







 该文通过分析餐厅订单数据,揭示了最受欢迎菜品、点菜种类、点菜数量、消费金额与平均消费单价等关键指标,提出优化菜品结构、调整主食价格、设置个性化菜单及员工排班策略等建议,帮助餐厅提升经营效率和服务质量。
该文通过分析餐厅订单数据,揭示了最受欢迎菜品、点菜种类、点菜数量、消费金额与平均消费单价等关键指标,提出优化菜品结构、调整主食价格、设置个性化菜单及员工排班策略等建议,帮助餐厅提升经营效率和服务质量。
餐厅订单数据分析
本文将从以下几个方面对餐厅订单数据进行可视化展示及剖析,旨在为营业者提供一定的决策和建议。
- 餐厅最受欢迎菜品TOP10
- 订单ID点菜种类TOP10(消费维度分析)
- 订单ID点菜数量TOP10(消费维度分析)
- 订单ID消费最多的金额(消费维度分析)
- 订单ID平均消费最贵(消费维度分析)
- 餐厅点菜量分析(日期与时间维度分析)
***## 第一步:导入相应的包***
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']= 'SimHei' ##设置中文字体
%matplotlib inline
***## 第二步:加载数据集***
data1 = pd.read_excel('E:\BaiduNetdiskDownload\meal_order_detail.xlsx',sheet_name='meal_order_detail1')
data2 = pd.read_excel('E:\BaiduNetdiskDownload\meal_order_detail.xlsx',sheet_name='meal_order_detail2')
data3 = pd.read_excel('E:\BaiduNetdiskDownload\meal_order_detail.xlsx',sheet_name='meal_order_detail3')
备注:此处数据由三个Sheet组成,分别是meal_order_detail1、meal_order_detail2、meal_order_detail3。
EXCEL数据如下图所示:

***## 第三步:数据预处理***
接下来我们进行数据合并的操作,代码如下:
data = pd.concat([data1,data2,data3],axis=0)
#axis=0 表示行连接数据,1表示列链接数据
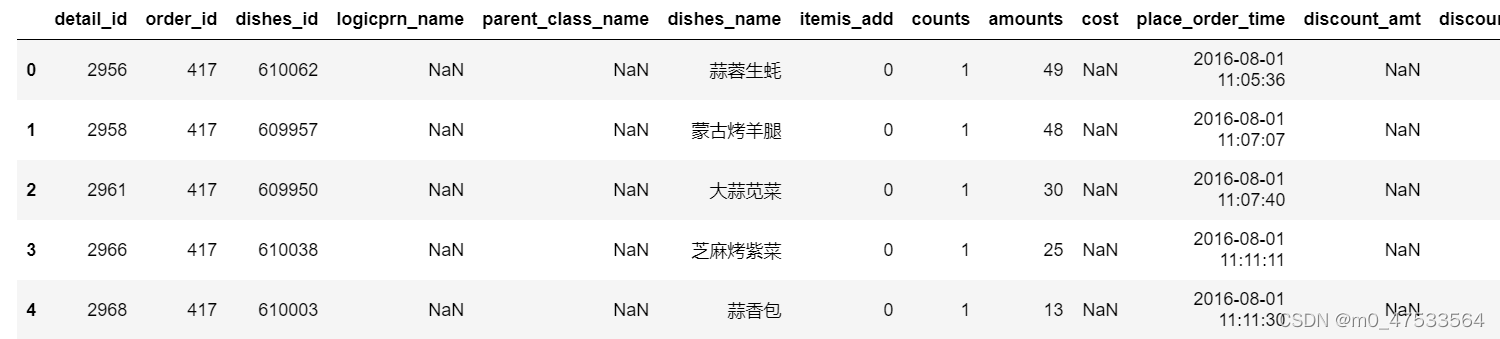
data.head() #只显示前5行
合并后的数据如下图
接下来我们查看合并后的数据信息,观察数据的基本构成
data.info() #查看数据信息
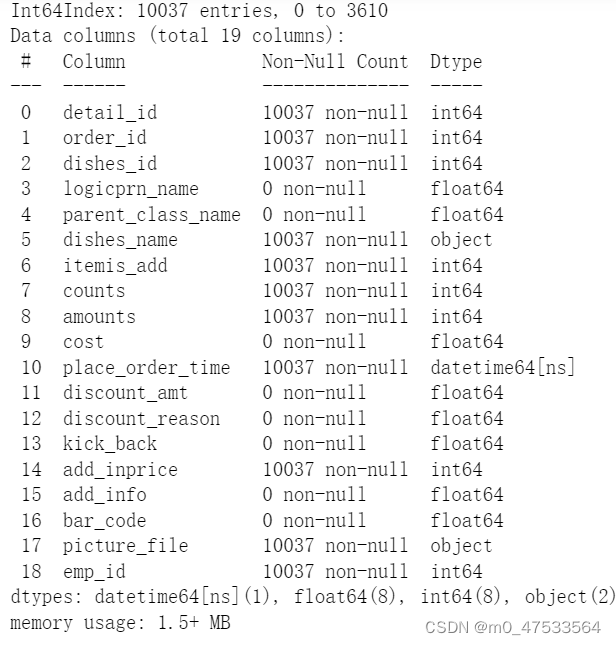 由基本信息可知该数据集共由10037条数据构成,其中数据类型分别是int整型、float 浮点型、object 、datetime64[ns]四种类型。同时我们发现还存在non-null的缺失数据,对其应进行进一步的处理。
由基本信息可知该数据集共由10037条数据构成,其中数据类型分别是int整型、float 浮点型、object 、datetime64[ns]四种类型。同时我们发现还存在non-null的缺失数据,对其应进行进一步的处理。
data.dropna(axis=1,inplace=True)
# 删除数据中的空值列,列的话是1,inplace= True 作用于源数据
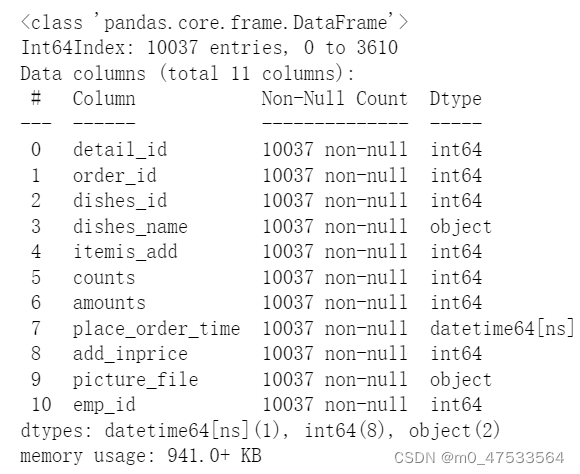 再次观察数据信息,发现空值数据已被剔除。
再次观察数据信息,发现空值数据已被剔除。
接下来我们对菜品的平均价格进行计算,可用如下两种方式实现。
统计买出菜品的平均价格
方法一:pandas 自带函数
data['amounts'].mean()
