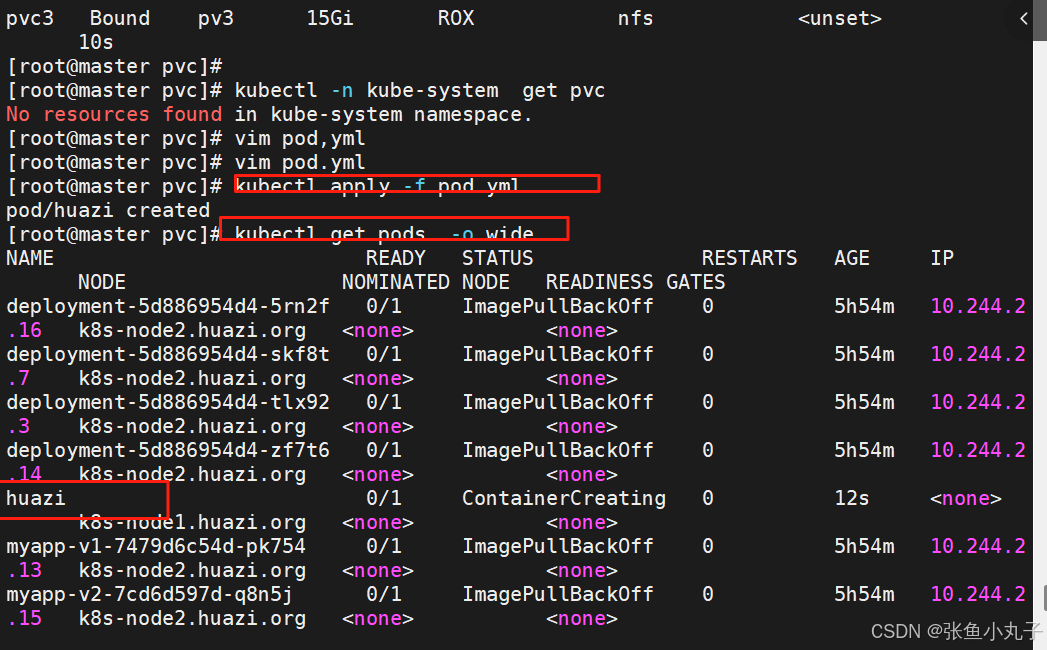
[root@master pvc]# vim pod.yml
应用并查看
18. 存储类storageclass
StorageClass说明
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到
StorageClass的属性
Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
储分配器NFS Client Provisioner
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
PV以 ${namespace}-${pvcName}-${pvName}的命名格式提供(在NFS服务器上)
PV回收的时候以 archieved-${namespace}-${pvcName}-${pvName} 的命名格式(在NFS服务器上)
18.1 部署NFS Client Provisioner
上传nfs到harbor仓库中
查看
创建sa并授权
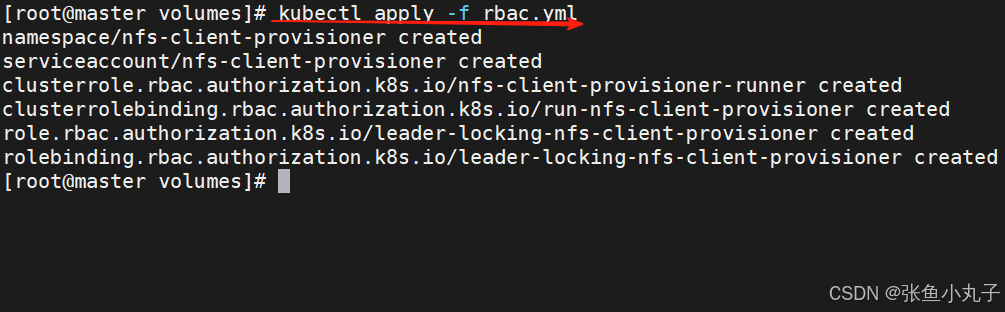
[root@master volumes]# vim rbac.yml
apiVersion: v1
kind: Namespace
metadata:
name: nfs-client-provisioner
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
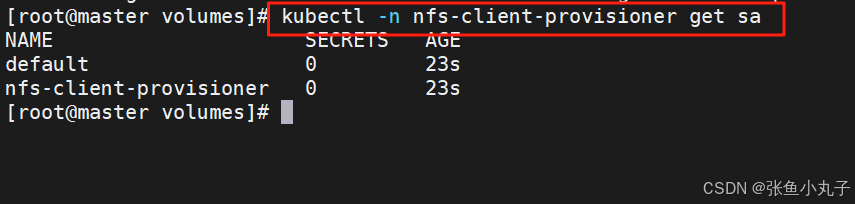
apiGroup: rbac.authorization.k8s.io查看rbac信息
部署应用
[root@master volumes]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
namespace: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: sig-storage/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 172.25.254.250
- name: NFS_PATH
value: /nfsdata
volumes:
- name: nfs-client-root
nfs:
server: 172.25.254.250
path: /nfsdata
创建存储类
[root@master volumes]# vim class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "false"
创建pvc
[root@master volumes]# vim pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1G
创建测试pod
[root@master volumes]# vim pod.yml
kind: Pod
apiVersion: v1
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: busybox
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1"
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim18.2 设置默认存储类
-
在未设定默认存储类时pvc必须指定使用类的名称
-
在设定存储类后创建pvc时可以不用指定storageClassName
一次性指定多个pvc
[root@master volumes]# vim pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc3
spec:
storageClassName: nfs-client
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 15Gi
设定默认存储类
[root@master volumes]# kubectl edit sc nfs-client
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{},"name":"nfs-client"},"parameters":{"archiveOnDelete":"false"},"provisioner":"k8s-sigs.io/nfs-subdir-external-provisioner"}
storageclass.kubernetes.io/is-default-class: "true" #设定默认存储类
creationTimestamp: "2025-08-17T13:49:10Z"
name: nfs-client
resourceVersion: "218198"
uid: 9eb1e144-3051-4f16-bdec-30c472358028
parameters:
archiveOnDelete: "false"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
reclaimPolicy: Delete
volumeBindingMode: Immediate
19. statefulset控制器
功能特性
Statefulset是为了管理有状态服务的问提设计的
StatefulSet将应用状态抽象成了两种情况:
拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一样
存储状态:应用的多个实例分别绑定了不同存储数据。
StatefulSet给所有的Pod进行了编号,编号规则是:$(statefulset名称)-$(序号),从0开始。
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,Pod对应的DNS记录。
StatefulSet的组成部分
Headless Service:用来定义pod网络标识,生成可解析的DNS记录
volumeClaimTemplates:创建pvc,指定pvc名称大小,自动创建pvc且pvc由存储类供应。
StatefulSet:管理pod的
建立无头服务
[root@master volumes]# vim headless.yml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
建立statefulset
[root@master volumes]# vim statefulset.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx-svc"
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
[root@haobor nfsdata]# ls /nfsdata/
default-test-claim-pvc-34b3d968-6c2b-42f9-bbc3-d7a7a02dcbac
default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f
default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c
default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854#为每个pod建立index.html文件
[root@haobor nfsdata]# echo web-0 > default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f/index.html
[root@haobor nfsdata]# echo web-1 > default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c/index.html
[root@haobor nfsdata]# echo web-2 > default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854/index.html
#建立测试pod访问web-0~2
[root@master volumes]# kubectl run -it testpod --image busyboxplus
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2
#删掉重新建立statefulset
[root@master volumes]# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted
[root@master volumes]# kubectl apply -f statefulset.yml
statefulset.apps/web created
#访问依然不变
[root@master volumes]# kubectl attach testpod -c testpod -i -t
If you don't see a command prompt, try pressing enter.
/ # cu
curl cut
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2statefulset的弹缩
首先,想要弹缩的StatefulSet. 需先清楚是否能弹缩该应用
用命令改变副本数
$ kubectl scale statefulsets <stateful-set-name> --replicas=<new-replicas>通过编辑配置改变副本数
$ kubectl edit statefulsets.apps <stateful-set-name>statefulset有序回收
[root@master volumes]# kubectl scale statefulset web --replicas 0 statefulset.apps/web scaled [root@master volumes]# kubectl delete -f statefulset.yml statefulset.apps "web" deleted [root@k8s-master statefulset]# kubectl delete pvc --all persistentvolumeclaim "test-claim" deleted persistentvolumeclaim "www-web-0" deleted persistentvolumeclaim "www-web-1" deleted persistentvolumeclaim "www-web-2" deleted persistentvolumeclaim "www-web-3" deleted persistentvolumeclaim "www-web-4" deleted persistentvolumeclaim "www-web-5" deleted [root@master volumes]# kubectl scale statefulsets web --replicas=0 [root@master volumes]# kubectl delete -f statefulset.yaml [root@master volumes]# kubectl delete pvc --all
20. k8s网络通信
k8s通信整体架构
k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等
CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
插件使用的解决方案如下
虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。
多路复用:MacVLAN,多个容器共用一个物理网卡进行通信。
硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。
容器间通信:
同一个pod内的多个容器间的通信,通过lo即可实现pod之间的通信
同一节点的pod之间通过cni网桥转发数据包。
不同节点的pod之间的通信需要网络插件支持
pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换
pod和外网通信:iptables的MASQUERADE
Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
flannel网络插件
插件组成:
插件 功能 VXLAN 即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network) VTEP VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因 Cni0 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡) Flannel.1 TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端 Flanneld flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息
20.1 flannel跨主机通信原理
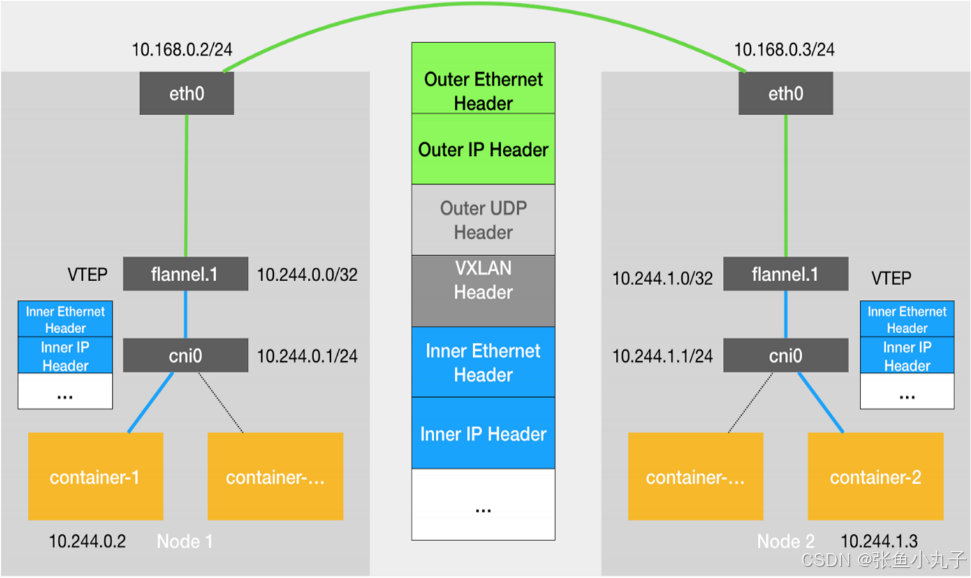
当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理。
VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识。
flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的。
linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取。
此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器。
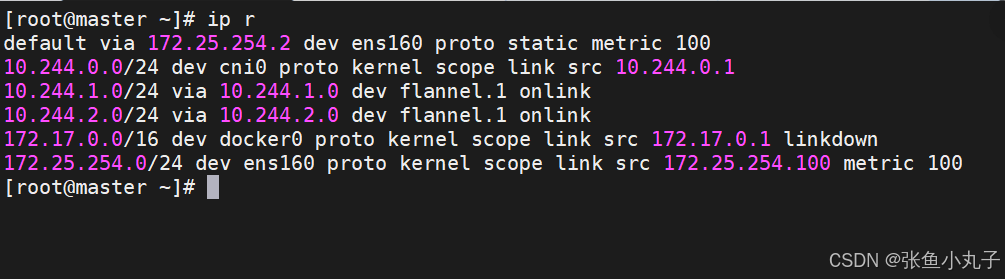
默认网络通信路由
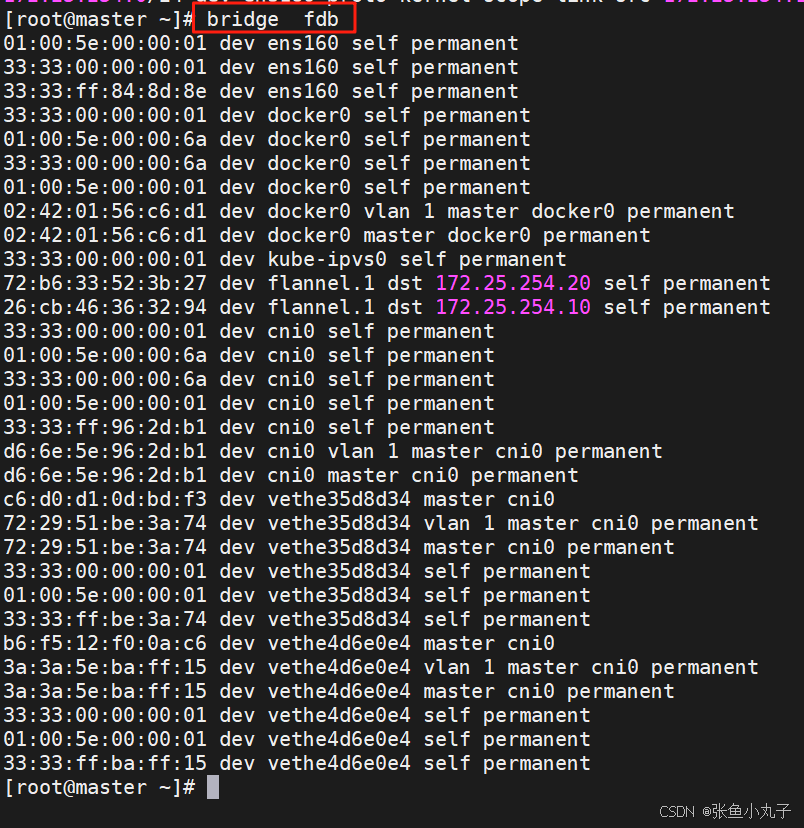
桥接转发数据库
arp列表
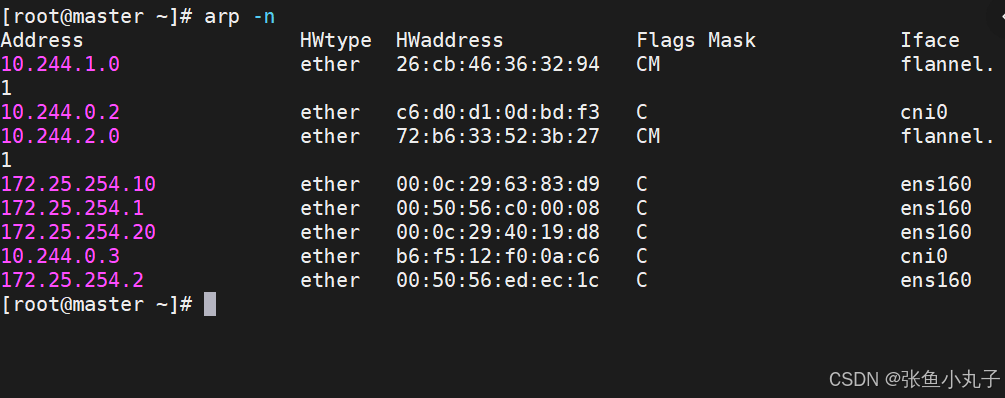
flannel支持的后端模式
网络模式 功能 vxlan 报文封装,默认模式 Directrouting 直接路由,跨网段使用vxlan,同网段使用host-gw模式 host-gw 主机网关,性能好,但只能在二层网络中,不支持跨网络 如果有成千上万的Pod,容易产生广播风暴,不推荐 UDP 性能差,不推荐
20.2 calico网络插件
calico简介:
纯三层的转发,中间没有任何的NAT和overlay,转发效率最好。
Calico 仅依赖三层路由可达。Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。
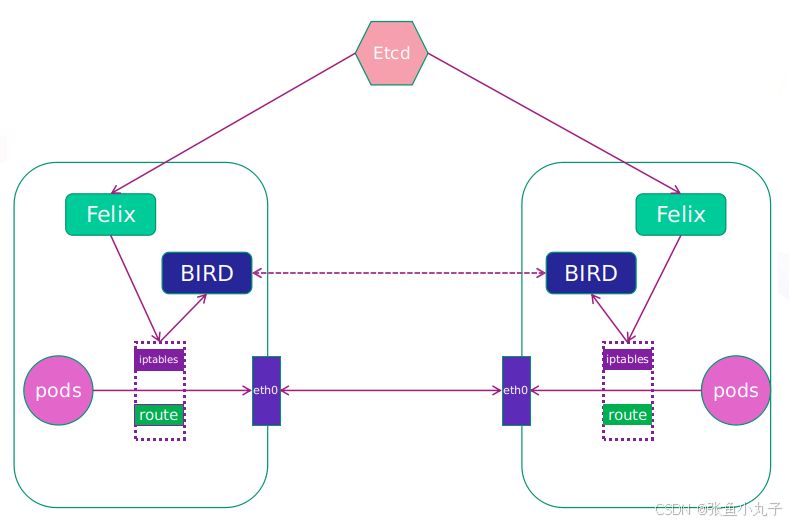
-
Felix:监听ECTD中心的存储获取事件,用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
-
BIRD:一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,路由的时候到这里
上传镜像至harbor仓库中
[root@master ~]# docker load -i calico-3.28.1.tar
6b2e64a0b556: Loading layer 3.69MB/3.69MB
38ba74eb8103: Loading layer 205.4MB/205.4MB
5f70bf18a086: Loading layer 1.024kB/1.024kB
Loaded image: calico/cni:v3.28.1
3831744e3436: Loading layer 366.9MB/366.9MB
Loaded image: calico/node:v3.28.1
4f27db678727: Loading layer 75.59MB/75.59MB
Loaded image: calico/kube-controllers:v3.28.1
993f578a98d3: Loading layer 67.61MB/67.61MB
Loaded image: calico/typha:v3.28.1
[root@master ~]# docker tag calico/cni:v3.28.1 reg.huazi.org/calico/cni:v3.28.1
[root@master ~]# docker tag calico/node:v3.28.1 reg.huazi.org/calico/node:v3.28.1
[root@master ~]# docker tag calico/typha:v3.28.1 reg.huazi.org/calico/typha:v3.28.1
[root@master ~]# docker push reg.huazi.org/calico/cni:v3.28.1
The push refers to repository [reg.huazi.org/calico/cni]
5f70bf18a086: Mounted from library/busyboxplus
38ba74eb8103: Pushed
6b2e64a0b556: Pushed
v3.28.1: digest: sha256:4bf108485f738856b2a56dbcfb3848c8fb9161b97c967a7cd479a60855e13370 size: 946
[root@master ~]# docker push reg.huazi.org/calico/node:v3.28.1
The push refers to repository [reg.huazi.org/calico/node]
3831744e3436: Pushed
v3.28.1: digest: sha256:f72bd42a299e280eed13231cc499b2d9d228ca2f51f6fd599d2f4176049d7880 size: 530
[root@master ~]# docker push reg.huazi.org/calico/typha:v3.28.1
The push refers to repository [reg.huazi.org/calico/typha]
993f578a98d3: Pushed
6b2e64a0b556: Mounted from calico/cni
v3.28.1: digest: sha256:093ee2e785b54c2edb64dc68c6b2186ffa5c47aba32948a35ae88acb4f30108f size: 740
查看
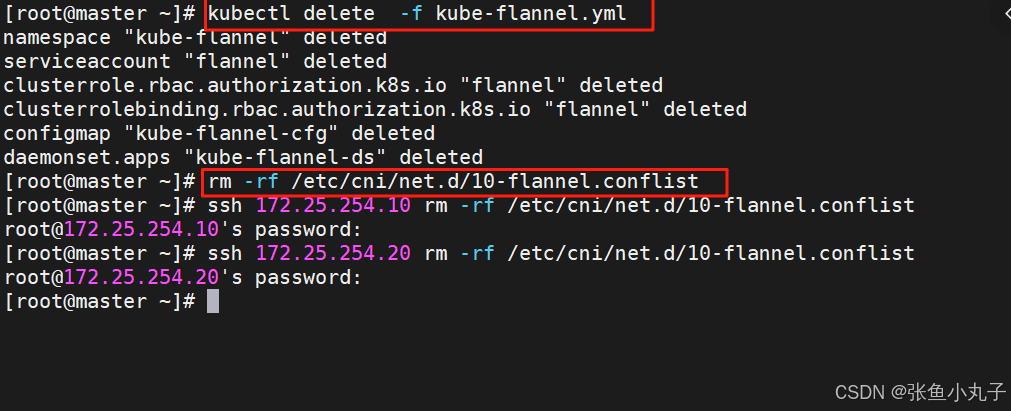
删除flannel插件,删除所有节点上flannel配置文件,避免冲突(node1和2都需)
更改yaml配置
4835 image: calico/cni:v3.28.1
4835 image: calico/cni:v3.28.1
4906 image: calico/node:v3.28.1
4932 image: calico/node:v3.28.1
5160 image: calico/kube-controllers:v3.28.1
5249 - image: calico/typha:v3.28.14970 - name: CALICO_IPV4POOL_IPIP
4971 value: "Never"4999 - name: CALICO_IPV4POOL_CIDR
5000 value: "10.244.0.0/16"
5001 - name: CALICO_AUTODETECTION_METHOD
5002 value: "interface=eth0"
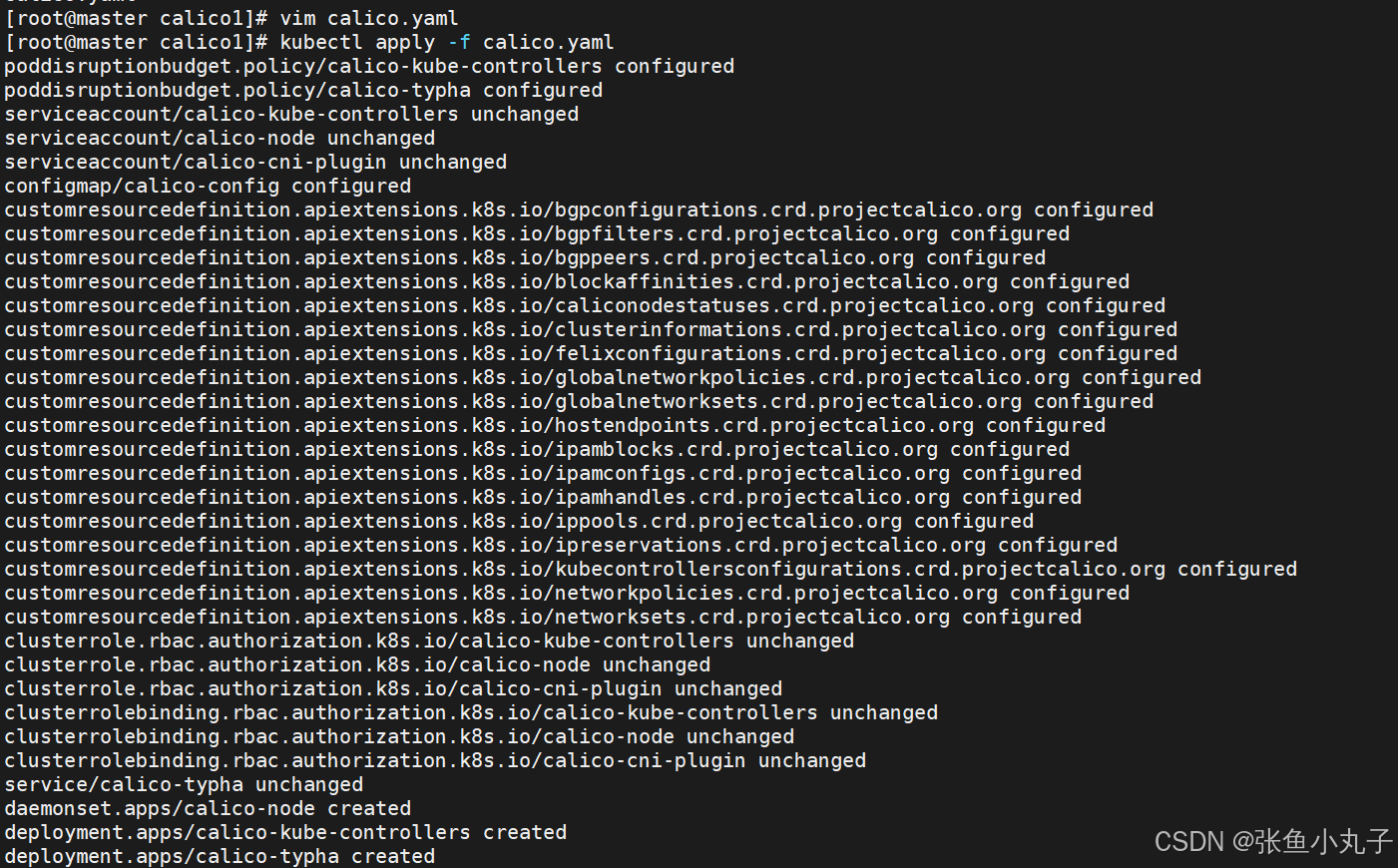
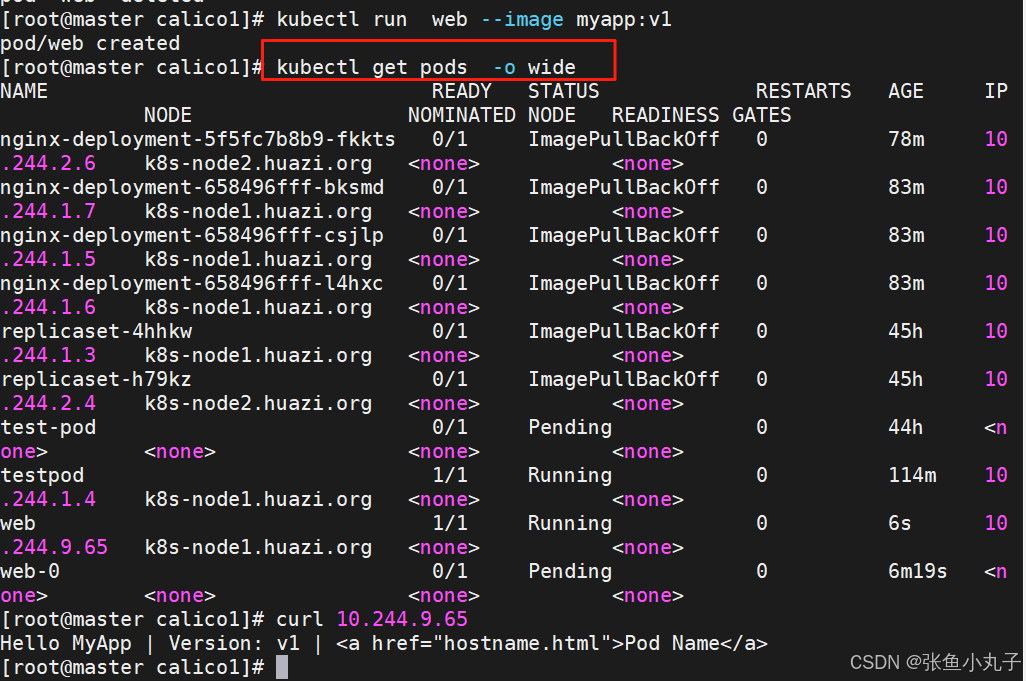
创建节点并查看
21. k8s调度(Scheduling)
调度在Kubernetes中的作用
调度是指将未调度的Pod自动分配到集群中的节点的过程
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
调度原理:
创建Pod
用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息。
调度器监视Pod
Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点。
选择节点
调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等。
绑定Pod到节点
调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息。
节点启动Pod
节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行。
调度器种类
默认调度器(Default Scheduler):
是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上。
自定义调度器(Custom Scheduler):
是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能。
扩展调度器(Extended Scheduler):
是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能。
kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
21.1 常用调度方法-nodename
-
nodeName 是节点选择约束的最简单方法,但一般不推荐
-
如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
-
使用 nodeName 来选择节点的一些限制
-
如果指定的节点不存在。
-
如果指定的节点没有资源来容纳 pod,则pod 调度失败。
-
云环境中的节点名称并非总是可预测或稳定的
-
建立pod文件
[root@master scheduler]# kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > pod1.yml
设置调度
[root@master scheduler]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeName: k8s-node2
containers:
- image: myapp:v1
name: testpod
建立pod
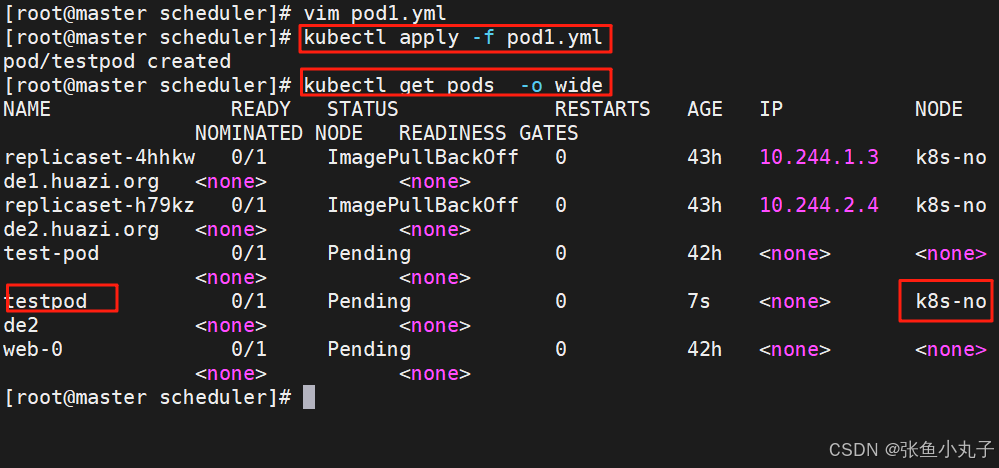
21.2 Nodeselector(通过标签控制节点)
-
nodeSelector 是节点选择约束的最简单推荐形式
-
给选择的节点添加标签:
kubectl label nodes k8s-node1 lab=lee
-
可以给多个节点设定相同标签
查看节点标签
设置节点标签


