






1.最小生成树
一个图中可能存在多条相连的边,我们一定可以从一个图中挑出一些边生成一棵树。这仅仅是生成一棵树,还未满足最小,当图中每条边都存在权重时,这时候我们从图中生成一棵树(n - 1 条边)时,生成这棵树的总代价就是每条边的权重相加之和
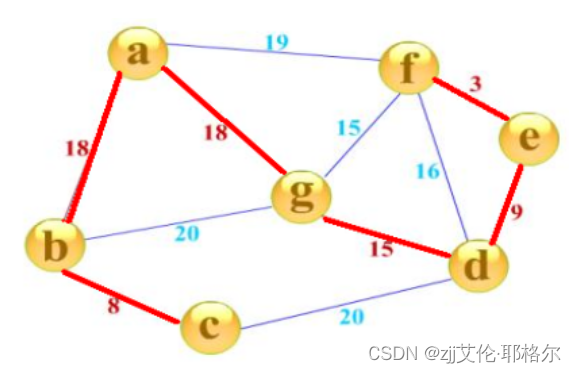
一个有N个点的图,边一定是大于等于N-1条的。图的最小生成树,就是在这些边中选择N-1条出来,连接所有的N个点。这N-1条边的边权之和(横线的数字相加)是所有方案中最小的。
2.最小生成树的现实应用
要在n个城市之间铺设光缆,主要目标是要使这 n 个城市的任意两个之间都可以通信,但铺设光缆的费用很高,且各个城市之间铺设光缆的费用不同,因此另一个目标是要使铺设光缆的总费用最低。这就需要找到带权的最小生成树。
当然,也可以用于村子的道路连接,使之路径最短。也可以是价格花费最少。
3.实现最小生成树的两种算法
1.Kruskal算法
也叫克鲁斯卡尔算法,它是求连通网的最小生成树的另一种方法。与普里姆算法(prime)不同,它的时间复杂度为O(eloge)(e为边数),适合于求边稀疏的网的最小生成树 。克鲁斯卡尔算法从另一途径求网的最小生成树。其基本思想是:假设连通网G,令最小生成树的初始状态为只有n个顶点而无边的非连通图T,概述图中每个顶点自成一个连通分量。在E中选择代价最小的边,若该边依附的顶点分别在T中不同的连通分量上,则将此边加入到T中;否则,舍去此边而选择下一条代价最小的边。说白了,优先先选出全体边里最短的那几条,然后如果各分量还没连起来,就继续选择剩余没被选择的边里最短的,直到全部节点都连接在一起。
Kruskal算法的基本思想
首先先定义一个结构存储所有的边 e d g e edgeedge ( f r o m , t o , w e i g h t ( 权值 ) ) (from,to,weight(权值))(from,to,weight(权值)),然后再按权值从小到大(一般是这样,这可以指距离,也可以指价格之类的)的排序,这样我们从头开始遍历,每一次取出来的边都是权值最小的一条边。每次先判断取出的边的两点是否已经在一个集合中了,不在一个集合中就合并,记录权值,反之就跳过本次循环。循环结束,我们就将所有的结点都加到了一个集合中
而且该算法是需要学习并查集的,实战的第一题就是该算法的实际应用,个人认为很好理解的,不明白的话,可以去看看。
现在用并查集的思想讲一下,一开始把所有元素当作独立元素,把权边小的两个点做‘查’判断处理,如果根节点不是一样的,就把这两个点连接,做并查集的”并“处理,就是根节点处理,然后累加对应的距离或者价格之类的就可以了。
2.prime算法
该算法将所有的顶点分为两类,树顶点(已被选入生成树的顶点)和非树顶点(还未被选入生成树的顶点)。首先选择任意一个顶点加入生成树(你可以理解成为生成树的根)。接下来要找出一条边添加到生成树,这需要枚举每一个树顶点到每一个非树顶点所有的边,然后找到最短边加入到生成树。照此方法,重复n-1次,找到将所有顶点都加入到树中。
下面,你们看看流程吧:
1.从任意一个顶点开始,构建生成树,假设从1号顶点开始,首先将顶点1加入生成树中,用一个一维数组book带标记那些定点已经加入了生成树, 如果加入了,则标记为1。
2.用数组dis记录生成树到各个顶点的距离 ,最初生成树只有1号顶点,有直联边时,数组dis中储存的就是1号顶点到该点的边的权值 没有直连边的时候就是无穷大,即初始化dis数组。
3.从数组dis中选出离生成树最近的顶点(假设这个点为j),再以j为中心点,更新生成数到每一个非树顶点的距离(就是松弛啦),即如果dis[k]>a[j][k]则跟新dis[k]=a[j][k]。
