






数据挖掘与数据分析学习
一、Jupyter Notebook 使用
1.启动
- 最好是在conda的base环境里启动
jupyter notebook
# 或
ipython notebook
2.cell使用
-
一对 In Out 会话被视作一个代码单元,称为 cell
-
jupyter支持两种模式:——附:快捷键
-
shift+enter,执行本单元代码,并跳转到下一单元
-
ctrl+enter,执行完本单元代码,留在本单元
-
命令模式:(ecs/鼠标在本单元格之外)
-
A,在当前 cell 的上面添加 cell
-
B,在当前 cell 的下面添加 cell
-
双击 D:删除当前 cell
-
y or m 切换 code 和 markdow
-
-
编辑模式:(enter/鼠标直接点)
-
多光标操作:Ctrl 键点击鼠标
-
回退:Ctrl+Z
-
补全代码:变量、方法后跟 Tab 键
-
为一行或多行代码添加/取消注释:Ctrl+/
-
-
二、matplotlib
-
最流行的Pyton底层绘图库,主要做数据可视化图表
-
三层结构:
- 1)容器层
- 画板层 Canvas
- 画布层 Figure(指整个图形(可以通过
plt.figure()设置画布的大小和分辨率等)) :plt.figure() - 绘图区/坐标系 axes(坐标轴) :
plt.subplot()- 2)辅助显示层(坐标轴,图例等辅助显示层都是建立在axes之上)
- 3)图像层
- 1)容器层
-
matplotlib.pyplot模块
-
它的函数作用于当前图形的坐标系
import matplotlib.pyplot as plt
-
1.作用
- 能将数据进行可视化,更直观的呈现
- 使数据更加客观,更具有说服力
2.常见图形种类及其意义
-
折线图plot
- 反应某事物,某指标随时间的变化状况
-
散点图scatter:用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
- 判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
-
柱状图bar:排列在工作表的列或行中的数据可以绘制到柱状图中。
- 绘制连离散的数据,能够一眼看出名个数据的大小,比较数据之间的差别(统计/对比)
-
直方图histotogram:由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据范围,纵轴表示分布情况。
- 绘制连续性的数据展示一组或者多组数据的分布状况(统计)
-
饼图pie:用于表示不同分类的占比情况,通过弧度大小来对比各种分类。
- 分类数据的占比情况(占比)
3.折线图(plot)与基础绘图功能
01.基础绘制
#创建画布
plt.figure()
#绘制图像
plt.plot([x轴数据][y轴数据])
#显示图像
plt.show()
02.设置画布属性与图片保存
plt.figure(figsize=(长,宽),dpi=)
"""
figsize:指定图的长度
dpi:图像的清晰度
返回fig对象
"""
plt.savefig(path) #path:保存路径
plt.show()会释放figure资源,如果在显示图像之后保存图片只能保存空图片
1`准备数据
-
对x,y的数据进行基础的处理
# 1、准备数据 x = range(60) # 准备60个x轴数据点 y_shanghai = [random.uniform(15,18) for i in x] #random.uniform 是均匀分布的意思# 温度变化折线图 import matplotlib.pyplot as plt import random # 1、准备数据 x = range(60) y_shanghai = [random.uniform(15,18) for i in x] y_beijing = [random.uniform(1,3) for i in x] # 2、创建画布 plt.figure(figsize=(20,8),dpi=80) # 3、绘制图像 plt.plot(x, y_shanghai) # 4、显示图像 plt.show()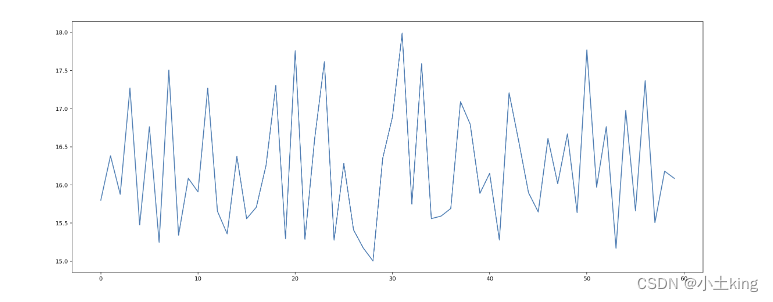](https://img-blog.csdnimg.cn/direct/f66a8cf71ce341e1a338facc20366909.png)
2`添加自定义x,y刻度
plt.xticks(x,**kwargs)
# x:x要显示的刻度
plt.yticks(y,**kwargs)
# y:y要显示的刻度
# 温度变化折线图
import matplotlib.pyplot as plt
import random
# 1、准备数据
x = range(60)
y_shanghai = [random.uniform(15,18) for i in x]
y_beijing = [random.uniform(1,3) for i in x]
# 2、创建画布
plt.figure(figsize=(20,8),dpi=80)
# 3、绘制图像
plt.plot(x, y_shanghai)
# 修改x y刻度
x_label = ["11分{}秒".format(i) for i in x]
plt.xticks(x[::5],x_label[::5])
plt.yticks(range(0,40,5))
# 4、显示图像
plt.show()
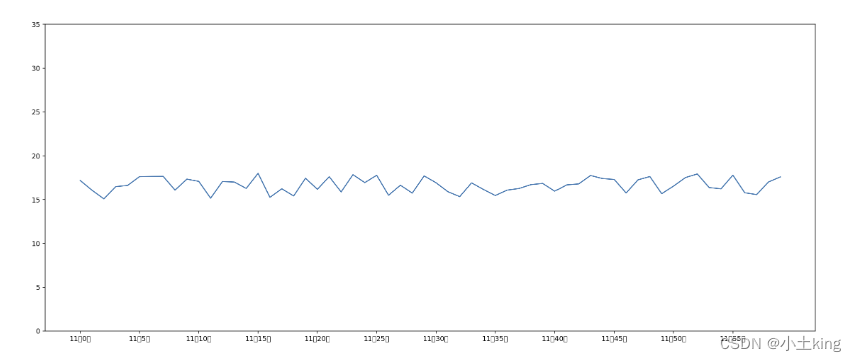
3`中文问题解决
-
我们发现上图中的中文全都替换为方框
-
加两行代码
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号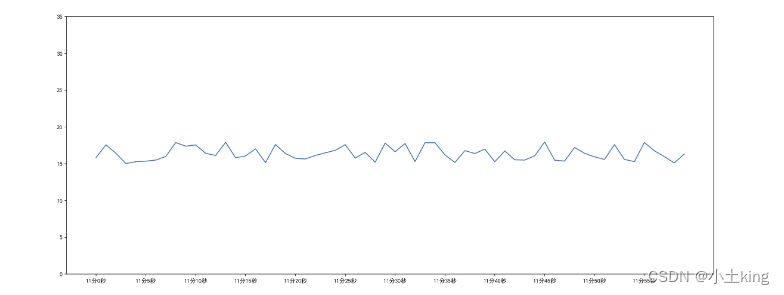
4`添加网格显示
plt.grid(True,linestyle='--', alpha=0.5)
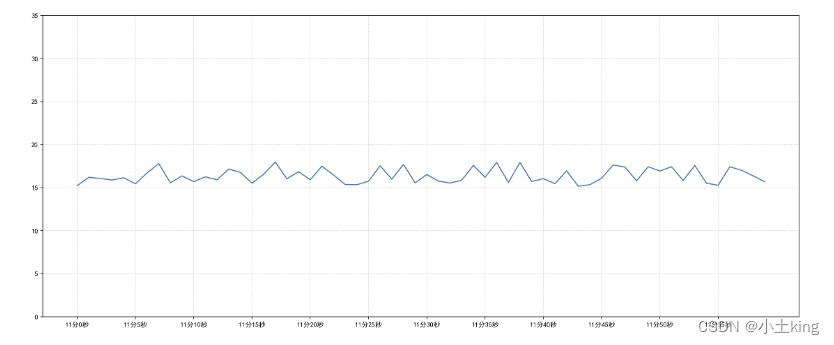
5`添加描述信息
-
添加x轴,y轴描述信息及标题
plt.xlabel("x标题") plt.ylabel("y标题") plt.title("标题")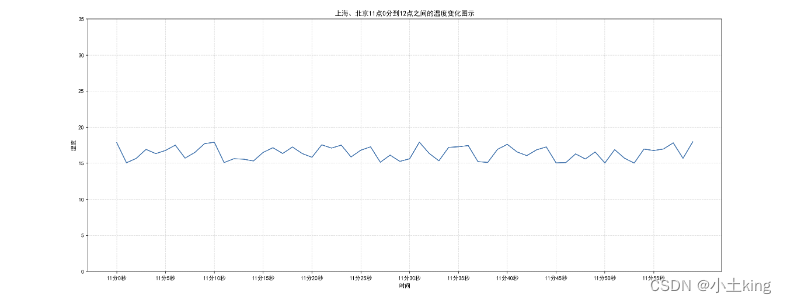
4.完善折线图
01多条折线
- 多次plot
补:设置图形风格z
| 颜色字符 | 风格字符 |
|---|---|
| r红 | -实线 |
| g绿 | - -虚线 |
| b蓝 | -.点划线 |
| w白 | :点虚线 |
| c青 | ‘ ‘留空,空格 |
| m洋红 | |
| y黄 | |
| k黑 |
02.添加图例
- 先要在绘制图像(plot())中添加
label=“ 你想要的图例” - 再加
plt.legend(loc="你想要的location")
| location string | location code |
|---|---|
| ‘best’ | 0 |
| ‘upper right’ | 1 |
| ‘upper left’ | 2 |