设置调度
[root@master scheduler]# vim pod2.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeSelector:
lab: huazi
containers:
- image: myapp:v1
name: testpod
21.3 affinity(亲和性)
官方文档 :
亲和与反亲和
nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。
使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
nodeAffinity节点亲和
那个节点服务指定条件就在那个节点运行
requiredDuringSchedulingIgnoredDuringExecution 必须满足,但不会影响已经调度
preferredDuringSchedulingIgnoredDuringExecution 倾向满足,在无法满足情况下也会调度pod
IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
nodeaffinity还支持多种规则匹配条件的配置如
匹配规则 功能 ln label 的值在列表内 Notln label 的值不在列表内 Gt label 的值大于设置的值,不支持Pod亲和性 Lt label 的值小于设置的值,不支持pod亲和性 Exists 设置的label 存在 DoesNotExist 设置的 label 不存在
编辑配置文件
[root@master scheduler]# vim pod3.yml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: nginx
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disk
operator: In | NotIn
values:
- ssd
Podaffinity(pod的亲和)
那个节点有符合条件的POD就在那个节点运行
podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,
Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。
[root@master scheduler]# vim exampl4.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
反亲和,先编辑配置文件
[root@master scheduler]# vim exampl5.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
affinity:
podAntiAffinity: #反亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
21.4 Taints(污点模式,禁止调度)
-
aints(污点)是Node的一个属性,设置了Taints后,默认Kubernetes是不会将Pod调度到这个Node上
-
Kubernetes如果为Pod设置Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去
-
可以使用命令 kubectl taint 给节点增加一个 taint:
$ kubectl taint nodes <nodename> key=string:effect #命令执行方法 $ kubectl taint nodes node1 key=value:NoSchedule #创建 $ kubectl describe nodes server1 | grep Taints #查询 $ kubectl taint nodes node1 key- #删除
其中[effect] 可取值:
| effect值 | 解释 |
|---|---|
| NoSchedule | POD 不会被调度到标记为 taints 节点 |
| PreferNoSchedule | NoSchedule 的软策略版本,尽量不调度到此节点 |
| NoExecute | 如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出 |
建立控制器并运行
[root@master scheduler]# vim example6.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
设定污点为NoSchedule
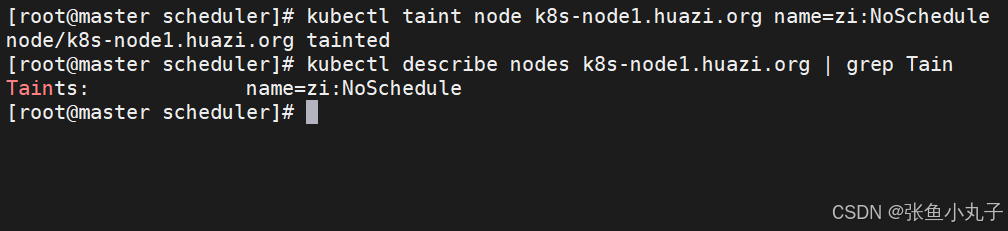
控制器增加pod
设定污点为NoExecute
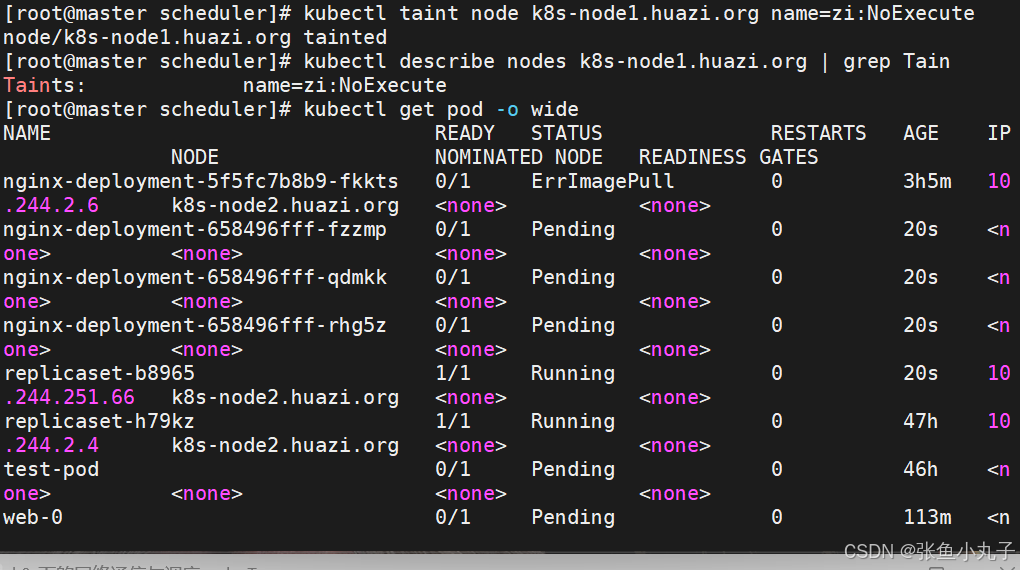
删除污点

tolerations(污点容忍)
-
tolerations中定义的key、value、effect,要与node上设置的taint保持一直:
-
如果 operator 是 Equal ,则key与value之间的关系必须相等。
-
如果 operator 是 Exists ,value可以省略
-
如果不指定operator属性,则默认值为Equal。
-
-
还有两个特殊值:
-
当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点。
-
当不指定effect ,则匹配所有的effect
-
22. kubernetes API 访问控制
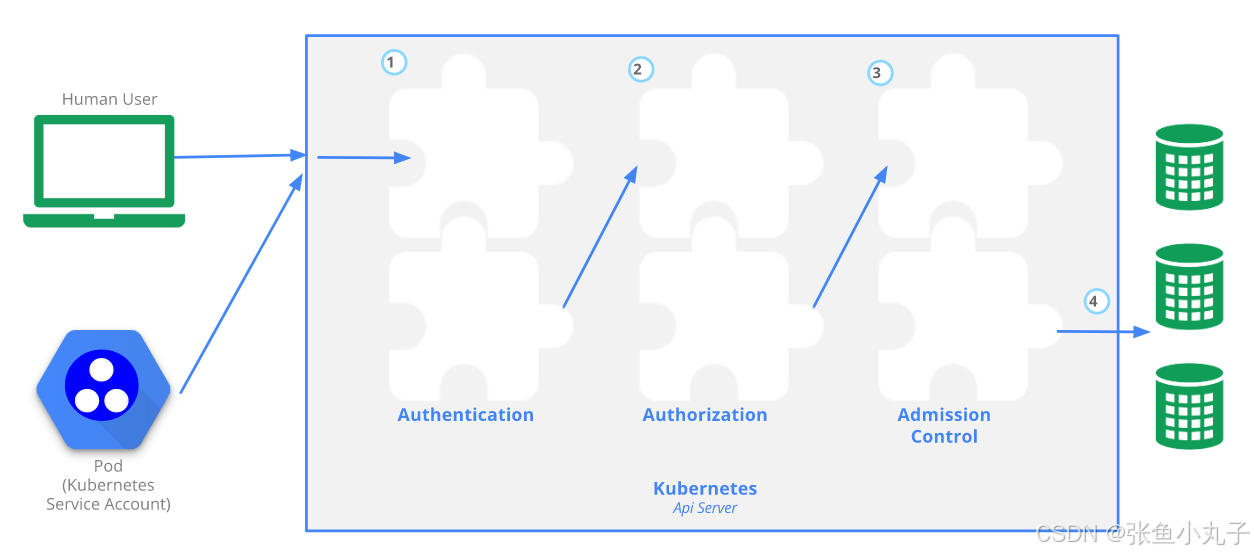
Authentication(认证)
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证。通常启用X509 Client Certs和Service Accout Tokens两种认证方式。
Kubernetes集群有两类用户:由Kubernetes管理的Service Accounts (服务账户)和(Users Accounts) 普通账户。k8s中账号的概念不是我们理解的账号,它并不真的存在,它只是形式上存在。
Authorization(授权)
必须经过认证阶段,才到授权请求,根据所有授权策略匹配请求资源属性,决定允许或拒绝请求。授权方式现共有6种,AlwaysDeny、AlwaysAllow、ABAC、RBAC、Webhook、Node。默认集群强制开启RBAC。
Admission Control(准入控制)
用于拦截请求的一种方式,运行在认证、授权之后,是权限认证链上的最后一环,对请求API资源对象进行修改和校验。
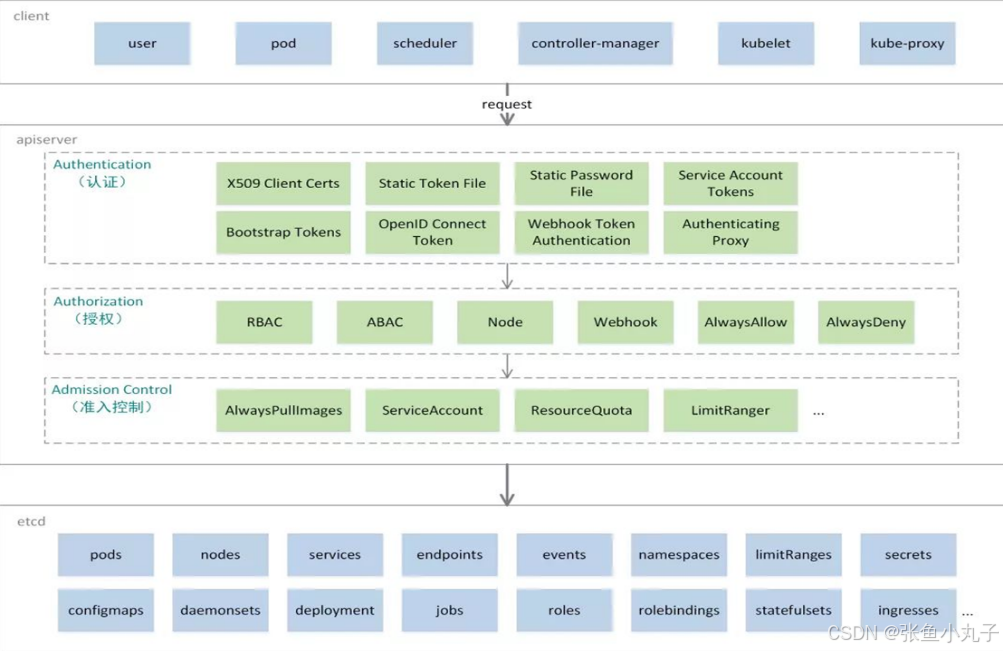
22.1 UserAccount与ServiceAccount
-
用户账户是针对人而言的。 服务账户是针对运行在 pod 中的进程而言的。
-
用户账户是全局性的。 其名称在集群各 namespace 中都是全局唯一的,未来的用户资源不会做 namespace 隔离, 服务账户是 namespace 隔离的。
-
集群的用户账户可能会从企业数据库进行同步,其创建需要特殊权限,并且涉及到复杂的业务流程。 服务账户创建的目的是为了更轻量,允许集群用户为了具体的任务创建服务账户 ( 即权限最小化原则 )。
ServiceAccount
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户
每个活跃的命名空间下存在一个名为 “default” 的服务账户
服务账户准入控制器(Service account admission controller)
相似pod中 ServiceAccount默认设为 default。
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
如果pod不包含ImagePullSecrets设置那么ServiceAccount中的ImagePullSecrets 被添加到pod中
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中
建立名字为admin的serviceAccount
[root@master scheduler]# kubectl create sa timinglee
serviceaccount/timinglee created
[root@master scheduler]# kubectl describe sa timinglee
Name: timinglee
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: <none>
Tokens: <none>
Events: <none>建立secret
[root@master scheduler]# kubectl create secret docker-registry docker-login --docker-username admin --docker-password lee --docker-server reg.timinglee.org --docker-email lee@huazi.org
secret/docker-login created
[root@k8s-master ~]# kubectl describe secrets docker-login
Name: docker-login
Namespace: default
Labels: <none>
Annotations: <none>
Type: kubernetes.io/dockerconfigjson
Data
====
.dockerconfigjson: 119 bytes将secrets注入到sa中
[root@master scheduler]# kubectl edit sa huazi
apiVersion: v1
imagePullSecrets:
- name: docker-login
kind: ServiceAccount
metadata:
creationTimestamp: "2024-09-08T15:44:04Z"
name: huazi
namespace: default
resourceVersion: "262259"
uid: 7645a831-9ad1-4ae8-a8a1-aca7b267ea2d
[root@master scheduler]# kubectl describe sa huazi
Name: huazi
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: docker-login
Mountable secrets: <none>
Tokens: <none>
Events: <none>
建立私有仓库并且利用pod访问私有仓库
[root@k8s-master auth]# vim example1.yml
[root@k8s-master auth]# kubectl apply -f example1.yml
pod/testpod created
[root@k8s-master auth]# kubectl describe pod testpod
Warning Failed 5s kubelet Failed to pull image "reg.huazi.org/lee/nginx:latest": Error response from daemon: unauthorized: unauthorized to access repository: lee/nginx, action: pull: unauthorized to access repository: lee/nginx, action: pull
Warning Failed 5s kubelet Error: ErrImagePull
Normal BackOff 3s (x2 over 4s) kubelet Back-off pulling image "reg.timinglee.org/lee/nginx:latest"
Warning Failed 3s (x2 over 4s) kubelet Error: ImagePullBackOffpod绑定sa
[root@k8s-master auth]# vim example1.yml
apiVersion: v1
kind: Pod
metadata:
name: testpod
spec:
serviceAccountName: timinglee
containers:
- image: reg.timinglee.org/lee/nginx:latest
name: testpod
[root@k8s-master auth]# kubectl apply -f example1.yml
pod/testpod created
[root@k8s-master auth]# kubectl get pods
NAME READY STATUS RESTARTS AGE
testpod 1/1 Running 0 2s23. 认证(在k8s中建立认证用户)
23.1 创建UserAccount
建立证书
[root@k8s-master auth]# cd /etc/kubernetes/pki/
[root@k8s-master pki]# openssl genrsa -out huazi.key 2048
[root@k8s-master pki]# openssl req -new -keyhuazi.key -out huazi.csr -subj "/CN=huazi"
[root@k8s-master pki]# openssl x509 -req -in timinglee.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out huazi.crt -days 365
Certificate request self-signature ok
[root@k8s-master pki]# openssl x509 -inhuazi.crt -text -noout
Certificate:
Data:
Version: 1 (0x0)
Serial Number:
76:06:6c:a7:36:53:b9:3f:5a:6a:93:3a:f2:e8:82:96:27:57:8e:58
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN = kubernetes
Validity
Not Before: Sep 8 15:59:55 2024 GMT
Not After : Sep 8 15:59:55 2025 GMT
Subject: CN = timinglee
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:a6:6d:be:5d:7f:4c:bf:36:96:dc:4e:1b:24:64:
f7:4b:57:d3:45:ad:e8:b5:07:e7:78:2b:9e:6e:53:
2f:16:ff:00:f4:c8:41:2c:89:3d:86:7c:1b:16:08:
2e:2c:bc:2c:1e:df:60:f0:80:60:f9:79:49:91:1d:
9f:47:16:9a:d1:86:c7:4f:02:55:27:12:93:b7:f4:
07:fe:13:64:fd:78:32:8d:12:d5:c2:0f:be:67:65:
f2:56:e4:d1:f6:fe:f6:d5:7c:2d:1d:c8:90:2a:ac:
3f:62:85:9f:4a:9d:85:73:33:26:5d:0f:4a:a9:14:
12:d4:fb:b3:b9:73:d0:a3:be:58:41:cb:a0:62:3e:
1b:44:ef:61:b5:7f:4a:92:5b:e3:71:77:99:b4:ea:
4d:27:80:14:e9:95:4c:d5:62:56:d6:54:7b:f7:c2:
ea:0e:47:b2:19:75:59:22:00:bd:ea:83:6b:cd:12:
46:7a:4a:79:83:ee:bc:59:6f:af:8e:1a:fd:aa:b4:
bd:84:4d:76:38:e3:1d:ea:56:b5:1e:07:f5:39:ef:
56:57:a2:3d:91:c0:3f:38:ce:36:5d:c7:fe:5e:0f:
53:75:5a:f0:6e:37:71:4b:90:03:2f:2e:11:bb:a1:
a1:5b:dc:89:b8:19:79:0a:ee:e9:b5:30:7d:16:44:
4a:53
Exponent: 65537 (0x10001)
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
62:db:0b:58:a9:59:57:91:7e:de:9e:bb:20:2f:24:fe:b7:7f:
33:aa:d5:74:0e:f9:96:ce:1b:a9:65:08:7f:22:6b:45:ee:58:
68:d8:26:44:33:5e:45:e1:82:b2:5c:99:41:6b:1e:fa:e8:1a:
a2:f1:8f:44:22:e1:d6:58:5f:4c:28:3d:e0:78:21:ea:aa:85:
08:a5:c8:b3:34:19:d3:c7:e2:fe:a2:a4:f5:68:18:53:5f:ff:
7d:35:22:3c:97:3d:4e:ad:62:5f:bb:4d:88:fb:67:f4:d5:2d:
81:c8:2c:6c:5e:0e:e2:2c:f5:e9:07:34:16:01:e2:bf:1f:cd:
6a:66:db:b6:7b:92:df:13:a1:d0:58:d8:4d:68:96:66:e3:00:
6e:ce:11:99:36:9c:b3:b5:81:bf:d1:5b:d7:f2:08:5e:7d:ea:
97:fe:b3:80:d6:27:1c:89:e6:f2:f3:03:fc:dc:de:83:5e:24:
af:46:a6:2a:8e:b1:34:67:51:2b:19:eb:4c:78:12:ac:00:4e:
58:5e:fd:6b:4c:ce:73:dd:b3:91:73:4a:d6:6f:2c:86:25:f0:
6a:fb:96:66:b3:39:a4:b0:d9:46:c2:fc:6b:06:b2:90:9c:13:
e1:02:8b:6f:6e:ab:cf:e3:21:7e:a9:76:c1:38:15:eb:e6:2d:
a5:6f:e5:ab建立k8s中的用户
[root@k8s-master pki]# kubectl config set-credentials timinglee --client-certificate /etc/kubernetes/pki/timinglee.crt --client-key /etc/kubernetes/pki/timinglee.key --embed-certs=true
User "timinglee" set.
[root@k8s-master pki]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://172.25.254.100:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
- name: timinglee
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED为用户创建集群的安全上下文
root@k8s-master pki]# kubectl config set-context timinglee@kubernetes --cluster kubernetes --user timinglee
Context "timinglee@kubernetes" created.切换用户,用户在集群中只有用户身份没有授权
[root@k8s-master ~]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".
[root@k8s-master ~]# kubectl get pods
Error from server (Forbidden): pods is forbidden: User "timinglee" cannot list resource "pods" in API group "" in the namespace "default"切换会集群管理,如果需要删除用户
[root@k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
[root@k8s-master pki]# kubectl config delete-user timinglee
deleted user timinglee from /etc/kubernetes/admin.conf23.2 RBAC(Role Based Access Control)
基于角色访问控制授权:
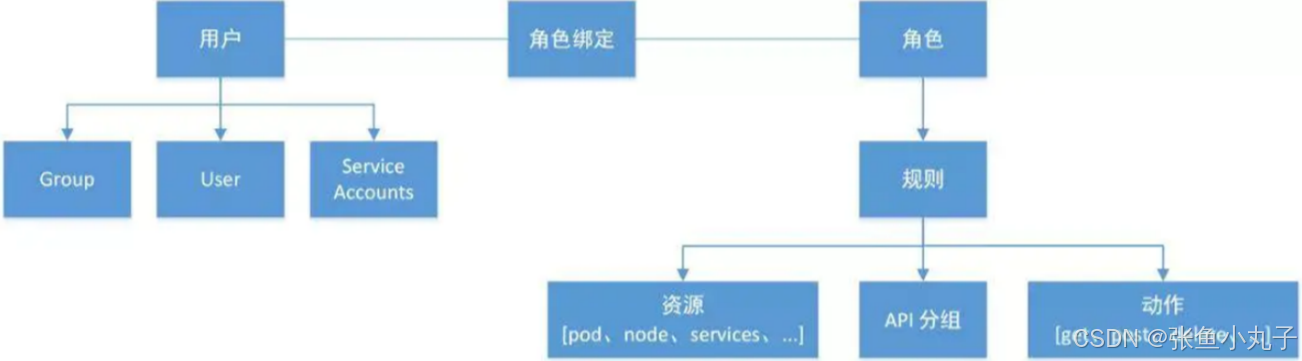
-
允许管理员通过Kubernetes API动态配置授权策略。RBAC就是用户通过角色与权限进行关联。
-
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可
-
RBAC的三个基本概念
-
Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
-
-
Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
-
RoleBinding:定义了“被作用者”和“角色”的绑定关系
-
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
-
Role 和 ClusterRole
-
Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限。
-
-
ClusterRole 跟 Role 类似,但是可以在集群中全局使用。
-
Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用
-
cluster-amdin、admin、edit、view
clusterrole授权实施,建立集群角色
[root@k8s-master rbac]# kubectl create clusterrole myclusterrole --resource=deployment --verb get --dry-run=client -o yaml > myclusterrole.yml
[root@k8s-master rbac]# vim myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: myclusterrole
rules:
- apiGroups:
- apps
resources:
- deployments
verbs:
- get
- list
- watch
- create
- update
- path
- delete
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
- create
- update
- path
- delete
[root@k8s-master rbac]# kubectl describe clusterrole myclusterrole
Name: myclusterrole
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
deployments.apps [] [] [get list watch create update path delete]
pods.apps [] [] [get list watch create update path delete]建立集群角色绑定
[root@k8s-master rbac]# kubectl create clusterrolebinding clusterrolebind-myclusterrole --clusterrole myclusterrole --user timinglee --dry-run=client -o yaml > clusterrolebind-myclusterrole.yml
[root@k8s-master rbac]# vim clusterrolebind-myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: clusterrolebind-myclusterrole
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: myclusterrole
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: timinglee
[root@k8s-master rbac]# kubectl describe clusterrolebindings.rbac.authorization.k8s.io clusterrolebind-myclusterrole
Name: clusterrolebind-myclusterrole
Labels: <none>
Annotations: <none>
Role:
Kind: ClusterRole
Name: myclusterrole
Subjects:
Kind Name Namespace
---- ---- ---------
User huazi测试
[root@k8s-master rbac]# kubectl get pods -A
[root@k8s-master rbac]# kubectl get deployments.apps -A
[root@k8s-master rbac]# kubectl get svc -A
Error from server (Forbidden): services is forbidden: User "huazi" cannot list resource "services" in API group "" at the cluster scope服务账户的自动化
服务账户准入控制器(Service account admission controller)
如果该 pod 没有 ServiceAccount 设置,将其 ServiceAccount 设为 default。
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
如果 pod 不包含 ImagePullSecrets 设置,那么 将 ServiceAccount 中的 ImagePullSecrets 信息添加到 pod 中。
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中。
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中。
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户,并且保证每个活跃的命名空间下存在一个名为 “default” 的服务账户
24. helm
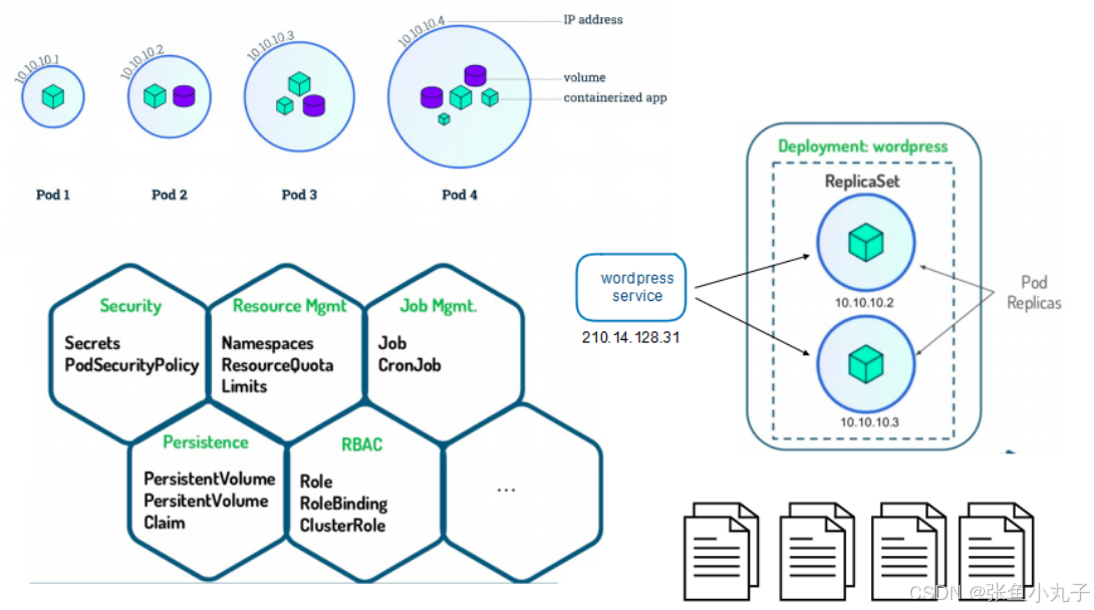
-
Helm是Kubernetes 应用的包管理工具,主要用来管理 Charts,类似Linux系统的yum。
-
Helm Chart是用来封装Kubernetes原生应用程序的一系列YAML文件。可以在你部署应用的时候自定义应用程序的一些 Metadata,以便于应用程序的分发。
-
对于应用发布者而言
-
通过Helm打包应用、管理应用依赖关系、管理应用版本并发布应用到软件仓库。
-
对于使用者而言
-
使用Helm后可以以简单的方式在Kubernetes上查找、安装、升级、回滚、卸载应用程序
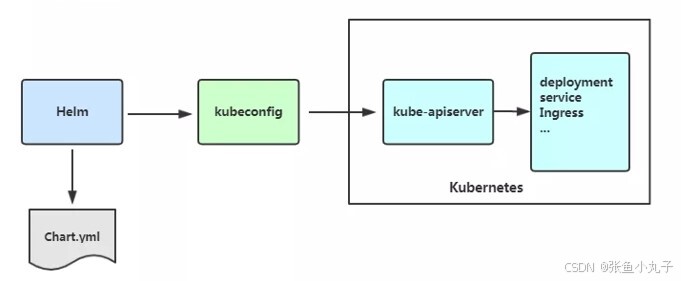
安装helm


