







引言
在深度学习领域,卷积神经网络(CNN)是解决图像分类、目标检测等问题的关键技术之一。近年来,随着深度学习的不断发展,新的网络架构不断涌现。在众多网络架构中,EfficientNet和ResNet都成为了深度学习模型的佼佼者,分别在高效性和深度特性上得到了广泛应用。本文将详细介绍EfficientNet,并与经典的ResNet进行对比,分析它的架构、使用场景、适用问题及实例。
什么是EfficientNet?
EfficientNet是一种由Google在2019年提出的深度神经网络架构,其目标是通过优化神经网络模型的深度、宽度和分辨率来实现计算效率和准确度的平衡。它的核心理念是:通过复合缩放(Compound Scaling)方法同时优化网络的深度、宽度和输入图像的分辨率,使得网络在给定计算预算下能够达到更高的性能。
EfficientNet的架构设计
EfficientNet的核心创新在于复合缩放方法。传统的深度网络通常只通过单一的维度(如深度、宽度或分辨率)进行缩放,而EfficientNet则结合了这三者,使得模型的计算效率和精度都得到了优化。
具体来说,EfficientNet架构包含以下几个关键点:
-
复合缩放(Compound Scaling):
- EfficientNet采用复合缩放方法,不是单独地调整网络的深度、宽度或分辨率,而是将三者结合,在缩放时保持它们之间的比例关系。通过这一方法,网络能够在给定的计算量下,以最小的损失提高模型的精度。
-
Mobile Inverted Bottleneck(MBConv)模块:
- 该模块是EfficientNet的核心构建模块,它结合了深度可分离卷积(Depthwise Separable Convolution)和倒置瓶颈结构,从而在计算量和参数量之间实现了较好的平衡。
-
神经架构搜索(NAS):
- EfficientNet的网络结构是在神经架构搜索(NAS)算法的指导下,自动化地寻找最优的架构。通过NAS,可以获得在性能上更为优秀的网络结构。
-
高效的激活函数:
- EfficientNet采用了Swish激活函数,Swish相比ReLU和LeakyReLU在一定程度上能提高模型的表现。
-
层次化结构:
- EfficientNet模型通过深度、宽度和输入分辨率的合理调整,保持网络层次的层次化结构,使得计算资源可以得到最充分的利用。
EfficientNet的应用场景
EfficientNet可以广泛应用于各类计算机视觉任务中,尤其是在需要高效计算资源的情况下,表现尤为突出。主要的应用场景包括:
- 图像分类:在ImageNet等数据集上,EfficientNet能够在保证高准确度的同时,显著减少计算资源消耗。
- 目标检测:适用于在高效计算的前提下进行复杂的目标检测任务。
- 语义分割:EfficientNet在图像分割任务中也能展现出强大的性能,特别是在有限的硬件资源下。
- 迁移学习:EfficientNet因其优秀的泛化能力,常常用于迁移学习任务,通过微调适应不同领域的需求。
EfficientNet与ResNet的对比
EfficientNet和ResNet都是现代深度学习中的重要网络架构,它们各自有着不同的设计理念和优缺点。我们可以从以下几个方面进行对比:
-
模型复杂度与计算效率:
- ResNet:ResNet通过引入残差连接(skip connection)解决了深层网络训练中的梯度消失问题,使得网络可以非常深(通常达到100层以上),但仍然能够训练收敛。ResNet网络的设计注重深度,但对于计算资源的需求也较大。
- EfficientNet:EfficientNet采用复合缩放,合理地调整网络的深度、宽度和分辨率,从而在相同的计算资源下获得更高的性能。相较于ResNet,EfficientNet在相同计算量下,通常能够提供更好的准确度和更少的计算开销。
-
精度:
- 在ImageNet等标准数据集上,EfficientNet通常能够提供比ResNet更高的准确度。例如,EfficientNet在ImageNet上的Top-1准确率明显高于ResNet-50,并且计算量更低。
-
训练速度和计算资源:
- ResNet:由于ResNet网络的深度,训练时需要更多的计算资源。
- EfficientNet:通过复合缩放,EfficientNet能在较低的计算资源下实现高效训练,尤其适用于硬件受限的设备,如移动端设备。
EfficientNetB0 和 ResNet 架构比较
下面是两种模型架构的详细解释与对比,首先我将分别讲解两种模型的结构,再进行对比,并绘制成图表格式。
1. EfficientNetB0 架构解析
EfficientNetB0 是 EfficientNet 系列中的一种轻量级卷积神经网络,其架构基于深度可分离卷积和多种优化策略。以下是其主要组成部分:
- 输入层(Input Layer): 输入尺寸为
(32, 32, 3),代表32x32的RGB图像。 - Rescaling Layer: 将输入图像的像素值标准化,将像素值从[0, 255]缩放到[0, 1]。
