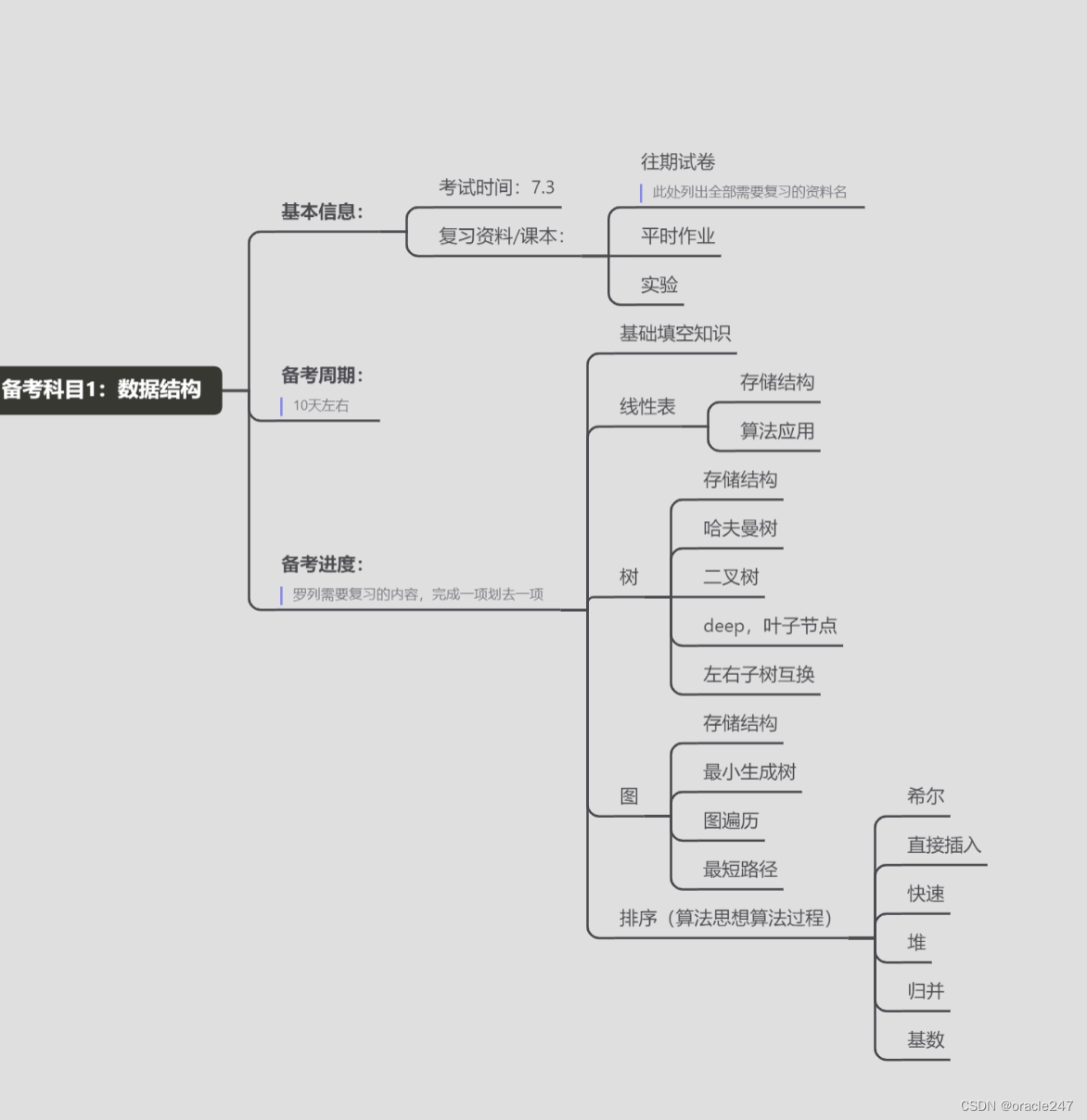
复习知识点大纲
 刷一套期末试题(了解题型分布和知识点)
刷一套期末试题(了解题型分布和知识点)
//下面这套年份有点早近几年的试卷老师都不发0.0,新的没有判断题重在后期编译题
理论部分
定义逻辑结构时可不考虑物理结构。
(F )
绪论部分知识
线性表采用顺序存储
,必
须 占用一片连续的存储单元。
(T)
了解线性表存储结构特点
&&循环队列的引入 目的是为了克服溢出F
F)
循环队列的引入主要目的并不是为了解决溢出问题,而是为了更高效地利用内存空间,避免传统队列中的“假溢出”现象。
一棵完全二叉树可以存在度不为
2的
非叶子节点。
(T)
在哈夫曼树中
,权
值最小的节点离根节点最近。
( F)
了解哈夫曼树的特点
图中
,所
有节点度数之和等于所有边的数 目的
2倍
。
(T)
这个特点可以用于后序计算
任何无环的有向图
,其
节点都可以排在一个拓扑序列里。T
拓扑排序是对有向无环图的节点进行线性排序的过程,满足以下条件:
- 每个节点出现且仅出现一次。
- 如果图中存在一条从节点A到节点B的有向边,则在拓扑序列中,节点A出现在节点B之前。
