







为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
sudo ifconfig eth0 192.168.1.1 netmask 255.255.255.0
这将配置eth0接口的IP地址为192.168.1.1,子网掩码为255.255.255.0。可以根据网络拓扑和需求配置其他接口。
3. 配置静态路由或使用动态路由协议:如果需要将数据包从一个网络转发到另一个网络,需要配置静态路由规则或使用动态路由协议(如BGP、OSPF、RIP)来管理路由表。可以使用ip route命令来配置静态路由。
sudo ip route add 10.0.0.0/24 via 192.168.1.2 dev eth0
这将添加一个静态路由,将数据包目的地为10.0.0.0/24的数据包发送到192.168.1.2的网关,通过eth0接口进行转发。
4. 配置NAT(Network Address Translation):如果要将内部网络连接到公共互联网,通常需要配置NAT,以便将内部IP地址映射到一个公共IP地址。可以使用iptables来配置NAT规则。
sudo iptables -t nat -A POSTROUTING -o eth1 -j MASQUERADE
这将配置NAT规则,允许数据包从eth1接口出口并将源IP地址替换为该接口的IP地址,以实现Internet访问。
5. 防火墙设置:配置适当的防火墙规则以保护你的路由器和网络。使用iptables或其他防火墙工具来配置入站和出站规则,确保只有授权的流量可以通过。
这些步骤是将Linux系统配置为路由器的基本步骤。具体的配置可能会根据网络拓扑和需求而有所不同。确保在进行配置时谨慎操作,并考虑网络安全和性能方面的需求。
2.19 你对Linux系统的node指标的理解是怎么样的?比如负载。(待进一步验证)
负载的话,看三个指标吧,一个是这个CPU,然后还有就是内存,最后就是这个它的这个硬磁盘的使用情况,然后这三方面来看,然后还有的话,如果可能就是这个网络情况吧,是这样。
2.20 这个node的值它一般到多大是算高?需要介入排查呢?
2.21 系统指标采集,比如你需要你用go写一个agent,采集agent,那采集这些系统指标的一般的实现方法大概有哪些?(待进一步验证)
采集CPU、内存、硬盘、网络,然后还有程序的运行数量。
2.22 你怎么用go代码去拿这些数据呢?(待进一步验证)
go 的话它里面它有一个包是OS,它这个里面的话主要是与系统相关的,应该可以通过这个包里面的一些方法来获取到这个系统服务器上面的一些参数。
2.23 在linux服务器上的话一般是用什么命令要看日志?
- 查看系统日志:使用journalctl命令可以查看systemd日志。这个命令提供了很多选项,可以用于筛选和查找特定的日志信息。
journalctl
- 查看特定日志文件:使用cat、tail、less等命令可以查看特定日志文件的内容。例如,查看/var/log/syslog文件的最后几行:
tail /var/log/syslog
- 查看实时日志:使用tail命令的-f选项可以实时查看日志文件的新增内容,有助于实时监控系统状态。
tail -f /var/log/syslog
- 查看指定服务的日志:使用journalctl命令,结合-u选项可以查看特定服务的日志。例如,查看SSH服务的日志:
journalctl -u ssh
- 查看错误日志:使用dmesg命令可以查看内核环缓冲区的内容,显示系统启动过程中的消息和错误信息。
dmesg
- 查看登录信息:使用last命令可以查看登录历史记录,显示系统上的用户登录信息。
last
- 查看用户活动日志:使用w或who命令可以查看当前登录用户的活动。
w
- 查看应用程序日志:不同的应用程序可能会将日志存储在不同的位置。通常,应用程序的日志会存储在/var/log目录下,具体位置和命名可能会因发行版和应用程序而有所不同。
这些命令和工具提供了一些基本的日志查看和分析功能。在实际应用中,可以根据具体的需求使用其他工具和技术,如grep、awk、sed等,以及日志分析工具如 Logrotate、ELK Stack等。
2.24 每周定时备份一下MySQL的一个数据库,shell脚本该怎么写。
#!/bin/bash
# MySQL 连接信息
DB\_HOST="localhost"
DB\_USER="your\_username"
DB\_PASS="your\_password"
DB\_NAME="your\_database"
# 备份存储路径
BACKUP\_DIR="/path/to/backup"
# 当前日期作为备份文件名前缀
DATE\_PREFIX=$(date +%Y%m%d)
# 创建备份目录
mkdir -p $BACKUP\_DIR
# 完整备份文件名
BACKUP\_FILE="$BACKUP\_DIR/$DATE\_PREFIX-$DB\_NAME.sql"
# 使用 mysqldump 导出数据库
mysqldump -h $DB\_HOST -u $DB\_USER -p$DB\_PASS $DB\_NAME > $BACKUP\_FILE
# 检查备份是否成功
if [ $? -eq 0 ]; then
echo "MySQL backup completed successfully: $BACKUP\_FILE"
else
echo "Error: MySQL backup failed!"
fi
脚本的说明:
- 修改DB_HOST、DB_USER、DB_PASS、DB_NAME分别为你的MySQL主机、用户名、密码、以及要备份的数据库名称。
- 修改BACKUP_DIR为你希望存储备份文件的目录。
- 使用date命令生成当前日期作为备份文件名的前缀。
- 使用mysqldump命令导出MySQL数据库到指定的备份文件中。
- 在脚本中使用条件语句检查导出过程是否成功,输出相应的信息。
请确保你在脚本中妥善处理数据库连接信息,以确保安全性。你可能需要设置脚本的执行权限,并使用cron作业调度工具来定期执行脚本。例如,将以下内容添加到你的 crontab文件中,以每周日的凌晨3点执行备份:
0 3 * * 0 /path/to/your/script.sh
这表示在每周日的凌晨 3 点执行指定的脚本。根据实际情况调整路径和时间。
3 Docker
Docker是一个用于开发、运输和运行容器化应用程序的平台。容器是轻量级、独立和可执行的软件包,包括运行一个软件所需的一切,包括代码、运行时、系统工具、库和设置。Docker因其简化创建、部署和管理应用程序的过程而在软件开发和部署领域广受欢迎。
3.1 Docker特点 / 优势
- 轻量级容器:
Docker容器非常轻量,因此可以在几秒钟内启动和停止。与传统虚拟化相比,它们消耗更少的资源,因此可以在同一物理主机上运行多个容器。 - 一致性:
Docker容器包含了应用程序及其所有依赖项,包括库、运行时和配置文件。这确保了在不同环境中容器的一致性,从而减少了“在我的机器上可以工作”的问题。 - 可移植性:
Docker容器可以在不同的环境中运行,无论是开发、测试、生产服务器还是云计算平台,都可以保持一致。这使得应用程序更容易迁移到不同的部署环境。 - 快速部署:由于容器可以快速启动,因此应用程序可以更快地部署和扩展。这对于需要快速响应用户需求的情况非常有用。
- 隔离性:
Docker容器提供了高度的隔离,使应用程序之间和与主机系统之间保持独立。这意味着一个容器的问题不会影响其他容器或主机系统。 - 版本控制和镜像管理:
Docker允许创建和管理容器镜像,这些镜像可以与其他开发人员和团队共享。可以使用Docker Hub或自己的私有注册表来存储和分享镜像。 - 易于扩展:
Docker容器可以根据需要水平扩展,以满足流量和资源需求的增加。容器编排工具如Kubernetes和Docker Swarm可以帮助自动化和管理扩展过程。 - 生态系统:
Docker拥有庞大的生态系统,有丰富的第三方工具和服务,可以扩展Docker的功能,例如监控、日志记录、安全性、网络等方面。 - 开源和社区支持:
Docker是一个开源项目,拥有活跃的社区支持。这意味着有大量的文档、教程和社区贡献的工具和插件可供使用。 - 多平台支持:
Docker不仅限于Docker,还支持Windows和macOS等操作系统,因此可以在多个操作系统上使用相同的Docker容器。
总的来说,Docker的特点包括高度的可移植性、一致性、隔离性和快速部署,使其成为开发人员和运维团队的有力工具,用于构建、交付和管理现代应用程序。
3.2 Docker架构
Docker的架构是一个分层的体系结构,它包括多个组件,每个组件都有特定的功能。以下是Docker的主要架构组件:
- Docker守护程序(Docker Daemon):
Docker守护程序是Docker的后台服务,负责管理Docker容器的生命周期。它接收来自Docker客户端的命令,并与容器运行时交互来创建、启动、停止和删除容器。Docker守护程序还管理镜像、网络、存储和卷等资源。 - Docker客户端:
Docker客户端是与用户交互的命令行工具或API客户端。用户可以使用Docker客户端通过命令行界面或API与Docker守护程序通信,以执行各种Docker操作。 - Docker镜像(Docker Images):