- Normalization: 对输入进行归一化处理,帮助模型更好地收敛。
- Stem Block:
ZeroPadding2D: 用于在图像边缘添加填充,使后续卷积操作不会丢失信息。Conv2D(卷积层): 采用3x3卷积核,将输入转换为16x16x32的特征图。BatchNormalization(批归一化) +Activation: 对卷积层输出进行标准化,并通过ReLU激活函数。
- Block1:
DepthwiseConv2D: 深度可分离卷积,减少计算量和参数量,输出32通道的16x16特征图。- 后续的类似结构包括多个
DepthwiseConv2D和Conv2D层,逐渐提取更高级的特征。
- 最后的输出层:
- 通过全连接层和softmax输出10个类别的预测结果。
2. ResNet 架构解析
ResNet(Residual Networks)是另一种深度卷积神经网络,它通过残差连接(skip connections)克服了深度网络中梯度消失和梯度爆炸的问题。以下是其主要组成部分:
- 输入层(Input Layer): 输入尺寸为
(32, 32, 3),同样代表32x32的RGB图像。 - Conv1 Block:
ZeroPadding2D: 对输入图像进行填充,使后续的卷积操作保持一致性。Conv2D(卷积层): 采用3x3卷积核,将输入转换为16x16x64的特征图。BatchNormalization+Activation: 对卷积输出进行标准化,并通过ReLU激活函数。
- Pool1 Block:
MaxPooling2D: 对卷积层的输出进行最大池化,降低空间维度,减少计算量。
- Block2:
- 包含多个残差单元(Residual Blocks),每个残差单元包括卷积层、批归一化、激活函数等,核心是残差连接,用于加强信息流。
- 最后的输出层:
- 类似EfficientNet,ResNet也会通过全连接层和softmax输出分类结果。
3. 对比分析
| 特性 | EfficientNetB0 | ResNet |
|---|---|---|
| 网络结构 | 基于复合缩放(Compound Scaling),采用深度可分离卷积 | 基于残差连接,传统的卷积层结构 |
| 输入尺寸 | (32, 32, 3) | (32, 32, 3) |
| 卷积层 | 深度可分离卷积(减少计算量) | 传统卷积层+残差连接 |
| 池化层 | 使用深度卷积和步长2的卷积替代池化层 | 使用最大池化层(MaxPooling2D) |
| 特点 | 轻量化设计,高效的计算和内存使用 | 深度网络结构,通过残差连接解决梯度消失 |
| 应用场景 | 适用于计算资源受限的场景,如移动端、嵌入式设备 | 适用于需要解决深度训练难题的场景 |
图表展示:EfficientNetB0 和 ResNet 架构
EfficientNetB0 架构图表:
| Layer (type) | Output Shape | Param # | Connected to |
|---|---|---|---|
| Input Layer (InputLayer) | (None, 32, 32, 3) | 0 | - |
| Rescaling (Rescaling) | (None, 32, 32, 3) | 0 | Input Layer |
| Normalization (Normalization) | (None, 32, 32, 3) | 7 | Rescaling |
| Stem Conv Pad (ZeroPadding2D) | (None, 33, 33, 3) | 0 | Normalization |
| Stem Conv (Conv2D) | (None, 16, 16, 32) | 864 | Stem Conv Pad |
| Stem BN (BatchNormalization) | (None, 16, 16, 32) | 128 | Stem Conv |
| Stem Activation (Activation) | (None, 16, 16, 32) | 0 | Stem BN |
| Block1a DwConv (DepthwiseConv2D) | (None, 16, 16, 32) | 288 | Stem Activation |
ResNet 架构图表:
| Layer (type) | Output Shape | Param # | Connected to |
|---|---|---|---|
| Input Layer (InputLayer) | (None, 32, 32, 3) | 0 | - |
| Conv1 Pad (ZeroPadding2D) | (None, 38, 38, 3) | 0 | Input Layer |
| Conv1 Conv (Conv2D) | (None, 16, 16, 64) | 9,472 | Conv1 Pad |
