






一、前言
人工智能技术的迅猛发展推动了大语言模型(LLMs)的迭代升级,然而模型性能的评估却面临两大核心挑战:测试集污染(模型通过训练数据记忆答案)和评测维度单一(过度依赖技术指标或主观偏好)。在此背景下,LiveBench与LMSYS两大评测平台应运而生,分别从客观能力验证与用户体验洞察切入,构建了互补的评估体系,成为学术界与产业界的重要参考工具。
LiveBench由Abacus AI团队联合图灵奖得主Yann LeCun开发,首创动态更新的防污染测试机制,每月更新10%的题目以规避模型“作弊”风险。其覆盖数学推理、代码生成等六大类任务,通过自动化评分系统量化模型的“硬实力”,例如要求模型生成代码并通过单元测试验证正确性。评测结果显示,开源模型如阿里Qwen2在特定任务中已逼近甚至超越闭源模型,标志着技术民主化的新趋势。
而LMSYS的Chatbot Arena则聚焦用户真实场景中的交互体验,通过匿名盲测与ELO排名机制,揭示模型在流畅性、安全性和实用性上的差异。例如,Claude 3.5 Sonnet虽在部分客观任务中落后于GPT-4o,却因自然对话能力长期位居用户偏好榜首。这种“主观与客观的割裂”凸显了技术性能与用户需求间的微妙平衡。
二者的协同价值在产业实践中尤为显著:企业可先用LiveBench筛选出技术达标的候选模型,再通过LMSYS评估其落地适用性。例如,阶跃星辰的Step-2模型凭借LiveBench的客观高分与LMSYS的用户口碑,成为金融、医疗等领域的首选方案。
- LiveBench:https://livebench.ai
- LMSYS:https://lmarena.ai/leaderboard
二、LiveBench
1. 背景与概述
LiveBench 是一个在线实时评测平台,旨在为研究者与开发者提供对各类大型语言模型(LLMs)的实时性能测试、对比和可视化。通过统一接口和标准化的评测任务,LiveBench 能够让不同模型的能力在同一环境下被快速量化与对照。它通常包括以下几个核心目标:
- 降低评测门槛:无需繁琐配置,即可在网页端或统一脚本中对主流大模型进行推理调用并记录结果。
