







网站:「长沙招聘」-2025年长沙人才招聘信息 - BOSS直聘
| Drissionpage (浏览器自动化操作) | pandas (数据处理和分析,特别是处理表格数据 保存数据) |
| time (控制程序执行的时间间隔或延时) | pprint (用于美化打印输出,方便调试) |
| pandas (文件读取模块) | pyecharts (生成可视化图表) |
明确需求:
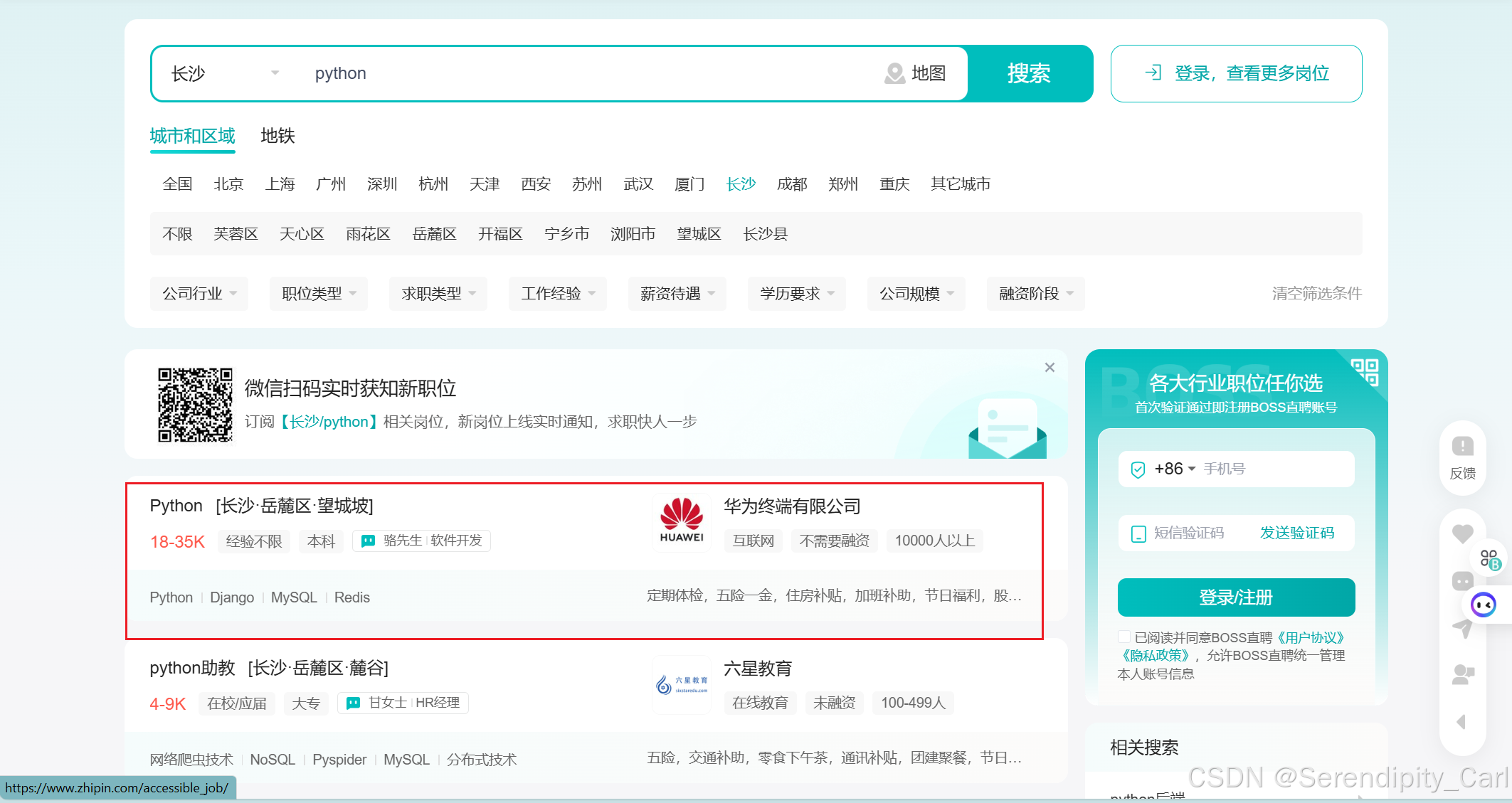
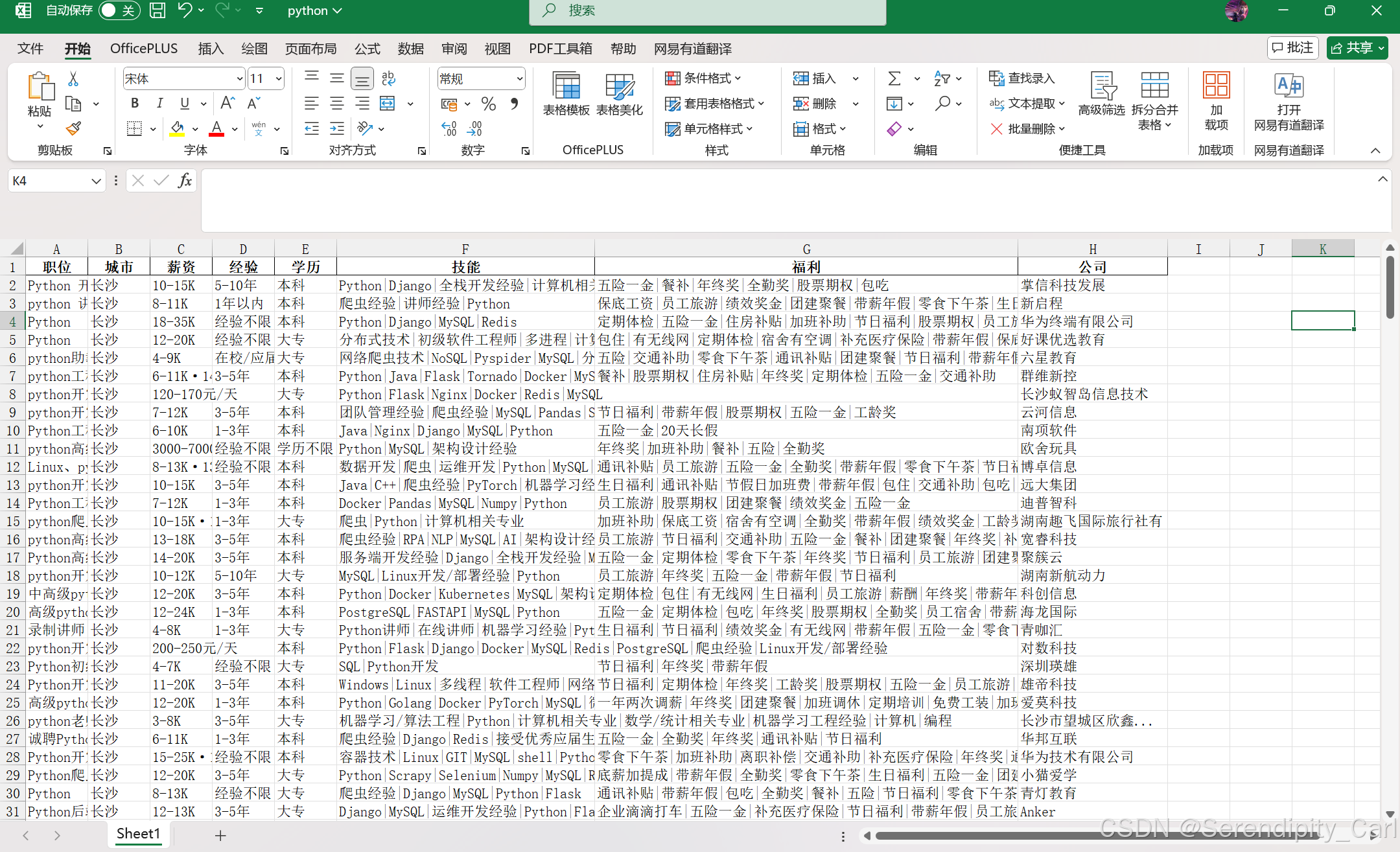
- 采集职位 城市 薪资 经验 学历 技能 福利 公司
- 保存到本地为excel 文件
- 对数据进行可视化
步骤:
一.分析页面
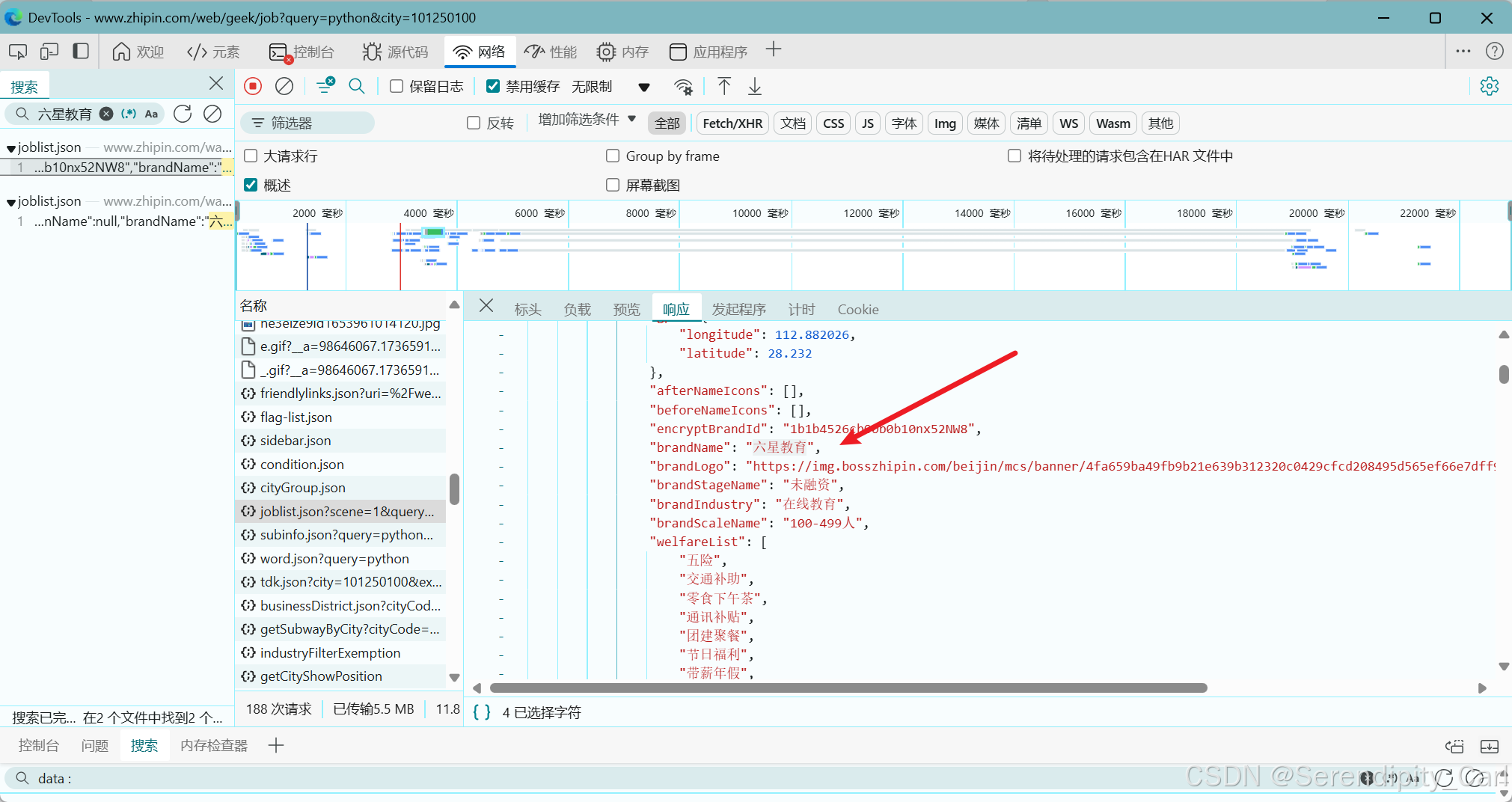
F12 or右键点击检查 打开检查
刷新页面
Ctrl+F 打开搜索框 输入想采集的数据 查看返回数据的数据包
