






python学习
一、虚拟环境的创建
1.查看已存在的虚拟环境:conda env list
2.创建虚拟环境:conda create -n 虚拟环境名 python==其版本
3.激活虚拟环境:conda activate 虚拟环境名
4.安装其他的库:pip install 安装内容
5.查看已安装的库:pip list或conda list
6.退到主环境:conda deactivate
7.删除虚拟环境:conda env remove --name 虚拟环境名
二、常识
1.命名规则:
- 命名文件名建议只是用小写字母、数字和下划线
- 文件名不能以数字开始
2.注释:
-
单行注释
- 以
#开头,#右边的所有东西都被当作说明文字 - 为保证程序的可读性,在
#后要添加一个空格
- 以
-
多行注释
-
一对 连续的 三个 引号
-
""" 这是一个多行注释 在多行注释之间,可以写很多内容 """ print("Hello Python")
-
3.变量:
01.变量定义
-
在Python中,每个变量 在使用前都必须赋值,变量 赋值以后 该变量 才会被创建
-
等号(
=)用来给变量赋值-
=左边是一个变量名 -
=右边是存储在变量中的值# 定义qq_number的变量用来保存 qq号码 qq_number = "1234567" # 输出 qq_number中保存的内容 print(qq_number)# 定义苹果价格变量 price = 8.5 # 定义购买重量 weight = 7.5 # 计算金额 money = price * weight* # 只要买苹果就返 5 元 money = money - 5 # 输出价格 print(money)
-
-
变量名 只有在第一次出现 才是 定义变量
-
变量名 再次出现,不是定义变量,而是直接使用之前定义过的变量
02.变量的类型:
- 数字型
- 整型(
int) - 浮点型(
flaot) - 布尔型(
bool)- 真
True非 0 数--非零即真 - 假
False0
- 真
- 复数型(
complex)- 主要用于科学计算,例如:平面场问题、波动问题、电感电容等问题
- 整型(
- 非数字型
- 字符串
- 列表
- 元组
- 字典
1`type
- 使用**
type函数**可以查看一个变量的类型
In [1]: type(name)
Out [1]: str
-
在
Python中定义变量时需要指定数据类型吗?- 不需要
Python可以根据=等号右侧的值,自动推导出变量中存储的数据类型
-
变量是没有类型的,但他存储的数据是有类型的
03.变量的输入
- 类型转换函数
| 函数 | 说明 |
|---|---|
int(x) | 将 x 转换为一个整数 |
float(x) | 将 x 转换到一个浮点数 |
| str(x) | 将 x 转换到一个字符串 |
- **想要将字符串转换成数字,必须要求字符串内的内容都是数**
4.标识符:
- 标识符可以由 字母、下划线 和 数字 组成
- 不能以数字开头
- 大小写敏感
- 不能与关键字重名
- 不推荐使用中文
5.运算符:
01.比较(关系)运算符
| 运算符 | 描述 |
|---|---|
== | 检查两个操作数的值是否 相等,如果是,则条件成立,返回True |
!= | 检查两个操作数的值是否 不相等,如果是,则条件成立,返回True |
> | 检测左操作数的值是否 大于 右操作数的值,如果是,则条件成立,返回True |
< | 检测左操作数的值是否 小于 右操作数的值,如果是,则条件成立,返回True |
>= | 检测左操作数的值是否 大于等于 右操作数的值,如果是,则条件成立,返回True |
<= | 检测左操作数的值是否 小于等于 右操作数的值,如果是,则条件成立,返回True |
02.算数(数学)运算符
-
// 取整除
-
**指数
- a**b=a的b次方
03.逻辑运算符
3.1 and
条件1 and 条件2
- 与/并且
- 两个条件同时满足,返回
True - 只要有一个不满足,就返回
False
3.2 or
条件1 or 条件2
- 或/或者
- 两个条件只要有一个满足,返回
True - 两个都不满足,返回
False
3.3 not
not 条件
- 非/不是
- 将条件取反,如果条件为假,则返回
True
04.赋值运算符
- 在 Python 中,使用
=可以给变量赋值 - 在算术运算时,为了简化代码的编写,
Python还提供了一系列的 与 算数运算符 对应的 赋值运算符 - 注意:赋值运算符中间不能使用空格
| 运算符 | 描述 | 实例 |
|---|---|---|
= | 简单的赋值运算符 | c = a + b 将 a + b 的运算符结果赋值为 c |
+= | 加法赋值运算符 | i += 1 等价于 i = i + 1 |
-= | 减法赋值运算符 | |
*= | 乘法赋值运算符 | |
/= | 除法赋值运算符 | |
//= | 取整除赋值运算符 | |
%= | 取模(余数)赋值运算符 | |
**= | 幂赋值运算符 |
6.字符串拓展
01.字符串的拼接——+号拼接
name="king"
print("我是"+name+"很菜")
- 字符串是无法单独同整数等直接进行拼接的
02.字符串的格式化
| 格式化字符 | 含义 |
|---|---|
%s | 字符串 |
%d | 有符号十进制整数,%06d表示输出的整数显示位数,不足的地方使用 0 补全 |
%f | 浮点数,%.2f表示小数点后只显示两位 |
%% | 输出% |
- %:我要占位
- s:将变量变成字符串放入占位的地方
name = "小明"
print("我的名字叫 %s ,请多多关照!" % name)
# output:我的名字叫小明,请多多关照!
#字符串与数字拼接
class_num=57
avg_salary=16781 # 此数数字变成了字符串进行拼接
message = "python大数据学科,北京%s期,毕业平均工资:%s"%(class_num,avg_salary)
#output:python大数据学科,北京57期,毕业平均工资:16781
03.快速字符串格式化
-
语法:f”内容{变量}”的格式来快速格式化
-
特点:不做精度控制,原样输出
p print(f"我是{name}我成立于:{set_up_year}我今天的股票价格是:{stock_price}")
04.格式化的精度控制
-
辅助符号控制数据的宽度和精度
- m, 控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
- .n, 控制小数点的精度,要求是数字,会进行小数的四舍五入
-
例子
- %5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成**【空格】【空格】【空格】11**,用3个空格补足宽度
- %5.2f:表示将宽度控制为5,将小数点的精度设置为2
-
price = 9.00 weight = 5.00 money = price * weight print("苹果单价 %.2f元/斤, 购买了%.3f斤, 需要支付%.4f元" % (price, weight, money)) #output 苹果单价 9.00元/斤, 购买了5.000斤, 需要支付45.0000元
05.表达式的格式化
print("1*1的结果是:%d"%(1*1))
print("字符串在Python中的类型名是:%s"% type("字符串"))
#output:1*1的结果是:1
#字符串在Python中的类型名是:<class 'str'>
name="传智播客"
stock_price=19.99
stock_code="003032"
stock_price_daily_growth_factor =1.2
growth_days=7
finally_stock_price=stock_price*stock_price_daily_growth_factor**growth_days
print(f"公司:{name},股票代码:{stock_code},当前股价:{stock_price}")
print("每日增长系数:%.1f,经过%d天的增长后,股价达到了:%.2f"%(stock_price_daily_growth_factor,growth_days,finally_stock_price ))
#output:公司:传智播客,股票代码:003032,当前股价:19.99
#每日增长系数:1.2,经过7天的增长后,股价达到了:71.63
7.数据输入——input
- 用来获取键盘输入
- 语法: input()/input(提示语)//这样就不用提前print
- 无论键盘输入什么类型的数据,获得的永远都是字符串类型
print ("请告诉我你是谁")
name=input()#等价于input(请告诉我你是谁)
print("我知道你是%s"% name)
input:king
output:我知道你是king
8.随机数的处理
01.语法
import random
num = radom.randint(a, b) #返回 [a, b] 之间的整数,包含 a 和 b
三、python判断语句
1.布尔类型
- 二、常识变量类型中有
- True,False首字母要大写
2. if语句的基本格式
01.语法:
if 要判断的条件:
条件成立时,要做的事情 # 要有4个空格做缩进
...
# 如果没有缩进 就不属于if的控制范围
- 注意:代码的缩进为一个
Tab键,或者 4个空格–建议使用空格 if语句以及缩进部分可以看成是一个完整的代码块- 不要忘记判断条件后的:冒号
age=int(input("请输入你的年龄:"))
if age>=18:
print("您已成年,游玩要补票10元。")
print("祝您游玩愉快"
"""
output:请输入你的年龄:18
您已成年,游玩要补票10元。
祝您游玩愉快
"""
3.if else 语句
01.语法:
if 要判断的条件:
条件成立时,要做的事情
...
else:
条件不成立时,要做的事情
...
- else 后的冒号别忘
4.if elif else 组合使用
01.语法:
if 条件1:
条件1满足执行的代码
...
elif 条件2:
条件2满足执行的代码
...
elif 条件3:
条件3满足执行的代码
...
else:
以上条件都不满足时,执行代码
...
elif和else都必须和if联合使用,而不能单独使用- 可以将
if,elif和else以及各自缩进的diamagnetic,看成一个完整的代码块
5. if的嵌套
01.语法:
if 条件1:
条件1满足执行的代码
...
if 条件1基础上的条件2:
条件2满足时,执行的代码
...
# 条件2不满足的处理
else:
条件2不满足时,执行的代码
# 条件1不满足的处理
else:
条件1不满足时,执行的代码
has_ticket = True
knife_length = 15
if has_ticket:
print("车票检查通过,准备开始安检")
if knife_length <= 20:
print("安检通过,祝您旅途愉快")
else:
print("携带道具长度为 %d厘米" % knife_length)
print("不允许上车")
else:
print("请先买票!")
6.综合实战
# 导入随机工具包
import random
player = int(input("请输入您出的拳 石头(1)/剪刀(2)/布(3): "))
computer = random.randint(1, 3)
print("玩家出的拳头是 %d - 电脑出的拳是 %d" % (player, computer))
# 玩家胜利的三种情况
if ((player == 1 and computer == 2)
or (player == 2 and computer == 3)
or (player == 3 and computer == 1)):
print("玩家赢了!")
# 平局
elif player == computer:
print("平居")
# 电脑获胜
else:
print("电脑获胜!")
四、python循环语句
1.while循环的基本使用
01.语法
初始条件设置 - 通常是重复执行的 计数器
while 条件(判断 计数器 是否达到 目标次数):
条件满足时,做的事情1
条件满足时,做的事情2
...(省略)...
处理条件(计数器 + 1)
- 条件需要提供布尔型结果
计算 0!100 之间所有数字的累计求和结果
# 0. 定义最终结果的变量
result = 0
# 1. 定义一个整数的变量记录循环的次数
i = 0
# 2. 开始循环
while i <= 100:
print(i)
# 每一次循环,都让 result 这个变量和 i 这个计数器相加
result += i
i += 1
print("0~100 之间的数字求和结果 = %d" % result)
2.while 循环嵌套
01.语法
while 条件1:
条件满足时,做的事情1
条件满足时,做的事情2
...(省略)...
while 条件2:
条件满足时,做的事情1
条件满足时,做的事情2
...(省略)...
处理条件2
处理条件1
02.经典案例——99乘法表
-
补充:
- 单独的print语句是会自动换行,但print(“abcd”,end=‘ ’)就不会自动换行了
-
i=1 while i<10: j=1 while j<=i: print(f"{j}*{i} = {j*i}\t",end=' ') j+=1 print('') i+=1 #output: 1*1 = 1 1*2 = 2 2*2 = 4 1*3 = 3 2*3 = 6 3*3 = 9 1*4 = 4 2*4 = 8 3*4 = 12 4*4 = 16 1*5 = 5 2*5 = 10 3*5 = 15 4*5 = 20 5*5 = 25 1*6 = 6 2*6 = 12 3*6 = 18 4*6 = 24 5*6 = 30 6*6 = 36 1*7 = 7 2*7 = 14 3*7 = 21 4*7 = 28 5*7 = 35 6*7 = 42 7*7 = 49 1*8 = 8 2*8 = 16 3*8 = 24 4*8 = 32 5*8 = 40 6*8 = 48 7*8 = 56 8*8 = 64 1*9 = 9 2*9 = 18 3*9 = 27 4*9 = 36 5*9 = 45 6*9 = 54 7*9 = 63 8*9 = 72 9*9 = 81
3.for循环
- 与while循环区别:
- while循环的条件是自定义的,自行控制条件
- for循环是一种轮询机制是对一批内容的逐个处理
01.语法
for 临时变量in待处理数据集:
循环满足条件时执行的代码
#例
name="king"
for i in name:
print(i)
02. range语句
- 语法中的待处理数据集严格的来说称为序列类型
- 序列类型指,其内容可以一个个依次取出来的一种类型包括:1.字符串2.列表3.元组······
1`语法
-
range(num):获取一个从0开始,到num结束的数字序列(不含数字本身)- range(5)获取的数据就是[0,1,2,3,4]
-
range(num1,num2):获得一个从num1开始到num2结束的数字序列(不含num2本身)- range(num1,num2):[5,6,7,8,9]
-
range(num1,num2,step):是从num1到num2(不包括num2)获取数字序列,步长以step为准(step默认为一)- range(5,10,2):[5,7,9]
03.for循环的作用域:
- 限定在循环内
4.for循环的嵌套
01.语法
for 临时变量in待处理数据集:
循环满足条件时执行的代码
for 临时变量in待处理数据集:
循环满足条件时执行的代码
### 5.break 和 continue
```py
i = 0
while i < 10:
# break 某一条件满足时,退出循环,不再执行后续重复的代码
# i == 3
if i == 3:
break
print(i)
i += 1
print("over")
#output:
0
1
2
over
i = 0
# 输出 0~10 不包括3
while i < 10:
# - `continue` 某一条件满足时,不执行后续重复的代码
# i == 3
if i == 3:
# 注意:在循环中,如果使用 continue 这个关键字
# 在使用关键字之前,需要确认循环的计数是否修改,
# 否则可能会导致死循环
i += 1
continue
print(i)
i += 1
print("over")
#output:
0
1
2
4
5
6
7
8
9
over
6.循环综合案例–发工资案例
money=10000
for i in range(1,21):
import random
num = random.randint(1, 10)
print(f"员工的绩效为{num}")
if num<5:
print(f"员工{i}绩效分{num}不满足,不发工资,下一位")
continue
if money>=1000:
money-=1000
print(f"员工{i}绩效分满足发放工资1000,公司账户余额:{money}")
else:
print(f"余额不足,当前余额{money}元,不发了,下个月再来")
break
五、python函数
1.基础认识
- 所谓 函数,就是把 具有独立功能的代码块 组织为一个小模块,在需要的时候 调用
- 函数的使用包含两个步骤:
- 定义函数 – 封装 独立的功能
- 调用函数 – 享受 封装 的成果
- 函数的作用,在于开发程序时,使用函数可以提高缩写的效率以及代码的 重用
2.函数的定义
01.语法
def 函数名():
函数封装的代码
...