- 实时性:随时查看模型在各项任务上的最新表现,跟进社区或厂商的新版本更新。
- 多维度可视化:通过图表、排名等方式直观呈现模型在准确率、速度、推理成本等方面的差异。
2. 主要功能
-
实时测试
LiveBench 通常提供若干预定义的测试集或交互式对话界面,用户可输入文本或问题,查看不同大模型的生成结果。平台会并列展示各模型输出,方便用户直观比较回答质量、逻辑连贯度、语言风格等。 -
多维度指标
除了传统的准确率、生成质量指标(如 BLEU、ROUGE、PPL 等),LiveBench 可能还监测:- 响应速度(Latency)
- 推理成本(Memory / GPU 资源占用)
- 安全与对齐(对敏感话题或有害内容的过滤能力)
-
模型列表与版本追踪
LiveBench 会列出多家机构或社区维护的大模型(如 GPT-3.5、GPT-4、PaLM 2、Llama2、Qwen 等),并标注其版本号与发布日期,帮助用户了解各模型的更新历程及其在不同时间点的性能。 -
可视化与排名
平台对评测结果进行可视化呈现,如柱状图、折线图或雷达图,并基于综合得分对模型进行排名。用户可自定义权重(如更关注速度或更关注准确度),以得到更符合自身需求的排名结果。
3. 用户价值
- 研究者:可将自己提出的新方法或改进版本提交到 LiveBench,快速验证在多任务场景下的表现,并与主流模型进行对比。
- 开发者:可借助 LiveBench 做选型决策,如在对话系统或搜索场景中,需要高速度还是高精度等。LiveBench 的可视化比较有助于快速定位合适模型。
- 普通用户:能在一个统一界面体验多种大模型的回答质量,了解其优缺点。
4. 可能的扩展
- 任务多样化:LiveBench 可能持续新增对话问答、翻译、代码生成、多语言场景等评测任务。
- 用户自定义:未来或支持用户上传自定义数据集进行批量测试,生成更具针对性的报告。
- 自动评估:引入自动化打分或多模态评测,适配语音、图像等多模态输入。
5. LLM最新排行榜
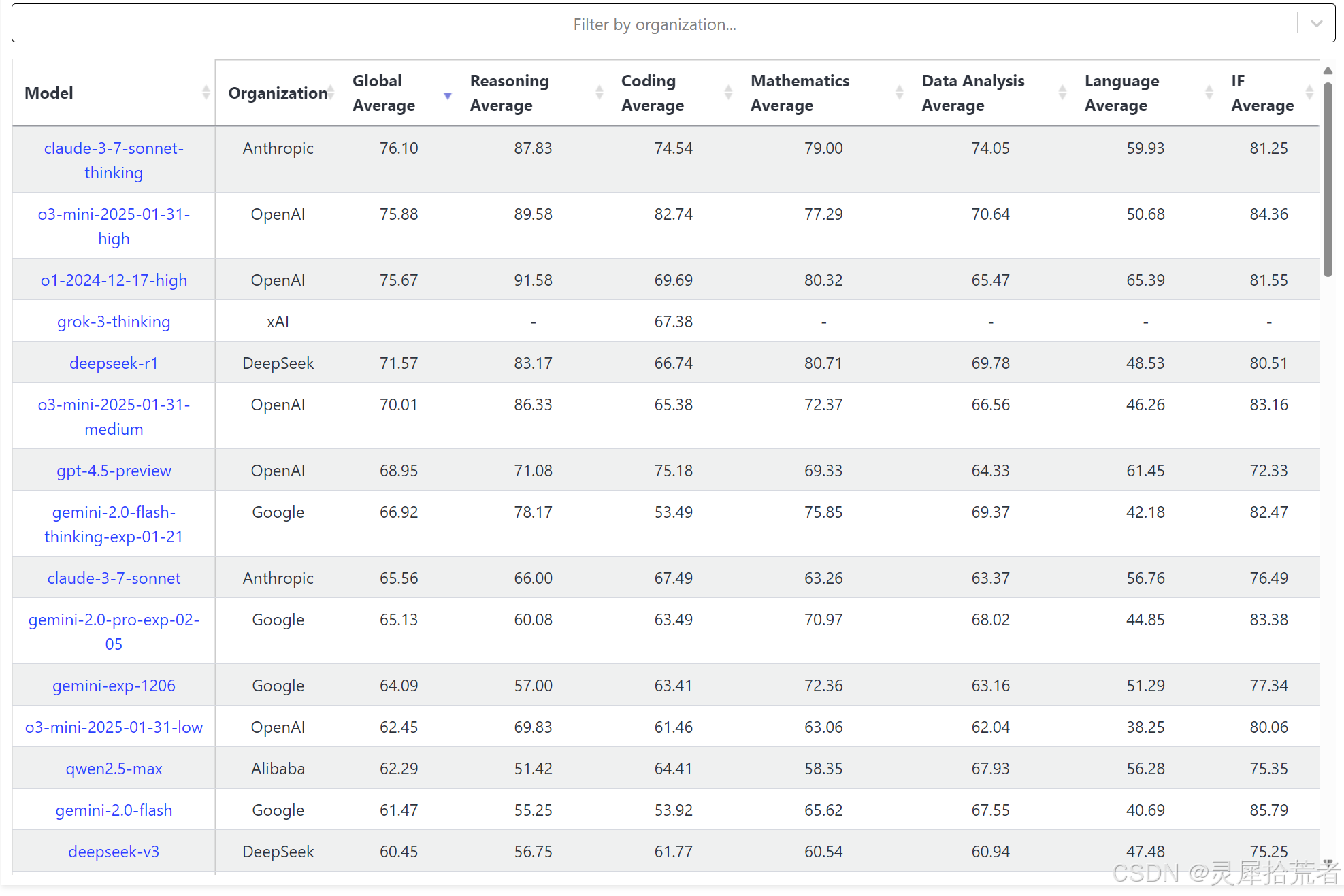