Docker镜像是容器的只读模板,包含了运行容器所需的文件系统、应用程序代码、运行时、系统工具、库和配置。镜像可以被用来创建多个容器实例。Docker镜像采用分层存储,这意味着它们可以共享相同的基础层,从而节省存储空间。 - Docker容器(Docker Containers):
Docker容器是Docker镜像的可运行实例。容器包括应用程序及其依赖项,并在隔离的环境中运行。容器是轻量级、可移植的,并且可以在不同的主机上运行,而不受主机操作系统的影响。 - Docker仓库(Docker Registry):
Docker仓库是用于存储和分享Docker镜像的中央位置。Docker Hub是一个公共Docker仓库,开发人员可以在其中找到和分享镜像。还可以设置自己的私有Docker仓库。 - Docker Compose:
Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。它使用YAML文件来描述应用程序的服务、网络、卷等配置,可以简化复杂应用程序堆栈的管理。 - Docker网络:
Docker提供多种网络模式,允许容器之间进行通信,以及容器与外部网络的连接。这包括桥接网络、主机网络、覆盖网络等。 - Docker存储:
Docker容器可以访问持久化存储,包括卷(volumes)和绑定挂载(bind mounts)。这允许容器在运行时持久化保存数据,并与主机文件系统交互。 - Docker编排工具:
Docker提供编排工具,如Docker Swarm和Kubernetes,用于自动化和管理多个容器的部署、伸缩和编排。
Docker的架构允许开发人员和运维人员轻松创建、交付和运行容器化应用程序,实现了应用程序的一致性、可移植性和隔离性。容器技术已经成为现代软件开发和部署的重要组成部分,为应用程序开发和部署带来了更高的效率和可靠性。
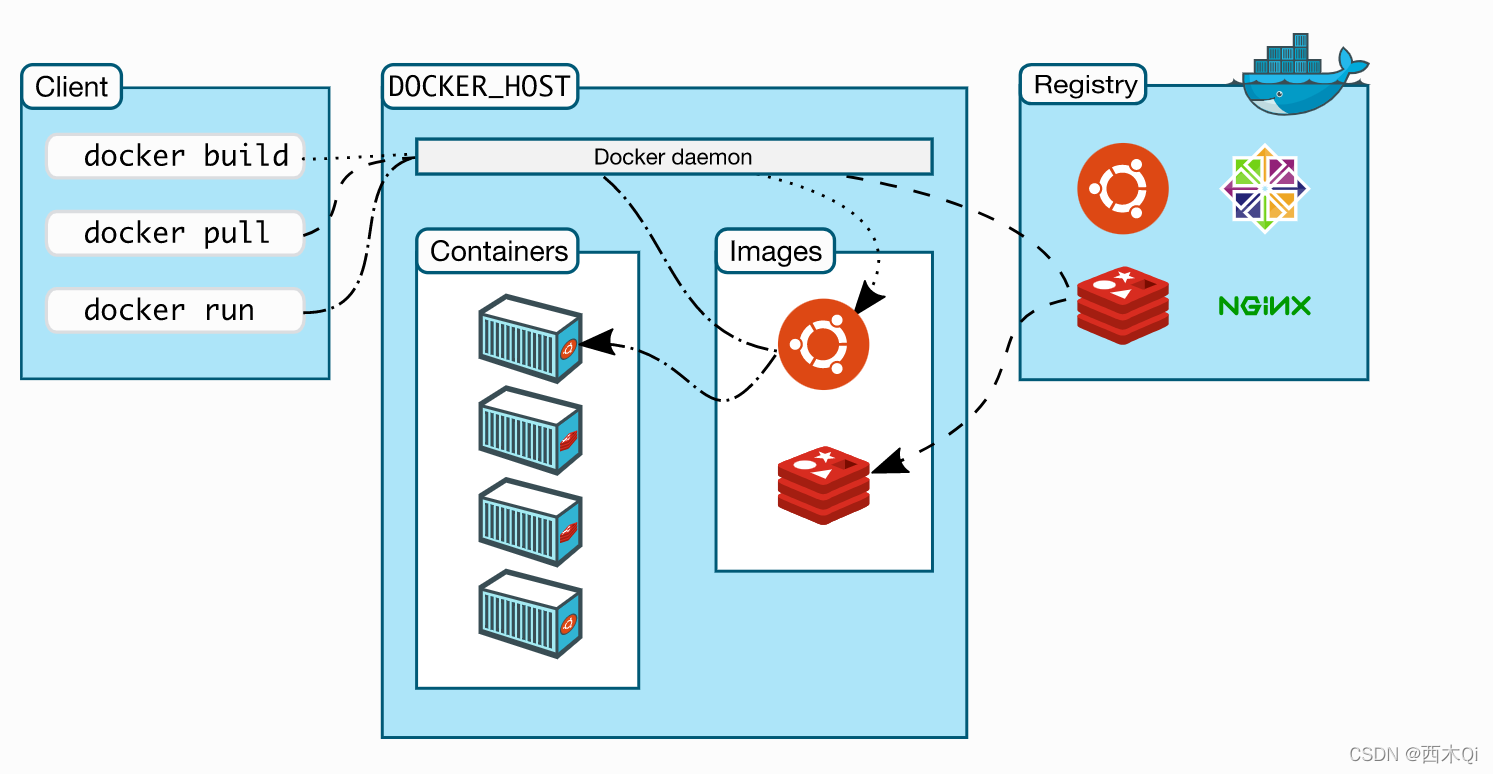
3.3 Docker底层原理
Docker的底层原理涉及多个关键技术和组件,包括Linux容器、cgroups、命名空间、联合文件系统以及Docker自身的架构。以下是Docker底层原理的关键要点:
- Linux容器(Linux Containers,LXC):
Docker基于Linux容器技术,这是Linux内核提供的一种虚拟化技术。容器允许将一个应用程序及其依赖项隔离到一个独立的用户空间中,但与宿主操作系统共享内核资源。这种隔离性使容器可以在不同的环境中运行,同时具有较低的资源开销。 - 命名空间(Namespaces):命名空间是
Linux内核提供的一种机制,用于隔离不同进程之间的资源。Docker使用不同类型的命名空间来隔离进程的文件系统、网络、进程、用户等方面的视图,从而实现容器的隔离。 - cgroups(Control Groups):
cgroups是Linux内核的特性,用于限制和管理资源的使用,如CPU、内存、磁盘I/O等。Docker使用cgroups来确保容器不会耗尽主机的资源,并允许对容器资源分配进行精细化控制。 - 联合文件系统(Union File System):联合文件系统是一种文件系统层叠技术,允许将多个文件系统层合并为一个单一的文件系统视图。
Docker使用联合文件系统来构建镜像,其中包含基础镜像和一系列文件系统层,使镜像变得轻量且易于共享和管理。 - Docker镜像:
Docker镜像是只读的、多层的文件系统,它包含了应用程序代码、运行时、系统工具、库和配置。每一层都可以被重新使用,这使得镜像变得高效且易于构建。容器实例基于这些镜像运行,并添加一个可写层用于容器特定的修改。 - Docker守护程序和客户端:
Docker的架构包括一个守护程序(Docker Daemon)和一个客户端(Docker Client)。守护程序负责管理容器的生命周期和资源,而客户端允许用户与守护程序交互,以执行各种Docker操作。 - Docker网络:
Docker提供了不同类型的网络模式,如桥接网络、主机网络和覆盖网络,以便容器之间通信以及与外部网络连接。这些网络模式使用Linux内核的网络命名空间来实现隔离。 - Docker存储:
Docker容器可以使用持久化存储,包括卷(volumes)和绑定挂载(bind mounts),以便在容器之间或与主机文件系统之间共享数据。
总结:
Docker的底层原理涉及了多个Linux内核功能的协同工作,以实现容器的隔离、资源管理和文件系统层叠。这些技术共同构成了Docker的核心,使其成为一种强大的容器化解决方案,可用于构建、交付和管理应用程序。理解这些原理有助于更深入地使用和调优Docker容器。
3.4 Docker镜像分层
参考1:https://zhuanlan.zhihu.com/p/139653646
docker中的镜像是按照分层的结构一层一层网上叠加的。每层代表Dockerfile中的一条指令。
以下面Dockerfile为例:
FROM ubuntu:18.04
COPY . /app
RUN make /app
CMD python /app/app.py
采用镜像分层的方式最好的就是共享资源,假设有多个镜像都是从相同的底层镜像构建来的,那么docker 只需要在磁盘上保持一份底层镜像,同时内存只用加载一份底层镜像,这样一来这一份镜像就可以为其他的镜像服务了。
容器和镜像区别:
对于容器和镜像(container和image)的主要区别就是顶部的可写层(the top writable layer),在容器中添加数据或者修改现有数据的所有读写操作都会存储在此可写层中。删除容器后,可写层也会被删除,而基础镜像则保持不变。
每个容器都会有自己的可写层,所有的改变都存储在该容器层中。多个容器可以共享对同一基础镜像的访问,但可以拥有自己的数据状态。
Docker镜像采用分层存储(Layered File System)的方式来构建,这个特性是Docker镜像的核心概念之一。镜像的分层结构使得镜像的创建、共享和管理变得高效。下面是有关Docker镜像分层的关键信息:
- 分层文件系统:
Docker镜像使用分层文件系统来构建。每个镜像可以由多个文件系统层组成,每一层都是只读的,并且包含了文件和目录。这些层以一种特殊的方式叠加在一起,形成了一个完整的镜像。 - 基础镜像(Base Image):镜像的最底层通常是一个基础镜像,它包含了操作系统的根文件系统和一些最基本的工具。基础镜像通常是一个标准的
Linux发行版,如Ubuntu、Alpine或CentOS。 - 镜像层:在基础镜像之上,每个
Docker镜像可以包含一个或多个镜像层。每个镜像层都添加了一些文件、目录或配置。这些镜像层可以在不同的镜像之间共享,从而节省存储空间。 - 只读和可写层:镜像的所有层都是只读的,这意味着它们不可更改。当容器运行时,
Docker会在顶部添加一个可写的层,用于存储容器运行时的修改。这个可写层通常被称为"容器层"或"容器文件系统",并且是唯一可写的部分。 - 分层的好处:镜像的分层结构具有以下好处:
- 高效存储和传输:因为镜像层可以在不同的镜像之间共享,所以它们不会被多次存储或传输,节省了存储空间和带宽。
- 可复用性:通过分层,镜像可以重复使用基础层,从而降低了创建新镜像的成本。
- 版本控制:每个镜像层都有一个唯一的哈希值,这使得镜像版本的管理更容易,以确保镜像的一致性和可重复性。
- Docker镜像命令: 使用
Docker镜像命令(如docker pull、docker build和docker push)可以方便地获取、构建和共享镜像。当构建或拉取一个镜像时,Docker会下载或创建所需的镜像层,并按顺序叠加它们以构建完整的镜像。
总结:
Docker镜像分层是一种高效的方式来管理和共享容器化应用程序的组件。它使得镜像的创建、更新和传输变得更加高效和可维护。通过共享基础层和分层结构,Docker镜像允许在不同环境中实现一致性和可移植性。
3.5 Docker Dockfile
Dockerfile(中文称为“Docker文件”)是一个文本文件,用于定义构建Docker容器镜像的一组指令。Docker容器是轻量、可移植且隔离的环境,可以在不同系统上一致地运行应用程序和服务。Dockerfile是Docker生态系统的基本组成部分,因为它们提供了创建定制容器镜像的方式,以满足特定需求。
Dockerfile结构的概述以及每个部分的作用:
- 基础镜像:
Dockerfile中的第一行指定了用于构建自定义镜像的基础镜像。可以将基础镜像视为应用程序的起点。例如,可以使用官方的Linux发行版镜像,如Ubuntu、轻量的Alpine Linux镜像,或针对特定编程语言或框架定制的镜像。
FROM ubuntu:20.04
- 环境设置:在定义基础镜像之后,可以设置应用程序的环境。这包括安装依赖项、设置环境变量和根据需要配置系统。
RUN apt-get update && \
apt-get install -y python3
- 复制文件:可以将本地计算机上的文件复制到容器镜像中。这通常用于添加应用程序代码、配置文件和其他资源。
COPY ./app /app
- 工作目录:设置容器内的工作目录,后续命令将在其中执行。这有助于组织应用程序的文件结构。
WORKDIR /app
- 暴露端口:如果应用程序监听特定网络端口,可以在
Dockerfile中暴露这些端口。
EXPOSE 80
- 命令:最后,指定容器启动时应执行的命令。这可以是简单的
shell命令、脚本或应用程序入口点。
CMD ["python3", "app.py"]
构建了Dockerfile之后,可以使用docker build命令来从中构建镜像。例如:
docker build -t my-custom-image:1.0 .
