






目录
数据探索阶段
adult数据集链接
首先下载并提取出数据
- adult.data改为csv
- adult.test后缀名也要改为csv,并且不能和adult重名
- adult.name是介绍
字段名:特征字段一共有13个,y值为二分类标签,目标就是预测y值
注意:给的adult.csv是不包括字段名的,所以需要我们自己设置字段名,方便后续dataframe索引与数据处理
age:年龄(离散数值,整数) workclass:工作类别(如私人公司、自雇、政府、无薪工作等) fnlwgt:人口普查使用的加权值(连续数值,用于抽样权重) education:教育水平(如学士、硕士、博士、小学等) education-num:对应教育水平的数值表示(离散数值,整数) marital-status:婚姻状况(如已婚、离婚、未婚、分居等) occupation:职业类型(如销售、技术支持、管理者、军人等) relationship:与家庭关系(如丈夫、妻子、子女、非家庭成员等) race:种族(如白人、黑人、亚太裔、美洲印第安人等) sex:性别(男性或女性) capital-gain:资本收益(连续数值) capital-loss:资本损失(连续数值) hours-per-week:每周工作小时数(离散数值,整数) native-country:出生国家或地区(如美国、加拿大、中国、墨西哥等)
# 附上处理源码
def get_data(type_):
"""type_: 训练还是测试数据"""
if type_ == "train":
data = pd.read_csv(base_dir + "/adult/adult.csv", header=None, sep=", ", engine="python")
else:
data = pd.read_csv(base_dir + "/adult/adult_test.csv", header=None, sep=", ", engine="python")
print(data.head(1).values) # 观察一下数据
data.columns = X_feature + ["y_label"] # X_feature就是上面一大堆的字段名
name = "<=50K" if type_ == "train" else "<=50K." # 训练集和测试集的y值不一样!!!!!!!!!!!!!
data["y_label"] = data["y_label"].apply(lambda x: 0 if x == name else 1) # 判断薪资进行标注
return data[X_feature], data["y_label"] # 返回X和y
值分为数值型与字符串型,大部分为离散型,只有6个字段为数值型
- 字符串型数据:由于字符串的数据无法作为一个特征输入模型,所以需要对数据进行编码,常见的有独热编码(和哑变量有点像,但是可以保留所有列,只有01,一共n列),标签编码(直接根据标签类数进行编码,有n种值取值范围为[0, n - 1],一共1列)
