






 本文描述了一个基于餐厅订单数据的后端项目,涉及菜品销量、消费维度(如点菜种类、数量、总额和平均消费)、消费时间的分析,并使用Python的Pandas和Matplotlib库进行数据预处理、清洗和可视化。项目旨在实现数据的自动化分析和可视化,为餐饮决策提供依据。
本文描述了一个基于餐厅订单数据的后端项目,涉及菜品销量、消费维度(如点菜种类、数量、总额和平均消费)、消费时间的分析,并使用Python的Pandas和Matplotlib库进行数据预处理、清洗和可视化。项目旨在实现数据的自动化分析和可视化,为餐饮决策提供依据。
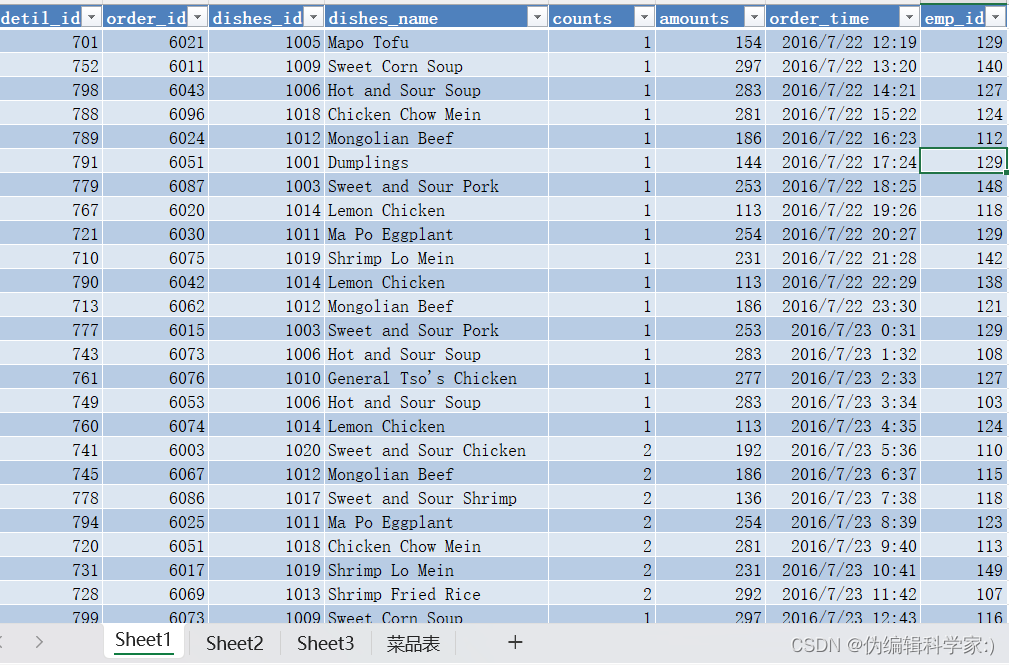 以上是我们需要处理的数据,这个数据是和餐厅订单有关的。
以上是我们需要处理的数据,这个数据是和餐厅订单有关的。
---数据介绍及需求:
该数据反应了餐厅的流水变化,主要反应了食客的点餐情况。我们的需求是做一个关于不同维度的分析并可视化的后端程序实现自动化。
实现以下维度的分析:菜品本身销量维度,关于食客消费的不同维度(点菜种类,点菜的数量,订单的消费总额,订单的平均消费),消费时间的维度
detil_id反应了每行数据的具体编号,是独一无二的详细编号。
order_id反应了食客的编号,一个编号反应一个食客
dishes_id反应了菜品的编号
dishes_name表示菜品的名字
counts表示该行的食客订了多少对应菜品
amounts表示该行的菜品价格
order_time表示食客点餐的详细时间
emp_id这里暂时用不到,属于无用数据
---后端实现:
1.数据的载入和预处理:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#1.加载数据
'''注意,pd.read_excel是pandas库中用于读取excel的文件代码,其中的参数如下
io表示文件路径的字符串;sheet_name是文件内分表的位置;header表示指定哪一行的数据作为列名字,默认为0;
'''
data1=pd.read_excel(r"C:\Users\lenovo\Desktop\python练习库\伪编辑科学家\餐厅数据可视化(练习).xlsx",sheet_name='Sheet1')
data2=pd.read_excel(r"C:\Users\lenovo\Desktop\python练习库\伪编辑科学家\餐厅数据可视化(练习).xlsx",sheet_name='Sheet2')
data3=pd.read_excel(r"C:\Users\lenovo\Desktop\python练习库\伪编辑科学家\餐厅数据可视化(练习).xlsx",sheet_name='Sheet3')
#2.数据预处理
#用pd.contact函数将传入的三个数据框进行合并,并传入data
data=pd.concat([data1,data2,data3],axis=0)
#用dropna函数将空值行删除(0列1行),实现数据清洗
