






目录
摘要
在机器学习和深度学习领域,模型调优是提升模型性能的关键环节。本文将介绍一些实用的模型调优技巧,包括参数调整、特征选择、正则化方法等,帮助读者提高模型的准确性和泛化能力。
引言
随着人工智能的发展,机器学习和深度学习模型在各个领域都取得了显著的成果。然而,一个好的模型并非一蹴而就,需要经过不断地调整和优化。模型调优是一个复杂的过程,涉及到多个方面的因素。本文将详细介绍模型调优的关键步骤,帮助读者提升模型性能。
一、参数调整
参数调整是模型调优的核心环节。对于不同的模型,需要调整的参数可能有所不同。以下是一些建议:
1.学习率
学习率定义了在梯度下降过程中参数更新的步长。一个较大的学习率可以加快收敛速度,但也可能导致在最优解周围震荡甚至偏离最优解。相反,较小的学习率虽然能保证收敛的稳定性,但可能需要更多的迭代次数。实践中,可以尝试不同的学习率,或者使用学习率衰减策略,如定时减少学习率或使用自适应学习率算法(如Adam、RMSprop等)。

2.批量大小
批量大小是指在每次迭代中使用的样本数量。较大的批量可以减少梯度估计的方差,从而得到更稳定的收敛过程,但也会增加内存消耗和计算时间。较小的批量大小可以加速训练过程并减小内存占用,但可能会导致收敛过程不稳定。选择合适的批量大小通常需要权衡硬件资源与训练稳定性。
3.迭代次数
迭代次数决定了模型看到整个数据集的次数。过多的迭代可能会导致过拟合,即模型在训练数据上表现良好但在未见数据上表现不佳。过少的迭代则可能导致欠拟合,模型未能捕捉到数据中的足够信息。为了找到合适的迭代次数,可以使用验证集来监控模型性能,并通过早停法来避免过拟合
二、特征选择
特征选择是去除无关特征、降低维度的过程,这有助于提高模型的性能和泛化能力。以下是特征选择的一些常用方法:
1.相关性分析
通过计算特征之间的相关系数,我们可以评估特征间的线性关系强度。保留高度相关的特征,而移除那些与其他特征相关性较低的特征,可以减少冗余信息。
2.特征重要性
一些模型(如随机森林)能够提供特征重要性的度量,这可以帮助我们识别哪些特征对模型的预测结果影响最大。优先选择这些高重要性的特征,可以提高模型的性能。
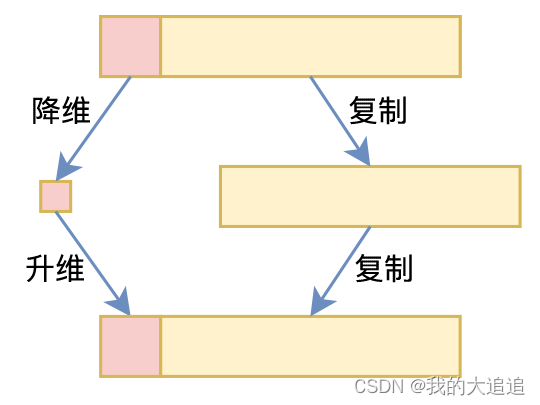
3.降维
主成分分析(PCA)和线性判别分析(LDA)是两种常用的降维技术。它们可以将原始的高维特征空间转换为较低维度的空间,同时尽量保留原始数据的变异性信息,这有助于减少计算负担并可能提高模型性能。
三、正则化方法
正则化是一种控制模型复杂度的方法,以防止过拟合。以下是几种常见的正则化技术:
1.L1正则化
L1正则化通过向损失函数添加权重绝对值之和的惩罚项来促进稀疏性,这对于特征选择很有帮助,因为它可以自动将不重要的权重设为零。
2.L2正则化
L2正则化通过向损失函数添加权重平方和的惩罚项来防止权重变得过大,它倾向于产生更平滑的模型,有助于控制模型复杂度并防止过拟合。
3.弹性网络正则化
弹性网络正则化结合了L1和L2正则化的优点,它允许在两者之间进行权衡,既可以实现特征选择也可以避免单独使用L2正则化时可能出现的过平滑问题。
四、交叉验证
交叉验证是评估模型泛化能力的重要工具。它将数据集分成多个子集,轮流使用其中一个子集作为验证集,其余作为训练集。这样可以更准确地估计模型在未知数据上的表现。
1.K折交叉验证
在K折交叉验证中,数据集被分成K个大小相等的子集。模型训练和验证会进行K次,每次都留出一个子集作为验证集,其余作为训练集。最后取K次验证的平均性能作为模型的最终评估指标。
2.留一法交叉验证
留一法是一种特殊的K折交叉验证,其中K等于数据集的样本数。每次只使用一个样本作为验证集,其余作为训练集。这种方法非常耗时,但可以提供非常准确的模型性能估计。
结论
模型调优是一个多方面的工作,涉及到从参数设置到特征工程,再到正则化和模型验证的各个环节。每一步都需要细致地考虑和实验,才能达到最佳的模型性能。希望本文能给读者带来帮助,提升模型性能。
以下是一些参考的链接:















 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









