









目录
一:冒泡排序——原理
冒泡排序的原理是:从序列的第一个元素开始,比较相邻的两个元素,如果它们的顺序错误(如:从大到小排序时,前一个元素大于后一个元素),则交换它们的位置。继续比较下一对相邻元素,执行相同的操作,直到序列的末尾。
二:冒泡排序——分析
冒泡排序核心就是:多趟排序
若以升序(从小到大)排序为例,假若有N个数。第一趟排序目的是找到整个数组中最大的数并把它排在最后端;最后一个最大数不再比较移动,第二趟排序目的是在剩下的N-1个数找出最大的(即整个数组中第二大的数)并把它放在倒数第二位......这样一轮一轮的比较,直到只剩下一个数时(完成了N趟的排序)这个排序就完成了,从而实现从小到大的排序。
动图如下:
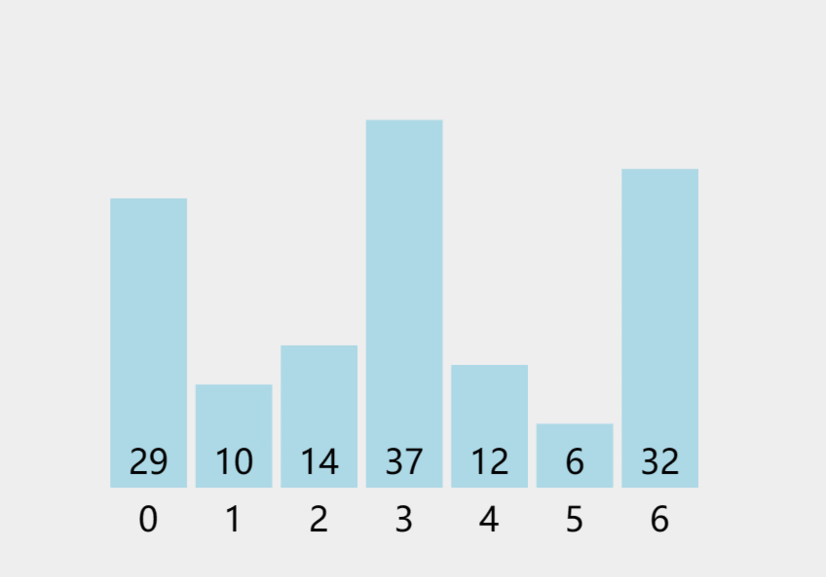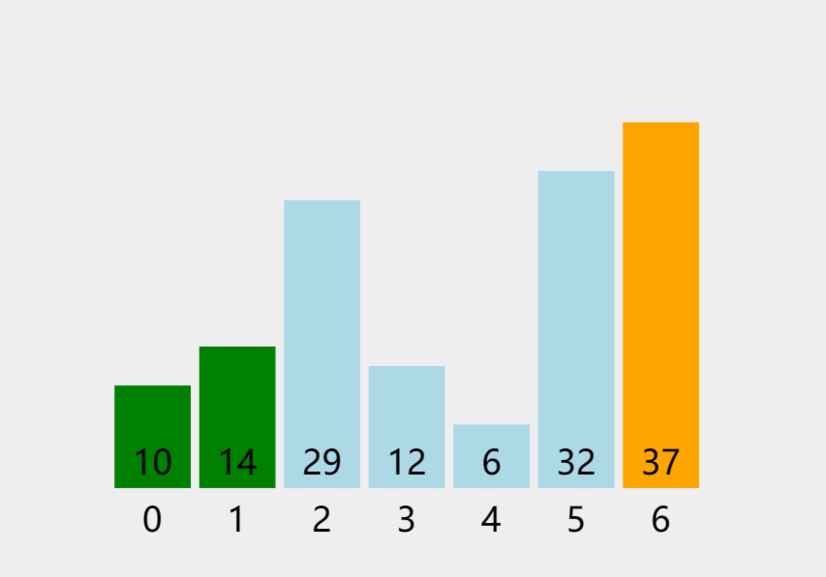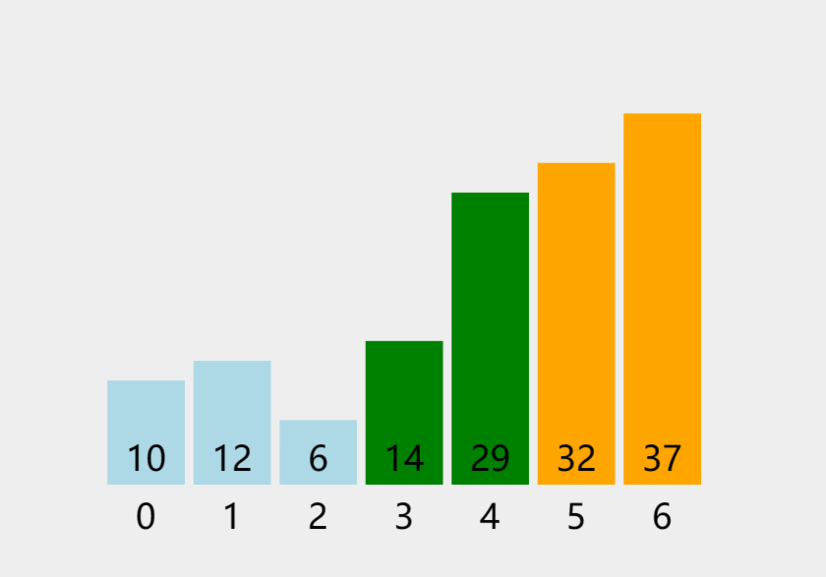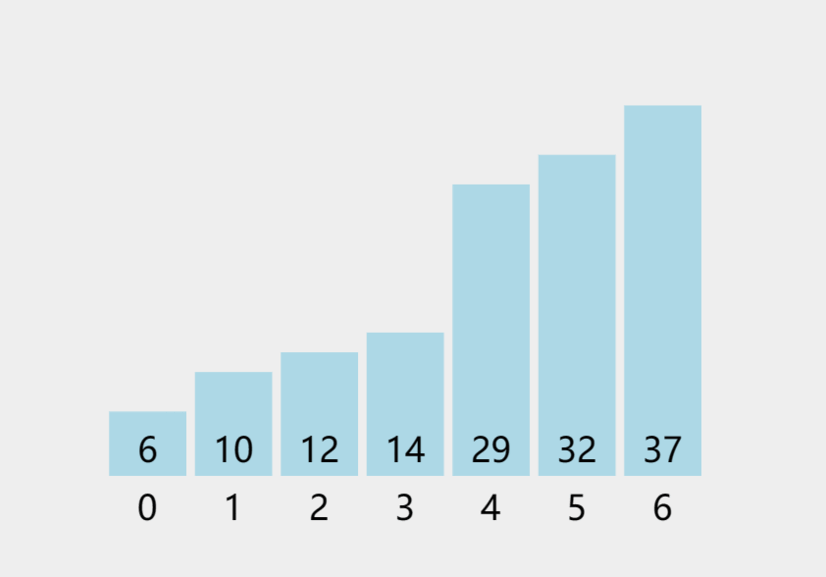
三:冒泡排序——实现
冒泡排序代码实现如下
#include<stdio.h>
// 实现冒泡排序
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n; i++) // 决定排序的趟数-->总共n趟
{
for (int j = 1; j < n - i; j++) // 一趟进行比较的次数
{
if (a[j - 1] > a[j]) // 若前一个数比后一个数大,就交换
{
int tem = a[j-1];
a[j-1] = a[j];
a[j] = tem;
}
}
}
}
int main()
{
int a[] = { 29,10,14,37,12,6,32 };
int sz = sizeof(a) / sizeof(a[0]); // 获取数组的大小
for (int i = 0; i < sz; i++) // 打印排序前的数组内容
{
printf("%d ", a[i]);
}
printf("\n");
BubbleSort(a, sz); // 实现冒泡排序
for (int i = 0; i < sz; i++) // 打印排序后的数组内容
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}四:冒泡排序——优化
冒泡排序代码优化如下
#include<stdio.h>
// 实现冒泡排序