| Conv1 BN (BatchNormalization) | (None, 16, 16, 64) | 256 | Conv1 Conv |
| Conv1 Relu (Activation) | (None, 16, 16, 64) | 0 | Conv1 BN |
| Pool1 Pad (ZeroPadding2D) | (None, 18, 18, 64) | 0 | Conv1 Relu |
| Pool1 Pool (MaxPooling2D) | (None, 8, 8, 64) | 0 | Pool1 Pad |
| Conv2 Block1 1 Conv (Conv2D) | (None, 8, 8, 64) | 4,160 | Pool1 Pool |
| Conv2 Block1 1 BN (BatchNormalization) | (None, 8, 8, 64) | 256 | Conv2 Block1 1 Conv |
- EfficientNetB0 采用了深度可分离卷积和复合缩放策略,目的是在尽可能小的参数量下达到较高的效率和性能。它非常适合在资源受限的设备上使用(例如移动设备)。
- ResNet 则通过残差连接让网络变得更深,避免了传统深度网络中的梯度消失问题。这使得 ResNet 在训练非常深的网络时更为有效。
EfficientNet实例应用
让我们通过一个实际的例子,使用TensorFlow Keras库实现EfficientNet,并与ResNet进行对比。我们选择的是Keras库自带的CIFAR-10数据集,进行图像分类任务。
1.首先加载数据集,这里使用cifar10数据集。
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import cifar10
# 加载CIFAR-10数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()x_train.shape(50000, 32, 32, 3)
可以看到训练数据有50000张图片,并且图片是32*32大小的3颜色通道图像。
from matplotlib import pyplot as plt
plt.subplot(131)
plt.imshow(x_train[1])
plt.subplot(132)
plt.imshow(x_train[2])
plt.subplot(133)
plt.imshow(x_train[3])
展示出一些图像进行查看。
2.为了方便比较resnet50和EfficientNet,我将从两个方面进行研究,第一,探索两个架构在不使用预训练参数的情况下,也就是从头开始训练模型,比较其准确率和损失。其二,对两个模型都使用预训练好的参数,比较其准确率和损失值。其他参数,例如epochs=10, batch_size=64都保持一致。
EfficientNet:从头开始训练
# 归一化处理
x_train, x_test = x_train / 255.0, x_test / 255.0
# 使用EfficientNet模型进行训练
efficientnet_model = tf.keras.applications.EfficientNetB0(
include_top=True,
weights=None, # weights='imagenet', 表示从头开始训练
input_shape=(32, 32, 3),
classes=10
)
# 编译模型
efficientnet_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型并记录历史
history = efficientnet_model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test))
# 测试模型
test_loss, test_acc = efficientnet_model.evaluate(x_test, y_test, verbose=2)
print(f"EfficientNet Test accuracy: {test_acc}")
# 绘制损失图
plt.figure(figsize=(10, 6))
# 绘制训练和验证的损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
# 添加标题和标签
plt.title('Loss during Training and Validation')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 显示图像
plt.show()
