







L3 Feature 特征
Encode data
将特征转化为实数
什么是特征?任何可获取的数据(除了label标签)
old features: new features:
Encode categorical data
Idea:将每个类别转化为独一无二的二进制数(通常不用)
e.g.
| nurse | 0 | 0 | 0 |
| admin | 0 | 0 | 1 |
| pharmacisst | 0 | 1 | 0 |
| doctor | 0 | 1 | 1 |
| social worker | 1 | 0 | 1 |
Idea:将每个类别转化为唯一的 0-1 数字(“one-hot encoding”)(使用于各类别无明显相关性)
e.g.
| nurse | 1 | 0 | 0 | 0 | 0 |
| admin | 0 | 1 | 0 | 0 | 0 |
| pharmacisst | 0 | 0 | 1 | 0 | 0 |
| doctor | 0 | 0 | 0 | 1 | 0 |
| social worker | 0 | 0 | 0 | 0 | 1 |
Idea:因子编码(单个数据包含多个因素)
e.g.
| pain | 1 | 0 |
| pain&blockers | 1 | 1 |
| blockers | 0 | 1 |
| no medications | 0 | 0 |
Encode ordinal(序数) data
Idea:Unary/thermometer code 温度计编码(各个值区别较大)
e.g.Likert scale 李克特量表
| Strongly disagree | Disagree | Neutral | Agree | Strongly agree |
| 1,0,0,0,0 | 1,1,0,0,0 | 1,1,1,0,0 | 1,1,1,1,0 | 1,1,1,1,1 |
Encode numerical data
Idea:标准化
for feature:
Nonlinear boundaries 不可线性分割的数据
Idea:用k次泰勒多项式逼近到一个平滑函数
| order(k) | terms when d=1 | terms for general d |
| 0 | ||
| 1 | ||
| 2 | ||
| 3 |
Evaluation of a learning algorithm
Idea:使用全部数据训练然后求出训练误差
Idea:保留一些数据用来测试
- More training data:closer to training on full data
- More testing data:less noisy estimate of performance
- Only one classifier might not be representative
- Good idea to shuffle order of data
伪代码如下:
Cross-validate #交叉验证
Divide into k chunks
(for roughly equal size)
for i = 1 to k
train on
(i.e. except chunk i)
compute "test" error
Return
代码如下:
import matplotlib.pyplot as plt
from sklearn import neighbors
import numpy as np
import pandas as pd
from sklearn import model_selection
df1 = pd.read_csv(r'iris.csv')
print(df1.head())#输出前五行
predictors = df1.columns[:-1]
x_train,x_test,y_train,y_test=model_selection.train_test_split(
df1[predictors],df1.Species,
test_size=0.5,
random_state = 1234
)
print(np.ceil(np.log2(df1.shape[0])))
#设置待测试的不同K值
K = np.arange(1,np.ceil(np.log2(df1.shape[0])))
print(np.arange(1,np.ceil(np.log2(df1.shape[0]))))
#设置空列表,用于储存平均准确率
accuracy = []
# 使用五重交叉验证的方法
for k in K:
cv_result = model_selection.cross_val_score \
(neighbors.KNeighborsClassifier(n_neighbors=int(k),
weights='distance'),
x_train, y_train, cv=5, scoring='accuracy')
accuracy.append(cv_result.mean())
# 从K个平均准确率中挑选出最大值做对应的目标
arg_max = np.array(accuracy).argmax()
#中文负号正常显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#绘制不同k值与准确率之间的折线图
plt.plot(K,accuracy)
plt.scatter(K,accuracy)
plt.text(K[arg_max],accuracy[arg_max],'最佳K值为%s'%int(K[arg_max]))
plt.show()L4 Logistic regression 逻辑回归/对数几率回归
回顾:感知器难以处理不可线性分割的数据
sigmoid/logistic function
Linear logistic classification
如何得到一个一个分类器
Probability(data)
Loss(data) = -(1/n)*log probability(data)
Negative log likelihood loss:
learn ( i.e.to minimize average loss):
Gradient descent 梯度下降
Gradient :
伪代码如下:
Gradinent-Descent
Initialize
Initialize
repeat
t = t + 1
until
Return
其他可能的停止条件:
- 达到最大迭代次数T
Logistic regression learning algorithm
LR-Gradient-Descent
Initialize
Initialize
Initialize
repeat
t = t + 1
until
Return
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from matplotlib.colors import ListedColormap
iris = load_iris()
X = iris.data[:,:2] # 可视化前两个特征
y = iris.target
# 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
# 训练逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train,y_train)
# 在测试及上进行预测
y_pred = lr.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print('Accuracy:',accuracy)
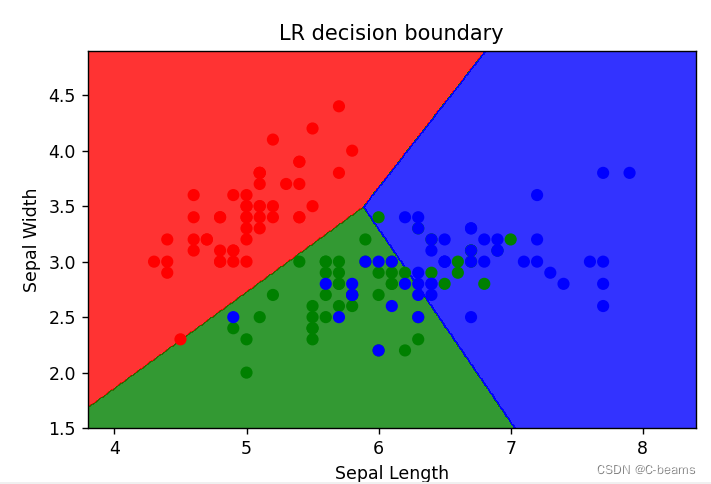
# 绘制决策边界
x_min,x_max = X[:,0].min() - 0.5,X[:,0].max() + 0.5
y_min,y_max = X[:,1].min() - 0.5,X[:,1].max() + 0.5
xx,yy = np.meshgrid(np.arange(x_min,x_max,0.01),np.arange(y_min,y_max,0.01))
Z = lr.predict(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制结果
plt.figure(figsize=(10,6))
plt.contourf(xx,yy,Z,alpha=0.8,cmap=ListedColormap(('red','green','blue')))
plt.scatter(X[:,0],X[:,1],c=y,cmap=ListedColormap(('red','green','blue')))
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('LR decision boundary')
plt.show()输出结果:
Accuracy: 0.9















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