配置helm命令补齐

24.1 常用操作
| 命令 | 描述 |
|---|---|
| create | 创建一个 chart 并指定名字 |
| dependency | 管理 chart 依赖 |
| get | 下载一个 release。可用子命令:all、hooks、manifest、notes、values |
| history | 获取 release 历史 |
| install | 安装一个 chart |
| list | 列出 release |
| package | 将 chart 目录打包到 chart 存档文件中 |
| pull | 从远程仓库中下载 chart 并解压到本地 # helm pull stable/mysql -- untar |
| repo | 添加,列出,移除,更新和索引 chart 仓库。可用子命令:add、index、 list、remove、update |
| rollback | 从之前版本回滚 |
| search | 根据关键字搜索 chart。可用子命令:hub、repo |
| show | 查看 chart 详细信息。可用子命令:all、chart、readme、values |
| status | 显示已命名版本的状态 |
| template | 本地呈现模板 |
| uninstall | 卸载一个 release |
| upgrade | 更新一个 release |
| version | 查看 helm 客户端版本 |
查询官方应用中心
[root@master helm]# helm search hub nginx #在官方仓库中搜索 [root@master helm]# helm search repo nginx #在本地仓库中搜索管理第三方repo源
#添加阿里云仓库
[root@master helm]# helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
"aliyun" has been added to your repositories
#添加bitnami仓库
[root@master helm]# helm repo add bitnami https://charts.bitnami.com/bitnami
"bitnami" has been added to your repositories
#查看仓库信息
[root@master helm]# helm repo list
NAME URL
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
bitnami https://charts.bitnami.com/bitnami
#查看仓库存储helm清单
[root@k8s-master helm]# helm search repo aliyun
NAME CHART VERSION APP VERSION DESCRIPTION #应用名称 封装版本 软件版本 软件描述
aliyun/acs-engine-autoscaler 2.1.3 2.1.1 Scales worker nodes within agent pools
aliyun/aerospike 0.1.7 v3.14.1.2 A Helm chart for Aerospike in Kubernetes
#删除第三方存储库
[root@master helm]# helm repo list
NAME URL
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
bitnami https://charts.bitnami.com/bitnami
[root@master helm]# helm repo remove aliyun
"aliyun" has been removed from your repositories
[root@k8s-master helm]# helm repo list
NAME URL
bitnami https://charts.bitnami.com/bitnami安装项目前预定义项目选项
拉取项目
#拉取项目
[root@master helm]# helm pull bitnami/nginx
[root@master helm]# ls
nginx-18.1.11.tgz
[root@master helm]# tar zxf nginx-18.1.11.tgz
[root@master helm]# ls
nginx nginx-18.1.11.tgz
[root@master helm]# cd nginx/
[root@master helm]# ls
Chart.lock charts Chart.yaml README.md templates values.schema.json values.yaml
[root@k8s-master nginx]# ls templates/ #项目模板
deployment.yaml hpa.yaml NOTES.txt serviceaccount.yaml
extra-list.yaml ingress-tls-secret.yaml pdb.yaml servicemonitor.yaml
health-ingress.yaml ingress.yaml prometheusrules.yaml svc.yaml
_helpers.tpl networkpolicy.yaml server-block-configmap.yaml tls-secret.yaml
[root@master helm]# vim values.yaml #项目变量文件
13 imageRegistry: "reg.timinglee.org"
#上传项目所需要镜像到仓库
[root@master helm]# docker tag bitnami/nginx:1.27.1-debian-12-r2 reg.timinglee.org/bitnami/nginx:1.27.1-debian-12-r2
[root@master helm]# docker push reg.timinglee.org/bitnami/nginx:1.27.1-debian-12-r2
#安装本地项目
[root@master helm]# helm install timinglee /root/helm/nginx
NAME: timinglee
LAST DEPLOYED: Tue Sep 10 15:24:40 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: nginx
CHART VERSION: 18.1.11
APP VERSION: 1.27.1
[root@master helm]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d21h
timinglee-nginx LoadBalancer 10.107.92.71 172.25.254.51 80:30413/TCP,443:32376/TCP 6s
[root@k8s-master nginx]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-nginx-784d4f9cff-krv49 1/1 Running 0 12s
#更新项目
[root@master helm]# vim values.yaml #更新变量文件
624 type: ClusterIP
751 enabled: true
763 hostname: myapp.timinglee.org
783 ingressClassName: "nginx"
[root@master helm]# helm upgrade timinglee .
Release "timinglee" has been upgraded. Happy Helming!
NAME: timinglee
LAST DEPLOYED: Tue Sep 10 15:31:19 2024
NAMESPACE: default
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
CHART NAME: nginx
CHART VERSION: 18.1.11
APP VERSION: 1.27.1
[root@master helm]## kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d21h
timinglee-nginx ClusterIP 10.107.92.71 <none> 80/TCP,443/TCP 7m34s
[root@master helm]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
timinglee-nginx nginx myapp.timinglee.org 172.25.254.20 80 68s
[[root@master helm]# curl myapp.timinglee.org
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
#查看历史
[root@master helm]# helm history timinglee
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Tue Sep 10 15:24:40 2024 superseded nginx-18.1.11 1.27.1 Install complete
2 Tue Sep 10 15:31:19 2024 deployed nginx-18.1.11 1.27.1
#删除项目
[root@master helm]# helm uninstall timinglee
release "timinglee" uninstalled
[root@master helm]# helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
24.2 构建helm中的chart包
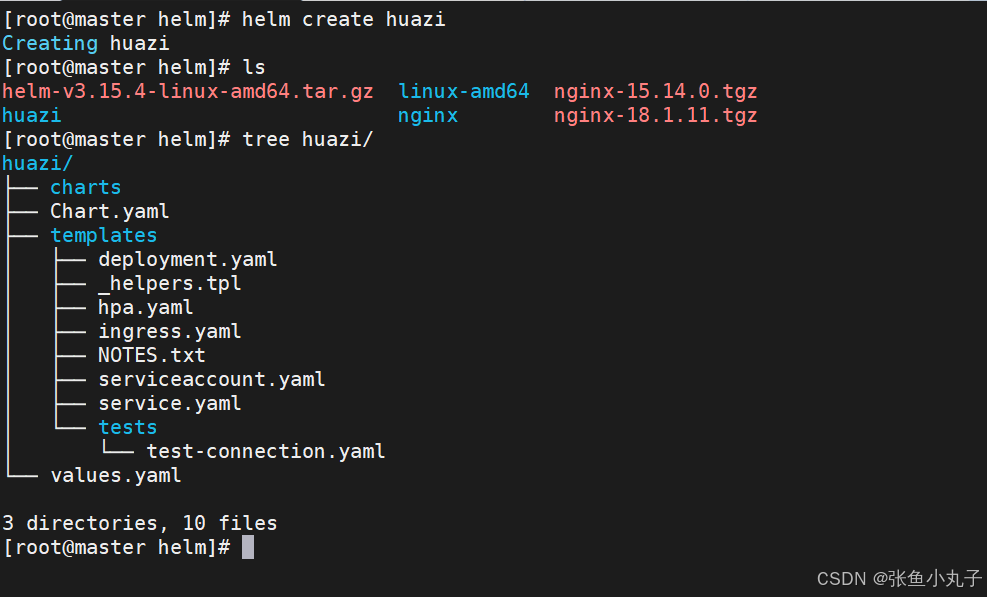
[root@master helm]# tree huazi/
huazi/
├── charts #目录里存放这个chart依赖的所有子chart。
├── Chart.yaml #用于描述这个 Chart 的基本信息
#包括名字、描述信息以及版本等。
├── templates #目录里面存放所有 yaml 模板文件。
│ ├── deployment.yaml
│ ├── _helpers.tpl #放置模板助手的地方,可以在整个 chart 中重复使用
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── NOTES.txt
│ ├── serviceaccount.yaml
│ ├── service.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml #用于存储 templates 目录中模板文件中用到变量的值。
3 directories, 10 files[root@master huazi]# vim Chart.yaml
[root@master huazi]# vim values.yaml
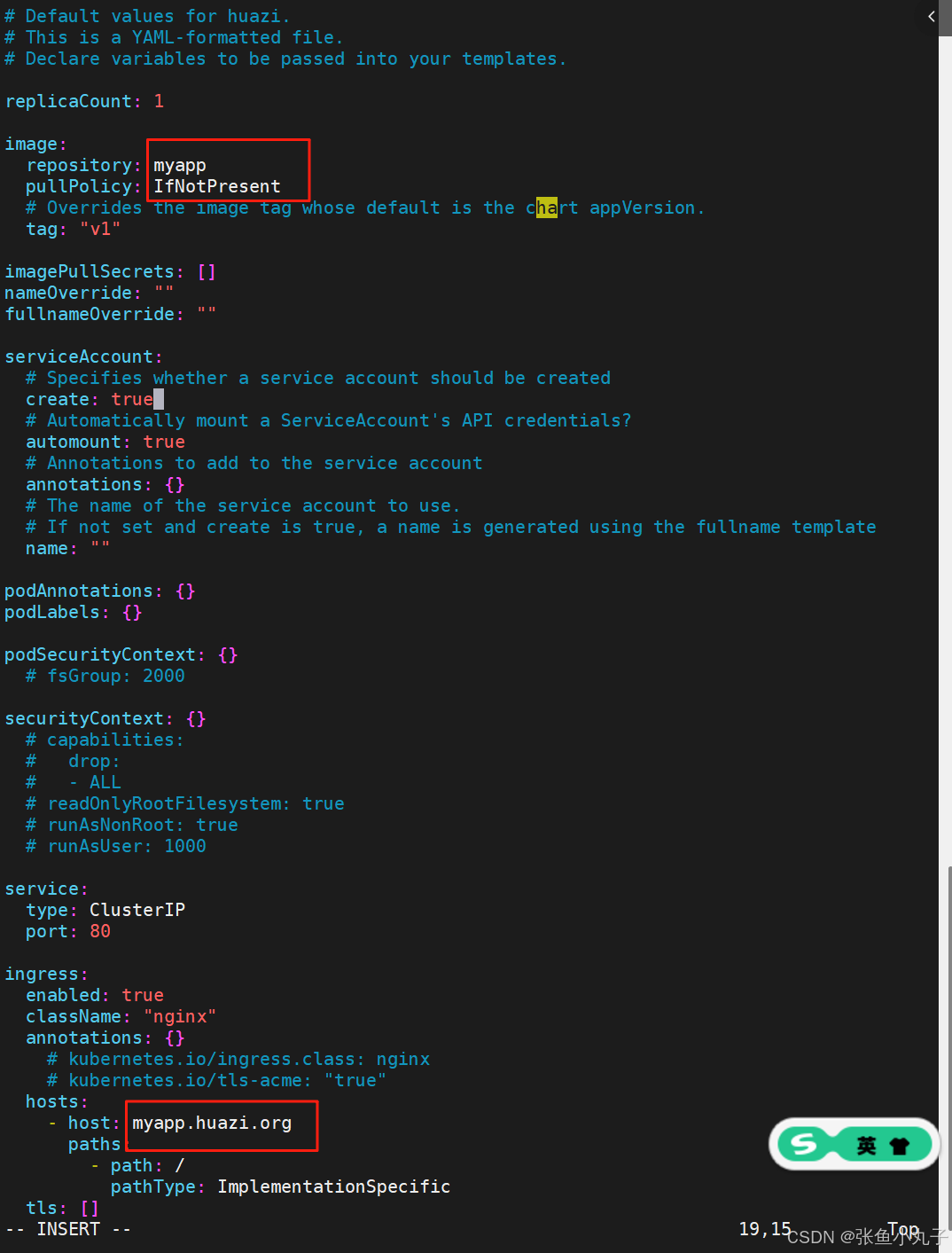
语法检查
打包项目
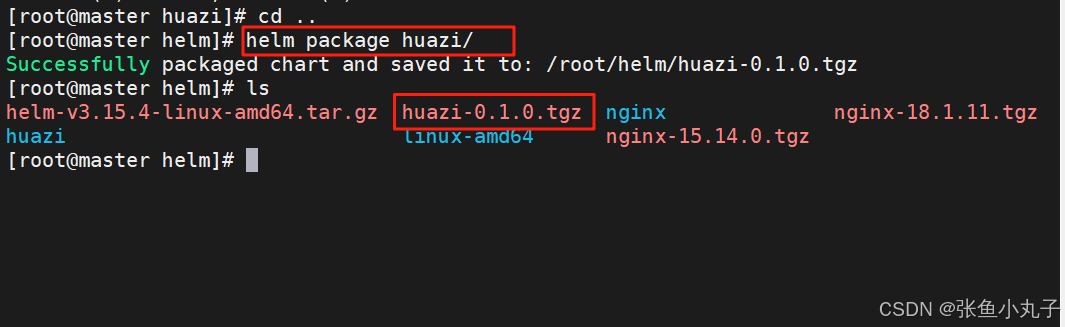
项目可以通过各种分享方式发方为任何人后部署即可
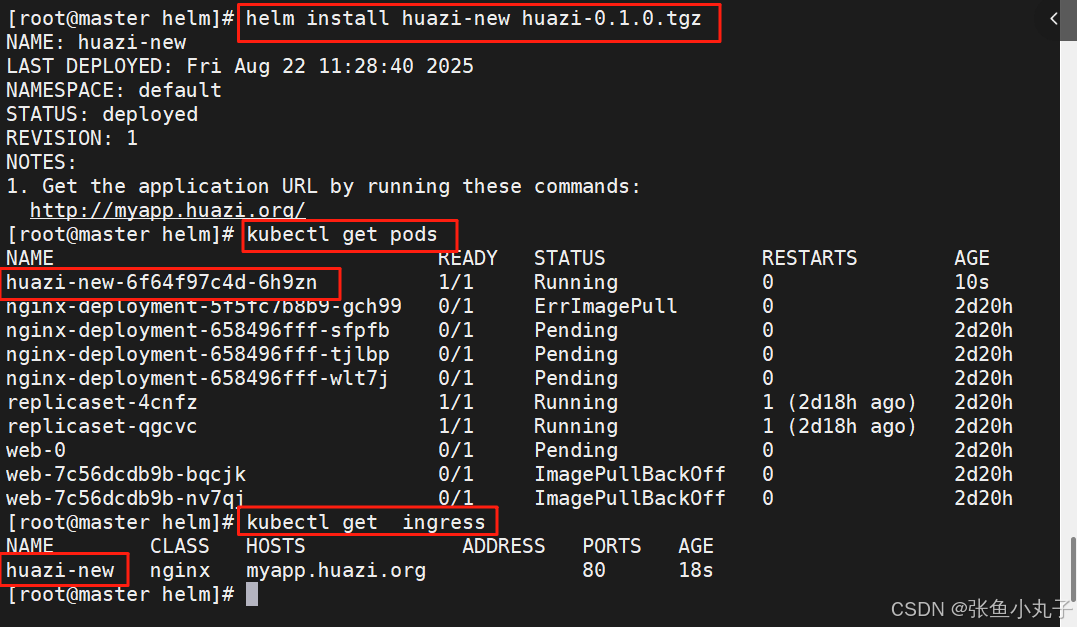
24.3 构建helm仓库
在线安装
如果网络没问题情况下直接安装即可
[root@master helm]# dnf install git -y
[root@master helm]# helm plugin install https://github.com/chartmuseum/helm-push
离线安装
#创建helm plugin的存放目录
[root@k8s-master helm]# mkdir ~/.local/share/helm/plugins/helm-push -p
#解压push插件包到指定目录
[root@master helm]# tar zxf helm-push_0.10.4_linux_amd64.tar.gz -C ~/.local/share/helm/plugins/helm-push
[root@master helm]# ls ~/.local/share/helm/plugins/helm-push
bin LICENSE plugin.yaml
#查看helm调用命令是否成功
[root@master helm]# helm cm-push --help
Helm plugin to push chart package to ChartMuseum
Examples:
$ helm cm-push mychart-0.1.0.tgz chartmuseum # push .tgz from "helm package"
$ helm cm-push . chartmuseum # package and push chart directory
$ helm cm-push . --version="1.2.3" chartmuseum # override version in Chart.yaml
$ helm cm-push . https://my.chart.repo.com # push directly to chart repo URL上传本地项目
#命令执行格式
helm cm-push <项目名称> <仓库名称> -u admin -p lee
[root@master helm]# helm cm-push huazi-0.1.0.tgz huazi -u admin -p lee
Pushing huazie-0.1.0.tgz to huazi...
Done.
#查看项目上传情况
[root@master helm]## helm search repo huazi #上传后数据未更新
No results found
#更新仓库
[root@master helm]# helm repo update timinglee
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "timinglee" chart repository
Update Complete. ⎈Happy Helming!⎈
#再次查看
[root@master helm]# helm search repo timinglee
NAME CHART VERSION APP VERSION DESCRIPTION
huazi/huazi 0.1.0 v1 A Helm chart for Kubernetes
#安装项目
[root@master helm]# helm install huazi huazi/huazi
NAME: huazi
LAST DEPLOYED: Tue Sep 10 16:48:14 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:
http://myapp.huazi.org/
[root@master helm]# curl myapp.huazi.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>24.4 helm的版本迭代
从新构建新版本项目
[root@master helm]# vim huazi/Chart.yaml
version: 0.2.0
appVersion: "v2"[root@master helm]# vim huazi/values.yaml
tag: "v2"[root@master helm]# helm package huazi
Successfully packaged chart and saved it to: /root/helm/huazi-0.2.0.tgz
上传项目到helm仓库中
[root@master helm]# helm cm-push huazi-0.2.0.tgz huazi -u admin -p lee
Pushing huazi-0.2.0.tgz to timinglee...
Done.[root@master helm]# helm cm-push huazi-0.2.0.tgz huazi -u admin -p lee
Pushing huazi-0.2.0.tgz to huazi...
Done.[root@master helm]# helm repo update huazi
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "huazi" chart repository
Update Complete. ⎈Happy Helming!⎈
[root@master helm]# helm search repo[root@master helm]# helm search repo huazi -l
NAME CHART VERSION APP VERSION DESCRIPTION
huazi/huazi 0.2.0 v2 A Helm chart for Kubernetes
huazi/huazi 0.1.0 v1 A Helm chart for Kubernetes
更新应用
#1.更新
[root@master helm]# helm upgrade huazi huazi/huazi
Release "huazi" has been upgraded. Happy Helming!
NAME: huazi
LAST DEPLOYED: Tue Sep 10 16:55:29 2024
NAMESPACE: default
STATUS: deployed
REVISION: 2
NOTES:
1. Get the application URL by running these commands:
http://myapp.huazi.org/[root@master helm]# curl http://myapp.huazi.org/
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>#显示项目版本
[root@master helm]# helm history huazi
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Tue Sep 10 16:48:14 2024 superseded huazi-0.1.0 v1 Install complete
2 Tue Sep 10 16:55:29 2024 deployed huazi-0.2.0 v2 Upgrade complete
#2.应用回滚
[root@master helm]# helm rollback huazi
Rollback was a success! Happy Helming!
[root@master helm]# helm history huazi
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Tue Sep 10 16:48:14 2024 superseded huazi-0.1.0 v1 Install complete
2 Tue Sep 10 16:55:29 2024 superseded huazi-0.2.0 v2 Upgrade complete
3 Tue Sep 10 16:57:12 2024 deployed huazi-0.1.0 v1 Rollback to 1[root@master helm]# curl myapp.huazi.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
25. Prometheus
Prometheus是一个开源的服务监控系统和时序数据库
其提供了通用的数据模型和快捷数据采集、存储和查询接口
它的核心组件Prometheus服务器定期从静态配置的监控目标或者基于服务发现自动配置的目标中进行拉取数据
新拉取到啊的 数据大于配置的内存缓存区时,数据就会持久化到存储设备当
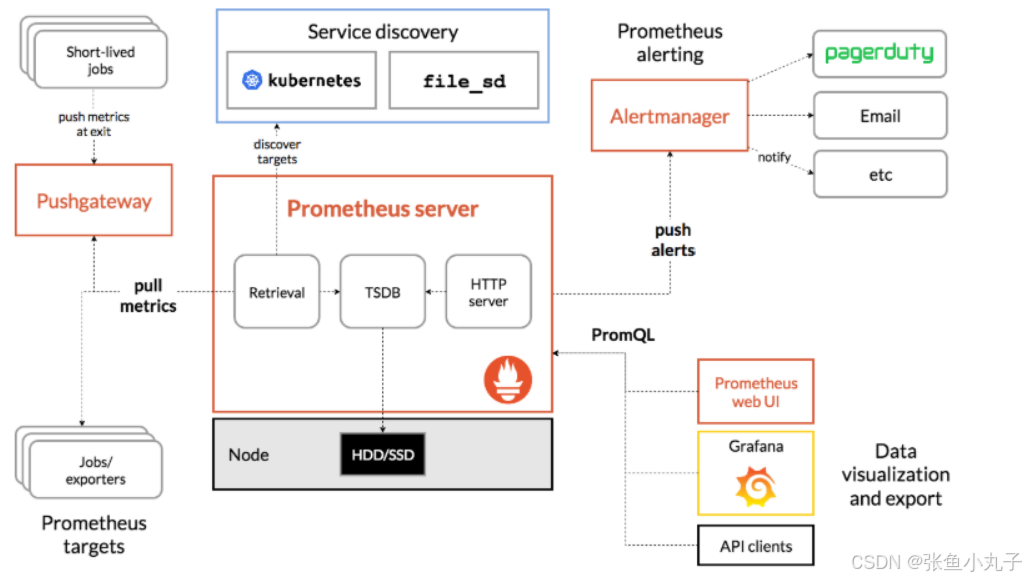
组件功能:
监控代理程序:如node_exporter:收集主机的指标数据,如平均负载、CPU、内存、磁盘、网络等等多个维度的指标数据。
kubelet(cAdvisor):收集容器指标数据,也是K8S的核心指标收集,每个容器的相关指标数据包括:CPU使用率、限额、文件系统读写限额、内存使用率和限额、网络报文发送、接收、丢弃速率等等。
API Server:收集API Server的性能指标数据,包括控制队列的性能、请求速率和延迟时长等等
etcd:收集etcd存储集群的相关指标数据
kube-state-metrics:该组件可以派生出k8s相关的多个指标数据,主要是资源类型相关的计数器和元数据信息,包括制定类型的对象总数、资源限额、容器状态以及Pod资源标签系列等。
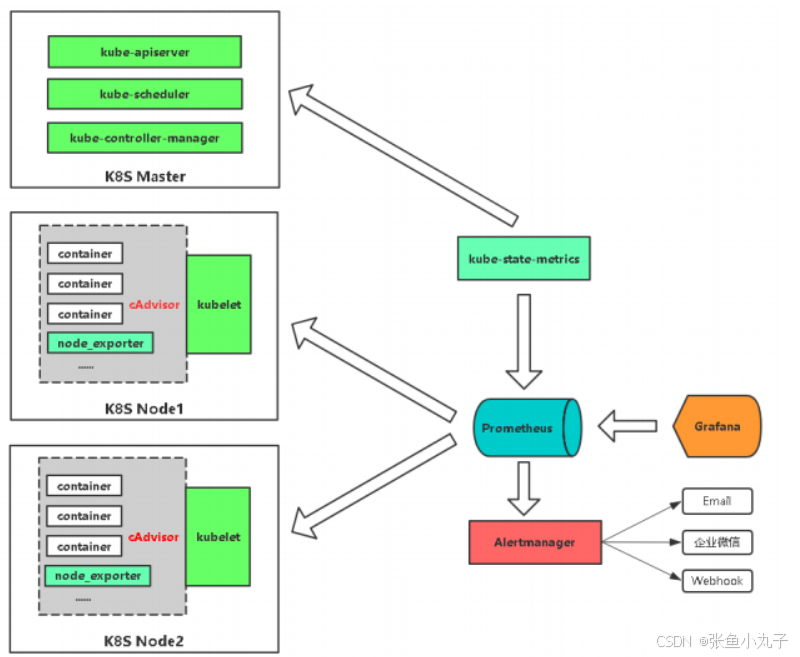
每个被监控的主机都可以通过专用的
exporter程序提供输出监控数据的接口,并等待Prometheus服务器周期性的进行数据抓取如果存在告警规则,则抓取到数据之后会根据规则进行计算,满足告警条件则会生成告警,并发送到
Alertmanager完成告警的汇总和分发当被监控的目标有主动推送数据的需求时,可以以
Pushgateway组件进行接收并临时存储数据,然后等待Prometheus服务器完成数据的采集任何被监控的目标都需要事先纳入到监控系统中才能进行时序数据采集、存储、告警和展示
监控目标可以通过配置信息以静态形式指定,也可以让Prometheus通过服务发现的机制进行动态管理
加载grafana-11.2.0.tar
查看
加载node-exporter-v1.8.2.tar