最小生戍树的WPL一定小于其他生成树的
WPL。
( F)
最小生成树MST)与最小WPL的哈夫曼树是两个不同的概念
快速排序算法在最坏情况下就变成了冒泡排序。
(F )
了
解排序的算法分析
填空部分
1一
个顺序表的第一个元素的存储地址是
Ox12fⅣ
c,每
个元素的长
度是
4,则
第
3个
元素的地址是
2.对
于顺序表
,定
位运算的时间复杂度为
。
3.双
向链表中
,求
节点的前驱节点算法的时间复杂度是
。
4.在
主串中查找字串的操作称为
5.含
有
3个
节点
a,b,c,且
先序遍历为
abc的
二叉树有
种。
6.己
知一棵满二叉树的节点个数为 ⒛到4
0之
间的素数
,则
此二叉树
的深度为
(根
节点深度为
1)。
7.存
储完全二叉树的最简单、最省空间的存储方式是
8.一
个具有
n个
顶点
e条
边的无向图的邻接矩阵中
,零
元素的个数
为
。
9.因
散列函数值不同而发生的冲突称为
10.
每一步都只考虑当前最优
,不
考虑全局最优的算法是
//1,5不会,有会的佬评论区踢我一下,老师说大家对概念部分都比较薄弱,能得8分他就谢天谢地了。
//下面是答案
选择部分
4设