| ‘lower left’ | 3 |
| ‘lower right’ | 4 |
# 3、绘制图像
plt.plot(x, y_shanghai, color="r",linestyle='-.',label="上海")#linestyle是线条风格
plt.plot(x, y_beijing, color="b",label="北京")
# 显示图例
plt.legend()
-
如果只在
plt.plot()中设置label还不能显示出图例,还需要通过plt.legend()将图例先显示出来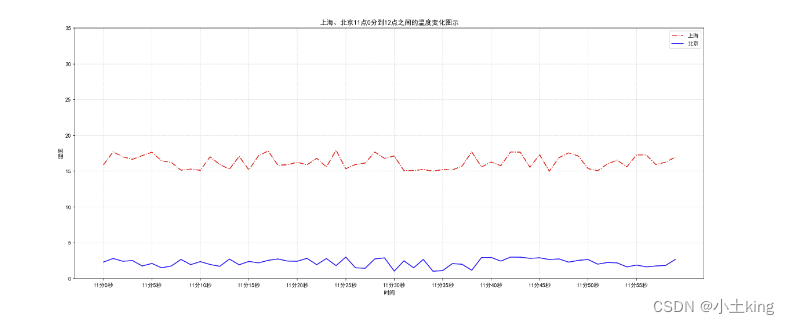
03.综合代码
# 温度变化折线图
import matplotlib.pyplot as plt
import random
# 1、准备数据
x = range(60) # 准备60个x轴数据点
y_shanghai = [random.uniform(15,18) for i in x] #random.uniform 是均匀分布的意思
y_beijing = [random.uniform(1,3) for i in x]
# 中文显示问题
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 2、创建画布
plt.figure(figsize=(20,8),dpi=80)
# 3、绘制图像
plt.plot(x, y_shanghai, color="r",linestyle='-.',label="上海")#linestyle是线条风格
plt.plot(x, y_beijing, color="b",label="北京")
# 显示图例
plt.legend()
# plt.legend(loc="lower left")
# plt.legend(loc=4)
# 修改x y刻度
#准备x的刻度说明
x_label = ["11分{}秒".format(i) for i in x]
plt.xticks(x[::5],x_label[::5])#[::5]代表设定步长为5
plt.yticks(range(0,40,5))
# 显示网格
plt.grid(linestyle='--', alpha=0.5)
# 添加描述 标题
plt.xlabel("时间")
plt.ylabel("温度")
plt.title("上海、北京11点0分到12点之间的温度变化图示")
# 4、显示图像
plt.show()
- 结果与上图一致
04.创建多个绘图区——plt.subplots(面向对象的画图方法)
- 更换此方法创建画布
figure, axes = plt.subplots(nrows=几行, ncols=几列, **fig_kw)
-
会返回两个对象
- figure
- axes
-
plt.函数名()相当于面向过程的画图方法,axes.set_方法名()相当于面向对象的画图方法
# 温度变化折线图
import matplotlib.pyplot as plt
import random
# 1、准备数据
x = range(60)
y_shanghai = [random.uniform(15,18) for i in x]
y_beijing = [random.uniform(1,3) for i in x]
# 中文显示问题
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 2、创建画布
# plt.figure(figsize=(20,8),dpi=80)
figure, axes = plt.subplots(nrows=1,ncols=2,figsize=(20,8),dpi=80)
# 3、绘制图像
axes[0].plot(x, y_shanghai, color="r",linestyle='-.',label="上海")
axes[1].plot(x, y_beijing, color="b",label="北京")
# 显示图例
axes[0].legend()
axes[1].legend()
# plt.legend(loc="lower left")
# plt.legend(loc=4)
# 修改x y刻度
x_label = ["11分{}秒".format(i) for i in x]
axes[0].set_xticks(x[::5])
axes[0].set_xticklabels(x_label[::5])
axes[0].set_yticks(range(0,40,5))
axes[1].set_xticks(x[::5])
axes[1].set_xticklabels(x_label[::5])
axes[1].set_yticks(range(0,40,5))
# 显示网格
axes[0].grid(linestyle='--', alpha=0.5)
axes[1].grid(linestyle='--', alpha=0.5)
# 添加描述 标题
axes[0].set_xlabel("时间")
axes[0].set_ylabel("温度")
axes[0].set_title("上海11点0分到12点之间的温度变化图示")
axes[1].set_xlabel("时间")
axes[1].set_ylabel("温度")
axes[1].set_title("北京11点0分到12点之间的温度变化图示")
# 4、显示图像
plt.show()
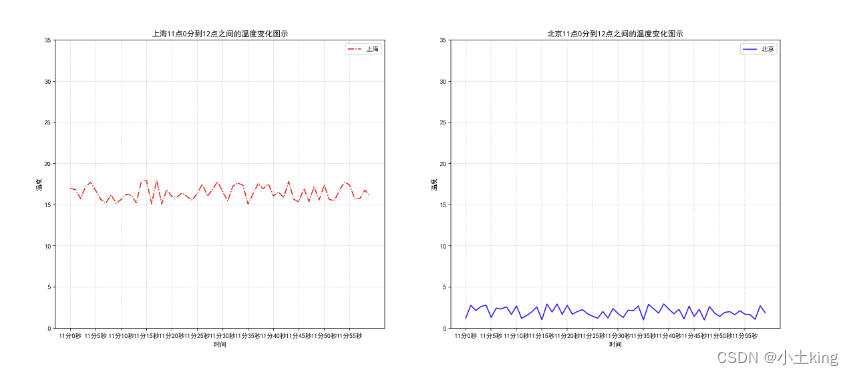
05应用场景
- 反应某事物,某指标随时间的变化状况
06`拓展
ply.plot()除了可以画折线图,也可以用于画各种数字函数图像- 利用numpy中的
np.linespace(a,b,n)- 即再[a,b]的区间范围里生成n个数,使自变量更加密集
例:
import matplotlib.pyplot as plt
import numpy as np
# 1、准备x、y数据
x = np.linspace(-1,1,1000)
y = 2 * x * x
# 2、创建画布
plt.figure(figsize=(20,8), dpi=80)
# 3、绘制图像
plt.plot(x, y)
#添加网格
plt.grid(linestyle="--",alpha=0.5)
plt.show()
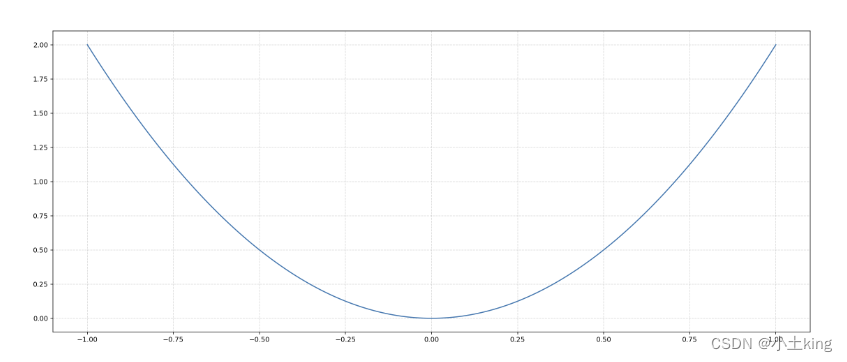
5.散点图(scatter)
import matplotlib.pyplot as plt
# 1、准备数据
x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64,
163.56, 120.06, 207.83, 342.75, 147.9 , 53.06, 224.72, 29.51,
21.61, 483.21, 245.25, 399.25, 343.35]
y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9 , 239.34,
140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1 ,