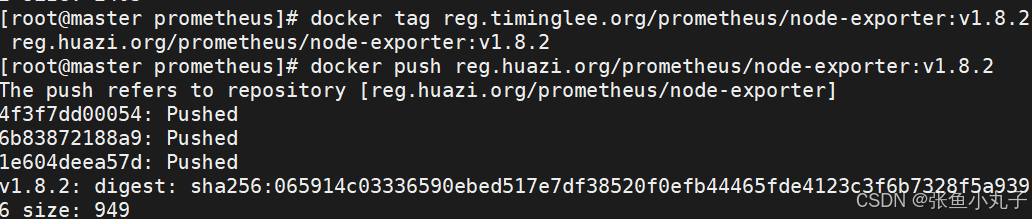
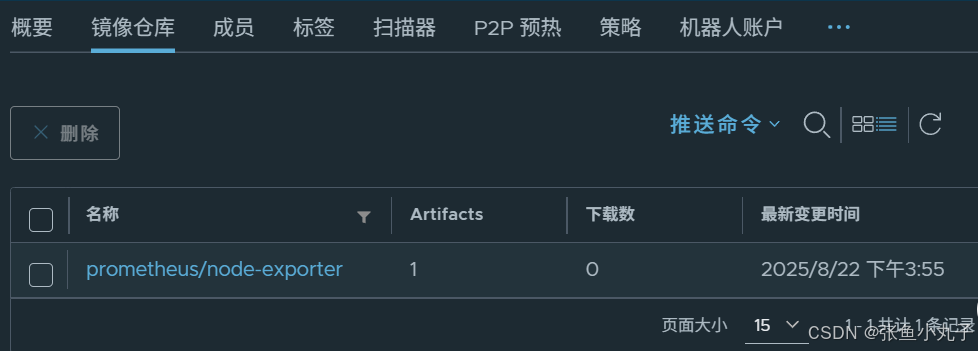
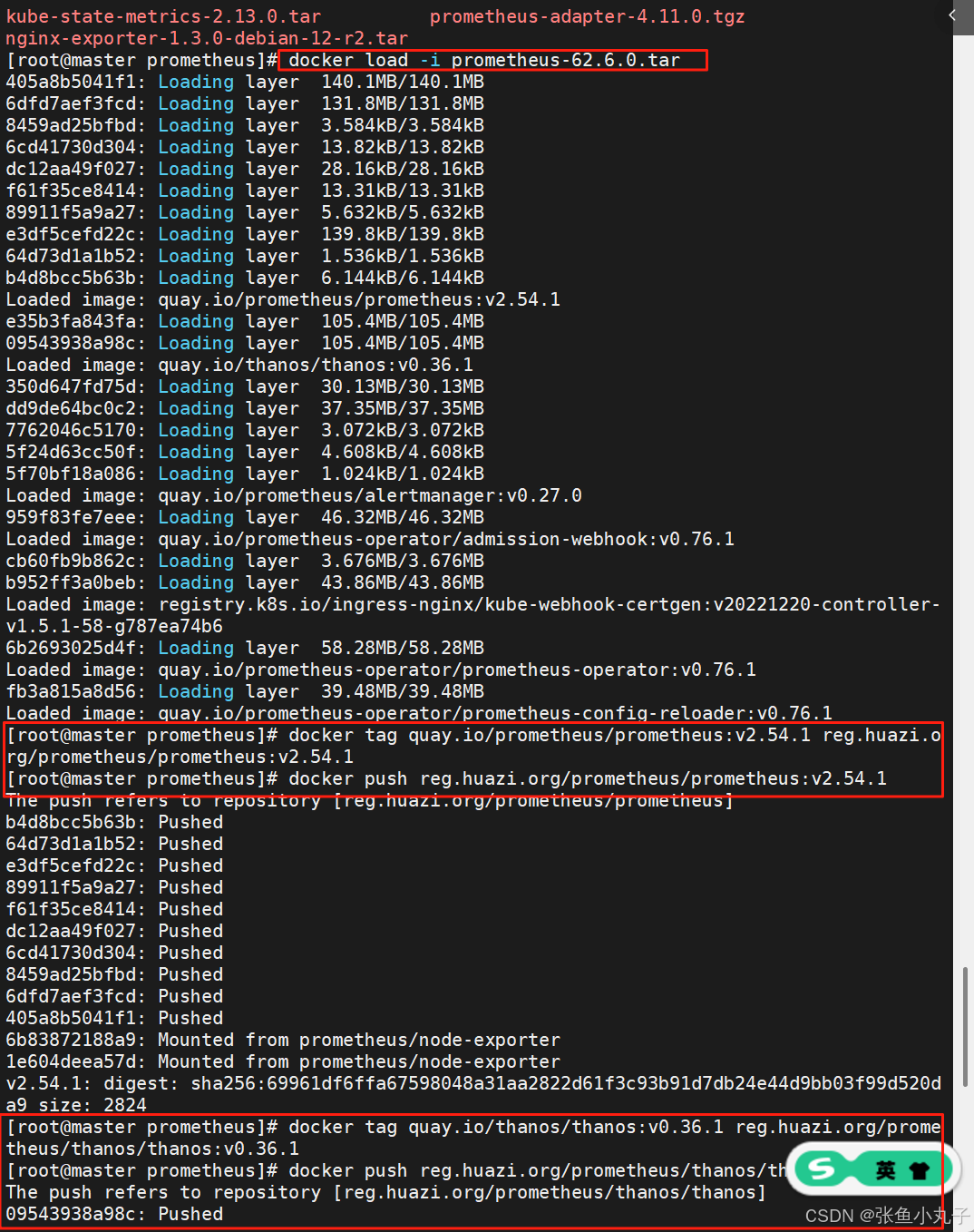
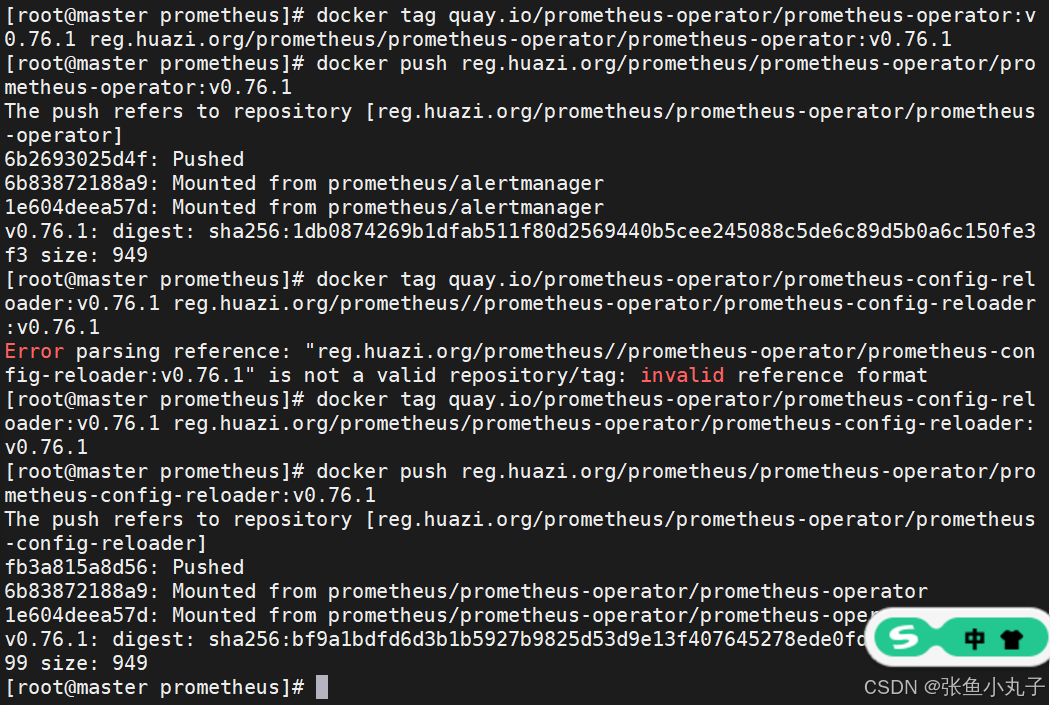
加载prometheus-62.6.0.tar
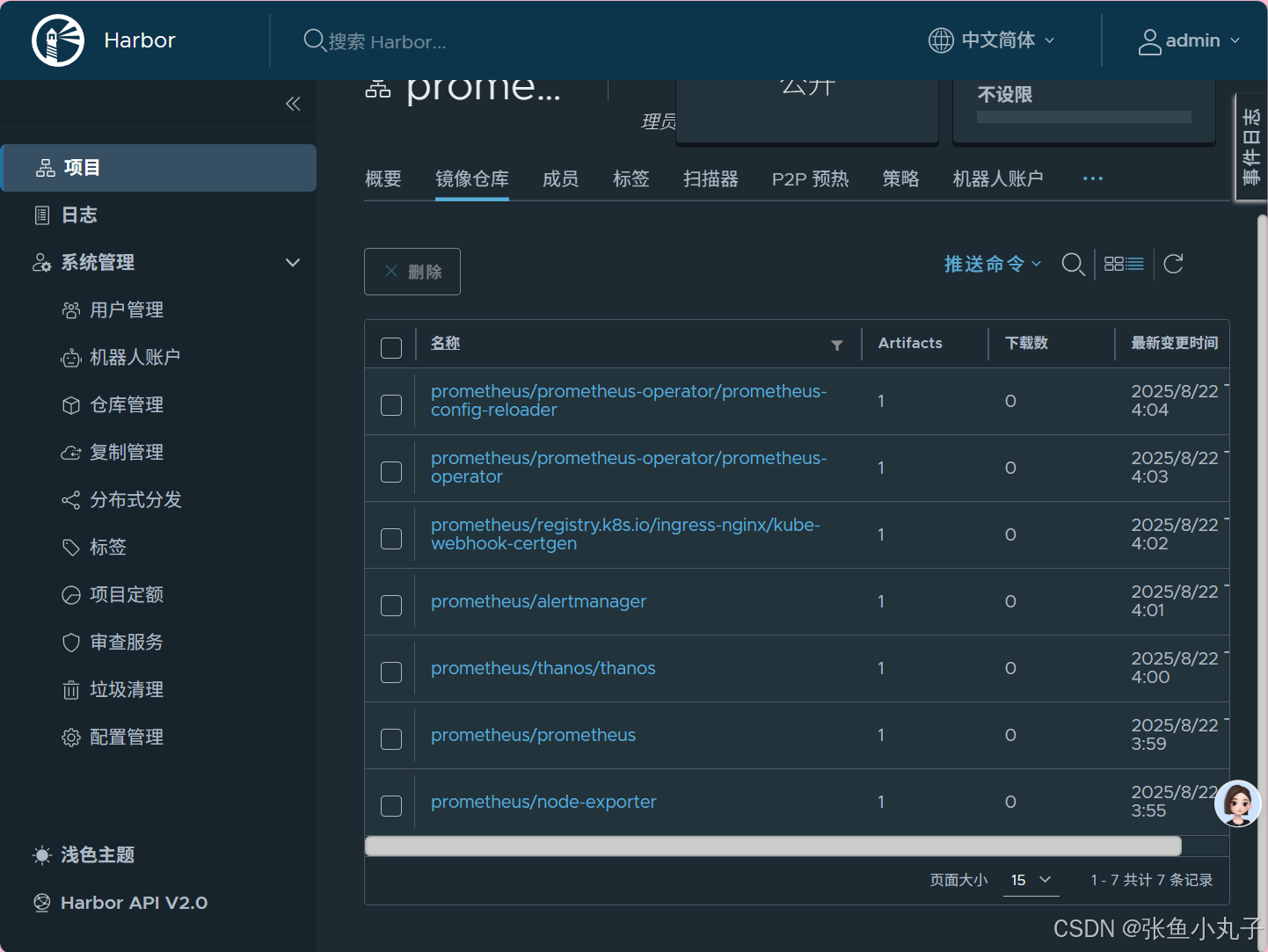
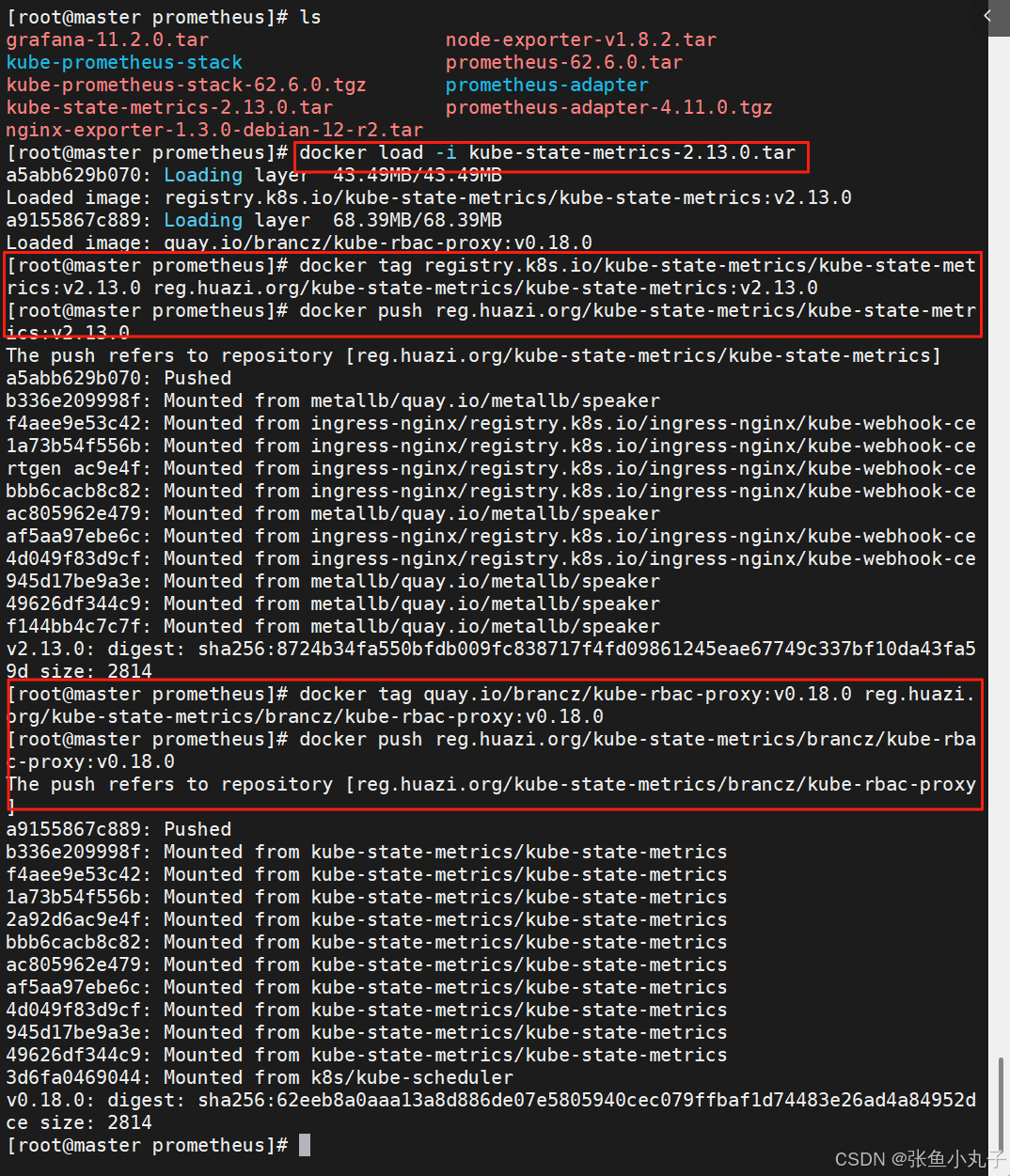
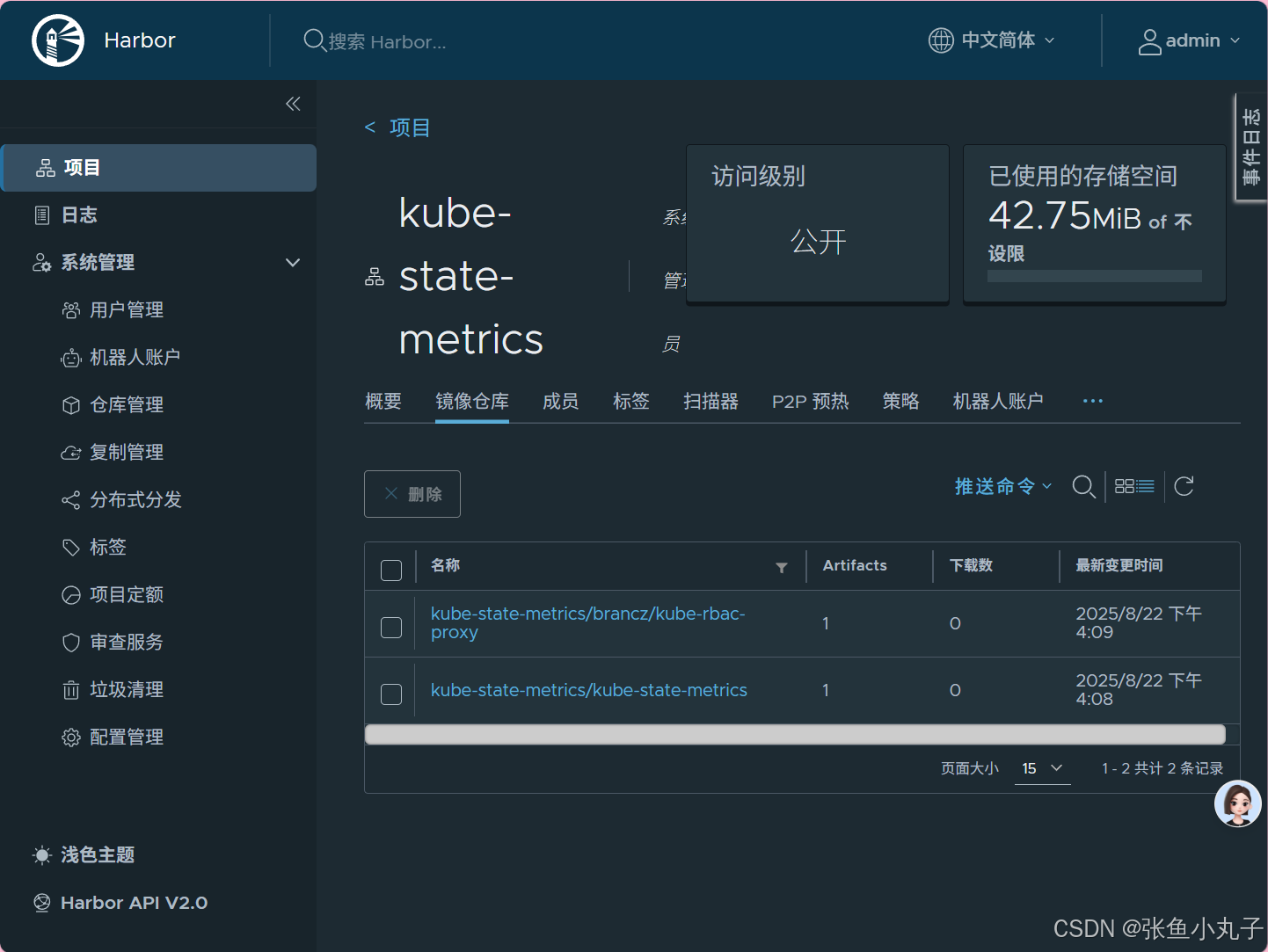
加载kube-state-metrics-2.13.0.tar
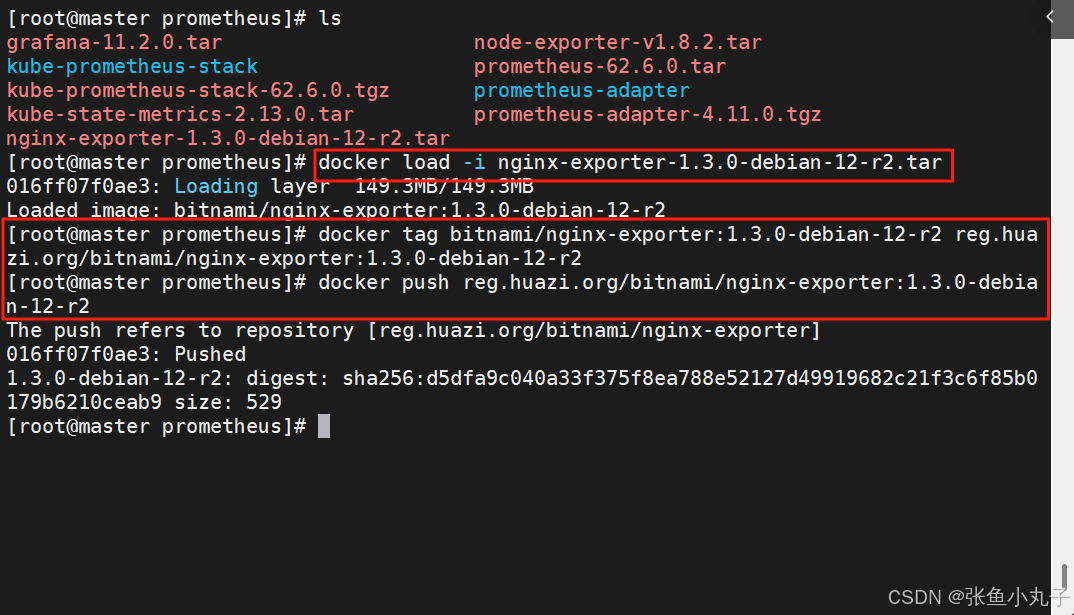
加载nginx-exporter-1.3.0-debian-12-r2.tar
修改yaml文件

