






目录
七、文件操作
1.文件概述


2.文件的基本操作
Python 中,对文件的操作有很多种,常见的操作包括创建、删除、修改权限、读取、写入等,这些操作可大致分为以下 2 类:
删除、修改权限:作用于文件本身,属于系统级操作。
写入、读取:是文件最常用的操作,作用于文件的内容,属于应用级操作。
对文件的系统级操作功能单一,比较容易实现,可以借助 Python 中的专用模块(os、sys 等),并调用模块中的指定函数来实现。例如,假设如下代码文件的同级目录中有一个文件“a.txt”,通过调用 os 模块中的 remove 函数,可以将该文件删除,具体实现代码如下:
import os
os.remove("a.txt")
文件的应用级操作可以分为以下 3 步,每一步都需要借助对应的函数实现:
打开文件:使用 open() 函数,该函数会返回一个文件对象;
对已打开文件做读/写操作:读取文件内容可使用 read()、readline() 以及 readlines() 函数;向文件中写入内容,可以使用 write() 函数。
关闭文件:完成对文件的读/写操作之后,最后需要关闭文件,可以使用 close() 函数。
一个文件,必须在打开之后才能对其进行操作,并且在操作结束之后,还应该将其关闭,这 3 步的顺序不能打乱。
3.文件的打开与关闭
(1)打开文件
内置函数open()用于打开文件,该方法的声明如下:
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]])
file:表示要创建的文件对象。
file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
mode:可选参数,用于指定文件的打开模式。如果不写,则默认以只读(r)模式打开文件。
buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区。
encoding:手动设定打开文件时所使用的编码格式,不同平台的 encoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。



#是否已关闭
print(file.closed)
# 输出访问模式
print(file.mode)
#输出编码格式
print(file.encoding)
# 输出文件名
print(file.name)

(2)关闭文件
Python可通过close()方法关闭文件,也可以使用with语句实现文件的自动关闭。
①close()方法
close()方法是文件对象的内置方法。
file.close()
如果在打开文件或文件操作过程中抛出了异常,还是无法及时关闭文件。
②with语句
with语句可预定义清理操作,以实现文件的自动关闭。
with open('a.txt') as f:
pass
无论期间是否抛出异常,都能保证 with as 语句执行完毕后自动关闭已经打开的文件。
思考:为什么要及时关闭文件
①计算机中可打开的文件数量是有限的
②打开的文件占用系统资源
③若程序因异常关闭,可能产生数据丢失
4.文件的读写
Python提供了一系列读写文件的方法,包括读取文件的read()、readline()、readlines()方法和写文件的write()、writelines()方法,下面结合这些方法分别介绍如何读写文件。
(1)read()方法
read()方法可以从指定文件中读取指定字符/字节的数据,如果文件是以文本模式(非二进制模式)打开的,则 read() 函数会逐个字符进行读取;反之,如果文件以二进制模式打开,则 read() 函数会逐个字节进行读取。其语法格式如下:
f.read([size]) #size表示可读取的最大字符(或者字节)数
with open('file.txt', mode='r’, encoding = "utf-8") as f:
print(f.read(2)) # 读取2个字符的数据
print(f.read()) # 读取剩余的全部数据
想使用 read() 函数成功读取文件内容,除了严格遵守 read() 的语法外,其还要求 open() 函数必须以包含可读模式打开文件。
(2)readline()、readlines()方法
和 read() 函数不同,这 2 个函数都以“行”作为读取单位,即每次都读取目标文件中的一行。对于读取以文本格式打开的文件,读取一行很好理解;对于读取以二进制格式打开的文件,它们会以“\n”作为读取一行的标志。
readline()方法可以从指定文件中读取一行数据,其语法格式如下:
f.readline([size])
size 为可选参数,用于指定读取每一行时,一次最多读取的字符(字节)数。
readlines()方法可以一次读取文件中的所有数据,若读取成功,该方法会返回一个列表,文件中的每一行对应列表中的一个元素。语法格式如下:
f.readlines()
with open('file.txt', mode='r', encoding='utf-8') as f:
print(f.readlines())

\n会被读进来
read()(参数缺省时)和readlines()方法都可一次读取文件中的全部数据
但因为计算机的内存是有限的,若文件较大,read()和readlines()的一次读取便会耗尽系统内存,所以这两种操作都不够安全。
按数量读入,分批处理
为了保证读取安全,通常多次调用read()方法,每次读取size字节/字符的数据


(3)write()方法
write()方法可以将指定字符串写入文件,其语法格式如下:
f.write(data)
以上格式中的参数data表示要写入文件的数据,若数据写入成功,write()方法会返回本次写入文件的数据的字符数。
注意:在使用 write() 向文件中写入数据,需保证使用 open() 函数是以 r+、w、w+、a 或 a+ 的模式打开文件,否则执行 write() 函数会抛出 io.UnsupportedOperation 错误。
string = "Here we are all, by day; by night." # 字符串
with open('write_file.txt', mode='w', encoding='utf-8') as f:
size = f.write(string) # 写入字符串
print(size) # 打印字符数
结果为34(就是字符串的长度)
在写入文件完成后,一定要将打开的文件关闭或者flush,否则写入的内容不会保存到文件中。
(4)writelines()方法
writelines()方法用于将行列表写入文件,其语法格式如下:
writelines(lines)
以上格式中的参数lines表示要写入文件中的数据,该参数可以是一个字符串或者字符串列表。
若写入文件的数据在文件中需要换行,需要显式指定换行符\n。
多学一招:字符与编码

