






都要2025了,还能靠加注意力机制发论文么?试了很多注意力机制,为何精度不升反降?
毫无疑问,注意力机制魔改依然是深度学习论文创新和涨点的利器!但诸多传统注意力被过度使用,导致创新不足。且如今简单地改层数已经不算创新了!
因而跟进领域前沿,采用全新的注意力机制才好脱颖而出,比如有模型就通过与频域结合进行魔改,实现了浮点运算降低98%的显著效果!此外,根据场景魔改也是重要趋势,比如关注添加注意力机制的位置、任务适配……
为方便大家研究的进行,花了几天时间给大家整理了40个必备的注意力机制,原文和源码都有,全部都是24年最新的,且大多来自顶会,质量有保证!相信通过这些文章的研读,大家能够从前辈们的改进思路中找到灵感启发,早点发出自己的顶会。
论文原文+开源代码需要的同学看文末
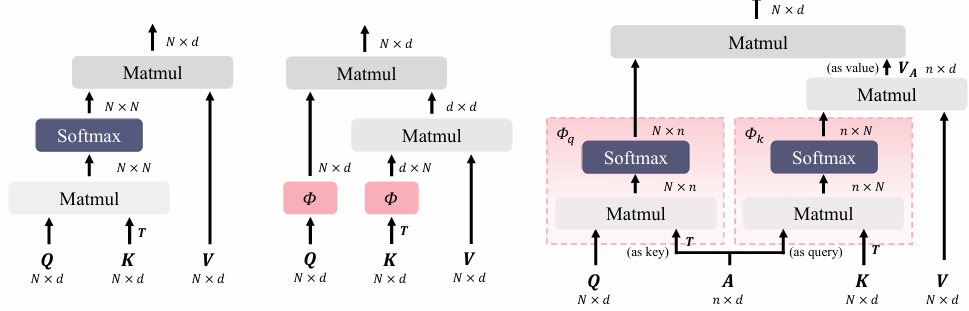
Agent 代理注意力
Agent Attention: On the Integration of Softmax and Linear Attention
内容:论文提出了一种新的注意力机制——Agent Attention,它通过引入一组代理令牌(来平衡计算效率和表示能力。这种机制首先让代理令牌作为查询令牌的代理,从键值对中聚合信息,然后将信息广播回查询令牌。由于代理令牌的数量可以远小于查询令牌,Agent Attention在保持全局上下文建模能力的同时,显著提高了计算效率。此外,Agent Attention被证明是线性注意力的一种推广形式,因此无缝地整合了强大的Softmax注意力和高效的线性注意力。
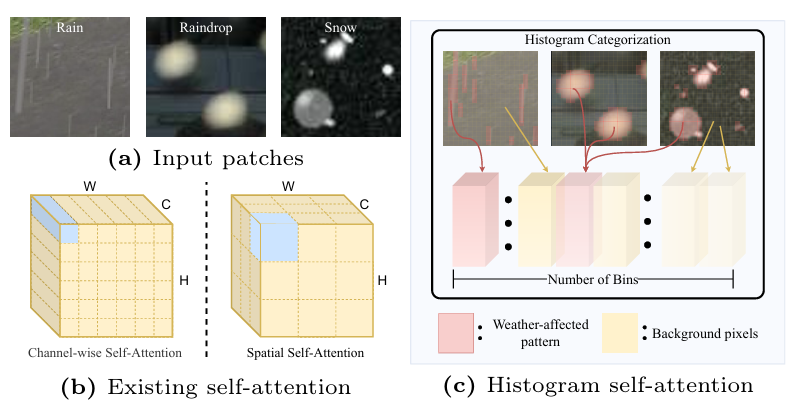
直方图注意力
Restoring Images in Adverse Weather Conditions via Histogram Transformer
内容:论文介绍了一种名为Histoformer的新型图像恢复方法,用于在恶劣天气条件下恢复图像。该方法通过一种称为直方图自注意力的机制,将空间特征按强度分桶,并在桶间或桶内应用自注意力,以选择性地关注动态范围内的相似退化像素。此外,论文还提出了一种动态范围卷积,使传统卷积能够在相似像素而非邻近像素上操作,并引入了相关性损失函数来强化恢复图像与真实图像之间的线性关系。
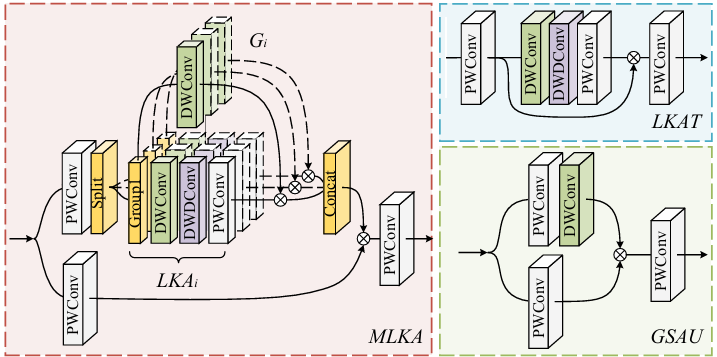
多尺度注意力
Multi-scale Attention Network for Single Image Super-Resolution
