









网站: 阳光开奖
目的: 爬取近100期的开奖信息
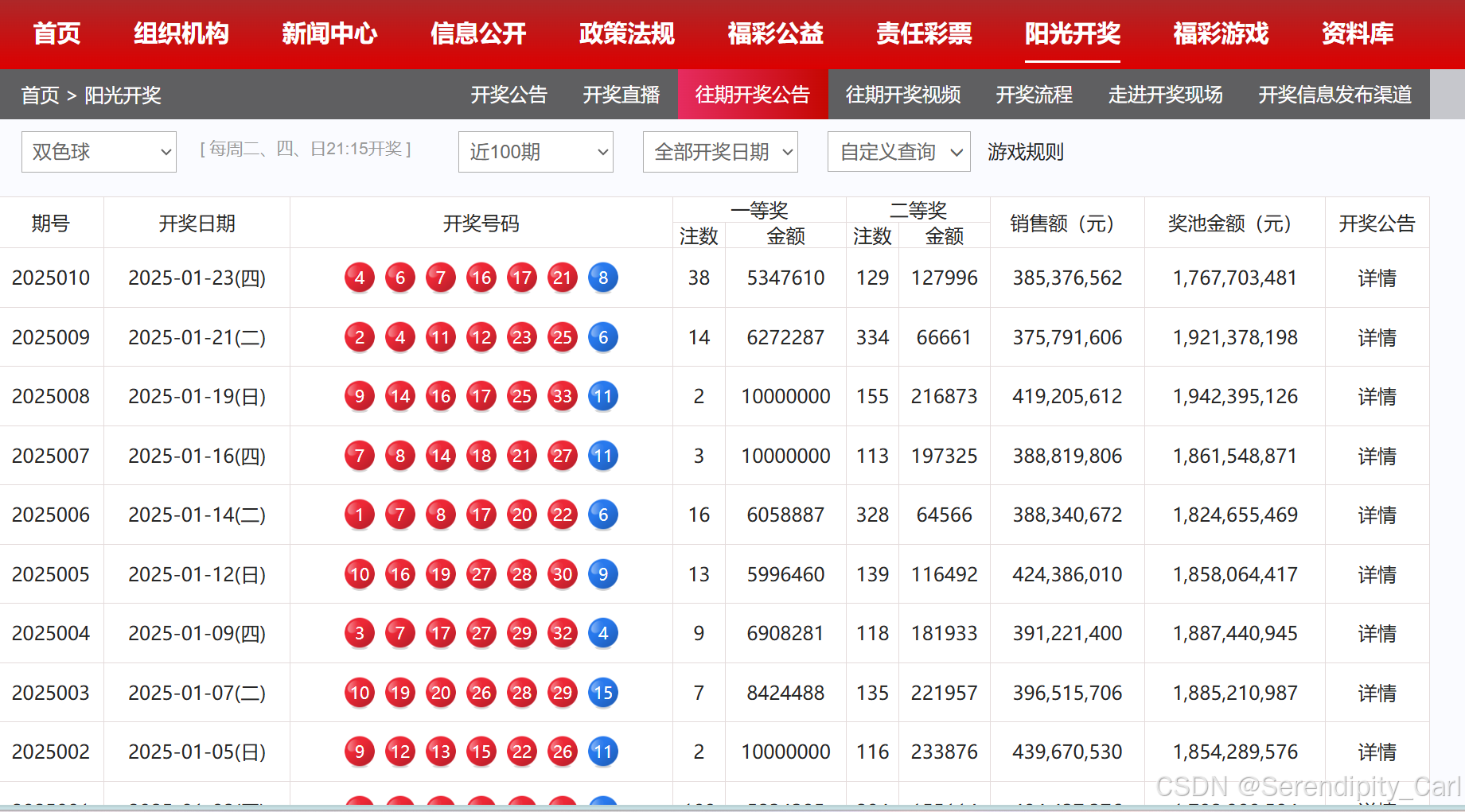
一.分析网页 确定包含我们所需要数据的数据包
F12 or 右击检查 打开开发者工具 点击网络(network) 刷新此网页
接着我们点击动态数据 XHR 将数据包清空 最后点击选择100期
监听到此数据包就为我们所需要的
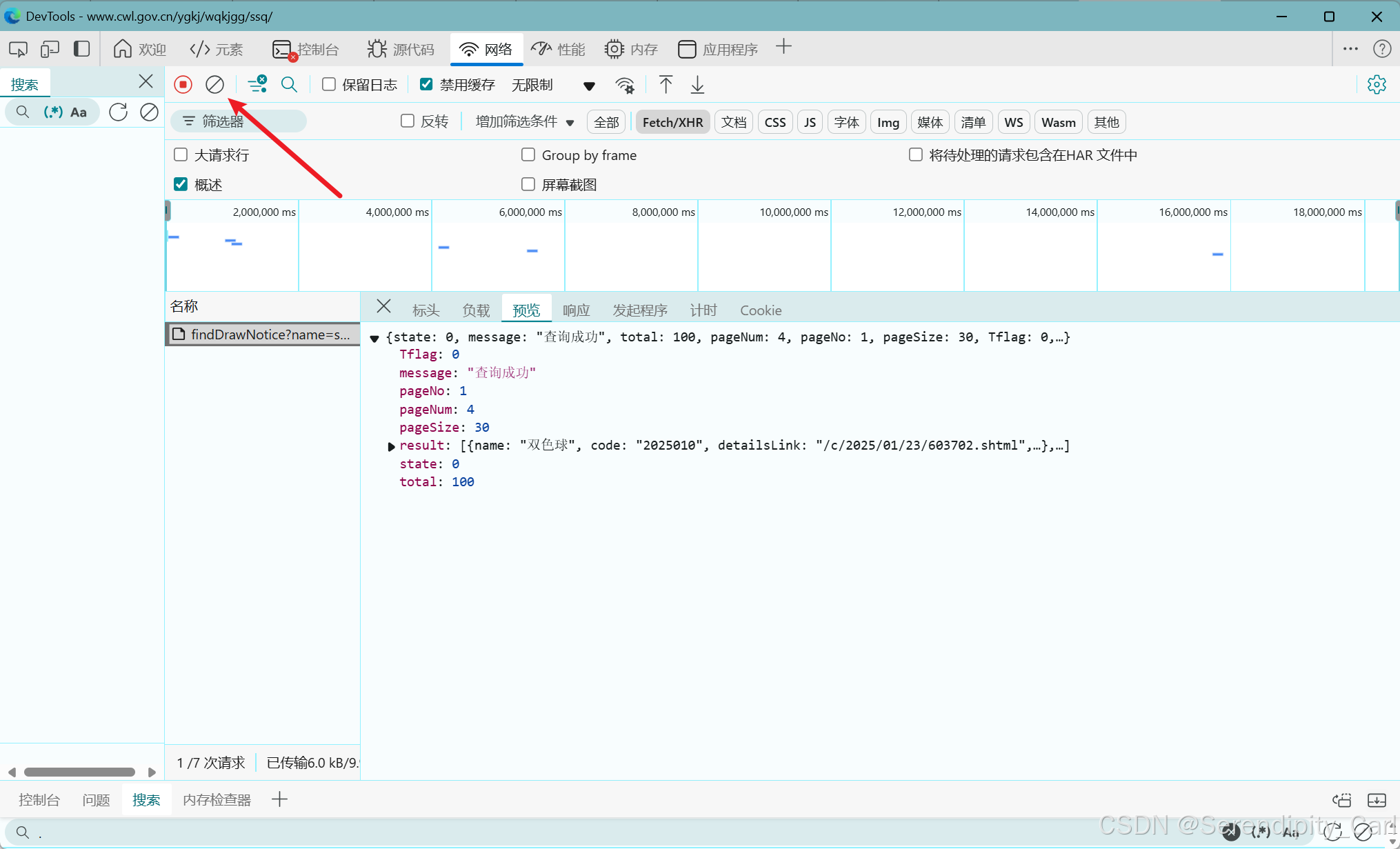
二.发送请求 模拟浏览器向服务器发送请求
Explain(headers基本的请求头):
-
UA --user-agent 包含了浏览器的基本信息 如载荷 什么浏览器 版本等
-
cookies: 用户的基本信息
-
host:域名
-
referer: 防盗链 页面跳转的初始网址
请求方式 GET or post
目的是将我们的python程序模拟成浏览器 向服务器拿数据 得到响应
右击此数据包 复制cURL(bash) 注意不要复制错了
到爬虫工具库-spidertools.cn 打开并复制到本地py文件
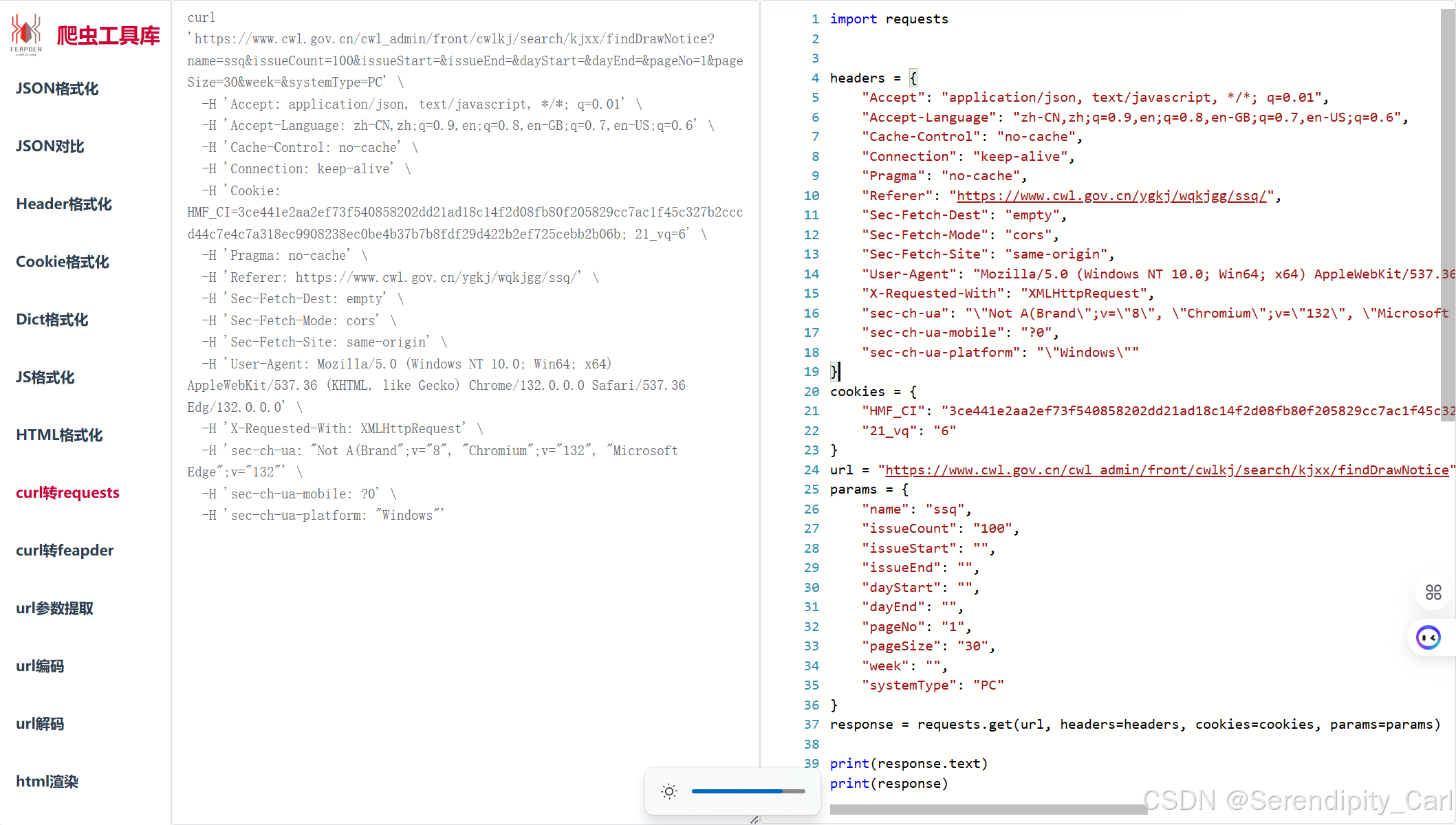
三. 获取数据
- response.text() 获取响应体的文本数据 比如源代码
- response.json() 获取JSON 格式的数据(动态数据 由服务器返回给前端的)
- response.content() 获取响应体的二进制数据 比如保存图片 音频 视频等
如果数据存在加密(cookie加密 关键字加密 md5 aes 非对称加密 瑞树 akaimai)或反爬(基本的上代理 过验证码 页面交互检测等等) 需要逆向 或者用自动化模块(简单的) 过风控
这里我们获取 json格式的数据即可 原因是服务器返回给前端页面的数据为json
import requests
import pprint