data.dropna(axis=1,inplace=True)
'''
清洗后的数据详情:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 150 entries, 0 to 49
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 detil_id 150 non-null int64
1 order_id 150 non-null int64
2 dishes_id 150 non-null int64
3 dishes_name 150 non-null object
4 counts 150 non-null int64
5 amounts 150 non-null int64
6 order_time 150 non-null datetime64[ns]
7 emp_id 150 non-null int64
dtypes: datetime64[ns](1), int64(6), object(1)
memory usage: 10.5+ KB
'''
#统计卖出菜品的平均价格。
round(data['amounts'].mean(),2)#方法1:pandas的统计函数
round(np.mean(data['amounts']),2)#方法2:numpy的统计函数,相对比pandas的计算效率高
#频数统计:什么菜最受欢迎(统计菜名在订单中出现的次数)
dishes_count=data['dishes_name'].value_counts()[:10]
#在进行数据预处理中,可以提前将相关的数据进行计算和提取,以便于后续的使用这里我们实现了数据的上载,数据的清洗,以及重要数据的计算和提取(卖出菜品的平均值和菜品出现次数的频数统计)
2.进行频数统计的数据可视化:
def pstj(dishes_count):
dishes_count.plot(kind='bar',fontsize=8)
dishes_count.plot(kind='line',linestyle='-.',color=['r'])
plt.xticks(rotation=16,color='b')
#小技巧:在每个柱状图上做记录enumerate是枚举遍历,x表坐标,y表高度,遍历完直接用text函数输入调试后的坐标即可简单的实现目标
for x,y in enumerate(dishes_count):
plt.text(x,y+0.2,y,ha='center',fontsize=12)
plt.show()
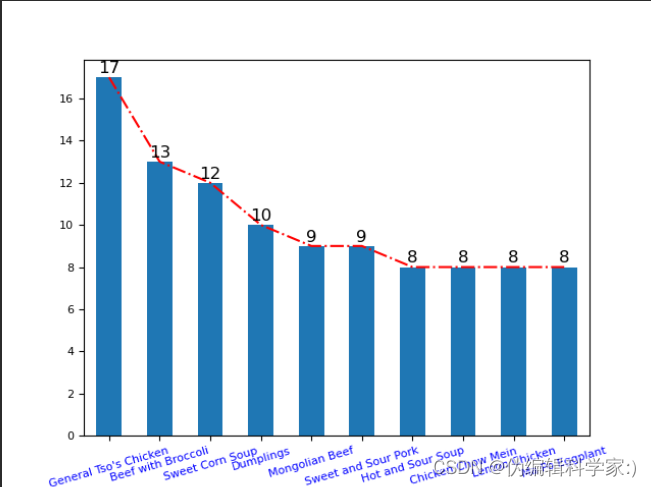
print(pstj(dishes_count))这里我们完成第一次简单的数据分析及其可视化,我们反映出了菜品的受欢迎程度排名前十并且进行了可视化。这可以对餐饮从业者提供可靠且美观的商业建议。
3.订单消费类型维度:
data_group=data['order_id'].value_counts()[:10]#按照order_id对data进行分组统计,这样就可以求出每个用户点的订单数量
def idsort(data_group):
data_group.plot(kind='bar',fontsize=13)
plt.xticks(rotation=0,color='b')
plt.title('订单点菜种类前十名',fontproperties='STsong',fontsize=20)
plt.xlabel('订单ID',fontproperties='STsong',fontsize=16)
plt.ylabel('种类数量',fontproperties='STsong',fontsize=16)
for i,j in enumerate(data_group):
plt.text(i,j+0.2,j,ha='center',fontsize=12)
plt.show()
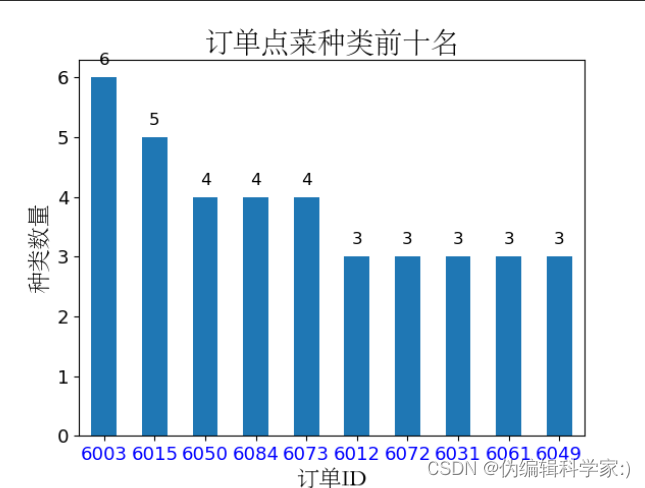
print(idsort(data_group))这里我们分析出了哪个客户点菜种类数量多少并进行了自动可视化,商家通过该数据呈现出来的信息可以决定要扩大菜品的种类还是专精特定种类的菜品。通过下面的图表可以看出消费菜品种类最多的前十名的平均数才为3.8。在该餐厅顾客可能多次喜欢点同类型的菜品。
4.订单消费金额和点菜数量维度分析:
#可见现在要用到order_id,counts(数量),amounts(单价)这三列
data['total_amounts']=data['counts']*data['amounts'] #统计单道菜的消费总额并添加到data中
data_Group=data[['order_id','counts','total_amounts']].groupby(by='order_id')#将要用到的三列按照order_id提前分类,以免后续统计出错
Group_sum=data_Group.sum() #分组求和
sort_counts=Group_sum.sort_values(by='counts',ascending=False)#对求和后的统计数据进行降序排序
#.sort_values(by=axis轴上的某个索引或某个索引列表,它排完序后其他元素进行自动调整),axis=轴数,ascending=True/Fulse是否递增排序)方法在指定轴上根据数据进行排序,默认排序
def dcsl(sort_counts):
sort_counts['counts'][:10].plot(kind='bar',fontsize=10)
plt.xticks(rotation=0,color='b')
plt.title('订单点菜数量前十名',fontproperties='STsong',fontsize=20)
plt.xlabel('订单ID',fontproperties='STsong',fontsize=16)