5.文件的定位读写
在文件的一次打开与关闭之间进行的读写操作是连续的,程序总是从上次读写的位置继续向下进行读写操作。
每个文件对象都有一个称为“文件读写位置”的属性,该属性会记录当前读写的位置。
文件读写位置默认为0,即在文件首部。
Python提供了一些获取与修改文件读写位置的方法,以实现文件的定位读写。
tell()。获取文件当前的读写位置。
seek()。控制文件的读写位置。
(1)tell()方法
tell()方法用于获取文件当前的读写位置,以操作文件file.txt为例,tell()的用法如下:
with open('file.txt') as f:
print(f.tell()) # 获取文件读写位置
print(f.read(5)) # 利用read()方法移动文件读写位置
print(f.tell()) # 再次获取文件读写位置
当程序使用文件对象读写数据时,文件指针会自动向后移动:读写了多少个数据,文件指针就自动向后移动多少个位置。
(2)seek()方法
Python提供了seek()方法,将文件指针移动至指定位置。seek()方法的语法格式如下:
file.seek(offset, [from])
file:表示表示文件对象。
from:用于指定文件的读写位置,该参数的取值为0、1、2。
0:表示文件开头。(默认值)
1:表示使用当前读写位置。
2:表示文件末尾。
offset:表示相对于 from 位置文件指针的偏移量,正数表示向后偏移,负数表示向前偏移。
seek()方法调用成功后会返回当前读写位置。
需要注意的是,在Python3中,若打开的是文本文件,那么seek()方法只允许相对于文件开头移动文件位置,若在参数from值为1、2的情况下对文本文件进行位移操作,将会产生错误。
若要相对当前读写位置或文件末尾进行位移操作,需以二进制形式打开文件。
6.文件与目录管理
对于用户而言,文件和目录以不同的形式展现,但对计算机而言,目录是文件属性信息集合,它本质上也是一种文件。
os模块中定义了与文件操作相关的函数,利用这些函数可以实现删除文件、文件重命名、创建/删除目录、获取当前目录、更改默认目录与获取目录列表等操作。
(1)文件路径
关于文件,它有两个关键属性,分别是“文件名”和“路径”。其中,文件名指的是为每个文件设定的名称,而路径则用来指明文件在计算机上的位置。
D:\demo\exercise\projects.docx(句点之后的部分称为文件的“扩展名”,它指出了文件的类型)
(2)绝对路径和相对路径
①什么是当前工作目录
每个运行在计算机上的程序,都有一个“当前工作目录”(或 cwd)。所有没有从根文件夹开始的文件名或路径,都假定在当前工作目录下。
在 Python 中,利用 os.getcwd() 函数可以取得当前工作路径的字符串,还可以利用 os.chdir() 改变它。例如,
import os
os.getcwd()
os.chdir('D:\\PycharmProjects')
os.getcwd()
如果使用 os.chdir() 修改的工作目录不存在,Python 解释器会报错
②什么是绝对路径和相对路径
明确一个文件所在的路径,有 2 种表示方式,分别是:
绝对路径:总是从根文件夹开始,Window 系统中以盘符(C:、D:)作为根文件夹,而 OS X 或者 Linux 系统中以 / 作为根文件夹。
相对路径:指的是文件相对于当前工作目录所在的位置。例如,当前工作目录为 "C:\Windows\System32",若文件 demo.txt 就位于这个 System32 文件夹下,则 demo.txt 的相对路径表示为 ".\demo.txt"(其中 .\ 就表示当前所在目录)。

 因此只有B方式不能打开文件,反斜线\是一个转义字符,\t组合成了一个横向制表符
因此只有B方式不能打开文件,反斜线\是一个转义字符,\t组合成了一个横向制表符
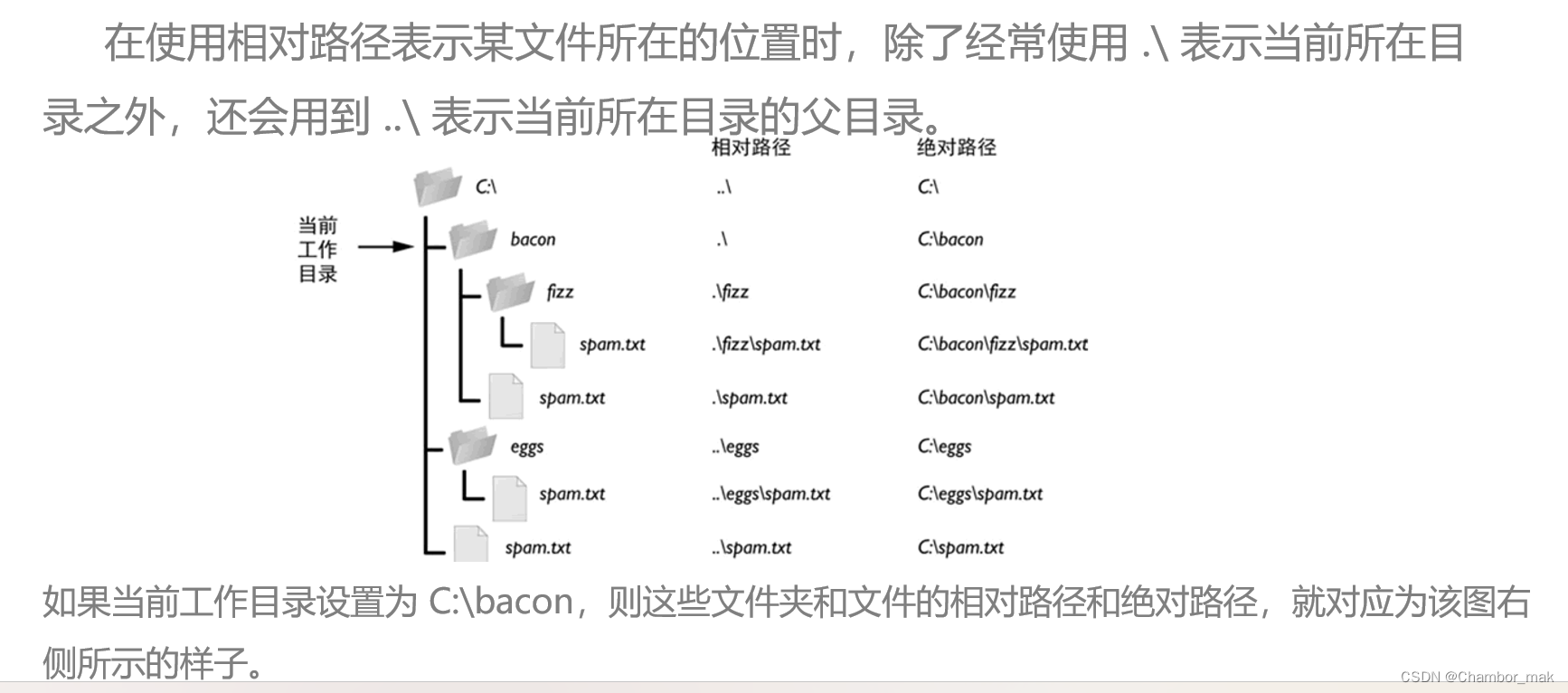
(3)管理文件与目录
删除文件——os.remove(文件名)
文件重命名——os.rename(原文件名,新文件名)
创建/删除文件夹——os.mkdir(目录名)/os.rmdir(目录名)
获取当前目录——os.getcwd()
更改默认目录——os.chdir(路径名)
获取目录下文件夹和文件名称——os.listdir(目录/路径)#得到的数据类型是列表
八、面向对象
1.面向对象概述
面向对象是程序开发领域的重要思想,这种思想模拟了人类认识客观世界的思维方式,将开发中遇到的事物皆看作对象。面向对象编程是程序员发展的分水岭,很多初学者会因无法理解面向对象而放弃学习编程。
面向过程和面向对象的区别:

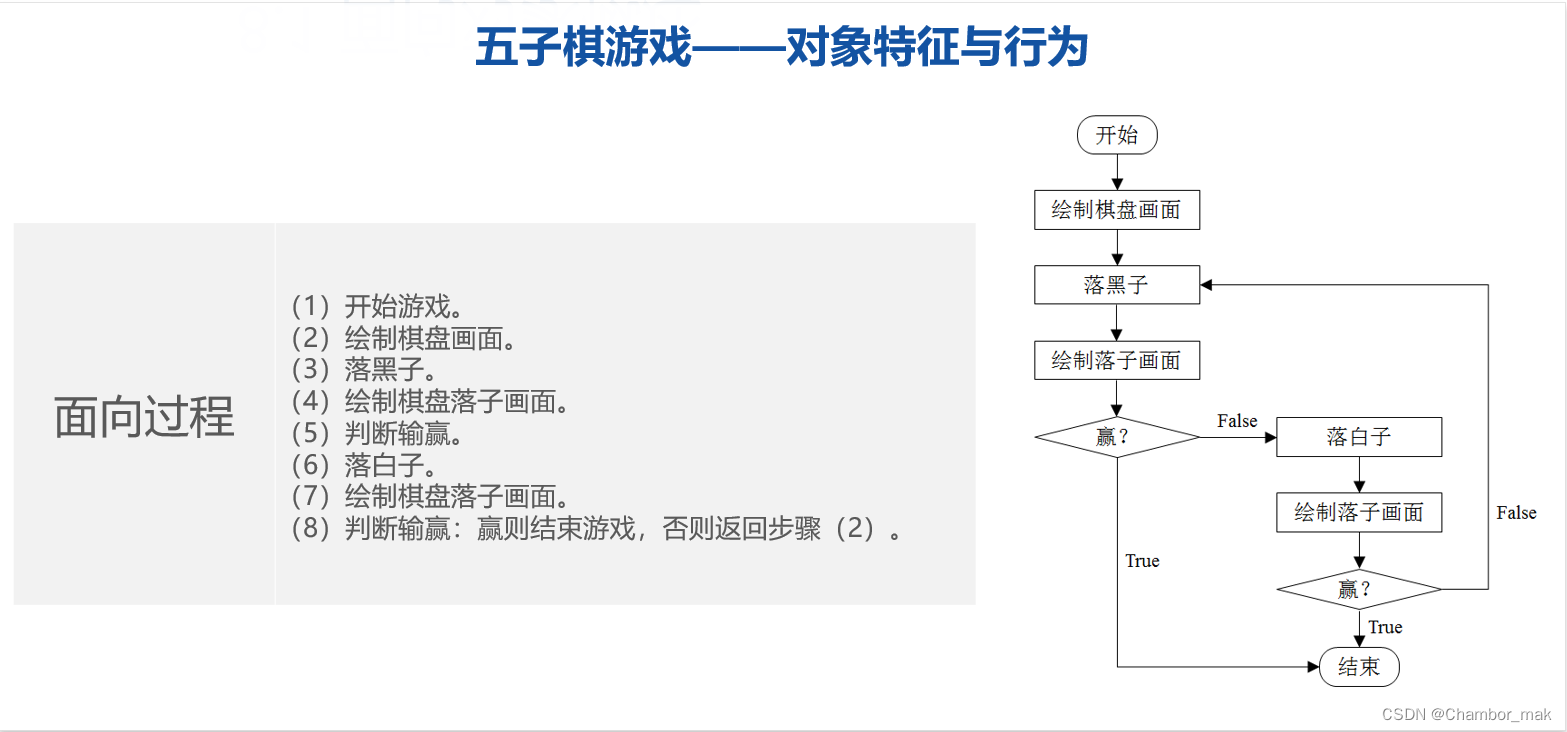

面向对象编程,是一种封装的思想,它可以更好地模拟真实世界里的事物(将其视为对象),并把描述特征的数据和代码块(函数)封装到一起。
代码封装,其实就是隐藏实现功能的具体代码,仅留给用户使用的接口。
面向对象中,常用术语包括:
类:可以理解是一个模板,通过它可以创建出无数个具体实例。
对象:类并不能直接使用,通过类创建出的实例(又称对象)才能使用。
属性:类中的所有变量称为属性。
方法:类中的所有函数通常称为方法。不过,和函数所有不同的是,类方法至少要包含一个 self 参数(后续会做详细介绍)。
2.类的定义和使用
(1)类的定义
面向对象编程有两个非常重要的概念:类和对象。
对象映射现实中真实存在的事物,如一本书。
具有相同特征和行为的事物的集合统称为类。
对象是根据类创建的,一个类可以对应多个对象。
类是对象的抽象,对象是类的实例。
格式:
class 类名:
‘’’这是Python定义类的格式’’’
属性名 = 属性值
def 方法名(self):
方法体
示例:
class Car:
wheels = 4 # 属性
def drive(self): # 方法
print('行驶')

注意,无论是类属性还是类方法,对于类来说,它们都不是必需的,可以有也可以没有。pass 关键字作为类体即可,例如:
class Empty:
pass
另外,Python 类中属性和方法所在的位置是任意的,即它们之间并没有固定的前后次序。
同属一个类的所有类属性和类方法,要保持统一的缩进格式,通常统一缩进 4 个空格。
(2)self方法
向类中添加方法,都要求将 self 参数作为方法的第一个参数。因此,方法最少要包含一个参数。
事实上,Python并没有规定该参数的具体名称。之所以将其命名为 self,只是程序员之间约定俗成的一种习惯,遵守这个约定,可以使我们编写的代码具有更好的可读性(大家一看到 self,就知道它的作用)。
同一个类可以产生多个对象,当某个对象调用类方法时,该对象会把自身的引用作为第一个参数自动传给该方法。换句话说,Python 会自动绑定类方法的第一个参数指向调用该方法的对象。如此,Python解释器就能知道到底要操作哪个对象的方法了。程序在调用实例方法,不需要手动为第一个参数传值。
class Person:
# 定义一个study()实例方法
def study(self):
print(self,"正在学Python")
zhangsan = Person()
zhangsan.study()
lisi = Person()
lisi.study()
结果为:
(3)对象的创建与使用

3.类的成员
在类体中,根据变量定义的位置不同,以及定义的方式不同,类属性又可细分为以下 3 种类型:
①类体中、所有函数之外:此范围定义的变量,称为类属性或类变量;
②类体中,所有函数内部:以“self.变量名”的方式定义的变量,称为实例属性或实例变量;
③类体中,所有函数内部:以“变量名=变量值”的方式定义的变量,称为局部变量。
(1)属性
①类属性

