







直观理解
-
合并区间:
- 按起始排序后,合并过程只需关注当前区间与前一个合并后的区间是否重叠,无需回溯。
- 合并后的结束时间越大,越可能覆盖后续重叠。
-
无重叠区间:
- 按结束时间排序后,每次选择最早结束的区间,能最大化后续可选区间数量。
- 结束越早,留给后续的“时间窗口”越长。
数学证明(无重叠区间贪心正确性)
假设存在一个最优解 A,其中第一个区间是 x(非最早结束的区间)。
将 x 替换为排序后的第一个区间 y(结束时间更早),则 y 的结束时间 ≤ x 的结束时间,因此替换后的解 A' 仍然有效且保留的区间数不变。
通过归纳法可证,贪心策略总能得到最优解。
总结
- 合并区间需要确保所有可能的重叠被覆盖,按起始时间排序便于连续合并。
- 无重叠区间需要最大化保留数量,按结束时间排序能保证每次选择的区间为后续留出最大空间。
两种策略均基于贪心思想的局部最优性,但问题目标不同导致排序依据截然相反。
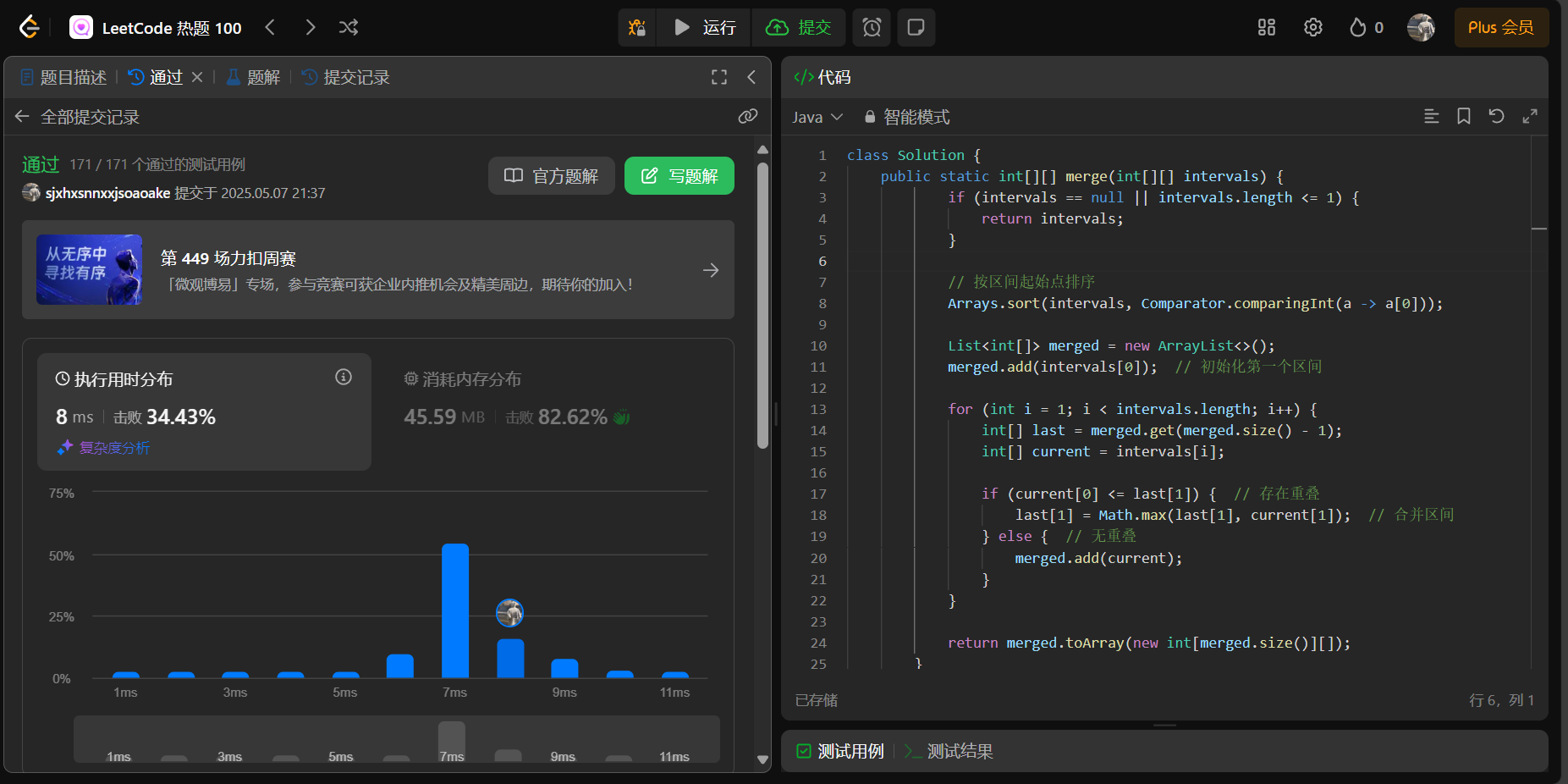
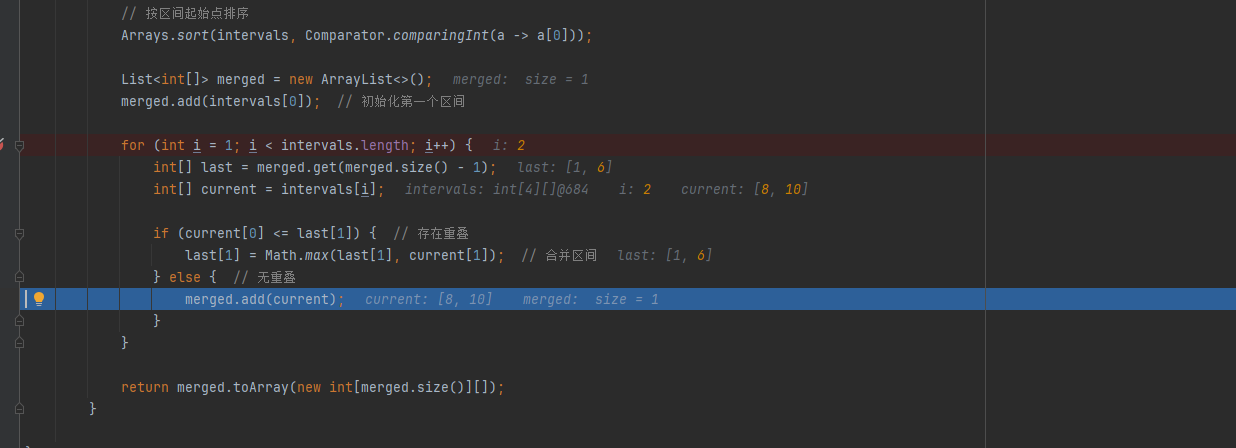
思路: 合并区间,要先进行排序,将相邻的区间排在一块,判断上一个区间的末尾和当前区间的开始,如果当前区间的开始在上一个区间的结尾,那么就是重复区间,就要合并
重叠:当前区间的结束点 ≥ 下一个区间的起始点时,合并并更新当前区间的结束点。
不重叠:将当前区间加入结果列表,并更新为下一个区间。

第一种,判断他们是重复区间之后,判断一下他们两个的结束点谁大,谁大谁就是合并区间后的结尾。
第三种直接把当前区间加到result区间中。


















 1747
1747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









