






摘要:本文通过 DrissionPage 自动化采集 Boss直聘 网站上的 大数据开发 岗位信息,并使用 pandas 和 SQLAlchemy 将数据存入 MySQL 数据库,再使用FineBI绘制可视化大屏。整个过程包括 浏览器自动化、数据解析、数据存储,最终实现职位信息的批量采集与分析以及图表绘制。
📌 小贴士: 请遵守网站爬取规则,合理控制请求频率!
1. 工具和库介绍🛠️
本项目使用以下强大的Python工具链:
| 工具 | 用途 | 特点 |
|---|---|---|
| 🐍 DrissionPage | 浏览器自动化操作 | 比Selenium更高效的新兴工具 |
| 📊 pandas | 数据处理与分析 | 数据分析神器 |
| 💾 SQLAlchemy | MySQL数据库连接 | ORM工具,安全高效 |
| 📁 csv | 本地CSV数据存储 | 轻量级数据存储 |
| ⏱️ time.sleep() | 程序暂停执行 | 控制爬取节奏 |
| 📈 FineBI | 数据可视化分析 | 企业级BI工具 |
环境配置💻
# 安装依赖📦
pip install DrissionPage pandas sqlalchemy pymysql
# 首先执行以下两行代码,(首次运行) 运行完毕即可注释🖥️
# path = r'C:\Program Files\Google\Chrome\Application\chrome.exe' #路径为chrome浏览器的可执行文件
# ChromiumOptions().set_browser_path(path).save()
#
# 导入time模块中的sleep函数📥
from time import sleep
# 导入SQLAlchemy模块中的create_engine函数📥
from sqlalchemy import create_engine
# 导入pandas模块📥
import pandas as pd
# 导入DrissionPage模块中的ChromiumPage类📥
from DrissionPage import ChromiumPage
# 导入csv模块📥
import csv
2. 实现流程 📌
✅ 目标:爬取 20 次 Boss直聘数据,每一次爬取10页(因为boss直聘只展示十页数据,每一页的招聘信息都是随机,无法爬取完整招聘信息只能通过反复爬取来扩大数据量),存入 CSV + MySQL
🔍2.1. 明确需求
- 网址:BOSS直聘
- 数据:全国大数据开发岗位信息
🕵️♂️2.2. 抓包分析
- 目标网页打开开发者工具:F12/右键点击检查选择network(网络)
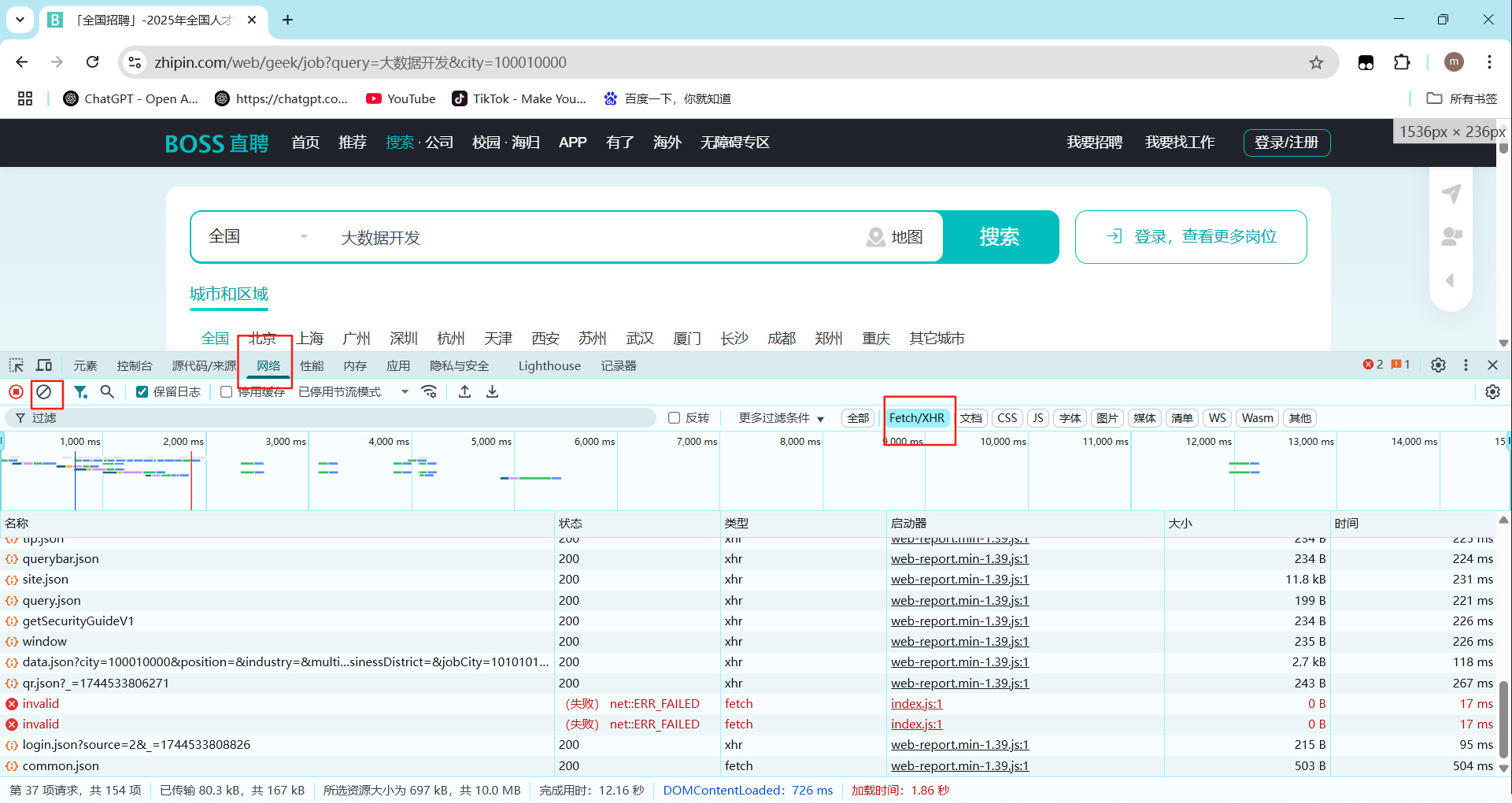