30.74, 400.02, 205.35, 330.64, 283.45]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制图像
plt.scatter(x, y)
# 4、显示图像
plt.show()
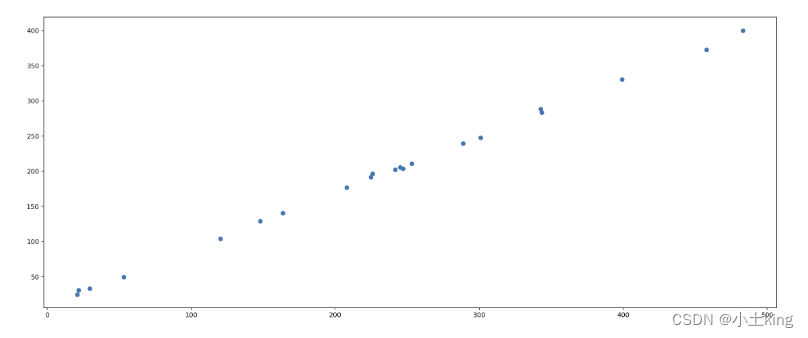
6.柱状图(bar)
plt.bar(x,y,width="宽度",align='center',**kwargs)#后两个一般用不到
01.单柱状图
import matplotlib.pyplot as plt
# 1、准备数据
movie_names = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴', '降魔传','追捕','七十七天','密战','狂兽','其它']
tickets =[73853,57767,22354,15969,14839,8725,8716,8318,7916,6764,52222]
# 中文显示问题
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制柱状图
x_ticks = range(len(movie_names)) #得到有几个类别,就是x轴参数有几个
plt.bar(x_ticks, tickets, color=['b','r','g','y','c','m','y','k','c','g','b'])
# 修改x刻度
plt.xticks(x_ticks, movie_names) #movie_names是添加的说明
# 添加标题
plt.title("电影票房收入对比")
# 添加网格显示
plt.grid(linestyle="--", alpha=0.5)
# 4、显示图像
plt.show()
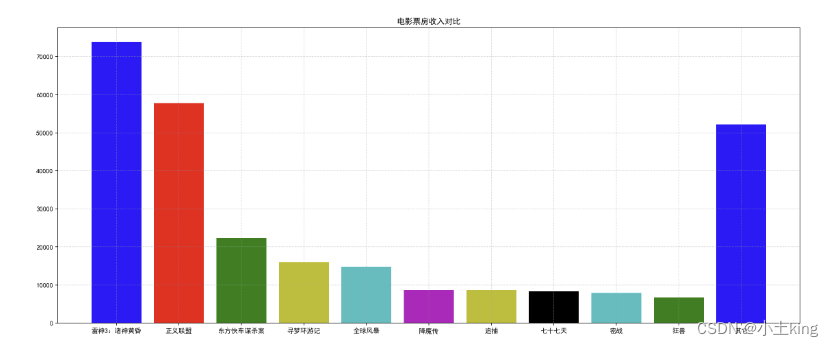
02.多柱状图
-
通过平移的方法
plt.bar(x,..,width=...) plt.bar([i+0.2 for i inn x],...,width=...) -
再去添加图例
03.应用场景
- 数量统计
- 用户数量对比分析
7.直方图(histotogram)
-
直方图牵涉统计学的概念,首先要对数据进行分组,然后统计每个分组内数据元的数量。在坐标系中,横轴标出每个组的端点,纵轴表示频数,每个矩形的高代表对应的频数,称这样的统计图为频数分布直方图。
plt.hist(x,bins=None,normed=None,**kwargs) """ x=time(数据) bins:组数 (max(time)-min(time))//组距(di) (地板除法) """ -
补 :range函数
range(start, stop, step)
"""
start:范围的起始值(包含在范围内)。如果省略,则默认为0。
stop:范围的结束值(不包含在范围内)。
step:步长(增量)。如果省略,则默认为1。
"""
# 需求:电影时长分布状况
import matplotlib.pyplot as plt
# 1、准备数据
time = [131, 98, 125, 131, 124, 139, 131, 117, 128, 108, 135, 138, 131, 102, 107, 114, 119, 128, 121, 142, 127, 130, 124, 101, 110, 116, 117, 110, 128, 128, 115, 99, 136, 126, 134, 95, 138, 117, 111,78, 132, 124, 113, 150, 110, 117, 86, 95, 144, 105, 126, 130,126, 130, 126, 116, 123, 106, 112, 138, 123, 86, 101, 99, 136,123, 117, 119, 105, 137, 123, 128, 125, 104, 109, 134, 125, 127,105, 120, 107, 129, 116, 108, 132, 103, 136, 118, 102, 120, 114,105, 115, 132, 145, 119, 121, 112, 139, 125, 138, 109, 132, 134,156, 106, 117, 127, 144, 139, 139, 119, 140, 83, 110, 102,123,107, 143, 115, 136, 118, 139, 123, 112, 118, 125, 109, 119, 133,112, 114, 122, 109, 106, 123, 116, 131, 127, 115, 118, 112, 135,115, 146, 137, 116, 103, 144, 83, 123, 111, 110, 111, 100, 154,136, 100, 118, 119, 133, 134, 106, 129, 126, 110, 111, 109, 141,120, 117, 106, 149, 122, 122, 110, 118, 127, 121, 114, 125, 126,114, 140, 103, 130, 141, 117, 106, 114, 121, 114, 133, 137, 92,121, 112, 146, 97, 137, 105, 98, 117, 112, 81, 97, 139, 113,134, 106, 144, 110, 137, 137, 111, 104, 117, 100, 111, 101, 110,105, 129, 137, 112, 120, 113, 133, 112, 83, 94, 146, 133, 101,131, 116, 111, 84, 137, 115, 122, 106, 144, 109, 123, 116, 111,111, 133, 150]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制直方图
distance = 2
group_num = int((max(time) - min(time)) / distance)
plt.hist(time, bins=group_num, density=True)
# 修改x轴刻度
plt.xticks(range(min(time), max(time) + 2, distance))
# 添加网格
plt.grid(linestyle="--", alpha=0.5)
# 4、显示图像
plt.show()

补:直方图与柱状图的区别
- 直方图展示数据的分布,柱状图比较数据的大小(最根本的区别)
- 直方图 X 轴为定量数据,柱状图 X 轴为分类数据
- 直方图柱子无间隔,柱状图柱子有间隔
- 直方图柱子宽度可不一,柱状图柱子宽度须一致
8.饼图(pie)
plt.pie(x,lebal=,autopct=,colors)
"""
x:数量,自动算百分比
labels:每部分名称
autopct:占比显示指定%1.2f%%(一般指定为此数)
colors:每部分颜色
"""