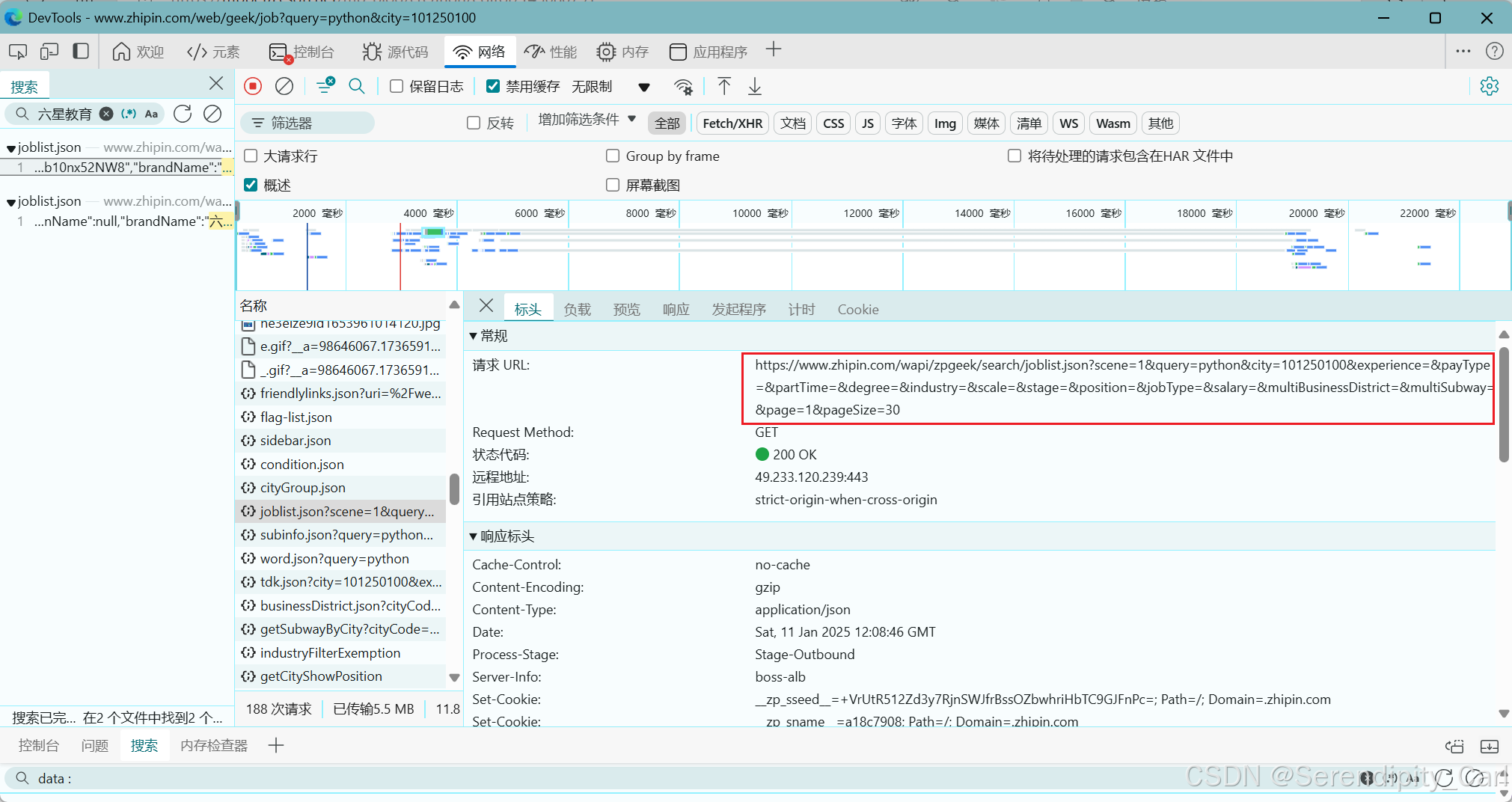
复制一段数据包的URL地址 方便后面监听数据包
# 导入自动化模块
from DrissionPage import ChromiumPage
dp=ChromiumPage()
# 监听数据包
dp.listen.start('wapi/zpgeek/search/joblist.json')
# 访问页面
# 复制浏览器 上面的地址 打开网址
dp.get('https://www.zhipin.com/web/geek/job?query=python&city=101250100')
# 等待数据包的加载
resp=dp.listen.wait()
# 将页面滑到最低端
dp.scroll.to_bottom()
# 获取响应的内容
json_data = resp.response.body
# 格式化打印json 数据
pprint.pprint(json_data )
查看我们的数据是否包含在里头
OK 接着我们提取数据 通过键值对取值 后续For 循坏遍历列表
