






 本文介绍了如何通过BF方法解决字符串的模式匹配问题,其时间复杂度为O(m*n),并通过KMP算法改进,将时间复杂度降低到O(m+n)。KMP算法的关键在于next数组,通过记录最长前后缀信息来减少比较次数。
本文介绍了如何通过BF方法解决字符串的模式匹配问题,其时间复杂度为O(m*n),并通过KMP算法改进,将时间复杂度降低到O(m+n)。KMP算法的关键在于next数组,通过记录最长前后缀信息来减少比较次数。
串的模式匹配可以通过BF(暴力)的方法解决,但是时间复杂度可以达到o(m*n),而使用KMP大法,可以把时间复杂度减少到o(m+n)
以下是暴力代码
//串的匹配算法
typedef struct
{
char s[100]="0";
int length;
}STRING;
int next[100] = {0};
//暴力枚举法
int BF(STRING S,STRING T)
{
int i=1, j=1;
while (i<=S.length&&j<=T.length)
{
if (S.s[i] == T.s[i])
{
++i;
++j;
}
else
{
i = i - j + 2;
j = 1;
}
if (j > T.length)
{
return i - T.length;
}
else
return 0;
}
}具体解释一下
以下是通过BF直接解决的办法,就是将模式串一个一个与母串进行比较,如果不匹配,那么就将母链的第二个字符当做第一个字符与模式串再进行以上操作
这样显然有些复杂
而KMP大法可能比较难以理解,但其实完全可以在BF算法的基础上去理解
KMP的基本原理
比如当模式串(子串)中发现与母串字符不相同时,我们不再将母串上的箭头往回,而是保持不动,然后子串找到最长的相同前后缀,将前缀移动到后缀的位置,通过这样就可以大大减少时间的复杂度
以下是b站一位up的视频截图(doge)