- 刷新网页:加载出完整数据
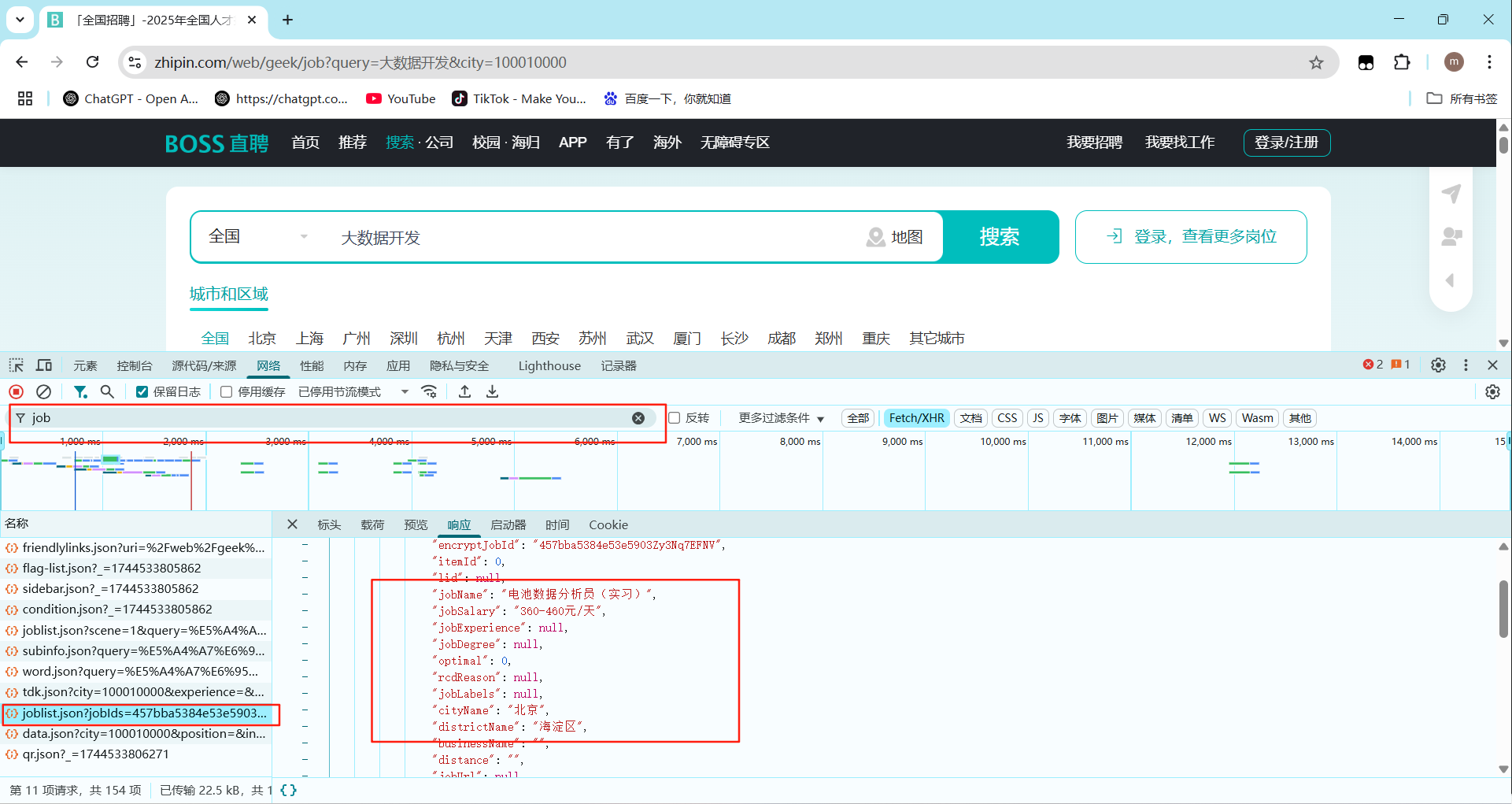
- 通过关键字搜索来找到对应的数据位置
📝2.3. 创建文件对象
# 创建一个文件对象
f = open('data.csv', mode='w', encoding='utf-8', newline='')
# 字典写入方法
csv_writer = csv.DictWriter(f, fieldnames=[
'职位名称',
'公司',
'行业',
'学历',
'经验',
'薪资',
'福利',
'技能要求',
'所在城市',
'区域',
'街道'
])
# 写入表头
csv_writer.writeheader()✅ CSV 数据存储示例
| 职位名称 | 公司 | 行业 | 学历 | 经验 | 薪资 | 福利 | 技能要求 | 所在城市 | 区域 | 街道 |
|---|---|---|---|---|---|---|---|---|---|---|
| 坤神 | aidou | 互联网 | 博士 | 两年半 | 100w | 九险二金 | 唱、跳、rap | xx | xx | xx |
🤖2.4. 数据采集(DrissionPage)
- 浏览器自动化:设置浏览器路径,访问网页
- 监听 API 请求:直接拦截
