






多模态融合新突破,入选CVPR25!这是一个通用的多模态融合框架,作者通过低层次视觉任务的交互,使模型性能飙升了88.12%!
不仅如此,在各顶会、顶刊其也都是研究焦点!像是NeurIPS Oral上的联合优化融合E2E-MFD;TPAMI上的空间-频域融合SFINet;ICML上高效像素级融合GeminiFusion……
这是因为,多模态融合作为AI领域的核心技术,在提高模型感知和决策能力方面,不可替代!且下游任务非常丰富(虚假新闻检测、情感分析、谣言检测等),三模态、二模态数据集都有,结合不同的场景,我们便能进行微创新!此外,Mamba等新技术的发展,也给我们提供了机会,比如把基于注意力机制的融合策略,改成Mamba便是新文章!
为方便大家研究的进行,我给大家准备了17种创新思路和源码。主要涉及动态融合、跨模态生成与推理、轻量化……
论文原文+开源代码需要的同学看文末
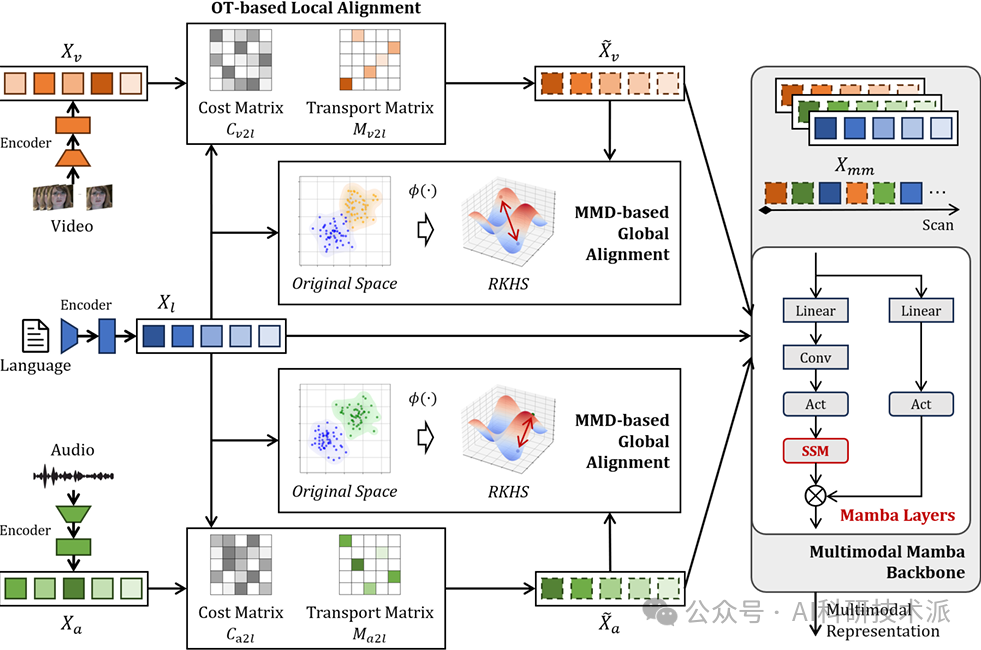
AlignMamba: Enhancing Multimodal Mamba with Local and Global Cross-modal Alignment
内容:这篇文章介绍了一种名为AlignMamba的多模态融合方法,旨在解决现有基于Mamba的方法在跨模态关系建模上的不足。AlignMamba通过引入基于最优传输(OT)的局部跨模态对齐模块和基于最大均值差异(MMD)的全局跨模态对齐损失,将局部和全局对齐信息整合到Mamba框架中,从而实现高效且有效的多模态融合。实验表明,AlignMamba在完整和不完整的多模态融合任务中均表现出色,不仅提升了分类准确率,还显著降低了GPU内存使用量和推理时间。
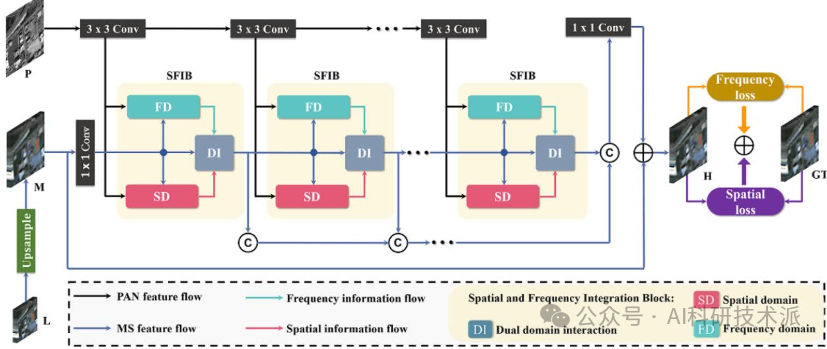
A General Spatial-Frequency Learning Framework for Multimodal Image Fusion
内容:这篇文章提出了一种名为AlignMamba的多模态融合方法,通过结合基于最优传输(OT)的局部对齐模块和基于最大均值差异(MMD)的全局对齐损失,解决了现有方法在跨模态对齐上的不足。该方法在保持线性计算复杂度的同时,能够有效捕捉模态间的细粒度对应关系和整体分布一致性,从而实现高效且准确的多模态表示融合。实验结果表明,AlignMamba 在完整和不完整的多模态融合任务中均达到了最先进的性能,显著降低了计算复杂度。