-
表格结构
- Model 列列出了各大模型的名称,如
claude-3-7-sonnet-thinking、o3-mini-2025-01-31-high、deepseek-r1、gpt-4.5-preview等。 - Organization 列标注了对应模型的提供方或社区,如 Anthropic、OpenAI、DeepSeek、Google 等。
- 后续各列则是不同评测维度的平均分数(Average),如 Global Average(整体平均分)、Reasoning Average(推理能力)、Coding Average(代码能力)、Mathematics Average(数学推理能力)、Data Analysis Average(数据分析能力)、Language Average(语言处理能力)以及 IF Average(可能是某个推断指标或“Instruction Following”指标的平均分)。
- Model 列列出了各大模型的名称,如
-
分数排序
- 表格按某个指标(如 Reasoning Average)或 Global Average 排序,可以看出在所列出的各模型中,
claude-3-7-sonnet-thinking、o3-mini-2025-01-31-high、o1-2024-12-17-high等模型在一些维度上得分较高。 - 也有一些模型分数较低,反映了它们在该场景或数据集上的表现相对不佳。
- 表格按某个指标(如 Reasoning Average)或 Global Average 排序,可以看出在所列出的各模型中,
-
多维度能力
- 评测维度较为细化:Reasoning(推理)、Coding(编程)、Mathematics(数学)、Data Analysis(数据分析)和 Language(语言理解/表达)等。
- 可以发现某些模型在特定领域得分突出,如在数学推理或编程能力上表现更好,但在语言表达或数据分析方面可能略有不足,反映了不同大模型在技术设计与训练数据上的差异。
-
整体趋势
