








博主主页:Yan. yan.
C语言专栏
数据结构专栏
力扣牛客经典题目专栏
C++专栏

文章目录
一、内联函数
1、概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
下面是一个普通的函数调用:
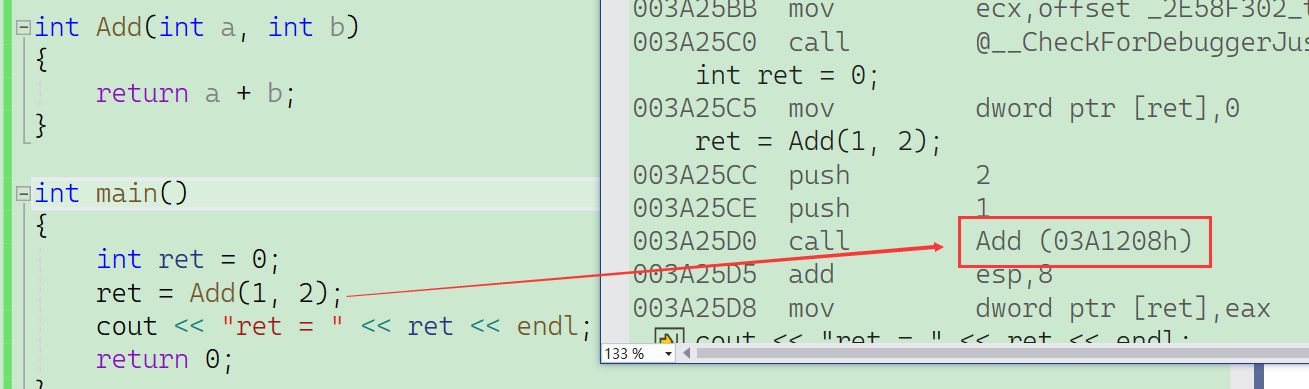
如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。
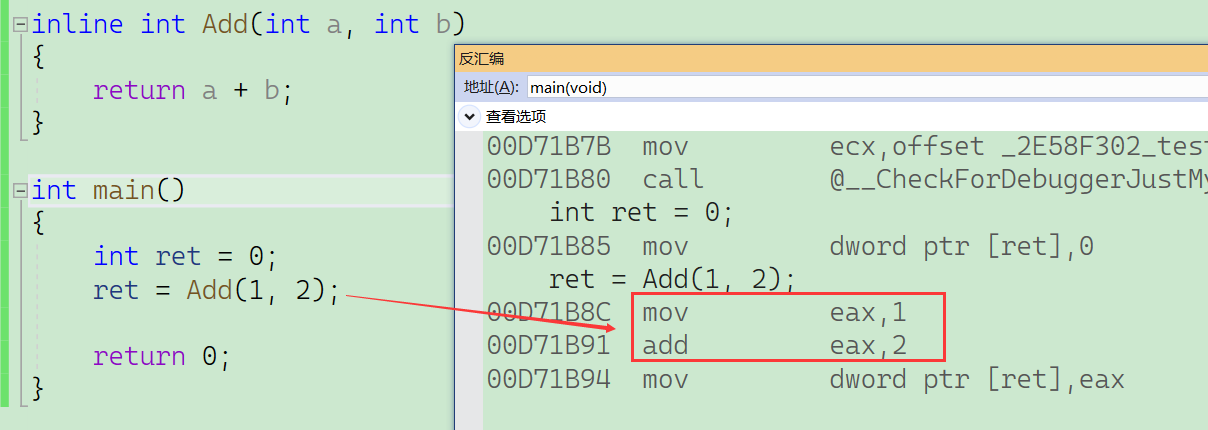
2、特性
-
inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运
行效率。 -