Epoch 1/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 119s 73ms/step - accuracy: 0.1605 - loss: 3.4596 - val_accuracy: 0.1718 - val_loss: 2.4781 Epoch 2/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 26ms/step - accuracy: 0.2614 - loss: 2.3754 - val_accuracy: 0.2990 - val_loss: 3.5932 Epoch 3/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.3080 - loss: 2.1670 - val_accuracy: 0.2642 - val_loss: 2.0965 Epoch 4/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.2998 - loss: 2.2079 - val_accuracy: 0.3511 - val_loss: 1.7923 Epoch 5/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.3160 - loss: 2.1311 - val_accuracy: 0.2875 - val_loss: 2.4609 Epoch 6/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.2823 - loss: 2.2442 - val_accuracy: 0.3555 - val_loss: 1.8949 Epoch 7/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.3466 - loss: 2.0003 - val_accuracy: 0.3637 - val_loss: 1.9848 Epoch 8/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.3813 - loss: 1.8895 - val_accuracy: 0.3848 - val_loss: 1.7935 Epoch 9/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.3739 - loss: 1.9279 - val_accuracy: 0.3653 - val_loss: 1.7812 Epoch 10/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 21s 27ms/step - accuracy: 0.3726 - loss: 1.9205 - val_accuracy: 0.4238 - val_loss: 1.6427 313/313 - 5s - 17ms/step - accuracy: 0.4238 - loss: 1.6427 EfficientNet Test accuracy: 0.423799991607666
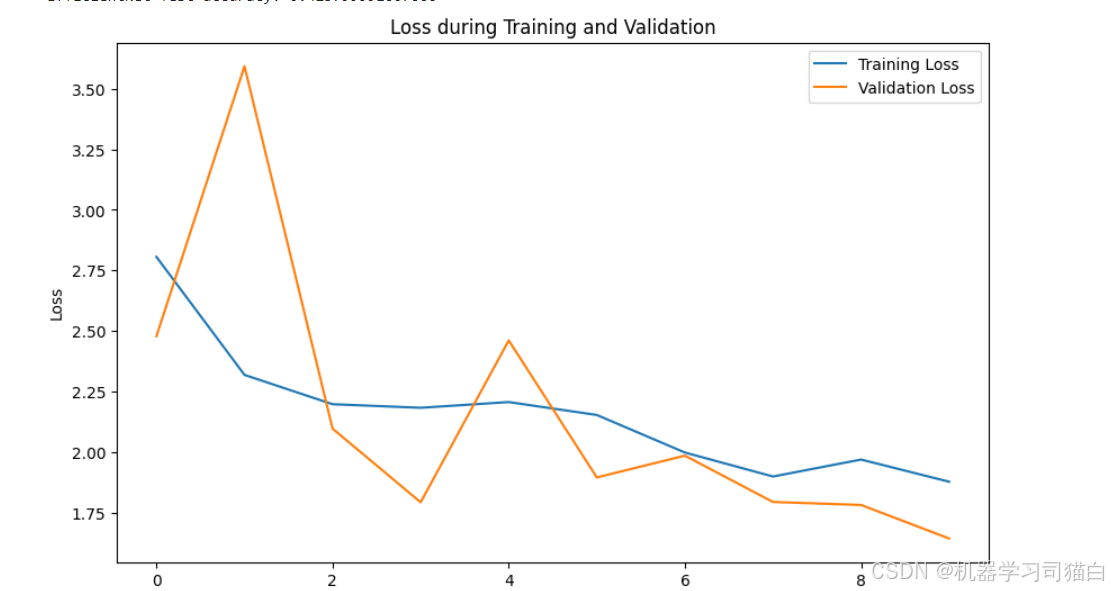
resnet50:从头开始训练
# 使用ResNet-50模型进行训练
resnet_model = tf.keras.applications.ResNet50(
include_top=True,
weights=None,
input_shape=(32, 32, 3),
classes=10
)
# 编译模型
resnet_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型并记录历史
history = resnet_model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test))
# 测试模型
test_loss, test_acc = resnet_model.evaluate(x_test, y_test, verbose=2)
print(f"ResNet Test accuracy: {test_acc}")
# 绘制损失图
plt.figure(figsize=(10, 6))
# 绘制训练和验证的损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
# 添加标题和标签
plt.title('Loss during Training and Validation')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 显示图像
plt.show()