plt.ylabel('菜品数量',fontproperties='STsong',fontsize=16)
plt.show()
#统计ID消费金额最高
amount_counts=Group_sum.sort_values(by='total_amounts',ascending=False)#对消费总金额进行降序排序
def xfze(amount_counts):
amount_counts['total_amounts'][:10].plot(kind='bar',fontsize=10)
plt.xticks(rotation=0,color='b')
plt.title('订单消费金额前十名',fontproperties='STsong',fontsize=20)
plt.xlabel('订单ID',fontproperties='STsong',fontsize=16)
plt.ylabel('消费金额',fontproperties='STsong',fontsize=16)
plt.show()
#分析哪个订单ID平均点菜最贵(总消费金额/点菜数量)
Group_sum['average']=Group_sum['total_amounts']/Group_sum['counts']
sort_ave=Group_sum.sort_values(by='average',ascending=False)[:10]
def average(sort_ave):
sort_ave['average'][:100].plot(kind='bar',fontsize=10)
plt.xticks(rotation=0,color='b')
plt.title('订单消费平均金额前十',fontproperties='STsong',fontsize=20)
plt.xlabel('订单ID',fontproperties='STsong',fontsize=16)
plt.ylabel('平均消费金额',fontproperties='STsong',fontsize=16)
plt.show()
这个维度要分析的东西比较多,可以让我们从点菜的数量,点菜的金额和点菜的平均金额进行分析消费人群的爱好和了解他们的定位: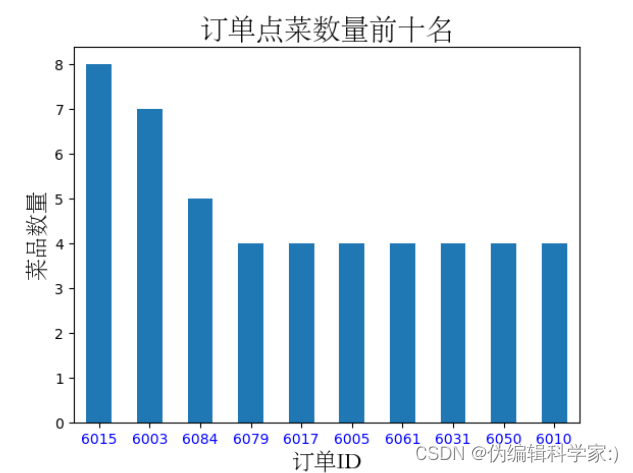
可见6015等食客应该是商务型或社交型人物,每次的点菜数量比较多
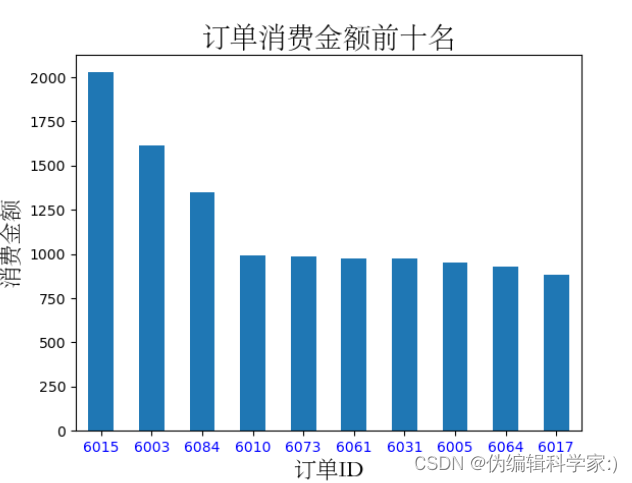
可见6015等食客应该是商务型人物,吃饭讲究排场
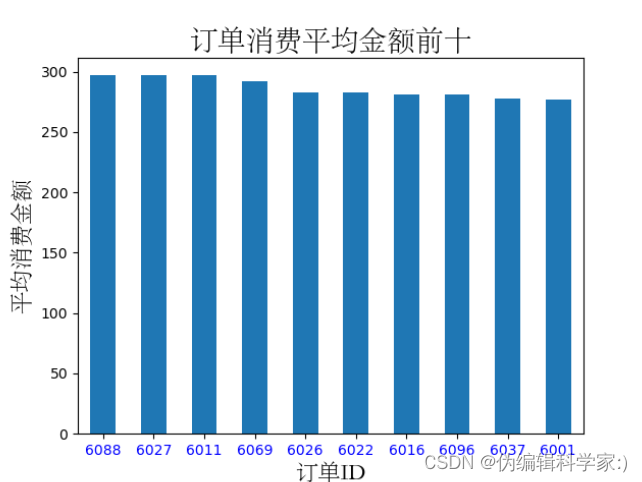
6088等食客在该时间段内在餐厅消费的平均金额最多,餐厅可以相应对该人群进行回馈活动
5.时间维度分析:
#这里日期的形式为xxxx-x-x xx:xx 包含年月日 时分秒
#分析一天当值什么时间段点菜量最集中