4.重复第三步,直到生成树中有n个顶点为止
这个还跟最短路径的Dijstra算法有关,未优化的代码,时间复杂度为O(N^2),使用邻接表来存储图的话,时间复杂度将会大大缩减。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e4 + 10;
const long long inf=0x3f3f3f3f;
int a[N][N],dis[N],book[N];
int n,m,t=0,sum=0;
int main() {
cin>>n>>m; //n个地方,m条路线
for(int i=1; i<=n; i++) {
for(int j=1; j<=n; j++) {
if(i!=j)
a[i][j]=inf; //最大值
}
}
int x,y,z;
for(int i = 1; i <=m; i ++) { //m条路线的距离
cin>>x>>y>>z;
a[x][y]=z; //因为这里是无向图,所以可以来回
a[y][x]=z;
}
for(int i=1; i<=n; i++) //初始化dis数组,因为当前生成树只有1号节点
dis[i]=a[1][i];
book[1]=1;
t++;
while(t<n) {
int mi=inf,j;
for(int i=1; i<=n; i++) {
if(book[i]==0&&dis[i]<mi) {
mi=dis[i];
j=i;
}
}
book[j]=1;
t++;
sum+=dis[j]; //累加权边,求最小生成树最短路径
for(int k=1; k<=n; k++) { //扫描当前顶点j所有的边,再以j为中间点,跟新生成树到每一个非树顶点的距离
if(book[k]==0&&dis[k]>a[j][k])
dis[k]=a[j][k];
}
}
printf("%d",sum);
return 0;
}啊,这个优化的不想写,有兴趣的可以自己去看看prime算法堆优化,而且我一般用的是Kruskal算法。
4.实战题目
1.题目:【模板】最小生成树

输入:
4 5
1 2 2
1 3 2
1 4 3
2 3 4
3 4 3输出:
7
单纯的模板。
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
struct node { //结构体的使用
int x,y,z;
} sb[N];
bool cmp(node a,node b) { //结构体与sort函数的联用
return a.z < b.z;
}
int s[N];
int n,m,sum;
int find(int x) {
return x == s[x] ? x : s[x] = find(s[x]);
}
int main() {
cin>>n>>m;
for(int i = 1; i <= m; i ++)
cin>>sb[i].x>>sb[i].y>>sb[i].z;
for(int i = 1; i <= n; i ++)
s[i] = i; //每一个都是独立的根节点
sort(sb + 1,sb + 1 + m,cmp);
for(int i = 1; i <= m; i ++) {
int x = find(sb[i].x);
int y = find(sb[i].y);
if(x == y) continue; //判断根节点是否一样,一样则说明这两个地方已经联通
s[y] = x;
sum += sb[i].z; //加距离或者价格都可以
}
int ans = 0;
for(int i = 1; i <= n; i ++) {