这个命令告诉Docker使用当前目录中的 Dockerfile(.)来构建一个镜像,并将其标记为my-custom-image,版本为1.0。
构建镜像后,可以使用docker run来创建和运行基于该镜像的容器:
docker run -p 8080:80 my-custom-image:1.0
这将从my-custom-image:1.0 镜像创建一个容器,并将容器内部的端口80映射到主机系统上的端口8080。
Dockerfile允许以版本控制的方式定义应用程序的环境和依赖关系,从而更容易在不同环境和平台上共享和部署应用程序。
3.5.1 Docker Dockfile完整示例
# 使用官方的 Golang 镜像作为基础镜像,选择需要的 Go 版本
FROM golang:1.17
# 设置容器内的工作目录
WORKDIR /app
# 将本地的 Go 源代码复制到容器中
COPY . .
# 构建 Go 应用程序
RUN go build -o myapp
# 暴露容器内的端口,此示例服务使用 8080 端口
EXPOSE 8080
# 定义容器启动时执行的命令
CMD ["./myapp"]
这个示例Dockerfile基于官方Golang镜像构建了一个容器镜像,执行以下操作:
- 设置工作目录为
/app,这将是容器内部的工作目录。 - 使用
COPY指令将本地的Go源代码复制到容器中。确保Dockerfile位于Go项目根目录下,以便将整个项目复制到容器。 - 使用
RUN指令运行go build命令来构建Go应用程序。这将生成一个名为myapp的可执行文件。 - 使用
EXPOSE指令暴露容器内的端口8080,以便外部可以访问该端口。 - 使用
CMD指令定义容器启动时要执行的命令,这里是运行myapp可执行文件。
可以将上述Dockerfile保存为文件,然后使用docker build命令来构建容器镜像,假设Go项目位于当前目录下:
docker build -t my-golang-app:1.0 .
接下来,可以使用docker run命令来创建和运行基于该镜像的容器:
docker run -p 8080:8080 my-golang-app:1.0
将创建一个运行Go服务的容器,并将容器内部的端口8080映射到主机上的端口8080,以便通过主机访问该服务。请确保 Go应用程序监听端口8080,以使其正常工作。
3.6 Docker Compose
参考1:Docker Compose和Docker Swarm简析与区别
Compose:是用于定义和运行多容器Docker应用程序的工具【即容器编排】。通过Compose,可以使用YML文件来配置应用程序需要的所有服务,包括容器、网络、卷等。然后,使用一个命令,就可以根据YML文件启动和管理整个应用程序堆栈。
Compose 使用的三个步骤:
- 使用
Dockerfile定义应用程序的环境。 - 使用
docker-compose.yml定义构成应用程序的服务,这样它们可以在隔离环境中一起运行。 - 最后,执行
docker-compose up命令来启动并运行整个应用程序。 - 执行
docker-compose down命令停止程序。
以下是使用docker-compose的基本概念和用法:
- Docker Compose文件:
Docker Compose使用一个名为docker-compose.yml(或docker-compose.yaml)的文件来定义应用程序的配置。这个文件包含了应用程序中各个服务的描述,以及它们之间的关系和依赖。 - 服务(Services):一个服务通常对应一个容器,它定义了应用程序的一个组件,例如一个 Web 服务器、数据库、消息队列等。在
docker-compose.yml文件中,可以指定服务的镜像、端口映射、环境变量、卷挂载等配置。 - 堆栈(Stacks):使用
docker-compose启动一组服务时,这组服务被称为一个堆栈。堆栈是一种逻辑上的组织方式,允许将相关的服务一起管理。 - 启动应用程序:使用
docker-compose up命令可以启动整个应用程序堆栈。Docker Compose会读取docker-compose.yml文件,并按照文件中的配置启动服务。可以通过添加-d标志来以守护进程模式运行应用程序。 - 关闭应用程序:使用
docker-compose down命令可以停止和删除整个应用程序堆栈的容器、网络和卷。这会清理堆栈中的资源。 - 构建镜像:如果需要,可以使用
docker-compose build命令来构建自定义的镜像,然后在docker-compose.yml文件中引用这些镜像。 - 扩展和伸缩:使用
docker-compose,可以轻松扩展应用程序的服务数量,以满足不同的负载需求。例如,可以使用docker-compose scale命令伸缩特定服务的容器数量。 - 环境变量和秘密:在
docker-compose.yml文件中,可以定义环境变量或引用Docker Swarm的秘密来配置服务,以便在容器中访问敏感信息。 - 覆盖文件:可以使用覆盖文件来在不修改原始
docker-compose.yml文件的情况下,更改服务的配置或添加额外的配置。这对于不同环境(例如开发、测试和生产)中的不同配置非常有用。
Docker Compose是一个强大的工具,特别适用于开发人员和运维团队,用于本地开发、测试和快速部署多容器应用程序。它简化了多容器应用程序的管理,同时提供了一种一致性的部署方式,以确保应用程序在不同环境中的行为一致。
3.6.1 Docker Compose常用命令
3.6.2 Docker Compose构建golang服务和MySQL数据库的示例
要使用Docker Compose构建一个包含Go服务和MySQL数据库的多容器应用,可以按照以下步骤进行操作:
- 创建一个新的目录,用于存放的
Go项目文件、Docker Compose配置文件和MySQL初始化脚本。 - 在该目录中创建一个
Go Web服务的源代码文件,例如main.go,以及一个Dockerfile来构建Go服务的Docker镜像。以下是一个示例Go Web服务的main.go文件,它将连接到MySQL数据库:
package main
import (
"database/sql"
"fmt"
"log"
"net/http"
\_ "github.com/go-sql-driver/mysql"
)
func handler(w http.ResponseWriter, r \*http.Request) {
// 连接到 MySQL 数据库
db, err := sql.Open("mysql", "root:password@tcp(database:3306)/mydb")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// 执行查询
rows, err := db.Query("SELECT message FROM messages")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
// 处理查询结果
var message string
for rows.Next() {
if err := rows.Scan(&message); err != nil {
log.Fatal(err)
}
fmt.Fprintf(w, "Message from MySQL: %s\n", message)
}
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8080", nil)
}
- 创建一个
Dockerfile文件,用于构建Go服务的Docker镜像。以下是一个示例Dockerfile文件:
# 使用官方的 Golang 镜像作为基础镜像
FROM golang:1.17
# 设置容器内的工作目录
WORKDIR /app
# 复制 Go 源代码到容器中
COPY . .
# 构建 Go 服务
RUN go build -o myapp
# 暴露容器内的端口,此示例服务使用 8080 端口
EXPOSE 8080
# 定义容器启动时执行的命令
CMD ["./myapp"]
- 创建一个
docker-compose.yml配置文件,定义Go服务和MySQL服务。以下是一个示例docker-compose.yml文件:
version: '3'
services:
webapp:
build:
context: .