- 数值型数据:常见的有标准化,离散的数值变量可以通过哑变量(要记得去掉一列,防止多重共线性,只有01,一共n-1列)输入线性模型。因为采用lgbm树模型所以标准化与哑变量对树的拟合差别不大,甚至容易维度爆炸
数据清洗
缺失值处理
-
预测建模非常重要的就是观察原始数据分布与数值分析
-
注意到存在问号缺失值,所以必须查看什么值缺失,如何处理缺失
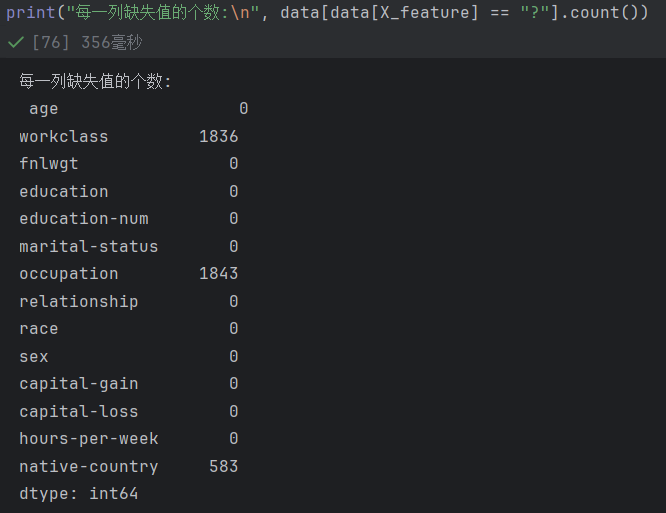
-
缺失集中在workclass,occupation,native-country,分别是工作类别,职业类型,出生国家
这些数值都是字符串型变量,可以通过“大众化”,也就是利用出现次数最多的工作类别,职业类型,出生国家来填补缺失值
如果是数值型变量,可以采用均值的方式填充(如果是时间序列也可以采用上一个时间节点的数据)
异常值处理
利用describe,对所有数值型变量看一下分布
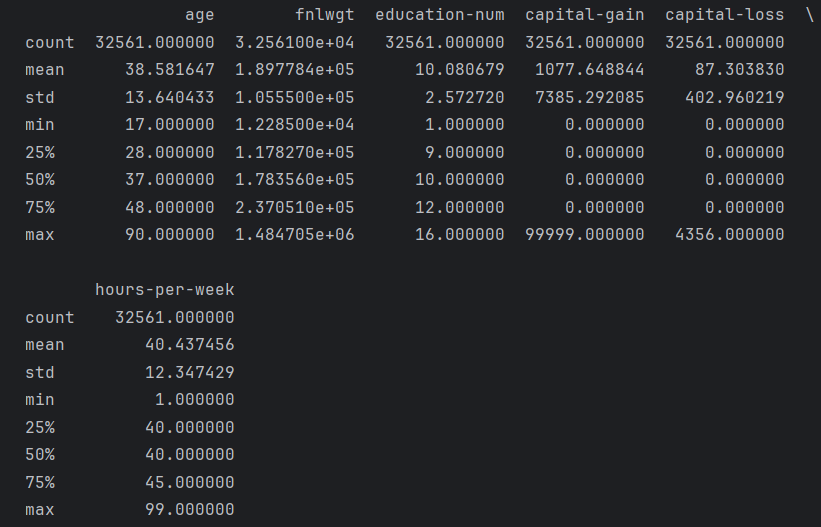
每一个特征都看过去
-
age,fnlwgt,education-num,hours-per-week都很正常
-
而capital-gain和capital-loss的数值非常诡异,std非常大,而且上四分位数均为0,说明0是大多数,需要考虑处理这些异常值
-
删除特值法:删除的好处在于模型不会拟合到异常值,是非常好用的方法,并且删除这几条数据对整体影响很小(不同数据集需要不同的讨论方法,如果时间序列删除这段时间就需要考虑时变特征会不会收到影响(滞后项,滑动窗口等))
-
二值化:由于等于0的值占大多数,所以我们可以将数值分为两类,一类等于0的值为0,一类大于0的值为1,直接区分有无capital,防止过大的capital异常值影响模型判断
缺点:无法分清capital中的数值差异,如果capital_gain为1和99999都将被归类到1,会影响模型的准确程度(也可以按照多层次划分,但是大于0的数是小部分,意味着划分出来其他类别的数字占比也会很小,可能1000个0,10个1,3个2这种特征对模型的拟合起不到很好的作用)
-
删除特征法:既然大部分数据都是0,那么通过删除这两个特征,就可以在保留数据集大小的情况下进行训练
缺点:可能这个特征是树模型中具有高信息增益的靠近根节点的分裂节点(所以可以在删除特征前后对比一下准确率或者F-score)
-
-
数据分析与特征工程
数据可视化
对于分类任务,最好先看看每一个种类的分布情况,这是一个不均衡的样本!!!
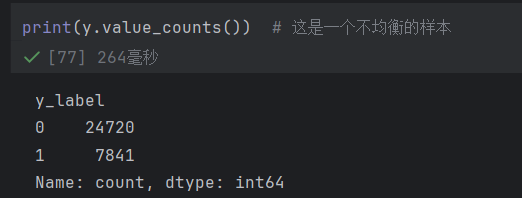
可视化出来一下
接下来探究特征分布与y值之间的关系
代码如下
def feature_explain(ax, data, feature_name, y, use_int=False):
"""特征解释函数,通过输入特征名称,获取该特征的分布情况与薪水分类的关系,同于数值型的特征!!!"""
