






用idea实验hive的常用代码
将数据放到项目·的目录下
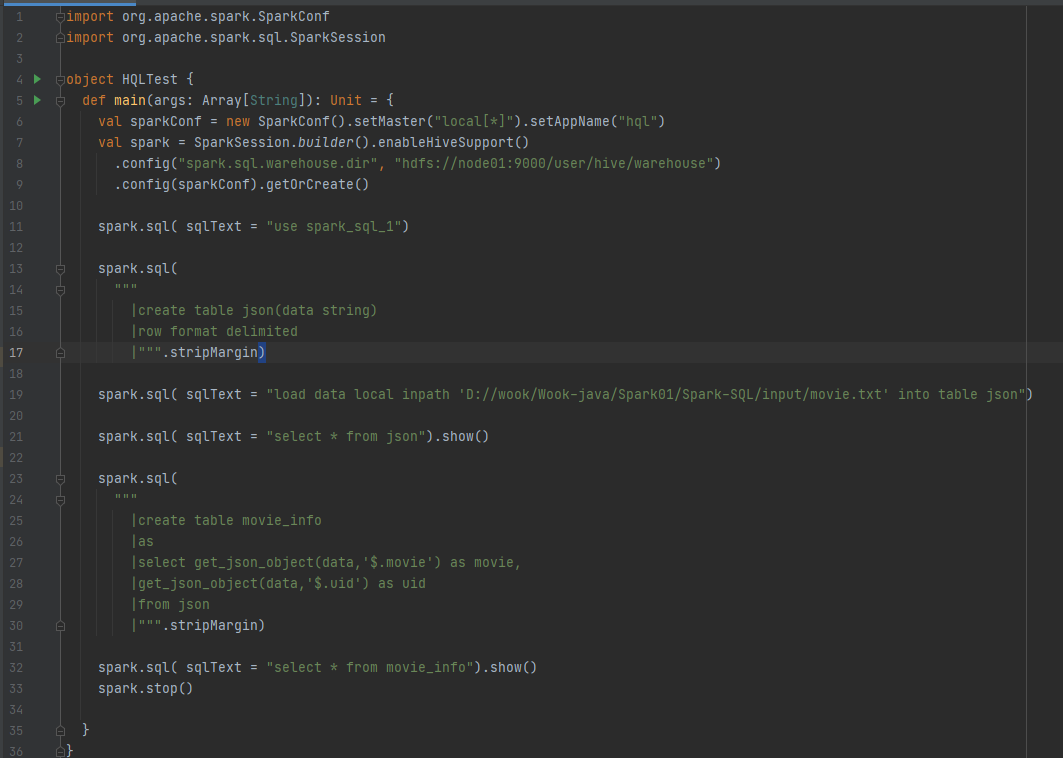
代码实现
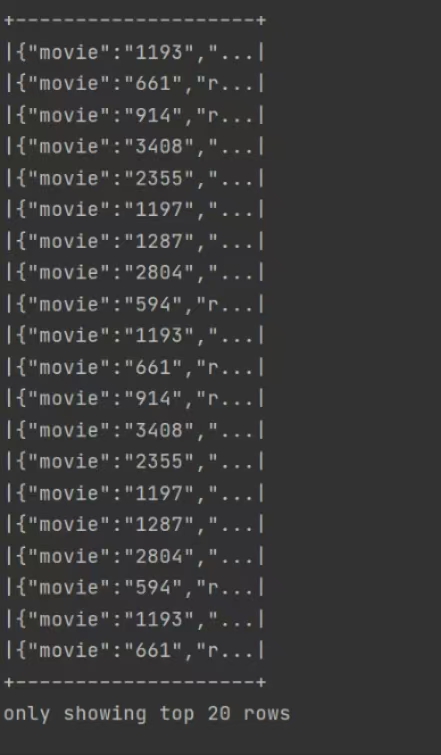
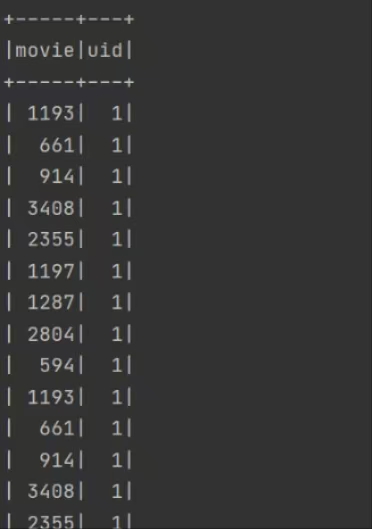
运行结果:
实验
统计有效数据条数及用户数量最多的前二十个地址
将数据放到Spark-SQL/input目录下

代码实现:
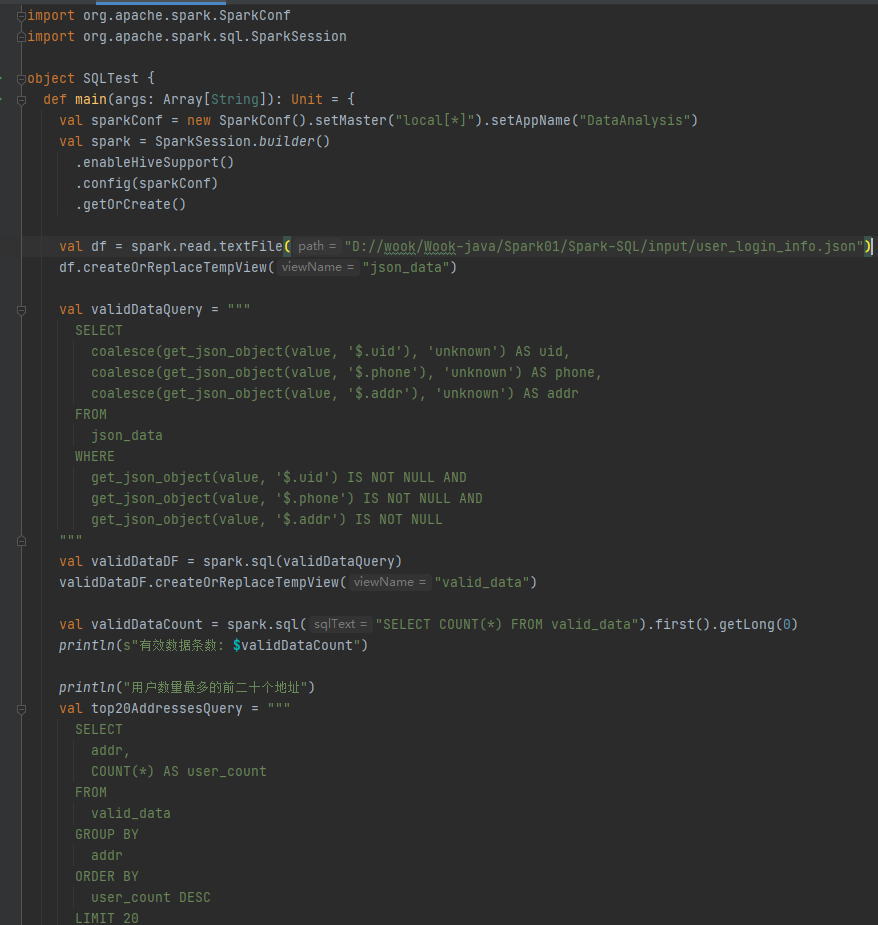