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Referer": "https://www.cwl.gov.cn/ygkj/wqkjgg/ssq/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"X-Requested-With": "XMLHttpRequest",
"sec-ch-ua": "\"Not A(Brand\";v=\"8\", \"Chromium\";v=\"132\", \"Microsoft Edge\";v=\"132\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
cookies = {
"HMF_CI": "3ce441e2aa2ef73f540858202dd21ad18c14f2d08fb80f205829cc7ac1f45c327b2cccd44c7e4c7a318ec9908238ec0be4b37b7b8fdf29d422b2ef725cebb2b06b",
"21_vq": "6"
}
url = "https://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice"
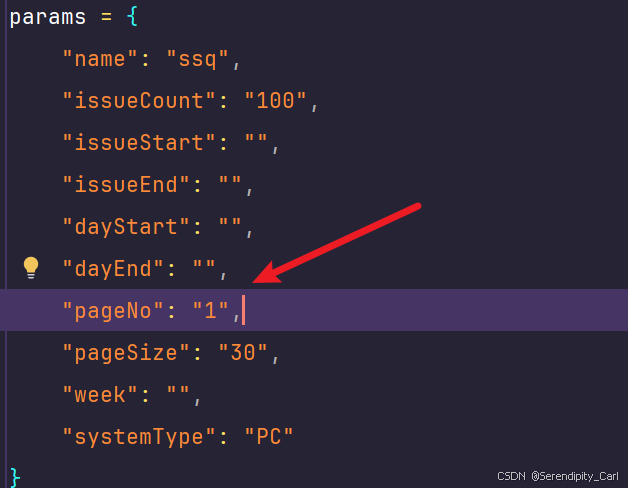
params = {
"name": "ssq",
"issueCount": "100",
"issueStart": "",
"issueEnd": "",
"dayStart": "",
"dayEnd": "",
"pageNo": "1",
"pageSize": "30",
"week": "",
"systemType": "PC"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params).json()