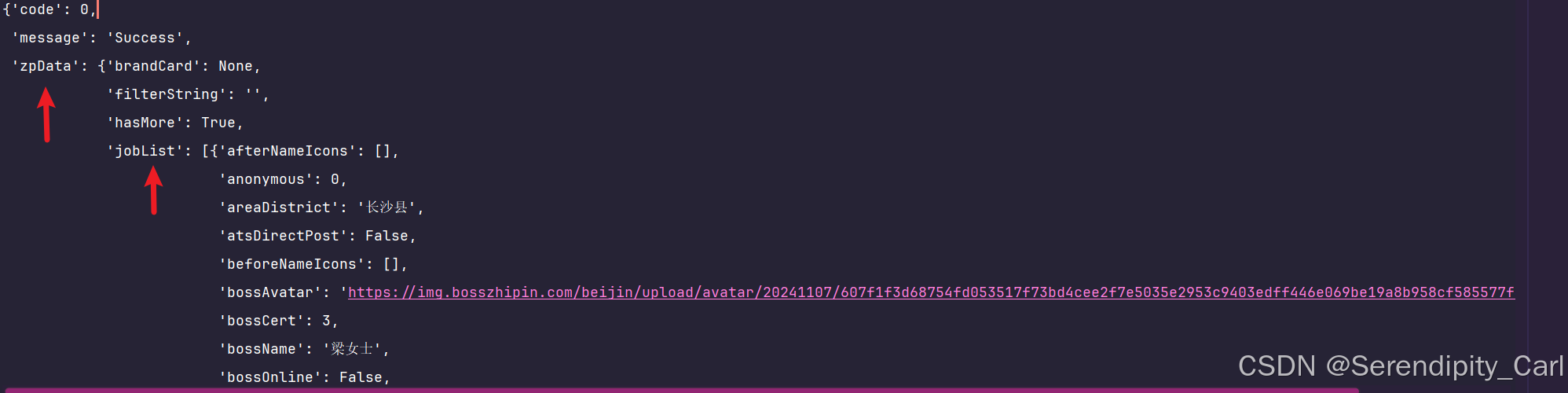
提取具体的岗位信息
用字典来存储数据
info_data = json_data['zpData']['jobList']
for i in info_data:
dit = {
'职位': i['jobName'],
'城市': i['cityName'],
'薪资': i['salaryDesc'],
'经验': i['jobExperience'],
'学历': i['jobDegree'],
'技能': i['skills'],
'福利': i['welfareList'],
'公司': i['brandName'],
}最后保存数据
for i in info_data:
dit = {
'职位': i['jobName'],
'城市': i['cityName'],
'薪资': i['salaryDesc'],
'经验': i['jobExperience'],
'学历': i['jobDegree'],