def是英文define的缩写- 函数名称 应该能够表达 函数封装代码 的功能,方便后续使用
- 函数名称 的命名应该 符合 标识符的命名规则
- 可以由 字母,下划线 和 数字 组成
- 不能以数字开头
- 不能与关键字重名
02.函数调用
-
函数名() -
例:
name = "小明" # Python 解释器知道下方定义了一个函数 def say_hello(): print("hello 1") print("hello 2") print("hello 3") print(name) # 只有在程序中,主动调用函数,才会让函数执行 say_hello() print(name)
3.函数的参数
01.使用
- 在函数明的后面的小括号内部填写 参数
- 多个参数之间使用
,分隔
02.作用
- 函数 把 具有独立功能的代码 组织为一个小模块,在需要的时候 调用
- 函数的参数,增加函数的 通用性,针对 相同的数据处理逻辑,能够 适应更多的数据
- 在函数 内部,把参数当做 变量 使用,进行需要的数据处理
- 函数调用时,按照函数定义的参数顺序,把 希望在函数内部处理的数据,通过参数传递
03.形参和实参
- 形参 定义 函数时,小括号中的参数,是用来接受参数用的,在函数内部 作为变量使用
- 实参:调用 函数时,小括号中的参数,是用来把数据传递到 函数内部 用的
-
例:
def sum_2_num(num1, num2): """对两个数字求和""" return num1 + num2 # 调用函数,并使用 result 变量接受计算结果 result = sum_2_num(10, 20) print("计算结果是 %d" % result)
4.函数的返回
01.正常情况下
- 在程序开发中,有时候,会希望 一个函数执行结束后,告诉调用者一个结果,以便调用者针对具体的结果做后续的处理
- 返回值 是函数完成工作后,最后 给调用者的 一个结果
- 在函数中使用
return关键字可以返回结果 - 调用函数一方,可以 使用变量 来 接受 函数的返回结果
注意:
return表示返回,后续代码都不会被执行
02.None类型
- 用在函数无返回值上
- 可以用到if的判断上,None等同于False
- 用在声名无内容上
5.函数的说明文档
-
就是多行注释
def check(a): """ 可用于解释函数作用 :param a: 解释参数意义 :return: 解释返回值意义 """ -
调用函数的时候在pycharm中鼠标悬停可以查看函数的说明文档
6.函数的嵌套调用
- 一个函数里面 右调用了 另外一个函数,这就是 函数嵌套调用
- 如果函数 test2中,调用了另外一个函数test1
- 那么执行调用
test1函数时,会把函数test1中的任务都执行完 - 才会回到
test2中调用函数test1的位置,继续执行后续的代码
- 那么执行调用
def test1():
print("*" * 50)
print("test 1")
print("*" * 50)
def test2():
print("-" * 50)
print("test 2")
test1()
print("-" * 50)
test2()
#output:
--------------------------------------------------
test 2
**************************************************
test 1
**************************************************
--------------------------------------------------
7.变量的作用域
- 作用域指变量的作用范围
01.局部变量
- 定义在函数体内部的变量,只在函数体内生效
- 作用:在函数运行,函数调用变量,运行完销毁变量
02.全局变量
- 函数体内外都能生效的变量
03.将函数内声明变量为全局变量才能修改值
- global 关键字
8.综合案例
money=5000000
name=None
name=input("请输入您的姓名:")
def query(show_header):
if show_header:
print("---------查询余额---------")
print(f"{name},您好,您的余额剩余:{money}元")
def saving(num):
global money #将money在函数内部定义为全局变量
money+=num
print("---------存款---------")
print(f"{name},您好,您存款:{num}元成功")
query(False)
def get_money(num):
global money # 将money在函数内部定义为全局变量
money -= num
print("---------取款---------")
print(f"{name},您好,您取款:{num}元成功")
query(False)
def main():
print("---------主菜单---------")
print(f"{name},您好欢迎来到atm,请输入您想操作的步骤")
print("查询余额\t\t[输入1]")
print("存款\t\t[输入2]")
print("取款\t\t[输入3]")
print("退出\t\t[输入4]")
choice=input("请输入你的选择:")
return choice
while True:
key=main()
if key=="1":
query(True)
continue
elif key=="2":
num=int(input("您想要存入多少钱:"))
saving(num)
continue
elif key=="3":
num = int(input("您想要取出多少钱:"))
get_money(num)
continue
else :
print("程序退出")
break
六、python数据容器
- 可以容纳多份数据的数据类型
1.列表
- 可以修改
01.列表的定义
-
列表用
[]定义,数据之间使用,分隔name_list = ["zhangsan", "lisi", "wangwu"] -
利用
type()得其数据类型为list -
嵌套列表
mylist = [[1,2,3],[4,5,6]]
02.列表的下标索引
-
列表的索引从0开始
- 索引 就是数据在 列表 中的位置编号,索引 又可以被称为 下标
-
也可通过反向下标索引
-
最后一个元素的下标是-1
my_list=[[1,2,3],[4,5,6]] # 3就是my_list[0][2]
-
-
嵌套的下标索引
- 写两层下标索引
-
输入第一个元素
my_list=[1,2,3,4] print(my_list[0])
03.列表的常用方法
| 序号 | 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|---|
| 1 | 增加 | list.insert(索引,数据) | 在指定位置插入数据 |
list.append(数据) | 在末尾追加数据 | ||
list.extend(列表2) | 将列表2 的数据追加到列表 | ||
| 2 | 修改 | list[索引] = 数据 | 修改指定索引的数据 |
| 3 | 删除 | del list[索引] | 删除指定索引的数据 |
list.remove[数据] | 删除第一个出现的指定数据 | ||
list.pop() | 删除末尾数据 | ||
list.pop(索引) | 删除指定索引数据 | ||
list.clear() | 清空列表 | ||
| 4 | 统计 | len(list) | 列表长度 |
list.count(数据) | 数据在列表中出现的次数 | ||
| 5 | 排序 | list.sort() | 升序排序 |
list.sort(reverse=True) | 降序排序 | ||
list.reverse() | 逆序、反转 | ||
| 6 | 查询 | list.index() | 查找指定元素的下标 |
- 补充
- 使用
del关键字(delete) 同样可以删除列表中元素 del关键字本质上是用来 将一个变量从内存中删除的- 如果使用
del关键字将变量从内存中删除出,后续代码就不能再使用这个变量了
- 使用
4. list(列表)的遍历
- 遍历就是从头到尾依次从列表中获取数据
- 在循环内部针对每一个元素,执行相同的操作
- 在
Python中为了提高列表的遍历效率,专门提供的 迭代 iteration 遍历
01.使用 for 实现迭代遍历
name_list = ["小李广-花荣", "呼保义-宋江", "玉麒麟-卢俊义", "黑旋风-李逵"]
# 使用迭代遍历列表
"""
顺序从列表中依次获取数据,每一次循环过程中,数据都会保存在my_name 这个变量中,
在循环体内部可以访问当前这一次获取到的数据
"""
for my_name in name_list:
print("我的名字是 %s" % my_name)
02.使用while实现迭代遍历
index=0
while index<len(mylist):
print(```)
index+=1
- 列表中可以存储不同类型的数据
- 在开发中,更多的应用场景是
- 列表存储相同类型的数据
- 通过迭代遍历,在循环体内部,针对列表中的每一项元素,执行相同的操作
2.元组
- 不同于列表——一旦定义完成不可修改
- 但是元组里嵌套一个list里的值是可以修改的
01.元组的定义
- 元组表示多个元素组成的序列
- 元组在
Python开发中,有特定的应用场景 - 用于存储一串信息,数据之间使用
,分隔 - 元组用
**()**定义 - 元组的索引从0开始
- 索引就是数据在元素中的位置编号
info_tuple = ("zhangsan", 18, 1.75)
- 创建空元组
tuple = () # 也可是t0=tuple()
- 元组中只包含一个元素时,需要在元素后面添加逗号
single_tuple = ("zhangsan",)
02.元组的下标索引
- 同list
03.元组常用方法
info_tuple = ("zhangsan", 18, 1.75)
# 1. 取值和取索引
print(info_tuple[0])
# 已知数据的内容,想得到该数据在元组中的索引
print(info_tuple.index("zhangsan"))
# 2. 统计计数
print(info_tuple.count("zhangsan"))
# 统计元组中包含元素的个数
print(len(info_tuple))
04.元组的遍历
info_tuple = ("宋江", "及时雨", "天魁星")
# 使用迭代遍历元组
for my_info in info_tuple:
# 使用格式化字符串拼接 my_info 这个变量不方便!
# 因为元组中通常保存的数据类型是不同的!
print(my_info)
index=0
t8=(1,2,3,4)
while index<len(t8):
print(```)
index+=1
3.字符串
- 字符串本质也是只读的不可修改的
01.字符串的定义
-
字符串就是一串字符,是变成语言中表示文本的数据类型
-
在 Python 中可以使用
一对双引号" "或者一对单引号’ '定义一个字符串
- 如果字符串内部需要使用双引号
",可以使用单引号''定义字符串 - 如果字符串内部需要使用单引号
',可以使用双引号"定义字符串
- 如果字符串内部需要使用双引号
02.字符串的下标索引
- 可以使用索引获取一个字符串中指定位置的字符,索引计数从0开始
03.字符串的常用方法
判断类型 - 9
| 方法 | 说明 |
|---|---|
isspace() | 如果只包含空格(空白字符),则返回 True |
isalnum() | 如果至少有一个字符并且所有字符都是字母或数字则返回 True |
isalpha() | 如果至少有一个字符并且所有字符都是字母则返回 True |
isdecimal() | 如果只包含数字则返回 True,全角数字 |
isdigit() | 如果只包含数字则返回 True,全角数字,(1),\u00b2 |
isnumeric() | 如果只包含数字则返回 True, 全角数字,汉字数字 |
istitle() | 如果是标题化的(每个单词的首字母大写)则返回 True |
islower() | 如果包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True |
isupper() | 同上,大写返回 True |
2)查找和替换和统计 - 7
| 方法 | 说明 |
|---|---|
startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
endswith(str) | 同上,结尾 |
string.find(str,start=0,end=len(string)) | 检查 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,负责返回 -1 |
string.rfind(str,start=0,end=len(string)) | 类似上,从右边开始查找 |
string.index(str,start=0,end=len(string)) | 和 find() 类似,只不过如果 str 不在会报错 |
rindex() | 同上,从右边开始 |
string.replace(old_str, new_str, num=string.count(old) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 注:不是修改字符串本身,而是得到一个新的字符串 |
string.count("统计内容") | 统计字符串内某字符串出现次数 |
| ** ** | 统计字符串长度 |
3)大小写转换 - 5
| 方法 | 说明 |
|---|---|
string.capitalize() | 把字符串的第一个字符大写 |
string.title() | 把字符串的每个单词首字母大写 |
string.lower() | 转换 string 中所有大写字母为小写 |
string.upper() | 转换 string 中的小写字母为大写 |
string.swapcase(0 | 翻转 string 中的大小写 |
4)文本对齐 - 3
| 方法 | 说明 |
|---|---|
string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
string.rjust(width) | 右对齐 |
string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
5)去除空白字符串 - 3
| 方法 | 说明 |
|---|---|
string.lstrip() | 截掉 string 左边(开始)的空白字符 |
string.rstrip() | 右边 |
string.strip() | 截掉 string 左右两边的空白字符,注:如果其中输入的是12这样的参数,删的不是十二,而是1,2都会删掉 |
6)拆分和连接 - 5
| 方法 | 说明 |
|---|---|
string.partition(str) | 把字符串 string 分成一个 3元素的元组(str前面,str,str后面) |
string.rpartition(str) | 同上,不过是从右边开始查找 |
string.split(str="",num) | 以 str 分隔符切片 string,如果 num 有指定值,则仅分隔 num+1个字符串,str默认包含\r,\t,\n,空格,注:字符串本身不变,而是得到一个列对象 |
string.splitlines() | 按照行(\r, \n)分隔,返回一个包含各行作为元素的列表 |
string.join(seq) | 以 string 作为分隔符,将 seq 中所有元素(的字符串表示)合并为一个新的字符串 |
my_str="itheima itcase boxuegu"
num=my_str.count("it")
print(f"字符串{my_str}中有{num}个it字符串")
mew_my_str=my_str.replace(" ","|")
print(f"字符串{my_str}被替换空格后,结果是:{mew_my_str}")
my_str_list=mew_my_str.split("|")
print(f"字符串{my_str}被|分割后,结果是:{my_str_list}")
#output:
"""
字符串itheima itcase boxuegu中有2个it字符串
字符串itheima itcase boxuegu被替换空格后,结果是:itheima|itcase|boxuegu
字符串itheima itcase boxuegu被|分割后,结果是:['itheima', 'itcase', 'boxuegu']
"""
04.字符串的遍历
- 也可以使用
for循环遍历字符串中每一个字符
4.序列的切片操作
-
序列:内容连续,有序,可使用下标索引的一类数据容器
- 故列表、元组、字符串等均可视为序列
-
切片——从一个序列中取出一个子序列
-
此操作不会影响序列本身,而是会得到一个新序列
方法适用于字符串、列表、元组
- 切片使用索引值来限定范围,从一个大的字符串中切出小的字符串
- 列表和元组都是有序的集合,都能够通过索引值获取到对应的数据
- 字典是一个无序的集合,是使用键值对保存数据
序列[开始索引:结束索引:步长]
- 指定的区间属于 左闭右开型([开始索引,结束索引))
- 从
起始位开始,到结束位的前一位结束(不包含结束位本身)
- 从
- 从头开始,开始索引数字可以省略,冒号不能省略
- 到末尾结束,结束索引数字可以省略,冒号不能省略
- 步长默认为1,如果连续切片,数字和冒号都可以省略
- 步长为n表示每次跳过n-1个元素取
- 反向切片,步长为-1——等同于将序列反转
my_str ="万过薪月,员序程马黑来,nohtyP学"
#倒序字符串,切片取出
result1 = my_str[::-1][9:14]
print(f"方式1结果:{result1}")
#切片取出,再倒序
result2 = my_str[5:10][::-1]
print(f"方式2结果:{result2}")
#Spilt分隔”,“,replace替换”来“为空,倒叙字符串
result3 = my_str.split(",")[1].replace("来","")[::-1]
print(f"方式3结果:{result3}")
"""
方式1结果:黑马程序员
方式2结果:黑马程序员
方式3结果:黑马程序员
"""
5.集合
- 列表,元组,字符串哦都支持重复元素且有序
- 集合无重复元素并且内容无序
- 因为集合无序所以集合不支持下标索引访问
01.集合的定义
#定义集合字面量
{元素,元素,元素...}
#定义集合变量
变量名称={元素,元素,元素...}
#定义空集合
变量名称=set()
02.集合的常用方法
| 方法 | 说明 |
|---|---|
myset.add() | 添加新元素 |