n个
元 素 进 栈 的 序 列 是
1,2,3,…
n,其
输 出 序 列 是
p1,pz,p3,…pn,若 p1司
,则
田 的值
( )。
A。
一定是
1 B。
一定是
2 C。
可能是
1 D。
可能是 2
5深
度为
7(根
节点深度为
1)的
完全二叉树至少有
( )个
节点
分清满二叉树和完全二叉树
6,若
一棵二叉树中度为
1的
结点个数是
3,度
为
2的
结点个数是
4,
则该二叉树叶子结点的个数是
( )。
A
4
B.5
C7
D8
“二叉树的性质5”:
对于任何非空的二叉树,如果 𝑛0n0 是度为0的节点(即叶子节点)的数量,𝑛1n1 是度为1的节点的数量,而 𝑛2n2 是度为2的节点的数量,则它们之间满足以下关系:
𝑛0=𝑛2+1
了解二叉树的性质
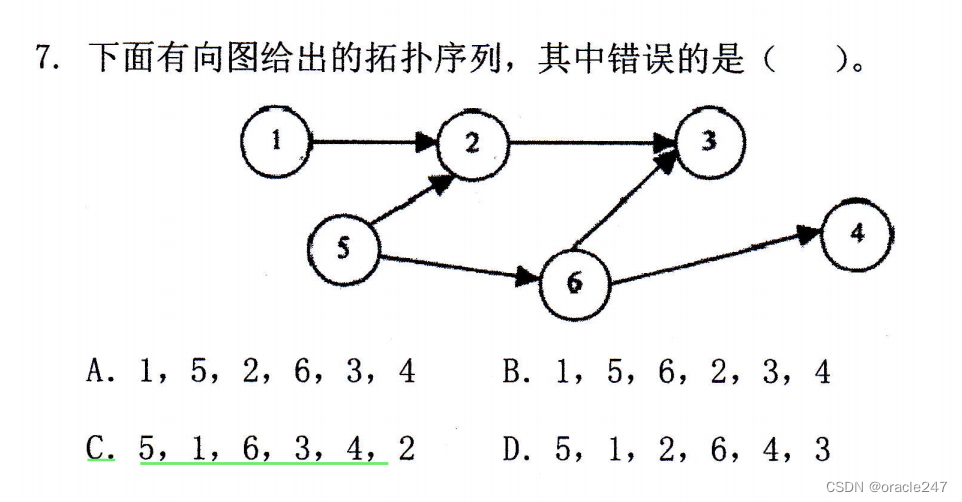
拓扑排序的步骤就是找入度为0的删掉然后继续找入度为0的,然后就这么写下去。
8在
带权图的最短路径问题中
,路
径长度是指
( )。
A.路
径上的顶点数
B。
路径上的边数
C。
路径上的顶点数与边数之和
D。
路径上各边的权值之和