feature_one = []
feature_zero = []
feature_range = []
bins = 10 # 分桶数量
explain_data = data.copy() # 不要对原数据进行修改,血的教训
bin_range = np.linspace(explain_data[feature_name].min(), explain_data[feature_name].max(), num=bins) # 分桶
delta = bin_range[1] - bin_range[0] # 间隔,后续用于确定范围与柱状图柱宽
explain_data["y"] = y # 把y对应上,否则加入mask后会错位
for i in bin_range:
next_i = i + delta
range_mask = (explain_data[feature_name] >= i) & (explain_data[feature_name] < i + bins) # 取出范围内的值
if use_int:
feature_range.append(f"{int(i)}-{int(next_i)}") # 使用int就直接按照整数输出,否则保留一位小数
else: # 因为大部分都是整数,所以没有必要保留一位小数点(虽然用int不严谨,精度损失太大)
feature_range.append(f"{i:.1f}-{next_i:.1f}")
range_data = explain_data[range_mask]
feature_zero.append(range_data[range_data["y"] == 0].count()[0]) # 取出y==0的数量
feature_one.append(range_data[range_data["y"] == 1].count()[0])
percent_one = ["{:.2f}%".format(feature_one[i] / (feature_one[i] + feature_zero[i]) * 100) for i in range(len(feature_one))]
percent_zero = ["{:.2f}%".format(feature_zero[i] / (feature_one[i] + feature_zero[i]) * 100) for i in range(len(feature_zero))]
zero_bar = plt.bar(bin_range, feature_zero, width=delta * 0.75, label="<=50k", align="center", tick_label=feature_range) # 将0值的样本数放在下面
one_bar = plt.bar(bin_range, feature_one, width=delta * 0.75, label=">50k", bottom=feature_zero, align="center") # 利用bottom参数,将1值得样本数叠放在上面
ax.bar_label(one_bar, labels=percent_one, label_type="center", fontsize=10, color="white") # 设置柱状图的内部文字,可以控制位置