- 评分大多在 50~90 区间,说明各模型都已有一定的通用语言理解与推理能力,但依旧存在明显的性能差异。
- 某些高分模型多来自 Anthropic、OpenAI 等大厂或社区团队,显示了它们在模型规模、训练数据和优化方法上的优势。
-
用途与价值
- 该表格可帮助研究者或开发者在不同维度快速了解主流大模型的强弱点,从而在应用场景中做出更合适的模型选择。
- 对普通用户而言,则能直观地看到目前各大模型在多项任务中的表现,对比它们的综合能力。
三、LMSYS
1. 背景与概述
LMSYS(Large Model Systems)可以理解为一个面向大模型系统的综合平台/组织,致力于收录与展示大模型在多维度下的表现,并提供与大模型开发、部署相关的资源与工具。其目标是打造一个面向 LLM 的评测、管理、协作、部署平台,涵盖从模型训练到推理落地的整个生命周期。
一些社区讨论中,也有人将 LMSYS 视为由特定团队发起的开源项目或竞赛平台,其主要思路是让各大模型在统一框架下进行对比,并为用户提供快速接入与实验环境。
2. 主要功能
-
模型管理与资源库
- 收录多种主流大语言模型的权重、配置、推理脚本等,用户可在同一平台获取所需模型并进行实验。
- 提供了版本追踪与 changelog,便于研究者了解模型在不同时期的更新内容(如结构调整、训练数据变动等)。
-
评测基准与自动化脚本
- LMSYS 可能集成了广泛的数据集与任务类型(如 GLUE、SuperGLUE、MMLU、SQuAD、HellaSwag 等),并配套自动化评测脚本,让用户能对模型进行标准化测试。
- 提供可视化仪表盘或表格,呈现模型在各数据集上的分数、推理速度、GPU 占用率等。
-
协作与社区
- 可能有论坛、issue 区或 pull request 机制,允许研究者提交新模型、新任务或新评测指标。
- 以开放社区的形式推动大模型生态的发展。
-
部署与分布式训练工具
- 由于许多大模型规模在数十亿到数千亿参数级别,LMSYS 或许会集成多机多卡训练方案、量化、剪枝等工具,方便用户快速实验并上线。
3. 典型应用场景
