







auto
用来推导变量类型
可以不用自己长长的变量名
如果一个变量类型是int &的类型时,用auto推导出的类型时int而不是int&,const类型的变量也是如此
变量类型的推导发生在编译时期,因为在编译期间就需要知道变量类型,,所以用auto不会增加编译时间,
decltype
和auto类似,推导变量类型,用法是在创建一个和之前变量类型相同的变量时,可以用decltype(变量)来创建
例如

using 重命名
和typedef的不同,能对模板进行重构命名,写法上也是不同
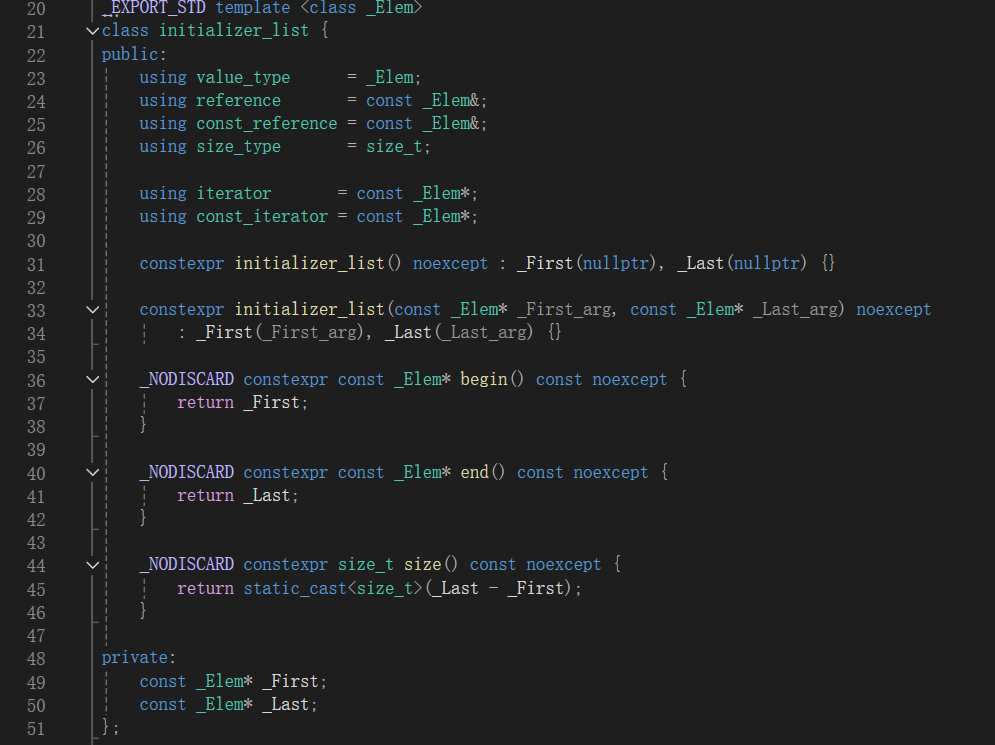
initialize list
本质上initialize list是一个类,成员包括头指针和尾指针
也就是 { } 里面的 头和尾
成员函数包括begin(),end(),size()
右值引用
左值,右值,左值引用,右值引用
左值和右值区分
左值能取地址,右值不能取地址
创建的那些变量就是左值
创建的那些临时变量就是右值(函数返回的临时变量)
一个&是左值引用
两个&(&&)是右值引用
右值具有常属性(例如x+y,匿名对象)
正常是左值引用是给左值取别名,如果要给右值取别名,需要加上const
如果用右值引用给左值取别名,可以给左值加上move
右值指的是那些将要被删除的对象
移动构造,移动赋值
移动构造和拷贝构造相对,

