






 本文详细介绍使用Python进行网络爬虫的基本步骤,包括发送请求、提取文本、解析HTML、数据检索及打印。通过三个具体实例,展示了如何从不同网站抓取分类信息、书籍详情及博客文章,适合初学者实践。
本文详细介绍使用Python进行网络爬虫的基本步骤,包括发送请求、提取文本、解析HTML、数据检索及打印。通过三个具体实例,展示了如何从不同网站抓取分类信息、书籍详情及博客文章,适合初学者实践。
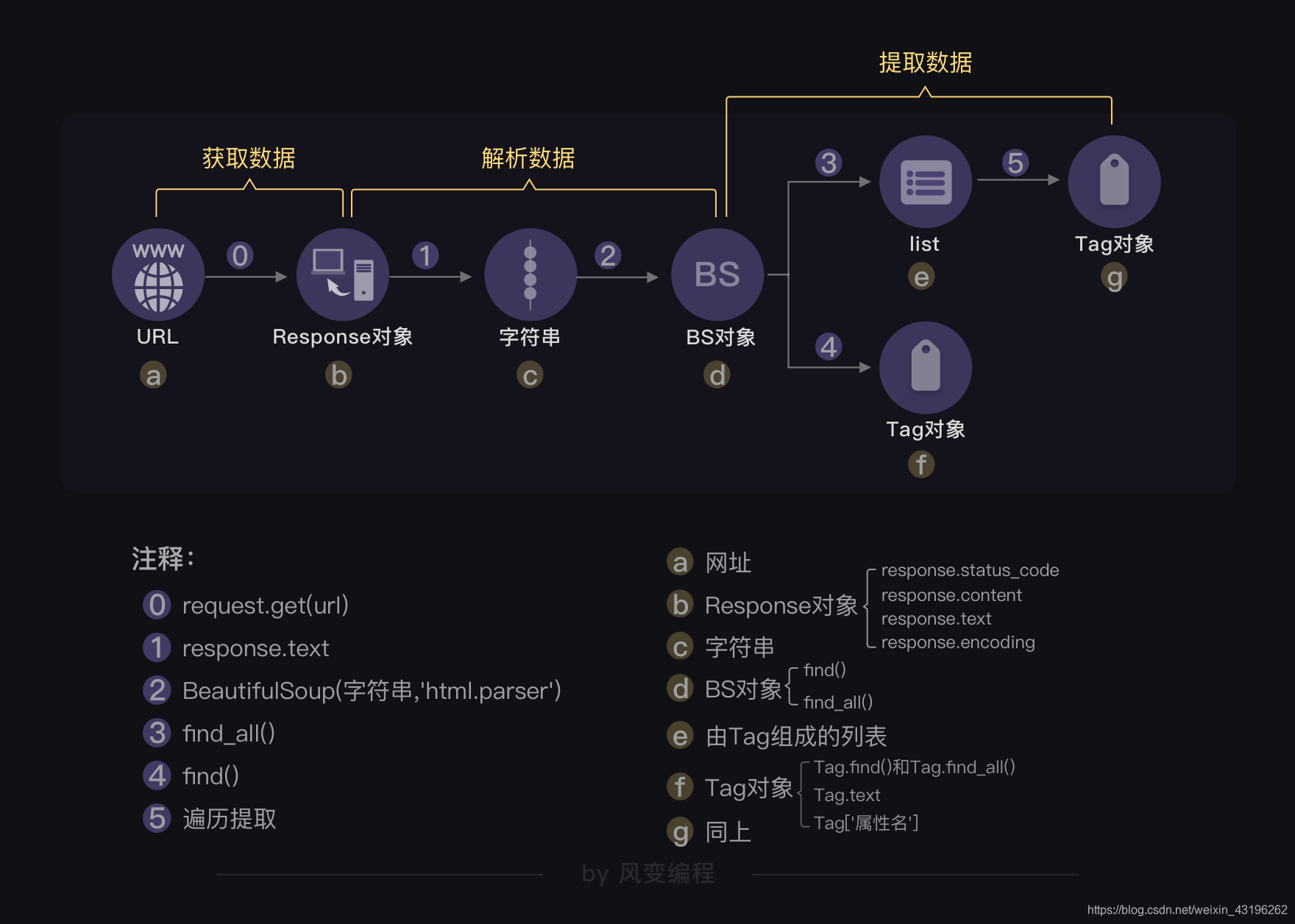
python搭建爬虫思维流程图
- 发送URL请求 response对象=request.get(URL)
- 提取文本 res=response对象.text
- html文件字符串解析 BS对象=BeautifulSoup(字符串, ‘html.parser’)
- find() 或 find_all() 函数返回所爬内容
- 遍历提取数据


练习1
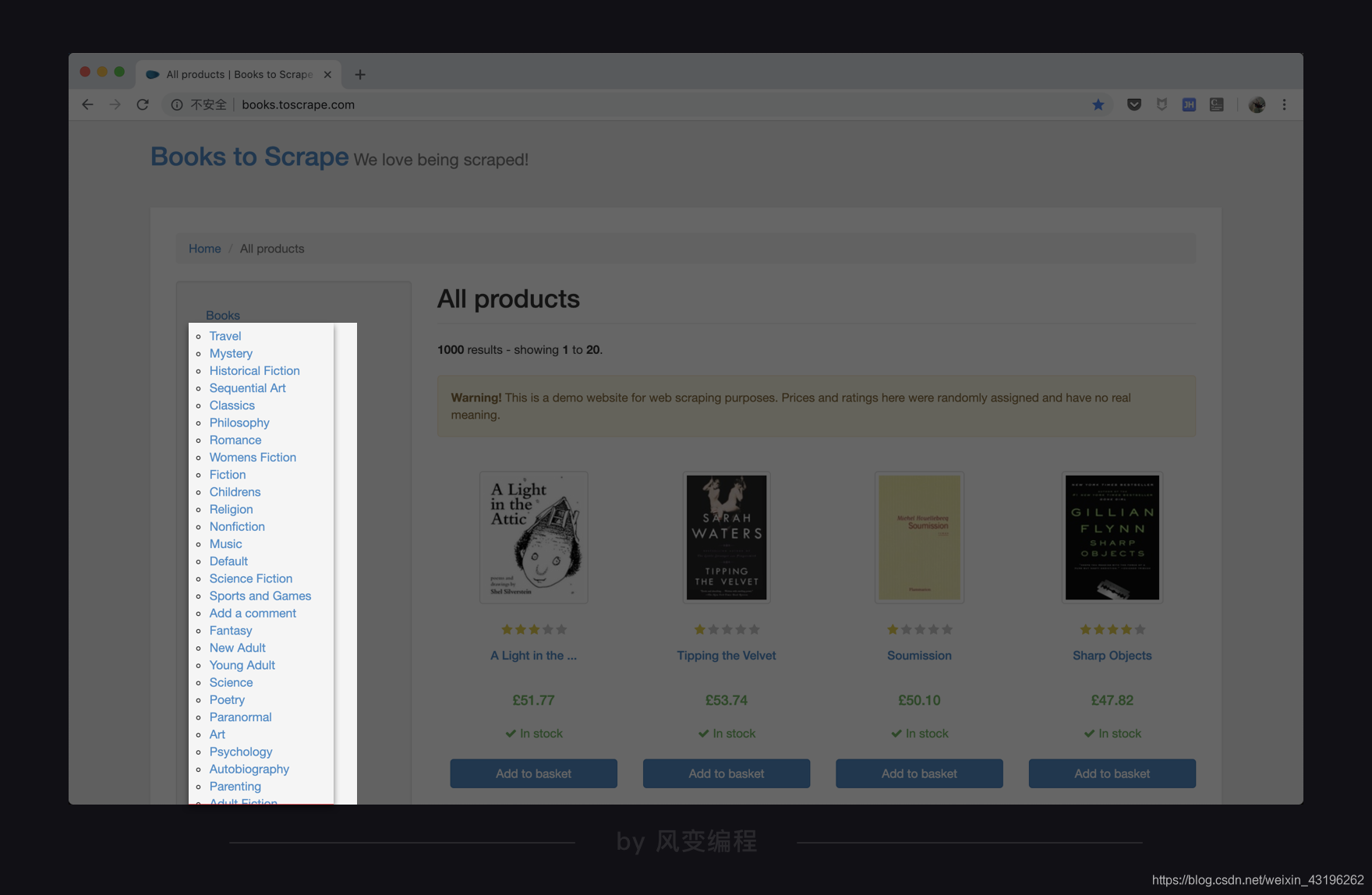
爬取的是网上书店Books to Scrape中所有书的分类类型,并且将它们打印出来。
它的位置就在网页的左侧,如:Travel,Mystery,Historical Fiction…等。
网页的URL网址:http://books.toscrape.com/
import requests
from bs4 import BeautifulSoup
URL='http://books.toscrape.com/'
# 1. 发送URL请求
res=requests.get(URL)
print('requests.get返回'+str(type(res))+'类型的对象')
# 2. 提取文本(字符串)
html=res.text
print('res.text返回'+str(type(html))+'类型的对象')
# 3. 字符串解析
soup=BeautifulSoup(html, 'html.parser')