if(i == s[i]) ans ++; //因为一开始每一个都是独立的根节点,到最后只能有一个,否则就是没有全部联通
}
if(ans > 1) printf("orz");
else printf("%d\n",sum);
return 0;
}
2.题目:租用游艇
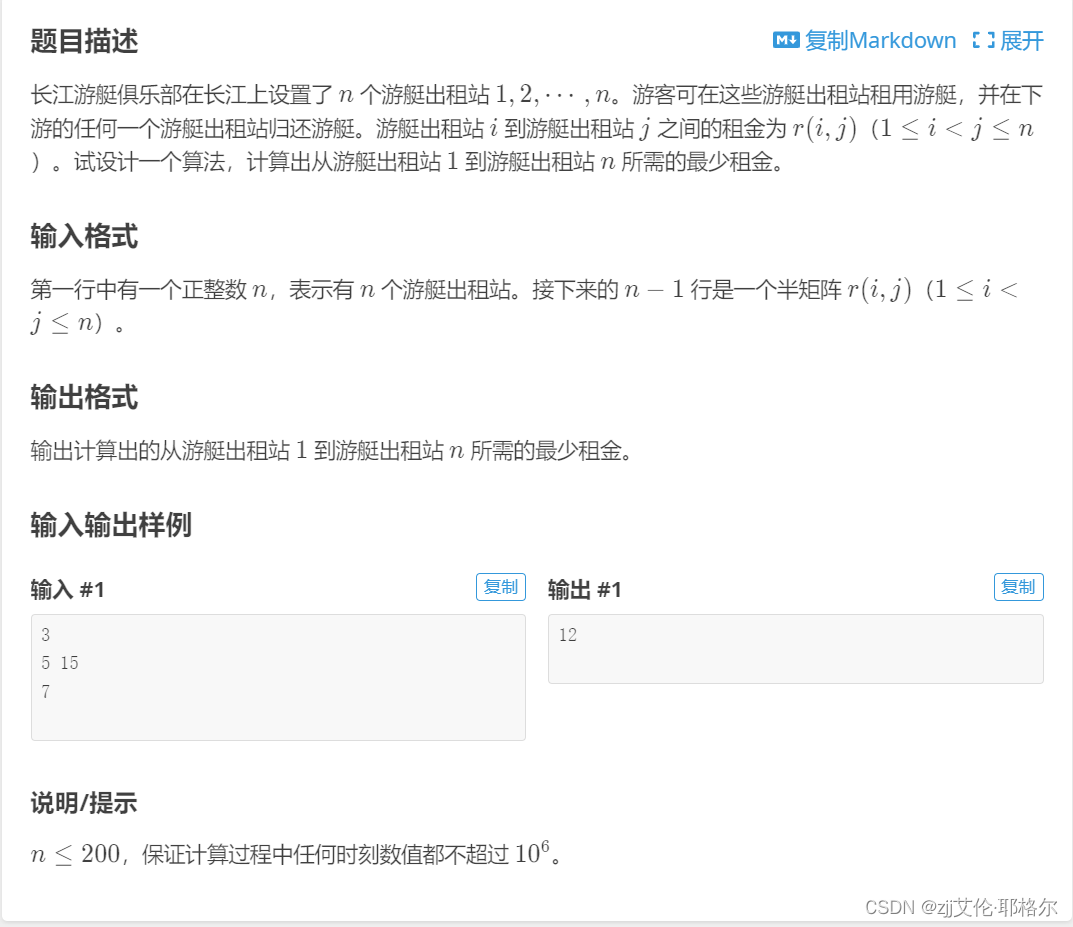
输入:
3
5 15
7
输出:
12注意仔细看题,有3个站,第二行分别是第1站到第2站的花费,第1站到第3站的花费,第三行是第1站到第3站的花费,而且题目说是下游,所以第2站在第1站的下游,第3站在第2站的下游。而且用了点dp思想。
#include<iostream>
#include<cmath>
using namespace std;
int a[201][201],i,j,n,dp[201];
int main(){
cin>>n;
for(i=1;i<n;i++){
for(j=i+1;j<=n;j++)
cin>>a[i][j];
dp[i]=1e9;//初始化数组dp,使它
}
for(i=n-1;i>=1;i--)//跑n上流的中转站
for(j=i+1;j<=n;j++)
dp[i]=min(dp[i],a[i][j]+dp[j]);//记录
cout<<dp[1];
return 0;
}3.题目:拆地毯

输入:
5 4 3
1 2 10
1 3 9
2 3 7
4 5 3输出:
22确实感觉跟第一题差不多,我这个都是根据第一题的代码改的,改了一点点吧。
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
struct node { //结构体的使用
int x,y,z;
} sb[N];
bool cmp(node a,node b) { //结构体与sort函数的联用
return a.z > b.z;
}
int s[N];
int n,m,sum=0,k,gh=0;
int find(int x) {
return x == s[x] ? x : s[x] = find(s[x]);
}
int main() {
cin>>n>>m>>k;
for(int i = 1; i <= m; i ++)
cin>>sb[i].x>>sb[i].y>>sb[i].z;
for(int i = 1; i <= n; i ++)
s[i] = i; //每一个都是独立的根节点
sort(sb + 1,sb + 1 + m,cmp);
for(int i = 1; i <= m; i ++) {
int x = find(sb[i].x);
int y = find(sb[i].y);
if(x == y) continue; //判断根节点是否一样,一样则说明这两个地方已经联通
s[y] = x;
sum += sb[i].z;
gh++; //加距离或者价格都可以
if(gh==k)break;
}
printf("%d\n",sum);
return 0;
}4.题目:营救

输入:
3 3 1 3
1 2 2
2 3 1
1 3 3输出:
2
这道题我用的kruskal,用该方法写的时候,最后得结果有点多此一举了,然后错了一点,删了最后的多于的循环判断,改为查并后直接判断输出就AC了。当然还是第一题的代码,改了一点点。
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
struct node { //结构体的使用
int x,y,z;
} sb[N];
bool cmp(node a,node b) { //结构体与sort函数的联用
return a.z < b.z;
}
int s[N];