9.某索引顺序表共有元素 395个 ,平均分成 5块。若先对索引 表采用顺序查找,再对块中元素进行顺序查找,则在等概率情况 下,分块查找成功的平均查找长度是 ( )。
A。 43 B。 79 C。 198 D。 2oo
//为了计算分块查找(也称为索引顺序查找或索引顺序存储查找)的平均查找长度(ASL, Average Search Length),我们需要了解两个关键概念:
-
块内查找的平均长度:在一个块内使用顺序查找时,平均查找长度是块内元素数量的一半(因为查找可能从第一个元素开始,到最后一个元素结束,所以平均位置是中间)。
-
索引查找的平均长度:由于索引表被平均分成5块,索引查找(选择正确的块)的平均长度是 (n + 1) / 2,其中 n 是索引表(块的数量)的大小。在这个例子中,n = 5
所以,总的平均查找长度(ASL)是索引查找的平均长度加上块内查找的平均长度,即 3 + 39 = 42。但给出的选项中没有42,我们需要考虑查找索引和块内元素都需要至少一次比较(即各加1),所以实际ASL是 4 + 39 = 43。//
算法分析
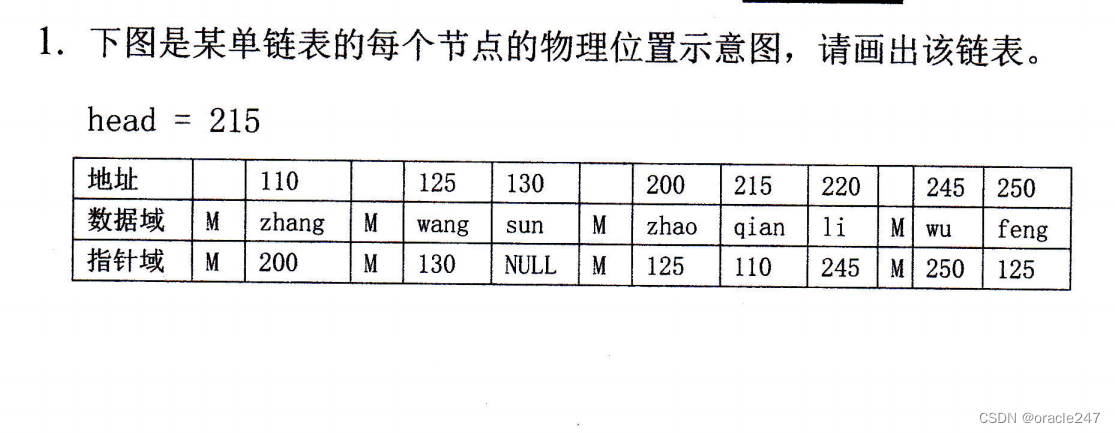