data['hourcount'] = 1 #添加新列,用作每个时间段的计数
data['time'] = pd.to_datetime(data['order_time']) #用pandas的函数将时间转化为日期形式
data['hour'] = data['time'].map(lambda x:x.hour)
#用lambda取出time列中的小时并存放到新建列hour中
gp_by_hour=data.groupby(by='hour').count()['hourcount']#将总数据集用hour进行分组,并统计每个hour出现的频率
def timecount(gp_by_hour):
gp_by_hour.plot(kind='bar')
plt.xticks(rotation=0,color='b')
plt.title('消费时间频数',fontproperties='STsong',fontsize=20)
plt.xlabel('小时',fontproperties='STsong',fontsize=16)
plt.ylabel('下单人数',fontproperties='STsong',fontsize=16)
plt.show()
#哪一天的订菜数量最多
data['daycount'] = 1 #同上,起到计算天数的作用
data['day'] = data['time'].map(lambda x:x.day) #用map函数嵌套lambda取出天数
gp_by_day=data.groupby(by='day').count()['daycount'] #进行分组求和并只取出daycount
def daycount(gp_by_day):
gp_by_day.plot(kind='bar')
plt.xticks(rotation=0,color='b',fontsize=8)
plt.title('消费天数频数',fontproperties='STsong',fontsize=20)
plt.xlabel('日期',fontproperties='STsong',fontsize=16)
plt.ylabel('下单人数',fontproperties='STsong',fontsize=16)
plt.show()
#拓展,排序日期并且取出点菜量最大的前十天
sort_day = gp_by_day.sort_values(ascending=False)[:10]#直接降序排序即可
def sortday(sort_day):
sort_day.plot(kind='bar')
plt.xticks(rotation=0, color='b', fontsize=12)
plt.title('消费最高日期前十', fontproperties='STsong', fontsize=20)
plt.xlabel('日期', fontproperties='STsong', fontsize=16)