dockerfile: Dockerfile
ports:
- "8080:8080"
depends\_on:
- database
database:
image: mysql:8
environment:
MYSQL\_ROOT\_PASSWORD: password
MYSQL\_DATABASE: mydb
在这个示例中,我们定义了两个服务:webapp和database。
- webapp:服务使用构建上下文 (
context) 为当前目录,指定了Dockerfile来构建Go服务的镜像。它还将容器内部的端口8080映射到主机上的端口8080,以便通过浏览器访问Web应用。depends_on选项确保webapp服务在database服务之后启动,以便数据库服务准备好后才启动Web服务。 - database:服务使用官方的
MySQL镜像,并设置了环境变量来配置MySQL数据库的根密码和数据库名称。
- 在同一目录中创建一个
MySQL初始化脚本,用于在容器启动时初始化数据库。创建一个名为init.sql的文件,内容如下:
CREATE TABLE messages (
id INT AUTO\_INCREMENT PRIMARY KEY,
message VARCHAR(255) NOT NULL
);
INSERT INTO messages (message) VALUES ('Hello, Docker Compose and MySQL!');
- 打开终端,导航到包含以上文件的目录,然后运行以下命令,使用
Docker Compose启动多容器应用:
docker-compose up
Docker Compose将会根据配置文件创建并启动两个容器,分别运行Go Web服务和MySQL数据库。Go Web服务将连接到MySQL数据库并查询数据。
7. 在浏览器中访问:http://localhost:8080,应该能够看到来自MySQL数据库的消息。
8. 若要停止并删除容器,可以在终端中按下Ctrl+C停止正在运行的Docker Compose进程,然后运行以下命令:
docker-compose down
这个示例演示了如何使用Docker Compose构建和管理一个包含Go服务和MySQL数据库的多容器应用程序。根据项目需求,可以进一步扩展和自定义docker-compose.yml文件以满足需要。
3.7 Docker Swarm
Docker Swarm是Docker的集群和编排工具,用于管理和编排多个Docker容器在多个主机上的部署。它允许创建一个Docker集群,将多个Docker主机组合在一起,以便更轻松地管理和扩展容器化应用程序。Docker Swarm提供了以下关键功能:
- 容器编排:
Docker Swarm允许定义容器化应用程序的服务和任务,并确保它们在整个集群中运行,从而轻松进行横向扩展和负载均衡。 - 高可用性:
Docker Swarm提供高可用性特性,可以在集群中保证服务的可用性。它会自动重新调度容器任务到其他可用节点上,以应对容器或节点的故障。 - 服务发现:
Swarm提供内置的服务发现功能,允许容器在集群中相互通信,而无需手动配置网络设置。 - 负载均衡:
Swarm集成了内置的负载均衡功能,可自动将请求分配给运行相同服务的不同容器实例,从而提供更好的性能和容错性。 - 安全性:
Swarm提供了安全性特性,包括节点身份验证、访问控制列表 (ACL) 和加密,以保护容器化应用程序和集群中的数据。 - 内置日志和监控:
Docker Swarm集成了日志记录和监控工具,能够轻松地监视和诊断容器化应用程序。
使用Docker Swarm,可以轻松地创建和管理一个容器编排集群,部署容器化应用程序,并实现高可用性和自动扩展。Swarm的配置文件通常称为docker-compose.yml,与Docker Compose兼容,因此可以无缝地将应用程序从本地开发环境迁移到Swarm集群中。
3.7.1 Docker Swarm常用命令
- 初始化一个
Docker Swarm集群:
docker swarm init
- 将其他
Docker主机加入Swarm集群:
docker swarm join --token <token> <manager-ip>:2377
- 部署一个服务(例如,Nginx):
docker service create --name my-nginx -p 80:80 nginx
- 列出当前
Swarm集群的服务:
docker service ls
- 扩展服务的副本数:
docker service scale my-nginx=5
- 删除一个服务:
docker service rm my-nginx
Docker Swarm是一个强大的容器编排工具,适用于搭建生产环境中的容器化应用程序,使应用程序更易于管理、部署和扩展。它提供了一种容器编排解决方案,使得容器集群的管理变得更加简单和可靠。
3.7.2 Docker Swarm构建golang服务和MySQL数据库的示例
下面是一个示例,演示如何使用Docker Swarm构建一个包含Go服务和MySQL数据库的分布式应用程序。在这个示例中,我们将创建一个Docker Swarm集群,并在该集群上部署一个简单的Go Web服务和一个MySQL数据库。
- 创建一个
Docker Swarm集群:
首先,初始化一个Docker Swarm集群,可以选择一个节点作为Swarm管理节点(manager),其他节点将加入到这个集群中。
在管理节点上运行以下命令:
docker swarm init
这将返回一个命令,可以在其他节点上运行以加入集群。例如:
docker swarm join --token <token> <manager-ip>:2377
在其他节点上运行上述命令以加入Swarm集群。
- 创建一个
docker-compose.yml文件:
在任何一个节点上创建一个名为docker-compose.yml的文件,用于定义服务。以下是一个示例docker-compose.yml文件:
version: '3.8'
services:
webapp:
image: my-golang-app:1.0
ports:
- "8080:8080"
deploy:
replicas: 3
networks:
- mynetwork
depends\_on:
- database
environment:
- DATABASE_URL=mysql://myuser:mypassword@database:3306/mydb
database:
image: mysql:8
environment:
MYSQL\_ROOT\_PASSWORD: mypassword
MYSQL\_DATABASE: mydb
networks:
- mynetwork
networks:
mynetwork:
此配置文件定义了两个服务:webapp和database。webapp服务是一个简单的Go Web服务,它运行在端口8080上,并依赖于database服务。database服务是一个MySQL数据库。
- 构建和推送
Go服务镜像:
在包含Go服务代码的节点上,使用以下命令构建和推送Go服务镜像到Docker镜像仓库(如果有的话):
docker build -t my-golang-app:1.0 .
- 部署服务到
Swarm集群:
在包含docker-compose.yml文件的节点上,运行以下命令来部署服务:
docker stack deploy -c docker-compose.yml myapp
这将创建一个名为myapp的服务堆栈,并在Swarm集群中部署webapp和database服务。
- 查看服务状态:
可以使用以下命令查看服务状态:
docker stack ps myapp
这将显示服务的运行状态,包括哪个节点上运行每个服务的副本。
- 测试应用程序:
使用浏览器或其他工具访问Swarm集群上的任何节点的http://<node-ip>:8080,应该能够访问Go Web服务。该服务将连接到MySQL数据库,执行查询并返回结果。 - 扩展和管理服务:
可以使用Docker Swarm的命令来扩展服务、更新服务、管理节点等。例如,要扩展webapp服务的副本数,可以运行:
docker service scale myapp\_webapp=5
这会将webapp服务的副本数扩展到5个。
3.8 Docker Stack
Docker Stack是一个用于在Docker Swarm集群中部署分布式应用程序的命令行工具。它建立在Docker Compose文件的基础上,允许定义和部署多个服务,这些服务可以在多个Swarm节点上运行,以实现高可用性和容器编排。
以下是Docker Stack的主要特点和用途:
- 应用部署:
Docker Stack允许使用一个docker-compose.yml文件来定义整个应用程序的多个服务、网络、卷和配置。这个文件可以包含应用程序的所有组件和设置。 - 多容器编排:通过
Docker Stack,可以轻松地在Docker Swarm集群中部署和编排多个容器。它提供了服务发现、负载均衡、容器间通信等功能。 - 高可用性:
Docker Stack支持高可用性配置,可以确保服务在整个Swarm集群中保持可用。如果某个节点失败,Swarm会自动重新调度任务到其他可用节点上。 - 自动负载均衡:
Docker Stack集成了内置的负载均衡功能,可以自动将请求分发给运行相同服务的不同容器实例,从而提供更好的性能和容错性。 - 服务扩展:使用
Docker Stack,可以轻松地扩展服务的副本数量,以满足流量和性能需求。这可以通过命令行或更新docker-compose.yml文件来实现。 - 栈管理:可以使用
Docker Stack来创建、列出、更新和删除服务堆栈。这使得应用程序的生命周期管理更加容易。 - 多环境支持:
Docker Stack支持不同的环境(例如开发、测试和生产),并可以使用不同的docker-compose.yml文件进行部署。
3.8.1 Docker Stack常用命令
- 创建一个服务堆栈:
docker stack deploy -c docker-compose.yml myapp
- 列出正在运行的服务堆栈:
docker stack ls
- 查看服务堆栈的详细信息:
docker stack ps myapp
- 扩展服务的副本数量:
docker service scale myapp\_web=5
- 删除服务堆栈:
docker stack rm myapp
Docker Stack是一个有力的工具,用于管理Docker Swarm集群中的容器化应用程序。它允许开发人员和运维团队轻松地定义、部署和管理复杂的分布式应用程序,并确保它们在多个节点上运行,并具备高可用性和容器编排的功能。这使得容器化应用程序在生产环境中更容易管理和维护。
3.8.2 Docker Stack构建golang服务和MySQL数据库的示例
以下是一个示例Docker Stack配置,演示如何使用Docker Stack在Docker Swarm集群中构建一个包含Go服务和MySQL数据库的分布式应用程序。在这个示例中,我们将使用一个简单的Go Web服务连接到MySQL数据库。
- 创建一个
Docker Swarm集群:
在初始化之前,确保已经创建了一个Docker Swarm集群。可以在其中一个节点上运行以下命令来初始化集群:
docker swarm init
然后,使用输出中提供的docker swarm join命令将其他节点加入到Swarm集群中。
- 创建一个目录并进入:
创建一个新的目录,用于存放应用程序代码和Docker Stack配置文件,并进入该目录。
mkdir my-golang-app
cd my-golang-app
- 创建一个
Go Web服务的源代码文件:
在目录中创建一个名为main.go的Go服务源代码文件。以下是一个示例main.go文件,它将连接到MySQL数据库并显示数据库中的消息:
package main
import (
"database/sql"
"fmt"
"log"
"net/http"
\_ "github.com/go-sql-driver/mysql"
)
func handler(w http.ResponseWriter, r \*http.Request) {
db, err := sql.Open("mysql", "myuser:mypassword@tcp(database:3306)/mydb")
if err != nil {
log.Fatal(err)
}
defer db.Close()
rows, err := db.Query("SELECT message FROM messages")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
var message string
for rows.Next() {
if err := rows.Scan(&message); err != nil {
log.Fatal(err)
}
fmt.Fprintf(w, "Message from MySQL: %s\n", message)
}
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8080", nil)
}
- 创建一个
Dockerfile文件:
在同一目录中创建一个名为Dockerfile的文件,用于构建Go服务的Docker镜像。以下是一个示例Dockerfile文件:
# 使用官方的 Golang 镜像作为基础镜像
FROM golang:1.17
# 设置容器内的工作目录
WORKDIR /app
# 复制 Go 源代码到容器中
COPY . .
# 构建 Go 服务
RUN go build -o myapp
# 暴露容器内的端口,此示例服务使用 8080 端口
EXPOSE 8080
# 定义容器启动时执行的命令
CMD ["./myapp"]
- 创建一个
docker-compose.yml文件:
在同一目录中创建一个名为docker-compose.yml的Docker Stack配置文件。以下是一个示例docker-compose.yml文件:
version: '3.8'
services:
webapp:
build:
context: .
dockerfile: Dockerfile
ports:
- "8080:8080"
deploy:
replicas: 3
networks:
- mynetwork
depends\_on:
- database
environment:
- DATABASE_URL=mysql://myuser:mypassword@database:3306/mydb
database:
image: mysql:8
environment:
MYSQL\_ROOT\_PASSWORD: mypassword
MYSQL\_DATABASE: mydb
networks:
- mynetwork
networks:
mynetwork:
这个配置文件定义了两个服务:webapp和database,与之前的示例相似。
- 构建
Go服务的镜像:
在包含Go服务代码的目录中,运行以下命令构建Go服务的Docker镜像:
docker build -t my-golang-app:1.0 .