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建
议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不
是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
内联只是想编译器发出一个请求,编译器可以选择忽略这个请求。 -
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址
了,链接就会找不到。
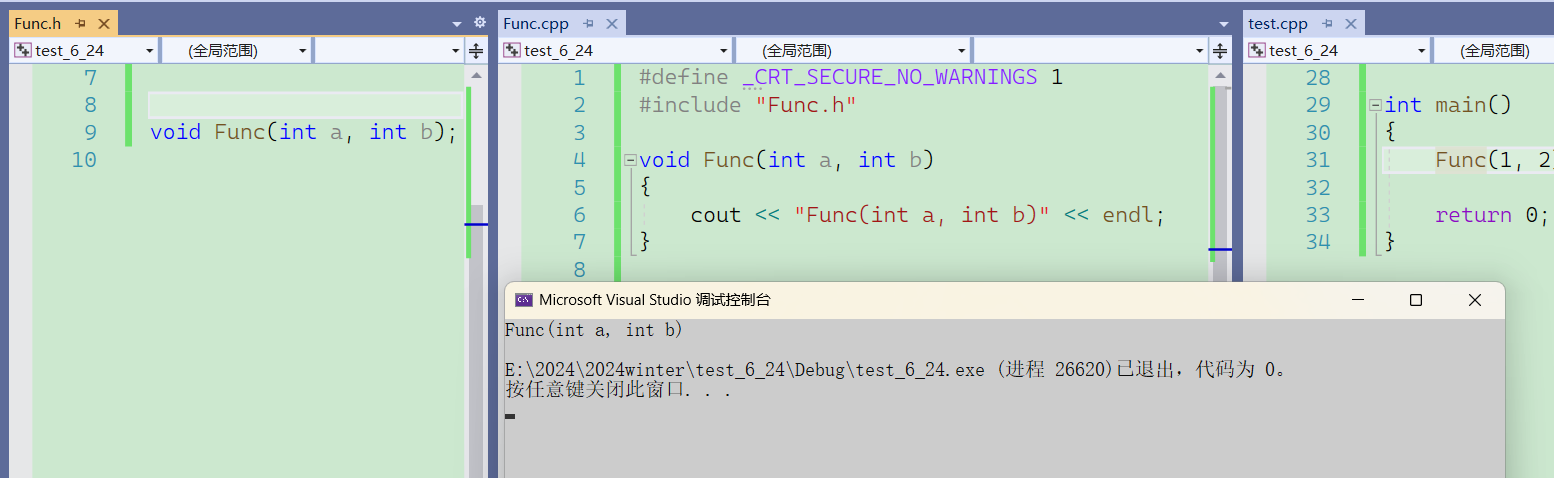
这是不加inline的函数调用
这是加了inline的函数调用
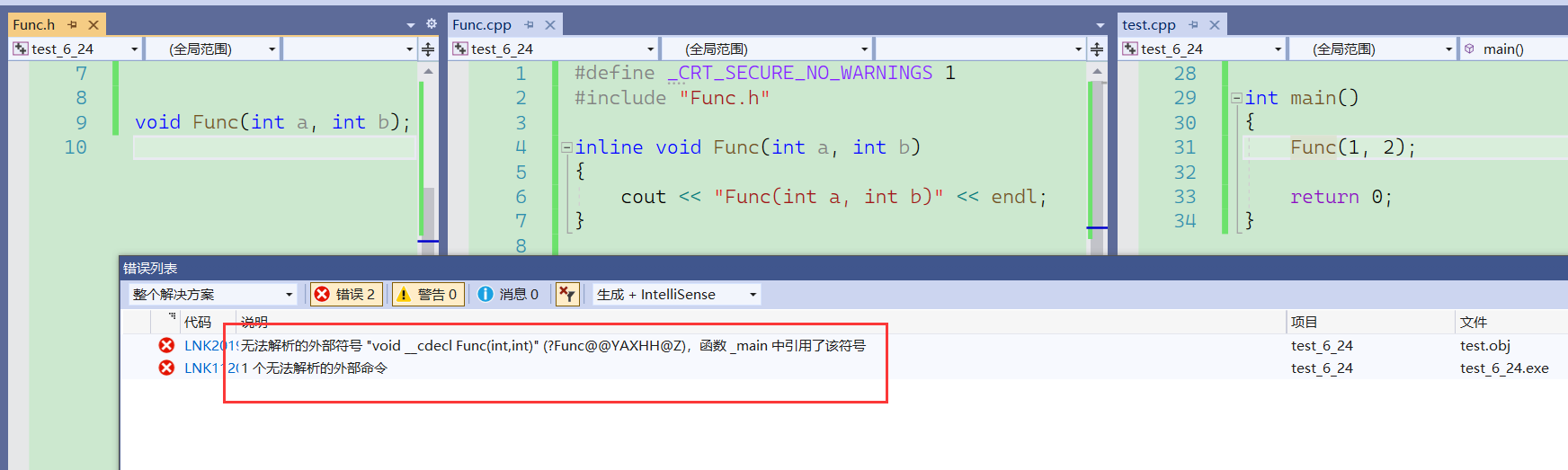
那么为什么声明和定义分离会导致链接错误呢?