利用helm安装Prometheus,注意,在安装过程中千万别ctrl+c
26. CICD
26.1 简介
CI/CD 是指持续集成(Continuous Integration)和持续部署(Continuous Deployment)或持续交付(Continuous Delivery)
持续集成(Continuous Integration)
持续集成是一种软件开发实践,团队成员频繁地将他们的工作集成到共享的代码仓库中。其主要特点包括:
频繁提交代码:开发人员可以每天多次提交代码,确保代码库始终保持最新状态。
自动化构建:每次提交后,自动触发构建过程,包括编译、测试、静态分析等。
快速反馈:如果构建失败或测试不通过,能够快速地向开发人员提供反馈,以便及时修复问题。
持续部署(Continuous Deployment)
持续部署是在持续集成的基础上,将通过所有测试的代码自动部署到生产环境中。其特点如下:
自动化流程:从代码提交到生产环境的部署完全自动化,无需人工干预。
高频率部署:可以实现频繁的部署,使得新功能能够快速地提供给用户。
风险控制:需要有强大的测试和监控体系来确保部署的稳定性和可靠性。
持续交付(Continuous Delivery)
持续交付与持续部署类似,但不一定自动部署到生产环境,而是随时可以部署。其重点在于确保软件随时处于可发布状态。
CI/CD 的好处包括:
提高开发效率:减少手动操作和等待时间,加快开发周期。
尽早发现问题:通过频繁的集成和测试,问题能够在早期被发现和解决。
降低风险:减少了大规模部署时可能出现的问题,提高了软件的质量和稳定性。
增强团队协作:促进团队成员之间的沟通和协作,提高团队的整体效率。
常见的 CI/CD 工具包括 Jenkins、GitLab CI/CD、Travis CI 等。这些工具可以帮助团队实现自动化的构建、测试和部署流程。
26.2 git工具使用
git简介
Git 是一个分布式版本控制系统,被广泛用于软件开发中,以管理代码的版本和变更。 主要特点:
-
分布式
-
每个开发者都有完整的代码仓库副本,这使得开发者可以在离线状态下进行工作,并且在网络出现问题时也不会影响开发。
-
即使中央服务器出现故障,开发者仍然可以在本地进行开发和查看项目历史。
-
-
高效的分支管理
-
Git 中的分支创建和切换非常快速和简单。开发人员可以轻松地创建新的分支来进行新功能的开发或修复 bug,而不会影响主分支。
-
合并分支也相对容易,可以使用多种合并策略来满足不同的需求。
-
-
快速的版本回退
-
如果发现某个版本存在问题,可以快速回退到之前的版本。
-
可以查看每个版本的详细变更记录,方便了解代码的演进过程。
-
-
强大的提交管理
-
每个提交都有一个唯一的标识符,可以方便地引用和查看特定的提交。
-
提交可以包含详细的提交信息,描述本次提交的更改内容。
-
-
支持协作开发
-
开发者可以将自己的更改推送到远程仓库,供其他开发者拉取和合并。
-
可以处理多个开发者同时对同一文件进行修改的情况,通过合并冲突解决机制来确保代码的完整性。
-
Git必看秘籍:Git![]() https://git-scm.com/book/zh/v2
https://git-scm.com/book/zh/v2
git 工作流程
Git 有三种状态:已提交(committed)、已修改(modified) 和 已暂存(staged)。
-
已修改表示修改了文件,但还没保存到数据库中。
-
已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
-
已提交表示数据已经安全地保存在本地数据库中。
这会让我们的 Git 项目拥有三个阶段:工作区、暂存区以及 Git 目录。
环境配置
创建一个新的虚拟机,IP地址为172.25.254.50
安装git
设置命令补全功能
初始化
获取 Git 仓库通常有两种方式:
-
将尚未进行版本控制的本地目录转换为 Git 仓库。
-
从其它服务器克隆 一个已存在的 Git 仓库。比如: git clone
初始化版本库

设定用户信息

查看当前文件状态

简化输出

.git目录是git跟踪管理版本库的,没事别瞎溜达
以上全部操作(可复制)
[root@gitlab ~]# mkdir huazi
[root@gitlab ~]# cd huazi/
[root@gitlab huazi]# echo "source /usr/share/bash-completion/completions/git" >> ~/.bashrc
[root@gitlab huazi]# source ~/.bashrc
[root@gitlab huazi]# git init
hint: Using 'master' as the name for the initial branch. This default branch name
hint: is subject to change. To configure the initial branch name to use in all
hint: of your new repositories, which will suppress this warning, call:
hint:
hint: git config --global init.defaultBranch <name>
hint:
hint: Names commonly chosen instead of 'master' are 'main', 'trunk' and
hint: 'development'. The just-created branch can be renamed via this command:
hint:
hint: git branch -m <name>
Initialized empty Git repository in /root/huazi/.git/
[root@gitlab huazi]# ls -a
. .. .git
[root@gitlab huazi]# ls .git/
branches config description HEAD hooks info objects refs
[root@gitlab huazi]# git config --global user.name ""
[root@gitlab huazi]# git config --global user.name "huazi"
[root@gitlab huazi]# git config --global user.email "huazi@huazi.org"
[root@gitlab huazi]# git status
On branch master
No commits yet
nothing to commit (create/copy files and use "git add" to track)
[root@gitlab huazi]# git status -s
[root@gitlab huazi]#
常用方法
提交暂存区的数据

无任何显示,标识已经提交到版本库

右M 表示文件在工作区被修改
撤销修改
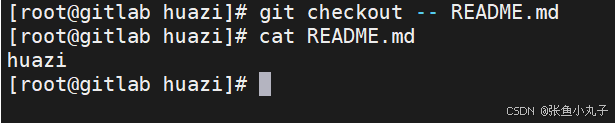
从新修改

从暂存区撤销

从新提交

更新

更新文件
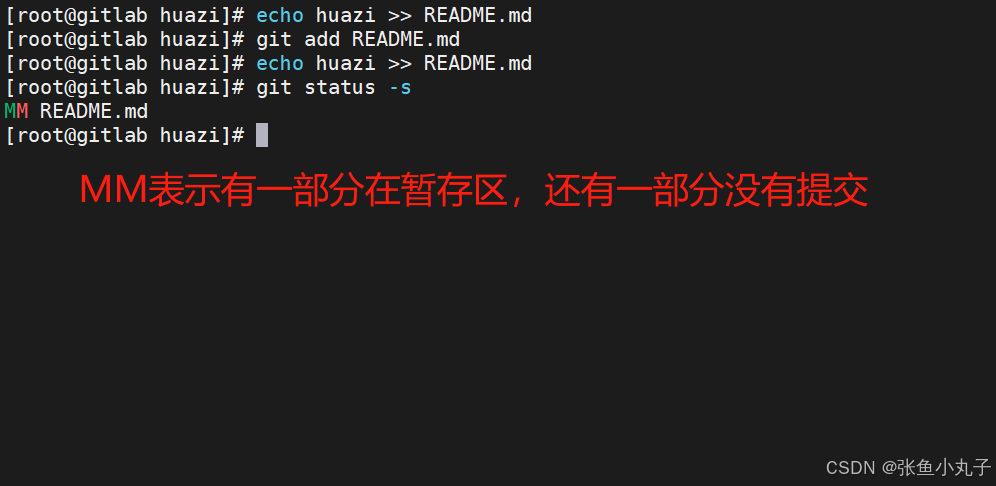
如果现在提交只能提交在暂存区中的部分
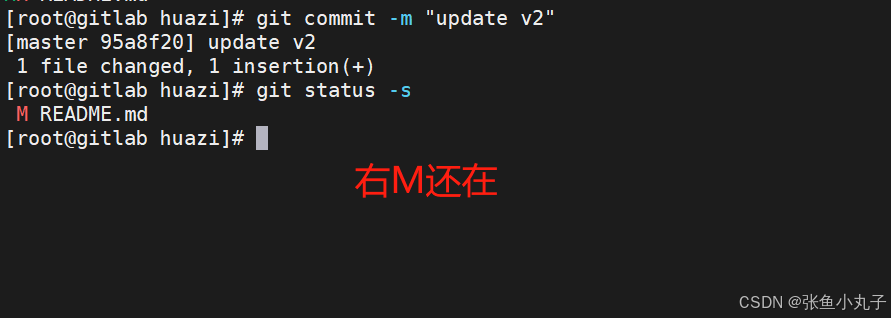
查看已暂存和未暂存的修改变化
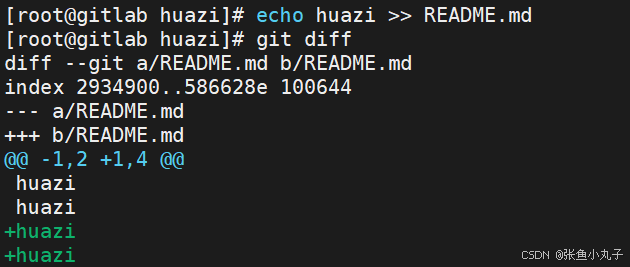
跳过使用暂存区,只能在提交过的在版本库中存在的文件使用如果文件状态是“??”不能用此方法

撤销工作区中删除动作
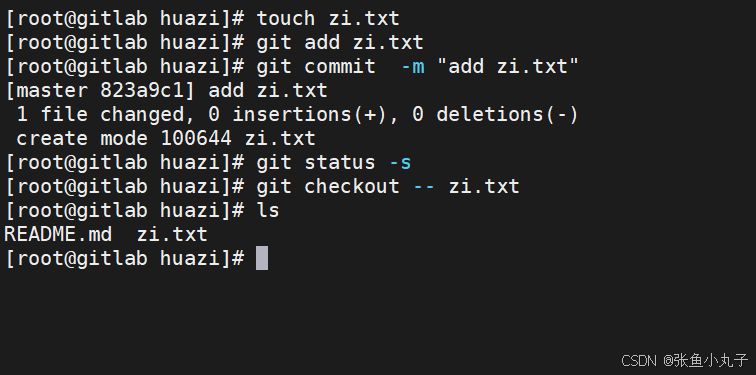
从版本库中删除文件
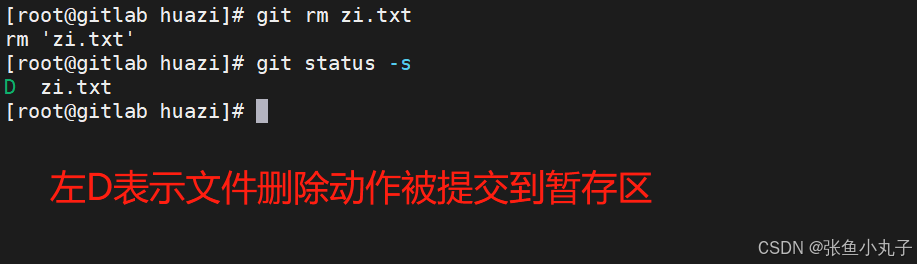