- 使用
Docker Stack部署服务:
在包含docker-compose.yml文件的目录中,使用以下命令来部署服务到Swarm集群:
docker stack deploy -c docker-compose.yml myapp
- 查看服务状态:
可以使用以下命令查看服务状态:
docker stack ps myapp
- 测试应用程序:
使用浏览器或其他工具访问Swarm集群中的任何节点的http://<node-ip>:8080,应该能够访问Go Web服务。该服务将连接到MySQL数据库并执行查询并返回结果。 - 扩展和管理服务:
可以使用Docker Stack的命令来扩展服务、更新服务、管理节点等。例如,要扩展webapp服务的副本数,可以运行:
docker service scale myapp\_webapp=5
这个示例演示了如何使用Docker Stack构建和管理一个包含Go服务和MySQL数据库的分布式应用程序。根据需求,可以进一步扩展和定制服务以满足复杂应用程序的需求。
3.9 Dockfile 、Compose、Swarm、Stack区别
- Dockerfile:
- 用途:
Dockerfile用于定义和创建容器镜像。它是一个文本文件,包含一系列指令,指导Docker引擎如何构建镜像。 - 功能:
Dockerfile包括镜像的基础配置、构建步骤、环境变量、依赖项安装等信息。 - 示例:
Dockerfile通常用于构建单个容器镜像,例如一个包含Web服务器的容器镜像。
- 用途:
- Docker Compose:
- 用途:
Docker Compose用于定义和管理多个Docker容器的编排和配置。它通过一个声明性的配置文件来定义应用程序的多个服务、网络、卷以及它们之间的关系。 - 功能:
Docker Compose简化了多容器应用程序的部署和管理,可以定义多个容器的组合和交互,并一键启动整个应用程序栈。 - 示例:
Docker Compose适用于部署多容器应用程序,如微服务架构,以及将应用程序的不同部分分为多个容器。
- 用途:
- Docker Swarm:
- 用途:
Docker Swarm用于创建和管理Docker容器的集群。它提供容器编排、高可用性、负载均衡和服务发现等功能,使多个 Docker 主机协同工作。 - 功能:
Docker Swarm允许容器在多个节点上运行,并提供服务发现、负载均衡、自动恢复和高可用性功能。 - 示例:
Docker Swarm适用于部署容器化应用程序到生产环境,以实现容器编排和高可用性。
- 用途:
- Docker Stack:
- 用途:
Docker Stack是Docker Swarm集群中部署分布式应用程序的命令行工具。它建立在Docker Compose文件的基础上,用于定义和部署多个服务,这些服务可以在多个Swarm节点上运行。 - 功能:
Docker Stack可以使用Docker Compose配置文件来部署多容器应用程序,并提供高可用性、负载均衡和容器编排功能。 - 示例:
Docker Stack适用于在Docker Swarm集群中部署和管理多容器应用程序,支持多节点部署和容器编排。
- 用途:
总结:
Docker Dockfile用于构建容器镜像,Docker Compose用于编排多容器应用程序的开发环境,Docker Swarm用于管理Docker集群和部署容器化应用程序,而Docker Stack是Docker Swarm中的一个工具,用于在集群中部署分布式应用程序。这些工具共同构成了Docker生态系统中的不同层次的解决方案,用于容器化应用程序的开发、测试和部署。
3.10 Docker的隔离机制
Docker通过多种隔离机制来确保容器之间和容器与主机之间的资源隔离。这些隔离机制有助于保护应用程序的安全性、稳定性和性能。以下是Docker的主要隔离机制:
- 命名空间(Namespaces):
Docker使用Linux命名空间来隔离容器的视图,以便它们能够在一个单独的用户空间内运行,而不会干扰其他容器或主机系统。以下是一些常见的命名空间类型:- PID命名空间:用于隔离进程
ID(PID),每个容器都有自己独立的进程空间。 - 网络命名空间:用于隔离网络接口和
IP地址,每个容器都有自己的网络命名空间。 - 挂载命名空间:用于隔离文件系统挂载点,每个容器都有自己的文件系统视图。
- UTS命名空间:用于隔离主机名和域名信息。
- IPC命名空间:用于隔离进程间通信资源,如共享内存、信号量等。
- PID命名空间:用于隔离进程
- 控制组(cgroups):
Docker使用cgroups来限制和管理容器的资源使用,包括CPU、内存、磁盘I/O等。每个容器可以被分配一定的资源配额,以确保它不会过度消耗主机资源。 - 联合文件系统(Union File System):
Docker镜像使用分层联合文件系统,允许多个镜像层以只读方式堆叠在一起。这允许容器共享相同的基础层,从而减少存储空间的占用和提高效率。 - 容器文件系统: 每个容器都有一个可写层,用于容器运行时的修改。这个层是容器唯一可以写入的部分,其他层都是只读的,以确保文件系统的隔离。
- 用户和组:
Docker容器通常在一个单独的用户空间内运行,每个容器可以有自己的用户和组。这有助于隔离容器内的进程和文件访问权限。 - Seccomp(安全计算):
Docker支持Seccomp来限制容器中的系统调用。通过Seccomp配置,可以减少容器对主机内核的敏感系统调用,从而提高安全性。 - AppArmor和SELinux:
Docker可以与Linux的强制访问控制(MAC)机制,如AppArmor和SELinux集成,以进一步加强容器的隔离。这些工具可以限制容器对主机资源和文件的访问。 - 容器网络隔离:
Docker提供不同类型的网络隔离,包括桥接网络、主机网络、覆盖网络等,以确保容器之间的通信隔离。这些网络隔离方式使用不同的网络命名空间。
这些隔离机制共同工作,确保容器可以在相对独立和安全的环境中运行,而不会干扰其他容器或主机系统。这使得Docker成为一个强大的容器化平台,适用于各种应用程序和工作负载的隔离需求。但需要注意,虽然Docker提供了许多隔离机制,但仍然需要谨慎配置和管理容器以确保安全性。
3.11 Docker的网络模式
Docker提供了多种网络模式,允许容器之间进行通信以及容器与外部网络连接。选择适当的网络模式取决于应用程序需求和安全性要求。以下是Docker的一些常见网络模式:
- 桥接网络(Bridge Network):这是
Docker的默认网络模式。在这种模式下,每个容器连接到一个本地虚拟网络桥接,容器可以相互通信,同时也可以通过主机的网络连接到外部网络。这种模式适用于多个容器需要在同一主机上互相通信的情况。 - 主机网络(Host Network):在这种模式下,容器与主机共享网络命名空间,容器可以直接使用主机的网络接口。这使得容器与主机之间的网络性能非常高,但也会导致容器与主机之间的网络隔离降低。这种模式适用于需要最大化网络性能的情况。
- 覆盖网络(Overlay Network):覆盖网络允许不同
Docker主机上的容器相互通信。这对于分布式应用程序和容器编排平台(如Docker Swarm和Kubernetes)非常有用,因为它允许容器跨主机进行通信。覆盖网络使用VXLAN等技术在不同主机之间建立虚拟网络。 - MACVLAN网络(MACVLAN Network):这种模式允许容器分配具有唯一
MAC地址的虚拟网络接口。每个容器在网络上看起来像是物理主机的一部分,这对于需要容器与外部网络直接交互的应用程序非常有用。 - 无桥接网络(None Network):在这种模式下,容器不会连接到任何网络,这意味着容器无法直接与外部网络通信。这种模式通常用于特定安全需求或测试目的。
- 自定义网络(Custom Networks): 可以创建自定义网络,根据应用程序的需要配置网络模式、子网、网关等属性。这种方式允许更精细地控制容器之间的通信和网络配置。
选择适当的网络模式取决于应用程序需求和安全性要求。通常情况下,使用桥接网络是最常见的,因为它提供了良好的隔离性和通信能力,但在某些情况下,可能需要使用其他网络模式来满足特定的需求。 Docker的网络模式灵活,可以根据不同的应用场景进行配置和调整。
3.12 Docker命令
3.12.1 Docker常用命令
- 容器生命周期管理:
docker run <options> <image> <command>:运行一个新的容器。docker start <container>:启动已停止的容器。docker stop <container>:停止运行中的容器。docker restart <container>:重启容器。docker pause <container>:暂停容器的进程。docker unpause <container>:恢复暂停的容器。docker kill <container>:强制停止容器。docker rm <container>:删除一个或多个容器。docker ps:列出运行中的容器。docker ps -a:列出所有容器,包括已停止的。docker logs <container>:查看容器的日志。docker exec -it <container> <command>:在运行的容器中执行命令。
- 镜像管理:
docker pull <image>:拉取镜像。docker push <image>:推送镜像到仓库。docker build <options> <path>:构建自定义镜像。docker images:列出本地镜像。docker rmi <image>:删除本地镜像。
- 容器网络管理:
docker network ls:列出所有网络。docker network inspect <network>:查看网络的详细信息。docker network create <network>:创建自定义网络。docker network connect <network> <container>:将容器连接到网络。docker network disconnect <network> <container>:将容器从网络断开。