Epoch 1/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 98s 63ms/step - accuracy: 0.3055 - loss: 2.2639 - val_accuracy: 0.4116 - val_loss: 1.6579 Epoch 2/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 35ms/step - accuracy: 0.3894 - loss: 1.8813 - val_accuracy: 0.1687 - val_loss: 2.5237 Epoch 3/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 35ms/step - accuracy: 0.4234 - loss: 1.8272 - val_accuracy: 0.1247 - val_loss: 73.8607 Epoch 4/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 35ms/step - accuracy: 0.3188 - loss: 2.1395 - val_accuracy: 0.2297 - val_loss: 2.5845 Epoch 5/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 34ms/step - accuracy: 0.4081 - loss: 1.7452 - val_accuracy: 0.4130 - val_loss: 1.6245 Epoch 6/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 34ms/step - accuracy: 0.4723 - loss: 1.6311 - val_accuracy: 0.2371 - val_loss: 2.5472 Epoch 7/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 34ms/step - accuracy: 0.4987 - loss: 1.5423 - val_accuracy: 0.4830 - val_loss: 3.2968 Epoch 8/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 35ms/step - accuracy: 0.5589 - loss: 1.3475 - val_accuracy: 0.5539 - val_loss: 1.7728 Epoch 9/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 34ms/step - accuracy: 0.6003 - loss: 1.2565 - val_accuracy: 0.3240 - val_loss: 2.1211 Epoch 10/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 27s 35ms/step - accuracy: 0.5625 - loss: 1.4461 - val_accuracy: 0.5895 - val_loss: 1.1765 313/313 - 4s - 14ms/step - accuracy: 0.5895 - loss: 1.1765 ResNet Test accuracy: 0.5895000100135803
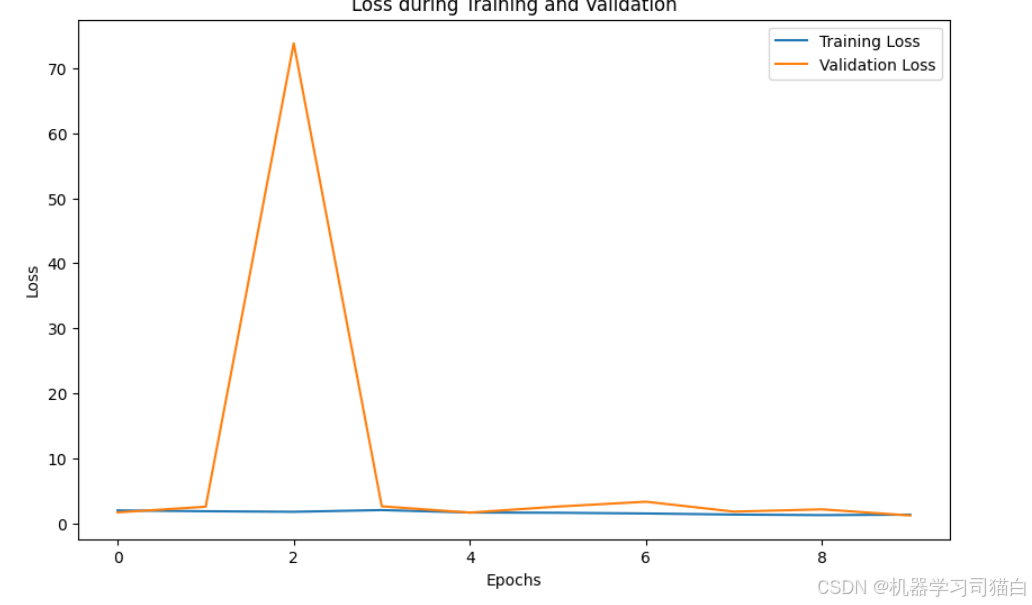
EfficientNet:使用预训练参数
# 使用EfficientNet模型进行训练 (不包括顶部的全连接层)
efficientnet_model = tf.keras.applications.EfficientNetB0(
include_top=False, # 不包含顶部的分类层
weights='imagenet', # 使用ImageNet预训练权重
input_shape=(32, 32, 3)
)
# 冻结预训练的层,不训练它们
efficientnet_model.trainable = False
# 在EfficientNet的顶部添加一个自定义的分类层
model = tf.keras.Sequential([
efficientnet_model,
tf.keras.layers.GlobalAveragePooling2D(), # 使用全局平均池化层
tf.keras.layers.Dense(10, activation='softmax') # CIFAR-10 有 10 个分类
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型并记录历史
history = model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test))
# 测试模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f"EfficientNet Test accuracy: {test_acc}")
# 绘制损失图
plt.figure(figsize=(10, 6))