plt.ylabel('下单人数', fontproperties='STsong', fontsize=16)
plt.show()
#分析查看星期几人数最多,订餐数最多,映射数据到星期
data['weekcount'] = 1 #计数器
data['weekday'] = data['time'].map(lambda x:x.weekday()) #用map和lambda将日期形式转变为星期
gp_by_weekday = data.groupby(by='weekday').count()['weekcount']
def weekcount(gp_by_weekday):
gp_by_weekday.plot(kind='bar')
plt.xticks(rotation=0, color='b', fontsize=12)
plt.title('每周消费统计', fontproperties='STsong', fontsize=20)
plt.xlabel('星期', fontproperties='STsong', fontsize=16)
plt.ylabel('下单人数', fontproperties='STsong', fontsize=16)
plt.show()我们在时间维度成功的分析出了日期频数,点菜数量和日期人数等方面的分析。要注意的是,在对日期进行维度分析时,特别是涉及到日期频数的计算,首先要对日期列进行日期类型的转化,因为有一些杂乱日期数据不是datetime类型的,然后要在原数据中添加一列都是1的列,并标清楚该列的名称,在后续进行频数统计时直接那这一列进行计算即可。
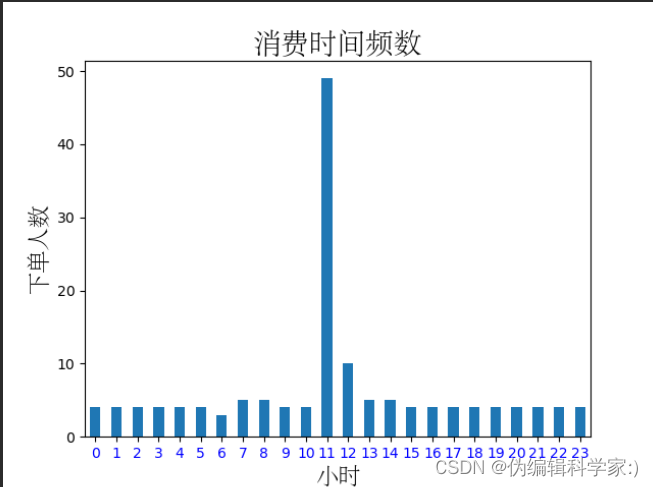
可见中午11点到12点人数最多,这是一个午餐类型的店
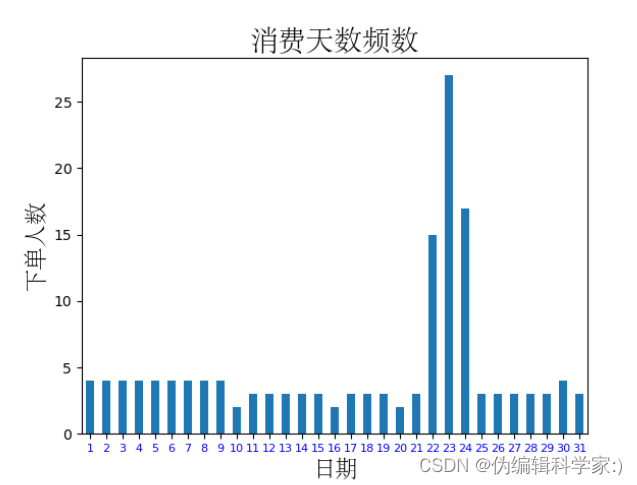
可见在22,23,24号吃饭的人数最多,应该这3天是有什么节日
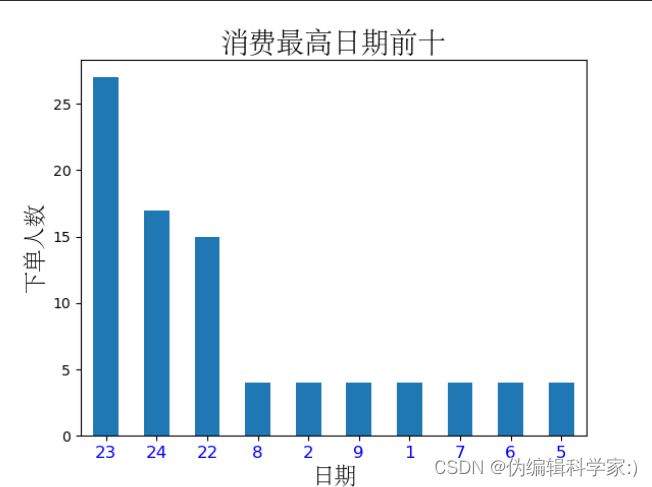
罗列出排名前十的日期
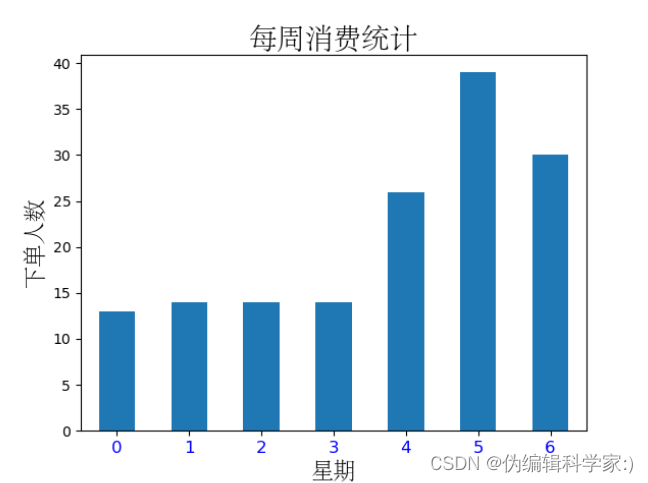
可见每周的4,5,6消费人数最多,可能时接近周末大家都特别开心吧。周日(0)的人数一般,可能接近周一大家都不怎么开心
---总结:
以上的数据不具有参考意义,都是随机生成的。
之所以说该项目很简单,是因为数据可视化的内容其实都差不多。在某一维度,我在编写可视化代码时候都是编完一个然后复制粘贴,修改一些参数即可。每个维度分析的可视化我都用def分为了一块块的自定义函数,未来和前端连接,我们只要选择想要的图像即可生成,实现真正的自动化。我的能力有限,目前还没有接触前端的开发,在pandas和matplotilb方面也是新手,代码可能编写的非常冗余,希望大家可以谅解。















 3448
3448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