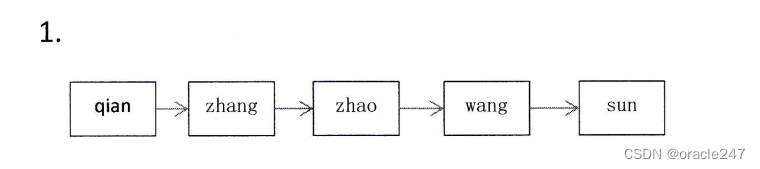
2.设
二维数组
DataType A[Gl[a],每
个元素用相邻的
6个
字节存储
,
存储器按字节编址
,已
知
A的
基地址为
1000,计
算
:
(1)数
组
A占
用的存储空间
6*8*6=188
(2)按
行优先顺序存储时
A[1]4]的
第一个字节的地址
1000+(1*8+4)*6=1072
(3)按
列优先顺序存储时 A[4][7]的 第一个字节的地址
1000+(7*8+4)*6=1276
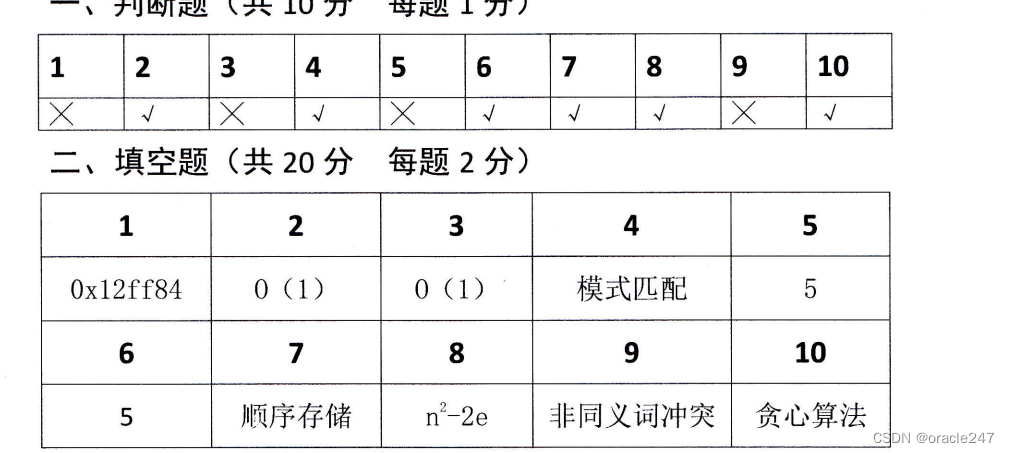
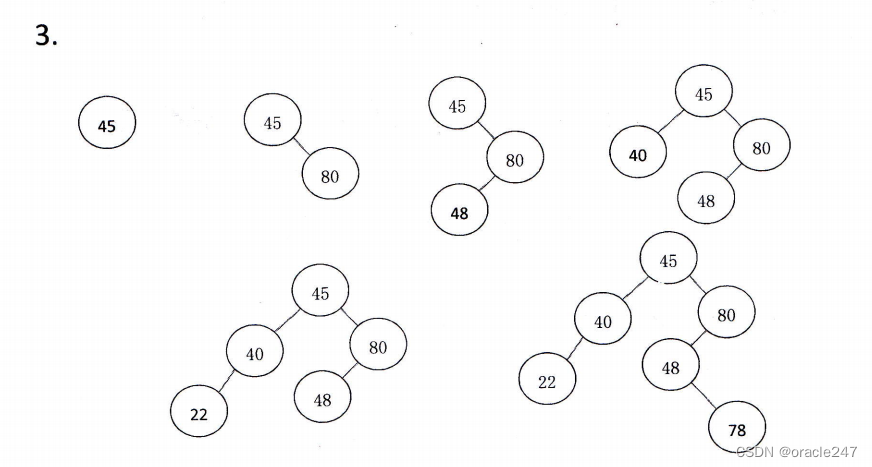
3.设
有一组初始记录关键字为{45,80,48,40,22,78
),要
求构
造一棵二叉排序树
,·
并给出构造
过程
。
//审题要过程只有最终结果分很少
方法就是遇谁干谁,从上到下,左小右大。方法链接下面
http://【【数据结构|查找】二叉排序树的创建、插入、删除(示例讲解)】https://www.bilibili.com/video/BV1fr4y1j7su?vd_source=7ba2257b4ce9212631d2decf4d987850
