







前言
面对海量数据,如何快速找到所需信息?如何优化查询性能?SQL的强大功能可以帮助解决这些常见的数据挑战。从基础的增删改查到高级的窗口函数,掌握SQL意味着掌握数据世界的钥匙。
这一期我们继续学习SQL语句,希望大家收获满满!
回顾一下:
模式与表的关系:
1.每一个基本表都属于某一个模式
2.一个模式包含多个基本表
3.定义基本表所属模式:

修改基本表
修改表主要用的就是ALTER
其结构框架是:

这时候有人就问了,为什么一个小小的修改搞得这么复杂?其实这是为了使得SQL功能完善而去专门设计的。修改:包含 增,删,改。而这个删又可以包括删表中的内容,还是删除指定的完整性约束条件。这么以来功能就非常强大了。

修改基本表案例:
向Student表增加“入学时间”列,其数据类型为日期:
ALTER TABLE Student ADD S_enterance DATE;
将年龄的数据类型由字符型改成整数:
ALTER TABLE Student ALTER COLUMN sage INT
增加课程名称必须取唯一值的约束条件:
ALTER TABLE Cource ADD UNIQUE(Cname)
记住不管怎么样,修改基本表开头就是 ALTER TABLE <表名>!然后就是具体的操作,该增就ADD,该改就ALTER,得听话!
删除基本表
DROP TABLE<表名>[RESTRICT|CASCADE]

CASCADE本身就有随意的意思,写的时候,感觉没啥子问题时候,就写这个,准没错。
案例:
删除Student表
DROP TABLE Student CASCADE
基本表定义被删除,数据被删除
表上建立的索引,视图,触发器等一般也将被删除
这就是CASCADE的强大之处,憎恨我吧,平凡的人类,我CASCADE终将是新世纪的王!emmmm,扯远了,我们回来一下。
在表格中增加/删除元组

索引的建立与删除
我怕大家对索引这个概念感到陌生,我就做了个直观的图,让大家一秒理解索引。
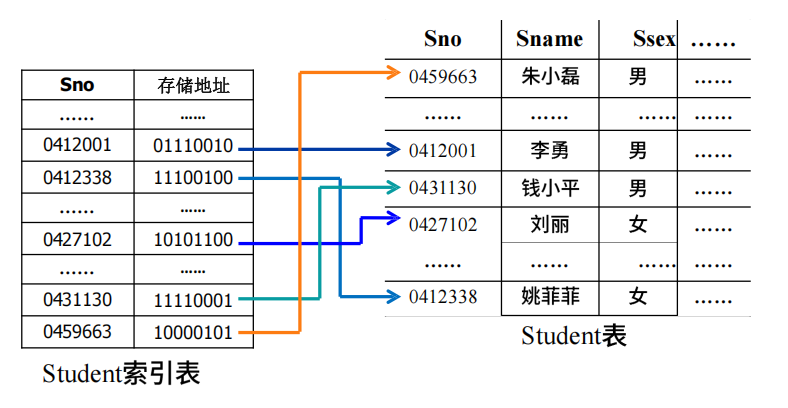
是不是很简单?一秒钟学会真的超酷的好吧
但是我还是得专业的具体介绍一下什么是索引:
在关系数据库中,索引是一种单独的、物理的对数据库表中的一列或多列的值进行排序的一种存储结构。
它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
为什么建立索引呢?其目的在于加快查询速度

建立索引的考虑

建立索引

CREATE[UNIQUE|CLUSTER] INDEX<索引名>
ON <表名>(<列名>[<次序>],........);

案例

切记切记切记切记!!!!!!修改索引是不能用ALTER的!知道了吗?
因为是需要调用存储的,如果对这个感到陌生就重新拉上去看看什么是索引!
当然主播这里一定有小妙招,助力各位道友解决疑难杂症!

删除索引

数据字典
数据字典是关系数据库管理系统内部的一组系统表,它记录了数据库中所有定义信息:

关系数据库管理系统在执行SQL的数据定义语句时,实际上就是在更新数据字典表中的相应数据。
数据查询
数据查询部分是我们主要学习的核心部分,其包括单表查询,连接查询,嵌套查询,集合查询这几类。
先给大家语句格式:

含义:根据WHERE子句的条件表达式从FROM子句指定的基本表、试图或派生表中找出满足条件的元组,再按SELECT子句中的目标列表表大式选出元组中的属性值形成结果表。
详细给大家解释一下,便于大家理解:
SELECT子句:指定要显示的属性列或列表达式
FROM子句:指定查询对象(基本表或视图)
WHERE子句:指定查询条件
GROUP BY子句:对查询结果按指定列的值分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数
HAVING短语:只有满足指定条件的组才予以输出
ORDER BY子句:对查询结果表按指定列值的升序或降序排序
查询仅涉及一个表时候,是一种最简单的查询操作
1.选择表中的若干列
2.选择表中的若干元组
3.使用ORDER BY 子句对查询结果排序
4.使用聚集函数
5.使用GROUP BY子句对查询结果分组
光说不练,毛都不学不会的。我们来看看案例
现在我们要查询全体学生的学号与性别
SELECT Sno,Sname FROM Student
是不是很简单的就能学会并上手查询了,切记 SELECT 是来选新建表的属性列,FROM是要查询的列来源的表
而且,我们目标列中各个列顺序可以和表中的顺序不一致
查询全部列
选出所有列:SELECT *
案例:查询全体学生的详细记录:
SELECT Sno,Sname,Ssex,Sage,Sdept FROM Student
或者
SELECT * FROM Student
依旧是很简单嗷
查询经过计算的值
SELECT子句的<目标列表达式>不仅可以为表中的属性列,也可以是表达式
查全体学生的姓名及其出生年份。
SELECT Sname ,2026-Sage FROM Student;
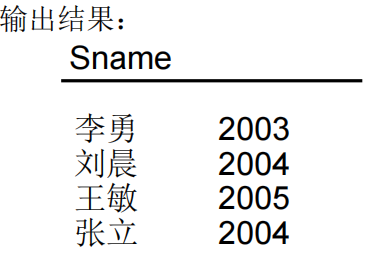
查询全体学生的姓名,出生年份和所在的院系,要求用小写字母表示系名。
SELECT Sname,'Year of Birth:',2026-Sage,LOWER(Sdept) FROM Student

使用列别名改变查询结果的列标题:
SELECT Sname NAME,'Year of Birth' BIRTH,2026-Sage BIRTHDAY,LOWER(Sdept) DEPARTMENT FROM Student;

加强记忆一下,想给这些列取新名字,就是先取目标列这样子我们才会有目标列的数据,才在其后面取新名字 加个 XXXX就OK了非常简单
取消取值重复行
如果没有指定DISTINCT关键词,则缺省为ALL
查询选修课程的学生学号。
SELECT Sno FROM SC;
等价于:SELECT ALL Sno FROM SC;
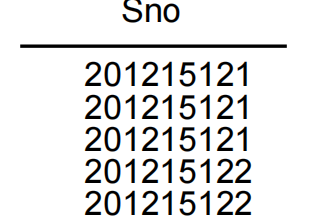
指定DISTINCT关键词,去掉表中重复的行
SELECT DISTINCT Sno FROM SC
查询满足条件的元组:WHERE子句

比较大小

确定范围

确定集合

字符匹配
这个部分内容我梳理一下:
首先就是LIKE 来进行字符匹配
接下来就是对字符本身的思考,类型,长度等就有




特殊点:如果要查询的字符串本身就还有%或这_时,要使用escape换码字符把通配符转义为普通字符。
案例:查询以‘DB_’开头的,且倒数第三个字符是i的课程的详细情况
SELECT * FROM Course WHERE Cname LIKE 'DB\_%I_ _'ESCAPE'\'
ESCAPE '\'表示‘\’为换码符号
涉及空值查询

注意“is”不能用“=”代替,不然你跟主播一样也是唐得很
多重条件查询
逻辑运算符:AND OR
这里要注意一下AND的优先级是要高于OR
当然还有别的办法调优先级,又不是什么跨越阶级,很好办的,()用括号就可以改变优先级


运用ORDER BY子句对查询结果排序
可以按一个或者多个属性列排序
升序:ASC 降序:DESC 缺省值为升序
对于空值,排序时显示的次序由具体系统实现来决定
ASC:排序为空值的元组最后显示
DESC:排序为空值的元组最先显示
查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排序
SELECT Sno ,Grade
FROM SC
WHERE Cno='3'
ORDER BY Grade DESC
查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
SELECT *
FROM Student
ORDER BY Sdept,Sage DESC
聚集函数

案例
查询学生总人数:
SELECT COUNT(*) FROM Student
查询选修了课程的学生人数:
SELECT COUNT(DISTINCT Sno) FROM SC
计算一号课程的学生平均成绩:
SELECT AVG(Grade) FROM SC WHERE Cno='1'
查询选修了1号课程的学生最高分数:
SELECT MAX(Grade) FROM SC WHERE Cno='1'
查询学生20125121选修课程的总学分数:
SELECT SUM(Ccredit) FROM SC,Course
WHERE Sno='201215121'AND SC.Cno=Course.Cno
运用GROUP BY 子句对查询结果分组
使用group by子句将查询结果表按某一列或多列值分组,值相等的分为一组
对查询结果的分组目的在于细化集函数的作用对象
如果未对查询结果分组,那么聚合函数就会作用于整个查询结果
其次对查询结果分组后,聚合函数会分别作用于每个组
按指定的一列或多列值分组,值相等的为一组
案例:

如果分组后还要按一定的条件对这些组进行筛选,最终只输出满足条件的组,则可以使用having断句来指定筛选条件。
查询选修了两门以上的课程的学生学号
SELECT Sno FROM SC GROUP BY Sno HAVING COUNT(*)>=2
OK,又到了关键时刻了!

接下来我给大家解释原因:
having短句与where子句的区别:作用对象不同
强扭的瓜不甜,对象找错了也是一样的会过苦13日子
WHERE子句作用于基表或视图,从中选择满足条件的元组
HAVING断句作用于组,从中选择满足条件的组
今天的内容就到这里吧,制作不易,喜欢的可以点赞关注加收藏支持一下!谢谢大家


















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