myset.remove() | 移除元素 |
myset.pop() | 随机取出一个元素 |
myset.clear() | 清空集合 |
myset1.difference(myset2) | 取集合1和集合2的差集(集合1有而集合2没有的),结果是得到一个新集合,集合1,集合2不变 |
myset1.difference_update(myset2) | 消除2个集合的差集,就是**在集合1内删除和集合2相同的元素。集合1被修改,集合2不变 |
myset1.unior(myset2) | 集合1集合2合并为一个新集合,得到新集合,集合1,集合2不变 |
len(myset) | 统计集合元素数量 |
03.集合的遍历
-
集合不支持下标索引,所以集合不可以用while循环来遍历
-
for循环遍历与之前的数据容器一样
6.字典——映射
01.字典的定义
-
dictionary(字典)是除列表以外Python之中最灵活的数据类型 -
字典同样可以用来存储多个数据
- 通常用来存储 描述一个
物体的相关信息
- 通常用来存储 描述一个
-
和列表的区别
- 列表是有序的对象集合
- 字典是无序的对象集合
-
字典用
{}定义 -
字典使用键值对存储数据,键值对之间使用,分隔
- 键
key是索引- 字典的 key 是不允许重复的
- 值
value是数据 - 键和值之间使用
:分隔 - 键必须是唯一的
- 值可以取任何数据类型,但键只能使用字符串、数字或元组
xiaoming = { "name":"宋江", "绰号":"及时雨", "地位":"梁山统领三代目", "星宿":"天魁星" } #从字典中基于key获取value name=xiaoming.["name"] - 键
02.字典的常用方法
| 方法 | 说明 |
|---|---|
mydict[key]=Value(key原本不存在于字典中) | 新增元素 |
mydict[key]=Value(key原本存在于字典中) | 更新元素 |
mydict,pop(key) | 删除元素 |
mydict.clear() | 清空元素 |
mydict.keys() | 获取全部的key |
len(mydict) | 计算字典的元素数量 |
03.字典的遍历
- 支持for循环 不支持while循环(字典不支持下标索引)
7.综合补充
01.通用操作
max(数据类型):最大元素min (数据类型): 最小元素list(容器):容器转列表tuple(容器):容器转元组str(容器):容器转字符串set(容器):容器转集合sorted(容器,[reverse==True/False])通用排序功能,默认False是从小到大,若要反向reverse==True
02.字符串的大小比较
- 基于数字的ASCII码值进行比较
- 按位比较,只要一位位进行比较,只要有一位大,那么整体就打
03.运算符
| 运算符 | Python表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
+ | [1,2]+[3,4] | [1,2,3,4] | 合并 | 字符串、列表、元组 |
* | ["Hi"]*3 | ["Hi","Hi","Hi"] | 重复 | 字符串、列表、元组 |
in | 3 in (1,2,3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
not in | 4 not in (1,2,3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
> >= == < <= | (1,2,3)<(2,2,3) | True | 元素比较 | 字符串、列表、元组 |
in在对字典操作时,判断的是字典的键in和not in被称为成员运算符- 成员运算符用于测试序列中是否包含指定的成员
| 运算符 | 描述 | 实例 |
|---|---|---|
in | 如果在指定的序列中找到值返回 True,否则返回 False | 3 in (1,2,3) 返回 True |
not in | 如果在指定的序列中没有找到值返回True,否则返回False | 3 not in (1,2,3) 返回 False |
注意:在对字典操作时,判断的是字典的键
七、python函数进阶
1.函数的多返回值
- 按照返回值的顺序变量之间用逗号隔开
- 支持不同类型的数据return
2.函数的多种参数使用
0.1.位置参数(最基础)
- 调用函数时根据函数定义的参数位置传递参数
02.关键字参数
-
函数调用时通过“键=值”形式传递参数
-
可以使函数更加清晰,容易使用,同时也清除了参数的顺序要求
-
可以不按照固定顺序
-
可以与位置参数混用,位置参数必须在前,且匹配参数顺序
def a(name,age): ... a(name="dpy",age=20) -
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数前面,但关键字参数之间不存在先后顺序
0.3. 不可变和可变参数
问题1:在函数内部,针对参数使用赋值语句,会不会影响调用函数时传递的实参变量?–不会
- 无论传递的参数是可变还是不可变
- 只要针对参数使用赋值语句,会在函数内部修改局部变量的引用,不会影响到外部变量的引用
问题2:如果传递的参数是可变类型,在函数内部,使用方法修改了数据的内容,同样会影响到外部的数据
def demo(num_list: list): #num_list 是参数名称,list表示是个列表
print("函数内部的代码")
# 使用方法修改列表的内容
num_list.append(9)
print(num_list)
print("函数执行完成")
gl_list = [1, 2, 3]
demo(gl_list)
print(gl_list)
"""
output:
函数内部的代码
[1, 2, 3, 9]
函数执行完成
[1, 2, 3, 9]
"""
运算符 +=
- 在
python中,列表变量调用+=本质上是在执行列表变量的extend方法,不会修改变量的引用
0.4. 缺省参数
- 定义函数时,可以给某个参数指定一个默认值,具有默认值的参数就叫做缺省参数
- 调用函数时,如果没有传入缺省参数的值,则在函数内部使用定义函数时指定的参数默认值
- 函数的缺省参数,将常见的值设置为参数的缺省值,从而简化函数的调用
- 例如:对列表排序的方法
gl_list = [4, 8, 2]
# 默认按照升序排序 - 较常用
gl_list.sort()
print(gl_list)
# 如果需要降序排序,需要执行reverse参数
gl_list.sort(reverse=True)
print(gl_list)
指定函数的缺省参数
- 在参数后使用赋值语句,可以指定参数的缺省值
def print_info(name, gender=True):
gender_text = "男生"
if not gender:
gender_text = "女生"
print("%s 是 %s" % (name, gender_text))
# 假设班上的同学,男生居多,所以将默认值设置为男生
# 提示:在指定缺省参数的默认值时,应该使用最常见的值作为默认值!
print_info("小明")
print_info("小红", False)
"""
小明 是 男生
小红 是 女生
"""
- 缺省参数,需要使用最常见的值作为默认值
- 如果一个参数的值不能确定,则不应该设置默认值,具体的数值在调用函数时,由外界传递
缺省参数的注意事项
- 缺省参数的定义位置
- 必须保证带有默认值的缺省参数在参数列表末尾
- 所以,以下定义是错误的
def print_info(name, gender=True, title):
pass
- 调用带有多个缺省参数的函数
- 在调用函数时,如果有多个缺省参数,需要指定参数名,这样解释器才知道参数的对应关系!
0.5 .多值参数(不定长参数)
定义支持多值参数的函数
- 有时候可能需要一个函数能够处理的参数个数是不确定的,这个时候,就可以使用多值参数
- python中有两种多值参数:
- 参数名前增加 一个
\*可以接受元组 - 参数名前增加 两个
\*可以接受字典
- 参数名前增加 一个
- 一般在给多值参数命名时,习惯使用以下两个名字
*args– 存放元组参数,前面有一个***kwargs– 存放字典参数,前面有两个*
args是arguments的缩写,有变量的含义kw是keywprd的缩写,kwargs可以记忆键值对参数
def demo(num, *nums, **person):
print(num)
print(nums)
print(person)
demo(1) # 输出:1 () {}
demo(1, 2, 3, 4, 5) # 输出:1, (2, 3, 4, 5) {}
demo(1, 2, 3, 4, 5, name="小明", age=18) # 输出:1, (2,3,4,5) {name="小明",age=18}
提示:多值参数的应用会经常出现在网络上一些大牛开发的框架中,知道多值参数,有利于读懂大牛的代码
多值参数案例 – 计算任意多个数字的和
import argparse
def sum_numbers(*args):
num = 0
# 循环遍历
for n in args:
num += n
print(args)
return num
res = sum_numbers(1, 2, 3, 4, 5)
print(res)
元组和字典的拆包
-
在调用带有多值参数的函数时,如果希望:
- 将一个元组变量,直接传递给
args - 将一个字典变量,直接传递给
kwargs
- 将一个元组变量,直接传递给
-
就可以使用
拆包
,简化参数传递,拆包的方式是:
- 在元组变量前,增加一个
* - 在字典变量前,增加两个
*
- 在元组变量前,增加一个
def demo(*args, **kwargs):
print(args)
print(kwargs)
# 元组/字典变量
gl_num = (1, 2, 3)
gl_dict = {"name":"小明", "age":18}
# 会将两个参数都传递给 *args
demo(gl_num, gl_dict)
# 拆包语法,简化元组/自带你变量的传递
demo(*gl_num, **gl_dict)
# 等价于
demo(1, 2, 3, name="小明", age=18)
"""
output:
(1, 2, 3, 4, 5)
15
"""
3.匿名函数
01.函数作参数传递
def func(compute):
result=compute(1,2)
print(result)
def compute(x,y)
return x+y
func(compute)
- 这是计算逻辑的传递,而非数据的传递
02. lambda匿名函数
- lambda关键字,可以定义匿名函数(无名称)
- 无名称的匿名函数,只可以临时使用一次
lambda 传入参数:函数体(一行代码)
- 传入参数表示匿名函数的形式参数,如:x,y表示接收两个参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
def func(compute):
result=compute(1,2)
print(result)
func(lambda x,y x+y)
八、python的文件操作
1.文件的基础认识
-
在计算机中,文件是以二进制的方式保存在磁盘上的文本文件和二进制文件
-
文本文件
- 可以使用文本编辑软件查看
- 本质上开始二进制文件
- 例如:python 的源程序
-
二进制文件
- 保存的内容不是给他人直接阅读的,而是提供给其他软件使用的
- 例如:图片文件、音频文件、视频文件等等
- 二进制文件不能使用文本编辑软件查看
2.文件操作
- 基础套路:打开文件——读写文件——关闭文件
01.操作总括
| 序号 | 函数/方法 | 说明 |
|---|---|---|
| 01 | open | 打开文件,并且返回文件操作对象 |
| 02 | read | 将文件内容读取到内存 |
| 03 | write | 将指定内容写入文件 |
| 04 | close | 关闭文件 |
open函数负责打开文件,并且返回文件对象read/write/close三个方法都需要通过文件对象来调用
02.打开文件——open函数
open函数默认以只读模式打开文件,并且返回文件对象
语法如下:
f = open("文件名", "访问方式",encoding(编码格式)(推荐使用UTF-8格式))
- 注意:此时的‘f’是open函数的文件对象。
- name:是要打开的目标文件名的字符串(可以包括文件所在的具体地址)
| 访问方式 | 说明 |
|---|---|
r | 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式。如果文件不存在,抛出异常 |
w | 以只写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
a | 以追加方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
r+ | 以读写方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常 |
w+ | 以读写方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件 |
a+ | 以读写方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入 |
f=open("C:\KING的python\pythonProject1\测试.txt","r",encoding="UTF-8")
03.读取文件
read 方法
文件对象.read(num)
# num 表示要从文件中读取的数据的长度(单位是字节)
read方法默认(不传入num值)会把文件的所有内容一次性读取到内存- 如果文件太大,对内存的占用会非常严重
- 如果连续的调用read,它会接着之前读的继续往后读
readline 方法
readline方法可以一次读取一行内容readlines方法一次读取全部内容- 方法执行后,会把文件指针移动到下一行,准备再次读取
f=open("C:\KING的python\pythonProject1\测试.txt","r",encoding="UTF-8")
print(f"读取10字节的结果,{f.read(11)}")
"""
output:读取11字节的结果,爱意随风起,风止意难平
"""
for循环读取文件行
for line in f:
print(f"每一行数据是:{line}")
读取大文件的正确姿势
# 1.打开文件
file = open("README")
# 2.读取文件
while True:
# 每次读取一行
text = file.readline()
# 判断是否读取到内容
if not text:
break
print(text, end="")
# 关闭文件
file.close()
04.关闭文件
f.close()
- **
with open**可以在操作完成后自动关闭close文件,避免忘掉close方法
with open("文件名", "访问方式",encoding(编码格式)(推荐使用UTF-8格式))as f:
05.文件的写入——模式是“w”
#文件写入
f.write("想写入的内容")
#内容刷新
f.flush()
-
直接调用write时,内容并未直接写入文件,而是会积攒在程序的内存中,称之为缓冲区
-
当调用flash的时候,内容才会真正写入文件
-
这样做是避免频繁操作硬盘,导致效率降低
06.文件的追加——模式是“a”
- 其余同5
07.综合案例
小文件复制
- 打开一个已有文件,读取完整内容,并写入到另一个文件
# 1.打开文件
file_read = open("README")
file_Write = open("README[复件]", "w")
# 2.读、写文件
text = file_read.read()
file_Write.write(text)
# 3.关闭文件
file_read.close()
file_Write.close()
大文件复制
- 打开一个已有文件,逐行读取内容,并顺序写入到另一个文件
# 1.打开文件
file_read = open("README")
file_Write = open("README[复件]", "w")
# 2.读、写文件
while True:
# 读取一行内容
text = file_read.readline()
# 判断是否读取到内容
if not text:
break
file_Write.write(text)
# 3.关闭文件
file_read.close()
file_Write.close()
九、python异常,模块,包
1.异常的概念
- 程序在运行时,如果
Python 解释器遇到一个错误,会停止程序的执行,并且提示一些错误信息,这就是异常 - 程序停止执行并且提示错误信息这个动作,我们通常称之为:抛出(raise)异常
2.捕获异常
- 在程序开发中,如果对某些代码的执行不能确定是否正确,可以增加
try(尝试)来捕获异常 - 捕获异常最简单的语法格式:
try:
尝试执行的代码
except:
出现错误的处理
try尝试,下方编写要尝试的代码,不确定是否能够正常执行的代码except如果不是,下方编写尝试失败的代码
简单异常捕获演练 – 眼球用户输入整数
try:
# 不能确定正确执行的代码
num = int(input("请输入一个整数:"))
except:
# 错误的处理代码
print("请输入正确的整数格式")
print("-" * 50)
"""
output:
请输入一个整数:dpy
请输入正确的整数格式
--------------------------------------------------
"""
0.1 错误类型的捕获——捕获指定的异常
- 在程序执行时,可能会遇到不同类型的异常,并且需要针对不同类型的异常,做出不同的响应,这个时候,就需要捕获错误类型
- 语法如下:
try:
# 尝试执行的代码
pass
except 错误类型1:
# 针对错误类型1,对应的代码处理
pass
except (错误类型2, 错误类型3):#这是捕获多个异常(创建一个元组)
# 针对错误类型2 和 3,对应的代码处理
pass
except Exception as result:
print("未知错误 %s " % result)
- 当
Python解释器抛出异常时,最后一行错误信息的第一个单词,就是错误类型
需求
- 提示用户输入一个整数
- 使用
8除以用户输入的整数并且输出
try:
# 1. 提示用户输入一个整数
num = int(input("输入一个整数:"))
# 2. 使用 `8` 除以用户输入的整数并且输出
res = 8 / num
print(res)
except ZeroDivisionError:
print("除0错误")
except ValueError:
print("请输入正确的整数")
捕获未知错误
- 在开发时,要预判到所有可能出现的错误,还是有一定难度的
- 如果希望程序无论出现任何错误,都不会因为