joblist.json返回的数据 - 翻页逻辑:循环采集20次1-20 页数据
# 设置循环20次🎯
for i in range(20):
# 实例化浏览器对象
dp = ChromiumPage()
# 监听数据包
dp.listen.start('https://www.zhipin.com/wapi/zpgeek/search/joblist.json')
# 访问网站,如需爬取其它岗位信息只需修改‘ ’内链接即可🌐
dp.get(
'https://www.zhipin.com/web/geek/job?query=%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91&city=100010000'
)
# 循环翻页
for page in range(1, 11):
print(f'🚀正在采集第{page}页数据')
# 下滑网页页面到底部
dp.scroll.to_bottom()
# 等待数据加载
resp = dp.listen.wait()
# 获取响应数据
json_data = resp.response.body
# 解析数据
# 提取职位信息所在列表
jobList = json_data['zpData']['jobList']
# for循环遍历,提取列表里面的元素
for index in jobList:
# 提取相关信息数据,保存字典
dit = {
'职位名称': index['jobName'],
'公司': index['brandName'],
'行业': index['brandIndustry'],
'学历': index['jobDegree'],
'经验': index['jobExperience'],
'薪资': index['salaryDesc'],
'福利': ' '.join(index['welfareList']),
'技能要求': ' '.join(index['skills']),
'所在城市': index['cityName'],
'区域': index['areaDistrict'],
'街道': index['businessDistrict']
}
print(dit)
# 写入数据
csv_writer.writerow(dit)
# 点击下一页
print(f'第{page}页写入完成')
dp.ele('css:.ui-icon-arrow-right').click()
sleep(3) # 等待3秒🗃️2.5. 存储到MySQL
- 读取csv文件
- 将读取的csv文件转成DataFrame
- 创建数据库连接:需要设置账户:密码,数据库名
- 将DataFrame导入到数据库:设置表名
# 读取csv文件📄
read_csv = pd.read_csv('data.csv')