- 学术研究:研究者将新提出的模型上传至 LMSYS 平台,通过已有基准数据集的自动化脚本进行对比评测,若结果优异,可快速获得社区关注。
- 企业选型:工业界可参考 LMSYS 提供的统一评测结果,结合自身需求(如推理速度、内存开销、License 限制等)做出选型决策。
- 社区互助:LMSYS 的论坛或 issue 区可汇集大模型开发者,讨论训练细节、推理优化等技术要点。
4. 未来可能发展
- 多模态与跨领域:除文本外,支持图像、音频、视频或表格数据的多模态大模型评测。
- 自动化调度与云服务:基于用户的负载自动调度最优模型或资源配置。
- 更强的安全评估:建立对大模型输出的伦理与合规检测体系,对模型进行深层审查并给出风险提示。
5. LLM最新排行榜
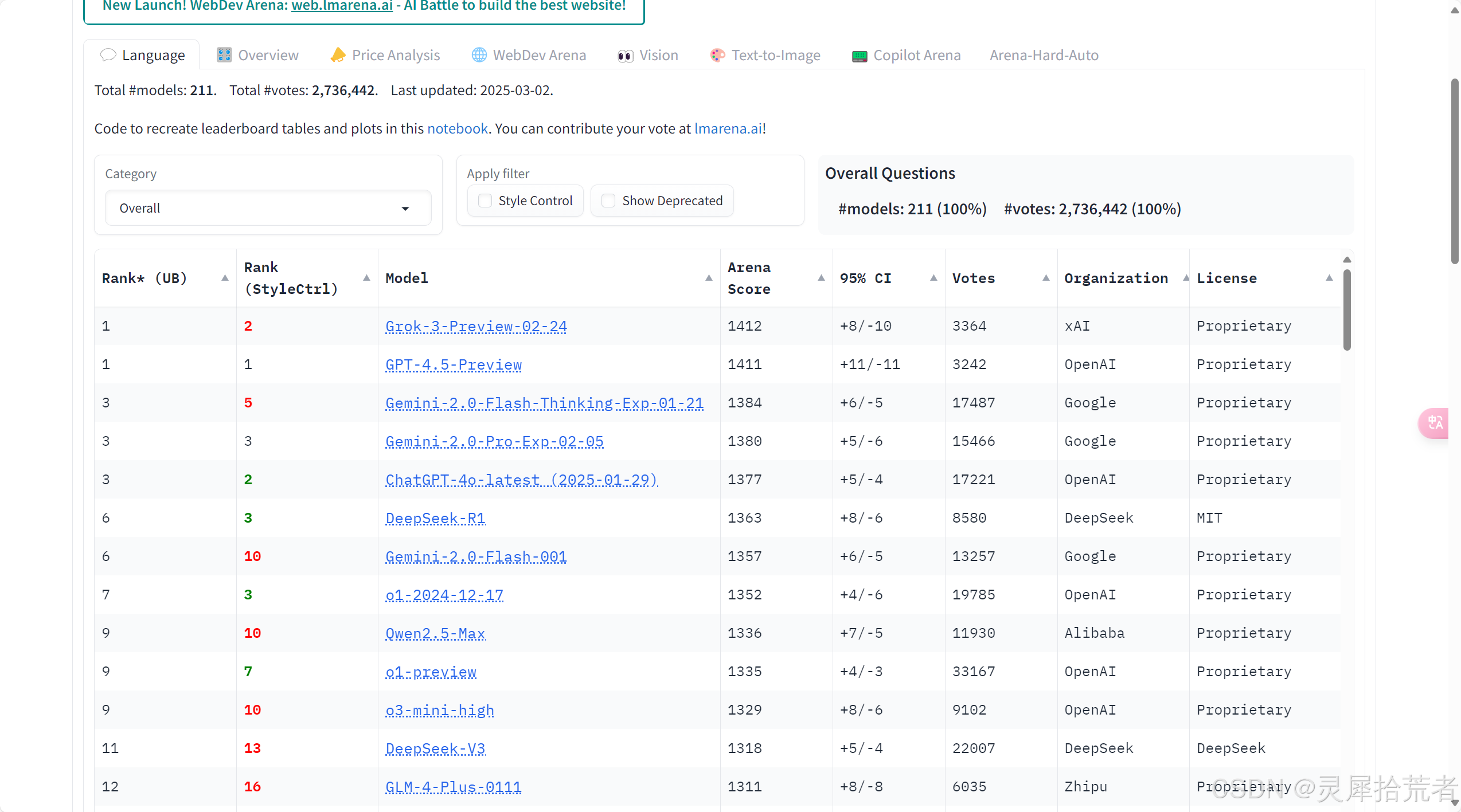
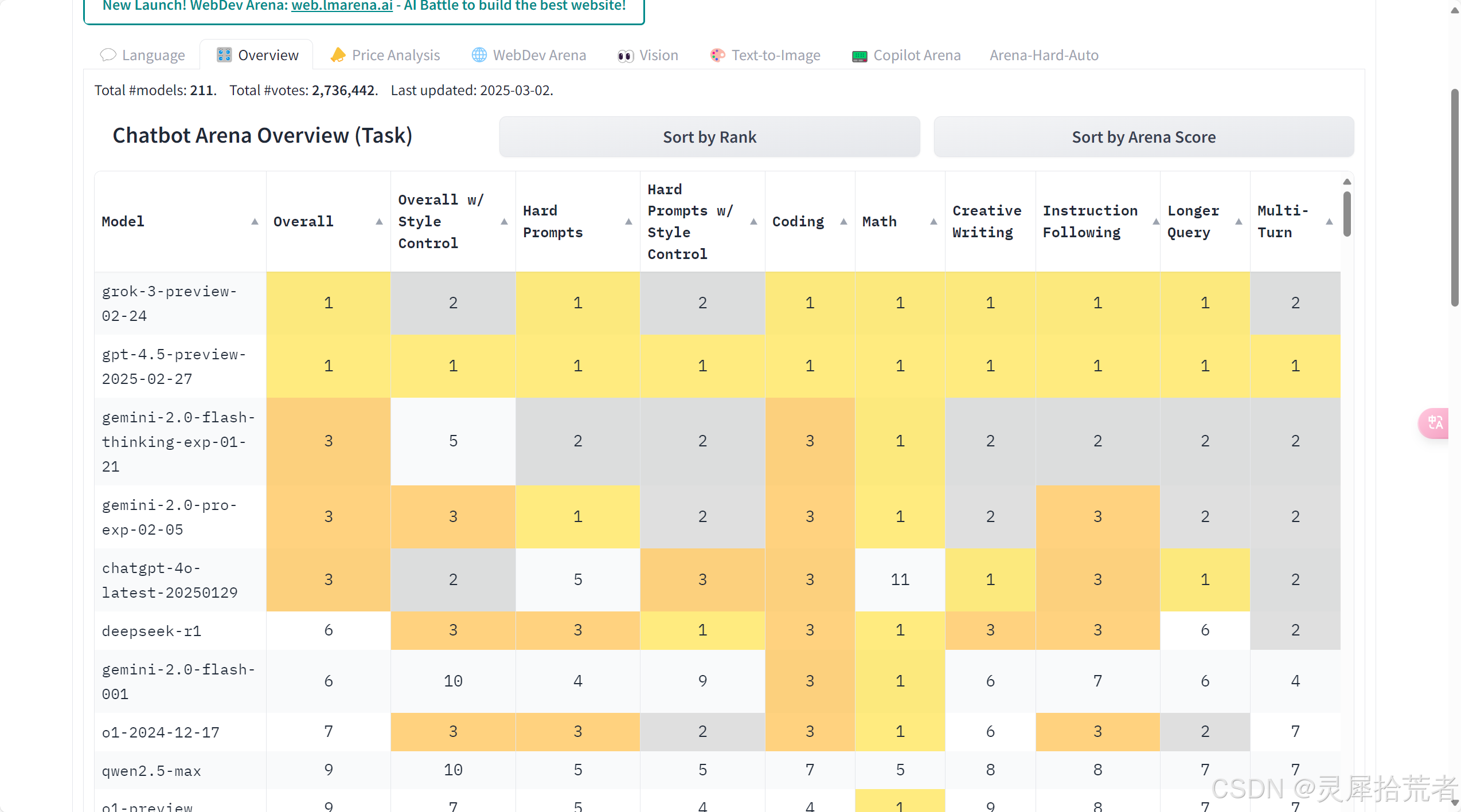
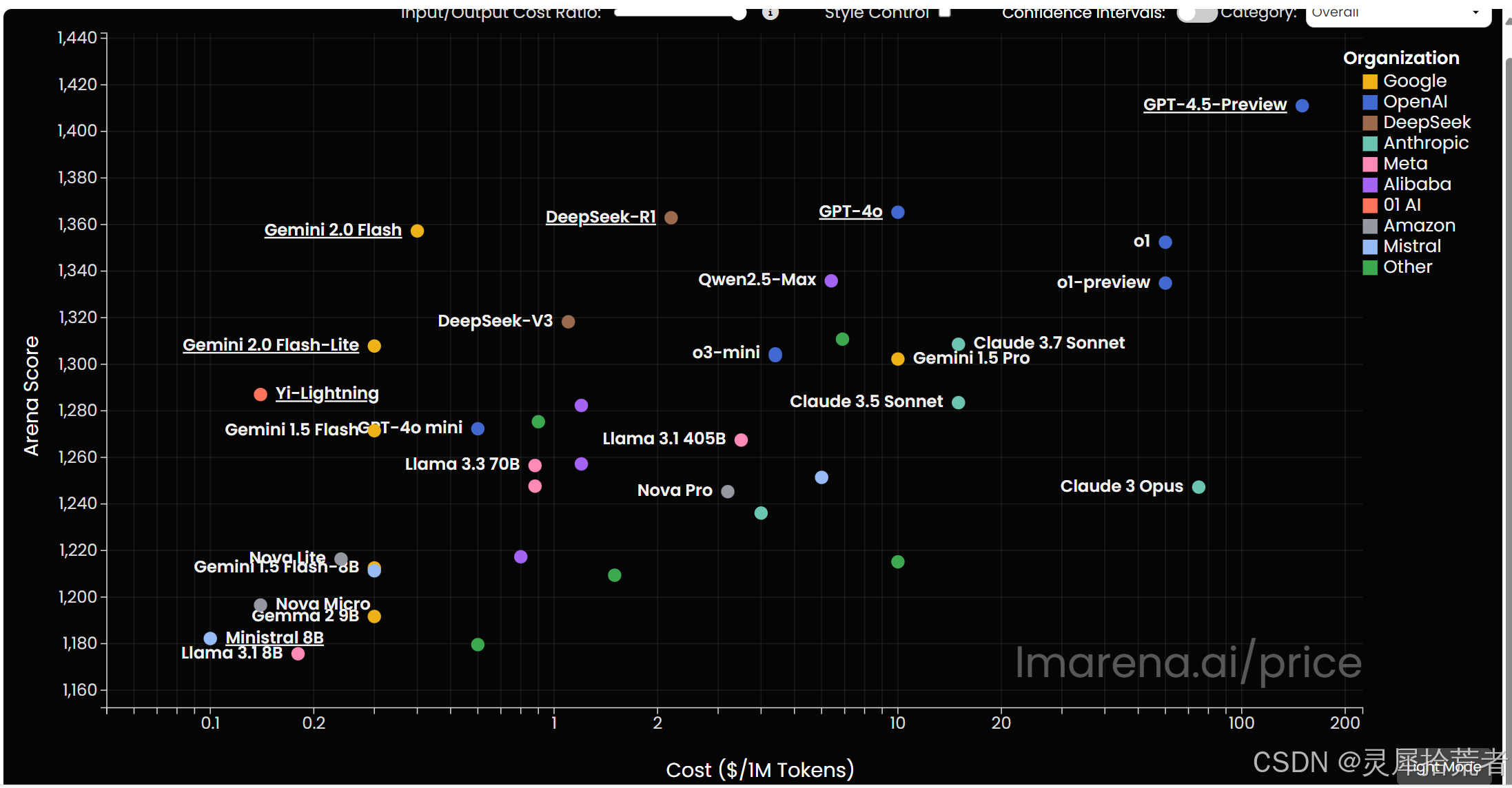
1. 模型与排名
- Grok-3-Preview-02-24:排名第一,Arena Score 为 1412,得到了 3364 次投票,属于 xAI(Proprietary License,专有许可)。
- GPT-4.5-Preview:紧随其后,排名第二,Arena Score 为 1411,投票数为 3242,来自 OpenAI,同样是专有许可。
- Gemini-2.0-Flash-Thinking-Exp-01-21:排名第三,Arena Score 1384,投票数为 17487,来自 Google,专有许可。
- Gemini-2.0-Pro-Exp-02-05:排名第四,Arena Score 1380,投票数为 15466,来自 Google。
- ChatGPT-4.0-latest (2025-01-29):排名第五,Arena Score 为 1377,投票数为 17221,来自 OpenAI,专有许可。
- DeepSeek-R1:排名第六,Arena Score 为 1363,投票数 8580,来自 DeepSeek,开源 MIT 许可。