数据结果显示:44.821360964431605
round(data['amounts'].mean(),2) #round 函数进行四舍五入操作,此处保留2位
数据结果显示:44.82
方法二:numpy 函数 (当数据量多的时候,建议使用此方法)
- round(np.mean(data['amounts']),2)
数据结果显示:44.82
频数统计 什么菜最受欢迎(对菜名进行频数统计,然后取最大的前10名)
dishes_count = data ['dishes_name'].value_counts()
dishes_count
结果显示如图

由于我们此处只需计算前十名的数据,所以对多余数据进行剔除,仅保留前十名。
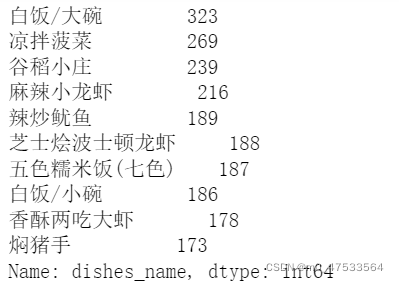
dishes_count = data ['dishes_name'].value_counts()[:10] # [:10]切片取前10名
dishes_count
结果如下:
将最受欢迎的菜品TOP10进行可视化展示
# 数据可视化 Matplotlib
dishes_count.plot(kind='line',color='pink') ##折线图
dishes_count.plot(kind='bar',fontsize=16) ##柱状图
for x,y in enumerate(dishes_count):
print(x,y)
plt.text(x,y+1,y,ha='center',fontsize=12) ##ha='center'字体居中显示
plt.title('最受欢迎菜品TOP10')
plt.xlabel('菜品名称')
plt.ylabel('点购数量')
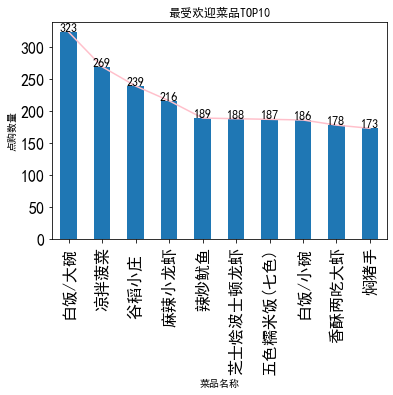
从显示结果来看,该餐厅的热门菜品可分为两类:
素菜类:凉拌菠菜。
肉菜类:麻辣小龙虾、辣炒鱿鱼 、芝士烩波士顿龙虾、香酥两吃大虾 、焖猪手 。
其中谷稻小庄经查询为饮品类,白饭/大碗、五色糯米饭(七色)、白饭/小碗为主食类不属于菜品范畴。
对此,我们可以提出建议如下:
①热门菜品凉拌菜类可否增加品类,以吸引顾客再次消费。
②生鲜食品能否和其他传统菜品进行搭配销售,以提高传统菜品的销售量。
③主食类价格调整策略:如小碗米饭1元,大碗米饭1.5元。
订单ID点菜种类TOP10
data_group = data['order_id'].value_counts()[:10]
data_group.plot(kind='bar',fontsize=16)
plt.title('订单点菜的种类TOP10')
plt.xlabel('订单ID',fontsize=16)
plt.ylabel('点菜种类',fontsize=16)
for x,y in enumerate(data_group):
print(x,y)
plt.text(x,y+1,y,ha='center',fontsize=12) ##ha='center'字体居中显示
plt.title('订单点菜的种类TOP10')
plt.xlabel('订单ID')
plt.ylabel('点菜种类')
 上图总结:八月份餐厅订单点菜种类前10名,平均点菜25个菜品。该点菜种类的菜品,那个菜品利润更高,可适当加大宣传力度,做好营销工作。以提高餐厅的利润。
上图总结:八月份餐厅订单点菜种类前10名,平均点菜25个菜品。该点菜种类的菜品,那个菜品利润更高,可适当加大宣传力度,做好营销工作。以提高餐厅的利润。
订单ID点菜数量TOP10(分组order_id,counts求和,排序,前十)
data['total_amounts']=data['counts']*data['amounts'] # 统计单道菜消费总额