'技能': i['skills'],
'福利': i['welfareList'],
'公司': i['brandName'],
}
# 前面定义一个空列表
lis.append(dit)
df = pd.DataFrame(lis)
df.to_excel('python.xlsx', index=False)多页数据的采集
外层嵌套一个For 循坏
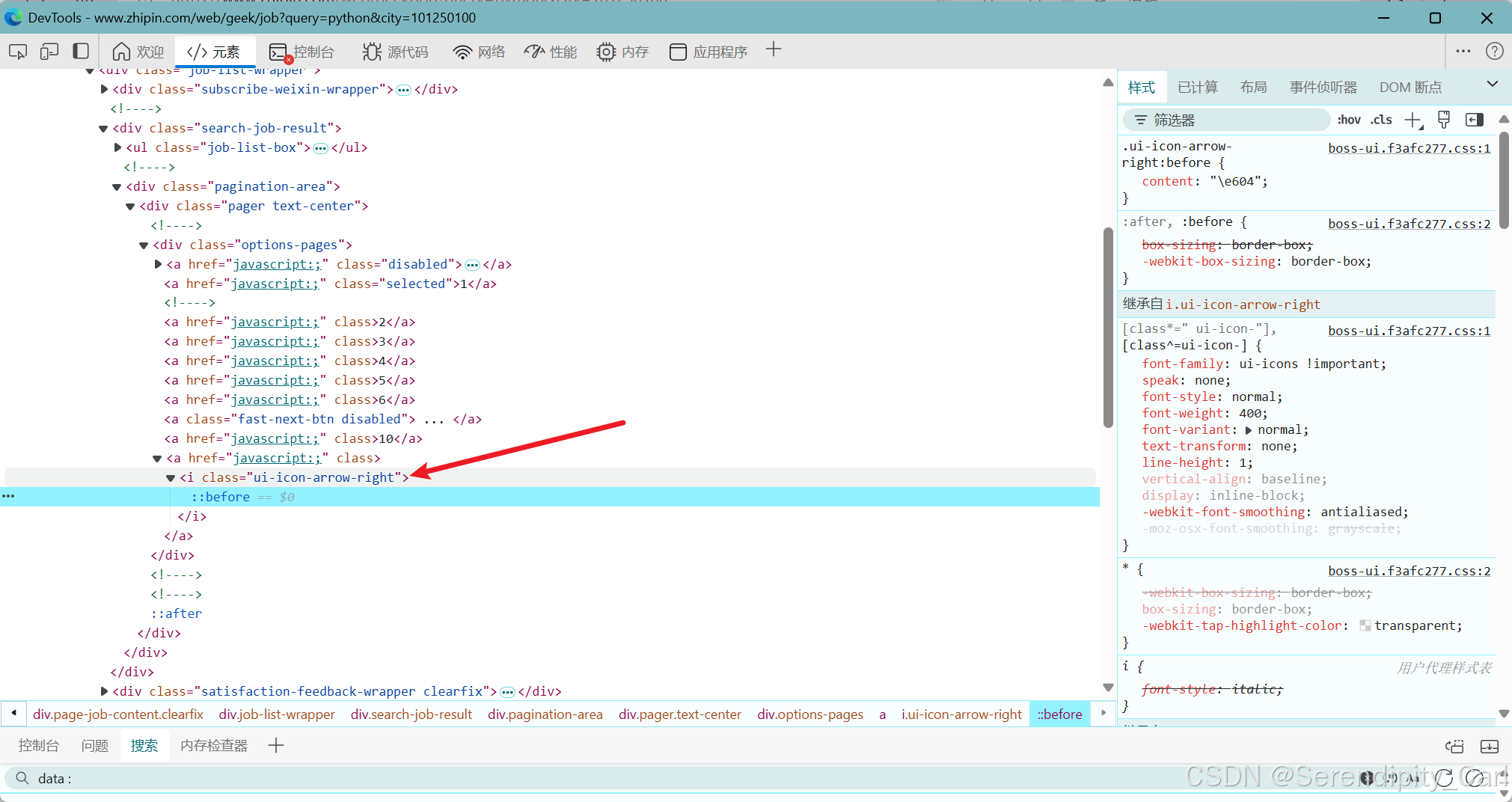
点击下一个 通过定位元素 拿到下一页的css名
完整的代码如下:
供大家参考 交流 学习使用
# 导入自动化模块
from DrissionPage import ChromiumPage
import pprint
import pandas as pd
import time
lis = []
# 创建一个浏览器对象
dp = ChromiumPage()
# 监听数据包
dp.listen.start('wapi/zpgeek/search/joblist.json')