2. 评分与表现
- Grok-3-Preview-02-24 和 GPT-4.5-Preview 的 Arena Score 非常接近,分别为 1412 和 1411,显示了这两款模型在评测中的非常接近的表现。然而,Grok-3-Preview 的 95% CI 置信区间略大(+8/-10),而 GPT-4.5-Preview 的为 (+11/-11),显示出 GPT-4.5-Preview 在输出的一致性上稍微更高一些。
- DeepSeek-R1 的表现稍逊色于前者,Arena Score 为 1363,排名第六。它的置信区间为 +8/-6,表明它在结果的稳定性上优于许多低排名的模型,但略逊于 GPT 和 Grok。
3. 投票数
- Gemini-2.0-Flash-Thinking-Exp-01-21 以 17487 次投票,明显超过其他模型,可能说明它在用户体验或研究中的活跃度更高。
- 相比之下,DeepSeek-R1 的投票数只有 8580,可能表明它的关注度或使用广度较少,尽管它在某些任务中表现优异。
4. 创新与变化
- Grok 3 和 Claude 3.7(并未出现在此图中,但可以推测其类似于 Grok)都属于较为新的模型,其设计可能集中在多轮对话、语境理解和细化推理能力上,尤其是在与 GPT-4 和 Gemini 系列的对比中,GroK 可能在推理任务中表现更为优秀。
- DeepSeek-R1 和 GPT-4.5 是具有显著技术优化的模型,代表了传统大模型(如 GPT 系列)与新兴模型(如 DeepSeek)的对比,分别在推理能力、数据处理和安全性方面有所不同。DeepSeek 可能更专注于高效推理,而 GPT-4.5 在语言表达上有较好的稳定性和连贯性。
5. 总结
- Grok 3 和 GPT-4.5 是当前市场中的佼佼者,在推理能力、模型表现以及整体稳定性上表现出色。
- DeepSeek-R1 则展示了开源和定制化的潜力,尤其在应用场景中的精细化调优上具有独特优势。
四、LiveBench 与 LMSYS 的比较与互补
-
关注重点