pprint.pprint(response)这里有个pprint 模块 方便格式化打印 json格式的数据 使用方法如上
四.解析提取数据 -- 从爬取下来的数据中得到自己想要的
常见的解析模块有:
- re正则表达式
- css选择器
- Xpath
- parsel(集合了前三种模块)
- bs64(已经沉沦 不再使用 版本许久未更新了)
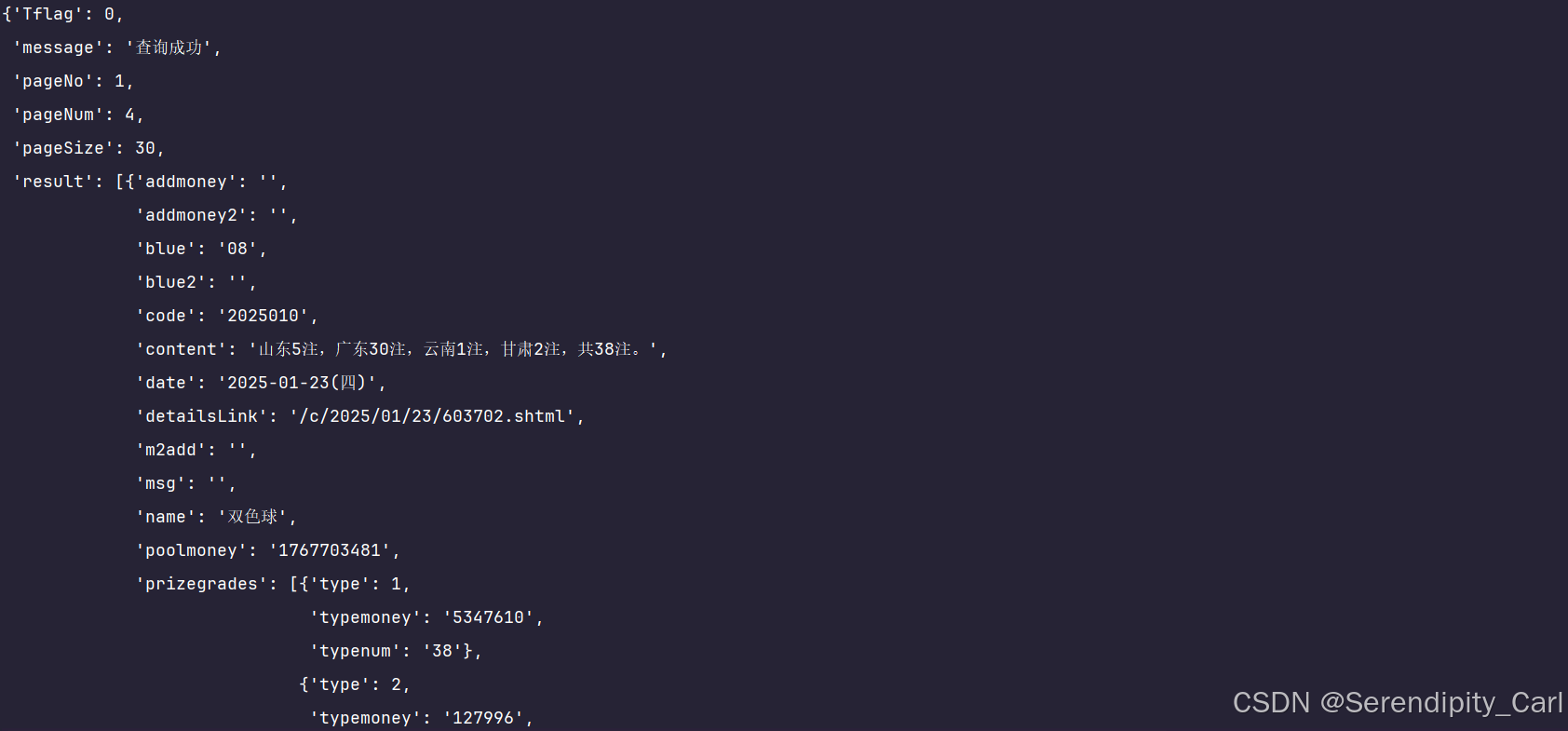
通过键值对 取数据 用字典存储提取的数据
json_data = response['result']
# for 循坏遍历数组
for i in json_data:
dit = {
'期号': i['code'],
'开奖日期': i['date'],
'红球': i['red'],
'蓝球': i['blue'],
'一等奖中奖注数': i['prizegrades'][0]['typenum'],
'一等奖奖金': i['prizegrades'][0]['typemoney'],
'二等奖中奖注数': i['prizegrades'][1]['typenum'],
'二等奖奖金': i['prizegrades'][0]['typemoney'],
'三等奖中奖注数': i['prizegrades'][2]['typenum'],
'三等奖奖金': i['prizegrades'][0]['typemoney'],
'四等奖中奖注数': i['prizegrades'][3]['typenum'],
'四等奖奖金': i['prizegrades'][0]['typemoney'],
'五等奖中奖注数': i['prizegrades'][4]['typenum'],
'五等奖奖金': i['prizegrades'][0]['typemoney'],