ax.bar_label(zero_bar, labels=percent_zero, label_type="center", fontsize=10, color="white")
ax.set_title(f"{feature_name}与薪水分类分布图")
ax.set_ylabel("样本数")
ax.set_xlabel(f"{feature_name}范围")
ax.legend()
# for i in range(1, 7):
# feature_explain(plt.subplot(int(f"23{i}")), data, continue_name[i - 1], y, use_int=True)
# 封装成函数就是方便调用,一次性能研究很多个特征与y的关系
fig = plt.figure(figsize=(12, 14))
feature_explain(plt.subplot(311), data, "age", y, use_int=True)
feature_explain(plt.subplot(312), data, "education-num", y, use_int=True)
feature_explain(plt.subplot(313), data, "hours-per-week", y, use_int=True)
plt.savefig("feature_explain.png", dpi=300, bbox_inches='tight')
```
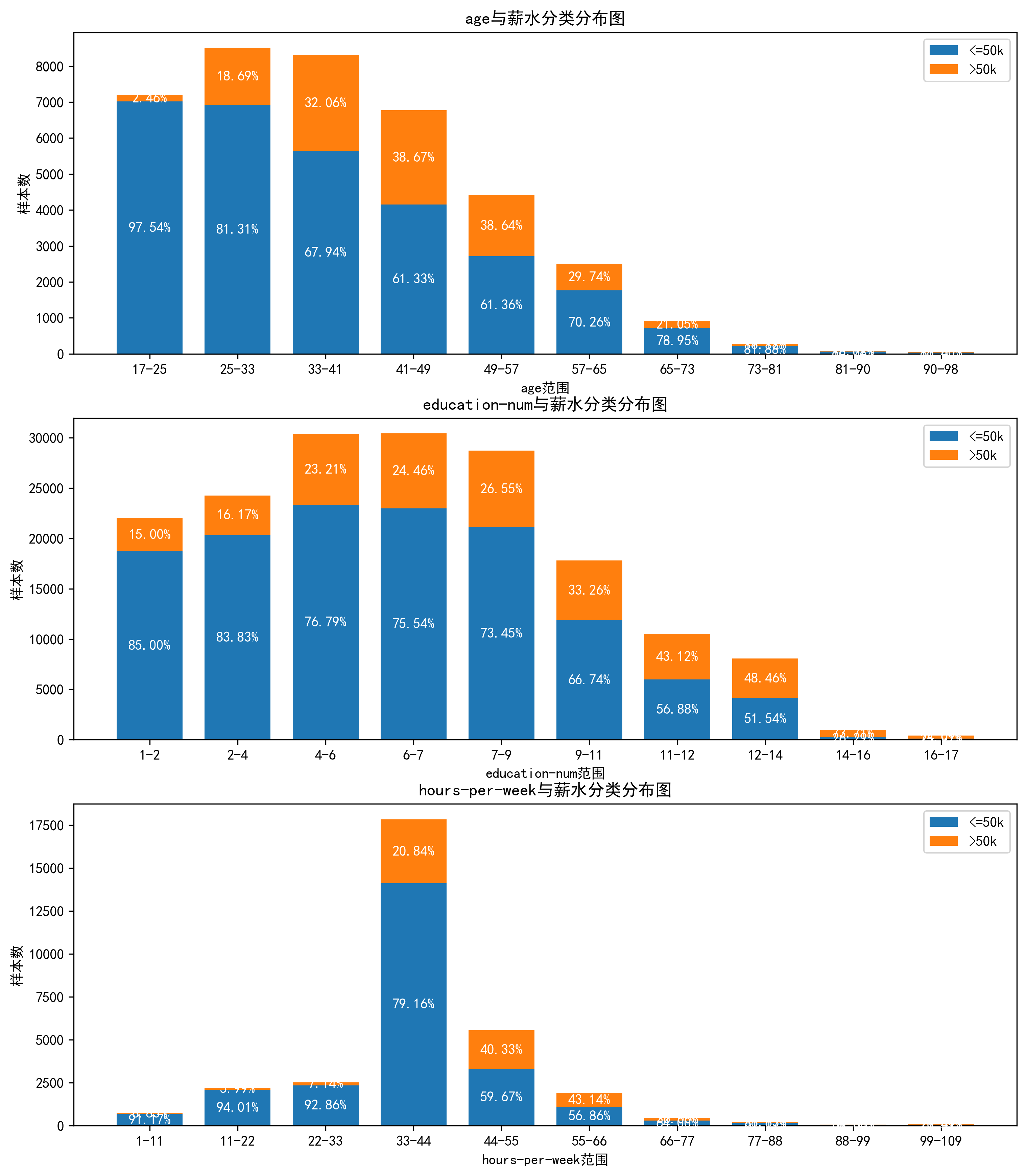
ps:这个绘图还有一些不足就是占比很小的时候,很难判断占比值
对这三个特征进行分析
- 一般人到中年更加容易高薪,且样本中青中年人数占比更高
- 学历越高,高薪概率越大,不过学历高的占比也很低
- 每周工作时间越长, 越容易高薪**,但是大部分人的工作市场集中在33-44小时,国外8小时工作制加劳动法保护,所以40个工作小时的人数最多
特征工程
只做了3件事,字符串编码,缺失值填充,异常值处理
附上详解代码
def feature_create(data):
"""data是传入的数据"""
dtype = data.dtypes.to_dict() # 获得每一个特征的类型(数值如果混了字符串也是object)
le = LabelEncoder() # 标签encoder,是sklearn的包
need_encoder = [] # 判断是否需要标签编码化
for k, v in dtype.items():
if str(v) == "object":
print(f"{k}为字符串型:" + data[k].value_counts().index[0])
data[k] = data[k].replace("?", data[k].value_counts().index[0]) # 缺失值按照最多出现的词填充
need_encoder.append(k)
else:
print(f"{k}为数值型:" + f"{data[k].mean()}")
data[k] = data[k].replace("?", data[k].mean()) # 按照均值,虽然用不上,这里如果用上round或者int更好一点(都是整数),用不上也不用改