②实例属性
实例属性是在方法内部声明的属性。以“self.变量名”的方式定义的变量。
Python支持动态添加实例属性。
class Car:
def drive(self):
self.wheels = 4 # 添加实例属性
car = Car() # 创建对象car
car.drive() #只有调用了 drive() 方法的类对象,才包含 wheels 实例变量
print(car.wheels) # 通过对象car访问实例属性 4
class Car:
def drive(self):
self.wheels = 4 # 添加实例属性
car = Car() # 创建对象car
print(car.wheels) # 报错'Car' object has no attribute 'wheels'
print(Car.wheels) # 通过类Car访问实例属性 报错type object 'Car' has no attribute 'wheels'


类中,实例变量和类变量可以同名,但这种情况下使用类对象将无法调用类变量,它会首选实例变量,这也是不推荐“类变量使用对象名调用”的原因。
class CLanguage :
name = "xxx" #类变量
# 下面定义了一个say实例方法
def say(self):
self.name ="Python语言中文网" #实例变量
clang = CLanguage()
#修改 clang 对象的实例变量
clang.say()
clang.name = "Python教程"
print(clang.name) #Python教程
clang2 = CLanguage()
print(clang2.name) #xxx(没有调用say方法)
#输出类变量的值
print(CLanguage.name) #xxx③局部变量

(2)方法
Python中的方法按定义方式和用途可以分为三类:实例方法、类方法和静态方法。采用 @classmethod 修饰的方法为类方法;采用 @staticmethod 修饰的方法为静态方法;不用任何修饰的方法为实例方法。
①实例方法
形似函数,但它定义在类内部。
以self为第一个形参,self参数代表对象本身
实例方法通常会用类对象直接调用


②类方法
类方法是定义在类内部
使用装饰器@classmethod修饰的方法
第一个参数为cls,代表类本身,我们在调用类方法时,无需显式为 cls 参数传参。
类方法推荐使用类名直接调用,当然也可以使用实例对象来调用(不推荐)
注意:和 self 一样,cls 参数的命名也不是规定的(可以随意命名),只是 Python 程序员约定俗称的习惯而已。
类方法中可以使用cls访问和修改类属性的值

③静态方法
静态方法是定义在类内部
使用装饰器@staticmethod修饰的方法
没有任何默认参数
类的静态方法中无法调用任何类属性和类方法
class Car:
@staticmethod
def test(): # 静态方法
print("我是静态方法")
静态方法可以通过类和对象调用
class Car:
@staticmethod
def test(): # 静态方法
print("我是静态方法")
car = Car()
car.test() # 通过对象调用静态方法
Car.test() # 通过类调用静态方法

(3)私有成员
类的成员默认是公有成员,可以在类的外部通过类或对象随意地访问,这样显然不够安全。
为了保证类中数据的安全,Python支持将公有成员改为私有成员,在一定程度上限制在类的外部对类成员的访问。只能在本类内部使用,类的外部以及子类都无法使用。
Python通过在类成员的名称前面添加双下画线(__)的方式来表示私有成员,语法格式如下:
__属性名
__方法名
class Car:
__wheels = 4 # 私有属性
def __drive(self): # 私有方法
print("开车")
注意:Python 类中还有以双下划线开头和结尾的类方法(例如类的构造函数__init__(self)),这些都是 Python 内部定义的,用于 Python 内部调用。我们自己定义类属性或者类方法时,不要使用这种格式。
私有成员在类的内部可以直接访问,在类的外部不能直接访问,但可以通过调用类的公有成员方法的方式进行访问。
class Car:
__wheels = 4 # 私有属性
def __drive(self): # 私有方法
print("行驶")
def test(self):
print(f"轿车有{self.__wheels}个车轮") # 公有方法中访问私有属性
self.__drive() # 公有方法中调用私有方法
car = Car()
car.test()
结果为:
轿车有4个车轮
行驶
4.特殊方法
除了3节介绍的方法之外,类中还包括两个特殊的方法:构造方法和析构方法,这两个方法都是系统内置方法。
(1)构造方法



(2)析构方法
 5.封装
5.封装
封装是面向对象的重要特性之一,它的基本思想是对外隐藏类的细节,提供用于访问类成员的公开接口。
如此,类的外部无需知道类的实现细节,只需要使用公开接口便可访问类的内容,这在一定程度上保证了类内数据的安全。
为了契合封装思想,我们在定义类时需要满足以下两点要求。
1.将类属性声明为私有属性。
2.添加两类供外界调用的公有方法,分别用于设置或获取私有属性的值。

6.继承
继承是面向对象的重要特性之一,它主要用于描述类与类之间的关系,在不改变原有类的基础上扩展原有类的功能。
若类与类之间具有继承关系,被继承的类称为父类或基类,继承其他类的类称为子类或派生类,子类会自动拥有父类的公有成员。
继承机制经常用于创建和现有类功能类似的新类,又或是新类只需要在现有类基础上添加一些成员(属性和方法),但又不想直接将现有类代码复制给新类。也就是说,通过使用继承这种机制,可以轻松实现类的重复使用。
(1)单继承
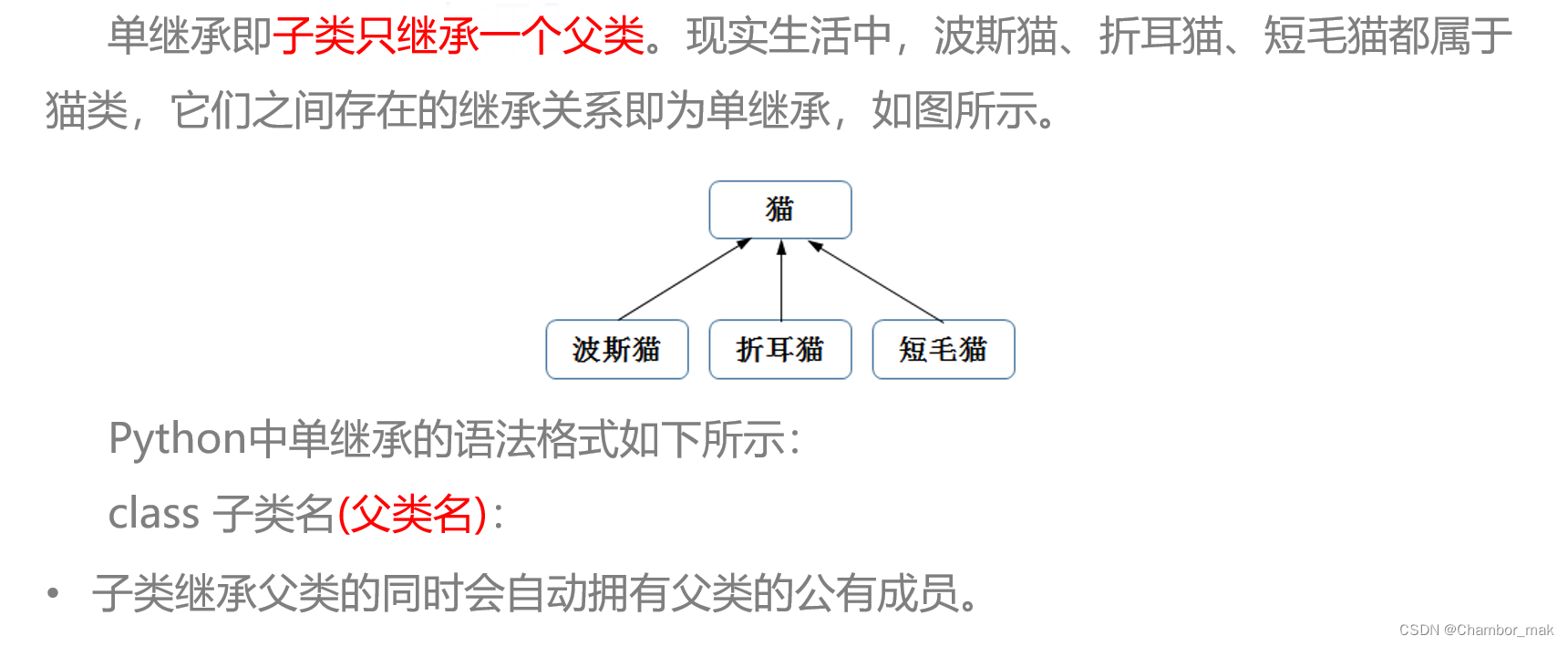