# 将读取的csv文件转换为DataFrame
df = pd.DataFrame(read_csv)
# 创建数据库连接🔌
conn =create_engine('mysql+pymysql://root:密码@localhost:3306/数据库名?charset=utf8')
# 将DataFrame导入数据库💾
df.to_sql('表名', con=conn, if_exists='append', index=False)
print('🎉导入数据库成功')2.6. 数据可视化分析(FineBI)

- 下载安装FineBI:免费下载FineBI - FineBI自助大数据分析工具
- 安装教程:FineBI个人试用版安装指南- FineBI帮助文档 FineBI帮助文档
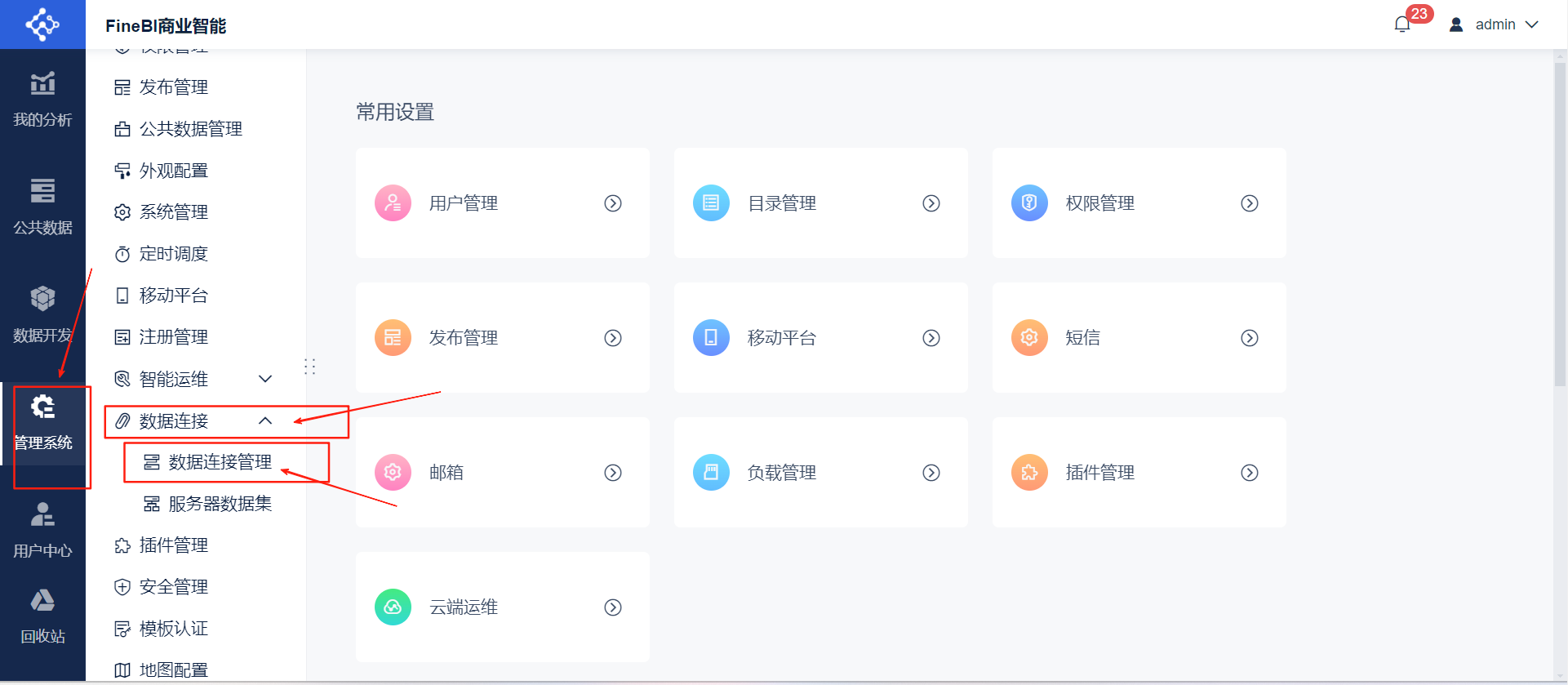
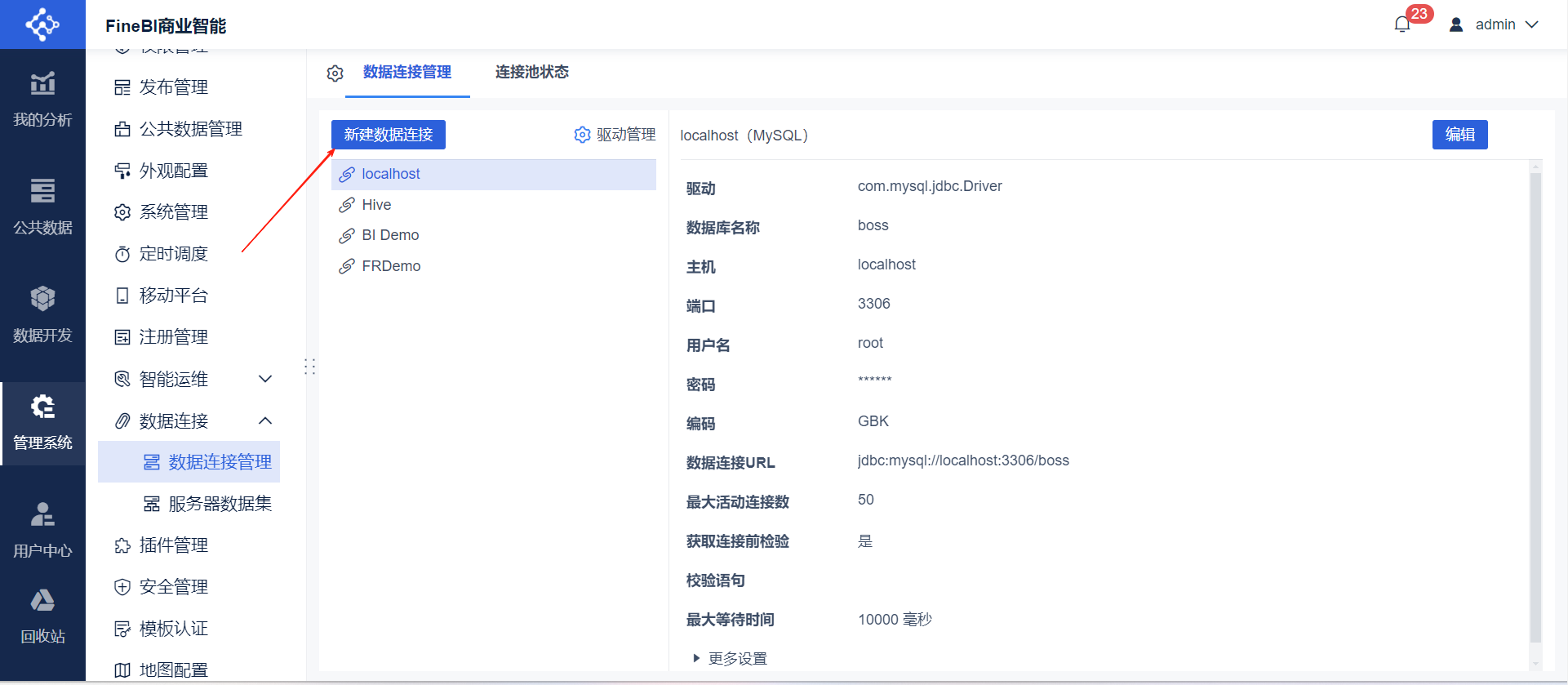
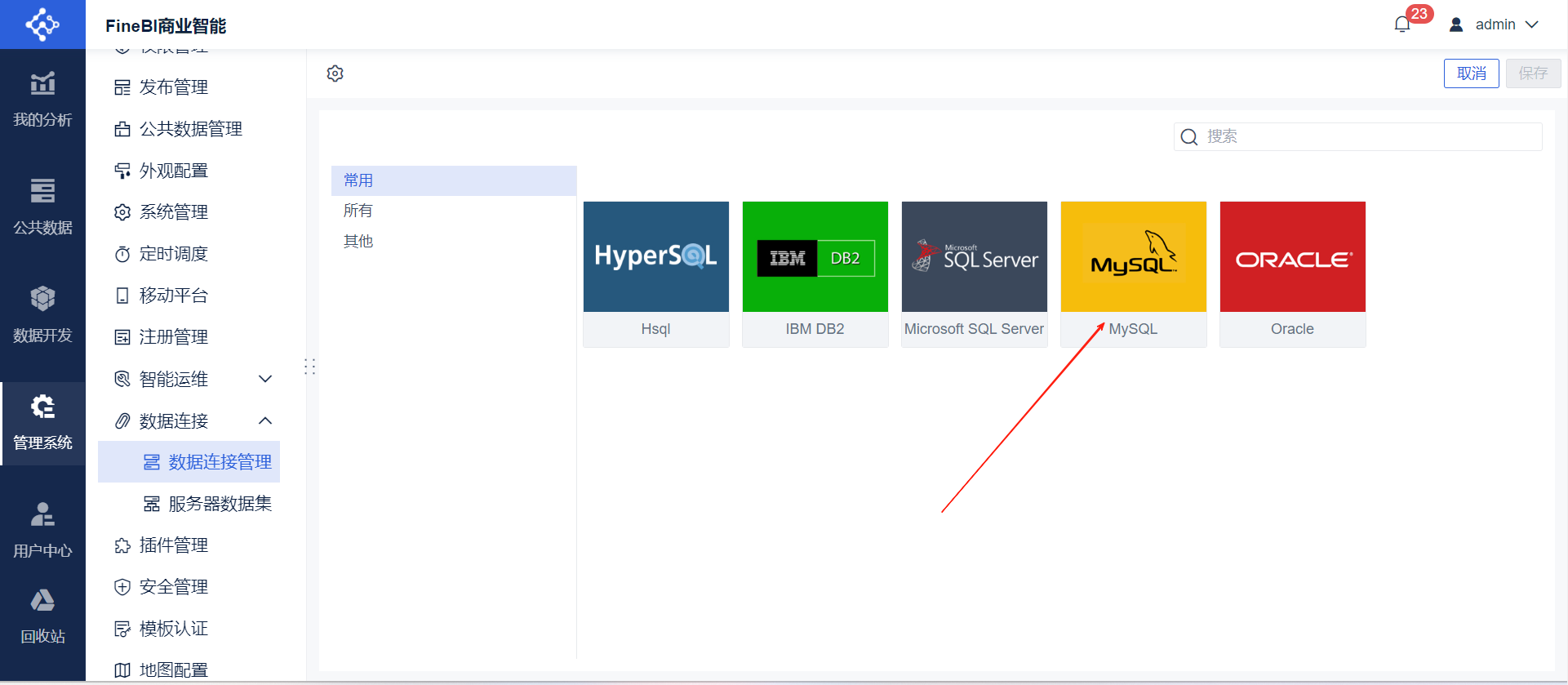
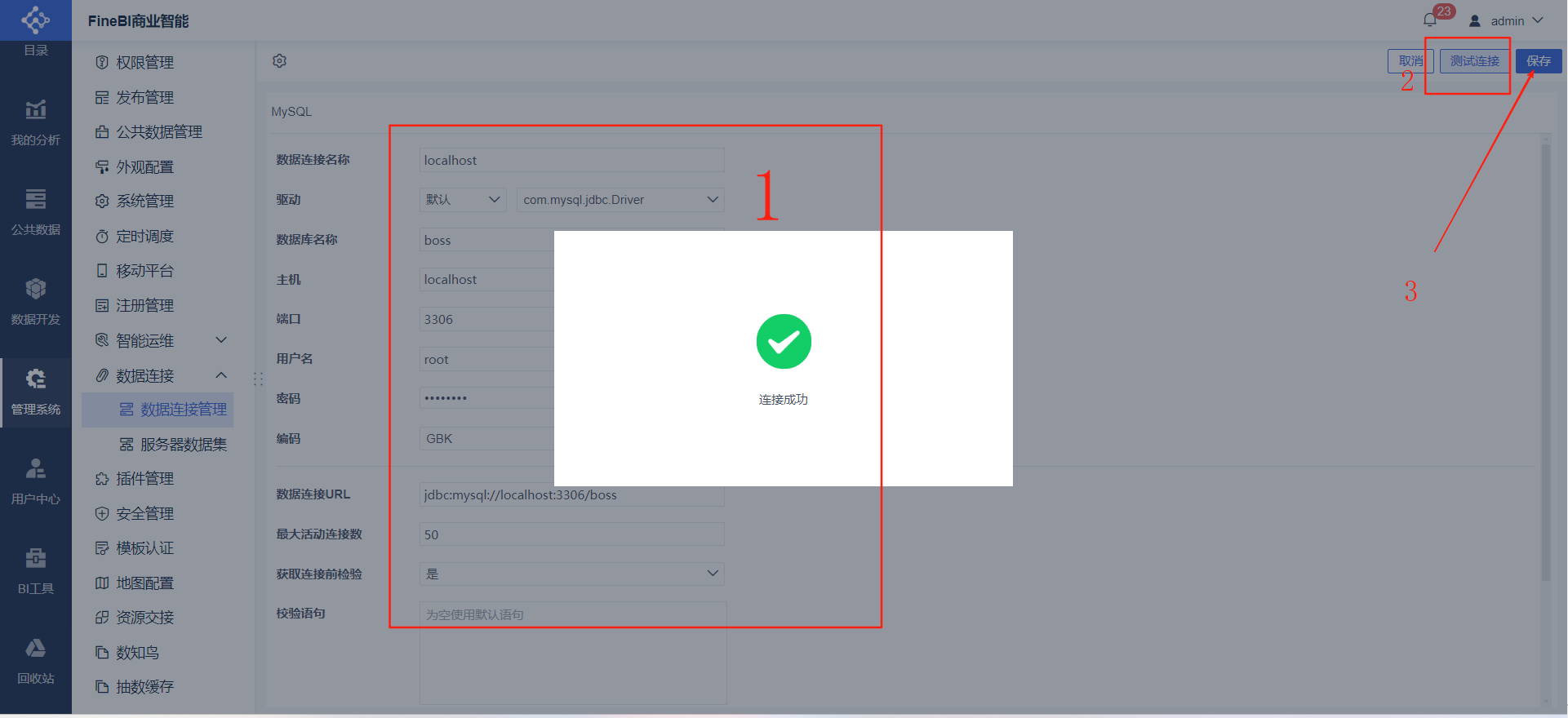
- 数据库连接:进入主页后点击管理系统➡数据连接➡数据连接管理➡新建数据连接➡选择MySQL➡完善数据库信息点击测试连接➡保存