内容:论文提出了一种基于卷积神经网络(CNN)的多尺度注意力网络(MAN),用于单图像超分辨率(SR)任务。该网络结合了多尺度大核注意力(MLKA)和门控空间注意力单元(GSAU),以提高卷积SR网络的性能,通过在不同粒度级别上获取丰富的注意力图,聚合全局和局部信息,避免潜在的块状伪影,并简化前馈网络以减少参数和计算量,同时保持性能。实验结果表明,MAN在不同复杂度下都能实现与最先进的性能和计算之间的良好权衡。
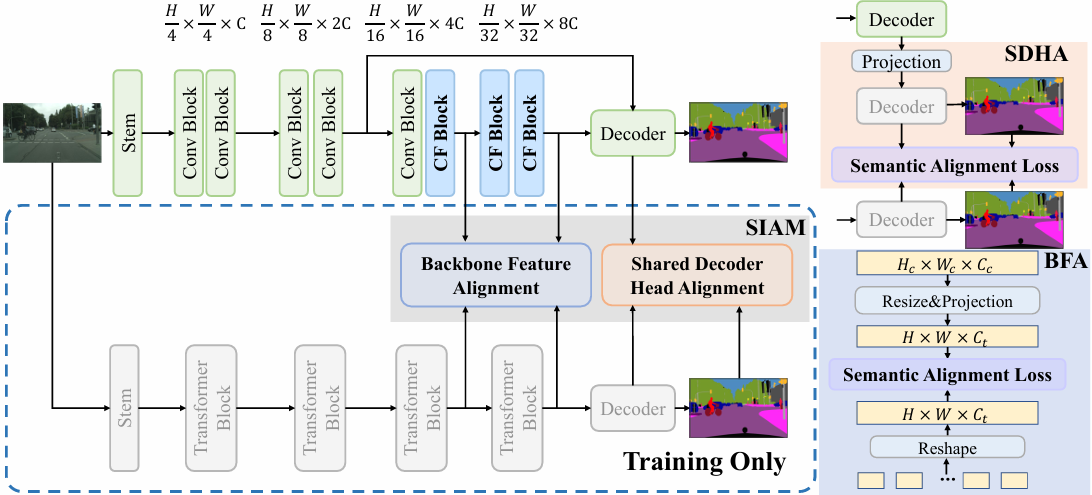
Conv-Former注意力
SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation
内容:论文介绍了一种名为SCTNet的单分支卷积神经网络(CNN),它通过Transformer的语义信息来实现实时语义分割。SCTNet在训练时使用变换器作为语义分支以提取丰富的全局上下文,并通过提出的CFBlock和语义信息对齐模块捕获丰富语义信息。在推理时,仅部署单分支CNN,从而在保持轻量级单分支CNN的高效率的同时,实现了与变换器相当的准确性。实验结果表明,SCTNet在多个数据集上达到了新的最先进性能。
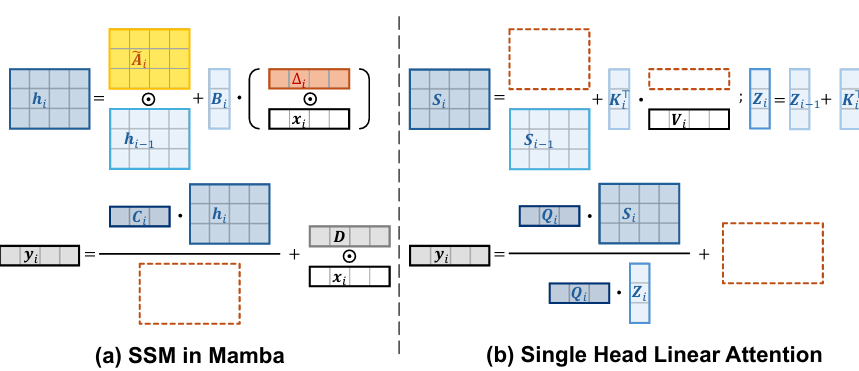
mamba线性注意力
Demystify Mamba in Vision: A Linear Attention Perspective
内容:论文揭示了Mamba模型与线性注意力Transformer之间的密切关系,并分析了Mamba成功的关键因素。作者将Mamba重新表述为线性注意力Transformer的一个变体,并指出了六个主要区别:输入门、遗忘门、快捷连接、无注意力归一化、单头和修改后的块设计。通过实验验证,文章发现遗忘门和块设计是提升性能的核心因素,而其他区别对性能提升贡献较小或有负面影响。
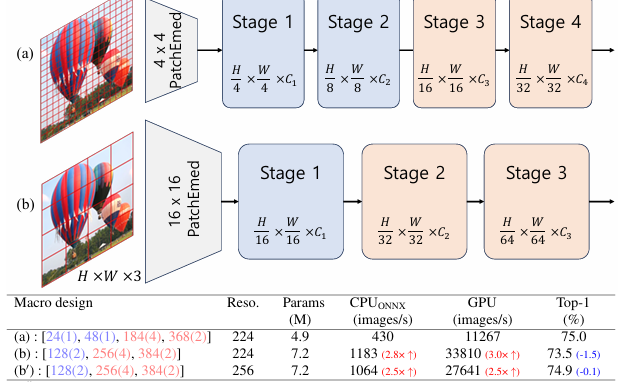
单头注意力机制
SHViT: Single-Head Vision Transformer with Memory Efficient Macro Design
内容:论文介绍了一种名为SHViT的新型单头视觉变换器,旨在提高资源受限设备上的实时语义分割性能。SHViT通过采用16×16的patch嵌入和3阶段层次结构,以及提出的单头自注意力(SHSA)模块,有效地减少了内存访问成本并提高了计算效率。实验结果表明,SHViT在ImageNet-1K分类、COCO目标检测和实例分割等多个任务上达到了与现有最先进方法相媲美的速度和准确性,同时在不同设备上展现出卓越的性能。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【40注意】获取完整论文
👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