Python解释器抛出异常而被终止,可以再增加一个except - 语法如下:
except Exception as result:
print("未知错误 %s" % result)
0.2 异常捕获完整语
-
在实际开发中,为了能够处理复杂的异常情况,实际的异常语法如下:
提示:
- 有关完整语法的应用场景,在后续学习中,结合实际的案例会更好理解
try:
# 尝试执行的代码
pass
except 错误类型1:
# 针对错误类型1,对应的代码处理
pass
except 错误类型2:
# 针对错误类型2,对应的代码处理
pass
except (错误类型3, 错误类型4):
# 针对错误类型3 和 4,对应的d代码处理
pass
except Exception as result:
# 打印错误信息
print(result)
else:
# 没有异常才会执行的代码
pass
finally:
# 无论是否有异常,都会执行的代码
print("无论是否有异常,都会执行的代码")
else只有在没有异常时才会执行的代码finally无论是否有异常,都会执行的代码- 之前一个演练的完整捕获异常代码如下:
try:
# 1. 提示用户输入一个整数
num = int(input("输入一个整数:"))
# 2. 使用 `8` 除以用户输入的整数并且输出
res = 8 / num
print(res)
except ValueError:
print("请输入正确的整数")
except Exception as result:
print("未知错误 %s" % result)
else:
print("尝试成功")
finally:
print("无论是否出现异常都会执行的代码")
print("-" * 20)
3.异常的传递
- 异常的传递 – 当函数/方法执行出现异常,会将异常传递给函数/方法的调用一方
- 如果传递到主程序,仍然没有异常处理,程序才会被终止
- 在开发中,可以在主函数中增加异常捕获
- 而在主函数中国调用的其他函数,只要出现异常,都会传递到主函数的异常捕获中
- 这样就不需要在代码中,增加大量的异常捕获,能够保证代码的整洁
需求
- 定义函数
demo1()提示用户输入一个函数并且返回 - 定义函数
demo2()调用demo1() - 在 主程序中调用
demo2()
def demo1():
return int(input("请输入整数:"))
def demo2():
return demo1()
# 利用异常的传递性,在主程序捕获异常
try:
print(demo2())
except Exception as result:
print("未知错误 %s" % result)
4.python模块
0.1 模块的概念
模块是 Python 程序架构一个核心概念
- 每一个以扩展名
.py结尾的Python源代码文件都是一个模块 - 模块名同样也是一个标识符,需要符合标识符的命名规则
- 在模块中 定义的全局变量、函数、类都是提供给外界直接使用的工具
- 模块就好比是工具包,要想使用这个工具包中工具,就需要先导入这个模块
0.2 模块的两种导入方式
1`import 导入
import 模块名1
import 模块名2
提示:在导入模块时,每个导入应该独占一行
- 导入之后
- 通过
模块名.使用模块提供的工具 – 全局变量、函数、类
- 通过
使用 as 指定模块的别名
如果模块的名字太长,可以使用
as指定模块的名称,以方便在代码中的使用
import 模块1 as 模块别名
注意:模块别名应该符合大驼峰命名法
import time
print("你好")
time.sleep(5)
print("我好")
2`from … import 导入
- 如果希望从某一个模块中,导入部分工具,就可以使用
from ... import的方式 import 模块名是一次性把模块中所有工具全部导入,并且通过 模块名/别名访问
# 从模块 导入 某一个工具
from 模块1 import 工具名
- 导入之后
- 不需要通过
模块名. - 可以直接使用模块提供的工具 – 全局变量、函数、类
- 不需要通过
注意:如果两个模块,存在同名的函数,那么后导入模块的函数,会覆盖掉先导入的函数
- 开发时
import代码就应该统一写在代码的顶部,更容易及时发现冲突 - 一旦发现冲突,可以使用
as关键字给其中一个工具起一个别名 from ... import *
# 从模块导入所有工具
from 模块名1 import *
这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
from time import sleep
print("你好")
sleep(5)
print("我好")
0.3 模块的搜索顺序
Python 的解释器在导入模块时,会:
- 搜索当前目录指定模块名的文件,如果有就直接导入
- 如果没有,再搜索系统目录
在开发时,给文件起名,不要和系统的模块文件重名
Python中每一个模块都有一个内置属性__file__可以查看导入模块的完整路径
import random
# 生成一个 0~10 的数字
rand = random.randint(0, 10)
print(rand)
注意:如果当前目录下,存在一个
random.py的文件按程序就无法正常运行 这个时候,Python的解释器会加载当前目录下的random.py而不会加载系统的random模块
-
原则 – 每一个文件都应该是可以被导入的
-
一个独立的
Python文件就是一个模块 -
在导入文件时,文件中所有没有任何缩进的代码都会被执行一遍!
在很多 Python 文件中都会看到以下格式的代码:
04.自定义模块
-
只需要正常的写一个python文件
-
如果调用两个模块的同名函数,会调用后一个,因为后一个会将前一个覆盖
实际开发场景
-
在实际开发中,每一个模块都是独立开发的,大多都有专人负责
-
开发人员通常会
在模块下发增加一些测试代码
- 仅在模块内部使用,而被导入到其他文件中不需要执行
__main__ 属性
__name__属性可以做到,测试模块的代码只在测试情况下被运行,而在被导入时不会被执行!
__name__是Python的一个内置属性,记录着一个字符串- 如果是被其他文件导入,
__name__就是模块名 - 如果是当前执行的程序,
__name__是__main__
# 导入模块
# 定义全局变量
# 定义类
# 定义函数
# 在代码的最下方
def mian():
# ...
pass
# 根据 __name__ 判断是否执行下方代码
if __name__ == "__main__":
main()
__all__变量
__all__=['test_a']
def test_a:
def test_b:
```
- 如果一个模块文件有**`__all__`变量**,当使用`from 模块名 import *`导入时,只能导入这个列表中的元素
- 所以如上例只能调用test_a
### 5.python 的包
#### 01.**概念**
- 包是一个**包含多个模块的特殊目录**
- 目录下有一个特殊的文件 `__init__.py`
- 包名的命名方式和变量名一致,小写字母 + `_`
#### 02.**好处**
- 使用 `import 保名` 可以**一次性导入包中所有模块**
**案例演练**
1. 新建一个 `cm_message` 的包
2. 在目录下,新建两个文件 `send_message` 和 `receive_message`
3. 在 `send_message` 文件中定义一个 `send` 函数
4. 在 `receive_message` 文件中定义一个 `receive` 函数
5. 在外部直接导入 `hm_message` 的包
**`__init__.py`**
- 要在外界使用包中的模块,**需要在 `__init__.py` 中指定对外界提供的模块列表**
```py
# __init__.py
# 从 当前目录 导入 模块列表
from ch_message import send_message
from ch_message import receive_message
# ch_10_导入包.py
import ch_message
ch_message.send_message.send("hello")
txt = ch_message.receive_message.receive()
print(txt)
- 也可以通过
__all___变量来控制import *
03.第三方包安装
- 见一的4.
十、基础数据可视化开发
1`.折线图
1.json数据格式
01.定义
- JSON是一种轻量级的数据交互格式,可以按照JSON指定的格式去组织和封装数据
- JSON本质上是一个带有特定格式的字符串
02.功能
- json就是一种在整个编程语言中流通的数据格式,负责不同编程语言中的数据交流和传递
03.python数据和json数据的相互转化
- 通过
**json.dump(data)**方法把python数据转化为json数据
data=json.dumps(data) - 通过
**json.loads(data)**方法把json数据转化为python数据
data=json.loads(data)
#导入json模块
import json
#准备符合格式json格式的python数据
data=[{"name":"老王"},{"name":"张三"}]
#通过json.dump(data)方法把python数据转化为json数据
data=json.dumps(data)
#通过json.loads(data)方法把json数据转化为python数据
data=json.loads(data)
- 在调用
json.dumps()时用**json.dumps(data.ensure_ascii=False)可以保证中文的正常显示**
2.pycharts模块
-
官方画廊
- https://gallery.pyecharts.org/#/README
01.基础折线图
#导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
#得到折线图对象
line=Line()
# 添加x轴数据
line.add_xaxis(["中国","美国","英国"])
#添加y轴数据
line.add_yaxis("GDP",[30,20,10])
#通过render方法生成图表
line.render()
- 需要使用浏览器打开
02.添加全局配置
- 全局配置选项可以通过**
set_global_opts**方法来进行配置
#导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts
#得到折线图对象
line=Line()
# 添加x轴数据
line.add_xaxis(["中国","美国","英国"])
#添加y轴数据
line.add_yaxis("GDP",[30,20,10])
#通过全局配置项set_global_opts来设置
line.set_global_opts(
title_opts=TitleOpts(title="GDP展示",pos_left="center",pos_bottom="1%"),#这是标题
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),#工具箱
visualmap_opts=VisualMapOpts(is_show=True),#视觉映视
)
#生成图表
line.render()
3.数据处理
- 通过第三方软件对数据进行处理如:ab137
- 通过**
replace()**的方法删除不需要的内容 - 再用**
json.loads()**将JSON转字典 - 再通过字典操作分别去取得x轴和y轴数据
2`地图可视化
01.基础绘制
from pyecharts.charts import Map
#准备地图对象
map = Map()
#准备数据
data = [
("北京市",99),
("上海市",199),
("湖南省",299),
("台湾省",399),
("广东省",499)
]
#添加数据
map.add("测试地图",data,"china")
#绘图
map.render()
02.添加全局配置
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
#准备地图对象
map = Map()
#准备数据
data = [
("北京市",99),
("上海市",199),
("湖南省",299),
("台湾省",399),
("广东省",499),
("黑龙江省",9),
]
#添加数据
map.add("测试地图",data,"china")
#设置全局配置
map.set_global_opts(
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True, # 是否分段
pieces=[
{"min":1,"max":9,"label":"1-9人","color":"#CCFFFF"},
{"min":10,"max":99,"label":"10-99人","color":"#FFFF99"},
{"min":100,"max":499,"label":"99-499人","color":"#FF9966"}
]
)
)
#绘图
map.render()

3`动态柱状图开发
1.基础柱状图
- 通过Bar构建基础柱状图
#导包
from pyecharts.charts import Bar
#通过Bar构建基础柱状图
bar=Bar()
#添加x轴数据
bar.add_xaxis(["中国","美国","英国"])
#添加y轴数据
bar.add_yaxis("GDP",[30,20,10])
#绘图
bar.render()
01.反转x和y轴
- `bar.reversal_axis()
#导包
from pyecharts.charts import Bar
#通过Bar构建基础柱状图
bar=Bar()
#添加x轴数据
bar.add_xaxis(["中国","美国","英国"])
#添加y轴数据
bar.add_yaxis("GDP",[30,20,10])
#反转x轴和y轴
bar.reversal_axis()
#绘图
bar.render()
02.设置数值标签在右侧
- 在添加数据时通过
label_opts=LabelOpts(position="位置信息")
#导包
from pyecharts.charts import Bar
from pyecharts.options import LabelOpts
#通过Bar构建基础柱状图
bar=Bar()
#添加x轴数据
bar.add_xaxis(["中国","美国","英国"])
#添加y轴数据
bar.add_yaxis("GDP",[30,20,10],label_opts=LabelOpts(position="right"))
#反转x轴和y轴
bar.reversal_axis()
#绘图
bar.render()

03.创建时间线
- 通过
Timeline功能
#导包
from pyecharts.charts import Bar,Timeline
from pyecharts.options import LabelOpts
#通过Bar构建基础柱状图
bar1=Bar()
bar1.add_xaxis(["中国","美国","英国"])
bar1.add_yaxis("GDP",[30,30,10],label_opts=LabelOpts(position="right"))
bar1.reversal_axis()
bar2=Bar()
bar2.add_xaxis(["中国","美国","英国"])
bar2.add_yaxis("GDP",[50,50,50],label_opts=LabelOpts(position="right"))
bar2.reversal_axis()
bar3=Bar()
bar3.add_xaxis(["中国","美国","英国"])
bar3.add_yaxis("GDP",[70,60,60],label_opts=LabelOpts(position="right"))
bar3.reversal_axis()
#构建时间线对象
timeline=Timeline()
#在时间线内添加柱状图对象
timeline.add(bar1,"点1")
timeline.add(bar2,"点2")
timeline.add(bar3,"点3")
#自动播放设置
timeline.add_schema(
play_interval=1000,#自动播放的时间间隔,单位毫秒
is_timeline_show=True,#是否显示时间线
is_auto_play=True,#是否自动播放
is_loop_play=True#是否循环自动播放
)
#绘图就是用时间线对象,而不是Bar对象
timeline.render("基础时间线柱状图.html")
补:1修改主题
-
from pyecharts.globals import ThemeType -
#构建时间线对象 timeline=Timeline({"theme":ThemeType.想要修改的主题})
补:2 列表的sort 排序
list.sort(key=选择排序依据的函数,reverse=True|False)
-
参数key,是要求传入一个函数,表示将列表的每一个元素都传入函数中,返回排序的依据
-
参数reverse,是否反转排序结果,True表示降序,False表示升序
#如下限套列表、要求对外层列表进行排序、排序的依据是内层列表的第二个元素数宇 #以前学习的sorted两数就无法适用了。可以使用列表的sort方法 my_list =[["a",33],["b",55],["c",11]] #定义排序方法 def choose_sort_key(element): return element[1] #将元素传入choose_sort_key函数中,用来确定按照谁来排序 my_list.sort(key=choose_sort_key,reverse=True) print(my_list) """ output: [['b', 55], ['a', 33], ['c', 11]] """
补:3 将数据大的放上面
- 将数据反转,利用**
data.reverse()**
十一、类和对象
1.类和对象初识
0.1类
- 类是对一群具有相同特征或者行为的事物的一个统称,是抽象的,不能直接使用
- 特征被称为属性
- 行为被称为方法
- 类就相当于制造飞机时的图纸,是一个模板,是负责创建对象的
0.2 对象
- 对象是由类创建出来的一个具体存在,可以直接使用
- 由哪一个类创建出来的对象,就拥有在哪一个类中定义的:
- 属性
- 方法
- 对象就相当于用图纸制造的飞机
在程序开发中,应该现有类,再有对象
2.类和对象的关系
- 类是模板,对象是根据类这个模板创建出来的,应该先有类,再有对象
- 类只有一个,而对象可以有很多个
- 不同的对象之间属性可能会各不相同
- 类中定义了什么属性和方法,对象中就有什么属性和方法,不可能多,也不可能少
3.类的设计
在使用面向对象开发前,应该首先分析需求,确定一下程序中需要包含哪些类!