dataGroup = data[['order_id','counts','amounts','total_amounts']].groupby(by='order_id')
Group_sum = dataGroup.sum() #分组求和
sort_counts = Group_sum .sort_values(by='counts',ascending=False)
sort_counts['counts'][:10].plot(kind='bar',fontsize=16)
plt.title('订单ID点菜数量TOP10')
plt.xlabel('订单ID')
plt.ylabel('点菜数量')
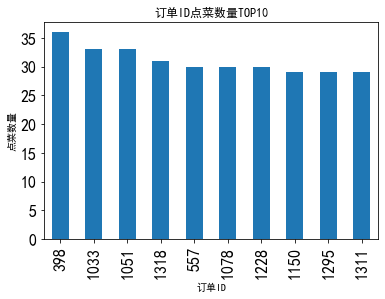
上图总结:八月份餐厅订单点菜数量前10名,平均点菜30个菜品。餐厅经营者可否根据点餐数量设满足不同需求的个性化菜单,对就餐者提供合理的订餐建议,避免菜品浪费现象产生。
订单id消费最多的金额TOP10(排序)
sort_total_amounts = Group_sum.sort_values(by='total_amounts',ascending=False)
sort_total_amounts['total_amounts'][:10].plot(kind='bar')
plt.title('消费金额前10名')
plt.xlabel('订单ID')
plt.ylabel('消费金额')
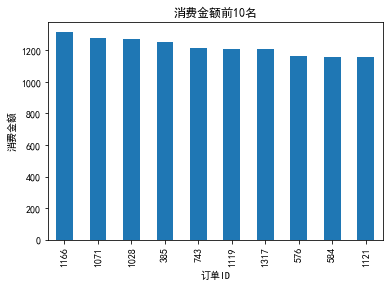
上图显示了前10名订单ID消费金额的分布情况,根据分布情况,餐厅经营者可否将订单ID者划分为不同的等级,如VIP1、VIP2、VIP3、VIP4、VIP5。数字越大等级越高。针对VIP办理年卡、季卡、月卡、周卡等促进顾客进行多次消费。
订单ID平均消费最贵TOP10
Group_sum['average']=Group_sum['total_amounts']/Group_sum['counts']
sort_average = Group_sum.sort_values(by='average',ascending=False)
sort_average['average'][:10].plot(kind='bar')
plt.title('消费单价前10名')
plt.xlabel('订单ID')
plt.ylabel('消费单价')
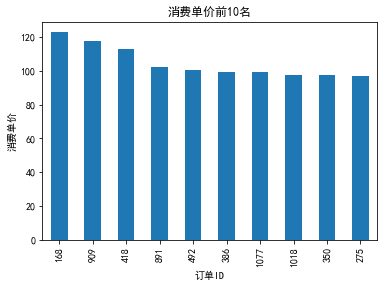
观察上图可看出前十名消费单价集中在100元左右。餐厅经营者可根据消费水平对餐厅菜品价格进行合理定价。同时帮助经营者认清该餐厅的消费等级,通过对餐厅消费水平设置价格标签,来精准的寻找该消费阶层的人群。
** 一天当中什么时间段,点菜量比较集中(用hour来计算)**
data['hourcount']= 1 #创建新列,用于计数
data['time'] = pd.to_datetime(data['place_order_time']) #将时间转换成日期类型存储
原始数据长这样:
可以看到数据格式并不规范,我们需进行处理
pandas中的to_datetime()可获取指定的时间和日期
将2016/8/1 11:05:36转换成2016-8-1 11:05:36
data[‘hour’] = data[‘time’].map(lambda x:x.hour)
此处操作是将上一步中转换了的日期类型数据进行拆分,分别将日期和时间赋予到不同的列。
 可以看到原始表格新增了两列,分别是time列和hour列。
可以看到原始表格新增了两列,分别是time列和hour列。
gp_by_hour = data.groupby(by='hour').count()['hourcount']