import matplotlib.pyplot as plt
# 中文显示问题
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 1、准备数据
movie_name = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴','降魔传','追捕','七十七天','密战','狂兽','其它']
place_count = [60605,54546,45819,28243,13270,9945,7679,6799,6101,4621,20105]
# 2、创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 3、绘制饼图
plt.pie(place_count, labels=movie_name, colors=['b','r','g','y','c','m','y','k','c','g','y'], autopct="%1.2f%%")
# 显示图例
plt.legend()
plt.axis('equal') # 为了让显示的饼图保持圆形,需要添加axis保证长宽一样
# 4、显示图像
plt.show()
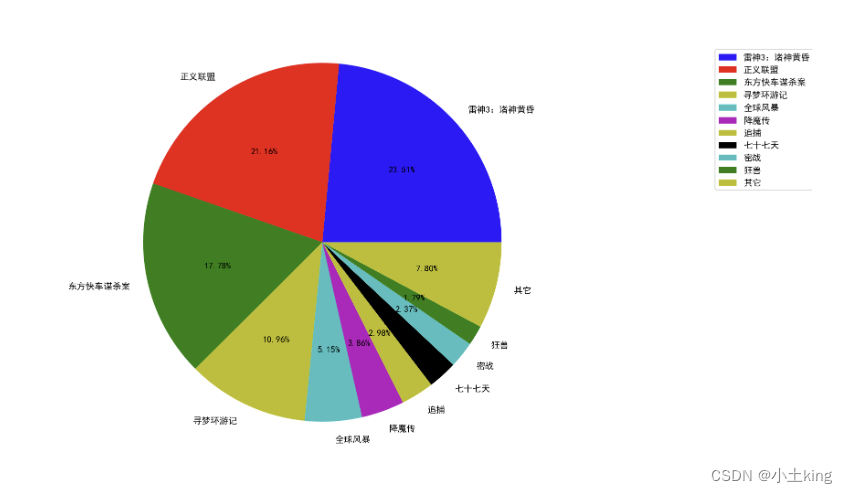
- 应用场景:分类的占比情况
三、numpy
1.介绍
-
Numpy (Numerical Python) 是一个开源的 Python 科学计算库,用于快速处理任意维度的数组。
-
Numpy 支持常见的数组和矩阵操作。对于同样的数值计算任务,使用 Numpy 比直接使用 Python 要简洁的多。
-
Numpy 使用 ndarray 对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
01.ndarray
- NumPy 提供了一个 N 维数组类型 ndarray,它描述了相同类型的"items"的集合
02.基本操作
- ndarray.方法()
- numpy.函数名()
03.优势
-
存储风格
-
ndarray - 相同类型 - 通用性不强
-
list - 不同类型 - 通用性很强
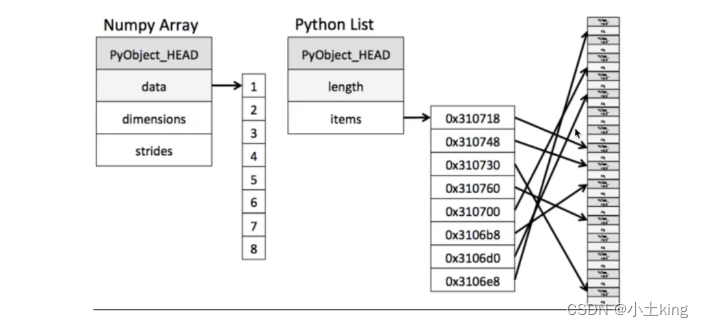
-
-
并行化运算
- ndarray 支持向量化运算
-
底层语言
- Numpy 底层使用 C 语言编写,内部解除了 GIL(全局解释器锁),其对数组的操作速度不受 Python 解释器的限制,效率远高于纯 Python 代码。
-
计算速率
- ndarray的计算速率很快,节约了时间
04.属性
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
在创建 ndarray 的时候,如果没有指定类型,默认:整数 int64/int32 浮点数 float64/float32
05.初体验
import numpy as np
score = np.array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])# np.array()用于存储数据
print(type(score))
print(score.shape)
print(score.dtype)
print(score.ndim)
print(score.size)
print(score.itemsize)
a = np.array([1,2,3,4])
print(a.shape)
"""
output:
<class 'numpy.ndarray'>
(8, 5)
int32
2
40
4
(4,) #加,的原因是为了表示其是一个元组
"""
2.基本操作
- 下列所有stock_change都是np.ndarry数据类型的一个随便起的数据名
1`生成数组的方法
01.生成 0 和 1 的数组
np.zeros(shape=(3, 4), dtype="float32") # 生成一组0
"""
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
"""
np.ones(shape=[2, 3], dtype=np.int32) # 生成一组1
"""
[[1 1 1]
[1 1 1]]
"""
02.从现有数组生成
data1 = np.array(score) # 深拷贝
data2 = np.asarray(score) # 浅拷贝
data3 = np.copy(score) # 深拷贝
03.生成固定范围的数组
np.linspace(0, 10, 5) # 生成[0,10]之间等距离的5个数
np.arange(0, 11, 5) # [0,11),5为步长生成数组
04.生成随机数组
# 生成均匀分布的一组数[low,high)
data1 = np.random.uniform(low=-1, high=1, size=1000000)
# 生成正态分布的一组数,loc:均值;scale:标准差
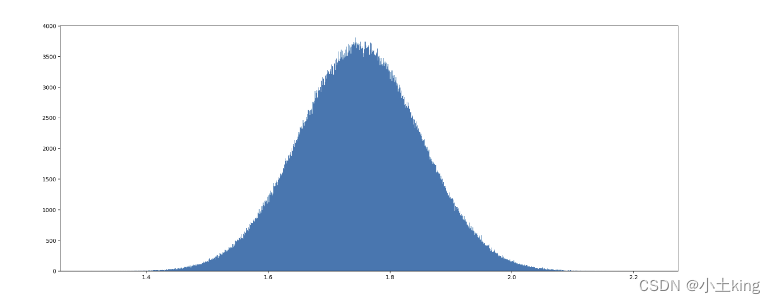
data2 = np.random.normal(loc=1.75, scale=0.1, size=1000000)
-
标准差越小图像越瘦高,离散程度越小
-
正态分布效果图
2`.数组的索引、切片
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
# 获取第一个股票的前3个交易日的涨跌幅数据
print(stock_change[0, :3])
a1[1, 0, 2] = 100000
import numpy as np
stock_change = np.random.normal(loc=0, scale=1, size=(8, 10))
# 获取第一个股票的前3个交易日的涨跌幅数据
print(stock_change)
print(stock_change[0, :3])#输出第一行的前三个元素
a1 = np.array([[[1,2,3],[4,5,6]],[[7,7,8],[10,11,12]]])
print(a1)
a1[1, 0, 2] = 100000
print(a1)
"""
[[ 0.12455896 1.60356128 -0.96744194 -1.57708835 3.14070696 0.12604571
0.20023585 -1.48834972 0.24268205 1.15312199]
[-1.74234154 1.66826578 -0.95890865 -0.97279575 -0.55804159 0.01670131
-0.40395126 0.26611422 1.27829164 -0.82104634]
[ 1.20374108 2.68291668 -0.08336255 1.13263706 -0.59999114 0.16728994
-0.65096619 0.66070642 1.06372729 -0.75172117]
[-0.56037862 -1.26270074 -2.44079645 -0.13754767 1.0711936 -0.45185777