- LiveBench 更倾向于“实时在线对比”大模型回答,可视化并行输出结果,让用户直接观摩不同模型在相同输入下的表现。
- LMSYS 更注重“全生命周期管理与评测”,包含从模型训练到分布式部署,以及多数据集、多指标的自动化测评。
-
受众与应用
- LiveBench:对需要快速体验和对比多模型回答的用户、想要直观查看生成内容质量的研究者和开发者更友好。
- LMSYS:适合想要深度研究大模型训练、评测和部署的团队,或在学术层面系统对比模型性能的研究者。
-
技术栈
- 两者可能都使用云端服务器或容器化部署,接入 Hugging Face 等模型来源或本地私有模型。
- 都需维护一套评测脚本/后端逻辑,处理并发用户请求,并对输出进行记录与可视化。
-
互补性
- 若将 LiveBench 集成进 LMSYS,可让用户在 LMSYS 管理的模型上直接进行实时交互评测,形成“管理 + 实时可视化”的闭环。
- 也可能各自独立,LiveBench 强调体验与可视化,LMSYS 强调底层评测与训练流程管理,供用户按需选择。
五、总结与思考
LiveBench 与 LMSYS 都是面向大模型的线上平台或工具集,各自从不同维度满足研究者、开发者对大模型评测、比较、管理、部署的需求:
- LiveBench:专注“实时可视化对比”,帮助用户快速了解多模型在相同输入下的输出差异,并记录速度、质量、合规性等指标。
- LMSYS:更偏向“全方位管理与评测”,支持自动化基准测试、分布式训练、模型版本管理和社区协作。
随着大语言模型在工业界和学术界的应用场景不断扩大,这类平台也会不断更新迭代,纳入更多评测任务、多模态能力以及安全合规评估机制,为大模型生态提供更完善的支持。
【作者声明】
本文为对 LiveBench 与 LMSYS 两个大模型评测/管理平台的简要介绍,所涉信息基于公开资料与社区讨论整理,若与官方更新不符,请以其官方页面为准。本文不代表任何商业或法律立场,仅供技术交流与参考。

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