移动构造的目的是将参数地址进行交换,节省拷贝构造,拷贝构造消耗大
移动赋值和赋值相对

进行交换地址,由于是深拷贝,也是减少了拷贝构造,减少消耗
深拷贝就意味着需要创建和参数一模一样的对象,这个对象的值和参数的值相同,但却是不同对象
右值引用就是给右值取别名,而右值是那些不能取地址的变量(像是返回变量的时候,会调用拷贝构造创建临时变量,在调用移动构造将值交换,减少拷贝构造)
而编译器会对传值返回进行优化,正常情况下,会先用返回值当作拷贝构造函数的参数,来创建临时变量,这个临时变量在被调用函数的栈帧中,之后调用移动构造,进行交换,
优化的情况是直接在接受返回值的函数栈帧中,使用此栈帧的变量,在调用函数中使用
嵌套多层函数的右值引用
例如将自己实现的string存在也是自己写的list里,如果ilst没有右值版本的函数,但string里有右值版本的函数,进行传参不会调用到底层string的相关移动函数,
也就是说,要想调用到移动函数,需要有右值引用变量来接受右值,但是这个右值引用变量不是右值,默认是左值如果此时还需要将此变量传的到下一个函数,那么就会调用左值版本的函数,这样就导致最后没调用相关移动函数
如果是那种一个函数嵌套另一个函数,就像是一条线一样,此时传右值,每个函数都得有右值版本,而且每次传给下个函数时还得变成右值
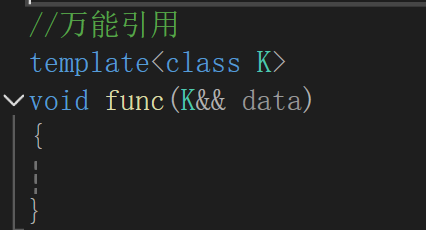
万能引用
在右值引用出现后,许多函数需要右值版本的函数(参数是右值引用的),这样需要做的重复工作就会变多,而为了解决这一情况,万能引用就诞生了(我猜的)
写法上是带有模板的函数
这样就写就可以接受右值和左值,根据所传的值的类型,在进行推导
完美转发
写法
![]()
根据T的类型进行转换
如果是右值的就转换成右值的,如果是左值的就转换成左值的
总结
右值引用就是减少深拷贝情况下的拷贝构造,
lambda
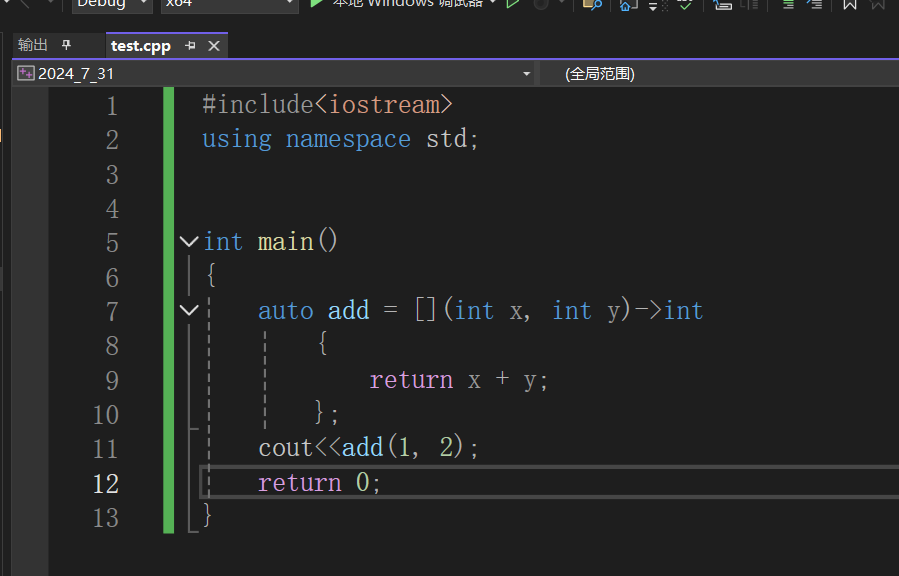
写法
[捕捉列表](参数)mutable->return_type{函数体}
[capture-list] (parameters) mutable -> return-type { statement }
捕捉列表:
由于不能直接使用lambda外作用域的变量,只能使用在lambda里的变量,如果要使用lambda以外作用域的变量,需要捕捉变量,
捕捉方式包括:
传值捕捉和传引用捕捉
写法 =,&,或是=加变量名
如果是传值捕捉,捕捉的变量默认是不可修改(const类型),如果让其变成可修改,需要在参数后变加上mutable,
如果是传引用捕捉,默认是可修改不需要加mutable
智能指针
auto_ptr 不建议用
unique_ptr 用delete禁掉
shared_ptr
















 2989
2989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