在程序开发中,要设计一个类,通常需要满足以下三个要素:
- 类名 这类事物的名字,满足大驼峰命名法
- 属性 这类食物具有什么样的特征
- 方法 这类食物具有什么样的行为
0.1 类名的确定
名词提炼法分析整个业务流程,出现的名词,通常就是找到的类
0.2 属性和方法的确定
- 对对象的特征描述,通常可以定义成属性
- 对象具有的行为(动词),通常可以定义成方法
提示:需求中没有设计的属性或者方法在设计类时,不需要考虑
4.面向对象基础语法
01.定义只含属性的类
#构建一个类
class Student:
name=None
gender=None
nationality=None
native_place=None
age=None
#创建一个对象
stu_1=Student()
#对象属性进行赋值
stu_1.name="xdb"
stu_1.gender="女"
stu_1.nationality="中国"
stu_1.native_place="江苏"
stu_1.age=20
#获取对象的数据
print(stu_1.name)
print(stu_1.gender)
print(stu_1.nationality)
print(stu_1.native_place)
print(stu_1.age)
"""
xdb
女
中国
江苏
20
"""
02,定义只含方法的类
- 在 Python 中要定义一个只包含方法的类,语法格式如下:
class 类名:
def 方法1(self, 参数列表):
pass
def 方法2(self, 参数列表):
pass
- 方法的定义格式和之前学习过的函数几乎一样
- 区别在于第一个参数必须是
self - 注意:类名的命名规则要符合大驼峰命名法
03.简单综合
定义一个猫类 Cat
定义两个方法 eat 和 drink
按照需求 - -不需要定义属性
class Cat:
"""这是一个猫类"""
def eat(self):
print("小猫爱吃鱼")
def drink(self):
print("小猫要喝水")
# 创建猫对象
tom = Cat()
tom.eat()
tom.drink()
print(tom)
addr = id(tom)
print("%x" % addr)
引用概念的强调
在面向对象开发中,引用的概念是同样适用的
- 在 Python 中使用类创建对象之后,
tom变量中仍然记录的是对象在内存中的地址 - 也就是
tom变量引用了新建的猫对象 - 使用
print输出对象变量,在默认情况下,是能够输出这个变量引用的对象是由哪一个类创建的对象,以及在内存中的地址(十六进制标识)
[
提示:在计算机中,通常使用十六进制标识内存地址
- 十进制和十六进制都是用来表达数字的,只是标识的方式不一样
- 十进制和十六进制的数字之间可以来回转换
%d可以以10进制输出数字%x可以以16进制输出数字
04.方法中的 self 参数
-
self是成员方法定义时必须填写的 -
在方法内部,想要访问类的成员变量,必须使用
self -
在类封装的方法内部,
self就表示当前调用方法的对象自己 -
调用方法时,程序员不需要传递
self参数 -
在放啊内部
- 可以通过
self.访问对象的属性 - 也可以通过
self.调用其他的对象方法
- 可以通过
-
改造代码如下:
class Cat:
"""这是一个猫类"""
def eat(self):
# 哪一个对象调用方法,self 就是哪一个对象的引用
print("%s 爱吃鱼" % self.name)
def drink(self):
print("%s 要喝水" % self.name)
# 创建猫对象
tom = Cat()
# 可以使用 .属性名,通过赋值语句就可以了
tom.name = "Tom"
tom.eat()
tom.drink()
# 再创建一个猫对象
jerry = Cat()
jerry.name = "大懒猫"
jerry.eat()
jerry.drink()
"""
Tom 爱吃鱼
Tom 要喝水
大懒猫 爱吃鱼
大懒猫 要喝水
"""
05. dir内置函数
- 在 Python 中对象几乎是无处不在的,之前学习的变量、数据、函数都是对象
- 在 Python 中可以使用以下两个方法验证:
- 在标识符/数据后输入一个
.,然后按下Tab键,iPython会提示改对象能够调用的方法列表 - 使用内置函数
dir传入标识符/数据,可以查看对象内的所有属性及方法
- 在标识符/数据后输入一个
提示:
__方法名__格式的方法是Python提供的内置方法/属性
| 序号 | 方法名 | 类型 | 作用 |
|---|---|---|---|
| 01 | __new__ | 方法 | 创建对象时,会被自动调用 |
| 02 | __init__ | 方法 | 对象被初始化时,会被自动调用 |
| 03 | __del__ | 方法 | 对象被从内存中销毁前,会被自动调用 |
| 04 | __str__ | 方法 | 返回对象的描述信息,print 函数输出使用 |
06.构造方法
- 当使用类名()创建对象时,会自动执行以下操作:
- 为对象在内存中分配空间 – 创建对象
- 为对象的属性设置初始值 – 初始化方法(
init)
- 这个初始化方法就是
__init__方法,是对象的内置方法
__init__方法是专门用来定义一个类具有哪些属性的方法
__init__——构造方法- 在创建类对象的时候,会自动执行
- 在创建类对象的时候,将参数自动传递给
__init__方法使用
01.在初始化方法内部定义属性
- 在
__init__方法内部使用self.属性名 = 属性的初始值就可以定义属性 - 定义属性之后,再使用
Cat类创建的对象,都会拥有该属性
class Cat:
"""这是一个猫类"""
def __init__(self):
print("调用初始化方法")
self.name = "Tom"
def eat(self):
print("%s 爱吃鱼" % self.name)
# 使用类名()创建对象时,会自动调用初始化方法 __init__
tom = Cat()
print(tom.name)
tom.eat()
"""
Tom
Tom 爱吃鱼
"""
02. 初始化的同时设置初始值
- 在开发中,如果希望在创建对象的同时,就设置对象的属性,可以
__init__方法进行改造- 把希望设置的属性值,定义成
__init__方法的参数 - 在方法内部使用
self.属性 = 形参接收外部传递的参数 - 在创建对象时,使用
类名(属性1,属性2,...)调用
- 把希望设置的属性值,定义成
class Cat:
"""这是一个猫类"""
def __init__(self, name):
print("调用初始化方法")
self.name = name
def eat(self):
print("%s 爱吃鱼" % self.name)
# 使用类名()创建对象时,会自动调用初始化方法 __init__
tom = Cat("Tom")
print(tom.name)
tom.eat()
snow = Cat("Snow")
snow.eat()
"""
调用初始化方法
Tom
Tom 爱吃鱼
调用初始化方法
Snow 爱吃鱼
"""
07.__del__方法
- 在 Python 中
- 当使用
类名()创建对象时,为对象分配空间后,自动调用__init__方法 - 当一个对象被从内存中销魂前,会自动调用
__del__方法
- 当使用
- 应用场景
__init__改造初始化方法,可以让创建对象更加灵活__del__如果希望在对象被销魂前,再做一些事情,可以考虑使用该方法
- 生命周期
- 一个对象从调用
类名()创建,生命周期开始 - 一个对象的
__del__方法一旦被调用,生命周期结束 - 在对象的生命周期内,可以访问对象属性,或者让对象调用方法
- 一个对象从调用
08.其他常用内置方法——魔术方法
1``str`字符串方法
- 通过
__str__方法,控制类转换为字符串行为 - 在 Python 中,使用print输出对象变量,默认情况下,会输出这个变量引用的对象是由哪一个类创建的对象,以及在内存中的地址(十六进制表示)
- 如果在开发中,希望使用
print输出对象变量时,能够打印自定义的内容,就可以利用__str__这个内置方法
- 如果在开发中,希望使用
注意:
__str__方法必须返回一个字符串
class Cat:
def __init__(self, name):
self.name = name
print("%s 来了" % self.name)
def __del__(self):
print("%s 走了" % self.name)
#def __str__(self):
# 必须返回一个字符串
#return "我是小猫[%s]" % self.name
# tom 是一个全局变量,在程序执行结束时内存被释放
tom = Cat("Tom")
print(tom)
"""
Tom 来了
<__main__.Cat object at 0x00000226E25E5940>
Tom 走了
"""
class Cat:
def __init__(self, name):
self.name = name
print("%s 来了" % self.name)
def __del__(self):
print("%s 走了" % self.name)
def __str__(self):
# 必须返回一个字符串
return "我是小猫[%s]" % self.name
# tom 是一个全局变量,在程序执行结束时内存被释放
tom = Cat("Tom")
print(tom)
"""
output:
Tom 来了
我是小猫[Tom]
Tom 走了
"""
2``lt`小于符号比较方法
- 相当于c++中的比较符号重载
- 直接对两个对象进行比较是不可以的,但是类中实现
__it__,即可同时完成 小于符号 和 大于符号 2种比较
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __lt__(self, other):
return self.age<other.age
#传入参数:other,另一个对象
#返回值:True或False
stu1=Student("zcx",17)
stu2=Student("xdb",18)
print(stu1<stu2)
print(stu1>stu2)
"""
output:
True
False
"""
3``le`小于等于符号比较
- 内容几乎同
__lt__
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __le__(self, other):
return self.age<other.age
#传入参数:other,另一个对象
#返回值:True或False
stu1=Student("zcx",17)
stu2=Student("xdb",17)
print(stu1<stu2)
print(stu1>stu2)
"""
output:
True
True
"""
4``eq`等于符号比较
- 同上
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __le__(self, other):
return self.age==other.age
#传入参数:other,另一个对象
#返回值:True或False
stu1=Student("zcx",17)
stu2=Student("xdb",17)
print(stu1==stu2)
"""
output:
True
"""
5.封装
01.封装的概念
- 封装是面向对象编程的一大特点
- 面向对象编程的第一步–将属性和方法封装到一个抽象的类中
- 外界使用类创建对象,然后让对象调用方法
- 对象方法的细节都被封装在类的内部
02.私有成员
- 类内不公开的属性和行为
- 私有方法无法直接被类的对象使用,但是可以被其他的成员使用
- 私有变量无法赋值,也无法获取值
-
私有成员变量
- 变量以__开头(两个下划线)
-
私有成员方法
- 变量以__开头(两个下划线)
class Phone:
__current_voltage = None
def __keep_single_core(self): #
print("让CPU以单核模式运行")
phone =Phone()
phone.__keep_single_core()
"""
Traceback (most recent call last):
File "D:\KING的python\pythonProject1\test01.py", line 8, in <module>
phone.__keep_single_core()
AttributeError: 'Phone' object has no attribute '__keep_single_core'
"""
- 私有方法无法直接被类的对象使用,但是可以被其他的成员使用的具体案例
class Phone:
__current_voltage =0.5
def __keep_single_core(self): #构建私有成员方法
print("让CPU以单核模式运行")
def call_by_5g(self):
if self.__current_voltage>=1:
print("5g通话开启")
else:
self.__keep_single_core()
print("电量不足,无法使用5g通话,并已经设置为单核运行进行省电")
phone =Phone()
phone.call_by_5g()
"""
让CPU以单核模式运行
电量不足,无法使用5g通话,并已经设置为单核运行进行省电
"""
6.继承
- 实现代码的重用,相同的代码不需要重复的编写
01.概念
- 子类拥有父类的所有方法和属性
[
02.单继承语法
class 类名(父类名):
#添加新内容
#不添加内容使用pass
- 子类继承自父类,可以直接享受父类中已经封装好的方法,不需要再次开发
- 子类中应该根据职责,封装子类特有的属性和方法
- 专业术语
Dog类是Animal类的子类,Animal类是Dog类的父类,Dog类从Animal类继承Dog类是Animal类的派生类,Animal类是Dog类的基类,Dog类从Animal类派生
- 继承的传递性
C类从B类继承,B类又从A类继承- 那么
C类就具有B类和A类的所有属性和方法
子类拥有父类以及父类的父类中封装的所有属性和方法
class Phone:
ID=None
producer="K"
def call_by_4g(self):
print("4g通话")
class Phone2024(Phone):
face_id="10001" #面部识别id
def call_by_5g(self):
print("新功能5g通话")
phone=Phone2024()
print(phone.producer)
phone.call_by_4g()
phone.call_by_5g()
"""
K
4g通话
新功能5g通话
"""
03.多继承
1`概念
- 子类可以拥有多个父类,并且具有所有父类的属性和方法
- 例如:孩子会继承自己父亲和母亲的特性
[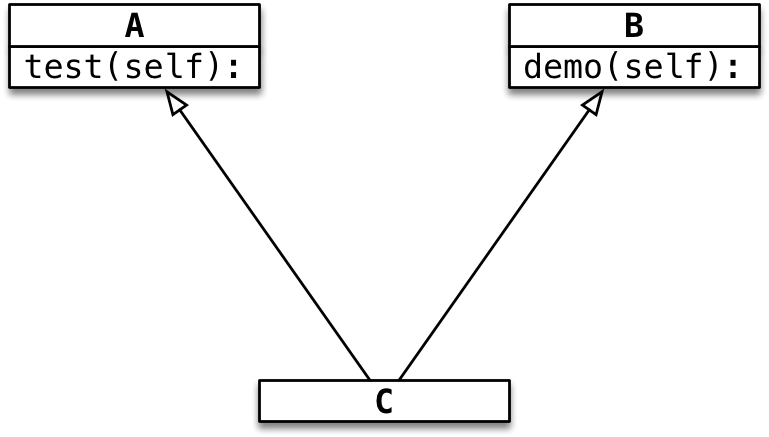 ]
]
2`语法
class 子类名(父类名1,父类名2...):
#添加新内容
#不添加内容使用pass
class A:
def test(self):
print("test 方法")
class B:
def demo(self):
print("demo 方法")
class C(A, B):
"""多继承可以让子类对象,同时具有多个父类的属性和方法"""
pass
# 创建子类对象
c = C()
c.test()
c.demo()
class Phone:
ID=None
producer="K"
def call_by_4g(self):
print("4g通话")
class NFReader:
nfc_type="第五代"
producer="K"
def read_card(self):
print("NFC读卡")
def write_card(self):
print("NFC写卡")
class RemoteControl:
rc_type="红外遥控"
def control(self):
print("红外遥控开启了")
class MyPhone(Phone,NFReader,RemoteControl):
pass
phone=MyPhone()
phone.call_by_4g()
phone.read_card()
phone.write_card()
phone.control()
"""
4g通话
NFC读卡
NFC写卡
红外遥控开启了
"""
3` 多继承的使用注意事项
问题的提出
- 如果不同的类中存在同名的方法,子类对象在调用方法时,会调用哪一个父类中的方法?