- 导入数据集:点击公共数据➡新建文件夹并命名
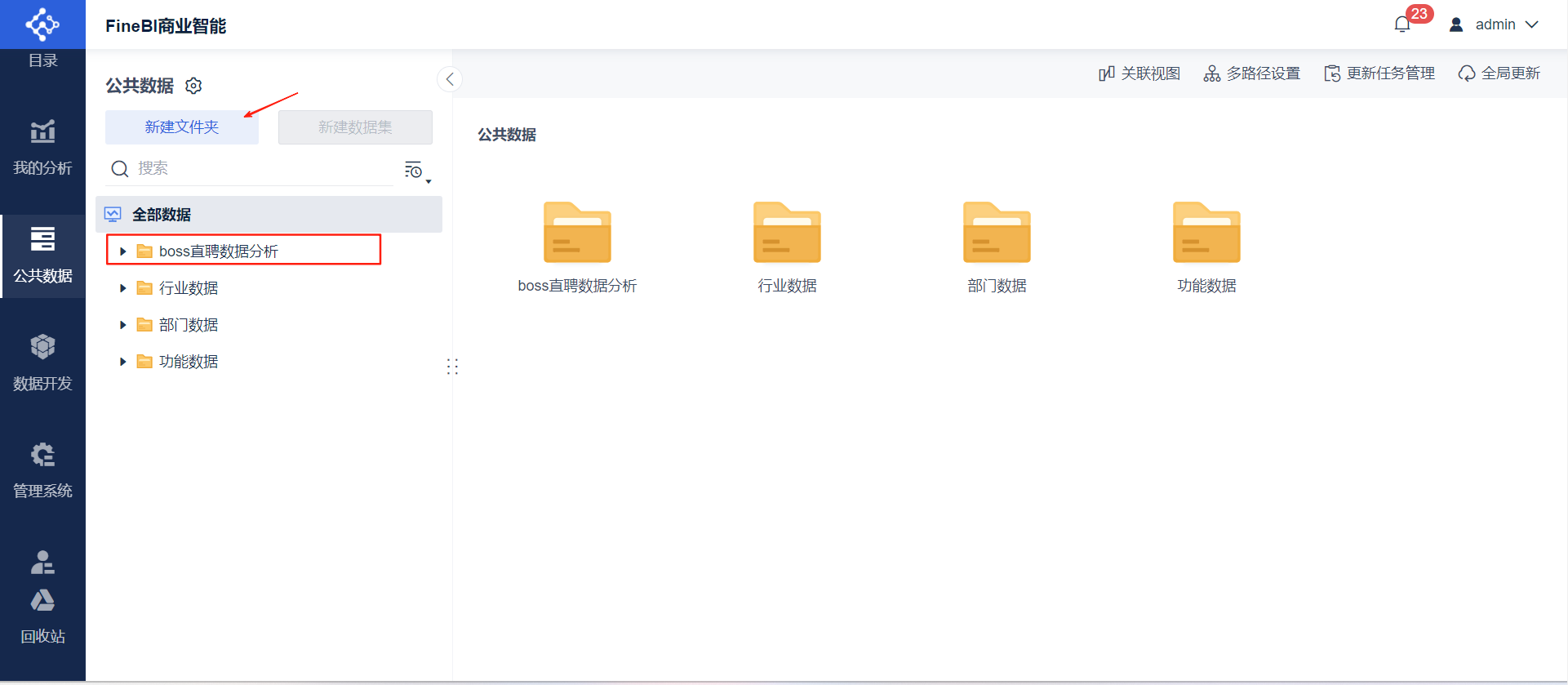
- ➡选择文件夹新建数据集
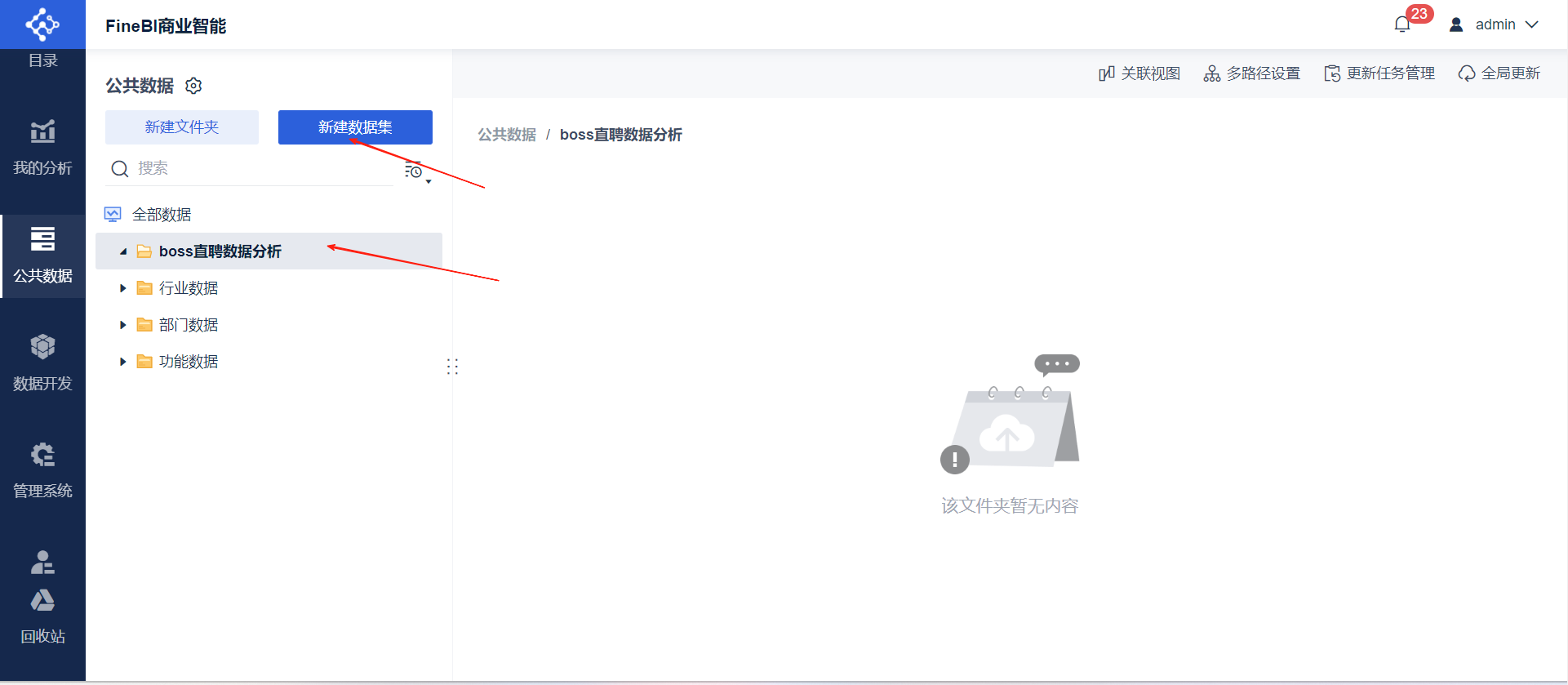
- ➡选择数据库表
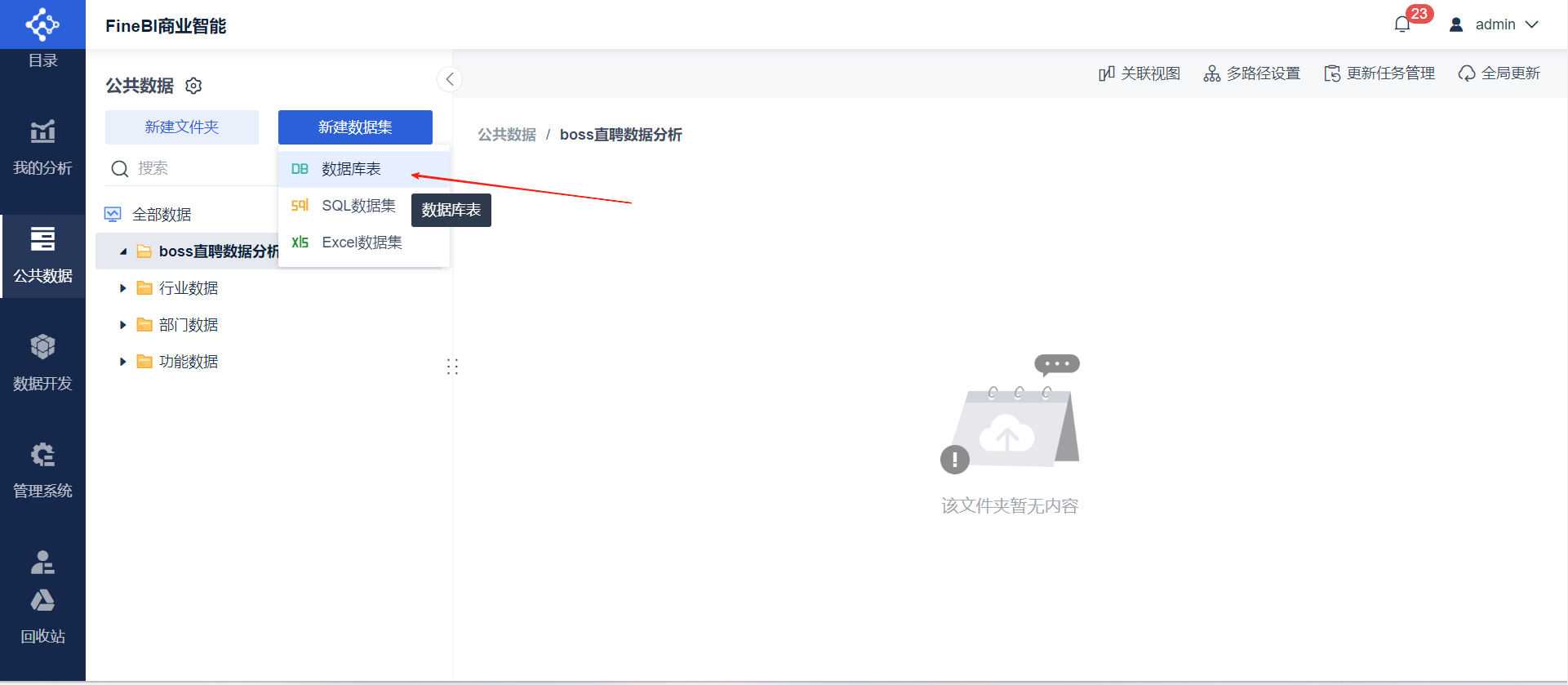
- ➡选择存取数据的数据库表
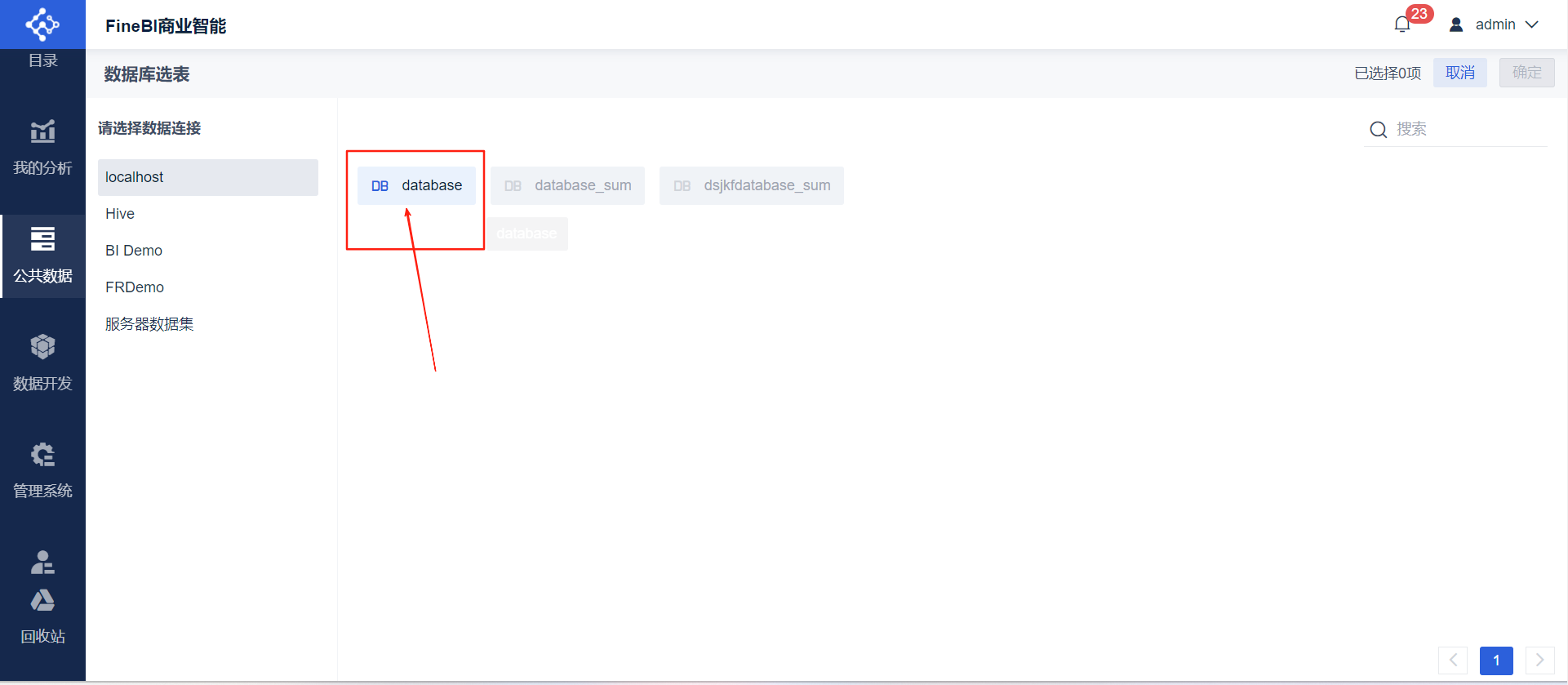
- 准备分析:点击我的分析➡新建文件夹
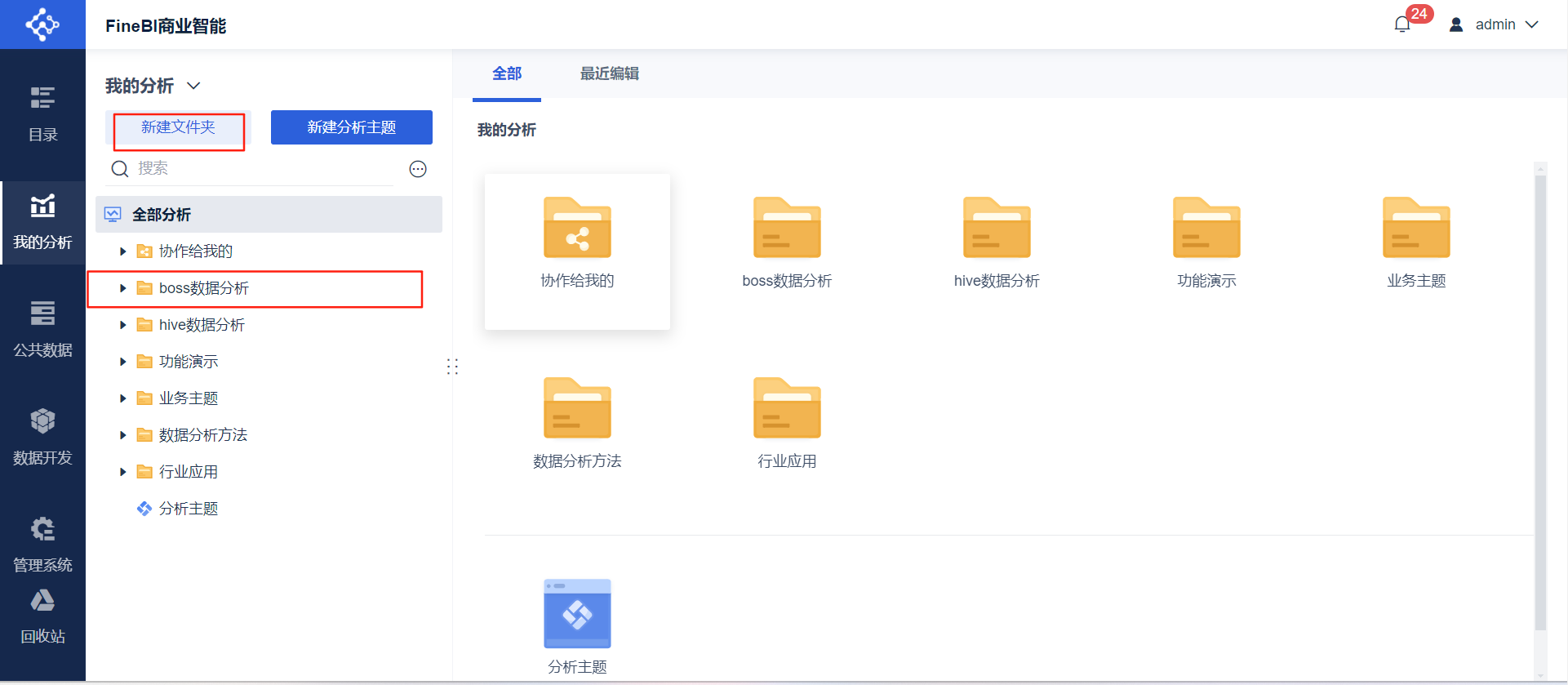
➡新建分析主题
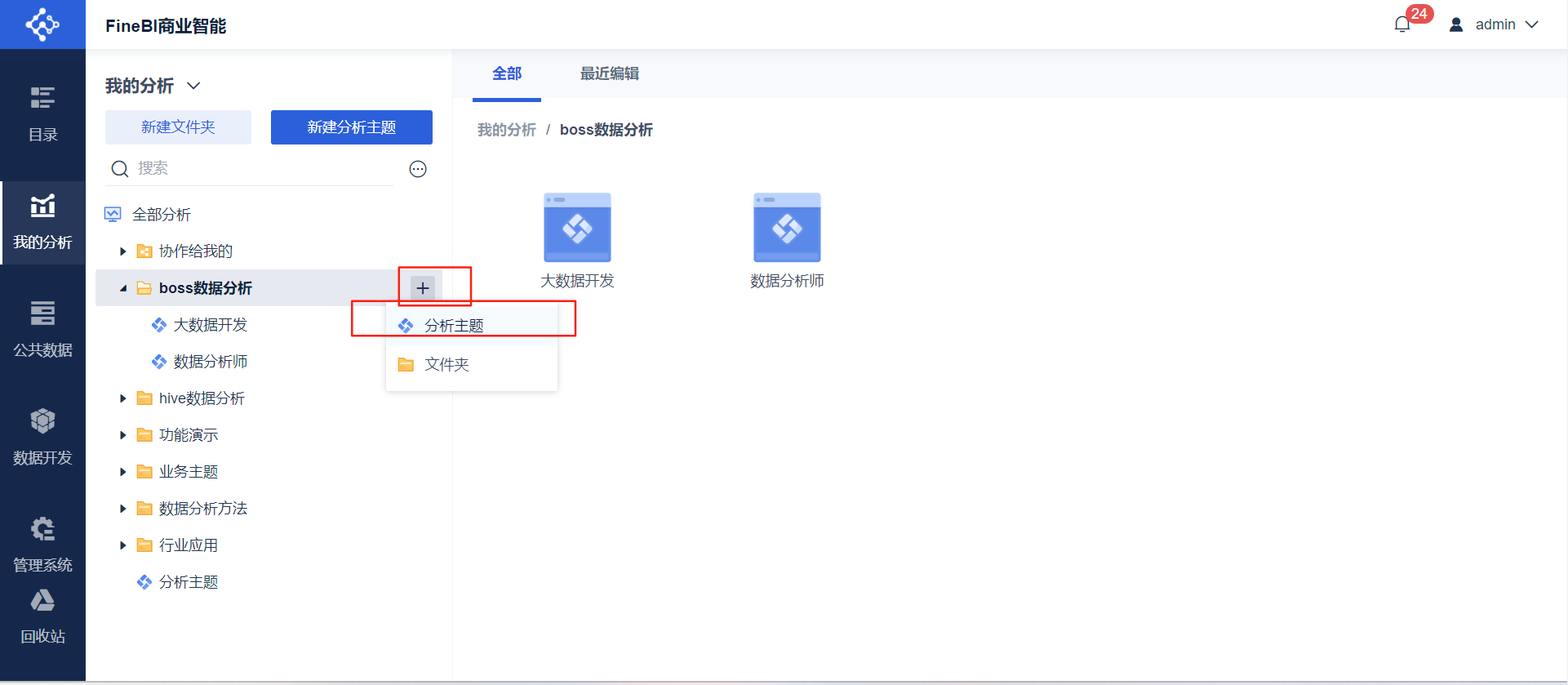
➡选择文件夹下导入的数据➡点击确定
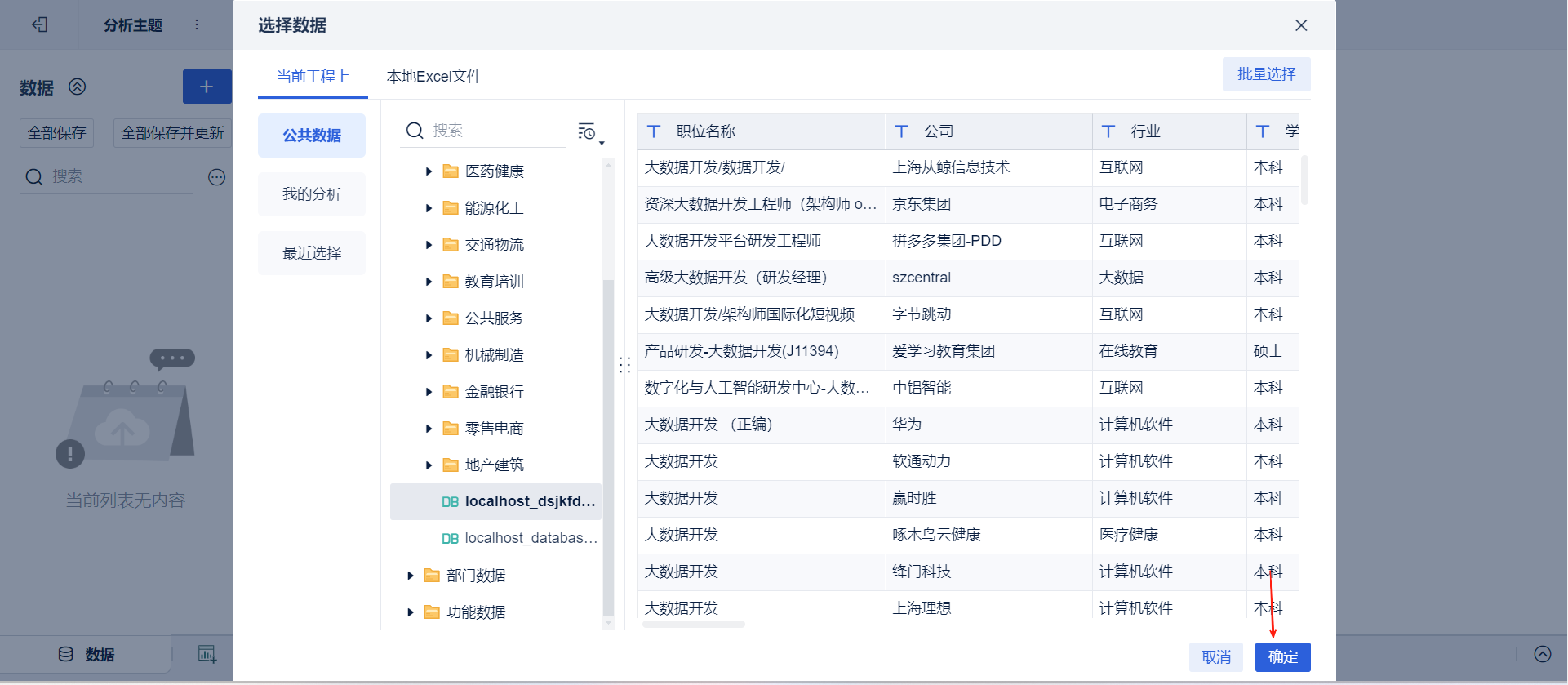
- 绘制图表:点击新建组件
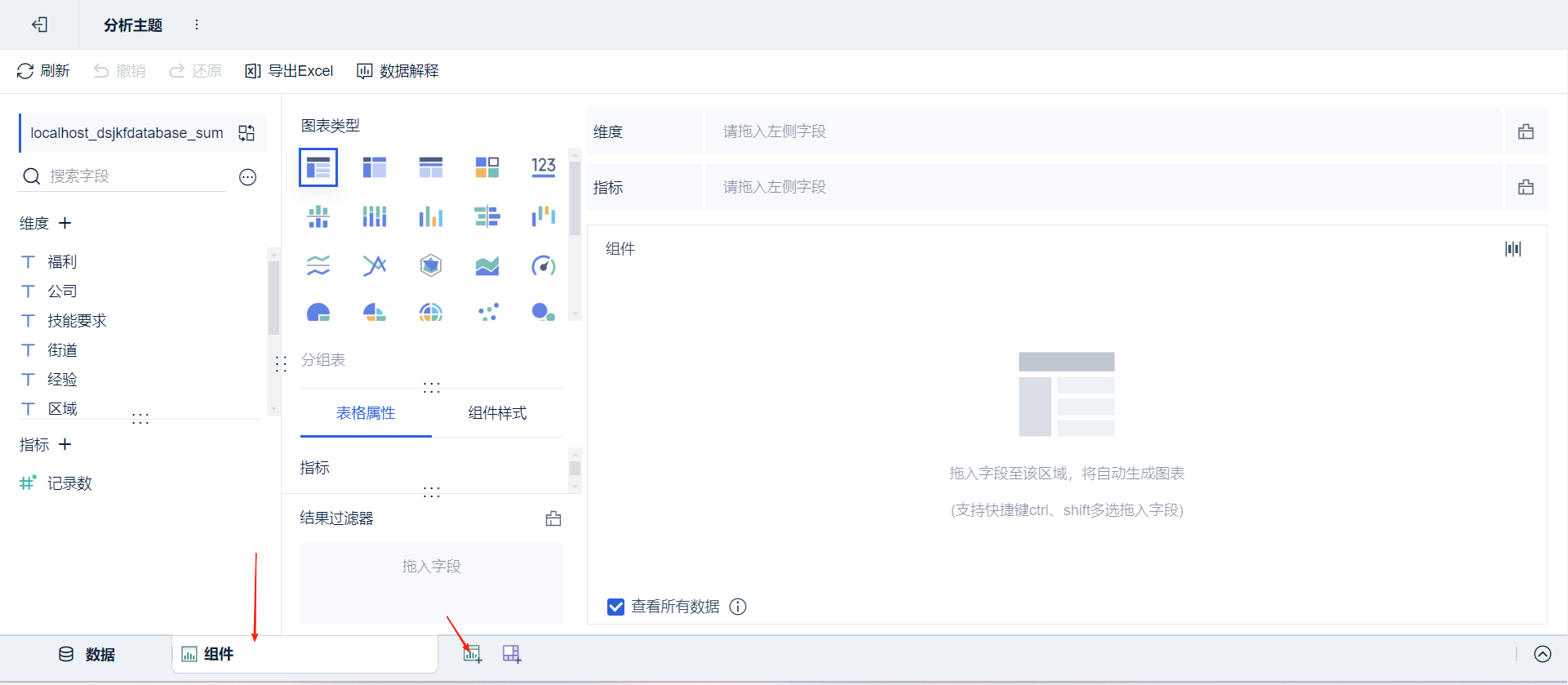
➡通过拖拽字段放置
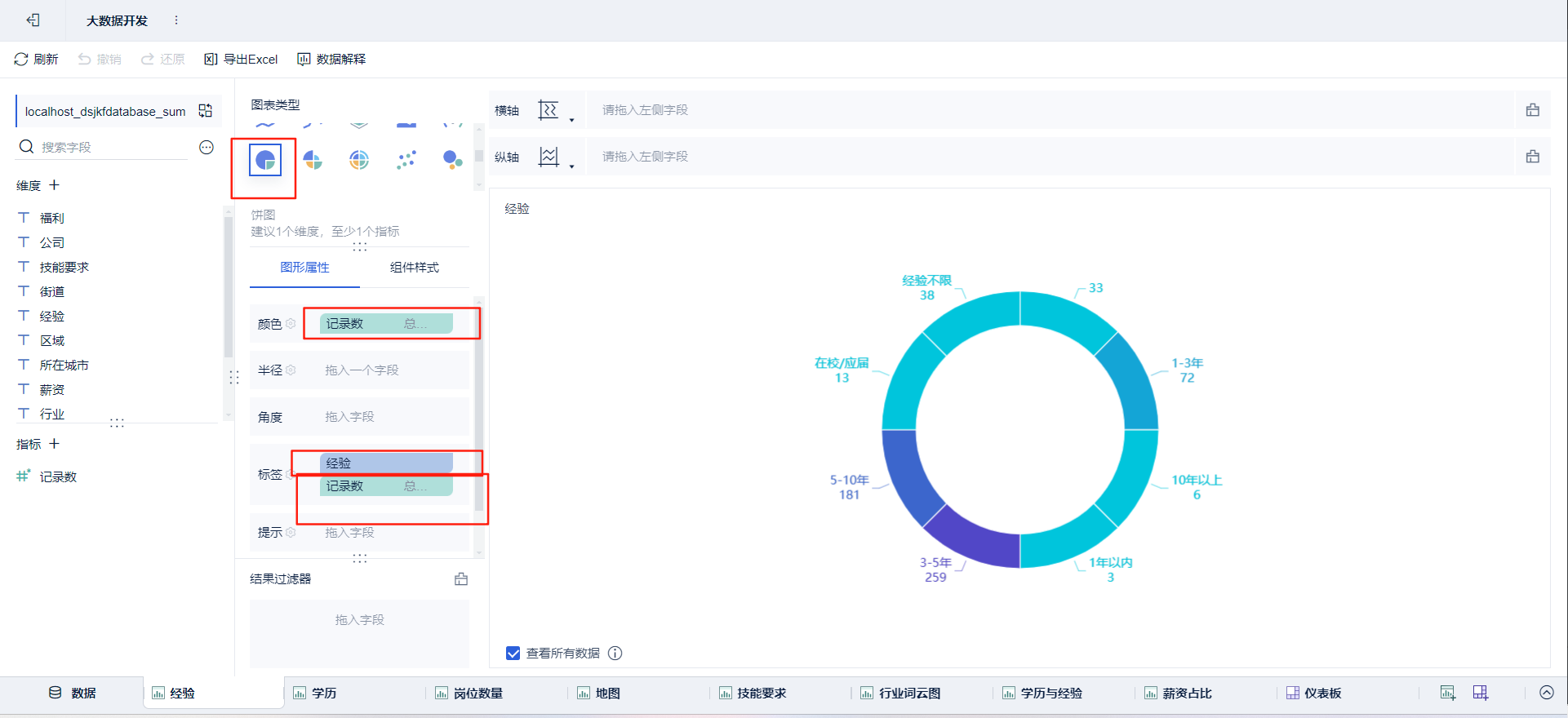
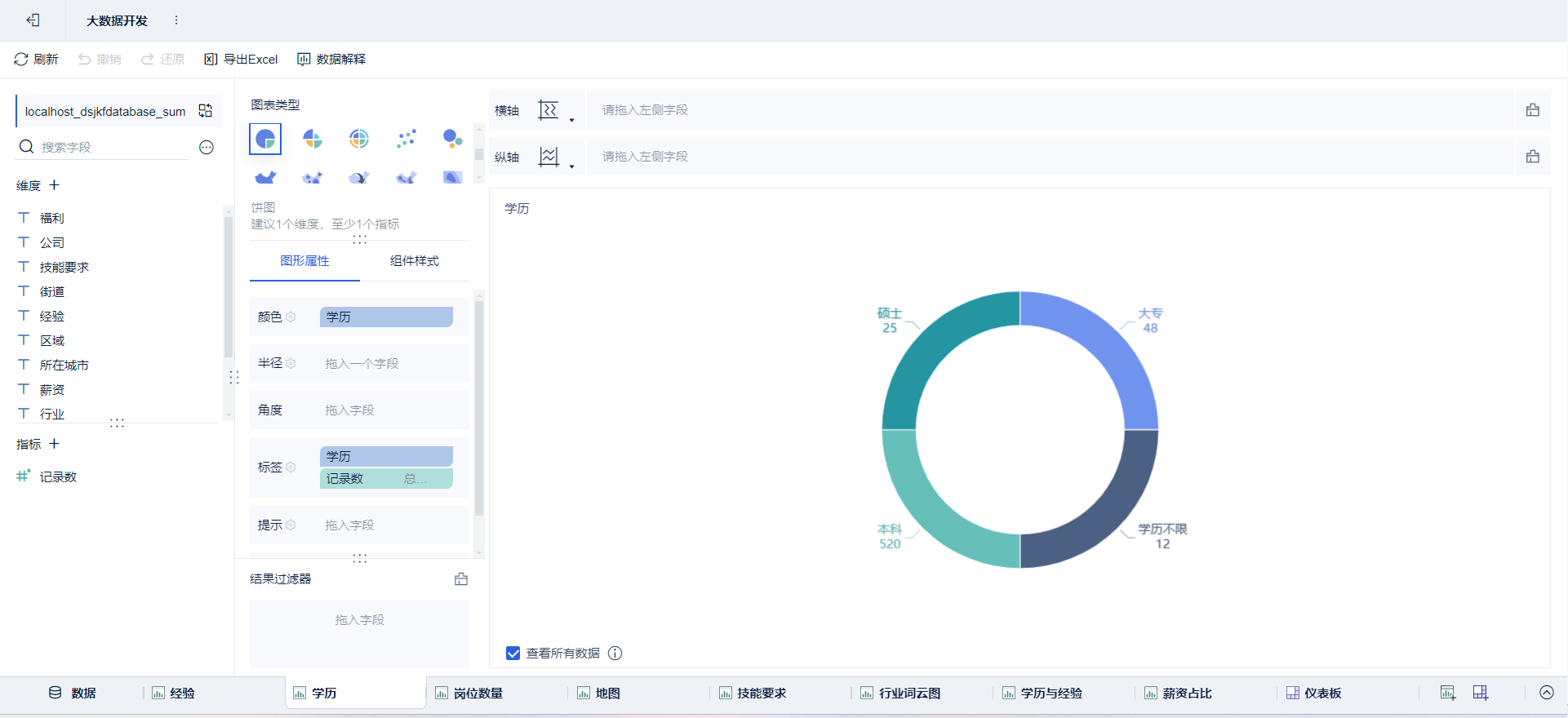
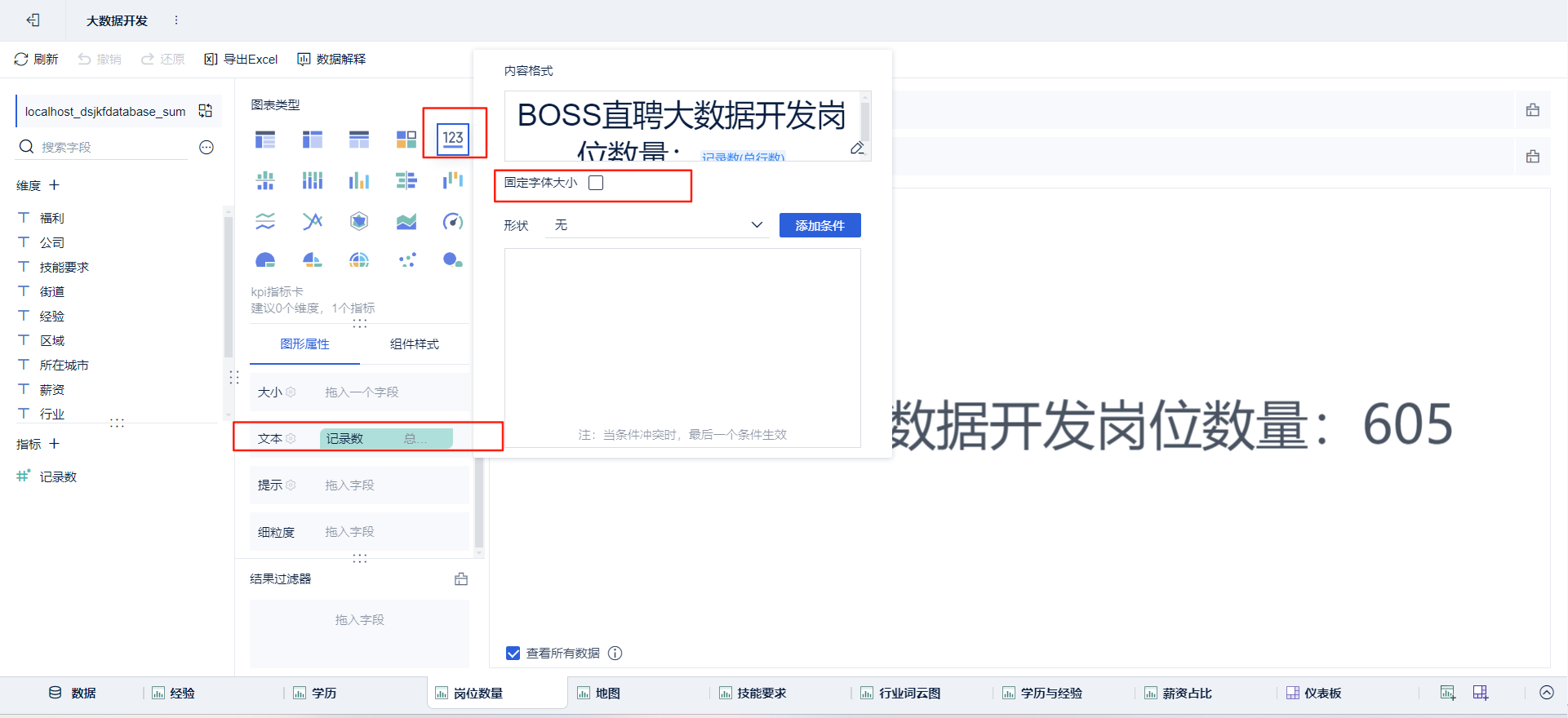