'六等奖中奖注数': i['prizegrades'][5]['typenum'],
'六等奖奖金': i['prizegrades'][0]['typemoney'],
'七等奖中奖注数': i['prizegrades'][6]['typenum'],
'七等奖奖金': i['prizegrades'][0]['typemoney'],
'一等奖中奖地区': i['content'],
'奖池金额':i['poolmoney']
}如果以后解析复杂的JSON格式数据的话可以打开那个爬虫工具库 点第一个格式化json数据 可以复制路径 非常地方便
多页爬取数据的话 在params里面有个参数 修改嵌套for循坏即可 或者设置pagesize为想要爬取的条数
五. 保存数据
- csv格式
- excel格式
- 数据库
基本的三种保存方式
第一种
import csv
f = open('ssq.csv','a',encoding='utf-8',newline='')
csvwriter = csv.DictWriter(f,fieldnames=['期号','开奖日期','红球','蓝球','一等奖中奖注数','一等奖奖金','二等奖中奖注数','二等奖奖金','三等奖中奖注数','三等奖奖金','四等奖中奖注数','四等奖奖金','五等奖中奖注数','五等奖奖金','六等奖中奖注数','六等奖奖金','七等奖中奖注数','七等奖奖金','一等奖中奖地区','奖池金额'])
csvwriter.writeheader()
csvwriter.writerow(dit)Explain:
打开名为 ssq.csv 的文件,以追加模式 (a) 打开,并指定编码为 utf-8 和换行符为空字符串。
创建一个 csv.DictWriter 对象,指定字段名列表,最后写入CSV文件的表头 再将字典写入表行
运行可得下面代码 发现 哦豁 乱码了
此时我们只需要将编码格式换成 utf-8-sig即可