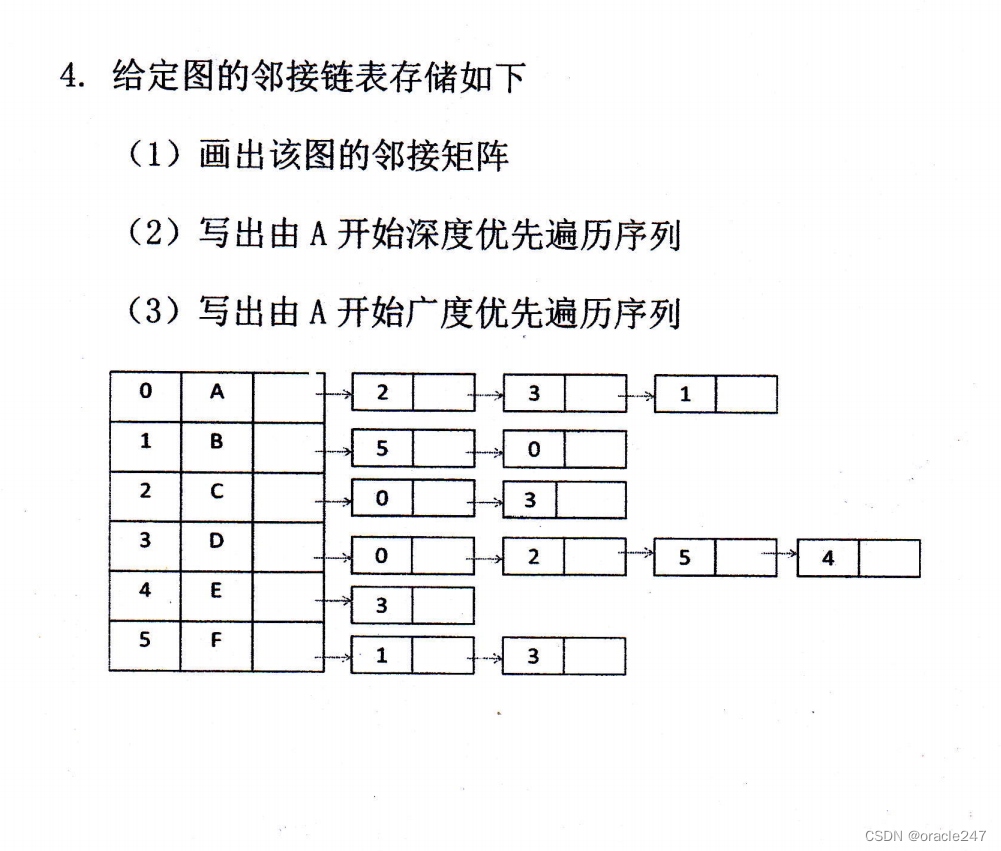
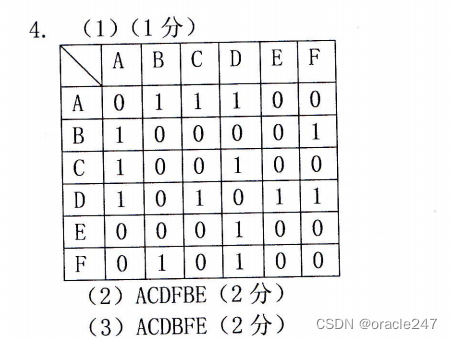
关于树的遍历划块写会快很多
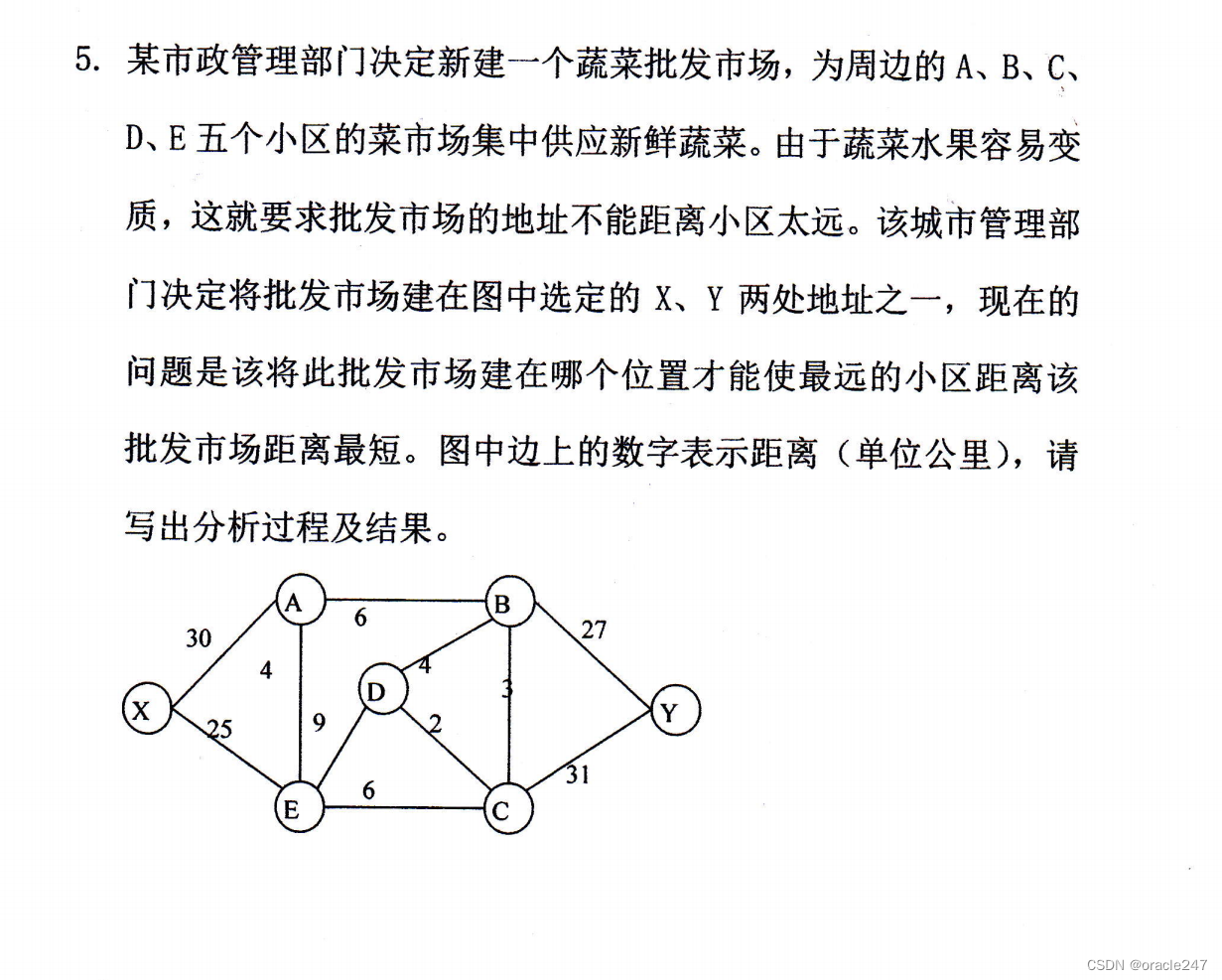
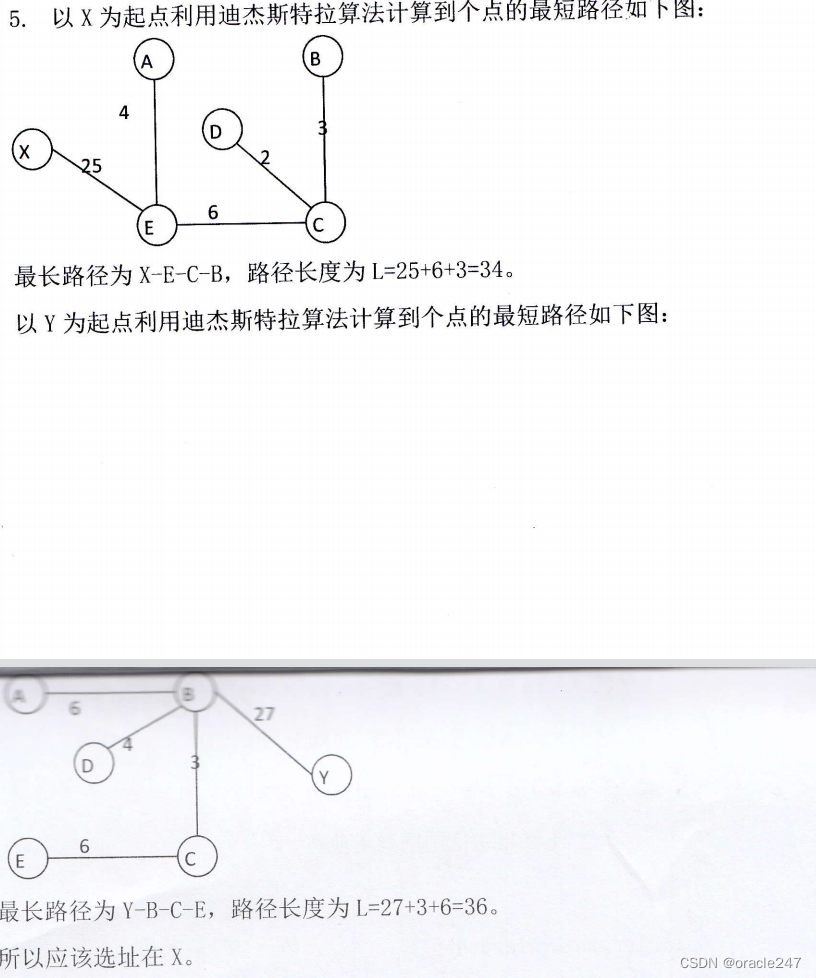 涉及最短路径http://【图-最短路径-Dijkstra(迪杰斯特拉)算法】https://www.bilibili.com/video/BV1uT4y1p7Jy?vd_source=7ba2257b4ce9212631d2decf4d987850
涉及最短路径http://【图-最短路径-Dijkstra(迪杰斯特拉)算法】https://www.bilibili.com/video/BV1uT4y1p7Jy?vd_source=7ba2257b4ce9212631d2decf4d987850

 //先这么多了今天有空再看看编程题
//先这么多了今天有空再看看编程题
编程题
1,二分查找
2,链表删除

void Delet_SqList(Sqlist *L,int x,int y){
if(x>y){
int t=x;x=y;y=t;//因为题目没有说谁大谁小
}
int m,n;
for(m=0;m<L->length;m++){
if((L->data[m]>=x)&&(L->data[m]<=y))n++;
else L->data[m-n]=L->data[m];
}
L->length=L->length-n;
}
总结
1.对于树章节的知识掌握i最好,链表其次。
2查找一点没学
3巩固了迪杰斯特拉算法,快排的过程分析
4认识拓扑排序,二叉排序树
5误区,
最小生戍树的WPL不一定小于其他生成树的
WPL。
循环队列是为了防止假溢出
6填空4,9,10.新输入大脑知识。
在主串中查找字串的操作称为模式匹配
因散列函数值不同而发生的冲突称为 非同义词冲突
每一步都只考虑当前最优,不考虑全局最优的算法是贪心

























 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









