







一 希尔排序的过程、增量序列的特点
希尔排序(Shell Sort)是一种基于插入排序的算法,它通过比较相隔较远距离(称为增量)的数来工作,使得数移动时能跨过多个元素,从而减少了元素的比较次数和移动次数。以下是希尔排序的过程和增量序列的特点:
希尔排序过程
- 选择增量序列:首先,选择一个增量序列D_k = {d_1, d_2, ..., d_t},其中d_1 > d_2 > ... > d_t = 1。
- 分组排序:对于每个增量d_k(k从1到t),将待排序序列按照下标增量d_k分成d_k个子序列,对每个子序列进行直接插入排序。
- 逐步缩小增量:按照增量序列的顺序,逐步缩小增量d_k的值,并重复分组排序的过程,直到增量d_t = 1,此时整个序列被分为一个子序列,对其进行一次直接插入排序,排序完成。
增量序列的特点
- 递减性:增量序列D_k必须是递减的,即d_1 > d_2 > ... > d_t = 1。这是为了确保排序的逐渐精细化,每个阶段都能基于前一阶段的结果进行。
- 互质性:增量序列中的元素最好是互质的,即它们之间除了1之外没有其他公因子。这有助于避免某些情况下可能出现的循环依赖,从而提高排序效率。然而,这并不是一个强制性的要求,有些有效的增量序列并不满足这一条件。
- 初次增量选取:增量序列的初次增量d_1通常选取待排序序列长度n的一半(即n/2),然后每次减半,直到增量为1。这是一种简单有效的增量选取方法,但并不一定是最优的。
- 与算法效率的关系:希尔排序的算法效率与增量序列的选取有密切关系。一个好的增量序列可以使算法的时间复杂度显著降低,但如何确定最优的增量序列仍是一个未解决的问题。
二 快速排序算法的思想,一趟快速排序的结果

快排的算法分析题,第一天做过
代码
int partition(SqList* L, int l, int r) {
int p;
p = L->a[l]; // 依然选择第一个元素作为基准,根据需要也可以选择其他策略
while (l < r) {
// 正确地从右向左找第一个小于基准的元素
while (l < r && L->a[r] >= p) {
r--;
}
// 交换找到的元素与基准位置的元素
swap(L->a[l], L->a[r]);
// 然后从左向右找第一个大于基准的元素
while (l < r && L->a[l] <= p) {
l++;
}
// 交换找到的元素与当前r指向的元素
swap(L->a[l], L->a[r]);
}
// 当l与r相遇时,它们所在的位置即为基准的最终位置
return l;
}
void QSort(SqList*L,int l,int r){
int p;
if(l<r){
p=partition(L,l,r);
QSort(L,l,p-1);
QSort(L,p+1,r);
}
}前期有做过
在选取轴的时候为了避免选择的数过大或过小,
可以选择三数取中方法。
// 三数取中找到中位数索引
int medianOfThree(int arr[], int l, int r) {
int center = (l+r) / 2;
// 将这三个数按大小排列,使arr[center]成为中位数
if (arr[l > arr[r])
swap(&arr[l], &arr[center]);
if (arr[l] > arr[r])
swap(&arr[l], &arr[r]);
if (arr[center] > arr[r])
swap(&arr[center], &arr[r);
// 现在arr[center]是中位数,返回其索引
return center;
}
//之后把p = L->a[l];改为int p= medianOfThree(arr, l, r);三 冒泡排序法算法思想、代码
算法思想
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
代码
#include<stdio.h>
void swap(int *a,int *b){
int t=*a;
*a=*b;
*b=t;
}
void Bubllesort(in a[],int n){
for(int i=0;i<n-1;i++){
for(int j=0;j<n-i-1;j++){
if(a[j]>a[j+1]){
swap(a[j],a[j+1]);
}
}
}
}四 堆的建立过程(如何在给定数据集上构造堆)


五 基数排序算法思想
从个位开始比较数字,为什么不直接比较最高位。因为决定性的比较放后面,比如29,32,先十位则32,29,再各位的时候,29,32.会导致结果不准确。
六 各类排序算法的时间复杂度,最好最坏情况
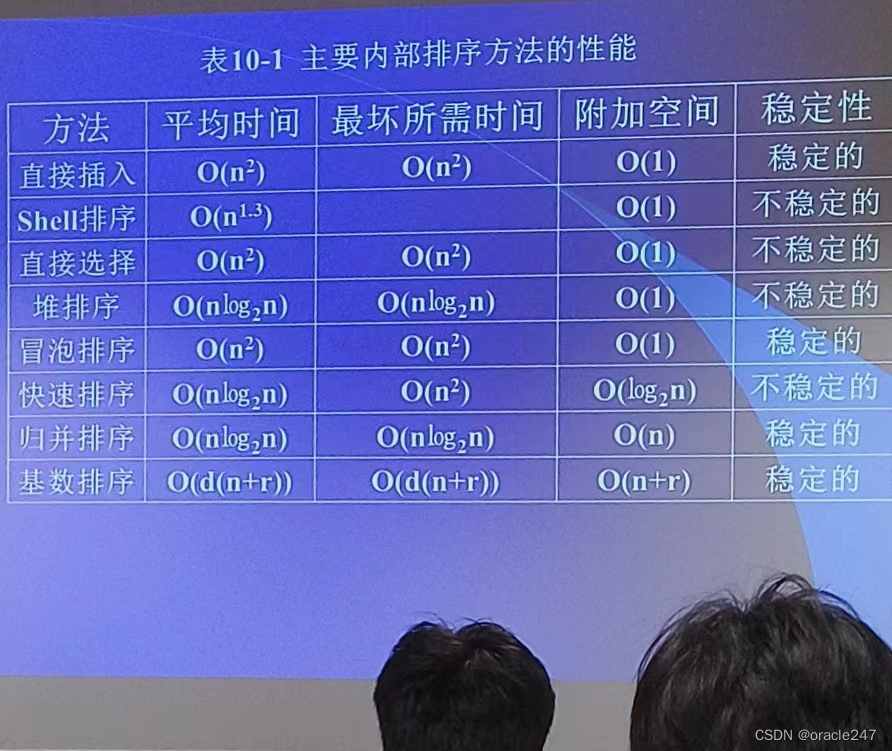
口诀,插冒龟(归),它很稳(稳定性)
它喜欢选冒插,插完就慌(方)了。
七 归并排序
算法思想
- 分解:将当前待排序的序列划分为两个等长的子序列,直到每个子序列只包含一个元素(此时子序列自然有序)。
- 递归进行排序并合并:递归地对子序列进行排序,并将已排序的子序列合并成一个大的有序序列,直到合并为1个完整的序列。
实现过程


//上面是选自大话数据结构的代码,放完假再自己写吧emm
八 总结
1插入排序 直接插入 表插入shell 排序
2交换排序 两两比较 冒泡 快排
3选择排序 简单选择排序 堆排序
4归并排序
5基数排序
//仅为期末突击使用,所以详略不一,有空优化















 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