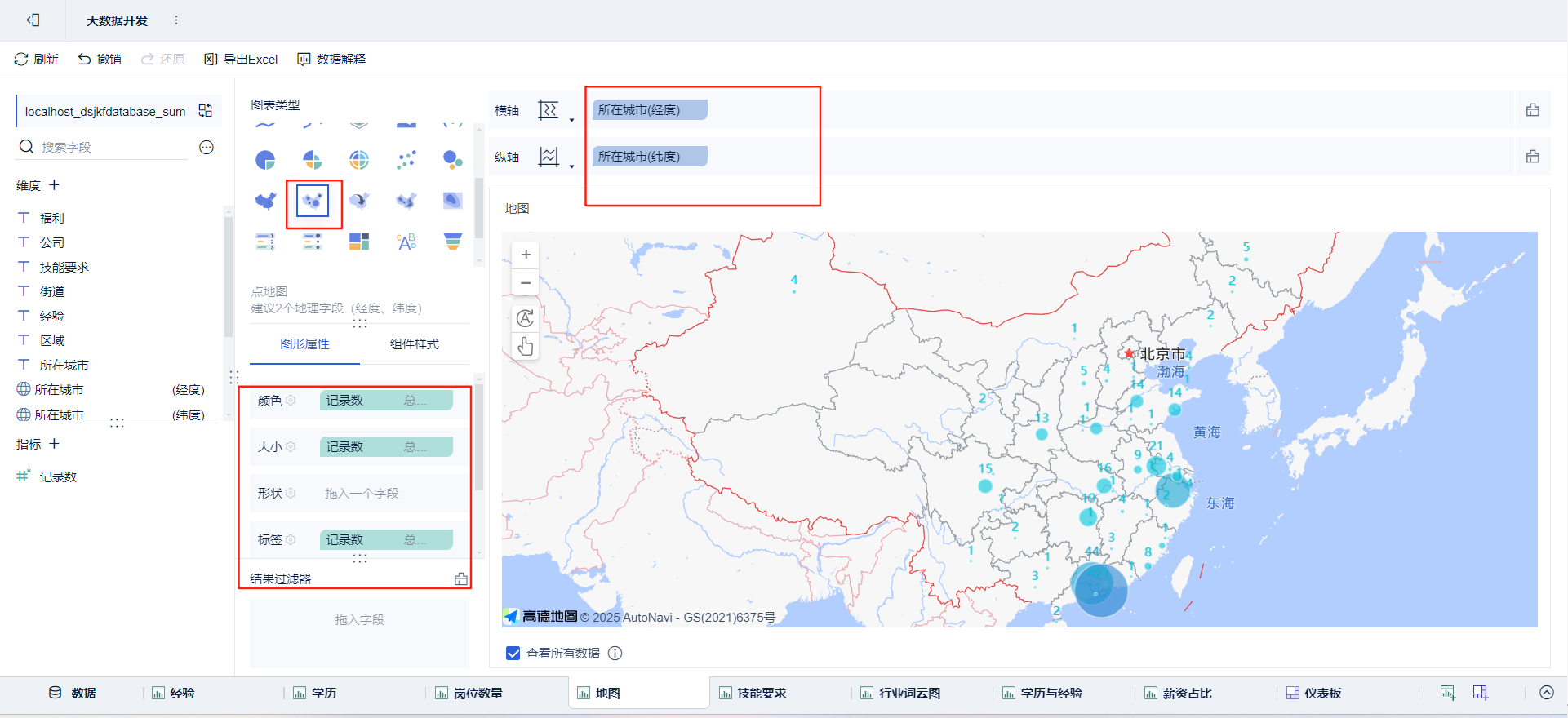
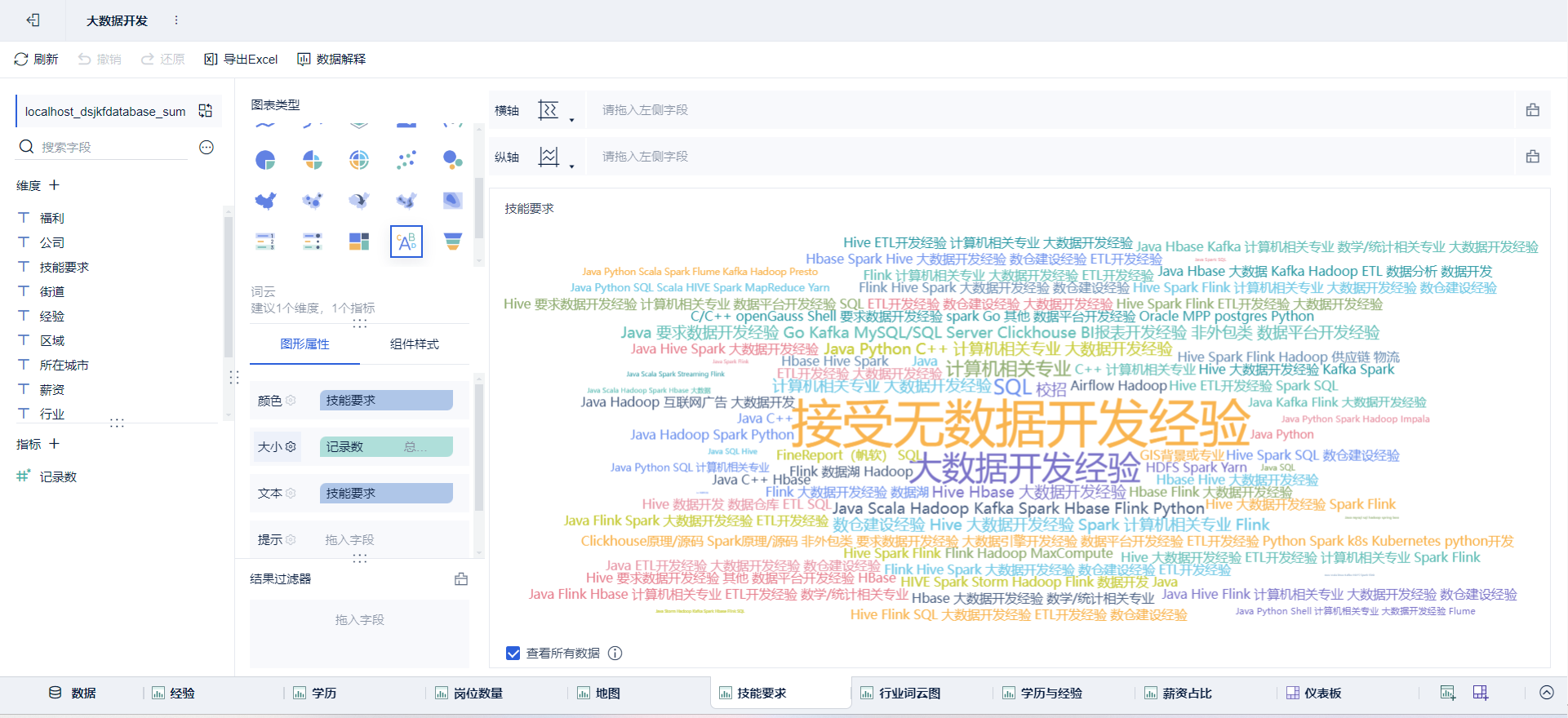
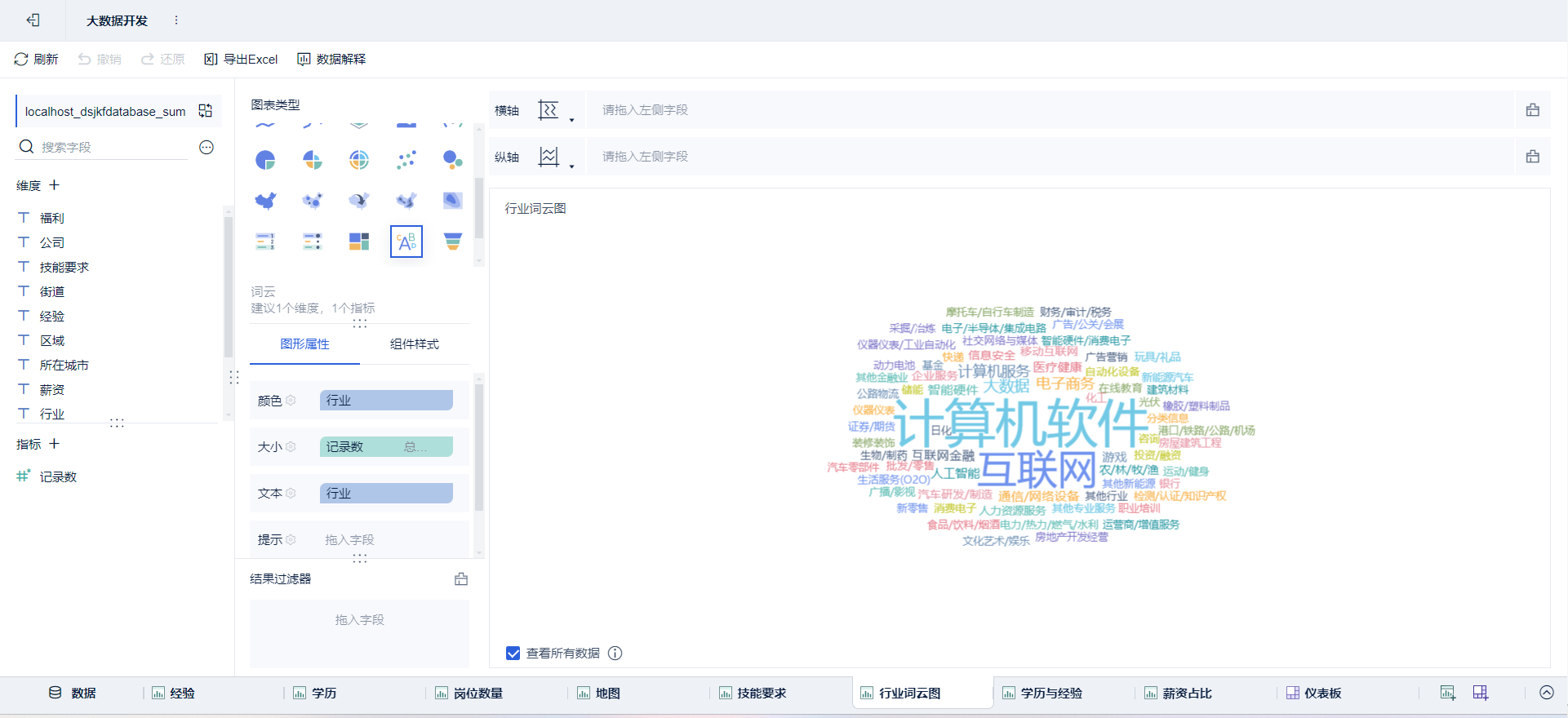
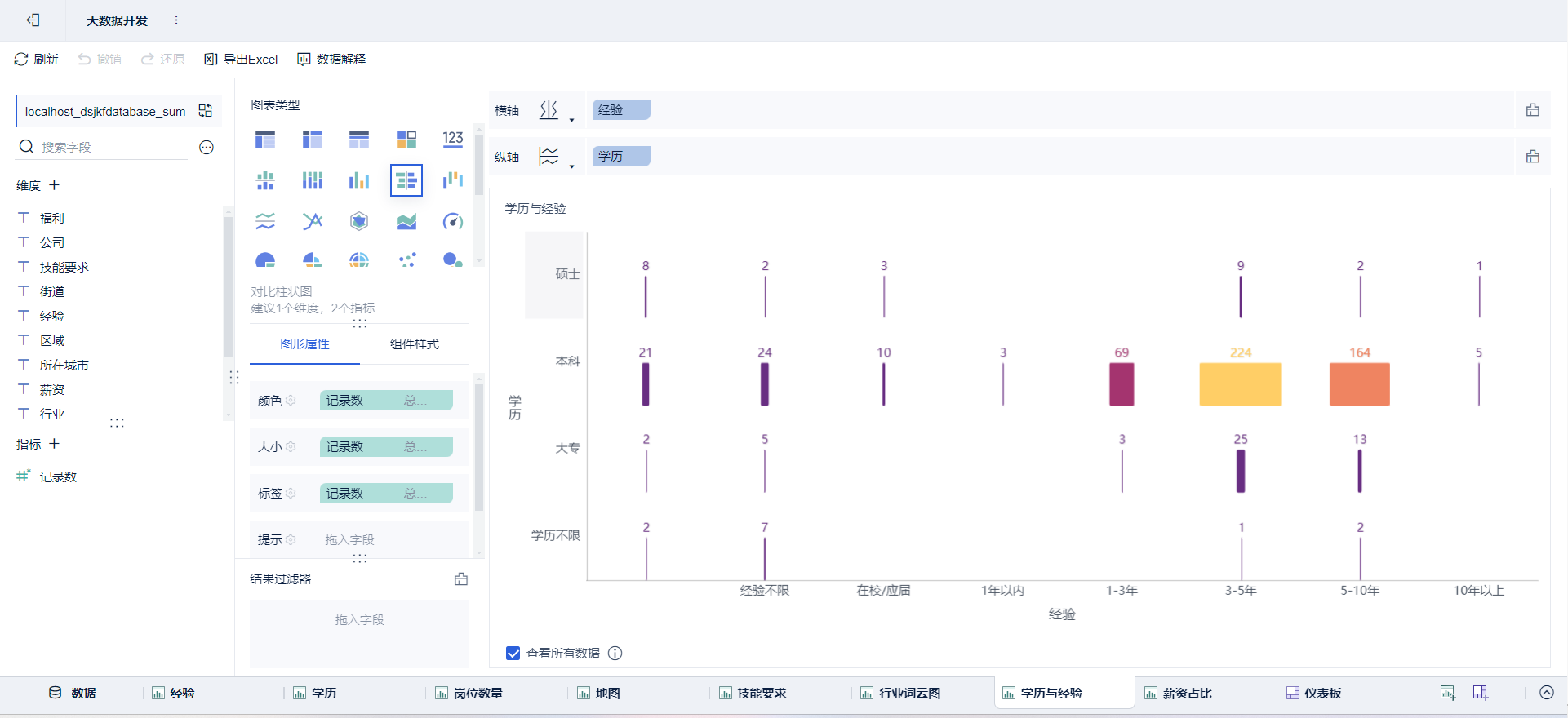
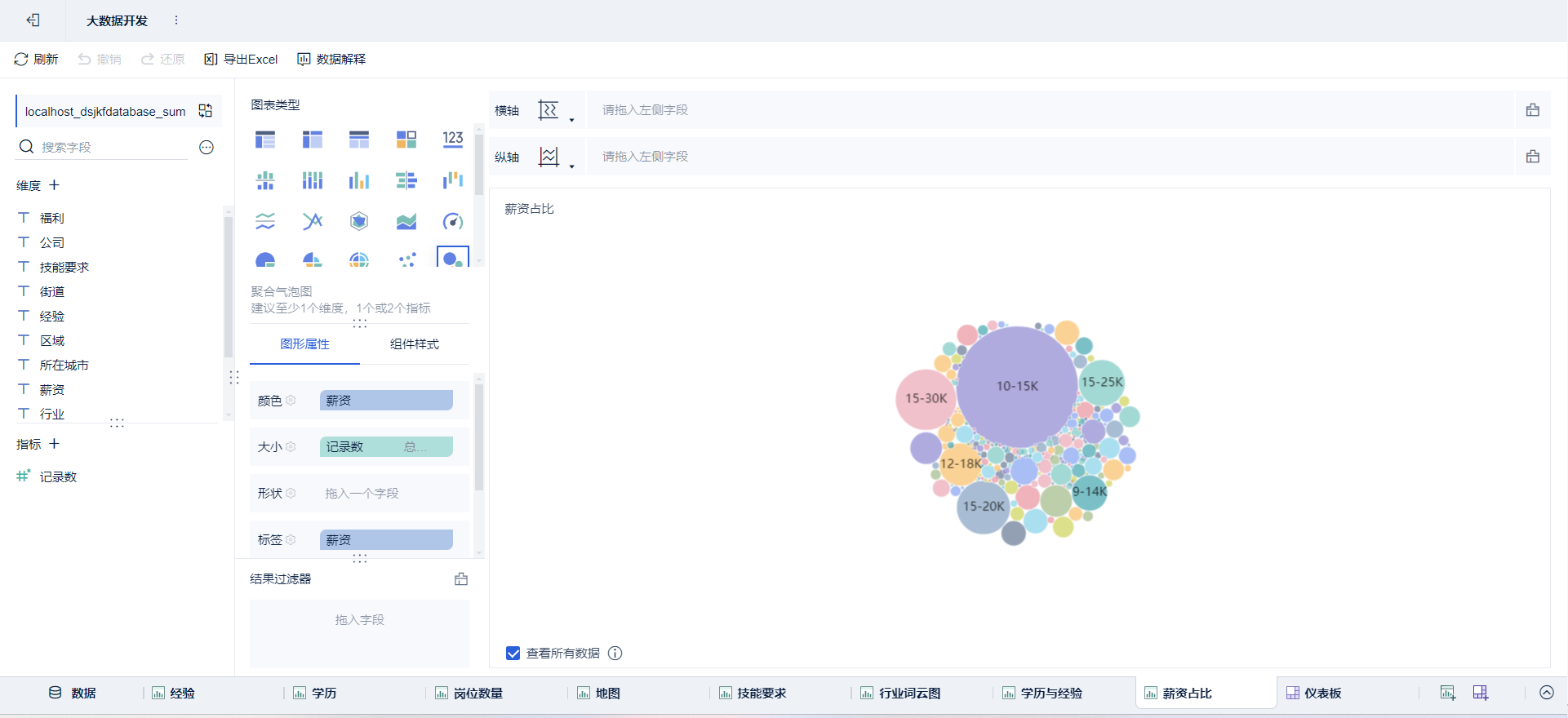
绘制可视化大屏:点击新建仪表板,将绘制好的组件放进去并布局
最终成果:
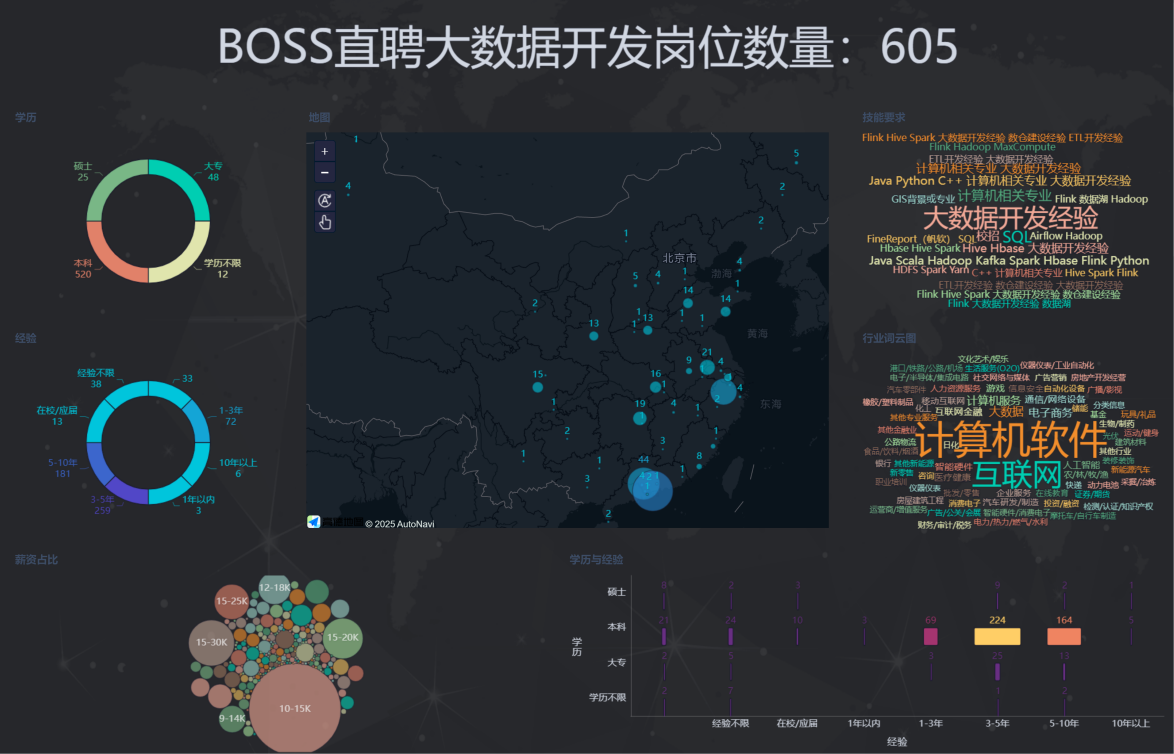
🏁3. 总结
🚀 技术点掌握:
- DrissionPage 接口监听(替代传统爬取方式)
- JSON 数据解析与存储
- pandas 数据处理 & SQL 存储
🛠 下一步优化:
✓ 增加代理(防止 IP 被封)
✓ 增加数据清洗(去除重复数据)
✓ 封装成独立爬虫(持续增量爬取) - 📌 FineBI 优势: ✔ 零代码分析(适合非技术人员)
✔ 强大的数据处理能力(ETL + 数据建模)
✔ 国产化支持(符合国内企业需求)
📌 小贴士: 请遵守网站爬取规则,合理控制请求频率!

















 1737
1737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









