






 本文详细介绍了Python中的模块概念,包括模块的定义、导入方式、模块命名规则,以及内置和标准库模块如math、time、random等的功能。此外,还涵盖了序列化、反序列化、持久化技术,如pickle、shelve和数据库的使用,以及Python的垃圾回收机制。
本文详细介绍了Python中的模块概念,包括模块的定义、导入方式、模块命名规则,以及内置和标准库模块如math、time、random等的功能。此外,还涵盖了序列化、反序列化、持久化技术,如pickle、shelve和数据库的使用,以及Python的垃圾回收机制。
一.模块
1.1 定义
.py结尾的文件是一个模块,里面存放的是类、函数、数......
1.2 导入模块
①另外创建一个“模块名.py” 文件
②导入的三种方式
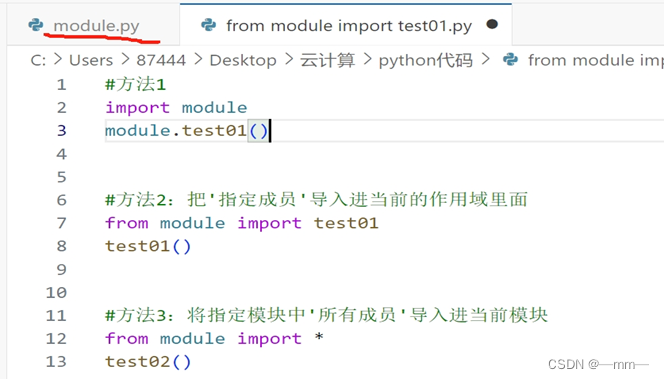
③如果导入进来的成员和自身成员冲突,距离谁近,就执行谁
④as别名:from 模块名 import test01 as a1
⑤如果模块中存在以 _ 开头的成员,则无法用from 模块名 import * 的方法导入到当前模块

⑥模块导入的时候,会执行模块中的顶层代码,而函数中的代码,只有在调用的时候会执行
1.3
①_all_ =[“ ”] :通过其指定的,只会限制from 模块名 import * 的导入,[ ]里面的不被限制
_doc_ :获取文档注释
_file_ :获取当前文件的绝对路径
_name_ :显示模块的名字
②if __name__ == "__main__" :
python文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本 中被调用。if __name__ == "main" : 之后的代码只有在第一种情况下会被执行,而import到其 他脚本中是不会被执行的。
1.4 模块分类
①内置模块
②标准库模块
(1)math库:
- math函数不支持复数类型,仅支持整数和浮点数运算。
- round(4.5) 个位数是奇数,严格按照四舍五入;个位数是偶数,则0.5会被舍去
- math.pow(2,3) 2的3次方等于8.0
- math.sqrt(4) 4开平方2.0
- math.fabs(x) x的绝对值
- math.fmod(x,y) 求余 y%x = y - (y/x)*x
(2)time库:
- 处理时间的标准库
- 三种表示时间的方式:时间戳、时间元组、格式化时间字符串
- 时间戳(1970-1-1 0:0:0):time.time