提示:开发时,应该尽量避免这种容易产生混淆的情况!–如果父类之间存在同名的属性或者方法,应该尽量避免使用多继承
[ ]
]
Python 中的 MRO – 方法搜搜索顺序
- Python 中针对类提供了一个内置属性
__mro__可以查看方法搜索顺序 - MRO 是
method resolution order,主要用于在多继承时判断方法、属性的调用路径
print(C.__mro__)
# 输出结果
(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>)
- 在搜索方法时 ,是按照
__mro__的输出结果从左至右的顺序查找的 - 如果在当前类中找到方法,就直接执行,不再搜索
- 如果没有找到,就查下一个类中是否有对应的方法,如果找到,就直接执行,不再搜索
- 如果找到最后一个类,还没有找到方法,程序报错
4`.复写
- 子类拥有父类的所有方法和属性
- 子类继承自父类,可以直接享受父类中已经封装好的方法,不需要再次开发
应用场景
- 当父类的方法实现不能满足子类需求时,可以对方法进行复写(override)
[
- 重写父类方法有两种情况:
- 覆盖父类的方法
- 对父类方法进行扩展
- 覆盖父类的方法
- 如果在开发中,父类的方法实现和子类的方法实现,完全不同
- 就可以使用覆盖的方式,在子类中重新编写父类的方法实现
- 重写之后,再运行时,只会调用子类中重写的放啊,而不再调用父类封装的方法
具体的实现方式,就相当于在子类中定义了一个和父类同名的方法并且实现
class Phone:
ID=None
producer="K"
def call_by_5g(self):
print("父类5g通话")
class Phone2024(Phone):
producer = "Q"
face_id="10001" #面部识别id
def call_by_5g(self):
print("新功能5g通话")
phone=Phone2024()
print(phone.producer)
phone.call_by_5g()
"""
output:
Q
新功能5g通话
"""
5`.复写后再使用父类成员
- 对父类方法进行扩展
- 如果在开发中,子类的方法实现中包含父类的方法实现
- 父类原本封装的方法实现是子类方法的一部分
- 就可以使用扩展的方式
- 在子类中重写父类的方法
- 在需要的位置使用
super().父类方法来调用父类方法的执行 - 代码其他的位置针对子类的需求,编写子类特有的代码实现
关于 super
- 在
Python中super是一个特殊的类 super()就是使用super类创建出来的对象- 最常使用的场景就是在复写父类方法时,调用在父类中封装的方法实现
调用父类方法的另一种方式
在
Python 2.x时,如果需要调用父类的方法,还可以使用以下方式:
父类名.方法(self)
- 这种方式,目前在
Python 3.x还支持 - 不推荐使用,因为一旦父类发生变化,方法调用位置的类名同样需要修改
提示
- 在开发时,
父类名和super()两种方式不要混用 - 如果使用当前子类名调用方式,会形成递归掉调用,出现死循环
class Phone:
ID=None
producer="K"
def call_by_5g(self):
print("父类5g通话")
class Phone2024(Phone):
producer = "Q"
face_id="10001" #面部识别id
def call_by_5g(self):
print("新功能5g通话")
#方式1
#print(f"父类的厂商是:{Phone.producer}")
#Phone.call_by_5g(self)
#方式2
print(f"父类的厂商是:{super().producer}")
super().call_by_5g()
phone=Phone2024()
print(phone.producer)
phone.call_by_5g()
"""
output:
Q
新功能5g通话
父类的厂商是:K
父类5g通话
"""
7.多态
01.概念
- 不同的子类对象调用相同的父类方法,产生不同的执行结果
- 多态可以增加代码的灵活度
- 以继承和重写父类方法为前提
- 是调用方法的技巧,不会影响到类的内部设计
[ ]
]
02.抽象类
- 父类的方法的实现是空实现,具体方法有子类自行决定,此种写法就叫做抽象类(也叫做接口)
- 抽象方法:方法体是空实现(pass)称之为抽象方法
class Dog(object):
def __init__(self, name) -> None:
self.name = name
def game(self):
print("%s 蹦蹦跳跳地玩耍..." % self.name)
class XiaoTianDog(Dog):
def game(self):
print("%s 飞到天上玩耍..." % self.name)
class Person(object):
def __init__(self, name) -> None:
self.name = name
def game_with_dog(self, dog: Dog):
print("%s 和 %s 快乐地玩耍..." % (self.name, dog.name))
# 让狗玩耍
dog.game()
# 1.创建 狗 对象
wangcai1 = Dog("旺财")
wangcai2 = XiaoTianDog("飞天旺财")
# 2.创建一个 小明 对象
xiaoming = Person("小明")
# 3.让小明调用和狗玩的方法
xiaoming.game_with_dog(wangcai1)
print("----------------------")
xiaoming.game_with_dog(wangcai2)
"""
output:
小明 和 旺财 快乐地玩耍...
旺财 蹦蹦跳跳地玩耍...
----------------------
小明 和 飞天旺财 快乐地玩耍...
飞天旺财 飞到天上玩耍...
"""
十二、注释拓展
1.变量注释
01.语法
- 方法1
变量:类型
-
在容器类型的详细注释中
-
元组类型设置类型详细注解,需要将每一个元素都标记出来
-
字典类型设置类型详细注解,需要两个类型,第一个是key第二个是value
-
-
方法2——在注释中进行类型注解
# type:类型 -
一般,无法直接看出变量类型只是,会添加变量的类型注解
02.功能
- 帮助第三方IDE工具(如pycharm)对代码进行类型推断,协助作代码提示
- 帮助开发者自身对变量进行类型注释
- 它并不会真正的对类型做验证和判断,也就是说类型注释仅仅是提示性的,不是决定性的
#基础数据类型注释
import random
v1:int =10
v2:str="慊慊为汝"
v3:bool=True
#类对象类型注释
class Student:
pass
stu:Student=Student()
#基础容器类型注释
my_list:list=[1,2,3]
my_tuple:tuple=(1,2,3)
my_dict:dict={"xdb":666}
#容器类型详细注释
mylist: list[int] = [1, 2, 3]
mytuple: tuple[int, str, bool] = (1, "xdb", True)
mydict: dict[str, int] = {"xdb": 666}
#在注释中进行类型注释
v4=random.randint(1,10) #type:int
def func():
return 10
v5=func() #type:intb
2.函数和方法的类型注解
01.语法
1.对形参进行类型注解
def 函数方法名(形参名:类型,形参名:类型,..)
pass
2.对返回值进行类型注解
def 函数方法名(形参:类型,...,形参:类型)->返回值类型:
pass
#对形参进行类型注解
def add(x:int,y:int):
return x+y
# add()
#对返回值进行类型注解
def func(data:list)->list:
return data
3.Union类型
- 表示一种联合类型
from typing import Union
- Union使用前要先调用上一段代码
from typing import Union
my_list:list[Union(int,str)]=[1,2,"K","Q"]
def func(data:Union[int,str])->Union[int,str]:
pass
十三、基础SQL
1.数据库简介
- 组织形式:库->表->数据
- 数据库软件提供数据组织存储能力,SQL语句则是操作数据,数据库的工作语言
2.SQL语法特征
- SQL语言,大小写不敏感
- SQL可以单行或多行书写,最后以;结尾
- SQL支持注释:
- 单行注释:–注释内容(–后面一定要有一个空格)
- 单行注释:#注释内容(#后面可以不加空格,推荐加上)
- 多行注释:/*注释内容 */
3.DDL数据定义
-
查看数据库
show databases; -
使用数据库
use 数据库名称 -
创建数据库
CREATE DATABASE 数据库名称 CHARACTER SET utf8; -
删除数据库
drop database 数据库名称 -
查看当前使用的数据库
select database(); -
查看有哪些表
show tables;- 注:需要先选择数据库
-
删除表
drop table 表名称drop table if exists 表名称 -
创建表
create table 表名称( 列名称 列类型, 列名称,列类型, ...... );-- 列类型: int -- 整数 float --浮点数 varchar -- 文本,长度为数字,做最大长度限制 date -- 日期类型 timestamp -- 时间戳类型create table student( id int, name varchar(10), age int );
3.DML数据操作
-
数据插入 INSERT
insert into 表[(列1,列2,...,列N)]values(值1,值2,...值N),(值1,值2,......,值N),......,(值1,值2,......,值N); -
数据删除 DELETE
delete from 表名称 where 条件判断-- 条件判断:列 操作符 值 操作符:= < > <= >= != 等等- 例子:
delete from student where id=1;3.数据更新 UPDATE
update 表名 set 列=值 where 条件判断-- 条件判断:列 操作符 值 操作符:= < > <= >= != 等等update student set name ='ddb' where id=5
4.DQL数据查询
01.基础数据查询
select 字段列表或* from 表
- 从表中,选择某些列进行展示
- *号代表查询所有的列
02.分组聚合
select 字段 或 聚合函数 from where 条件 group by 列
- 聚合函数:
- sum(列) 求和
- avg(列) 求平均值
- min(列) 求最小值
- max(列) 求最大值
- count(列) 求数量
select gender,avg(age),sum(age),min(age),from student group by gender
03.排序分页
select 列 或 聚合函数 或 * from 表
where ...(判断条件)
group by ...(按照哪一列)
order by ...(按照哪一列) asc(升序排列)|desc(降序排列)
limit n,m (n是跳过几条,m是取几条)
5.python & mysql
01.基础使用
- 如何获取链接对象?