0.62360603 -0.9027949 0.49461052 -0.50844748]
[ 0.63599613 -1.0843819 0.6707884 -0.40655387 -0.26391073 0.35591563
-0.56203954 -0.57270898 0.43979076 0.45598596]
[-0.38386679 -0.45825336 -0.76392446 1.24782378 -1.82295677 -1.30619527
-0.46390338 0.23872066 0.02615395 -0.53313593]
[-0.29008722 0.00807149 -0.67299834 -0.08159296 1.4005296 1.67761784
-0.11875453 0.15726626 0.12790766 0.31385371]
[ 0.71190147 1.5754346 0.31734722 -0.16753831 0.34303597 -0.40881497
-0.49979205 -0.3470053 -0.44370621 0.2529197 ]]
[ 0.12455896 1.60356128 -0.96744194]
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 7 8]
[10 11 12]]]
[[[ 1 2 3]
[ 4 5 6]]
[[ 7 7 100000]
[ 10 11 12]]]
"""
3`. 形状修改
stock_change.reshape((a,b)) # 返回新的ndarray,但单纯只修改了形状,原始数据没有改变
stock_change.resize((a,b)) # 没有返回值,对原始的ndarray进行了修改
stock_change.T # 转置 行变成列,列变成行
- reshape 还有自动计算的的功能,比如要生成2列,会自动生成行数
4`.类型修改
stock_change.astype("你想要转化的类型")
stock_change.tostring() # ndarray序列化到本地,转化为bytes类型数据
5`.数组去重
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
法一:np.unique(temp)
法二:set(temp.flatten())
3. ndarray 运算
01.逻辑运算
1` 运算符——bool索引
# 逻辑判断, 如果涨跌幅大于0.5就标记为True 否则为False
stock_change > 0.5
stock_change[stock_change > 0.5] = 1.1 #将选择部分进行操作
2`通用判断函数
np.all(布尔值)
只要有一个False就返回False,只有全是True才返回True
np.any()
只要有一个True就返回True,只有全是False才返回True
# 判断stock_change[0:2, 0:5]是否全是上涨的
np.all(stock_change[0:2, 0:5] > 0)
# 判断前5只股票这段期间是否有上涨的
np.any(stock_change[:5, :] > 0)
3`三元运算符
# np.where(布尔值,设置True的位置的值,设置 False的位置的值)
np.where(temp > 0, 1, 0)
# 大于0.5且小于1 且
np.where(np.logical_and(temp > 0.5, temp < 1), 1, 0)
# 大于0.5或小于-0.5 或
np.where(np.logical_or(temp > 0.5, temp < -0.5), 11, 3)
02.统计运算
1`统计指标函数
min,max,mean(均值),median(中位数),var(方差),std(标准差)
temp.max(axis=0) # 比各行(就是求每一列最值)axis=0,比各列(就是比每一行最值)axis=1
np.max(temp, axis=1)
# 返回最大值、最小值的位置
np.argmax(tem,axis=)
np.argmin(tem,axis=)
# 比各行(就是求每一列最值)axis=0,比各列(就是比每一行最值)axis=1
np.argmax(temp, axis=-1)
03.数组间运算
1`数组与数的运算
- ndarray数据类型可以直接对数组做整体处理
- 而单纯的python列表运算是不行的
arr = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr / 10
2`数组与数组的运算
1`.广播机制
-
执行 broadcast 的前提在于,两个 nadarray 执行的是 element-wise 的运算,Broadcast 机制的功能是为了方便不同形状的 ndarray(numpy 库的核心数据结构)进行数学运算。
-
当操作两个数组时,numpy 会逐个比较它们的 shape(构成的元组 tuple),只有在下述情况下,两个数组才能够进行数组与数组的运算。
-
维度相等
-
shape(其中相对应的一个位置为 1)
- 可以理解为维度不足的地方补1
-
2`.矩阵运算
-
英文 matrix
-
和 array 的区别是:矩阵必须是 2 维的,但是 array 可以是多维的。
-
存出矩阵方式
-
np.array() -
np.mat()将数组转换成矩阵类型- 将其从ndarray类型转化为matrix类型
a=np.array(传入的数据) np.mat(a)
-
-
矩阵乘法规则(M 行,N 列)x (N 行,L 列) = (M 行,L 列)]
- 第一个矩阵的列=第二个矩阵的行
-
如果是 ndarray
np.dot(data,data1)
np.matmul(data,data1)
data @ data1
- 如果是 martix
data*data1 #如果是矩阵的话直接相乘即可
- 矩阵和二维数组的区别
4.合并,分割
01.合并
-
numpy.hstack水平拼接
-
numpy.vstack竖直拼接
-
numpy.concatenate((a1,a2),axis=1|0)水平|竖直拼接- axis默认为0

02.分割
numpy.split(x,n)分n份numpy.split(x,[3,4,6,10])# 按索引分割
5.IO 操作与数据处理
01.读取数据
np.genfromtxt("文件路径", delimiter="分割符的设定 一般为,") # 会有问题,读不出字符串
02.如何处理缺失值
-
什么是缺失值
- 什么时候numpy中会出现nan:当我们读取本地文件为float的时候,如果有缺失(或者为None),就会出现nan
-
两种思路:
-
直接删除含有缺失值的样本(前提样本数量非常大)
-
替换/插补 (补入平均值或中位数)
-
四、pandas
1.介绍
- 2008 年 WesMcKinney 开发出的库
- 专门用于数据挖掘的开源 Python 库
- 以 Numpy 为基础,借力 Numpy 模块在计算方面性能高的优势
- 基于 matplotlib,能够简便的画图
- 独特的数据结构
01.为什么用?