- 时间元组:time.localtiime

- 格式化时间字符串:年%Y 月%m 日%d 时%H 分%M 秒%S
- asctime : 接收时间元组,转换为字符串返回

- ctime() : 接收时间戳,返回字符串

- time.sleep(4) : 睡眠时间,程序暂停4s后在运行
(3)random模块:
- 该模块实现了各种分布的伪随机数生成器
- random.randint(1,10):获取某个范围内的随机整数 [left,right]
- int(random.random( )*10):获取0~1之间的随机数 [0,1)
- random.choice(ls):从有序的序列里面随机选一个元素,直接返回具体的元素
- random.choices(ls):返回的是随机抽取的元素组成的列表
(4)os模块
- 多种操作系统接口,主要提供和操作系统相关的功能
-
os.system(“ipconfig”) 帮助执行命令的
-
os.curdir 获取相对路径
-
os.getcwd( ) 获取当前工作目录的绝对路径
-
os.chdir("E:\\") 切换工作路径
-
os.listdir("E:\\7、5前端录屏") 列出指定目录下的文件
-
os.getlogin( ) 当前登录的用户名
-
os.sep 获取分隔符
(5)path模块
- path模块是os的子模块
- os.path 专门针对路径和文件系统的
- 导入:from os import path
-
path.basename(ll) 返回路径中的文件名部分 ll----文件地址
-
path.dirname(ll) 返回路径中的目录部分
-
altsep 分隔符
-
path.exists(ll) 判断文件是否存在,存在则返回True;不存在则返回False
-
path.split(ll) 分割
-
path.join(参数1,参数2) 用分割符\\将两个参数进行拼接
(6)sys模块
-
sys 提供的关于操作python自身解释器的方法,以及变量
-
sys.argv 返回的是脚本名称;返回的列表可以是多个数据
-
sys.getdefaultencogong() 获取默认编码
-
sys.getfilesystemencoding() 获取文件系统的默认编码
-
sys.getrecursionlimit() 获取递归限制
-
sys.setrecursionlimit(1500) 设置递归限制
-
sys.getrefcount() 获取引用数量
(7)UUID模块
-
生成一个不会重复的标识
-
UUID的生成算法是基于时间戳、硬件地址、随机数等多个因素的组合,这些因素的组合可以保证生成的UUID在全球范围内的唯一性。
-
缺点:检索效率会相应的减低
(8)hash相关的模块
-
hash表:①结果唯一 ②无序 ③单项不可逆
-
加密算法:对称加密des----加密和解密用的是同一个秘钥
非对称加密rsa----用的不是一个秘钥
-
hashlib:①数字检验 ②数据加密
-
hmac:专门进行数字加密的模块
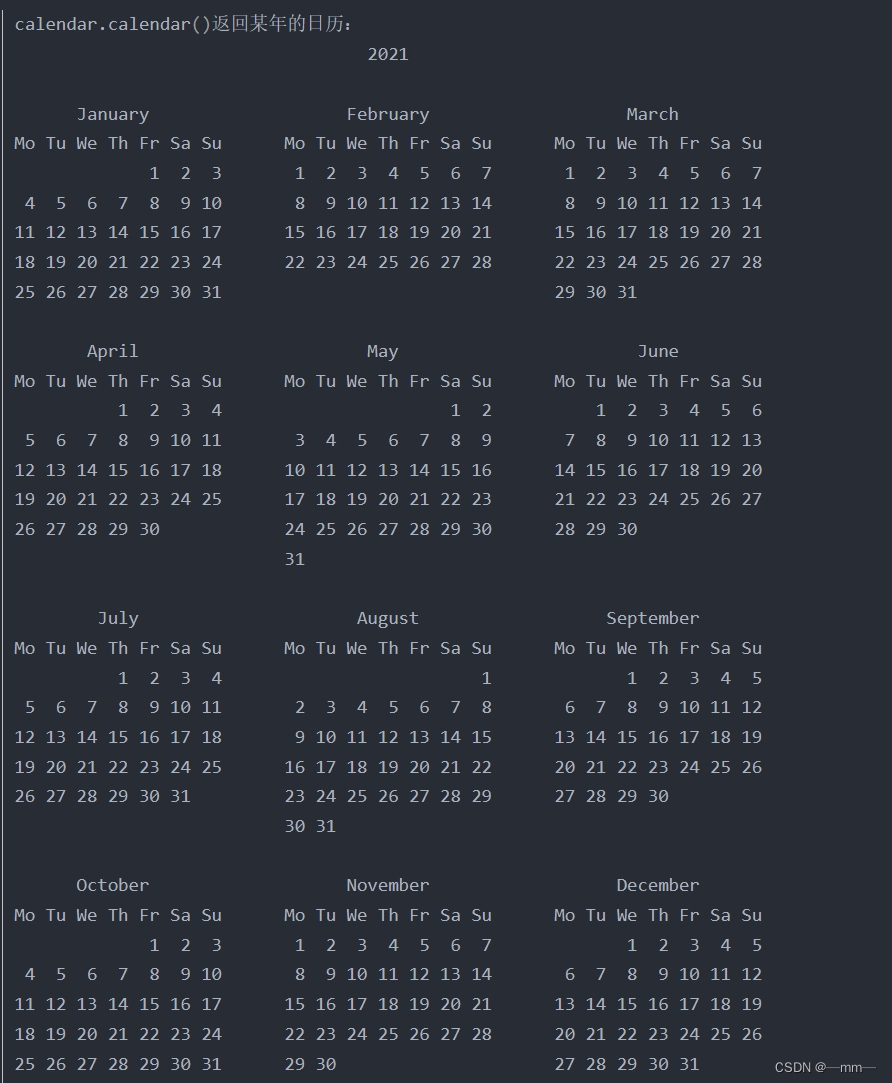
(9)calendar模块
-
python常用的处理日历的模块
-
calendar.firstweekday() 返回当前每周起始日期的设置。calendar模块默认周一为一周的第 一天。返回
0时,即星期一 -
calendar.calendar(2021)
-
-
二.i/o流
-
2.1
-
①i/o流:input output stream
-
②输入输出流:广义---指代的是计算机中数据的输入与输出,网络中的通信
狭义---指代的是内存中的输入与输出
-
③磁盘---内存---CPU
-
④内存:最重要的缓冲设备
-
⑤操作i/o流是通过函数:open
-
⑥关闭i/o流:f.close
-
2.2输入流和输出流
-
①i/o:数据的流动方向---站在内存的角度
②输入流:磁盘中的文件读取dia内存当中
③输出流:把内存当中的数据存储在磁盘上
-
2.3数据的类型
-
①字节流(0101二进制的):照片、音频、视频等媒体文件
-
②字符流:字符串 读取的效率高
-
2.4

三.
3.1序列化和反序列化
①序列化:将逻辑上存在的对象转换成字节或字符串,进行传输或保存 arr[1]=[1,2,3,4]
②反序列化:将字符或字节恢复为原来的数据结构形式
3.2持久化和反持久化
①持久化:将数据保存在磁盘当中
- 文件操作:可以使用Python内置的文件操作来将数据保存到文本文件中,例如open()函数打开文件并使用read()、write()、readlines()等方法来读写文件。
-
ickle模块:Python的pickle模块可以序列化Python对象并将其保存到文件中。反序列化后可以恢复原始对象。但是,pickle模块可能存在安全问题,因为它可以执行任意代码。
-
shelve模块:Python的shelve模块使用key-value存储方式将Python对象保存到文件中。shelve是一种简单易用的持久化方案,它使用pickle来实现序列化和反序列化。
-
数据库:使用关系型数据库如MySQL、PostgreSQL、SQLite等或非关系型数据库如MongoDB、Redis等可以更好的管理和组织数据。
②反持久化:从磁盘中将已持久化的对象恢复到内存中。这个过程的前提是序列化
四.
4.1垃圾回收机制
垃圾回收机制:代码运行在内存中,函数,进行弹栈释放内存
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