- from pymysql import Connection 导包
- Connection(主机,端口,账户,密码)即可得到链接对象
链接对象.close()关闭和MySQL数据库的连接
- 3.如何执行SOL查询
- 通过连接对象调用cursor()方法,得到游标对象
- 游标对象.execute()执行SQL语句
游标对象.fetchall()将查询结果封装进元组内
- 通过连接对象调用cursor()方法,得到游标对象
from pymysql import Connection
#构建mysql数据库链接
conn=Connection(
host="localhost", #主机名
port=3306, #端口
user="root", #账户
password="123456" #密码
)
print(conn.get_server_info())
#执行非查询性质SQL
cursor=conn.cursor() #获取游标对象
#选择数据库
conn.select_db("world")#先选择数据库
#使用游标对象,执行sql查询
#cursor.execute("create table test_pymysql(id int);") 创建一个表
cursor.execute("select * from student")#提取所有列
results=cursor.fetchall()#获取的结果是双层嵌套元组
# print(results)
for r in results:
print(r)
#关闭链接
conn.close()
"""
output:
8.0.36
(10001, '周杰轮', 31, '男')
(10002, '王力鸿', 33, '男')
(10003, '蔡依琳', 35, '女')
(10004, '林志灵', 36, '女')
(10005, '刘德滑', 33, '男')
(10006, '张大山', 10, '男')
(10007, '刘志龙', 11, '男')
(10008, '王潇潇', 33, '女')
(10009, '张一梅', 20, '女')
(10010, '王一倩', 13, '女')
(10011, '陈一迅', 31, '男')
(10012, '张晓光', 33, '男')
(10013, '李大晓', 15, '男')
(10014, '吕甜甜', 36, '女')
(10015, '曾悦悦', 31, '女')
(10016, '刘佳慧', 21, '女')
(10017, '项羽凡', 23, '男')
(10018, '刘德强', 26, '男')
(10019, '王强强', 11, '男')
(10020, '林志慧', 25, '女')
"""
02.数据插入
- pymysql在执行数据插入或其他产生数据更改的SQL语句时,默认是需要提交更改的,即需要通过代码“确认”这种更改行为
- 通过链接对象.commit()即可确认这种行为或者在构建mysql数据库链接时添加
autocommit=True设置为自动确认
from pymysql import Connection
#构建mysql数据库链接
conn=Connection(
host="localhost", #主机名
port=3306, #端口
user="root", #账户
password="123456",#密码
autocommit=True #自动确认
)
print(conn.get_server_info())
#执行非查询性质SQL
cursor=conn.cursor() #获取游标对象
#选择数据库
conn.select_db("world")#先选择数据库
#使用游标对象,执行sql
#cursor.execute("create table test_pymysql(id int);") 创建一个表
cursor.execute("insert into student values(10021,'xdb',17,'女')")#提取所有列
#通过commit确认
#conn.commit()
#关闭链接
conn.close()
十四、PySpark入门
- PySpark是Spark的Python实现,是Spark为Python开发者提供的编程入口,用于以Python代码完成Spark任务的开发
- PySpark不仅可以作为Python第三方库使用,也可以将程序提交的Spark集群环境中,调度大规模集群进行执行。
1.构建PySpark执行环境入口对象
- 想要使用PySpark库完成数据处理,首先需要先构建一个执行环境如露对象。
- PySpark的执行环境入口对象是:类 SparkContext 的类对象
#导包
from pyspark import SparkConf,SparkContext
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_saprk_app")
#基于SparkConf类对象创建SparkContext类对象
sc=SparkContext(conf=conf)
#打印PySpark的运行版本
#print(sc.version)
#停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
2.PySpark数据输入
- Pyspark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象(RDD全称:弹性分布式数据集)
- PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD中
- 各类数据的计算方法也都是RDD方法
- RDD的数据计算方法返回值依旧是RDD对象
1.通过parallelize方法将python对象加载到Spark内,成为RDD对象
-
如果要查看RDD里面有什么内容,需要用**
collect()方法**#导包 from pyspark import SparkConf,SparkContext #创建SparkConf类对象 conf=SparkConf().setMaster("local[*]").setAppName("test_saprk_app") #基于SparkConf类对象创建SparkContext类对象 sc=SparkContext(conf=conf) #通过parallelize方法将python对象加载到Spark内,成为RDD对象 rdd1=sc.parallelize([1,2,3,4,5])#列表 rdd2=sc.parallelize((1,2,3,4,5))#元组 rdd3=sc.parallelize("abcdefg") #字符串 rdd4=sc.parallelize({1,2,3,4,5})#集合 rdd5=sc.parallelize({"key1":"value1","key2":"value"})#字典 #如果要查看RDD里面有什么内容,需要用collect()方法 print(rdd1.collect()) print(rdd2.collect()) print(rdd3.collect()) print(rdd4.collect()) print(rdd5.collect()) sc.stop() """ output: [1, 2, 3, 4, 5] [1, 2, 3, 4, 5] ['a', 'b', 'c', 'd', 'e', 'f', 'g'] [1, 2, 3, 4, 5] ['key1', 'key2'] """
2.读取文件转RDD对象——通过textFile方法,读取文件数据加载到Spark内,成为RDD对象
-
PySpark也支持通过
SparkContext入口对象,来读取文件,来构建出RDD对象#导包 from pyspark import SparkConf,SparkContext #创建SparkConf类对象 conf=SparkConf().setMaster("local[*]").setAppName("test_saprk_app") #基于SparkConf类对象创建SparkContext类对象 sc=SparkContext(conf=conf) #通过textFile方法,读取文件数据加载到Spark内,成为RDD对象 rdd=sc.textFile("D:\KING的python\pythonProject1\测试.txt") print(rdd.collect()) """ output: ['爱意随风起,风止意难平', '慊慊为汝', '慊慊为汝', '慊慊为汝', '慊慊为汝', '慊慊为汝', '慊慊为汝', '慊慊为汝', '慊慊为汝', '慊慊为汝', '慊慊为汝'] """
3.数据计算
01.map方法
- map算子,是将RDD的数据一条条处理(处理逻辑 基于map算子中接受的处理函数),返回新的RDD
1`语法
rdd.map(func)
# func : f:(T) ->U
# f: 表示这是一个函数(方法)
# (T) -> U 表示的是方法的定义:
# () 表示的是传入参数,(T)表示传入一个参数, () 表示没有传入参数
# T 是泛型的代称,在这里表示 任意类型
# U 也是泛型代称,在这里表示,任意类型
# -> U 表示返回值
# (T) -> U 总结起来的意思是:这是一个方法,这个方法接受一个参数传入,传入类型不限,返回一个返回值,返回类型不限
# (A) -> A 总结起来的意思是:这是一个方法,这个方法接受一个参数传入,传入类型不限,返回一个返回值,返回类型不限,返回值和传入参数类型一致
#导包
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="king D:\anaconda\envs\king\python.exe"
#创建SparkConf类对象
conf=SparkConf().setMaster("local[*]").setAppName("test_saprk_app")
#基于SparkConf类对象创建SparkContext类对象
sc=SparkContext(conf=conf)
#准备一个RDD
rdd =sc.parallelize([1,2,3,4,5])
#通过map方法得到全部的数据库都乘以10
def func(data):
return data*10
rdd2=rdd.map(func)
print(rdd2.collect())
02.flatmap算子
-
对RDD执行map操作,然后进行解除嵌套操作
-
计算逻辑与map一致,比map多一个解除嵌套的作用
# 嵌套的list lst = [[1,2,3],[4,5,6],[7,8,9]] # 解除嵌套 lst = [1,2,3,4,5,6,7,8,9]#导包 from pyspark import SparkConf,SparkContext import os os.environ['PYSPARK_PYTHON']="king D:\anaconda\envs\king\python.exe" #创建SparkConf类对象 conf=SparkConf().setMaster("local[*]").setAppName("test_saprk_app") #基于SparkConf类对象创建SparkContext类对象 sc=SparkContext(conf=conf) #准备一个RDD rdd =sc.parallelize(["xdb h","ddb m","xxx s","xtj d"]) #将rdd数据里面的一个个单词提取出来 rdd2 = rdd.flatMap(lambda x:x.spilt(" ")) print(rdd2.collect()) """ output: ['xdb','h','ddb','m','xxx','s','stj','d'] """
03.reduceByKey算子
- 针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
- KV型RDD就是存储的是二元元组(第一个是key,第二个是value)
rdd.reduceByKey(func)
#func:(v,v) -> v
#接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致
rdd = sc.parallelize([('a',1),('a',1),('b',1),('b',1),('b',1)])
result = rdd.reduceByKey(lambda a,b:a+b)
print(result.collect())
"""
output:
[('b',3),('a',2)]
"""
- 先是根据key分组,再把value两两传入
04.filter算子
-
过滤掉想要的数据进行保留
rdd.filter(func) # func:(T) -> bool 传入1个参数进来随意类型,返回值必须是True or False返回值是True的数据被保留,False的数据被丢弃
05.distinct算子
-
对RDD数据进行去重,返回新的RDD
rdd.distinct() 无需传参
06.sorBy算子
- 对RDD数据进行排序,基于你指定的排序顺序
rdd.sortBy(func.ascending=False,numPartition=1)
#func:(T) -> U:告知按照rdd中的哪个数据进行排序,比如 lambda x:x[1] 表示按照rdd中的第二列元素进行排序
# ascending True升序 False 降序
# numPartition:用多少分区排序
十五、高阶技巧
1.闭包
- 在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数成为闭包
01.简单闭包
02.在内部函数修改外部函数变量的值
- 需要使用nonlocal关键字修饰外部函数的变量才可以在内部函数中修改它
def outer(num1):
def inner(num2):
nonlocal num1num1 += num2print(num1)
return inner
fn = outer(10)
fn(10)
#output: 20
def account_create(in1tial_amount=0)
def atm(num, deposit=True):
nonlocal initial_amount
if deposit:
initial_amount += num
print(f"存款:+{num},账户余额{initial_amount}")
else:
initial_amount -= num
print(f"取款:-{num},账户余额:{initial_amount}")
return atm
fn = account_create()
fn(300)
fn(200)
fn(300,False)
"""
output:
存款:+300,账户余额:300
存款:+200,账户余额:500
取款:-300,账户余额:200
"""
03.优缺点
- 优点:使用闭包可以让我们得到:无需定义全局变量即可实现通过函数,持续的访问、修改某个值闭包使用的变量的所用于在函数内,难以被错误的调用修改
- 由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用内存
2.装饰器
-
装饰器其实也是一种闭包,其功能就是在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能
-
定义一个闭包函数,在闭包函数内部:
- 执行目标函数
- 并完成功能的添加
3.多线程
01.进程,线程,并行执行
- 进程:就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程ID方便系统管理
- 线程:线程是归属于进程的,一个进程可以开启多个进程,执行不同的工作,是进程的实际工作最小单位
- 注意:
- 进程之间是内存隔离的,即不同的进程拥有各自的内存空间。这就类似于不同的公司拥有不同的办公场所。
- 线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的文就好比,公司员工之间是共享公司的办公场所。
02.多线程编程
- python的多线程编程可以通过threading模块来实现
import threading
thread_obj = threading.Thread([group [, target [, name [, args [, kwargs]]]]])group:暂时无用,未来功能的预留参数
- target:执行的目标任务名
- args:以元组的方式给执行任务传参
- kwargs:以字典方式给执行任务传参
- name:线程名,一般不用设置
#启动线程,让线程开始工作
thread_obj.start()
#演示多线程编程的使用
import time
import threading
def sing():
while True:
print("我在唱歌,啦啦啦..")
time.sleep(1)
def dance():
while True:
print("我在跳舞,畖呱...")
time.sleep(1)
if--name_- =='-_main--':
# 创建一个唱歌的线程
sing_thread =threading.Thread(target=sing)
# 创建一个跳舞的线程
dance_thread =threading.Thread(target=dance)
# 让线程去于活吧
sing_thread.start()
dance_thread.start()
4.正则表达式
- 正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。
- 简单来说,正则表达式就是使用:字符串定义规则,并通过规则去验证字符串是否匹配。比如,验证一个字符串是否是符合条件的电子邮箱地址,只需要配置好正则规则,即可匹配任意邮箱。比如通过正则规则:(1+(.[\w-]+)*@[\w-]+(.[w-]+)+$)即可匹配一个字符串是否是标准邮箱格式
- 但如果不使用正则,使用if,else来对字符串做判断就非常困难了
01.使用re模块做正则匹配
1``re.match(匹配规则,被匹配字符串)`
-
从被匹配字符串开头进行匹配,匹配成功后返回匹配对象(包含匹配信息),匹配不成功,返回空(就是开头直接匹配,若不匹配向后直接不匹配)
s ='python itheima python itheima python itheima' result = re.match('python', s) print(result)#<re.Match object;span=(0,6),match='python'> print(result.span())#(0,6)表示匹配成功,下标由0,6 print(result.group())#python s ='1python itheima python itheima python itheima' result =re.match('python',s) print(result)#None
2``re.search(匹配规则,被匹配字符串)`
-
搜索整个字符串,找出匹配的。从前向后,找到第一个后,就停止,不会继续向后
s ='1python666itheima666python666' result = re.search('pytHon',s) print(result)#<re.Match object;span=(1,7),match='python'> print(result.span())#(1,7) print(result.group())# python 整个字符串都找不到,返回None s ='itheima666' result =re.search('python',s) print(result)# None
3``findall(匹配规则,被匹配字符串)`
- 匹配整个字符串,找出全部匹配项
s =1python666itheima666python666
result = re.findall('python's )
print(result)#['python''python'
找不到返回空list:[]
s =1python666itheima666python666result = re.findall('itcast', s)print(result)#[]
02.元字符匹配
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,‘n’ 匹配字符 “n”。‘\n’ 匹配一个换行符。序列 ‘\’ 匹配 “” 而 “(” 则匹配 “(”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,‘o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像"(.|\n)"的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘(’ 或 ‘)’。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"`(?<=95 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"`(?<!95 |
| x|y | 匹配 x 或 y。例如,‘z|food’ 能匹配 “z” 或 “food”。‘(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,‘[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,‘[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,‘\x41’ 匹配 “A”。‘\x041’ 则等价于 ‘\x04’ & “1”。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,‘(.)\1’ 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
#匹配账号,只能由字母和数字组成,长度限制6到10位
r=^[0-9a-zA-Z]{6,10}$
s=123456_
print(re.findall(r,s))
#匹配QQ号,要求纯数字,长度5-11,第一位不为0
r=^[1-9][0-9]{4,10}$'
s=123453678
print(re.findall(r,s))
#匹配邮箱地址,只允许99、163、gmail这三种邮箱地址
# abc.efg.dawqq.com.cn.eu.qq.aa.cc
# abcgq.com
#{内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}.{内容}@{内容}.{内容}.{内容}
r=r'^[\w-]+(\.[\w-]+)*@(991163lgmail)(\.[\w-]+)+$'
s='a.b.c.d.e.f.ggq.com.a.z.c.d.e'
print(re.findall(r,s))
5.os标准库
1. 简介
os就是“operating system”的缩写,顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口。通过使用os模块,一方面可以方便地与操作系统进行交互,另一方面也可以极大增强代码的可移植性。如果该模块中相关功能出错,会抛出OSError异常或其子类异常。
注意,如果是读写文件的话,建议使用内置函数
open();如果是路径相关的操作,建议使用os的子模块os.path;如果要逐行读取多个文件,建议使用fileinput模块;要创建临时文件或路径,建议使用tempfile模块;要进行更高级的文件和路径操作则应当使用shutil模块。
当然,使用os模块可以写出操作系统无关的代码并不意味着os无法调用一些特定系统的扩展功能,但要切记一点:一旦这样做就会极大损害代码的可移植性。
此外,导入os模块时还要小心一点,千万不要为了图调用省事儿而将os模块解包导入,即不要使用from os import *来导入os模块;否则os.open()将会覆盖内置函数open(),从而造成预料之外的错误。
2. 常用功能
注意,
os模块中大多数接受路径作为参数的函数也可以接受“文件描述符”作为参数。
文件描述符:file descriptor,在 Python 文档中简记为 fd,是一个与某个打开的文件对象绑定的整数,可以理解为该文件在系统中的编号。
2.1 os.name
该属性宽泛地指明了当前 Python 运行所在的环境,实际上是导入的操作系统相关模块的名称。这个名称也决定了模块中哪些功能是可用的,哪些是没有相应实现的。
目前有效名称为以下三个:posix,nt,java。
其中posix是 Portable Operating System Interface of UNIX(可移植操作系统接口)的缩写。Linux 和 Mac OS 均会返回该值;nt全称应为“Microsoft Windows NT”,大体可以等同于 Windows 操作系统,因此 Windows 环境下会返回该值;java则是 Java 虚拟机环境下的返回值。
因此在我的电脑(win10)上执行下述代码,返回值是nt:
>>> import os
>>> os.name
'nt'
而在 WSL(Windows Subsystem Linux,Windows 下的 Linux 子系统)上的结果则是:
>>> import os
>>> os.name
'posix'
查看
sys模块中的sys.platform属性可以得到关于运行平台更详细的信息,在此不再赘述
2.2 os.environ
os.environ属性可以返回环境相关的信息,主要是各类环境变量。返回值是一个映射(类似字典类型),具体的值为第一次导入os模块时的快照;其中的各个键值对,键是环境变量名,值则是环境变量对应的值。在第一次导入os模块之后,除非直接修改os.environ的值,否则该属性的值不再发生变化。
比如其中键为“HOMEPATH”(Windows 下,Linux 下为“HOME”)的项,对应的值就是用户主目录的路径。Windows 下,其值为:
>>> os.environ["HOMEPATH"]
'd:\\justdopython'
Linux 下,其值为:
os.environ[“HOME”]
‘/home/justdopython’
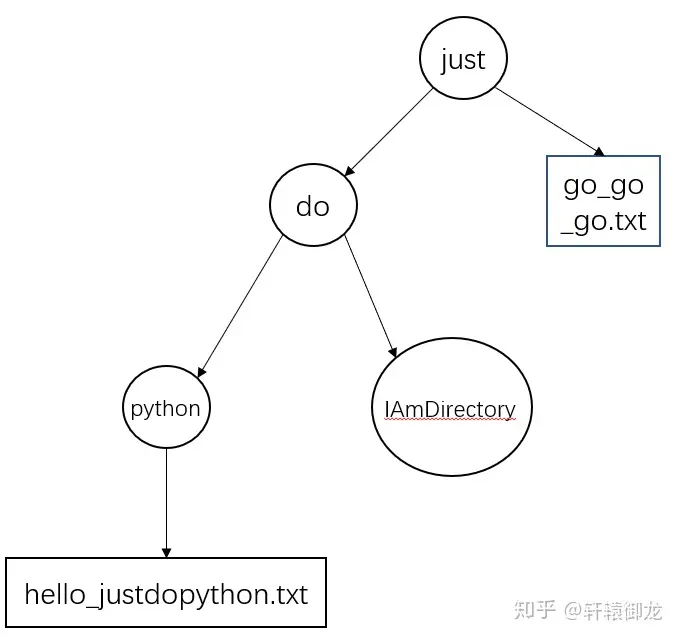
2.3 os.walk()
这个函数需要传入一个路径作为top参数,函数的作用是在以top为根节点的目录树中游走,对树中的每个目录生成一个由(dirpath, dirnames, filenames)三项组成的三元组。
其中,dirpath是一个指示这个目录路径的字符串,dirnames是一个dirpath下子目录名(除去“.”和“..”)组成的列表,filenames则是由dirpath下所有非目录的文件名组成的列表。要注意的是,这些名称并不包含所在路径本身,要获取dirpath下某个文件或路径从top目录开始的完整路径,需要使用os.path.join(dirpath, name)。
注意最终返回的结果是一个迭代器,我们可以使用for语句逐个取得迭代器的每一项:
>>> for item in os.walk("."):
... print(item)
...