print('BeautifulSoup返回'+str(type(soup))+'类型的对象')
# 4. 检索所需内容
items=soup.find('ul', class_='nav').find('ul').find_all('li')
# 5. 遍历打印结果
print('Books to Scrape中图书分类类型表:\n')
for item in items:
print(item.text.strip())
练习2
题目要求:爬取的是网上书店Books to Scrape Travel这类书中,所有书的书名、评分、价格三种信息,并且打印提取到的信息。
网页URL:
http://books.toscrape.com/catalogue/category/books/travel_2/index.html
import requests
from bs4 import BeautifulSoup
URL='http://books.toscrape.com/catalogue/category/books/travel_2/index.html'
# 1. 发送URL请求
res=requests.get(URL)
print('requests.get返回'+str(type(res))+'类型的对象')
# 2. 提取文本(字符串)
html=res.text
print('res.text返回'+str(type(html))+'类型的对象')
# 3. 字符串解析
soup=BeautifulSoup(html, 'html.parser')
print('BeautifulSoup返回'+str(type(soup))+'类型的对象')
# 4. 检索所需内容
#items=soup.find('ul', class_='nav').find('ul').find_all('li')
x1=soup.find_all(class_='product_pod')
print(type(x1))
for item in x1:
book_name=item.find('h3').find('a')
book_price=item.find('div', class_='product_price').find('p', class_='price_color')
book_rating=item.find('p')
print('Title:'+book_name['title']+'\n','Price:'+book_price.text.strip()+'\n',book_rating['class'])
练习3
题目要求:你需要爬取的是博客人人都是蜘蛛侠,首页的四篇文章信息,并且打印提取到的信息。
提取每篇文章的:
文章标题
发布时间
文章链接
网页URL:
https://wordpress-edu-3autumn.localprod.oc.forchange.cn/
import requests
from bs4 import BeautifulSoup
URL='https://wordpress-edu-3autumn.localprod.oc.forchange.cn/'
res=requests.get(URL)
html=res.text
soup=BeautifulSoup(html, 'html.parser')
items=soup.find_all('article')
for item in items:
book_title=item.find('h2', class_='entry-title')
book_ref=item.find('a')
release_time=item.find('div', class_='entry-meta')
print(book_title.text+'\n',book_ref['href'], release_time.text)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