- 容器数据管理:
docker volume ls:列出所有卷。docker volume create <volume>:创建卷。docker volume inspect <volume>:查看卷的详细信息。docker volume rm <volume>:删除卷。docker cp <container>:<source_path> <destination_path>:从容器复制文件到主机。docker cp <source_path> <container>:<destination_path>:从主机复制文件到容器。
- 其他常用命令:
docker info:查看Docker系统信息。docker version:查看Docker版本信息。docker login:登录到Docker Hub或其他Docker仓库。docker logout:退出登录。docker search <term>:搜索Docker Hub上的镜像。docker-compose <command>:使用Docker Compose管理多容器应用程序。
3.12.2 Docker挂载文件的命令
Docker允许将主机文件系统上的文件或目录挂载到容器内部,以便容器可以访问这些文件。这是通过-v或--volume选项来实现的。以下是挂载文件的Docker命令示例:
- 将主机文件挂载到容器内部:
docker run -v /host/path:/container/path <image>
/host/path:是主机上的文件或目录路径。/container/path:是容器内部的挂载点路径。<image>:是要运行的Docker镜像。
例如,要将主机上的/app/data目录挂载到容器内的/data目录,可以运行以下命令:
docker run -v /app/data:/data myapp_image
- 将主机当前目录挂载到容器内部:
docker run -v $(pwd):/container/path <image>
这个命令将主机的当前工作目录挂载到容器内的指定路径。
- 挂载具有读写权限的卷:
docker run -v /host/path:/container/path:rw <image>
通过添加:rw选项,可以将卷以读写模式挂载到容器内。
- 挂载匿名卷:
docker run -v /container/path <image>
如果省略主机路径,则Docker将创建一个匿名卷,并将其挂载到容器内的指定路径。匿名卷可以用于临时数据存储。
请注意,挂载文件或目录可以在容器和主机之间进行双向数据传输,因此容器对这些文件的更改将反映在主机上,反之亦然。挂载是非常有用的,因为它允许容器访问主机上的配置文件、数据或其他资源,同时也提供了一种简单的方式来在主机和容器之间共享数据。
3.12.3 Docker中查看Pod日志的命令
在Docker中,容器是最小的可部署单元,而Pod通常是Kubernetes中用于组织容器的概念。如果要查看容器的日志,可以使用Docker命令,但如果正在使用Kubernetes或其他容器编排工具来管理容器,通常需要使用相应的工具来查看Pod日志。
在Docker中查看容器日志的命令:
- 使用docker logs命令查看容器日志:
docker logs <container_id>
其中<container_id>是要查看日志的容器的ID或名称。这将显示容器的标准输出和标准错误日志。如果容器已经停止,仍然可以使用这个命令来查看容器的最后一次运行时的日志。
- 使用docker logs命令实时查看容器日志:
docker logs -f <container_id>
添加-f标志,可以实时跟踪容器的日志输出,这对于查看容器当前正在发生的事情非常有用。
请注意,这些命令用于查看单个容器的日志。如果正在使用Kubernetes或其他容器编排工具,通常需要使用该工具提供的命令来查看Pod日志,因为Pod可以包含多个容器。
在Kubernetes中,可以使用以下命令来查看Pod的日志:
- 使用kubectl logs命令查看
Pod日志:
kubectl logs <pod_name> -c <container_name>
<pod_name>:是Pod的名称。<container_name>:是要查看日志的容器的名称。如果Pod中只有一个容器,可以省略-c选项。
- 实时查看
Pod日志:
kubectl logs -f <pod_name> -c <container_name>
添加-f标志,可以实时跟踪日志输出。
这些命令适用于Kubernetes中的Pod,用于查看每个容器的日志。如果使用的是其他容器编排工具,具体的命令可能会有所不同,但一般原理是类似的:首先选择Pod,然后选择容器,最后使用相关命令查看日志。
3.12.4 Docker崩溃后自动重启的命令
假设你有一个docker镜像叫做coolimage:v1,如何运行该镜像?需要保证即使容器内部的程序崩溃了,该容器依然能自动恢复;同时需要保证当主机重启之后,该容器能够自动运行起来。
答:①运行镜像的命令:docker run coolimage --restart always
Docker本身不提供自动重启容器的功能。然而,可以使用一些外部工具和策略来实现在Docker容器崩溃或停止后自动重启容器的目标。以下是一些方法:
- 使用Docker Compose: 如果使用
Docker Compose来管理容器,可以在docker-compose.yml文件中为每个服务定义重启策略。例如,可以将restart字段设置为"always",以指定容器应该始终自动重启:
services:
my-service:
image: my-image
restart: always
- 使用Docker Swarm: 如果使用
Docker Swarm来编排容器,可以使用--restart标志来设置容器的重启策略。例如,以下命令将创建一个服务并设置它在崩溃或停止时自动重启:
docker service create --name my-service --restart-condition any my-image
- 使用容器编排工具: 如果使用
Kubernetes或其他容器编排工具,这些工具通常提供了管理容器重启策略的功能,可以在Pod或Deployment配置中定义重启策略。 - 使用监控和自动恢复工具: 还可以考虑使用监控和自动恢复工具,如
Docker的Healthcheck、Supervisor、Systemd等。这些工具可以监测容器的健康状态,当容器崩溃时触发自动重启。 - 使用第三方工具: 有一些第三方工具,如
Docker自动重启脚本或监控工具,可以监测Docker容器并在容器崩溃时自动重启。这些工具可以根据需求进行定制。
注意:
自动重启容器可能会在某些情况下隐藏问题,因此在实施自动重启策略之前,建议仔细考虑容器的稳定性和问题排查。确保了解为什么容器会崩溃,并采取适当的措施来解决根本问题,以确保应用程序的稳定性。
3.12.5 Docker打包镜像的操作【golang项目】
参考1:https://www.jianshu.com/p/f1c34772f058
完整的Dockerfile:
# 编译镜像
FROM golang:1.16-alpine AS build
WORKDIR /project/
COPY ./project /project
RUN go env -w GOPROXY=https://goproxy.io,direct
RUN go build -o /project/work/server main.go
# 运行镜像
FROM alpine
ENV TZ Asia/Shanghai
COPY --from=build /project/work/ /work/
# 定义工作目录为work
WORKDIR /work
# 开放http 80端口
EXPOSE 80
# 启动http服务
ENTRYPOINT ["./server"]
构建并推送镜像:
# 在Dockerfile所在文件夹运行
docker build -t xxxx/xxxx:v1 .
# 构建成功后,运行测试一下
docker run -d xxxx/xxxx:v1
# docker ps查看一下运行情况
docker ps
# 查看一下容器对应的pid
docker inspect 554c4578242e|grep -i pid
# 查看对应的IP配置
nsenter -t 256418 -n ip a
3.12.6 Docker构建镜像的命令
在Docker中,可以使用docker build命令来构建自定义的镜像。要构建镜像,需要创建一个名为Dockerfile的文件,其中包含有关如何构建镜像的指令。然后,使用以下命令构建镜像:
docker build -t <image_name>:<tag> <path_to_Dockerfile_directory>
以下是各个部分的解释:
<image_name>:要创建的镜像的名称。<tag>:要分配给镜像的标签(可选),通常用于版本控制。如果不指定标签,默认为latest。<path_to_Dockerfile_directory>:包含Dockerfile的目录的路径。Docker将在该目录中查找Dockerfile并使用它来构建镜像。
以下是一个示例,演示如何构建一个名为myapp的镜像,标签为v1.0,Dockerfile位于当前目录下:
docker build -t myapp:v1.0 .
Docker将会读取Dockerfile并执行其中的指令,这些指令包括基础镜像选择、安装软件包、拷贝文件等。在构建过程中,Docker将创建一系列的镜像层,这些层包含了构建过程中的每个步骤,以便后续的重用和版本控制。
一旦构建完成,可以使用以下命令来列出新构建的镜像:
docker images
这会显示创建的镜像以及它们的标签和其他信息。
请确保在构建镜像之前正确编写和测试Dockerfile,以确保镜像包含期望的应用程序和配置。构建的镜像可以用于启动容器,以便在各种环境中运行应用程序。
3.13 Docker Compose部署的服务,如果有一个挂了,它是怎么重新发送到正常服务里的,怎么实现的?
Docker Compose本身并不提供高可用性(High Availability, HA)功能。Docker Compose用于定义和运行多个Docker容器的应用程序堆栈,通常在单个主机上运行。要实现Docker应用的高可用性,通常需要考虑以下几个方面:
- 使用编排工具:
Docker Compose适用于本地开发和测试,它通常不用于生产环境的高可用性。对于生产环境,可以考虑使用编排工具,如Docker Swarm、Kubernetes或其他容器编排工具,以实现容器应用的高可用性。 - 容器编排: 使用容器编排工具,可以将容器部署到多个主机上,并配置容器的副本以确保服务的冗余和高可用性。这些工具还提供故障恢复和自动扩展功能。
- 数据存储高可用: 对于需要数据持久性的应用程序,确保数据库和存储解决方案具有高可用性配置。这可能涉及到复制、分区、备份等机制,以确保数据不会因单点故障而丢失。
- 负载均衡: 高可用的应用程序通常使用负载均衡器来将流量分发到多个容器实例。这有助于确保即使其中一个容器实例出现问题,流量仍然可以被正确路由到其他正常工作的实例。
- 监控和自动恢复: 使用监控工具来检测容器或主机的故障,以及应用程序的性能问题。配置自动恢复机制,以便在故障发生时能够快速恢复服务。
- 容器注册中心: 使用容器编排工具通常需要一个容器注册中心,如
Consul或etcd,以存储和管理容器和服务的状态信息。这有助于实现服务发现、故障恢复和负载均衡。 - 存储卷和数据管理: 确保应用程序在容器重启或重新部署时不会丢失重要数据。使用
Docker卷或外部存储解决方案,以确保数据的持久性和高可用性。 - 多区域部署: 如果应用程序需要更高级别的高可用性,考虑在多个数据中心或云区域中部署,并设置跨区域的负载均衡和故障恢复策略。
总结:Docker Compose适用于本地开发和测试,但对于生产环境中的高可用性,需要使用适当的容器编排工具,并采取适当的措施来确保容器应用的冗余、故障恢复和性能。具体的配置和实施取决于应用程序和基础架构需求。
3.14 Docker与虚拟机的区别
Docker和虚拟机(VM)是两种不同的虚拟化技术,它们在多个方面有着明显的区别。以下是Docker和虚拟机之间的主要区别:
- 架构差异:
Docker:Docker是一种容器化技术,它利用操作系统的容器化功能来隔离应用程序和其依赖项。每个Docker容器共享主机操作系统的内核,但拥有自己的用户空间。这使得Docker容器轻量且启动迅速。- 虚拟机:虚拟机是一种基于
Hypervisor的虚拟化技术,它模拟了完整的硬件层,每个虚拟机都运行一个完整的操作系统,包括内核。这导致虚拟机相对较重,并且启动速度较慢。
- 资源利用效率:
Docker:由于Docker容器共享主机操作系统的内核,因此它们更加轻量,需要更少的资源。多个容器可以在同一主机上运行而不会显著增加资源消耗。- 虚拟机:虚拟机需要模拟整个操作系统,因此每个虚拟机通常需要较多的资源,包括内存和磁盘空间。这限制了在同一主机上运行的虚拟机数量。
- 启动时间:
Docker:Docker容器的启动时间通常非常快,几乎可以瞬间启动。这使得Docker容器非常适合快速扩展和缩减。- 虚拟机:虚拟机的启动时间相对较长,通常需要几分钟来启动,因为它们必须启动整个操作系统。
- 隔离性和安全性:
Docker:Docker容器提供了良好的进程隔离,但容器共享主机操作系统的内核,因此容器之间有一定的安全风险。Docker引入了一些安全性功能,如命名空间和Seccomp,以提高容器的安全性。- 虚拟机:虚拟机提供更高级别的隔离,每个虚拟机都有独立的内核。这增加了虚拟机之间的隔离程度,使其更适合多租户环境和安全性要求严格的工作负载。
- 镜像管理:
Docker:Docker使用分层文件系统和Docker镜像来轻松创建、分享和管理容器。镜像可以非常高效地共享和复用。- 虚拟机:虚拟机镜像通常较大,复制和传输的成本更高,镜像管理相对较为复杂。
总结:
Docker更适合轻量级应用程序容器化和快速部署,而虚拟机通常更适合要求更严格的隔离和安全性的工作负载。选择使用哪种虚拟化技术取决于特定需求和应用场景。在某些情况下,Docker和虚拟机可以结合使用,以充分利用它们各自的优势。
3.15 Docker容器有几种状态
- 运行中(Running):容器正在正常运行,其内部的应用程序或服务正在执行。
- 停止(Exited):容器已经停止,其内部的应用程序或服务已经退出或被停止。这可能是因为容器的主进程已完成或手动停止了容器。
- 暂停(Paused):容器的所有进程都被暂停,但容器的状态保持不变。容器可以被恢复以恢复正常运行。
- 创建中(Creating):容器正在创建,
Docker正在初始化容器的资源和环境。 - 终止中(Terminating):容器正在被停止或删除。这个状态表示容器正在进行清理操作。
- 重启中(Restarting):如果使用了重启策略(如
--restart选项),容器在崩溃或退出后会尝试重新启动。这个状态表示容器正在重新启动。
这些状态反映了容器的当前状态,可以使用docker ps -a命令来查看容器的状态以及其他相关信息。容器状态的管理和监控对于运维容器化应用程序非常重要,以确保容器的稳定性和可用性。
3.16 DockerFile中的命令COPY和ADD命令有什么区别
在Dockerfile中,COPY和ADD命令都用于将文件或目录从主机系统复制到容器内部,但它们有一些重要的区别:
- COPY命令:
COPY命令用于将本地文件或目录复制到容器内部。它的语法如下:
COPY <src> <dest>
#<src> 是主机上的源文件或目录的路径。
#<dest> 是容器内部的目标路径。
* `COPY`命令只复制本地文件系统上的文件或目录到容器,不执行额外的解压缩或处理操作。这使得它更加可预测和透明。
* `COPY`命令通常用于将应用程序代码、配置文件等静态文件复制到容器中。
- ADD命令:
ADD命令也用于将本地文件或目录复制到容器内部。它的语法如下:
ADD <src> <dest>
#<src> 是主机上的源文件或目录的路径。
#<dest> 是容器内部的目标路径。
* 与`COPY`不同,`ADD`命令具有附加功能,它可以处理网络上的`URL`、压缩文件(如`.tar`和`.zip`)以及自动解压缩文件。这使得`ADD`命令更灵活,但也更复杂。
* 使用`ADD`命令时要小心,因为它可能导致意外行为。例如,如果`<src>`是一个`URL`,容器构建可能会因为网络问题而失败,或者可能会导致每次构建时都重新下载文件。
总的来说,COPY命令更加简单和可预测,适用于复制本地文件或目录到容器。而ADD命令具有更多的功能,但需要小心使用,以避免意外行为。通常情况下,如果只需要复制文件或目录,建议使用COPY命令,而在需要处理特殊情况时再考虑使用ADD命令。
3.17 如何批量清理临时镜像文件
要批量清理Docker中的临时镜像文件,可以使用Docker提供的docker system prune命令。此命令可用于删除不再使用的镜像、容器、卷和网络资源,以释放磁盘空间。
以下是如何使用docker system prune命令进行批量清理的步骤:
- 打开终端,并确保以
Docker管理员或拥有足够权限的用户身份登录。 - 运行以下命令以清理不再使用的临时镜像文件:
docker system prune,这将会列出要删除的临时镜像文件以及将删除的总数量。程序会要求确认操作。 - 如果需要自动确认并删除,可以使用
-f或--force选项:docker system prune -f,这将跳过确认提示,立即删除不再使用的资源。 - 如果只想清理特定类型的资源,可以使用子命令,例如清理未被使用的容器、卷、网络或镜像:
- 清理未被使用的容器:
docker container prune - 清理未被使用的卷:
docker volume prune - 清理未被使用的网络:
docker network prune - 清理未被使用的镜像:
docker image prune
- 清理未被使用的容器:
请注意,清理操作是不可逆的,一旦删除,无法恢复。因此,在执行清理操作之前,请确保了解要删除的资源,以免意外删除重要数据。
另外,如果需要定期清理Docker资源,可以设置定时任务或脚本来自动运行docker system prune -f或其他适当的清理命令。这有助于保持磁盘空间的干净和可用。
3.18 如何查看镜像支持的环境变量
查看Docker镜像支持的环境变量,可以使用以下步骤:
- 运行容器:首先,需要运行该镜像的一个容器实例。可以使用
docker run -it <image_name_or_id> /bin/bash命令启动一个容器,并将进入其Shell,请将<image_name_or_id>替换为要查看的镜像的名称或ID。这会启动一个交互式容器。 - 查看环境变量:一旦进入容器的
Shell,可以使用env命令查看环境变量,这将显示容器内部的所有环境变量及其值。可以滚动查看列表以查找感兴趣的特定环境变量。 - 退出容器:当查看完环境变量后,可以使用
exit命令退出容器并返回到主机系统的终端。
请注意,这种方法只能查看镜像在运行时设置的环境变量。如果镜像的环境变量是在Dockerfile中设置的,那么可以查看Dockerfile以了解它们的定义。此外,一些应用程序可能会动态加载环境变量,这些变量可能不会在容器启动时立即可见,而是在应用程序运行时设置。
3.19 本地的镜像文件都存放在哪里
本地的Docker镜像文件存储在Docker守护程序的数据目录中。Docker数据目录的位置因操作系统而异:
- Linux:在大多数
Linux发行版中,Docker数据目录通常位于/var/lib/docker。镜像文件和其他Docker相关数据存储在这个目录中。 - Windows:在
Windows上,Docker数据目录通常位于C:\ProgramData\Docker。这个目录包含了Docker镜像和容器数据。 - macOS:在
macOS上,Docker数据目录通常位于/var/lib/docker,与Linux类似。请注意,在macOS上,Docker使用的是HyperKit虚拟化技术。
Docker镜像文件存储在数据目录的子目录中,其中包括镜像的层(layers)、容器的元数据和其他相关数据。具体的存储路径和目录结构可能会因Docker版本和配置而异,但通常情况下,不需要手动操作这些文件,Docker会负责管理它们。
如果想要查看Docker数据目录的位置,可以运行以下命令来查看Docker的配置信息:
docker info
在输出中,查找名为"Data Root"的项,它将显示Docker数据目录的路径。
请注意,如果不是管理员或没有足够的权限,可能无法访问Docker数据目录中的文件。对Docker数据目录进行直接操作通常是不推荐的,而应该使用Docker命令和API来管理容器和镜像。
3.20 容器退出后,通过docker ps命令查看不到,数据会丢失么
当容器退出后,通过docker ps命令查看不到容器的时候,容器的元数据会被清除,但容器内的数据通常不会立即丢失:
- 容器元数据:
Docker容器在运行时会有一个相应的元数据记录,包括容器的名称、ID、状态等信息。当容器退出(例如,正常停止或发生错误导致退出)时,这些元数据记录会被清除,所以通过docker ps命令查看不到已经退出的容器。 - 容器数据:容器的数据(文件系统等)通常不会立即删除。
Docker会保留容器的数据,以便可以随时重新创建容器并访问先前运行的容器内部的数据。