-
便捷的数据处理能力
-
读取文件方便
-
封装了 Matplotlib、Numpy 的画图和计算
02.核心数据结构
- DataFrame
- Pannel
- Series
1`DataFrame
1``结构
- 既有行索引,又有列索引的二维数组
- 行索引,表明不同行,横向索引,叫 index
- 列索引,表明不同列,纵向索引,叫 columns
import numpy as np
stock_change = np.random.normal(0,1,(10,5))
print(stock_change)
"""
output:
[[-0.13099443 -1.36357654 0.6153307 1.69451766 -0.13454747]
[ 0.80746328 0.62361234 0.02118496 -0.81135035 0.25138561]
[-0.38326572 0.81530876 0.25968533 0.20841051 0.11721951]
[ 0.16724835 -0.12465807 1.97210514 -0.0913593 -1.11968288]
[-1.51092521 -1.9286114 -0.4193797 -1.26636806 -0.72380917]
[-0.18253667 0.26614846 0.45303077 0.17771643 0.32120197]
[-1.13992299 -1.6569034 -0.88756731 -0.79265633 -0.01516654]
[ 0.08785445 -1.08140417 0.87104683 -0.99921854 0.18212618]
[ 0.60645609 1.22010339 -0.09939846 1.12120391 -0.12140574]
[-0.62669966 1.71027326 -0.6317914 0.62417384 0.39099414]]
"""
import pandas as pd
a1=pd.DataFrame(stock_change)
print(a1)
"""
0 1 ... 3 4
0 -0.070932 2.745953 ... -0.492423 0.649944
1 0.857743 0.586064 ... -0.219407 -0.105657
2 -0.690164 -0.318960 ... 0.776566 -0.778466
3 0.089199 0.337234 ... 1.885281 -0.001930
4 -1.317920 -0.535508 ... 2.325393 1.533367
5 1.262642 -1.194206 ... 0.823052 0.929497
6 -0.535851 -0.165593 ... 0.205639 0.466984
7 -2.002434 0.129920 ... -1.061750 0.263746
8 -1.450914 -0.086264 ... 1.728306 0.259328
9 -0.930675 -0.666912 ... -0.764696 -0.445526
"""
# 添加行索引
stock = ["股票{}".format(i) for i in range(10)]
pd.DataFrame(stock_change, index=stock)
# 添加列索引
date = pd.date_range(start="20200101", periods=5, freq="B")
stock_change = pd.DataFrame(stock_change, index=stock, columns=date)
print(stock_change)
"""
2020-01-01 ... 2020-01-07
股票0 NaN ... NaN
股票1 NaN ... NaN
股票2 NaN ... NaN
股票3 NaN ... NaN
股票4 NaN ... NaN
股票5 NaN ... NaN
股票6 NaN ... NaN
股票7 NaN ... NaN
股票8 NaN ... NaN
股票9 NaN ... NaN
"""
2``常用属性
| 属性名字 | 属性解释 |
|---|---|
| pd.shape | 数组维度的元组 |
| pd.index | 行索引列表 |
| pd.columns | 列索引列表 |
| pd.values | 直接获取其中 array 的值 |
| pd.T | 行列转置 |
3``常用方法
| 方法名 | 方法解释 |
|---|---|
| .head(n) | 开头n行 |
| .tail(n) | 最后n行 |
- head和tail默认都是取5行
3``索引的设置
- 修改行列索引值
不能单独修改修改索引,必须整体修改
stock_code=["股票_"+str(i) for i in range(stock_change[0])]
data.index=stock_code
-
重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
- reset_index(drop=False)
-
以某列值设置为新的索引
- set_index(keys,drop=True)
- keys:列索引名称或列索引名称的列表
- drop:boolean,default True,当作新的索引,删除原来的列
- set_index(keys,drop=True)
# 修改行列索引值
# data.index[2] = "股票88" 不能单独修改索引
stock_ = ["股票_{}".format(i) for i in range(10)]
data.index = stock_
"""
2020-01-01 2020-01-02 2020-01-03 2020-01-06 2020-01-07
{股票_0} -0.204708 0.478943 -0.519439 -0.555730 1.965781
{股票_1} 1.393406 0.092908 0.281746 0.769023 1.246435
{股票_2} 1.007189 -1.296221 0.274992 0.228913 1.352917
{股票_3} 0.886429 -2.001637 -0.371843 1.669025 -0.438570
{股票_4} -0.539741 0.476985 3.248944 -1.021228 -0.577087
{股票_5} -0.220844 -0.191836 -0.887629 -0.747158 1.692455
{股票_6} -0.012592 -0.038788 0.708105 0.892603 0.801861
{股票_7} -0.362177 -0.672460 -0.359553 -0.813146 -1.726283
{股票_8} 0.177426 0.401781 -1.630198 0.462782 -0.907298
{股票_9} 0.051945 0.729091 0.128982 1.139401 -1.234826
"""
# 重设索引
data.reset_index(drop=False) # drop=True把之前的索引删除
# 设置新索引
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
# 以月份设置新的索引
df.set_index("month", drop=True)
# 设置多个索引,以年和月份
new_df = df.set_index(["year", "month"])
#设置多个索引,index返回是MultiIndex
- 设置多个索引,index返回是MultiIndex
2`MultiIndex 与 Panel
1.MultiIndex
-
多级或分层索引对象
-
index 属性
- names: levels 的名称
- levels: 每个 level 的元组值
print(new_df.index)
print(new_df.index.names)
print(new_df.index.levels)
2.Panel
- 通常看为dataframe的容器
pandas.Panel(data=None,items=None,major_axis=None,minor_axis=None,copy=False,dtype=None)
- 存储 3 维数组的 Panel 结构
- items - axis 0,每个项目对应于内部包含的数据帧(DataFrame)。
- major_axis - axis 1,它是每个数据帧(DataFrame)的索引(行)。
- minor_axis - axis 2,它是每个数据帧(DataFrame)的列。
p = pd.Panel(np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
a1=p["A"]
a2=p.major_xs("2013-01-01")
a3=p.minor_xs("first")
"""
创建了一个 Panel 对象 p,其内容是一个 4x3x2 的三维数组,分别代表了“项目”(items)、“主轴”(major_axis)和“次轴”(minor_axis)。具体地:
“项目”(items)是一个包含 'A', 'B', 'C', 'D' 的列表。
“主轴”(major_axis)是一个包含 2013 年 1 月 1 日开始的 3 天日期范围。
“次轴”(minor_axis)是一个包含 'first' 和 'second' 的列表。
接着,代码分别提取了 Panel 中的数据:
a1 是 Panel 中 'A' 项目的内容。
a2 是 Panel 中 2013 年 1 月 1 日这一天的内容。
a3 是 Panel 中 'first' 这个次轴的内容。
"""
- 注:Pandas 从版本 0.20.0 开始弃用,推荐的用于表示 3D 数据的方法是 DataFrame 上的 MultiIndex 方法
3`Series
- 带索引的一维数组
- series结构只有行索引
1``常用属性
-
index
-
values :一维数组,类型ndarray
# 创建 pd.Series(np.arange(3, 9, 2), index=["a", "b", "c"]) # 或 pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000}) sr = data.iloc[1, :] sr.index # 索引 sr.values # 值 -
总结:DataFrame 是 Series 的容器,Panel 是 DataFrame 的容器
2.基本数据操作
01.索引操作
- 直接索引,先列后行
- 按名字索引
- 数字索引——使用iloc
- ix组合索引
data = pd.read_csv("./stock_day/stock_day.csv")
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1) # 去掉一些不要的列