恢复从版本库中被删除的文件
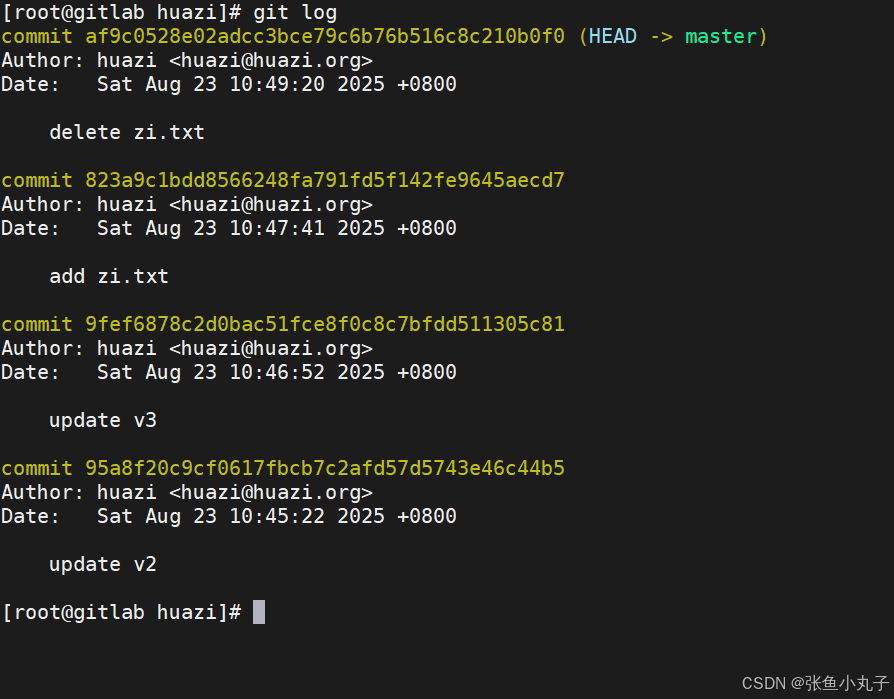
查看提交动作

版本回退到删除之前

26.3 gitlab代码仓库

-
GitLab 是一个用于仓库管理系统的开源项目,使用 Git 作为代码管理工具,并在此基础上搭建起来的 web 服务。
-
GitLab 具有很多功能,比如代码托管、持续集成和持续部署(CI/CD)、问题跟踪、合并请求管理等。它可以帮助开发团队更好地协作开发软件项目,提高开发效率和代码质量。
官网:https://about.gitlab.com/install/
中文站点: GitLab下载安装_GitLab安装和配置_GitLab最新中文官网免费版下载-极狐GitLab
官方包地址:gitlab/gitlab-ce - Packages · packages.gitlab.com
部署gitlab
部署gitlab需要内存大于4G,在安装包之前需配置好软件仓库来解决依赖性
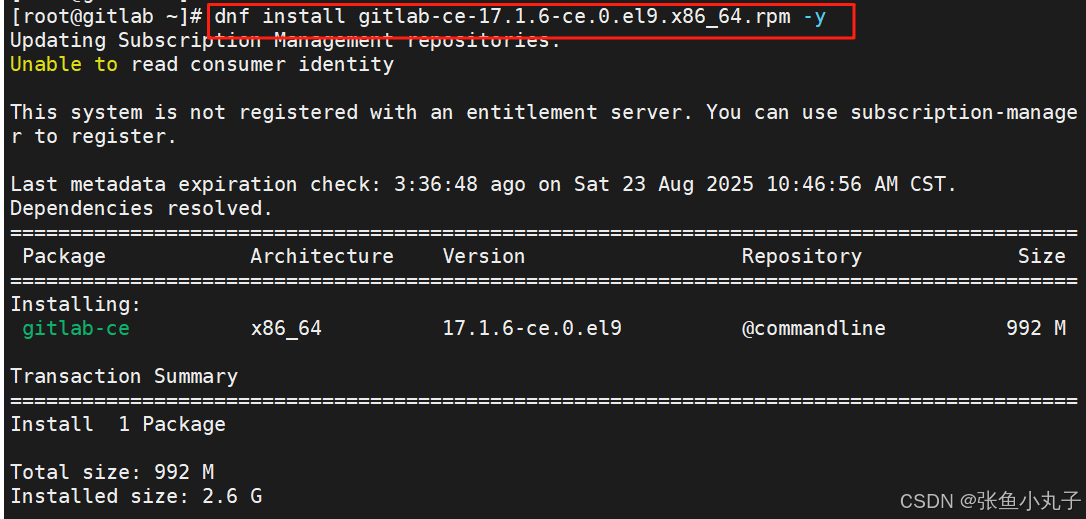
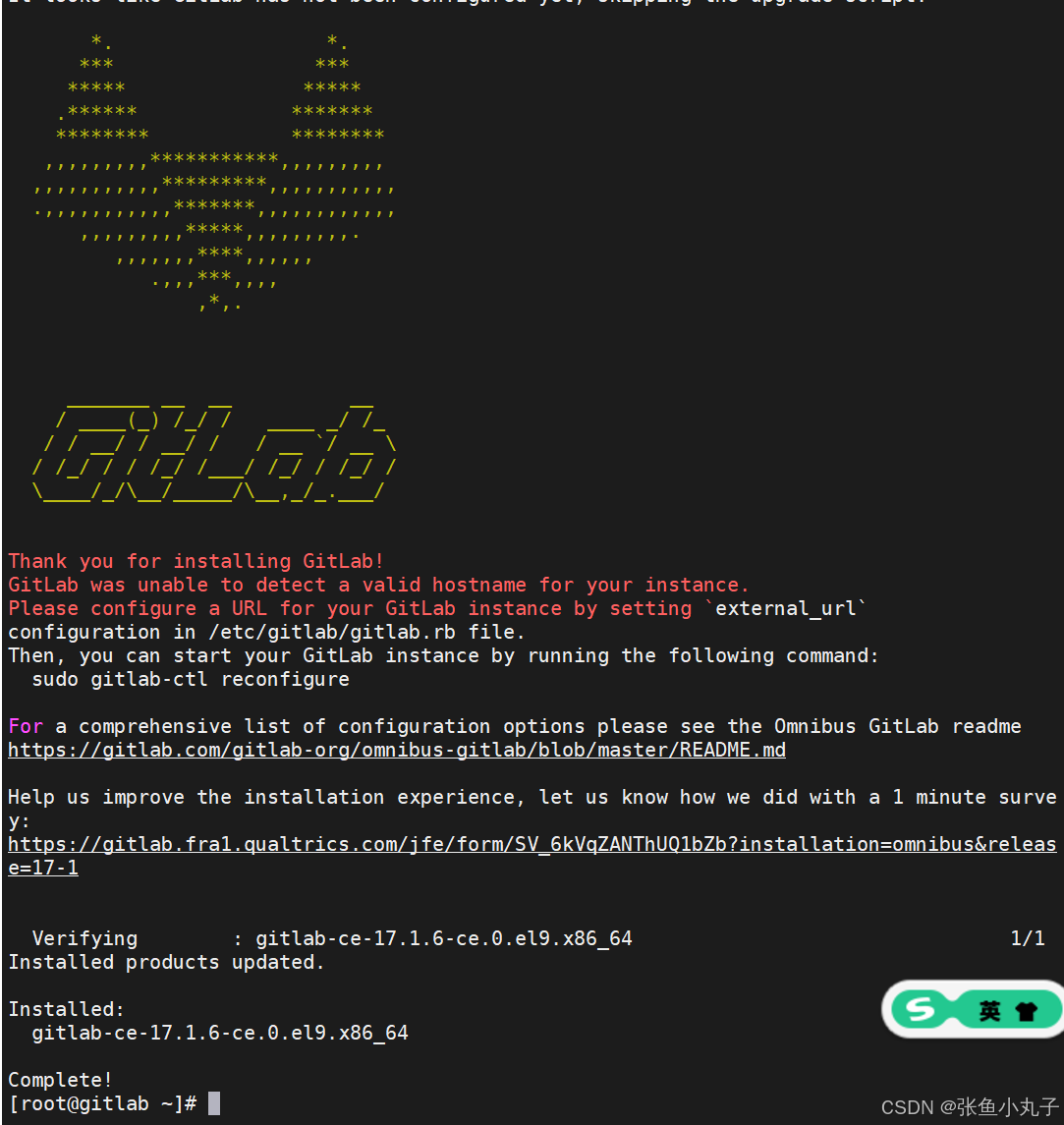
修改配置文件
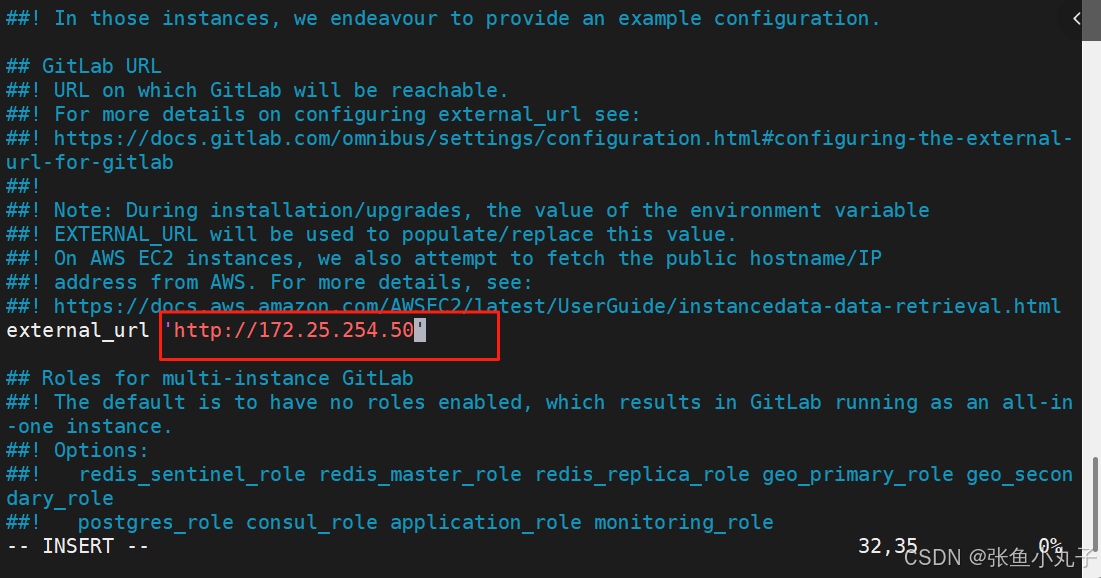
修改配置文件后需利用gitlab-crt来生效
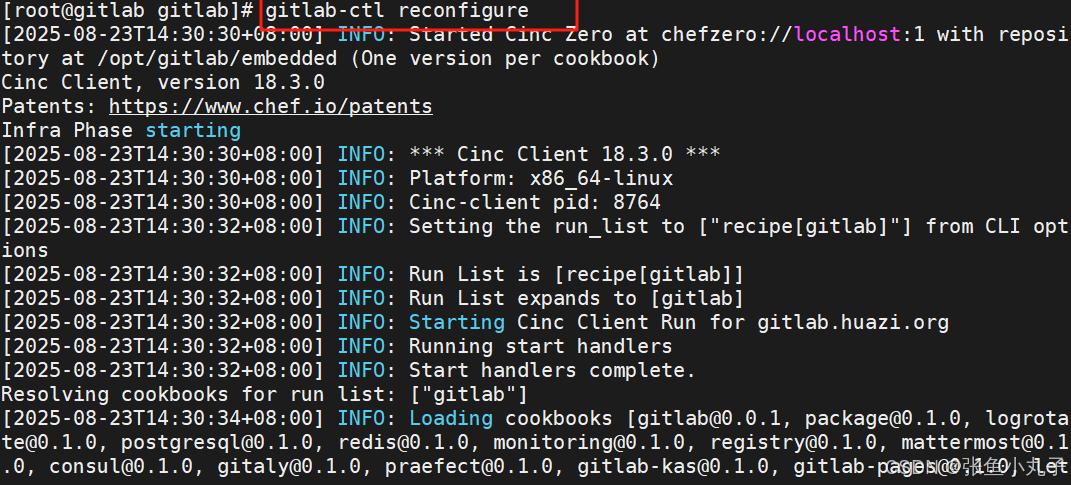
执行命令成功后会把所有组件全部启动起来,等待完成即可
登陆gitlab
用户名默认为
root。如果在安装过程中指定了初始密码,则用初始密码登录,如果未指定密码,则系统会随机生成一个密码并存储在/etc/gitlab/initial_root_password文件中, 查看随机密码并使用root用户名登录。注意:出于安全原因,24 小时后,
/etc/gitlab/initial_root_password会被第一次gitlab-ctl reconfigure自动删除,因此若使用随机密码登录,建议安装成功初始登录成功之后,立即修改初始密码。
查看原始密码
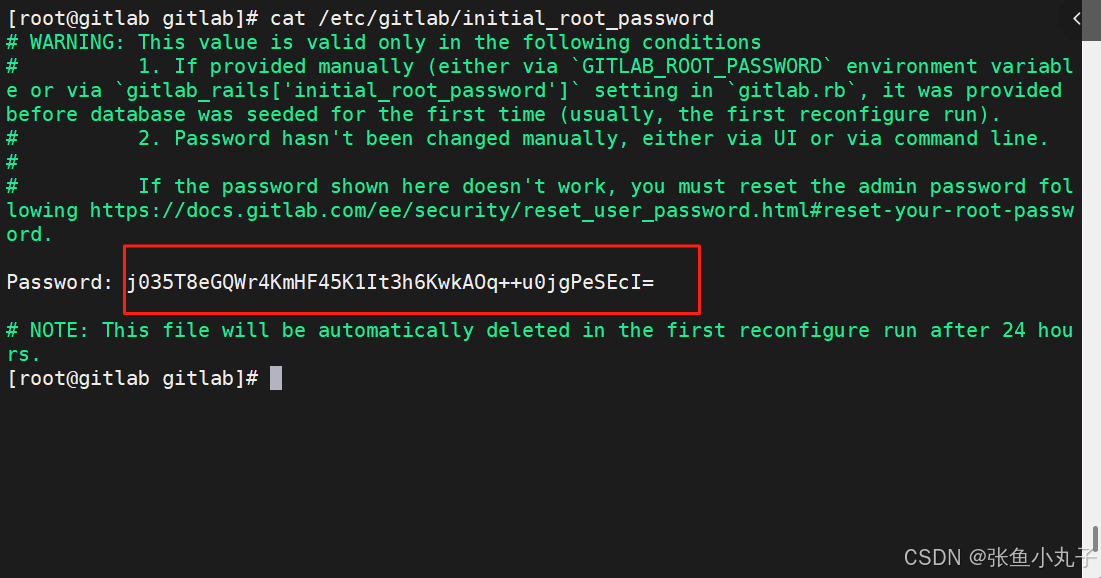
登录
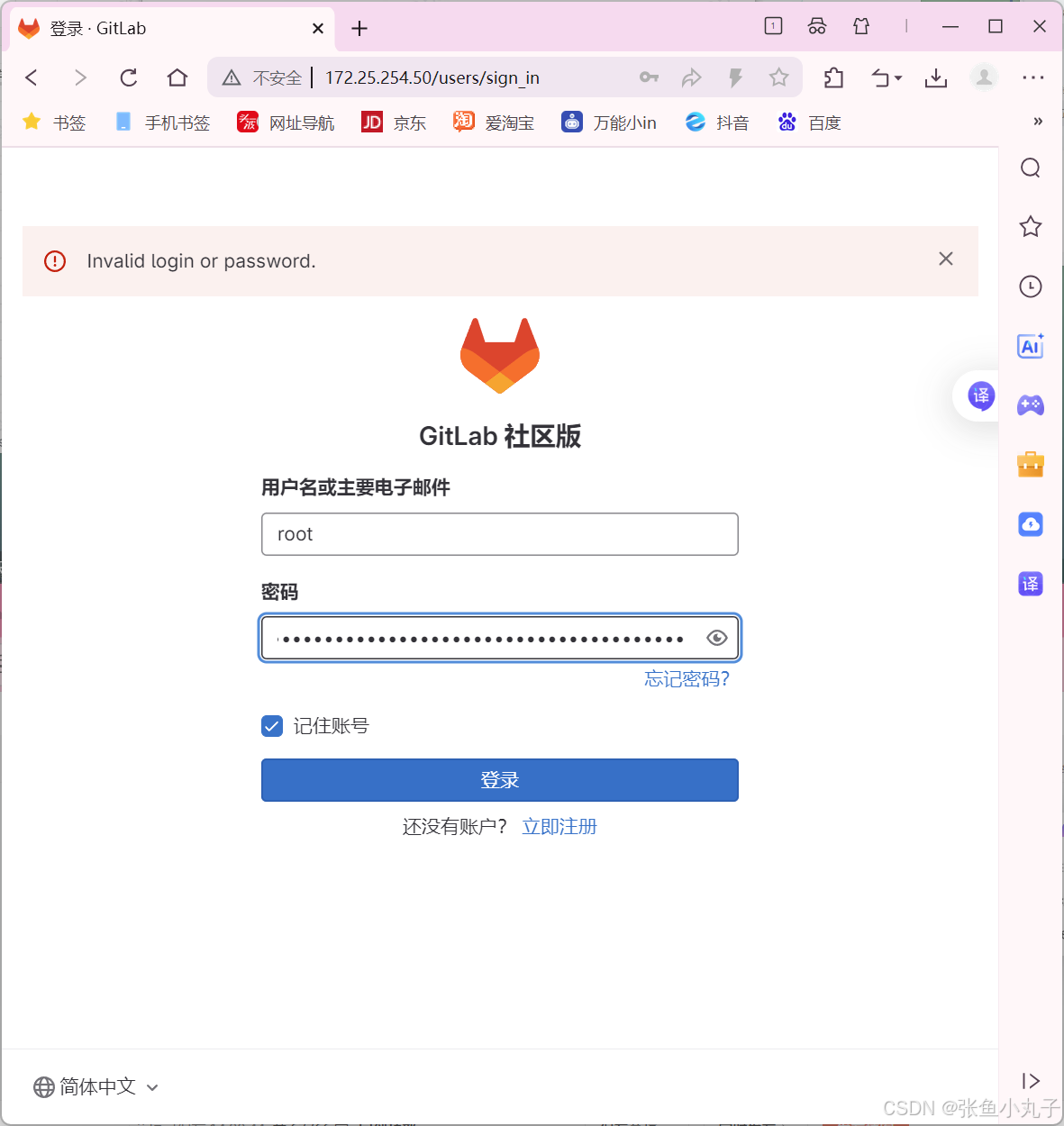
修改密码
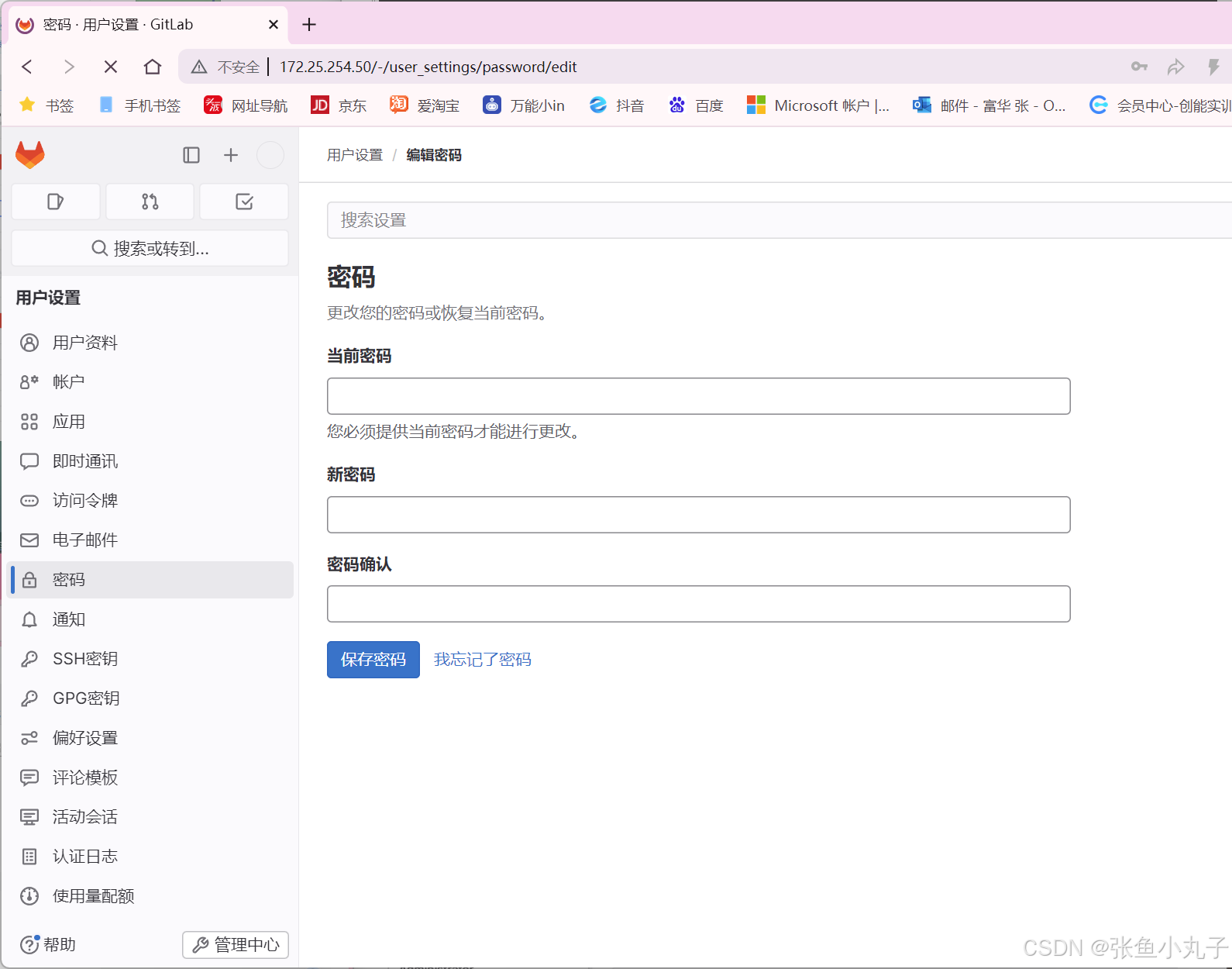
新建项目
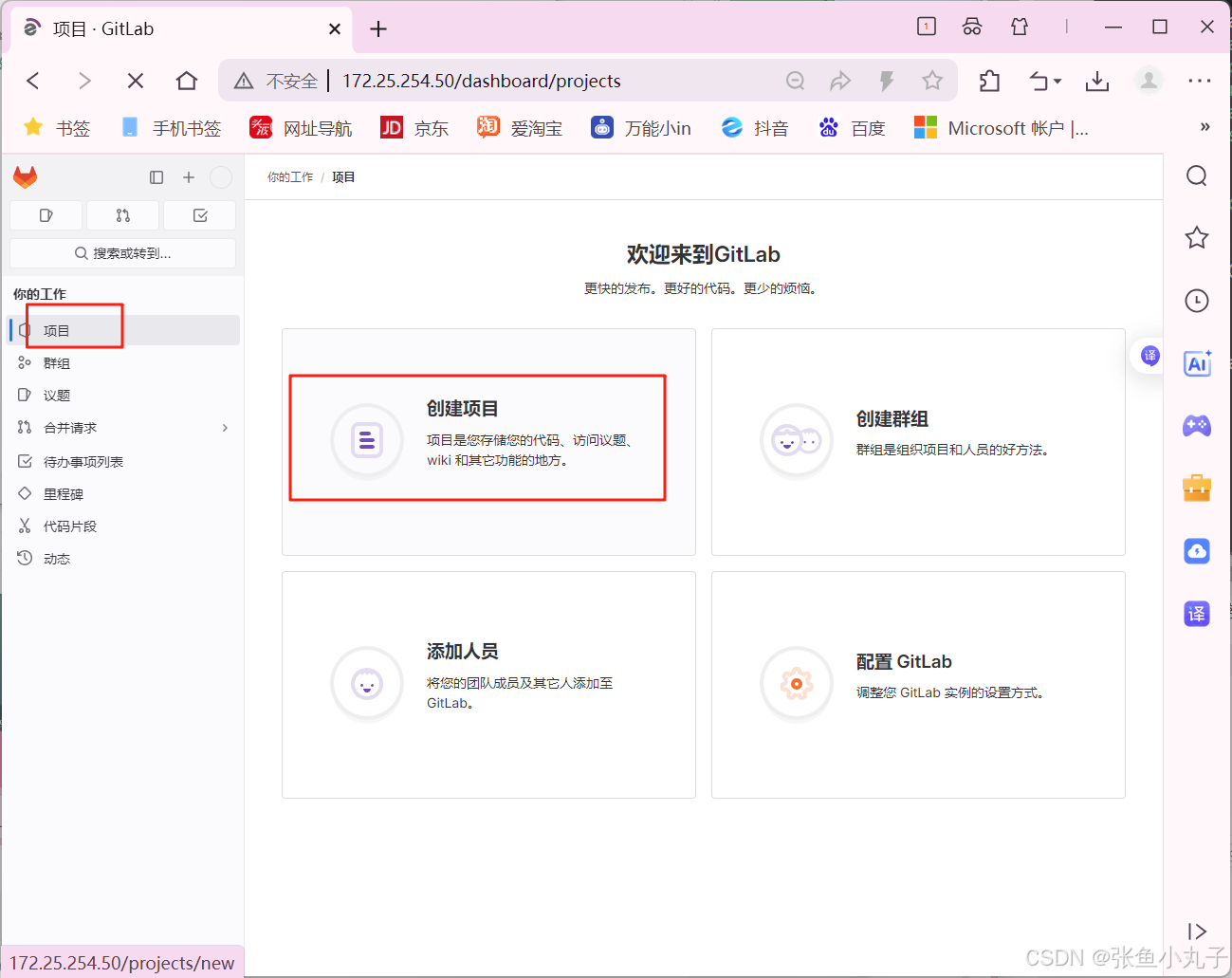
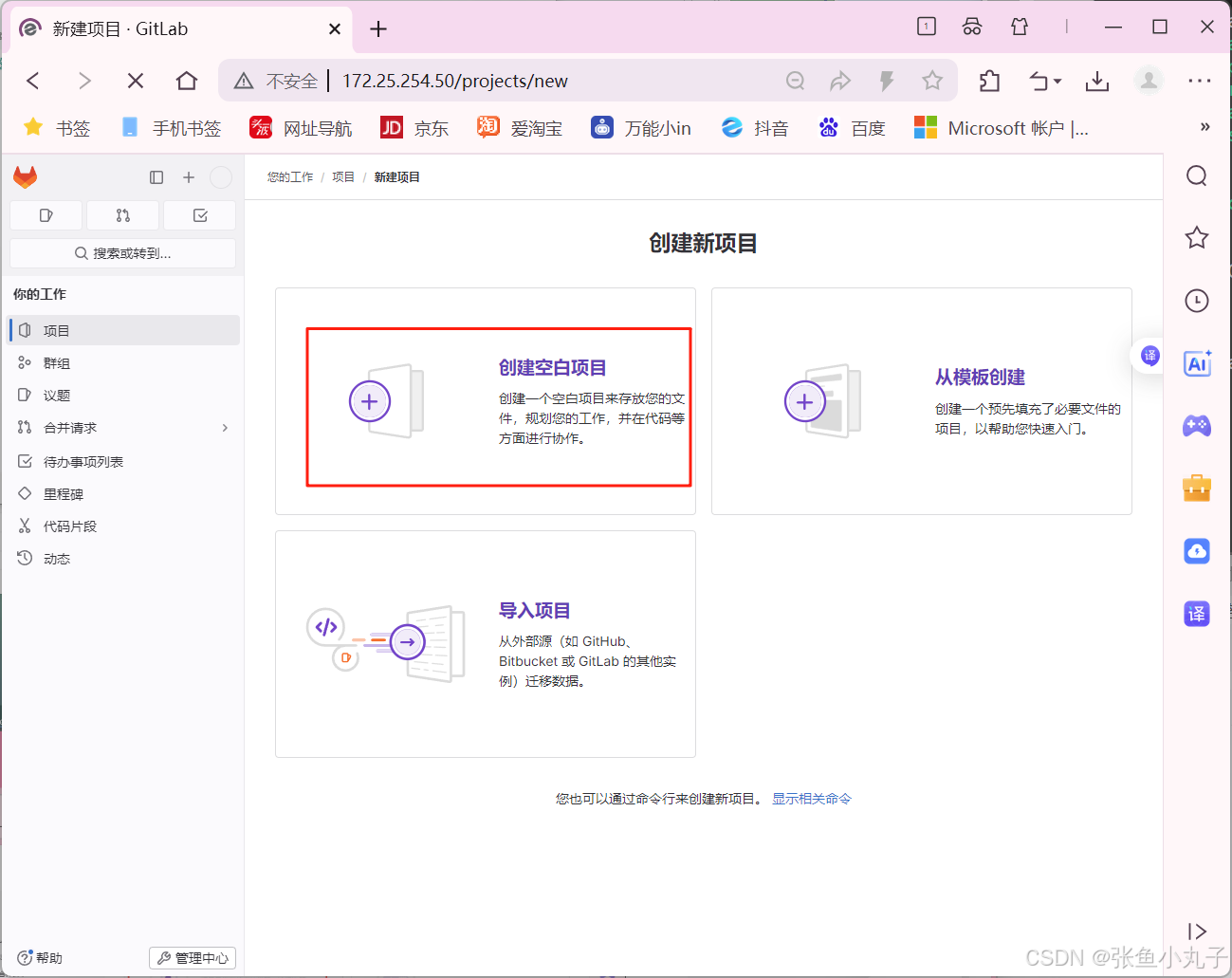
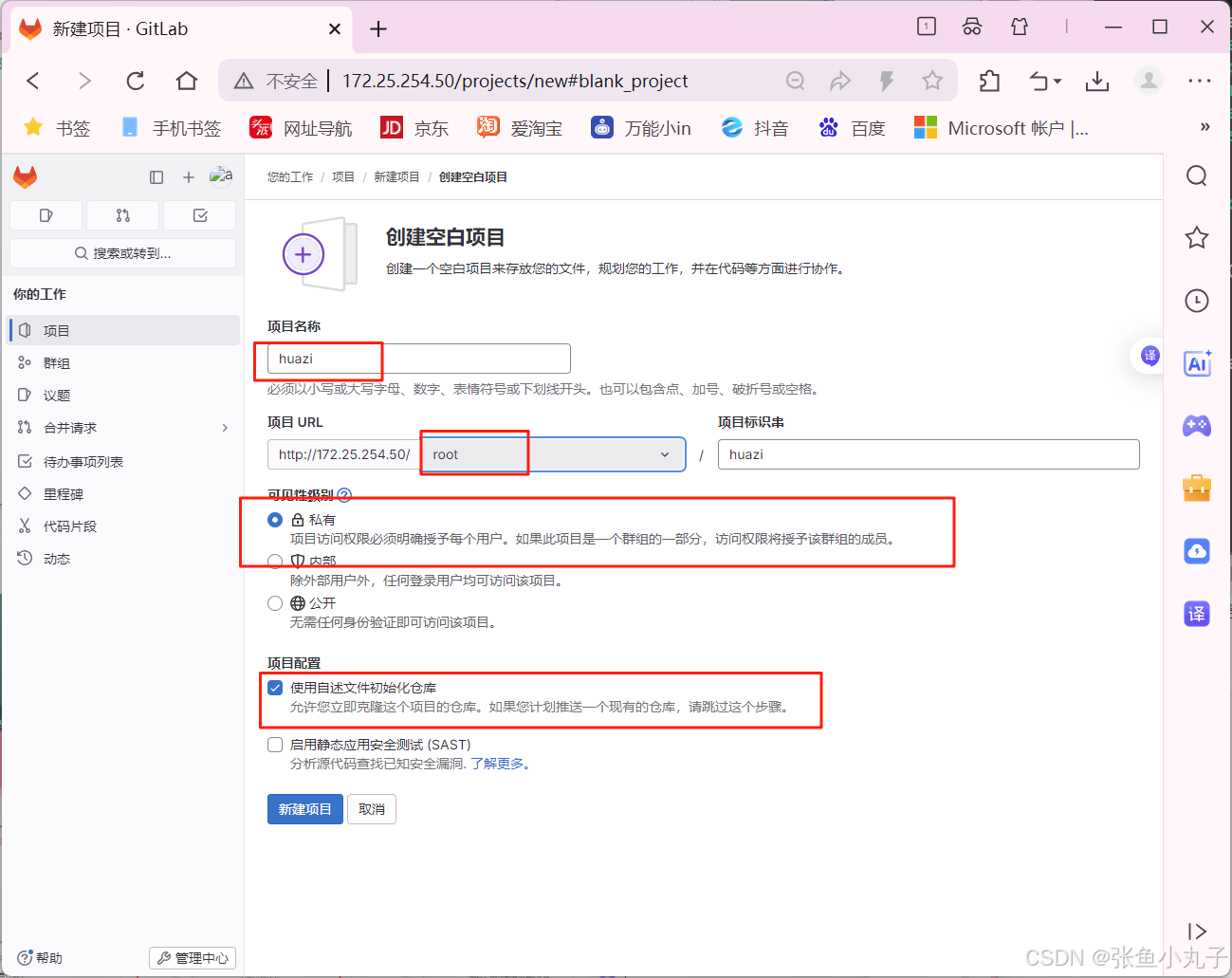
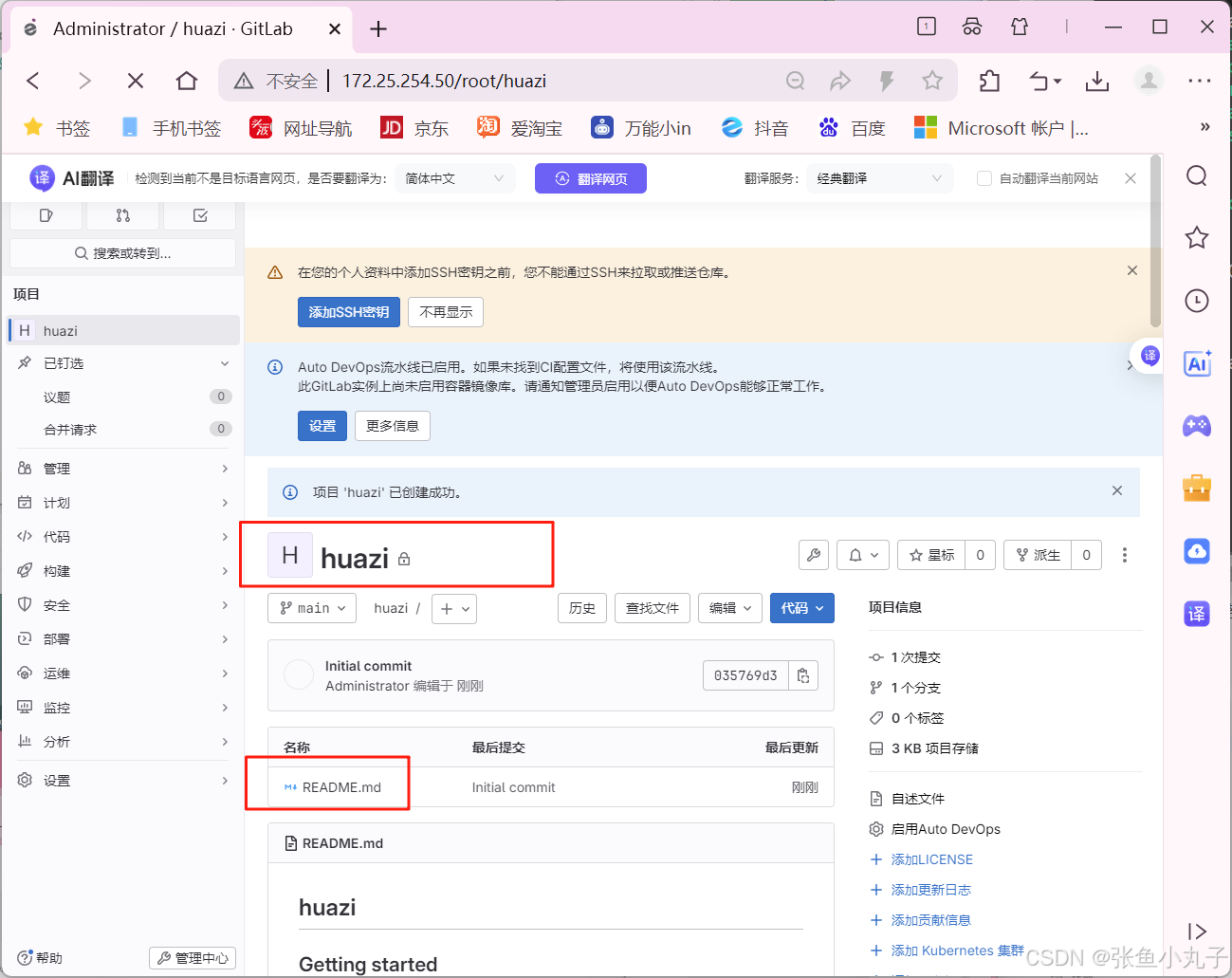
生成sshd秘钥
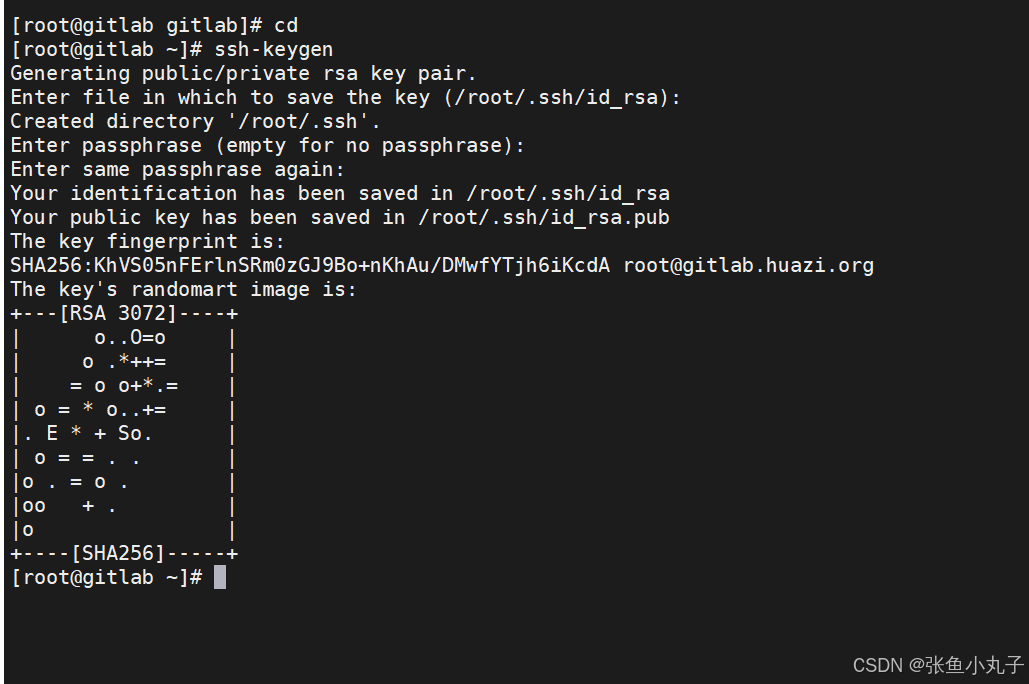
上传公钥到gitlab中
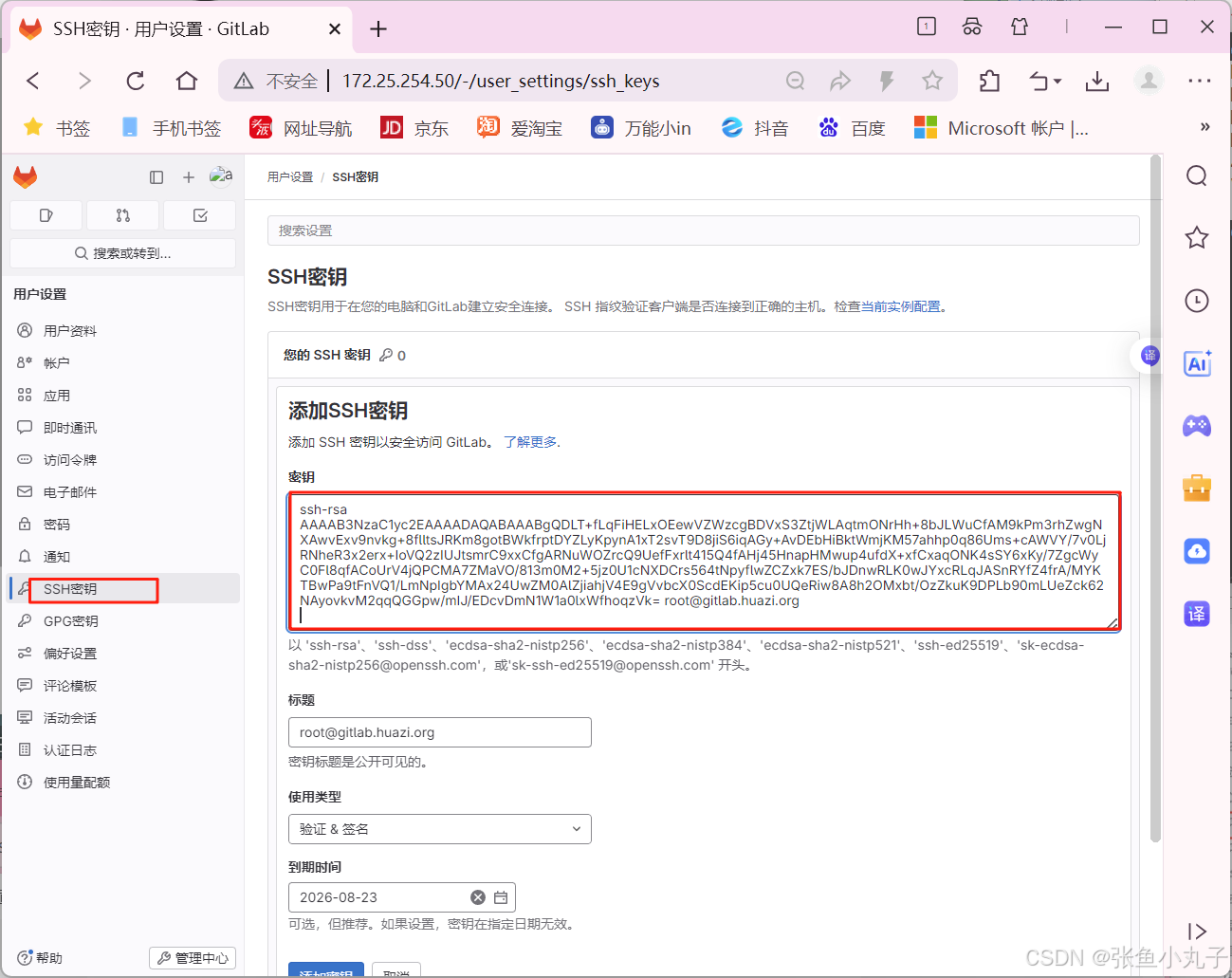
下载项目
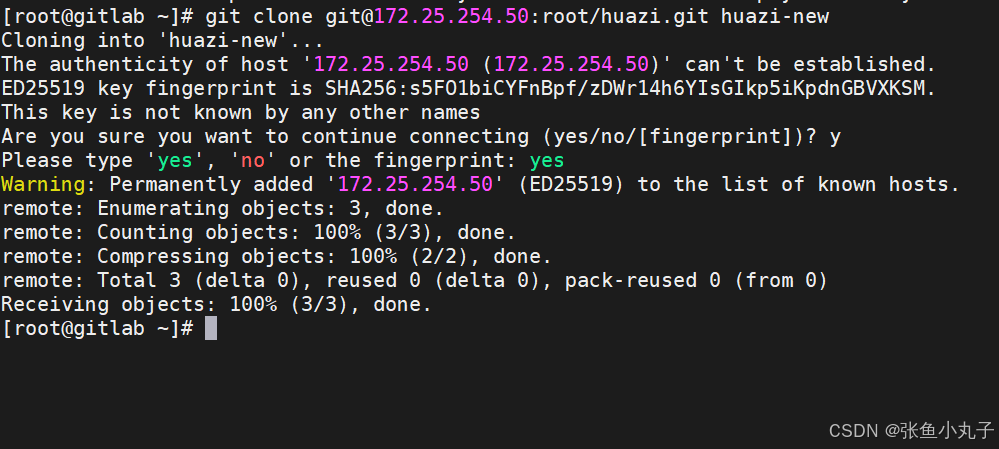
26.4 jenkins