注意: 子类不会拥有父类的私有成员,也不能访问父类的私有成员。

(2)多继承
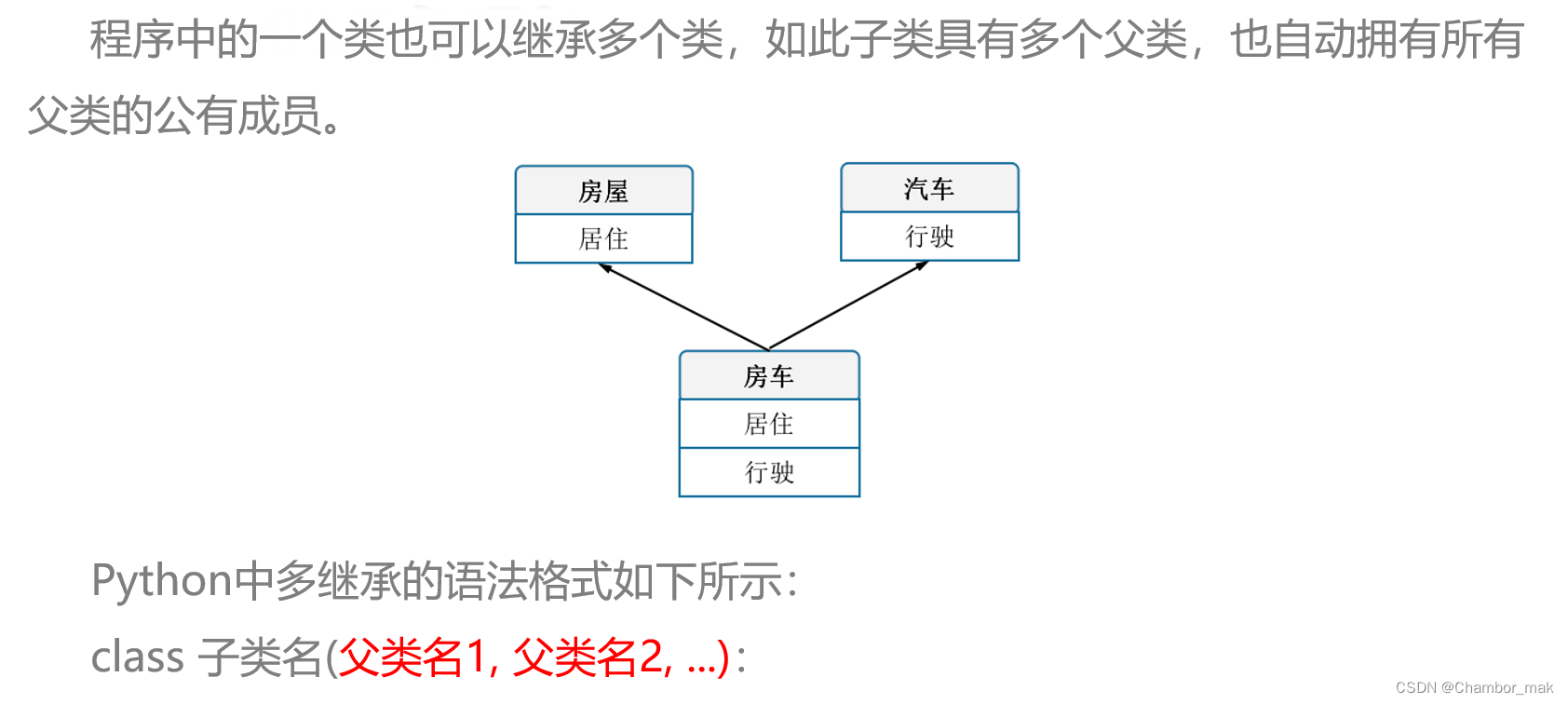

父类有同名方法情况下:如果子类继承的多个父类是平行关系的类,那么子类先继承哪个类,便会先调用哪个类的方法。

(3)重写
子类会原封不动地继承父类的方法,但子类有时需要按照自己的需求对继承来的方法进行调整,也就是在子类中重写从父类继承来的方法。


7.多态
多态是面向对象的重要特性之一,它的直接表现即让不同类的同一功能可以通过同一个接口调用,表现出不同的行为。

8.运算符重载
前面介绍Python 中的各个序列类型,每个类型都有其独特的操作方法,例如列表类型支持直接做加法操作实现添加元素的功能,字符串类型支持直接做加法实现字符串的拼接功能,也就是说,同样的运算符对于不同序列类型的意义是不一样的,这是怎么做到的呢?
为运算符定义方法被称为运算符重载。所谓重载,就是赋予新的含义。同一个运算符可以有不同的功能。
其实在 Python 内部,每种序列类型都是 Python 的一个类,例如列表是 list 类,字典是 dict 类等,这些序列类的内部使用了一个叫作“重载运算符”的技术来实现不同运算符所对应的操作。
所谓重载运算符,指的是在类中定义并实现一个与运算符对应的处理方法,这样当类对象在进行运算符操作时,系统就会调用类中相应的方法来处理。
运算符重载赋予内置运算符新的功能,使内置运算符能适应更多的数据类型。让自定义的类生成的对象(实例)能够使用运算符进行操作。