data["open"]["2018-02-26"] # 直接索引,先列后行
data.loc["2018-02-26"]["open"] # 按名字索引
data.loc["2018-02-26", "open"]
data.iloc[1, 0] # 数字索引
# ix组合索引
# 获取行第1天到第4天,['open', 'close', 'high', 'low']这个四个指标的结果
data.ix[:4, ['open', 'close', 'high', 'low']] # 不能用了
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
02.赋值操作
#直接赋值整列
data.open = 100
#单个赋值——先索引,在赋值
data.iloc[1, 0] = 222
03.排序操作
- 排序有两种形式,一种对内容进行排序,一种对索引进行排序
1`内容排序
-
使用
df.sort_values(key=,ascending=)对内容进行排序-
单个键或者多个键进行排序,默认升序
-
ascending=False:降序 True:升序
-
多个键进行排序,需要创建为一个链表
-
2`索引排序
- 使用
df.sort_index对索引进行排序
data.sort_values(by="high", ascending=False) # DataFrame内容排序
data.sort_values(by=["high", "p_change"], ascending=False).head() # 多个列内容排序
data.sort_index().head()
sr = data["price_change"]
sr.sort_values(ascending=False).head()
sr.sort_index().head()
3.DataFrame运算
01.算数运算
- add 加
- sub 减
- div 除
- mul 乘
data+10 #整体+10
data["open"].add(3).head() # open统一加3 data["open"] + 3
data.sub(100).head() # 所有统一减100 data - 100
data["close"].sub(data["open"]).head() # close减open
02.逻辑运算
-
逻辑运算符:< > | &
-
逻辑运算函数
-
query(expr)expr:查询字符串
-
isin(values)- 判断是否为 values
-
data[data["p_change"] > 2].head() # p_change > 2
data[(data["p_change"] > 2) & (data["low"] > 15)].head()
data.query("p_change > 2 & low > 15").head()
# 判断'turnover'是否为4.19, 2.39
data[data["turnover"].isin([4.19, 2.39])]
03.统计运算
1.describe()
-
综合分析:能够直接得出很多统计结果,count,mean,std,min,max 等
#计算平均值,标准差,最大值,最小值 data.describe() data.max(axis=0|1) 列或行 data.idxmax(axis=0|1) #最大值位置
2.累计统计函数
| 函数 | 作用 |
|---|---|
| cumsum | 计算前 1/2/3/…/n 个数的和 |
| cummax | 计算前 1/2/3/…/n 个数的最大值 |
| cummin | 计算前 1/2/3/…/n 个数的最小值 |
| cumprod | 计算前 1/2/3/…/n 个数的积 |
04.自定义运算
- apply(func, axis=0)
- func: 自定义函数
- axis=0: 默认按列运算,axis=1 按行运算
data.apply(lambda x: x.max() - x.min())
3.pandas画图
1`pandas.DataFrame.plot
-
DataFrame.plot(x=None, y=None, kind=‘line’)
-
x: label or position, default None
-
y: label, position or list of label, positions, default None
- Allows plotting of one column versus another
-
kind: str
- ‘line’: line plot(default)
- ''bar": vertical bar plot
- “barh”: horizontal bar plot
- “hist”: histogram
- “pie”: pie plot
- “scatter”: scatter plot
-
data.plot(x="volume", y="turnover", kind="scatter")
data.plot(x="high", y="low", kind="scatter")
2`pandas.Series.plot
sr.plot(kind="line")
4.文件读取和存储
01.CSV
-
读取文件
pandas.read_csv(filepath_or_buffer,sep=‘,’,delemeter = None)- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式
-
写入文件
-
DataFrame.to_csv(path_or_buf=None,sep=‘,‘,columns=None,header=True,index=True, index_label=None, mode='w', encoding=None)- path_or_buf :string or file handle, default Nonea文件指定路径
- sep :character, default ',’
- columns :sequence, optional 列名
- mode:‘w’:重写,'a’追加
- index:是否 写进 行索引
- header :boolean or list of string, default True,是否写进列索引值
-
Series.to_csv(path=None,index=True,sep=‘,‘,na_rep=",float_format=None,header=False, index_label=None, mode='w',encoding=None, compression=None,date_format=None,decimal=‘,’)Write Series to a comma-separated values (csv) file
-
pd.read_csv("./stock_day/stock_day.csv", usecols=["high", "low", "open", "close"]).head() # 读哪些列
data = pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"]) # 如果列没有列名,用names传入
data[:10].to_csv("test.csv", columns=["open"]) # 选取10行保存open列数据
data[:10].to_csv("test.csv", columns=["open"], index=False, mode="a", header=False) # 保存opend列数据,index=False不要行索引,mode="a"追加模式|mode="w"重写,header=False不要列索引
02.HDF5
-
hdf5 存储3维数据文件
-
HDF5 文件的读取和存储需要指定一个键,值为要存储的 DataFrame
-
读取数据
-
pandas.read_hdf(path_or_buf, key=None, **kwargs)-
path_or_buffer: 文件路径
-
key: 读取的键(如果只读一个内容,可以不指定,但是如果读取多个key,就必须指定)
-
mode: 打开文件的模式
-
reurn: The Selected object
-
-
-
存储数据
DataFrame.to_hdf(path_or_buf, key, **kwargs)- 这边的key必须要指定
day_close = pd.read_hdf("./stock_data/day/day_close.h5")
day_close.to_hdf("test.h5", key="close")
03.JSON
- 读取数据
- pandas.read_json(path_or_buf=None,orient=None,typ=“frame”,lines=False)
- 将 JSON 格式转换成默认的 Pandas DataFrame 格式
- orient: string,Indication of expected JSON string format. 告诉API读取的JSON以怎样的格式进行展示
- ‘split’: dict like {index -> [index], columns -> [columns], data -> [values]} ,API 期望以一种类似字典的结构表示 JSON 数据
- ‘records’: list like [{column -> value}, …, {column -> value}],API 期望 JSON 数据以列表形式表示
- ‘index’: dict like {index -> {column -> value}},API 期望 JSON 数据以字典形式表示
- ‘columns’: dict like {column -> {index -> value}}, 默认该格式,API 期望 JSON 数据以字典形式表示
- ‘values’: just the values array,API 期望 JSON 数据直接表示值的数组
- lines: boolean, default False
- 按照每行读取 json 对象
- typ: default ‘frame’,指定转换成的对象类型 series 或者 dataframe
- pandas.read_json(path_or_buf=None,orient=None,typ=“frame”,lines=False)
sa = pd.read_json("Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
sa.to_json("test.json", orient="records", lines=True)
04.缺失值处理
- replace 实现数据替换
- dropna 实现缺失值的删除
- fillna 实现缺失值的填充
- isnull 判断是否有缺失数据 NaN
如何进行缺失值处理?