# 该如何处理异常值才是最优结果?
# data["capital-gain"] = np.where(data["capital-gain"] > 0, 1, 0) # 二值化
# data["capital-loss"] = np.where(data["capital-loss"] > 0, 1, 0)
mask = (data["capital-gain"] == 0) | (data["capital-loss"] == 0) # 删除非0值
data = data[mask]
# data.drop(["capital-loss", "capital-gain"], axis=1, inplace=True) # 删除这两个特征
for i in need_encoder:
data[i] = le.fit_transform(data[i]) # 针对每一个feature进行编码
# data[need_encoder] = data[need_encoder].astype("category") # 将需要编码的特征转换为独热编码
# data = pd.get_dummies(data) # 独热编码特征对树模型没啥效果
return data
训练与测试
训练
写了一个通用的训练函数,只需要利用sklearn的train_test_split分割训练集与验证集,直接输入就可以直接训练
并且支持多个参数,代码详解如下
def explain(y_pred, y_val):
"""预测值和实际值,不仅可以用于验证集,测试集也可以"""
acc = accuracy_score(y_val, y_pred) # 计算准确率
rec = recall_score(y_val, y_pred, average='macro') # 计算召回率,macro是正负召回率平均,micro只考虑正召回率
print(f"准确率 (Accuracy): {acc:.4f}")
print(f"召回率 (Recall): {rec:.4f}")
print(classification_report(y_val, y_pred, target_names=["<=50K", ">50K"], digits=4)) # 这是非常好用的展示分类效果的函数,强烈推荐,sklearn里面和accuracy在同一个包里
def train_model(X_train, y_train, X_val, y_val, model, grid_search=False, name=False):
"""
可选参数
:param model: 选用的模型,xgb或者lgb
:param grid_search: 是否采用网格搜索
:param name:模型的名称
:return: 返回模型值
支持xgb和lgb的模型训练(这俩树模型一起调用sklearn的接口)
"""
model_name = {LGBMClassifier: "lgb", XGBClassifier: "xgb"}
if grid_search:
param_grid = {
"learning_rate": [0.01, 0.05, 0.1, ],
"max_depth": [3, 5, 7],
"subsample": [0.8, 1.0],
"n_estimators": [100, 200, 300]
}
grid_search = GridSearchCV(
estimator=model(random_state=42, objective='binary'), # 如果是二分类
param_grid=param_grid, # 参数网格
cv=3, # 交叉验证次数
scoring='accuracy', # 利用准确率进行评分
n_jobs=10 # 采用核心数量
)
grid_search.fit(X_train, y_train) # 训练比较久,xgb更久,建议lgb
best_params = grid_search.best_params_
print("最佳参数:", best_params)
else:
best_params = {'learning_rate': 0.01, 'max_depth': 7, 'n_estimators': 100, 'subsample': 1} # 可以随意改参数,手动试参数(