pandas的groupby需要明确以什么维度聚合,以及聚合的方式是sum求和,抑或max求最值,还是count计数。上述代码是用‘hour’来聚合,聚合方式是count计数。接下来绘制以小时来聚合的数据,代码展示如下:
gp_by_hour.plot(kind='bar',fontsize=16)
for x,y in enumerate(gp_by_hour):
print(x,y)
plt.text(x,y+1,y,ha='center',fontsize=12) ##ha='center'字体居中显示
plt.xlabel('小时',fontsize=16)
plt.ylabel('下单数量',fontsize=16)
plt.title('下单数与小时的关系图',fontsize=16)
- List item
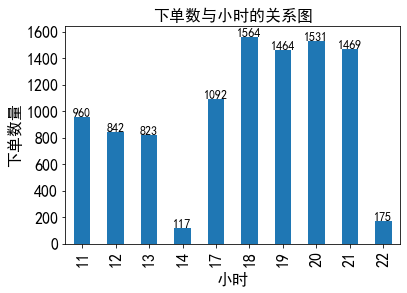 从上述图表中我们可以得到如下结论:
从上述图表中我们可以得到如下结论:
①14:00和22:00 下单人数最少,可以减少该时间段工作的员工人数。
②17:00-21:00 时间段,进餐人数达到了一日中的高峰期,下单数量均大于1000。可以增加该时间段员工的数量,或者雇佣该小时段的临时工,来帮助餐厅服务的开展。
③上午的下单量约为下午下单量的三分之二,人们更倾向于下午时间段在餐厅消费。
那一天订餐数量最多(操作同上)
data['daycount']= 1 #创建新列,用于计数
data['day'] = data['time'].map(lambda x:x.day)
gp_by_day = data.groupby(by='day').count()['daycount']
gp_by_day.plot(kind='bar',fontsize=10)
for x,y in enumerate(gp_by_day):
print(x,y)
plt.text(x,y+1,y,ha='center',fontsize=10) ##ha='center'字体居中显示
plt.xlabel('8月份日期',fontsize=16)
plt.ylabel('点菜数量',fontsize=16)
plt.title('点菜数量与日期的关系图',fontsize=16)
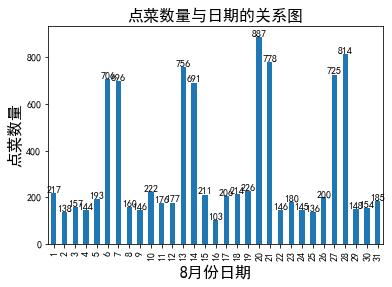
查看星期几人数最多,订餐数最多,映射数据到日期
data['weekcount']= 1 #创建新列,用于计数
data['weekday'] = data['time'].map(lambda x:x.weekday())
gp_by_weekday = data.groupby(by='weekday').count()['weekcount']
gp_by_weekday.plot(kind='bar',fontsize=10)
for x,y in enumerate(gp_by_weekday):
print(x,y)
plt.text(x,y+1,y,ha='center',fontsize=10) ##ha='center'字体居中显示
plt.xlabel('星期',fontsize=16)
plt.ylabel('点菜数量',fontsize=16)
plt.title('点菜数量与星期的关系图',fontsize=16)
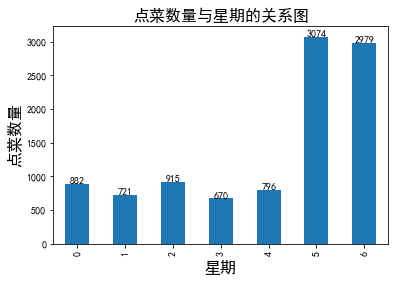
时间维度的餐厅订单分析,可以帮助经营者合理的设置员工排班时间和员工规模数量的敲定。做出更清楚、客观的决策。

















 1580
1580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