# 访问页面
dp.get('https://www.zhipin.com/web/geek/job?query=python&city=101250100')
for page in range(1,10):
time.sleep(2)
dp.scroll.to_bottom()
resp = dp.listen.wait()
json_data = resp.response.body
info_data = json_data['zpData']['jobList']
for i in info_data:
dit = {
'职位': i['jobName'],
'城市': i['cityName'],
'薪资': i['salaryDesc'],
'经验': i['jobExperience'],
'学历': i['jobDegree'],
# 转换成字符串格式 以|分隔
'技能': '|'.join(i['skills']),
'福利': '|'.join(i['welfareList']),
'公司': i['brandName'],
}
lis.append(dit)
df = pd.DataFrame(lis)
df.to_excel('java.xlsx', index=False)
dp.ele('css:.ui-icon-arrow-right').click()
print(f'{page + 1}采集完成')
运行代码

数据可视化模块
#使用pandas读取Excel文件中的数据
import pandas as pd
from pyecharts.charts import Pie
from pyecharts.charts import Pie
from pyecharts import options as opts
df = pd.read_excel('python.xlsx')
#统计“学历”列中各学历的数量
x = df['学历'].value_counts().index.to_list()
y = df['学历'].value_counts().to_list()
# 创建饼图对象
pie = (
Pie()