use_model = model(**best_params, random_state=42, objective='binary', n_jobs=4) # is_unbalance=True看情况加
use_model.fit(X_train, y_train)
y_pred = use_model.predict(X_val) # 预测值
acc = accuracy_score(y_val, y_pred) # 准确率
explain(y_pred, y_val) # 这里是验证的展示函数
if type(name) == str:
joblib.dump(use_model, get_dir_name(True) + f"/models/{model_name[model]}_{name}_acc{acc:.3f}.pkl")
return use_model
# 在准备好数据之后就可以进行处理了
data = feature_create(data) # 前面提到的特征工程
print(data.iloc[0]) # 展示一下输入的内容
X_train, X_test, y_train, y_test = train_test_split(data, y, test_size=0.2) # 划分测试集和验证集,验证集占总数的20%
model = train_model(X_train, y_train, X_test, y_test, LGBMClassifier, grid_search=False) # 这里可以调整参数
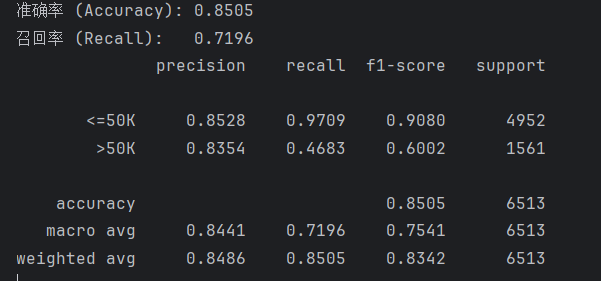
最后结果如下(下面那个矩阵就是classification_report的结果,非常清晰明了)
测试
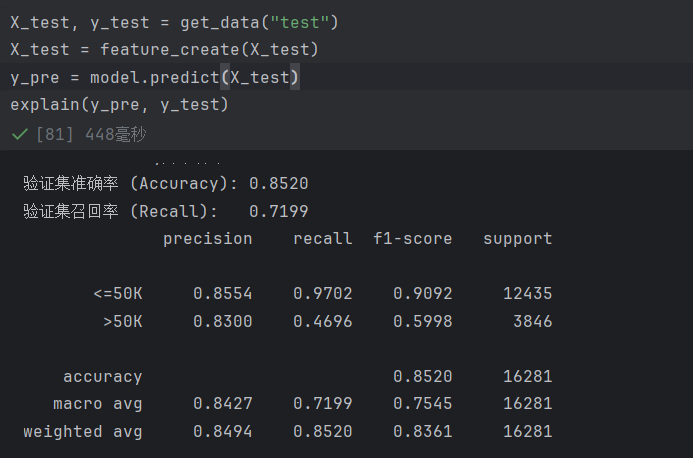
使用封装好的函数,测试也只是调用自己之前写过的函数
EX:查看特征重要性
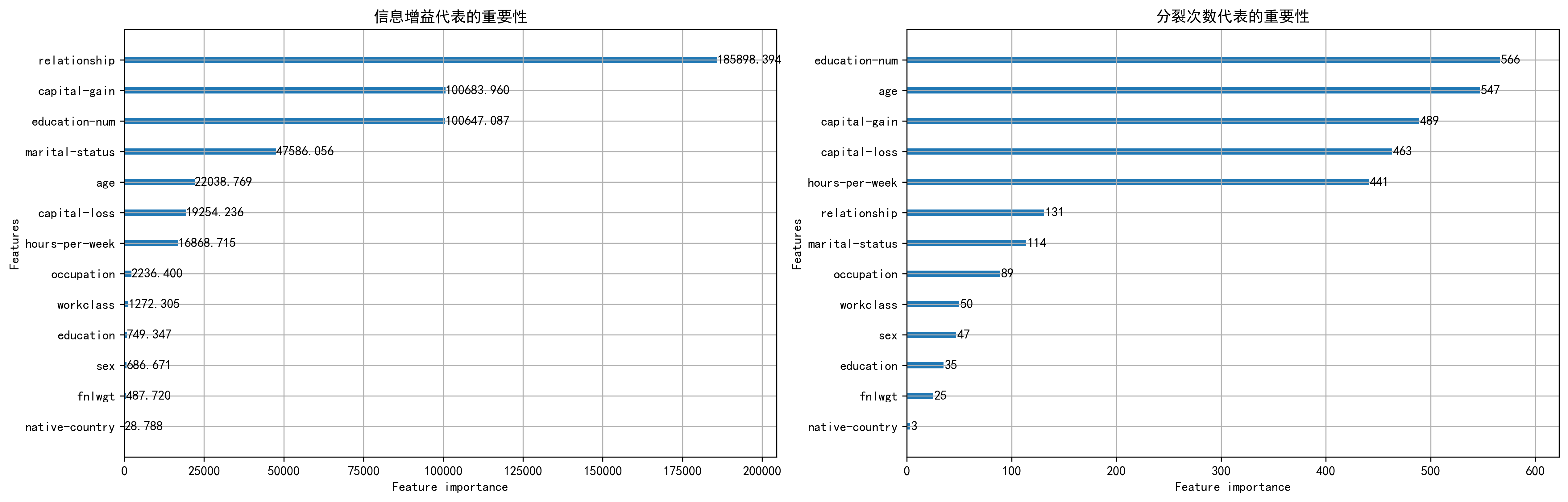
plt.show()booster = model.booster_
fig = plt.figure(figsize=(20, 6))
lgb.plot_importance(booster, max_num_features=20, ax=plt.subplot(121), importance_type="gain", figsize=(10, 6))# 不同的importance_type对应了不同重要性方法
plt.title("信息增益代表的重要性")
lgb.plot_importance(booster, max_num_features=20, ax=plt.subplot(122), importance_type="split", figsize=(10, 6))
plt.title("分裂次数代表的重要性")
plt.show()
fig.savefig("feature_importance.png", dpi=300, bbox_inches='tight')
重点讲一下importance_type
就是指定 按什么指标衡量“重要性”:
- split:计数特征被用来做分裂的次数
- gain:累计该特征在所有节点带来的 信息增益(loss 降低量)
- 想同时看两种就传入
ax=fig.subplot(121)或者122吧(放到同一张图)
为什么relationship明明信息增益很大,但是分裂次数很少呢
答:因为其更靠近根节点的分裂节点,分裂次数更少,但是其信息增益很大
为什么age明明在分裂次数中排第二,而且和第一相差无几,但是其信息增益才为第一的 1 5 \frac{1}{5} 51呢
答:因为其更靠近叶节点,末端信息增益的均值小,虽然分裂次数多,但是提供总的信息增益不行
靠近根节点覆盖的样本多,因此对损失下降做出了更大贡献,信息增益更大

















 4611
4611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