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n; i++) // 决定排序的趟数-->总共n趟
{
int exchange = 0; // 用来标记数组排序的大致情况
for (int j = 1; j < n - i; j++) // 一趟进行比较的次数
{
if (a[j - 1] > a[j]) // 若前一个数比后一个数大,就交换
{
int tem = a[j-1];
a[j-1] = a[j];
a[j] = tem;
exchange = 1;
}
}
if (exchange == 0) // exchange == 0 表示这一趟没有进入循环,即不需要交换数
据,代表前面的数据已经有序了,又因为后面的数据也是有序的,故此不需要再排了,退出趟数循环
{
break;
}
}
}
int main()
{
int a[] = { 29,10,14,37,12,6,32 };
int sz = sizeof(a) / sizeof(a[0]); // 获取数组的大小
for (int i = 0; i < sz; i++) // 打印排序前的数组内容
{
printf("%d ", a[i]);
}
printf("\n");
BubbleSort(a, sz); // 实现冒泡排序
for (int i = 0; i < sz; i++) // 打印排序后的数组内容
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}使用 exchange 标记可以使循环的次数减少,增大效率,从而达到优化的效果。
五:冒泡排序——效率(时间复杂度)
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
分析时间复杂度:
因为比较和交换需要的时间由一个常数限制,我们称之为 c。然后,在(标准)冒泡排序中有两个嵌套循环。外循环正好运行 N-1 次迭代。但是内循环的运行时间越来越短:
- 当 R=N-1 时,(N−1) 次迭代(比较和交换),
- 当 R=N-2 时,(N−2) 次迭代,
- ...,
- 当 R=1 时,1 次迭代(然后完成)。
因此,总的迭代次数 = (N−1)+(N−2)+...+1 = N*(N−1)/2
总时间 = c*N*(N−1)/2 = O(N^2).
以上的内容若是对大家起到帮助的话,大家可以动动小手点赞,评论+收藏。大家的支持就是我进步路上的最大动力!



















 39万+
39万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