('.', ['do'], ['go_go_go.txt'])
('.\\do', ['IAmDirectory', 'python'], [])
('.\\do\\IAmDirectory', [], [])
('.\\do\\python', [], ['hello_justdopython.txt'])
2.4 os.listdir()
“listdir”即“list directories”,列出(当前)目录下的全部路径(及文件)。该函数存在一个参数,用以指定要列出子目录的路径,默认为“.”,即“当前路径”。
函数返回值是一个列表,其中各元素均为字符串,分别是各路径名和文件名。
- 通常在需要遍历某个文件夹中文件的场景下极为实用。
比如定义以下函数:
def get_filelists(file_dir='.'):
list_directory = os.listdir(file_dir)
filelists = []
for directory in list_directory:
# os.path 模块稍后会讲到
if(os.path.isfile(directory)):
filelists.append(directory)
return filelists
- 该函数的返回值就是当前目录下所有文件而非文件夹的名称列表。
2.5 os.mkdir()
“mkdir”,即“make directory”,用处是**“新建一个路径”**。需要传入一个类路径参数用以指定新建路径的位置和名称,如果指定路径已存在,则会抛出FileExistsError异常。
该函数只能在已有的路径下新建一级路径,否则(即新建多级路径)会抛出FileNotFoundError异常。
相应地,在需要新建多级路径的场景下,可以使用os.makedirs()来完成任务。函数os.makedirs()执行的是递归创建,若有必要,会分别新建指定路径经过的中间路径,直到最后创建出末端的“叶子路径”。
示例如下:
>>> os.mkdir("test_os_mkdir")
>>> os.mkdir("test_os_mkdir")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: 'test_os_mkdir'
>>>
>>> os.mkdir("test_os_mkdir/test_os_makedirs/just/do/python/hello")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'test_os_mkdir/test_os_makedirs/just/do/python/hello'
>>>
>>> os.makedirs("test_os_mkdir/test_os_makedirs/just/do/python/hello")
2.6 os.remove()
用于删除文件,如果指定路径是目录而非文件的话,就会抛出IsADirectoryError异常。删除目录应该使用os.rmdir()函数。
同样的,对应于os.makedirs(),删除路径操作os.rmdir()也有一个递归删除的函数os.removedirs(),该函数会尝试从最下级目录开始,逐级删除指定的路径,几乎就是一个os.makedirs()的逆过程;一旦遇到非空目录即停止。
2.7 os.rename()
该函数的作用是将文件或路径重命名,一般调用格式为os.rename(src, dst),即将src指向的文件或路径重命名为,dst指定的名称。
注意,如果指定的目标路径在其他目录下,该函数还可实现文件或路径的“剪切并粘贴”功能。但无论直接原地重命名还是“剪切粘贴”,中间路径都必须要存在,否则就会抛出FileNotFoundError异常。如果目标路径已存在,Windows 下会抛出FileExistsError异常;Linux 下,如果目标路径为空且用户权限允许,则会静默覆盖原路径,否则抛出OSError异常,
和上两个函数一样,该函数也有对应的递归版本os.renames(),能够创建缺失的中间路径。
注意,这两种情况下,如果函数执行成功,都会调用os.removedir()函数来递归删除源路径的最下级目录。
2.8 os.getcwd()
“getcwd”实际上是“get the current working directory”的简写,顾名思义,也就是说这个函数的作用是**“获取当前工作路径”**。在程序运行的过程中,无论物理上程序在实际存储空间的什么地方,“当前工作路径”即可认为是程序所在路径;与之相关的“相对路径”、“同目录下模块导入”等相关的操作均以“当前工作路径”为准。
在交互式环境中,返回的就是交互终端打开的位置;而在 Python 文件中,返回的则是文件所在的位置。
在 Windows 下会有如下输出:
>>> os.getcwd()
'd:\\justdopython\\just\\do\\python'
Linux 下的输出则是:
>>> os.getcwd()
'/home/justdopython/just/do/python'
2.9 os.chdir()
“chdir”其实是“change the directory”的简写,因此os.chdir()的用处实际上是切换当前工作路径为指定路径。其中“指定路径”需要作为参数传入函数os.chdir(),该参数既可以是文本或字节型字符串,也可以是一个文件描述符,还可以是一个广义的类路径(path-like)对象。若指定路径不存在,则会抛出FileNotFoundError异常。
在 Windows 下,调用该函数的效果为:
>>> os.chdir("d:/justdopython/just/do")
>>> os.getcwd()
'd:\\justdopython\\just\\do'
在 Linux 下的效果则是:
>>> os.chdir("/home/justdopython/just/do") # 也可将参数指定为"..",即可切换到父目录
>>> os.getcwd()
'/home/justdopython/just/do'
有了这个函数,跨目录读写文件和调用模块就会变得非常方便了,很多时候也就不必再反复将同一个文件在各个目录之间复制粘贴运行,脚本完全可以坐镇中军,在一个目录下完成对其他目录文件的操作,正所谓“运筹帷幄之中,决胜于千里之外”也。
举例来说,可以通过将“当前工作目录”切换到父目录,从而直接访问父目录的文件内容:
>>> os.chdir("..")
>>> os.getcwd()
'D:\\justdopython\\just'
>>> with open("hello_justdopython.txt", encoding="utf-8") as f:
... f.read()
...
'欢迎访问 justdopython.com,一起学习 Python 技术~'
>>> os.listdir()
['hello_justdopython.txt']
3. os.path 模块
其实这个模块是os模块根据系统类型从另一个模块导入的,并非直接由os模块实现,比如os.name值为nt,则在os模块中执行import ntpath as path;如果os.name值为posix,则导入posixpath。
使用该模块要注意一个很重要的特性:os.path中的函数基本上是纯粹的字符串操作。换句话说,传入该模块函数的参数甚至不需要是一个有效路径,该模块也不会试图访问这个路径,而仅仅是按照“路径”的通用格式对字符串进行处理。
更进一步地说,os.path模块的功能我们都可以自己使用字符串操作手动实现,该模块的作用是让我们在实现相同功能的时候不必考虑具体的系统,尤其是不需要过多关注文件系统分隔符的问题。
3.1 os.path.join()
这是一个十分实用的函数,可以将多个传入路径组合为一个路径。实际上是将传入的几个字符串用系统的分隔符连接起来,组合成一个新的字符串,所以一般的用法是将第一个参数作为父目录,之后每一个参数即使下一级目录,从而组合成一个新的符合逻辑的路径。
但如果传入路径中存在一个“绝对路径”格式的字符串,且这个字符串不是函数的第一个参数,那么其他在这个参数之前的所有参数都会被丢弃,余下的参数再进行组合。更准确地说,只有最后一个“绝对路径”及其之后的参数才会体现在返回结果中。
>>> os.path.join("just", "do", "python", "dot", "com")
'just\\do\\python\\dot\\com'
>>>
>>> os.path.join("just", "do", "d:/", "python", "dot", "com")
'd:/python\\dot\\com'
>>>
>>> os.path.join("just", "do", "d:/", "python", "dot", "g:/", "com")
'g:/com'
3.2 os.path.abspath()
将传入路径规范化,返回一个相应的绝对路径格式的字符串。
也就是说当传入路径符合“绝对路径”的格式时,该函数仅仅将路径分隔符替换为适应当前系统的字符,不做其他任何操作,并将结果返回。所谓“绝对路径的格式”,其实指的就是一个字母加冒号,之后跟分隔符和字符串序列的格式:
>>> os.path.abspath("a:/just/do/python")
'a:\\just\\do\\python'
>>> # 我的系统中并没有 a 盘
当指定的路径不符合上述格式时,该函数会自动获取当前工作路径,并使用os.path.join()函数将其与传入的参数组合成为一个新的路径字符串。示例如下:
>>> os.path.abspath("ityouknow")
'D:\\justdopython\\ityouknow'
3.3 os.path.basename()
该函数返回传入路径的“基名”,即传入路径的最下级目录。
>>> os.path.basename("/ityouknow/justdopython/IAmBasename")
'IAmBasename'
>>> # 我的系统中同样没有这么一个路径。可见 os.path.basename() 页是单纯进行字符串处理
整这个函数要注意的一点是,返回的“基名”实际上是传入路径最后一个分隔符之后的子字符串,也就是说,如果最下级目录之后还有一个分隔符,得到的就会是一个空字符串:
>>> os.path.basename("/ityouknow/justdopython/IAmBasename/")
''
3.4 os.path.dirname()
与上一个函数正好相反,返回的是最后一个分隔符前的整个字符串:
>>> os.path.dirname("/ityouknow/justdopython/IAmBasename")
'/ityouknow/justdopython'
>>>
>>> os.path.dirname("/ityouknow/justdopython/IAmBasename/")
'/ityouknow/justdopython/IAmBasename'
3.5 os.path.split()
哈哈实际上前两个函数都是弟弟,这个函数才是老大。
函数os.path.split()的功能就是将传入路径以最后一个分隔符为界,分成两个字符串,并打包成元组的形式返回;前两个函数os.path.dirname()和os.path.basename()的返回值分别是函数os.path.split()返回值的第一个、第二个元素。就连二者的具体实现都十分真实:
def basename(p):
"""Returns the final component of a pathname"""
return split(p)[1]
def dirname(p):
"""Returns the directory component of a pathname"""
return split(p)[0]
通过os.path.join()函数又可以把它们组合起来得到原先的路径。
3.6 os.path.exists()
这个函数用于判断路径所指向的位置是否存在。若存在则返回True,不存在则返回False:
>>> os.path.exists(".")
True
>>> os.path.exists("./just")
True
>>> os.path.exists("./Inexistence") # 不存在的路径
False
一般的用法是在需要持久化保存某些数据的场景,为避免重复创建某个文件,需要在写入前用该函数检测一下相应文件是否存在,若不存在则新建,若存在则在文件内容之后增加新的内容。
3.7 os.path.isabs()
该函数判断传入路径是否是绝对路径,若是则返回True,否则返回False。当然,仅仅是检测格式,同样不对其有效性进行任何核验:
>>> os.path.isabs("a:/justdopython")
True
3.8 os.path.isfile() 和 os.path.isdir()
这两个函数分别判断传入路径是否是文件或路径,注意,此处会核验路径的有效性,如果是无效路径将会持续返回False。
>>> # 无效路径
>>> os.path.isfile("a:/justdopython")
False
>>>
>>> # 有效路径
>>> os.path.isfile("./just/plain_txt")
True
>>>
>>> # 无效路径
>>> os.path.isdir("a:/justdopython/")
False
>>> # 有效路径
>>> os.path.isdir("./just/")
True
\W- ↩︎

















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