-
Jenkins是开源CI&CD软件领导者, 提供超过1000个插件来支持构建、部署、自动化, 满足任何项目的需要。
-
Jenkins用Java语言编写,可在Tomcat等流行的servlet容器中运行,也可独立运行
CI(Continuous integration持续集成)持续集成强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。
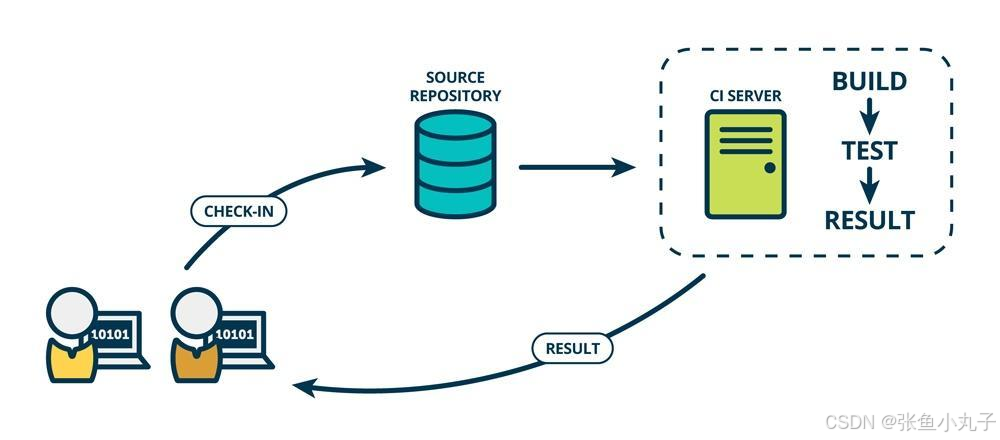
CD(Continuous Delivery持续交付) 是在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境(类生产环境)中
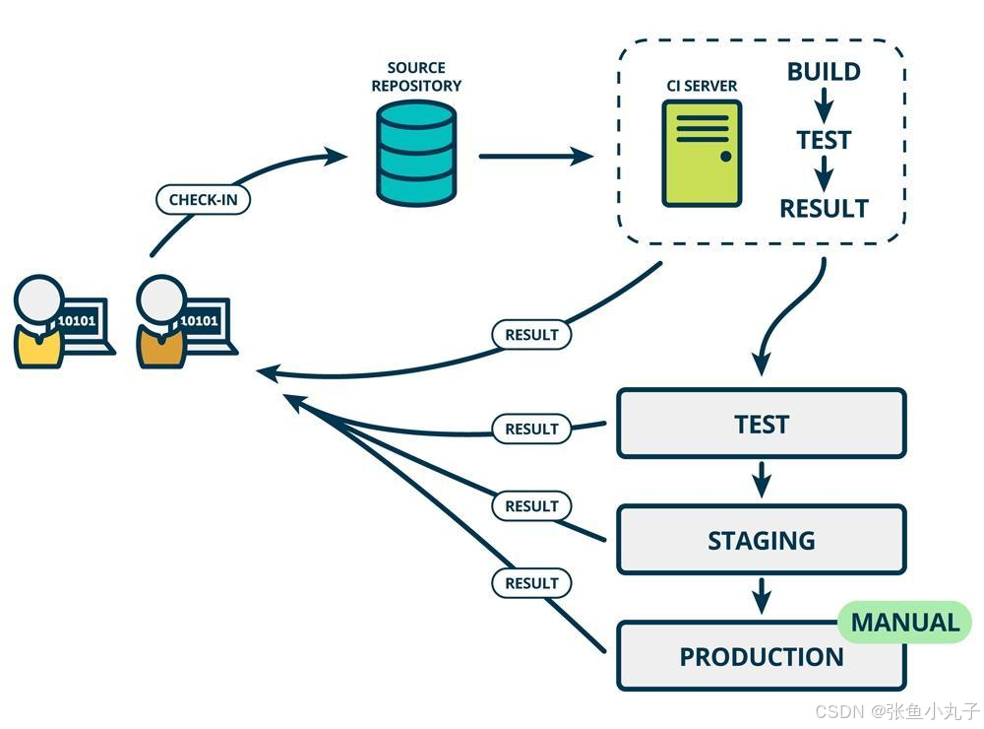
部署
增加一台虚拟机,IP地址为172.25.254.60
jenkins需要部署在新的虚拟机中
[!WARNING]
jenkins需要部署在新的虚拟机中,建议最少4G内存,4核心cpu
[root@jenkins ~]# vim /etc/hosts
安装依赖包还有git
安装jenkins