int n,m,sum=1e4+1,k,gh=0,t;
int find(int x) {
return x == s[x] ? x : s[x] = find(s[x]);
}
int main() {
cin>>n>>m>>k>>t;
for(int i = 1; i <= m; i ++)
cin>>sb[i].x>>sb[i].y>>sb[i].z;
for(int i = 1; i <= n; i ++)
s[i] = i; //每一个都是独立的根节点
sort(sb + 1,sb + 1 + m,cmp);
for(int i = 1; i <= m; i ++) {
int x = find(sb[i].x);
int y = find(sb[i].y);
if(x == y) continue; //判断根节点是否一样,一样则说明这两个地方已经联通
s[y] = x;
if(find(k)==find(t)){
printf("%d\n",sb[i].z);
return 0;
}
}
return 0;
}5.题目:无线通讯网

输入:
2 4
0 100
0 300
0 600
150 750输出:
212.13题目意思差不多就是用S个半径为D的圆,把这P个点覆盖,而且圆心得在这P个点中的一个,而且D即半径最小时,总有至少一个点刚刚好在圆上,这也是解题的一个思路,在这个例子中,这个在圆上的点刚刚好是(150,750),并且这个圆的圆心是(0,600)半径刚刚好是212.13,记得用double双精度浮点。保留两位小数也需要用0.2lf。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e7 + 10;
struct node { //结构体的使用
int x;
int y;
double z;
} q[N];
int a[501],b[501];
bool cmp(node a,node b) { //结构体与sort函数的联用
return a.z < b.z;
}
int s[N];
int n,m,k=0,num=0,readf=0,t,sb=0; //只不过是readf容易打而已我,而且没想到read也是关键词
int find(int x) {
return x == s[x] ? x : s[x] = find(s[x]);
}
int main() {
cin>>n>>m;
for(int i = 1; i <=m; i ++) {
cin>>a[i]>>b[i];
for(int j=1; j<i; j++) { //以距离为权边(q[i].z)
readf++;
q[readf].x=i;
q[readf].y=j;
q[readf].z=sqrt(pow((a[i] - a[j]),2) + pow((b[i] - b[j]),2)); //pow次方函数
}
}
for(int i = 1; i <= m; i ++)
s[i] = i;
sort(q + 1,q + 1 + readf,cmp);
for(int i = 1; i <= readf; i ++) {
int x = find(q[i].x);
int y = find(q[i].y);
if(x == y) continue; //根节点相同,是同一个坐标,所以直接拜拜
s[y] = x;
k++;
if(k>=m-n) {
printf("%0.2lf\n",q[i].z);
return 0;
}
}
return 0;
}6.题目:买礼物

输入:
1 1
0
输出:
1
输入:
3 3
0 2 4
2 0 2
4 2 0输出:
7
如果题目看不出与最小生成树有什么关系的话,可以看看我代码中写的注释哦!