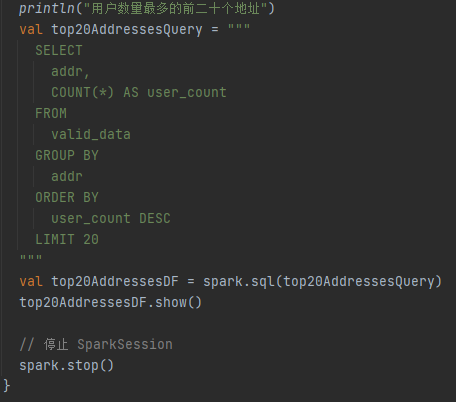
运行结果:
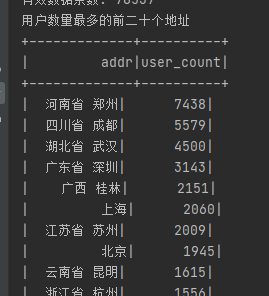
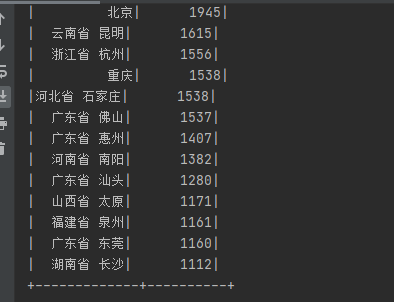
将数据放到项目·的目录下
代码实现
运行结果:
将数据放到Spark-SQL/input目录下
代码实现:
运行结果:
 930
2611
747
930
2611
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