启动jenkins

查看密码
![]()
部署插件
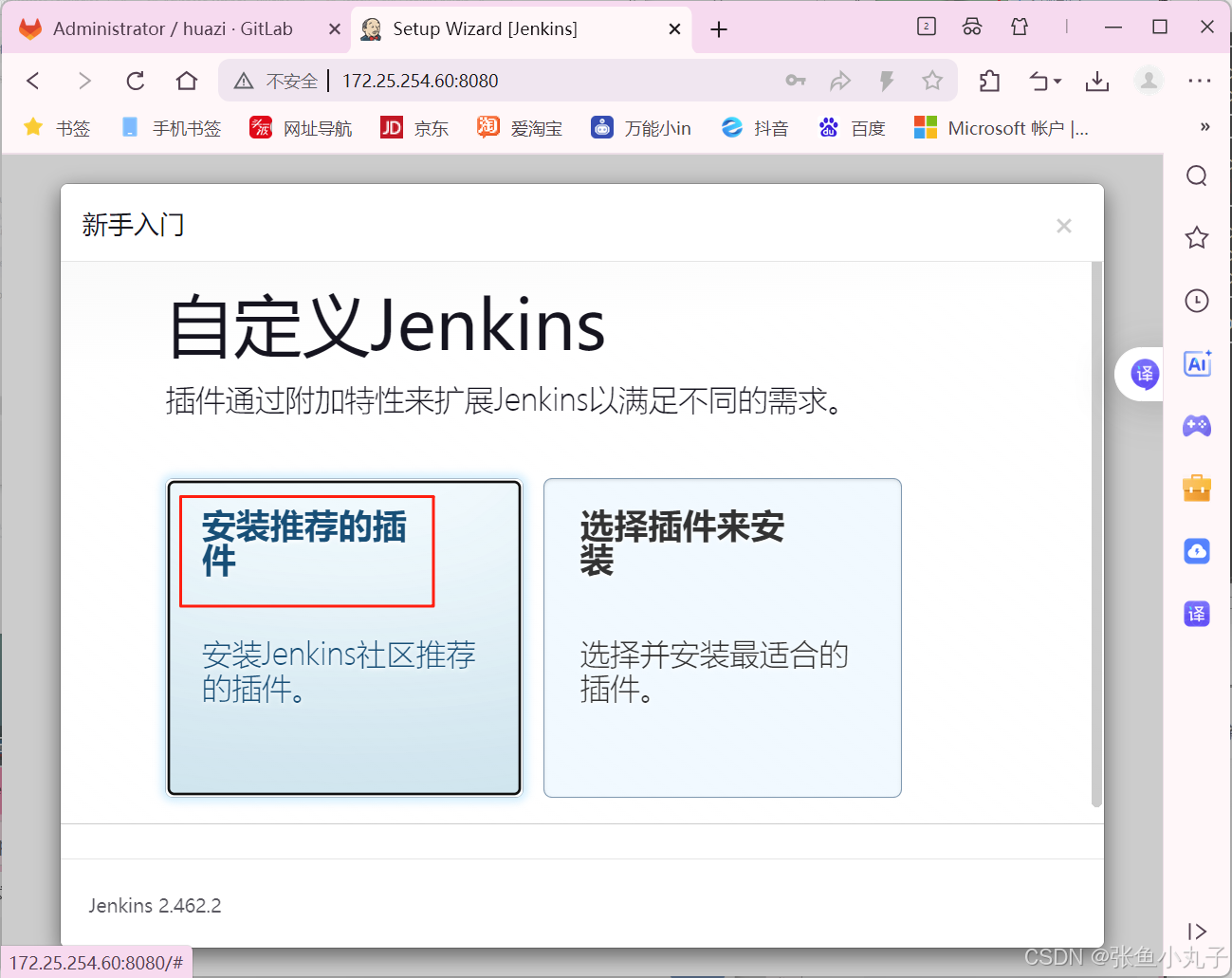
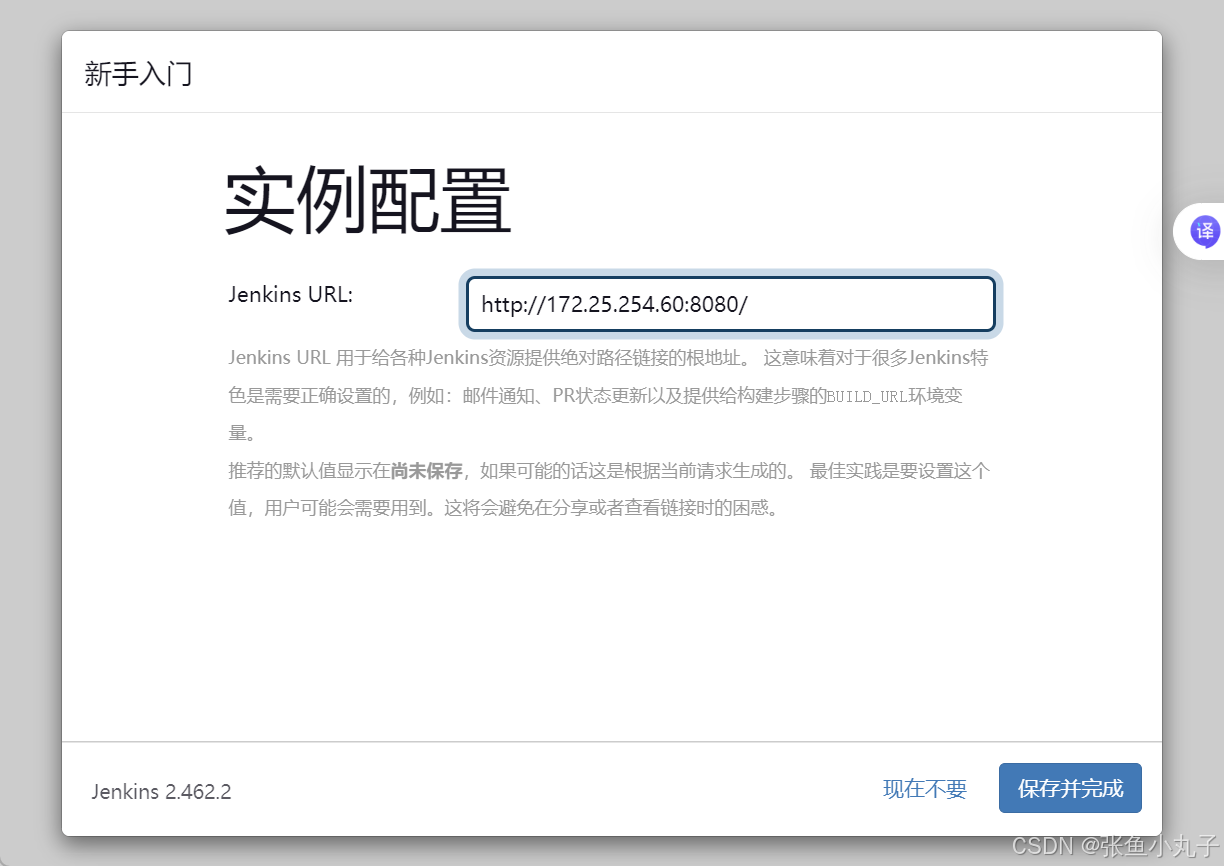
jenkins 与gitlab的整合
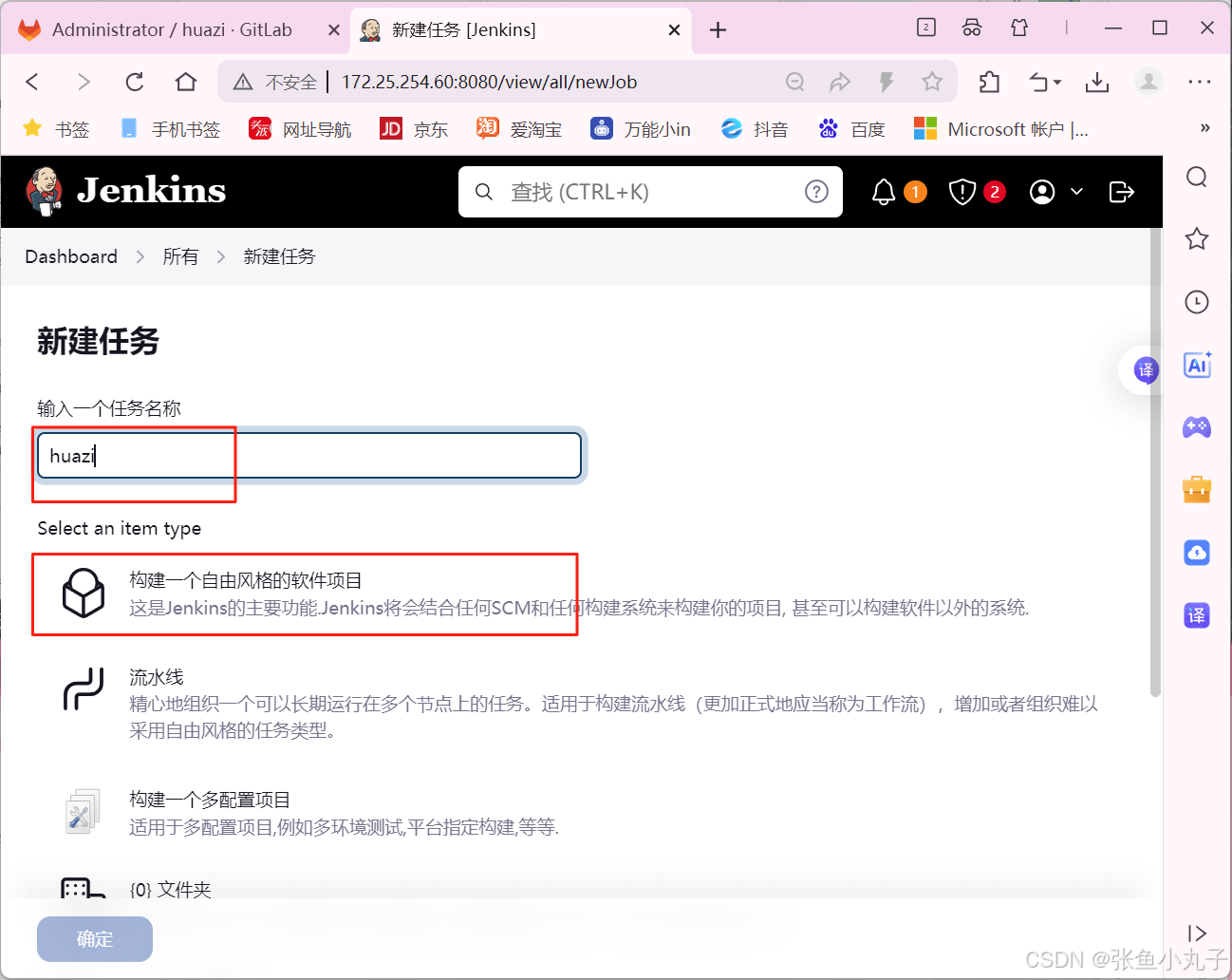
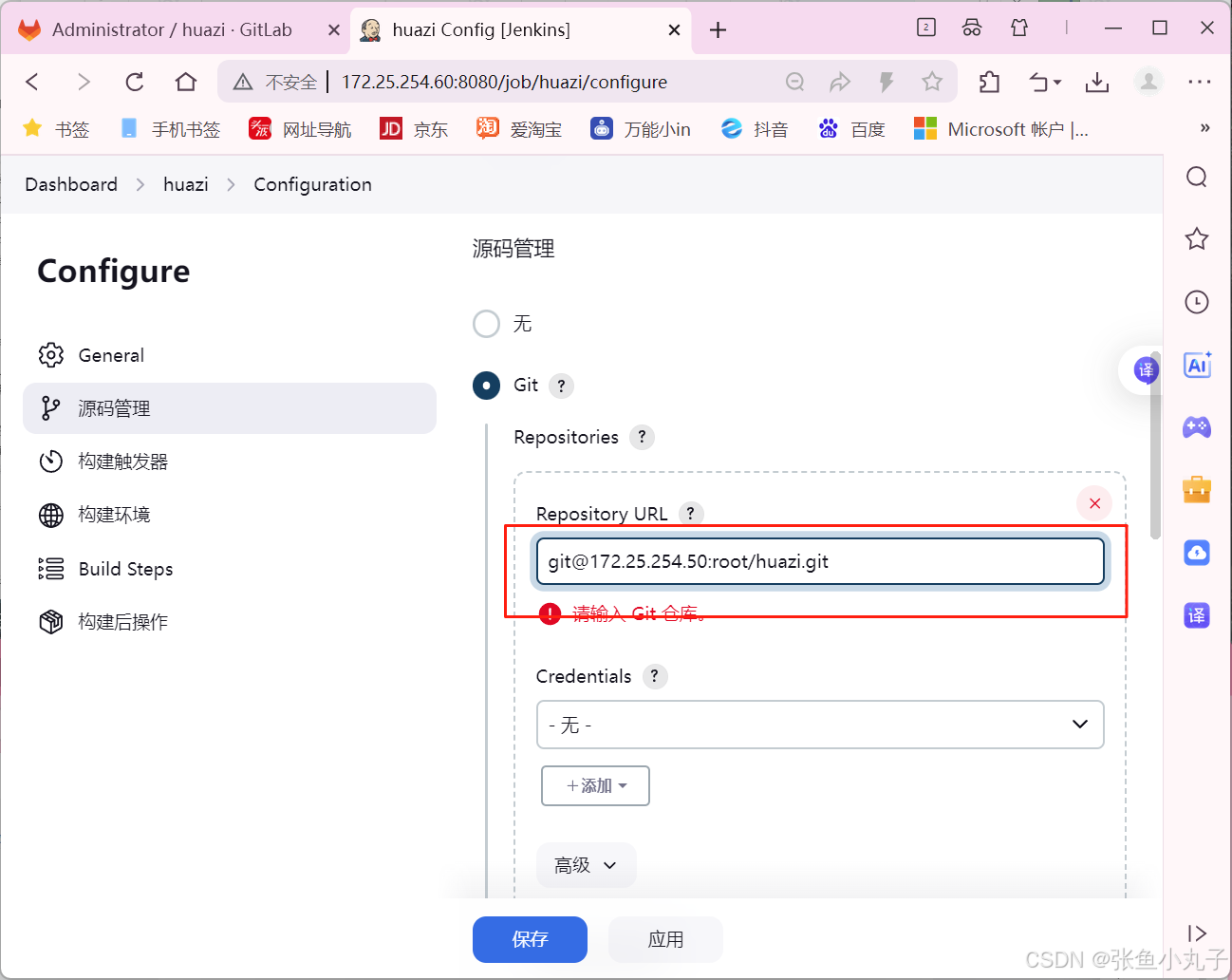
生成密钥
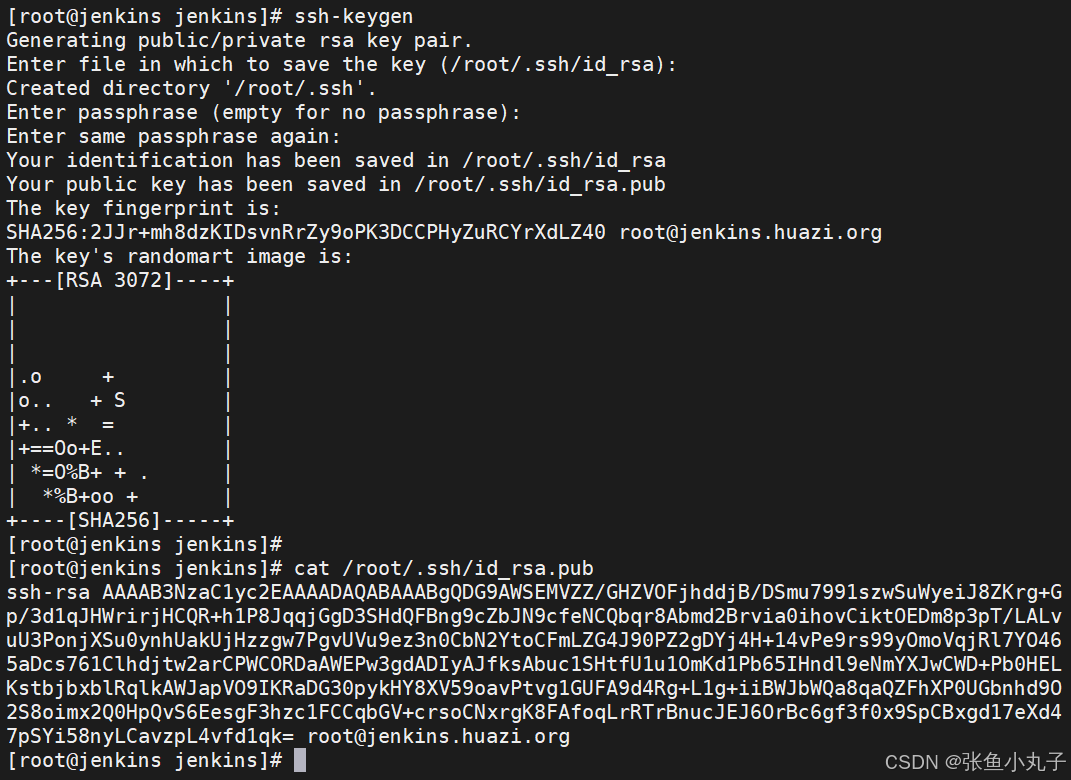
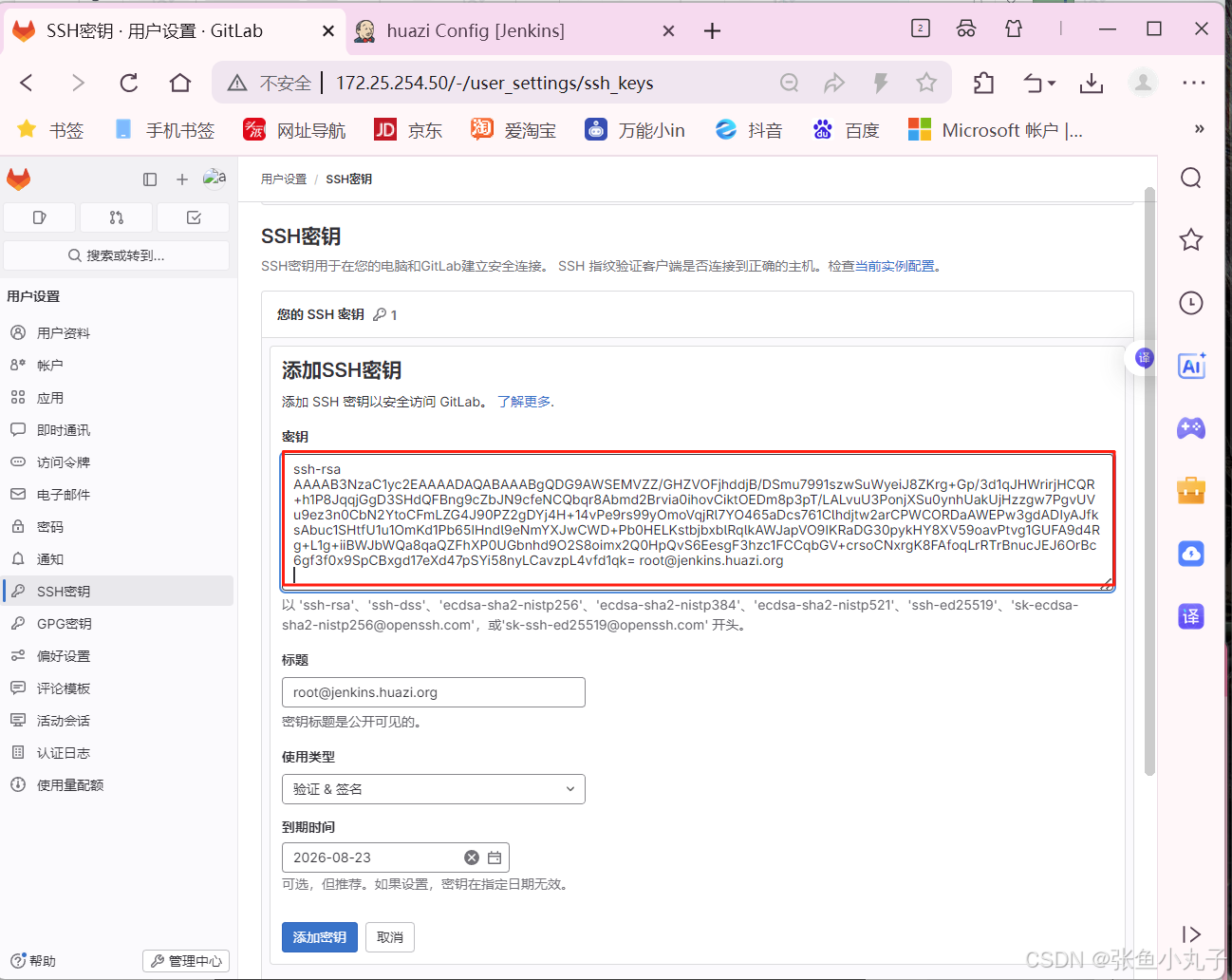
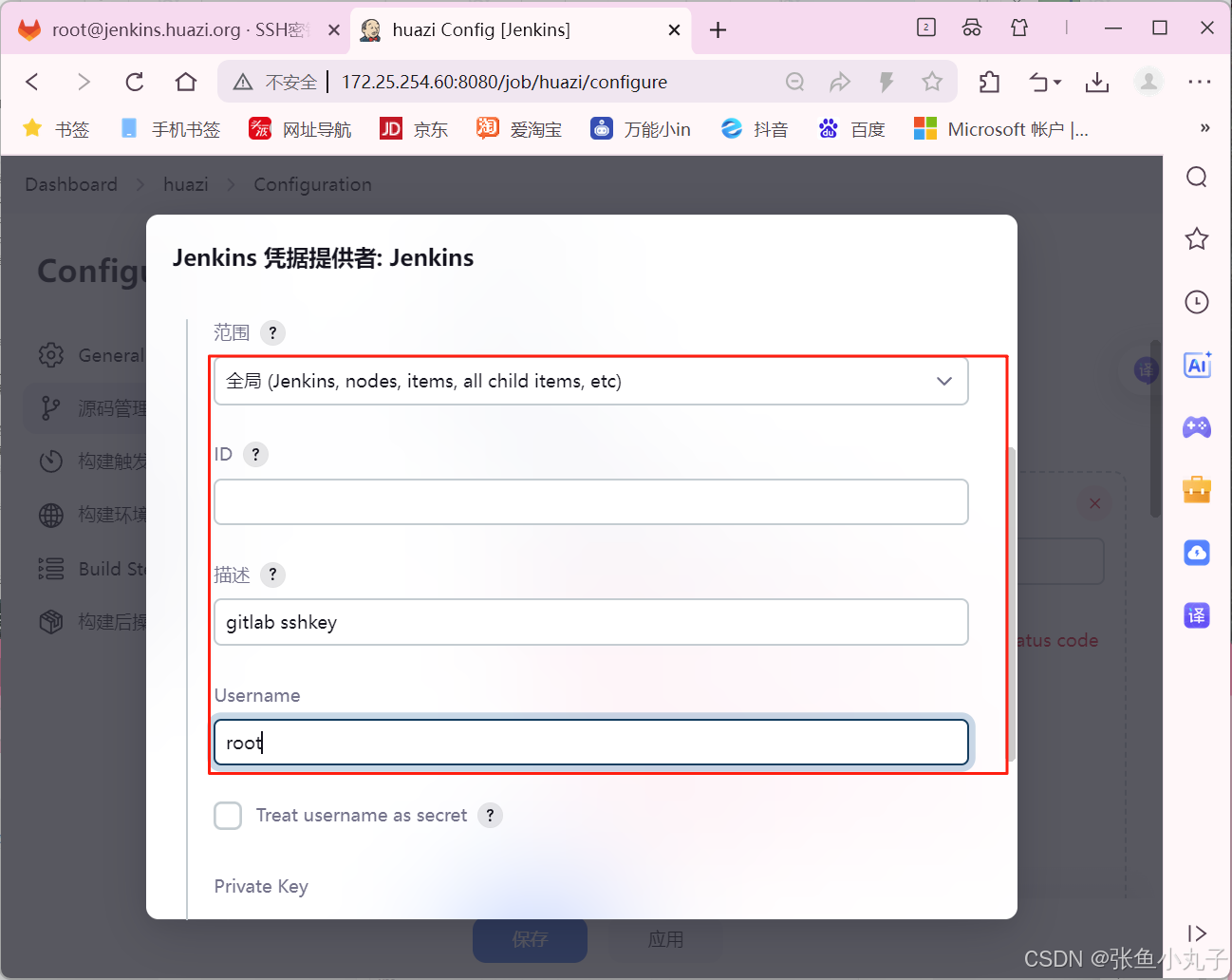
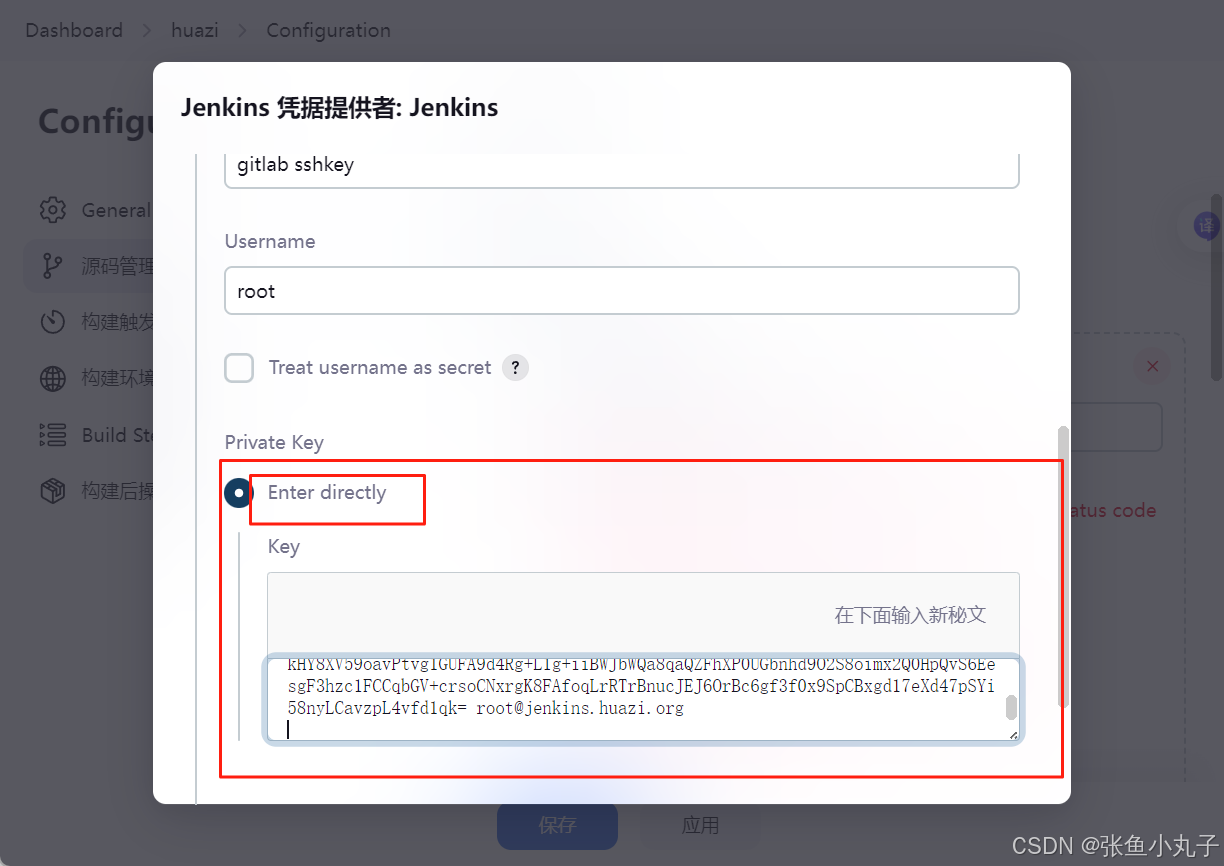
添加完成后报错依然存在,因为ssh首次连接主机是需要签名认证,需要手动输入yes
还有两台主机之间一定要做好解析
[root@jenkins jenkins]# vim /etc/ssh/ssh_config

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









