






要注意看网页的请求方式是request还是get
一、小型爬虫 (爬百度首页)
from urllib.request import urlopen
url = "https://www.baidu.com"
resp = urlopen(url)
print(resp.read().decode('utf-8'))
print("over!")
//!!!!!!!!!!!!!!!!!
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
with open ("mybai.html",mode = "w") as f:
f.write(resp.read().decode("utf-8"))
print("ok")二、http协议
1.请求:
请求行:请求方式(get/post) 请求url地址 协议 请求方式:get显示提交、post隐式提交
请求头:放服务器用到的附加信息::User-Agent\Referer\cookie
请求体:一般放一些请求参数
2.响应
状态行:协议 状态码 200 404 500 302
响应头:放客户端使用的附加信息::cookie
响应体:服务器真正返回给客户端的
三、Request111(爬百度搜索结果1)Get方式直接拼接f,Query String Parameters
//小小反爬,在网页f12找network,在Request里找User-Agent
import requests
url = 'http://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
resp = requests.get(url,headers = headers)
print(resp)
print(resp.text)
//改良版通过交互获得需要的内容!!!!!!!!!!!!!!!!!!
import requests
query = input("请输入要查找的内容:")
url = f'https://www.baidu.com/s?wd={query}'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
resp = requests.get(url,headers = headers)
print(resp.text)
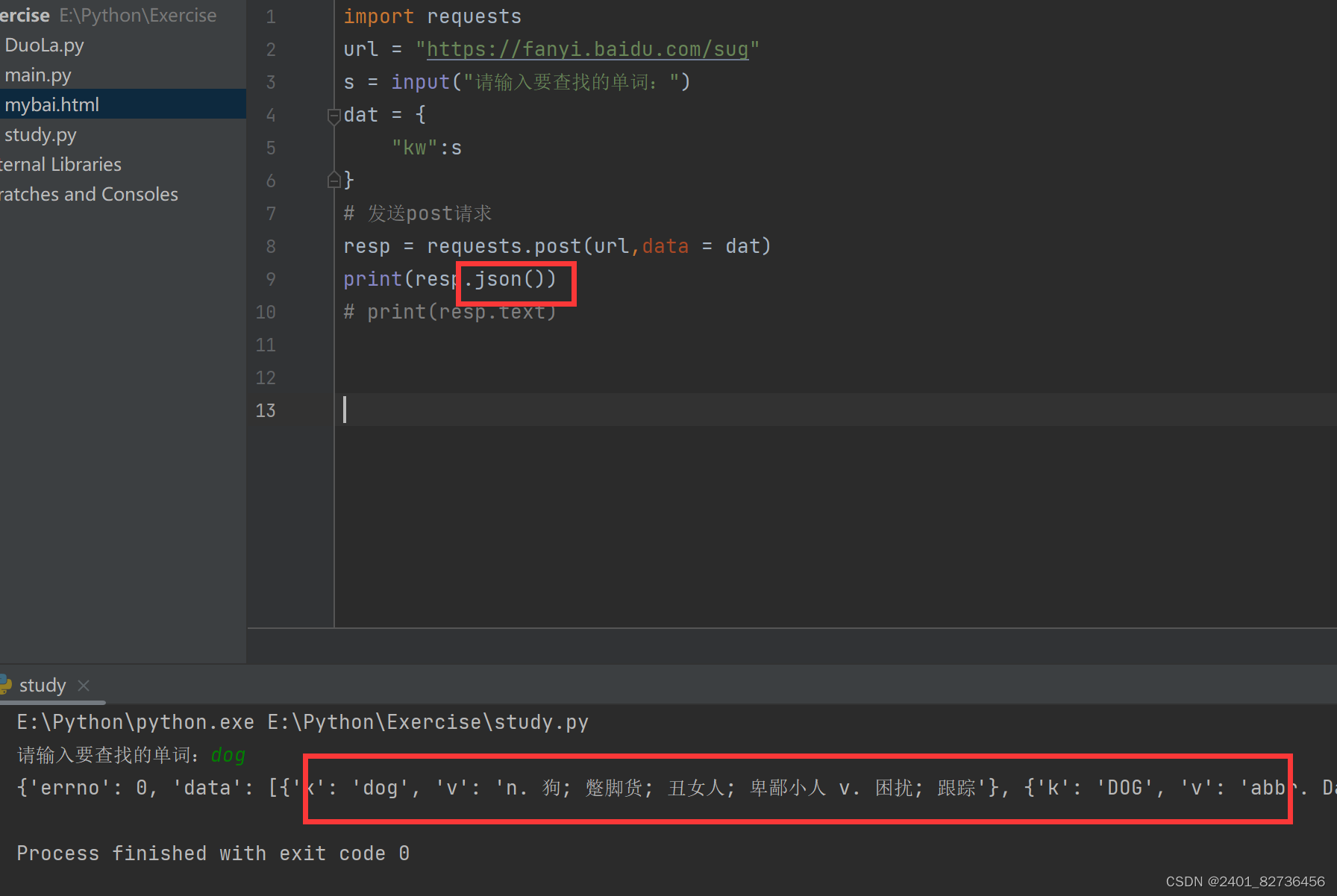
四、Request222(爬百度翻译)Post方式 User-Agent
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入要查找的单词:")
dat = {
"kw":s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url,data = dat)
print(resp.json())#将服务器返回的内容直接处理成json()
# print(resp.text)运行显示时用 .json() 解决乱码问题














 80
80











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