# 绘制训练和验证的损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
# 添加标题和标签
plt.title('Loss during Training and Validation')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 显示图像
plt.show()
Epoch 1/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 39s 28ms/step - accuracy: 0.1013 - loss: 2.3282 - val_accuracy: 0.1000 - val_loss: 2.3202 Epoch 2/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.0990 - loss: 2.3311 - val_accuracy: 0.1000 - val_loss: 2.3488 Epoch 3/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.0971 - loss: 2.3280 - val_accuracy: 0.1000 - val_loss: 2.3273 Epoch 4/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.0984 - loss: 2.3272 - val_accuracy: 0.1000 - val_loss: 2.3191 Epoch 5/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.1045 - loss: 2.3287 - val_accuracy: 0.1000 - val_loss: 2.3206 Epoch 6/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.1032 - loss: 2.3272 - val_accuracy: 0.1000 - val_loss: 2.3103 Epoch 7/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.0990 - loss: 2.3287 - val_accuracy: 0.1000 - val_loss: 2.3229 Epoch 8/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.1001 - loss: 2.3273 - val_accuracy: 0.1000 - val_loss: 2.3333 Epoch 9/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.1002 - loss: 2.3312 - val_accuracy: 0.1000 - val_loss: 2.3290 Epoch 10/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 8s 10ms/step - accuracy: 0.0994 - loss: 2.3294 - val_accuracy: 0.1000 - val_loss: 2.3264 313/313 - 5s - 15ms/step - accuracy: 0.1000 - loss: 2.3264 EfficientNet Test accuracy: 0.10000000149011612
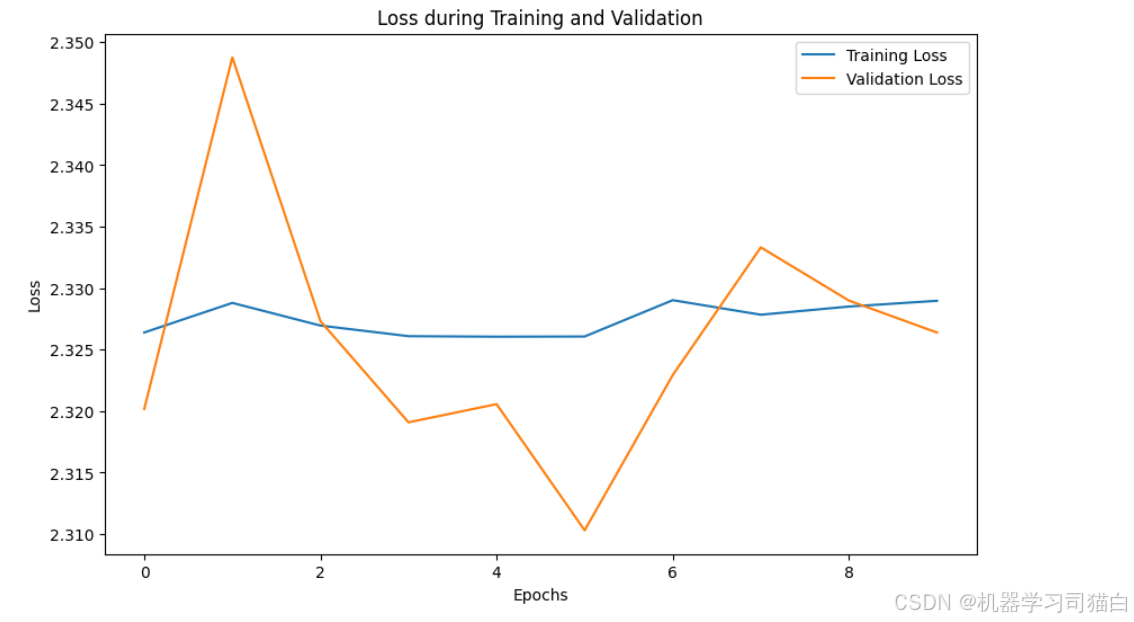
ResNet:使用预训练参数
# 使用ResNet-50模型进行训练 (不包括顶部的全连接层)
resnet_model = tf.keras.applications.ResNet50(
include_top=False, # 不包含顶部的分类层
weights='imagenet', # 使用ImageNet预训练权重
input_shape=(32, 32, 3)
)
# 冻结预训练的层,不训练它们
resnet_model.trainable = False
# 在ResNet-50的顶部添加一个自定义的分类层
model = tf.keras.Sequential([
resnet_model,
tf.keras.layers.GlobalAveragePooling2D(), # 使用全局平均池化层
tf.keras.layers.Dense(10, activation='softmax') # CIFAR-10 有 10 个分类
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型并记录历史
history = model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test))