#include<bits/stdc++.h>
using namespace std;
const int N = 2e5 + 10;
struct node { //结构体的使用
int x,y,z;
} sb[N];
bool cmp(node a,node b) { //结构体与sort函数的联用
return a.z < b.z; //转化符号就是大到小,我博客有讲的
}
int s[N];
int n,m,sum=0,num=0,k=0,ans=0;
int find(int x) { //查根
return x == s[x] ? x : s[x] = find(s[x]);
}
int main() {
cin>>n>>m; //n是价格,m是数量
int r;
for(int i=1; i<=m; i++) {
for(int j=1; j<=m; j++) {
cin>>r;
if(i>=j||r==0||r>n)continue; //我这里说的是(r>n)这个条件,题目说要求最小,这大于就是反向优惠了,不减反增
sb[++k].x=i; //至于为什么要(i>=j)是因为题目说了,输入格式的第三行,我打不出来,所以只需要半壁江山就ok了
sb[k].y=j; //r=0是没有优惠的哦!
sb[k].z=r;
}
}
for(int i = 1; i <= n; i ++)
s[i] = i; //每一个都是独立的根节点
sort(sb + 1,sb + 1 + k,cmp); //排序,小到大
for(int i = 1; i<=k; i ++) {
int x = find(sb[i].x);
int y = find(sb[i].y);
if(x == y) continue; //判断根节点是否一样,一样则说明这两个地方已经联通
s[y] = x;
sum += sb[i].z;
num++; //计数,优惠了m-1个物品就行了
ans++;
if(num==m-1)break; //防止一直加,加到我们所需要的数量就好了
}
printf("%d\n",n+sum+(m-1-ans)*n); //如果刚好数量达标,(m-1-ans)*n就为0了,就不需要if判断了
return 0;
}7.题目:建筑道路 S

输入:
4 1
1 1
3 1
2 3
4 3
1 4输出:
4.00
考虑到连接的地方所需要的长度为0,就可以了,还要记得用double,题目中特意强调过的。
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
struct node { //结构体的使用
int x;
int y;
double z;
} q[N];
int a[1001],b[1001];
bool cmp(node a,node b) { //结构体与sort函数的联用
return a.z < b.z;
}
int s[N];
bool ok[1001][1001]; //数组大小,因为一开始定义的501,所以错了30分
int n,m,k=0,num=0,readf=0,t=0;
double sum=0.0; //只不过是readf容易打而已我,而且没想到read也是关键词
int find(int x) {
return x == s[x] ? x : s[x] = find(s[x]);
}
int main() {
cin>>n>>m;
for(int i = 1; i <=n; i ++)
cin>>a[i]>>b[i];
for(int i = 1; i <= n; i ++)
s[i] = i;
int x1,y1;
for(int i=1; i<=m; i++) {
cin>>x1>>y1;
ok[x1][y1]=ok[y1][x1]=true; //true是正确的意思,大小为1
q[++readf]=(node) { //因为他们已经连接了,所以按0处理
x1,y1,0
};
}
for(int i=1; i<=n; i++)
for(int j=i+1; j<=n; j++) {
if(!ok[i][j]) { //双方否定表肯定
q[++readf].x=i; //i和j表示第i个点和第j点
q[readf].y=j;
q[readf].z=(double)sqrt(pow((double)(a[i] - a[j]),2) + pow((double)(b[i] - b[j]),2)); //pow次方函数
}
}
int gh=0;
sort(q + 1,q + 1 + readf,cmp);
for(int i = 1; i <= readf; i ++) {
int x = find(q[i].x);
int y = find(q[i].y);
if(x == y) continue; //根节点相同,是同一个坐标,所以直接拜拜
s[y] = x;
sum+=q[i].z;
gh++; //缩短时间(看情况加吧)
if(gh==n-1)break;
}
printf("%0.2lf\n",sum);
return 0;
}














 4904
4904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