再次运行代码 记得删除之前保存的csv文件再运行 ez
第二种 通过pandas 保存为excel文件
# 首先导包 并起个别名
import pandas as pd
# 定义一个空列表 后续存储数据
lis=[]
lis.append(dit)
pd.DataFrame(lis).to_excel('ssq.xlsx',index=False)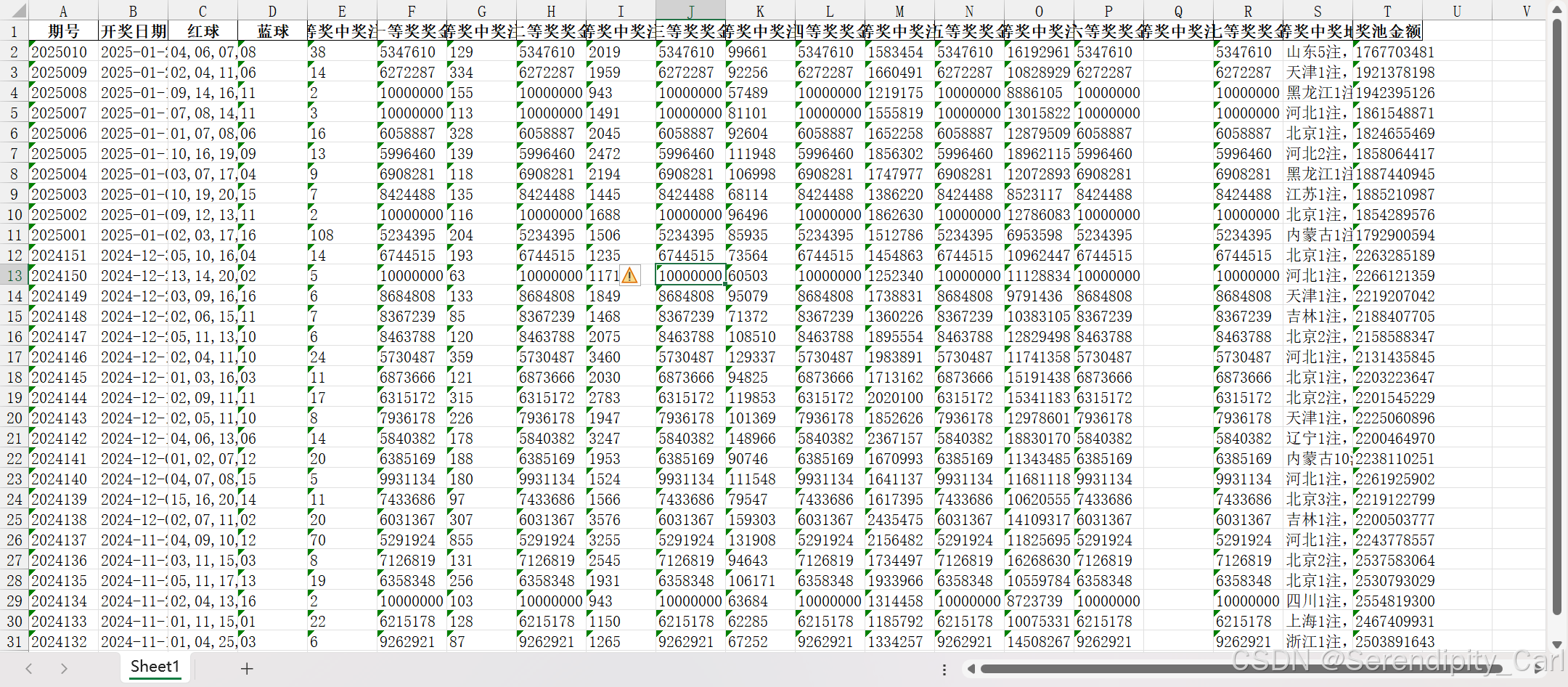
第三种 保存到数据库 看我上篇文章 在此就不演示了
爬虫的代码如下 供学习交流使用
import requests
import pprint
import pandas as pd
lis=[]
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Referer": "https://www.cwl.gov.cn/ygkj/wqkjgg/ssq/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36 Edg/132.0.0.0",
"X-Requested-With": "XMLHttpRequest",
"sec-ch-ua": "\"Not A(Brand\";v=\"8\", \"Chromium\";v=\"132\", \"Microsoft Edge\";v=\"132\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
cookies = {
"HMF_CI": "3ce441e2aa2ef73f540858202dd21ad18c14f2d08fb80f205829cc7ac1f45c327b2cccd44c7e4c7a318ec9908238ec0be4b37b7b8fdf29d422b2ef725cebb2b06b",