- 删除含有缺失值的样本
- 替换/插补数据
05.如何处理 NaN?
- 判断是否有 NaN
- pd.isnull(df):有缺失值返回True,反之返回False
- pd.notnull(df):与上相反
- 删除含有缺失值的样本
df.dropna(inplace=True)默认按行删除- inplace:True 修改原数据,False 返回新数据,默认 False(在高版本中inplace已经被抛弃了)
- 替换/插补数据
- df.fillna(value,inplace=True)
- value 替换的值 (一般用平均值或者中位数)
- inplace:True 修改原数据,False 返回新数据,默认 False
- df.fillna(value,inplace=True)
import pandas as pd
import numpy as np
movie = pd.read_csv("./IMDB/IMDB-Movie-Data.csv")
# 1)判断是否存在NaN类型的缺失值
np.any(pd.isnull(movie)) # 返回True,说明数据中存在缺失值
np.all(pd.notnull(movie)) # 返回False,说明数据中存在缺失值
pd.isnull(movie).any()#查看每个字段是否存在缺失值
pd.notnull(movie).all()
# 2)缺失值处理
# 方法1:删除含有缺失值的样本
data1 = movie.dropna()
pd.notnull(data1).all()
# 方法2:替换
# 含有缺失值的字段
# Revenue (Millions)
# Metascore
movie["Revenue (Millions)"].fillna(movie["Revenue (Millions)"].mean(), inplace=True)
movie["Metascore"].fillna(movie["Metascore"].mean(), inplace=True)
06.处理其他标记的缺失值(不是缺失值 NaN)
- 不是缺失值 NaN,有默认标记的
- 先将其他标记的缺失值替换为np.nan
- 再重复nan对应的操作
# 读取数据
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
name = ["Sample code number", "Clump Thickness", "Uniformity of Cell Size", "Uniformity of Cell Shape", "Marginal Adhesion", "Single Epithelial Cell Size", "Bare Nuclei", "Bland Chromatin", "Normal Nucleoli", "Mitoses", "Class"]
data = pd.read_csv(path, names=name)
# 1)替换
data_new = data.replace(to_replace="?", value=np.nan)
# 2)删除缺失值
data_new.dropna(inplace=True)
5.数据离散化
01.什么是数据的离散化
连续属性的离散化就是将连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间的属性值。
- one-hot编码(也叫做哑变量)
02.为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
03.如何实现数据的离散化
-
对数据进行分组
- 自动分组
sr = pd.qcut(data, bins)- bins:表示分几组
- 自定义分组
sr = pd.cut(data, [])
- 自动分组
-
将分组好的结果转换成 one-hot 编码(哑变量)
pd.get_dummies(sr, prefix=)- prefix: 前缀
-
通过
value_counts()查看每一组的分组情况
# 1)准备数据
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])
# 2)分组
# 自动分组
sr = pd.qcut(data, 3)
sr.value_counts() # 看每一组有几个数据
# 3)转换成one-hot编码
pd.get_dummies(sr, prefix="height")
# 自定义分组
bins = [150, 165, 180, 195]
sr = pd.cut(data, bins)
# get_dummies
pd.get_dummies(sr, prefix="身高")
6.合并
01.按方向
pd.concat([data1, data2], axis=1)- axis:0 为列索引;1 为行索引
02.按索引
-
pd.merge(left, right, how="inner", on=[])-
left:左表
-
right:右表
-
how:
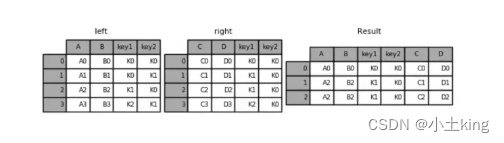
-
‘inner’:执行内连接,返回两个 DataFrame 中共有的行。
-
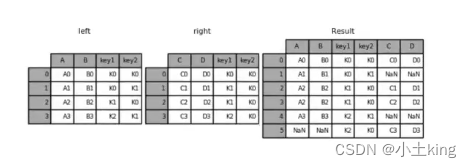
‘outer’:执行外连接,返回两个 DataFrame 的并集,缺失值填充为 NaN。
-
-
‘left’:执行左连接,返回左边 DataFrame 的所有行以及右边 DataFrame 中与左边 DataFrame 匹配的行。
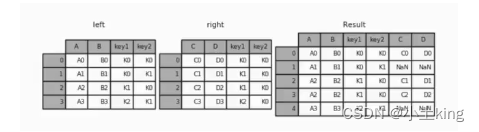
-
‘right’:执行右连接,返回右边 DataFrame 的所有行以及左边 DataFrame 中与右边 DataFrame 匹配的行。
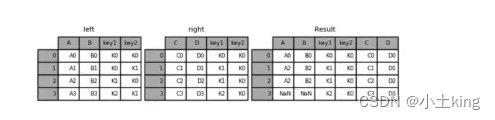
-
‘cross’:执行交叉连接,返回两个 DataFrame 中所有可能的组合,又称笛卡尔积。
-
-
on:索引
-
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, how="inner", on=["key1", "key2"])
pd.merge(left, right, how="left", on=["key1", "key2"])
pd.merge(left, right, how="outer", on=["key1", "key2"])
7.交叉表和透视表
01.交叉表
交叉表用于计算一列数据对于另外一列数据的分组个数(寻找两个列之间的关系)
pd.crosstab(value1, value2)- value1:数据列1
- value2:数据列2
data = pd.crosstab(stock["week"], stock["pona"])
data.div(data.sum(axis=1), axis=0).plot(kind="bar", stacked=True)
#stacked表示是否要堆叠
02.透视表
DataFrame.pivot_table([], index=[])
# 透视表操作
stock.pivot_table(["pona"], index=["week"])
- 交叉表返回的是统计的结果,透视表返回的是比例结果
8.分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。
DataFrame.groupby(key, as_index=False)- key:分组的列数据,可以多个
.count再聚合
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
# 进行分组,对颜色分组,price1进行聚合
# 用dataframe的方法进行分组
col.groupby(by="color")["price1"].max()
# 或者用Series的方法进行分组聚合
col["price1"].groupby(col["color"]).max()















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