# 测试模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f"ResNet Test accuracy: {test_acc}")
# 绘制损失图
plt.figure(figsize=(10, 6))
# 绘制训练和验证的损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
# 添加标题和标签
plt.title('Loss during Training and Validation')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 显示图像
plt.show()
94765736/94765736 ━━━━━━━━━━━━━━━━━━━━ 4s 0us/step Epoch 1/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 24s 20ms/step - accuracy: 0.0980 - loss: 2.4080 - val_accuracy: 0.1000 - val_loss: 2.3360 Epoch 2/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 12ms/step - accuracy: 0.0980 - loss: 2.3526 - val_accuracy: 0.1000 - val_loss: 2.3432 Epoch 3/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 12ms/step - accuracy: 0.1007 - loss: 2.3432 - val_accuracy: 0.1000 - val_loss: 2.3263 Epoch 4/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 11ms/step - accuracy: 0.1027 - loss: 2.3470 - val_accuracy: 0.1000 - val_loss: 2.3581 Epoch 5/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 11ms/step - accuracy: 0.0996 - loss: 2.3540 - val_accuracy: 0.1000 - val_loss: 2.3316 Epoch 6/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 11ms/step - accuracy: 0.0993 - loss: 2.3496 - val_accuracy: 0.1000 - val_loss: 2.4083 Epoch 7/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 12ms/step - accuracy: 0.1008 - loss: 2.3473 - val_accuracy: 0.1000 - val_loss: 2.4054 Epoch 8/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 11ms/step - accuracy: 0.1002 - loss: 2.3534 - val_accuracy: 0.1000 - val_loss: 2.3475 Epoch 9/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 11ms/step - accuracy: 0.0993 - loss: 2.3522 - val_accuracy: 0.1000 - val_loss: 2.3304 Epoch 10/10 782/782 ━━━━━━━━━━━━━━━━━━━━ 9s 11ms/step - accuracy: 0.1008 - loss: 2.3523 - val_accuracy: 0.1000 - val_loss: 2.3446 313/313 - 4s - 12ms/step - accuracy: 0.1000 - loss: 2.3446 ResNet Test accuracy: 0.10000000149011612

这里的准确率确实比较差,因为并没有进行细致的调参,只是为了比较两种模型,图像大小可以调整为224*224,并且epoch可以适当增加,batch_size可以适当缩小。这样效果应该会变好。
最后,制作不易,如果我的内容对你有帮助,请动动发财的小手,点个关注,非常感谢。



















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