"21_vq": "6"
}
url = "https://www.cwl.gov.cn/cwl_admin/front/cwlkj/search/kjxx/findDrawNotice"
params = {
"name": "ssq",
"issueCount": "100",
"issueStart": "",
"issueEnd": "",
"dayStart": "",
"dayEnd": "",
"pageNo": "1",
"pageSize": "30",
"week": "",
"systemType": "PC"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params).json()
json_data = response['result']
for i in json_data:
dit = {
'期号': i['code'],
'开奖日期': i['date'],
'红球': i['red'],
'蓝球': i['blue'],
'一等奖中奖注数': i['prizegrades'][0]['typenum'],
'一等奖奖金': i['prizegrades'][0]['typemoney'],
'二等奖中奖注数': i['prizegrades'][1]['typenum'],
'二等奖奖金': i['prizegrades'][0]['typemoney'],
'三等奖中奖注数': i['prizegrades'][2]['typenum'],
'三等奖奖金': i['prizegrades'][0]['typemoney'],
'四等奖中奖注数': i['prizegrades'][3]['typenum'],
'四等奖奖金': i['prizegrades'][0]['typemoney'],
'五等奖中奖注数': i['prizegrades'][4]['typenum'],
'五等奖奖金': i['prizegrades'][0]['typemoney'],
'六等奖中奖注数': i['prizegrades'][5]['typenum'],
'六等奖奖金': i['prizegrades'][0]['typemoney'],
'七等奖中奖注数': i['prizegrades'][6]['typenum'],
'七等奖奖金': i['prizegrades'][0]['typemoney'],
'一等奖中奖地区': i['content'],
'奖池金额':i['poolmoney']
}
lis.append(dit)
pd.DataFrame(lis).to_excel('ssq.xlsx',index=False)
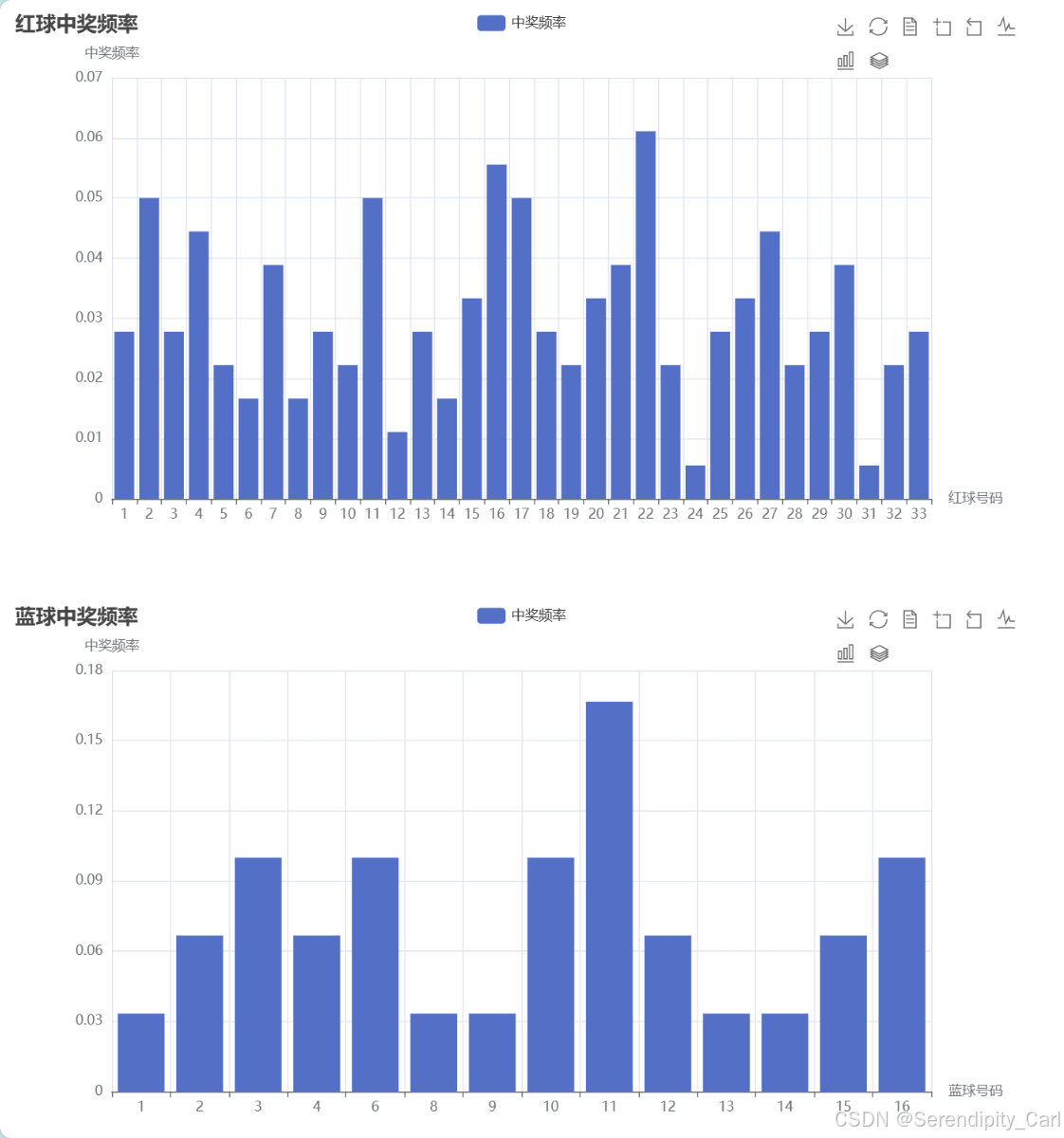
数据可视化模块
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Page
df = pd.read_excel('ssq.xlsx',index_col=False)
# 处理红球数据,将其拆分为单个数字
red_balls = df['红球'].str.split(',', expand=True).stack()
red_balls = red_balls.astype(int)
# 计算红球和蓝球各个号码的中奖频率
red_ball_freq = red_balls.value_counts(normalize=True).sort_index()
blue_ball_freq = df['蓝球'].value_counts(normalize=True).sort_index()
# 创建红球中奖频率柱状图
red_bar = (
Bar()
.add_xaxis(red_ball_freq.index.tolist())
.add_yaxis("中奖频率", red_ball_freq.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="红球中奖频率"),
xaxis_opts=opts.AxisOpts(name="红球号码"),
yaxis_opts=opts.AxisOpts(name="中奖频率"),
toolbox_opts=opts.ToolboxOpts(is_show=True)
)
#将柱状图上面的数字隐藏 不显示
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 创建蓝球中奖频率柱状图
blue_bar = (
Bar()
.add_xaxis(blue_ball_freq.index.tolist())
.add_yaxis("中奖频率", blue_ball_freq.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="蓝球中奖频率"),
xaxis_opts=opts.AxisOpts(name="蓝球号码"),
yaxis_opts=opts.AxisOpts(name="中奖频率"),
toolbox_opts=opts.ToolboxOpts(is_show=True)
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
# 将两个图表放在同一页面中
page = Page()
page.add(red_bar, blue_bar)
# 渲染图表到 HTML 文件
page.render("ball_frequency.html")



















 3340
3340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