.add(
"",
[list(z) for z in zip(x,y)],
radius=[30, 75],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="学历分布"),
legend_opts=opts.LegendOpts(orient='vertical',pos_top='15%',pos_left='2%'),
toolbox_opts=opts.ToolboxOpts(is_show=True),
)
).render("pie_chart.html")
# 渲染生成HTML文件,在当前目录下会生成名为pie_chart.html的文件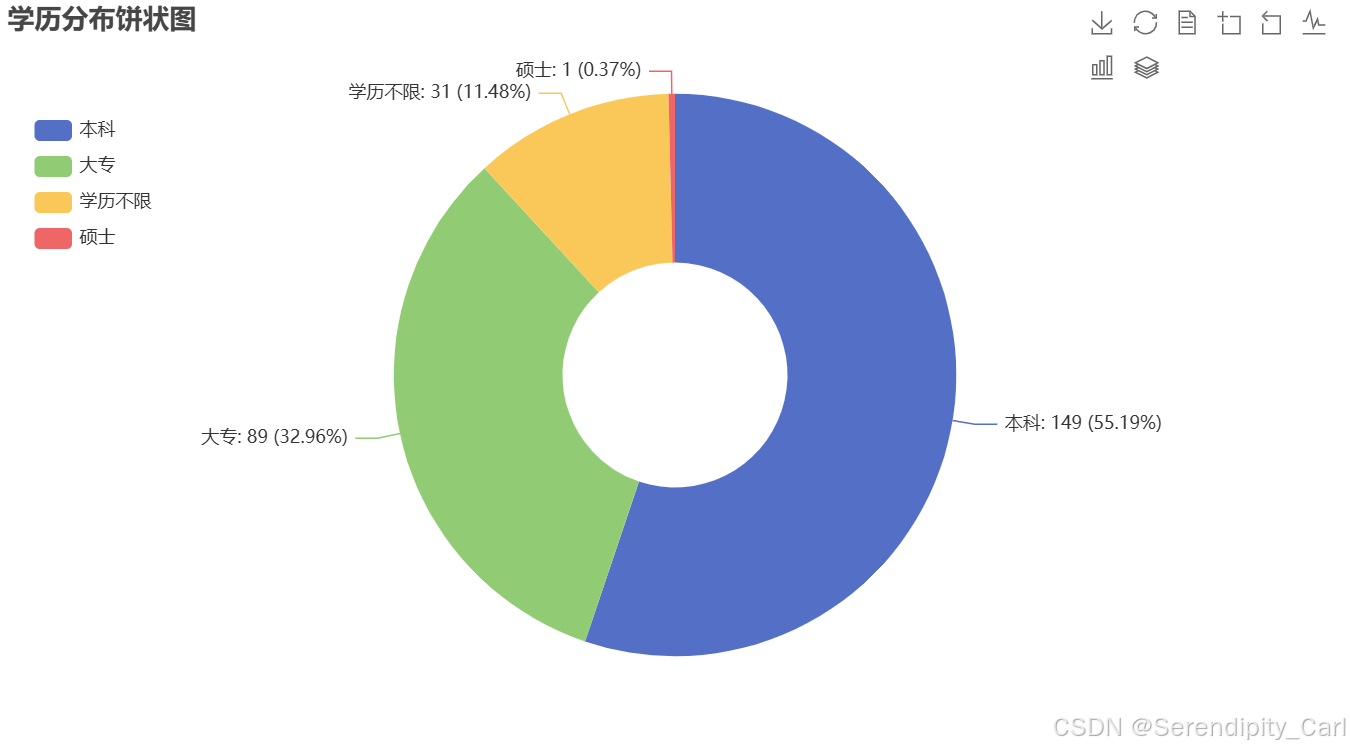
本次的案例分享到此结束 感谢大家的观看 您的点赞和关注是我更新的动力



















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











