







L5 回归建模
回顾
分类和回归的比较:
Classification
- Datum i : feature vector
label
- Hypothesis h :
- Loss : 0-1 , asymmetric , NLL(负对数似然损失)
- Example : linear classification
Regression
- Datum i : feature vector
- Hypothesis h :
- Loss :
- Example : linear regression
Linear regression
- Hypothesis :
- Training error(平方损失)
dimension agument
A Direct Solution
- Goal : minimize
- Uniquely minimized at a point when gradient is zero
- Gradient
- Matrix of second derivatives
Wrong in practice
- 超平面不唯一(数据线性相关)
- 噪声
Regularizing linear regression(正交化)
- With square penalty : ridge regression
- Special case : with no offset
- Min at :
- Matrix of second derivatives
Gradient descent for linear regression
LR-Gradient-Descent
Initialize
Initialize
for t = 1 to T
Return
Stochastic gradient descent 随机梯度下降
Stomachastic-Gradient-Descent
Initialize
for t = 1 to T
randomly select i from {1,...,n} (w.e.p)
Return
L6 神经网络 neutral nets
回顾
Linear classification with default features
Linear classification with polynomial features :
New Features : step functions
NN,some new notation
1st layer ,constructing the features :
-
Input x(a data point) : size
-
Output
(vector of features) : size
-
The ith feature :
-
All the features at once:
2nd layer ,assigning a label(or labels) :
-
Input (the features) : size
-
Output
(vector of labels) : size
-
The ith feature :
-
All :
Whole thing : 
For one neuron/unit/node :
| inputs | dot product | pre_activation | activation function | activation |
Forward vs. backward
A feed-forward neural network : RNN
Different activation functions
do regression :
use NLL loss :
Need non-zero derivatives for (S)GD : Above &
Learning the parameters
目标函数:
如果目标函数平滑且有唯一极值,(S)GD perform well !
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 加载手写数字识数据集
digits = load_digits()
X = digits.data
y = digits.target
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X_scaled,y,test_size=0.2,random_state=42)
# 构建神经网络模型
mlp = MLPClassifier(hidden_layer_sizes=(100,50),activation='relu',solver='adam',max_iter=500,random_state=42)
# 训练模型
history = mlp.fit(X_train,y_train)
# 预测并计算准确率
y_pred = mlp.predict(X_test)
accuracy = accuracy_score(y_test,y_pred)
print('Accuracy:',accuracy)
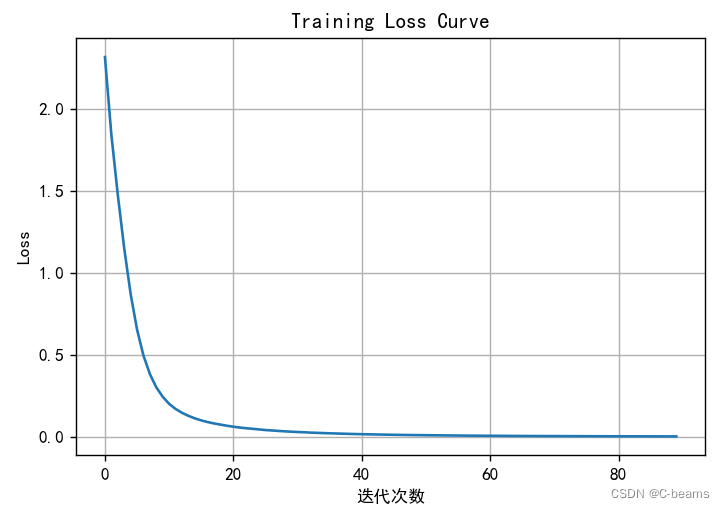
# 绘制训练过程中的损失曲线
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,6))
plt.plot(history.loss_curve_)
plt.title('Training Loss Curve')
plt.xlabel('迭代次数')
plt.ylabel('Loss')
plt.grid(True)
plt.show()Accuracy: 0.9805555555555555















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