我们知道,如果函数没有加inline的话它会在编译期间进行符号汇总,在汇编期间生成符号表,最后链接的时候会进行符号标的合并,定义函数的文件和声明函数的文件就都能拿到函数的地址,就可以使用函数了。尽管定义和声明分离后面 使用函数的时候也能找到函数的地址。
如果函数加了inline的话,而且声明和定义分离,那么就只有定义函数的文件里可以使用这个函数,声明函数的文件就不可以使用,这是因为,定义函数的文件不会将该函数放在符号表里,符号会中的时候声明函数的文件找不到该函数地址,所以,声明函数文件就不可以使用这个函数了,也不是找不到这个函数, 这个函数本身也就不存在,没有进符号表,也就找不到地址。
3、内联函数与宏定义
使用宏函数最大的缺点就是很容易出现错误,有太多的语法坑了,稍不注意就写出bug了。
#define sum(x, y) (x) > (y) ? (x) : (y)
int ret = sum(x, y)+2;
//预处理器扩展后
int ret = (x) > (y) ? (x) : (y) + 2;
由于运算符"+“比运算符”?:"的优先级高,所以上述语句并不等价于
如果把宏代码改写为:
#define sum(a,b) ( ( a ) > ( b ) ? ( a ) : ( b ) )
则能解决优先级的问题。但是会引发另一个问题
ret = sum(i++, j);
//被预处理器扩展为
ret = ( i + + ) > ( j ) ? ( i + + ) : ( j ) //在同一个表达式中i被两次求值。
宏的另一个缺点就是不可以调试, 也没有类型安全的检测。
内联机制既具备宏代码的效率,又增加了安全性,而且可以自由操作的类的数据成员,所以应该尽量使用内联函数来取代宏代码
二、auto关键字(C++11)
1、类型别名思考
随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在:
- 类型难于拼写
- 含义不明确导致容易出错
#include <string>
#include <map>
int main()
{
std::map<std::string, std::string> m{ { "apple", "苹果" }, { "orange",
"橙子" },
{"pear","梨"} };
std::map<std::string, std::string>::iterator it = m.begin();
while (it != m.end())
{
//....
}
return 0;
}
std::map<std::string, std::string>::iterator 是一个类型,但是该类型太长了,特别容易写错。聪明的同学可能已经想到:可以通过typedef给类型取别名,比如:
#include <string>
#include <map>
typedef std::map<std::string, std::string> Map;
int main()
{
Map m{ { "apple", "苹果" },{ "orange", "橙子" }, {"pear","梨"} };
Map::iterator it = m.begin();
while (it != m.end())
{
//....
}
return 0;
}
使用typedef给类型取别名确实可以简化代码,但是typedef有会遇到新的难题
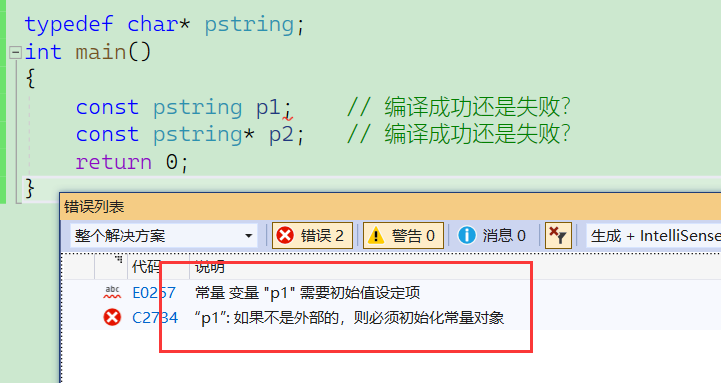
typedef char* pstring;
int main()
{
const pstring p1; // 编译成功还是失败?
const pstring* p2; // 编译成功还是失败?
return 0;
}
在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的类型。然而有时候要做到这点并非那么容易,因此C++11给auto赋予了新的含义
2、auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
3、 auto的使用细则
- auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须
加&
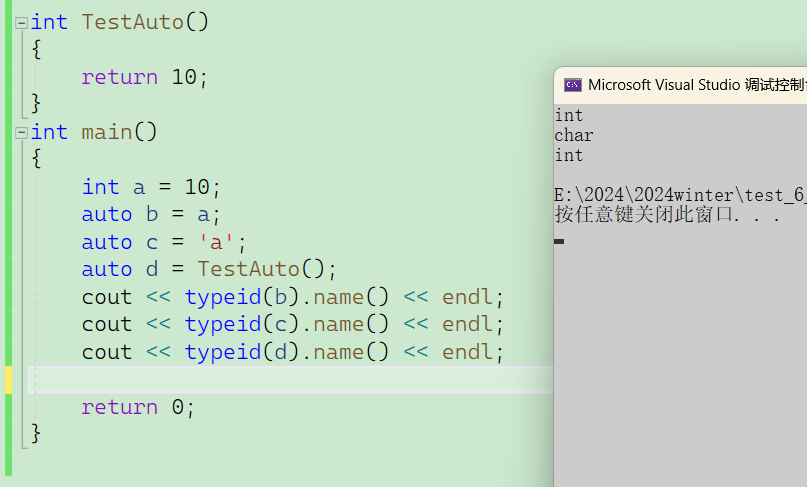
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 20;
*b = 30;
c = 40;
}
return 0;
- 在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译
器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
void TestAuto()
{
auto a = 1, b = 2;
auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}
4、 auto不能推导的场景
- auto不能作为函数的参数
- auto不能直接用来声明数组
- 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
- auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有
lambda表达式等进行配合使用。















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