使用print()会调用__str__ 方法



九、异常
1.异常概述

程序开发或运行时可能出现异常,开发人员和运维人员需要辨别程序的异常,明确这些异常是源于程序本身的设计问题,还是由外界环境的变化引起,以便有针对性地处理异常。
程序运行出现异常时,若程序中没有设置异常处理功能,解释器会采用系统的默认方式处理异常,即返回异常信息、终止程序。
Python 提供了处理异常的机制,可以让我们捕获并处理这些错误,让程序继续沿着一条不会出错的路径执行。

2.异常的类型
(1)NameError

(2) IndexError
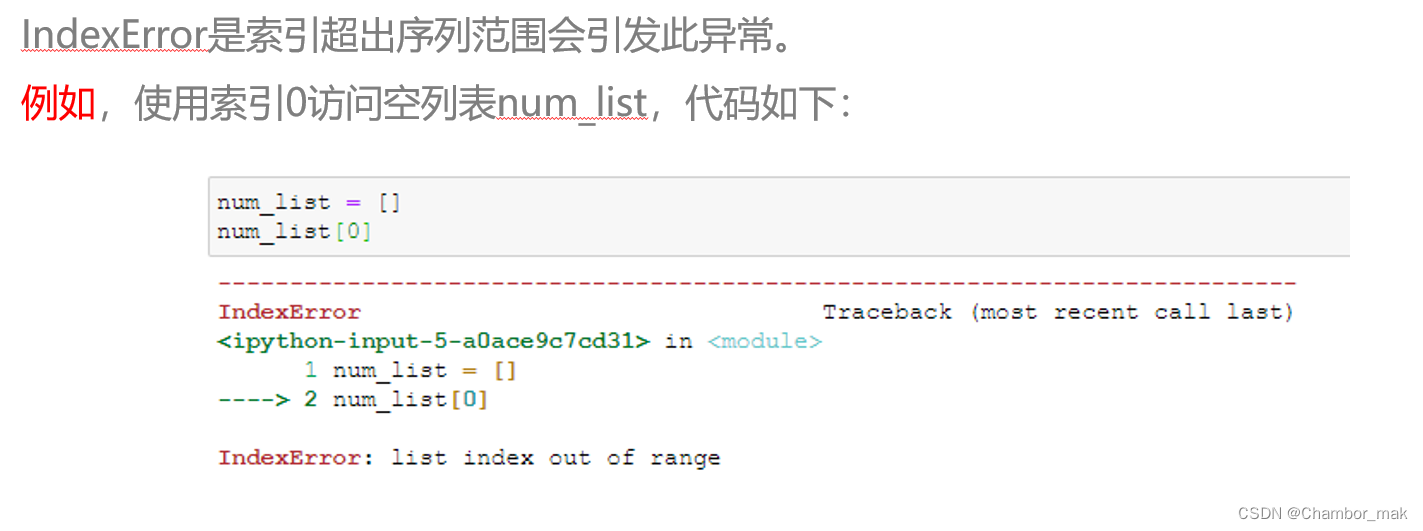
(3)AttributeError

(4)FileNotFoundError

(5)KeyError

(6)TypeError

当一个程序发生异常时,代表该程序在执行时出现了非正常的情况,无法再执行下去。默认情况下,程序是要终止的。如果要避免程序退出,可以使用捕获异常的方式获取这个异常的名称,再通过其他的逻辑代码让程序继续运行,这种根据异常做出的逻辑处理叫作异常处理。
3.异常捕获语句
Python既可以直接通过try-except语句实现简单的异常捕获与处理的功能,也可以将try-except语句与else或finally子句组合实现更强大的异常捕获与处理的功能。还提供了可主动使程序引发异常的 raise 语句。
(1)try-except语句









(2)else子句


(3)finally子句
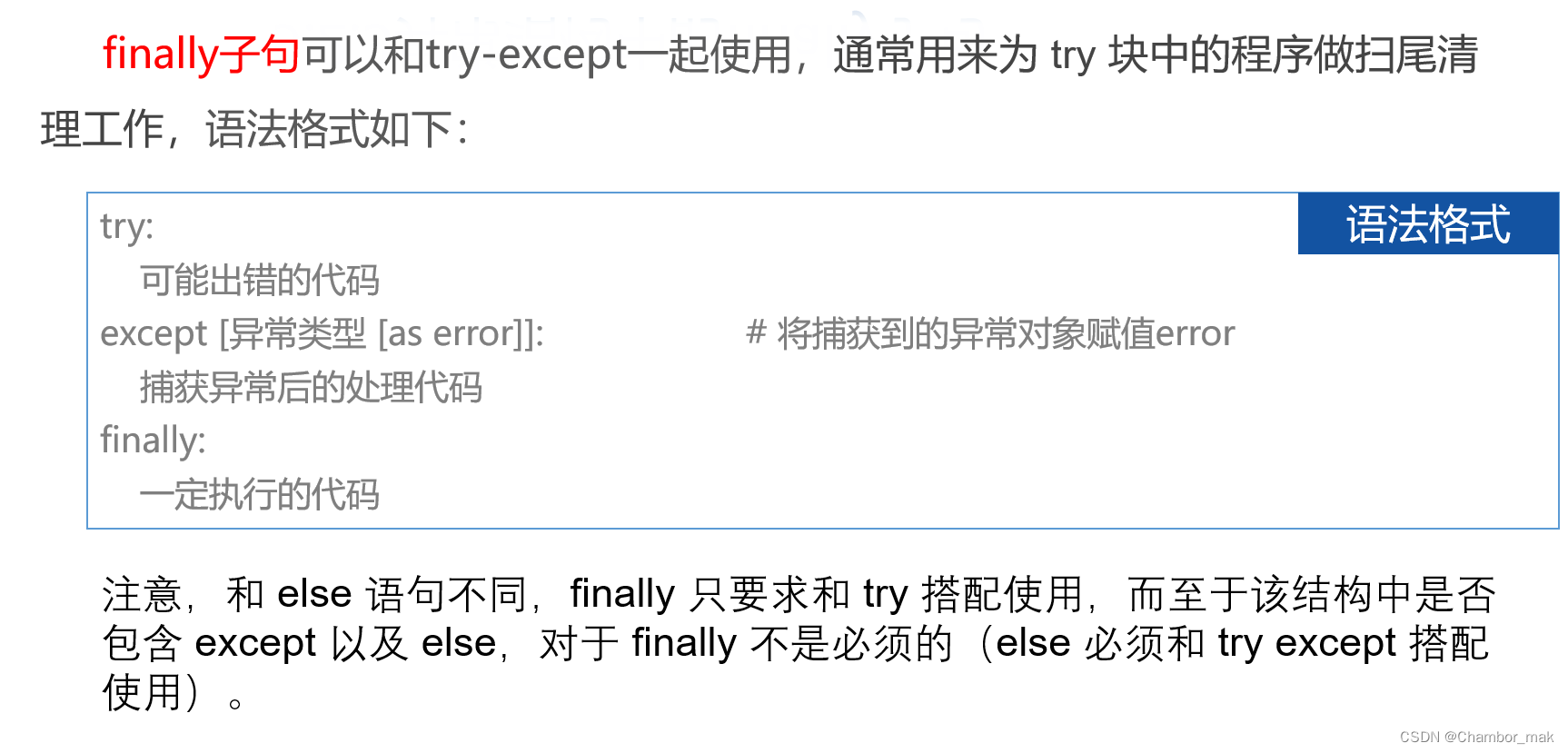

def divide(x, y):
try:
result = x / y
except ZeroDivisionError:
print("division by zero!")
else:
print("result is", result)
finally:
print("executing finally clause")
结果为:

4.抛出异常
Python程序中的异常不仅可以自动触发异常,而且还可以由开发人员使用raise和assert语句主动抛出异常。
(1)raise语句抛出异常


(2)assert语句抛出异常


5.异常的传递
如果程序中的异常没有被处理,默认情况下会将该异常传递到上一级,如果上一级仍然没有处理异常,那么会继续向上传递,直至异常被处理或程序崩溃。
6.自定义异常
有时我们需要自定义异常类,以满足当前程序的需求。自定义异常的方法比较简单,只需要创建一个继承Exception类或Exception子类的类(类名一般以“Error”为结尾)即可。

十、正则表示式
1.正则表达式概述
在处理文本字符串时,常常需要检查文本字符串中是否有满足某些规则(模式)的字符串。正则表达式就是用于描述这些规则的。说某个字符串匹配某个正则表达式,通常是指这个字符串里有一部分(或几部分分别)能满足正则表达式给出的规则。
正则表达式(Regular Expression)是一些由字符和特殊符号组成的字符串。它能帮助你方便的检查一个字符串是否与某种模式匹配。
所有关于正则表达式的操作都使用 Python 标准库中的 re 模块。re 模块使 Python 语言拥有全部的正则表达式功能。
应用:
正则表达式目前被集成到了各种文本编辑器/文本处理工具当中。
(1)验证:表单提交时,进行用户名密码的验证。
(2)查找:从大量信息中快速提取指定内容,在一批url中,查找指定url。
(3)替换:将指定格式的文本进行正则匹配查找,找到之后进行特定替换
例如:r ‘^a...s$’
上面的代码定义了一个RegEx模式。模式是:以a开头并以s结尾的任何五个字母字符串。
使用RegEx定义的模式可用于与字符串匹配。
import re
pattern = r'^a...s$'
test_string = 'abyss'
result = re.match(pattern, test_string)
if result:
print("查找成功.")
else:
print("查找不成功.")
这里,我们使用re.match()函数来搜索测试字符串中的模式。如果搜索成功,该方法将返回一个匹配对象。如果没有,则返回None。
2.元字符
为了指定正则表达式,使用了元字符。在前述示例中,^和$是元字符。
元字符是RegEx引擎以特殊方式解释的字符。以下是元字符列表:
[] . ^ $ * + ? {} () \ |
(1)方括号[]
指定您要匹配的一组字符

也可以使用-指定方括号内的字符范围。
[a-e]与相同[abcde]。
[1-4]与相同[1234]。
[0-39]与相同[01239]。
可以通过在方括号的开头使用插入符号^来补充(反转)字符集。
①[^abc]表示除a或b或c之外的任何字符。
②[^0-9] 表示任何非数字字符。
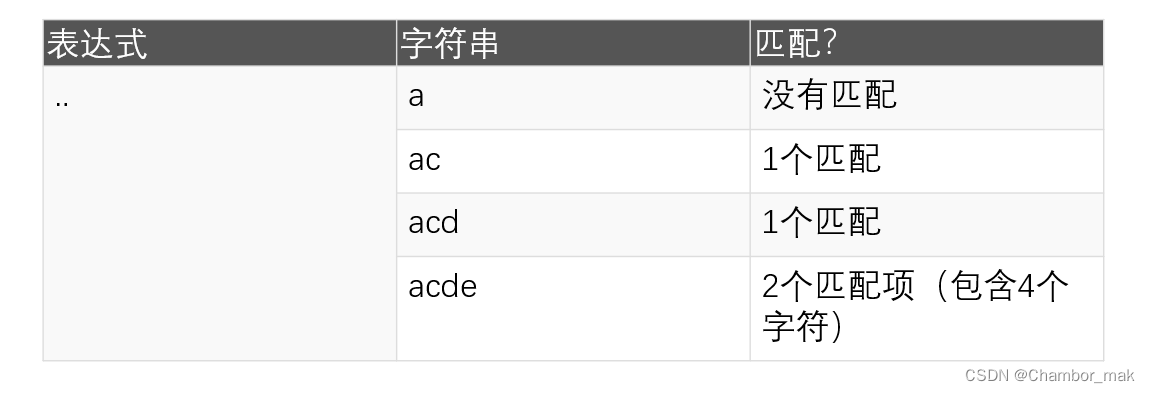
(2) 句号.
句点匹配任何单个字符(换行符除外'\n')。
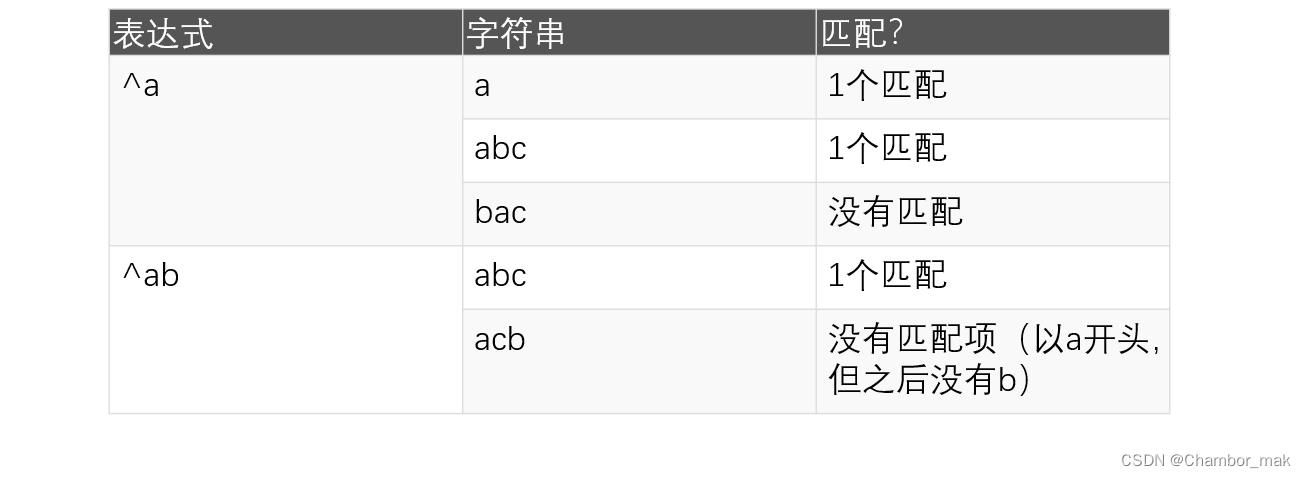
(3)插入符号^
插入符号^用于检查字符串是否以某个字符开头。
(4)美元符号$
美元符号$用于检查字符串是否以某个特定字符结尾。

