






副本
副本机制的好处:
- 提供数据冗余。即使系统部分组件失效,系统依然能够继续运转,因而增加了整体可用性以及数据持久性。
- 提供高伸缩性。支持横向扩展,能够通过增加机器的方式来提升读性能,进而提高读操作吞吐量。
- 改善数据局部性。允许将数据放入与用户地理位置相近的地方,从而降低系统延时。
Kafka 的副本机制只有提供数据冗余这一个好处。
副本数据一致
Kafka 的解决方案是采用基于领导者的副本机制。
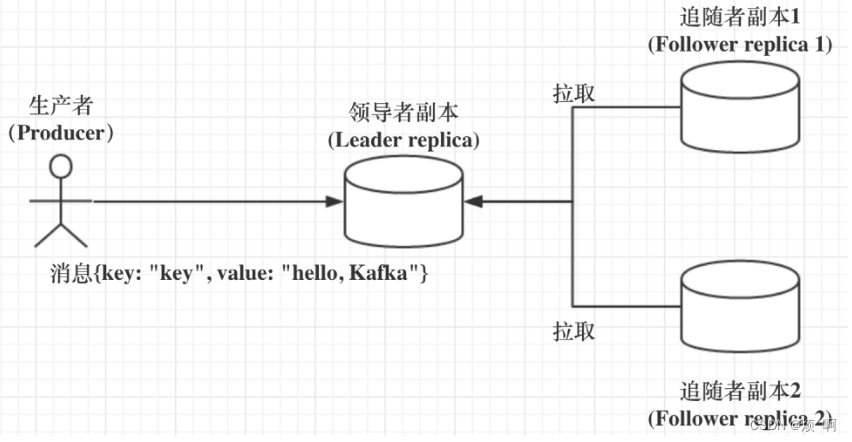
- 在 Kafka 中,副本分成两类:领导者副本(Leader Replica)和追随者副本(Follower Replica)。每个分区在创建时都要选举一个副本,称为领导者副本,其余的副本自动称为追随者副本。
- Kafka 的副本机制比其他分布式系统要更严格一些。在 Kafka 中,追随者副本是不对外提供服务的。这就是说,任何一个追随者副本都不能响应消费者和生产者的读写请求。所有的请求都必须由领导者副本来处理,或者说,所有的读写请求都必须发往领导者副本所在的 Broker,由该 Broker 负责处理。追随者副本不处理客户端请求,它唯一的任务就是从领导者副本异步拉取消息,并写入到自己的提交日志中,从而实现与领导者副本的同步。
- 当领导者副本挂掉了,或者说领导者副本所在的 Broker 宕机时,Kafka 依托于 ZooKeeper 提供的监控功能能够实时感知到,并立即开启新一轮的领导者选举,从追随者副本中选一个作为新的领导者。老 Leader 副本重启回来后,只能作为追随者副本加入到集群中。
为什么追随者副本是不对外提供服务的?
数据一致性:Kafka 使用复制机制来保证数据的一致性和可靠性。每个主题分区通常都有多个副本,其中一个被选为 Leader,负责处理读写请求,其他副本则负责备份数据。如果所有副本都能提供读服务,就可能出现数据不一致的情况,因为不同副本之间可能存在短暂的数据同步延迟。
这样设计的好处:
- 方便 Read-your-writes。当生产者向 Kafka 成功写入消息后,消费者可以马上读取刚才生产的消息。
- 方便实现单调读。如果 follower 提供读服务,可能会由于副本数据不一致,可能会看到:第一次消费时看到的最新消息在第二次消费时不见了。















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