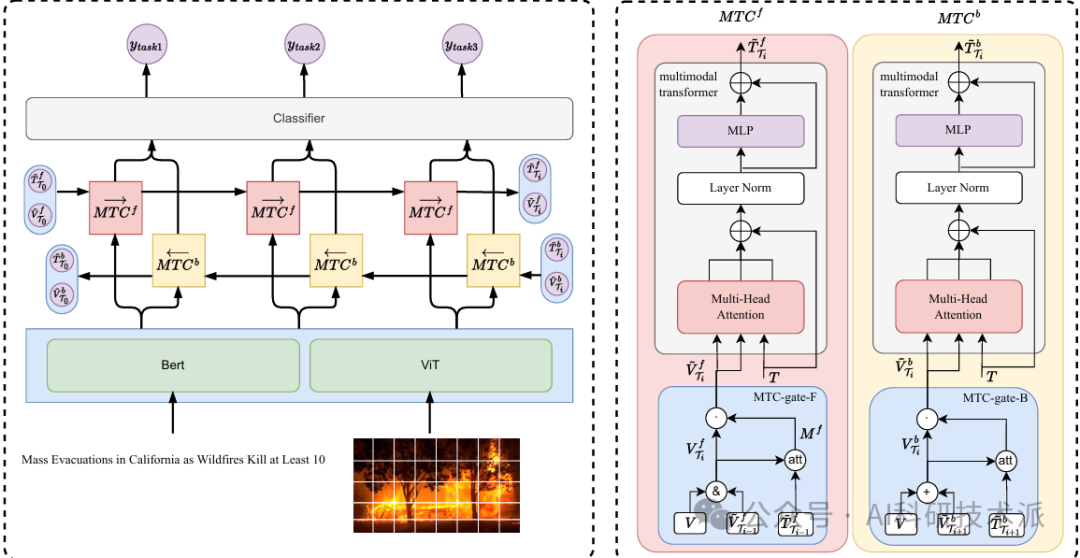
Damage Analysis via Bidirectional Multi-Task Cascaded Multimodal Fusion
内容:这篇文章提出了一种名为BiMCF的方法,用于社交媒体平台中的灾害分析。灾害分析涉及多个子任务,包括信息相关性预测、人道主义类别分类和严重性评估。BiMCF 通过引入双向多任务级联框架,将视觉和文本信息分别整合到每个任务中,并利用双向传播机制在任务间传递交互信息,从而增强多模态融合效果。实验结果表明,BiMCF 在灾害分析的多个子任务上均取得了优于现有方法的性能,同时展示了对不同任务序列和模型架构的鲁棒性。
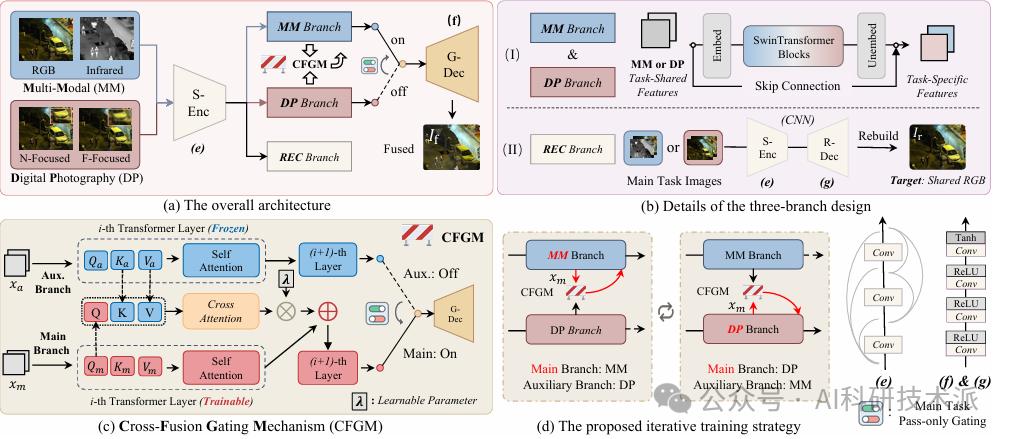
One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
内容:这篇文章提出了一种名为GIFNet的新型图像融合网络,旨在通过低层次视觉任务的交互来实现任务无关的图像融合。GIFNet 通过结合多模态图像融合和数字摄影图像融合任务,利用像素级监督信号来增强任务共享的特征学习,从而提高融合性能。该网络采用三分支架构,包括主任务分支、辅助任务分支和协调分支,通过交叉融合门控机制(CFGM)实现任务间的有效交互,并通过重建任务和增强的 RGB 数据集来对齐不同融合任务的特征。实验结果表明,GIFNet 在多种图像融合任务(包括多模态和单模态场景)中均表现出色,不仅在已见任务上取得了优异性能,还在未见任务上展示了强大的泛化能力。此外,GIFNet 还支持单模态增强,为实际应用提供了更大的灵活性。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【17多融】获取完整论文
👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