(5)星号*
星号*匹配前一个字符0次或无限次的模式。
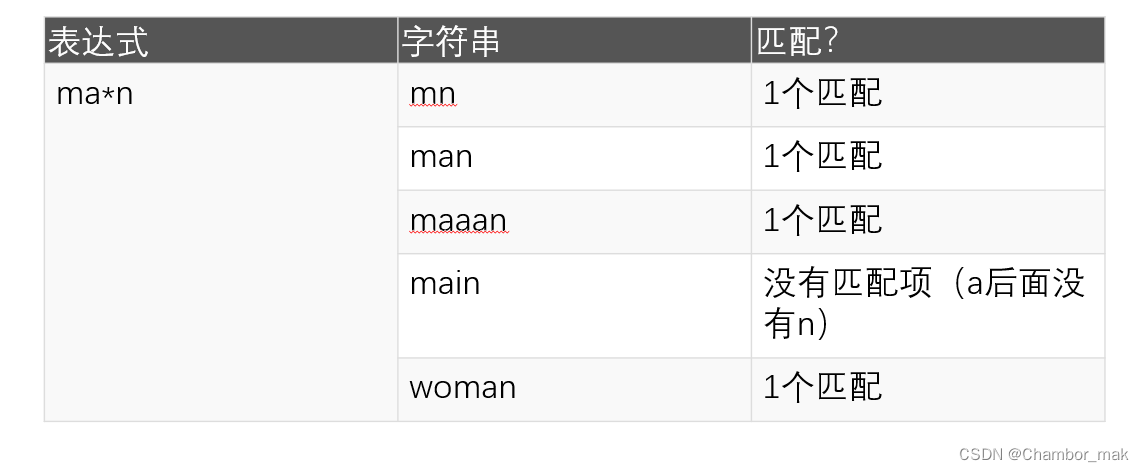
(6)加号+
加号+匹配前一个字符1次或无限次的模式。

(7)问号?
问号?匹配前一个字符0次或1次的模式。

(8)大括号{}
{m}匹配前一个字符m次;{n,m}匹配前一个字符n次至m次;

(9)竖线|
竖线|用于左右表达式任意匹配一个

在这里,a|b匹配任何包含a或b的字符串
(10)括号()
括号()用于对子模式进行分组。例如,(a|b|c)xz匹配任何与a或b或c匹配且后跟xz的字符串
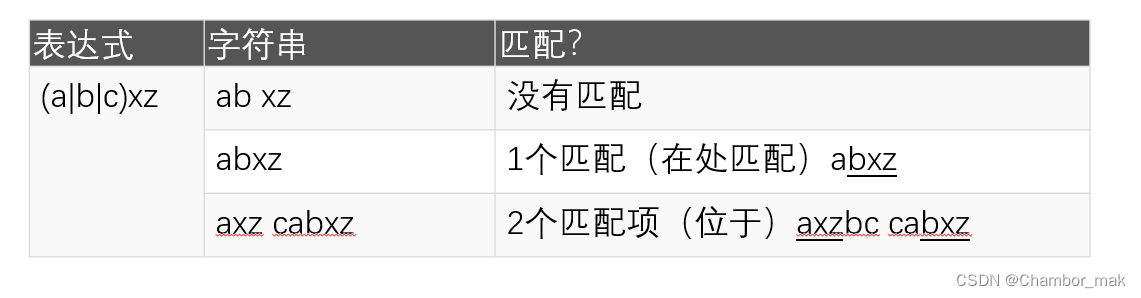
(11)反斜杠\
反斜杠\用于转义包括所有元字符在内的各种字符。例如,\$a如果字符串包含$后跟a则匹配。在此,$ RegEx引擎不会以特殊方式对其进行解释。
如果不确定某个字符是否具有特殊含义,可以将其\放在前面。这样可以确保不对字符进行特殊处理。
3.特殊字符类
(1)\A
如果指定字符在字符串的开头,则匹配。
(2)\b
如果指定的字符在单词的开头或结尾,则匹配。

(3)\B
如果指定的字符不在单词的开头或结尾,则匹配。

(4)\d
匹配任何十进制数字。相当于[0-9]

(5)\D
匹配任何非十进制数字。相当于[^0-9]

(6)\s
匹配字符串包含任何空格字符的地方。
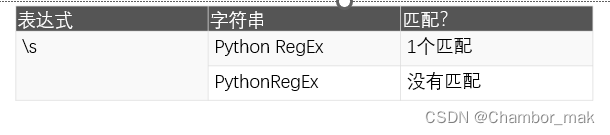
(7)\S
匹配字符串包含任何非空白字符的地方。

(8)\w
匹配任何字母数字字符(数字和字母)

(9)\W
匹配任何非字母数字字符

(10)\Z
如果指定的字符在字符串的末尾,则匹配。

4.re模块
(1)re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,匹配成功re.match方法返回一个匹配的对象。
函数语法:
re.match(pattern, string[, flags=0])

标志位:正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过 |它们来指定。如 re.I | re.M 被设置成 I 和 M 标志

(2)re.findall函数
re.findall()方法返回包含所有匹配项的字符串列表,如果找不到该模式,则re.findall()返回一个空列表。

(3)re.split函数
split方法对匹配的字符串进行拆分,并返回发生拆分的字符串列表。如果找不到该模式,则re.split()返回一个包含空字符串的列表。


(4)re.sub函数
该方法返回一个字符串,其中匹配的匹配项被替换为replace变量的内容。如果找不到该模式,则re.sub()返回原始字符串。count用于指定最多替换次数,不指定时全部替换。
格式:
re.sub(pattern, replace, string[, count])

(5)re.subn函数
re.subn()与re.sub()类似,它返回一个包含2个项目的元组,其中包含新字符串和替换的次数。

(6)re.search函数
re.search()方法采用两个参数:模式和字符串。 该方法寻找RegEx模式与字符串匹配的第一个位置。如果搜索成功,则re.search()返回一个匹配对象。如果不是,则返回None。re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。re.search()并不要求必须从字符串的开头进行匹配,也就是说,正则表达式可以是字符串的一部分。
格式:
match = re.search(pattern, str)















 4170
4170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