找到最大前后缀

前缀移动到后缀的位置
这就是KMP算法的基本原理
只看子串
我们可以发现,字串中的每一个字符都可能是与母串不同的字符,也就是说,每一个字串中的字符都有嫌疑成为匹配失败发现的第一个字符,如果真的是它,那么就要想办法找到在第二次匹配应该开始比较的位置,比如图1,发现A匹配失败,那么就要移动子串,从第四个位置开始比较,而这个“四”,是从哪来的呢?可以发现,找到的最长前后缀的长度是3,那么必定是从第四个位置开始
也就是说,假设找到的最长前后缀是k,那么必定从子串的k+1的位置开始比较
那么如何找到该位置的最长前后缀呢?
如何找到最长前后缀?
我们可以定义一个人next【j】数组,这个数组里面存放着子串中每一个当字符犯罪(成为不匹配的第一个字符)时,所应使用的k+1的位置,相当于一本法律,让每一个字符犯罪时,都有处理的办法
那么
next数组该怎么写呢?
这是这个算法里最重要也是最妙的一个点(以下图片来源b站一位up)
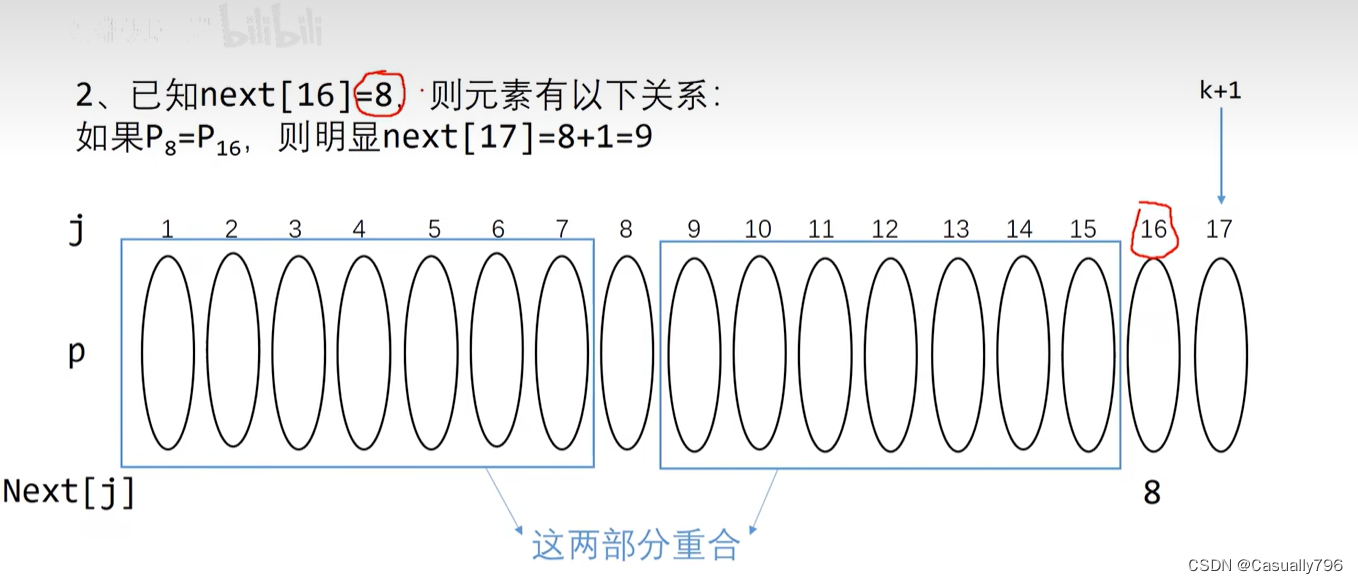
假设我们要存放子串的第17位的next值, 而假设第十六位所存放的next值为8,那么说明,第16位字符前面的7位(后缀)和1~7位(前缀)是一样的,而只有第8位我们是不知道的,那么只要第16位和第8位一样的话,那么我们next[17]里面是不是就可以存放8+1=9了(8是说明前后缀长度为8,在第9个位置开始)!
而16位由我们的指针i指着,然后用指针j找next[16],就可以定位到第8位了!
那如果第8位和第16位不一样怎么办?
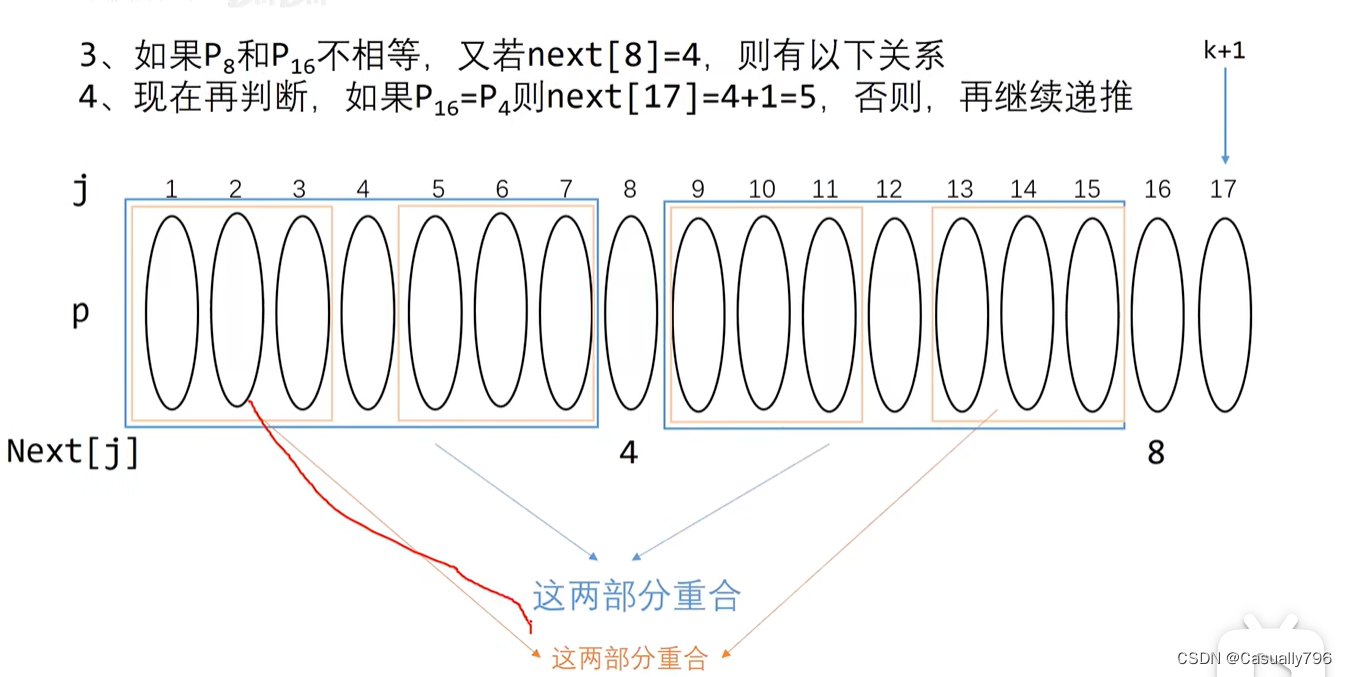
用指针j找第8位的next[8],假设是4,那么j又可以定位到第4位了,如果第4位和第16位一样,那么就可以说明next[17]里可以存4+1=5啦!
以此类推,直到找到第1位(存放的是0)

如果是0,那么就直接从第一个字符开始了,这是最坏情况
//KMP大法
void getnext(STRING T,int *next)
{
int i = 1;
int j = 0;
while (i < T.length)//i一直往后移
{
if (j == 0 || T.s[i] == T.s[j])//0的时候就存1
next[++i] = ++j;
else
j = next[j];
}
}
int KMP(STRING S, STRING T)
{
getnext(T, next);
int i = 1, j = 1;
if (S.s[i] == T.s[i])
{
++i;
++j;
}
else
{
j = next[j];
}
if (j > T.length)
{
return i - T.length;
}
else
return 0;
}















 8661
8661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