如果想要重新启动已经退出的容器,可以使用容器的名称或ID来重新创建它,例如:docker start <container_name_or_id>,这将重新启动容器,并且可以通过docker ps查看到运行中的容器。
但是,请注意以下几点:
* 如果在容器退出之前没有使用`docker commit`命令将其保存为新的镜像,容器内所做的更改将不会被保留。
* 如果手动删除了容器(使用`docker rm`命令),那么容器的数据将被删除,除非在删除容器时使用了`-v`选项来保留卷数据。
* 数据的保留时间也受到`Docker`存储驱动程序的影响,不同的存储驱动程序可能会有不同的行为。
如果希望容器的数据永久保存,通常的做法是将数据卷挂载到容器中,这样即使容器退出,数据卷中的数据仍然会被保留。
3.21 如何停止所有正在运行的容器
要停止所有正在运行的Docker容器,可以使用以下命令:
docker stop $(docker ps -q)
这个命令执行了以下两个步骤:
docker ps -q:这个命令将列出当前正在运行的容器的ID,每个ID占据一行。-q标志表示仅输出容器的ID,而不包括其他信息。docker stop:然后,使用docker stop命令来停止列出的所有容器。$(docker ps -q)将上一步中列出的容器ID作为参数传递给docker stop命令。
请注意,这个命令将会停止所有正在运行的容器,包括正在执行的应用程序。确保在执行此命令之前,已经保存了必要的数据或状态。
如果只想停止特定容器,可以使用docker stop命令,后跟容器的名称或ID。例如:
docker stop my_container
3.22 如何清理批量后台停止容器
要清理并批量删除后台停止的容器,可以使用以下步骤:
- 查找并列出后台停止的容器:使用
docker ps -q -f "status=exited"命令来列出后台停止的容器,这个命令使用-q标志仅输出容器的ID,并使用-f标志来筛选状态为"exited"(已停止)的容器。 - 批量删除容器:使用
docker rm命令来批量删除列出的容器。可以将上一步中列出的容器ID作为参数传递给docker rm命令,docker rm $(docker ps -q -f "status=exited"),这将删除所有后台停止的容器。
如果只想删除特定容器,可以将容器的名称或ID传递给docker rm命令。例如:
docker rm my_container
这将删除名为my_container的容器。请谨慎使用docker rm命令,因为删除容器后,与容器关联的数据也将被删除。
请注意,这个操作不会删除镜像,只会删除容器。如果需要删除不再使用的镜像,可以使用docker image prune命令,这将删除未被任何容器引用的镜像,以释放磁盘空间。
3.23 如何临时退出一个正在交互的容器的终端,而不终止它
在一个正在交互的Docker容器终端中,如果想临时退出而不终止容器,可以使用以下方法:
- Ctrl+P,Ctrl+Q组合键:
- 在容器终端内,按下
Ctrl+P键,然后按下Ctrl+Q键,这将退出容器终端,但容器本身会保持运行状态。 - 请确保按下
Ctrl键不要释放,然后按下P和Q键,最后释放Ctrl键。
- 在容器终端内,按下
- 使用docker attach重新连接:
- 使用
docker ps命令查找容器的ID或名称。 - 然后使用
docker attach命令重新连接到容器的终端,如下所示:
- 使用
docker attach <container_id_or_name>
这将重新连接到容器的终端,能够再次与容器交互。
请注意,使用Ctrl+P和Ctrl+Q组合键退出容器终端后,可以使用docker attach命令或docker exec命令来重新连接到容器的终端进行进一步的交互。这种方式可以保持容器的运行状态,不会终止容器。
3.24 很多应用容器都是默认后台运行的,怎么查看它们的输出和日志信息
- 使用docker logs命令:
- 使用
docker ps命令列出正在运行的容器,并找到要查看的容器的名称或ID。 - 使用
docker logs命令来查看容器的标准输出和标准错误日志。例如:docker logs <container_name_or_id>,这将显示容器的输出和日志信息,可以用来查看应用程序的运行情况。
- 使用
- 使用docker attach命令:
- 使用
docker ps命令找到容器的名称或ID。 - 使用
docker attach命令来连接到容器的终端,例如:docker attach <container_name_or_id>,这将连接到容器的终端,允许查看实时输出和日志信息。要从终端断开连接,可以按下Ctrl+C组合键。
- 使用
- 使用容器日志驱动程序:
Docker支持不同的容器日志驱动程序,如json-file、syslog、journald等。可以在创建容器时通过--log-driver选项来指定使用的日志驱动程序,以及其他相关配置。- 使用
docker logs命令查看容器的输出和日志信息时,将使用所配置的日志驱动程序。
- 使用监控和日志集成工具:
- 对于复杂的应用程序,可以考虑使用监控和日志集成工具,如
ELK Stack(Elasticsearch、Logstash、Kibana)或Prometheus等,来集中管理和分析容器日志。
- 对于复杂的应用程序,可以考虑使用监控和日志集成工具,如
通过这些方法,可以查看和管理正在后台运行的容器的输出和日志信息,以便监控和排查问题。根据需求,可以选择适当的方法来查看容器的日志。
3.25 使用docker port命令映射容器的端口时,系统报错Error:NO public port ‘80’ published for …,是什么意思
当使用docker port命令尝试查看容器的端口映射时,如果出现"Error: No public port '80' published for ..."错误,这通常意味着容器在端口80上没有公开(映射)端口。
这个错误的原因可能有以下几种:
- 端口未映射:尝试查看的容器没有将其端口映射到主机的任何公开端口。这可能是因为在运行容器时没有使用
-p或-P选项来映射端口。 - 错误的端口号:可能尝试查看一个容器上没有的端口号。请确保使用的是正确的端口号。
要解决这个问题,可以执行以下步骤:
- 使用
docker ps命令查看容器的详细信息,包括端口映射。查找"PORTS"列,以确定容器上已经映射到主机的端口。 - 如果端口确实没有映射,可以在运行容器时使用
-p选项来映射端口。例如,要将容器的端口80映射到主机的端口8080,可以运行以命令:docker run -d -p 8080:80 <image_name> - 重新运行容器后,再次使用
docker port命令来查看映射的端口。
3.26 可以在一个容器中同时运行多个应用进程吗
可以,不推荐。
Docker容器的最佳实践通常是一个容器只运行一个主要的应用进程。虽然在一个容器中同时运行多个应用进程是技术上可行的,但这并不是推荐的做法,因为它会引入一些挑战和问题:
- 进程管理复杂性:在一个容器中同时运行多个应用进程可能需要复杂的进程管理和监控,包括启动、停止、重启、错误处理等。这可能导致容器的复杂性增加,难以管理。
- 日志和输出管理:多个应用进程将共享标准输出和标准错误流,这可能导致日志混淆,难以追踪问题和分析日志。
- 资源管理:多个应用进程共享容器的资源,如
CPU和内存。这可能会导致资源争用和性能问题。 - 隔离性:容器是用来隔离应用程序的,多个应用进程在同一个容器中运行可能会减弱隔离性,增加安全风险。
- 可维护性:当需要升级或更改其中一个应用程序时,可能需要重新构建整个容器,而不仅仅是更改一个应用进程。这可能会导致不必要的复杂性和资源浪费。
为了更好地利用Docker的优势,通常建议将每个容器设计成一个独立的、单一用途的容器,只运行一个主要的应用进程。如果需要运行多个服务,可以使用Docker Compose或Kubernetes等容器编排工具来协调多个容器的运行。
总之,虽然可以在一个容器中运行多个应用进程,但这不是最佳实践,容易引入复杂性和问题。推荐的方式是将每个容器用于一个独立的应用程序,并使用容器编排工具来管理多个容器之间的关系和依赖。
3.27 如何控制容器占用系统资源(CPU,内存)的份额
可以使用Docker提供的一些选项和限制来控制容器占用系统资源(如CPU和内存)的份额。这可以帮助确保容器在共享主机上的资源时不会无限制地占用资源,从而保证系统的稳定性。以下是一些常见的资源控制方法:
- CPU份额限制:
- 使用
--cpu-shares或-c选项来设置容器的CPU份额。这个值表示容器在CPU资源上的相对权重,可以是一个整数值。例如,以下命令将容器的CPU份额设置为512,相对于其他容器的权重:
- 使用
docker run -d --cpu-shares 512 my_container
默认情况下,每个容器的CPU份额为1024。如果将容器的CPU份额设置为512,它将获得相对于默认份额的一半CPU时间。
* 使用--cpus选项来设置容器可以使用的CPU核心数量。例如,以下命令将容器限制为使用一个CPU核心:
docker run -d --cpus 1 my_container
- 内存限制:
- 使用
--memory选项来设置容器的内存限制。可以指定限制的值,并可以使用单位(例如MB、GB)来表示。例如,以下命令将容器的内存限制设置为512MB:
- 使用
docker run -d --memory 512m my_container
* 使用`--memory-swap`选项来设置容器的总内存限制,包括物理内存和交换空间。默认情况下,它是无限制的。例如,以下命令将容器的内存限制设置为`512MB`,交换空间为`1GB`:
docker run -d --memory 512m --memory-swap 1g my_container
3.28 从非官方仓库(如:dl.dockerpool.com)下载镜像的时候,有时候会提示"Error:Invaild registry endpointhttps://dl.docker.com:5000/v1/…"
如果尝试从非官方仓库(如dl.dockerpool.com)下载镜像时出"Error: Invalid registry endpoint https://dl.docker.com:5000/v1/..."错误,这可能是因为Docker配置中的镜像仓库配置不正确或有误。
以下是一些可能的原因和解决方法:
- 仓库地址错误:提供的镜像仓库地址(
registry endpoint)可能不正确。请确保使用正确的镜像仓库地址。在docker pull命令中,或者在Docker Compose文件或Dockerfile中,检查是否有任何错误的仓库地址。 - 仓库地址包含端口号:如果指定了端口号,确保它与仓库实际使用的端口号匹配。默认的
Docker仓库端口号是80,但有些仓库可能使用其他端口号。 - HTTP和HTTPS:仓库地址可能使用了
HTTPS,但是Docker配置没有正确配置HTTPS代理或证书。如果是这种情况,请确保Docker配置正确并具有所需的证书。 - Docker仓库的可访问性:请确保可以访问指定的
Docker仓库。有时候网络问题或防火墙设置可能会阻止访问特定仓库。 - Docker仓库的状态:有时,非官方仓库可能会不稳定或离线。在这种情况下,可能需要等待一段时间或考虑使用其他镜像仓库。
如果确定镜像仓库地址是正确的,并且仍然遇到问题,可以尝试运行以下命令来清除Docker缓存并重试:
docker system prune -a
docker pull <image_name>
这将清除Docker的镜像缓存并重新尝试下载镜像。如果问题仍然存在,请检查Docker配置和网络设置,确保没有任何问题阻止了与镜像仓库的通信。
3.29 Docker的配置文件放在那里?如何修改配置
Docker的配置文件通常位于操作系统中的不同位置,具体位置取决于操作系统和Docker版本。以下是一些常见的Docker配置文件的位置:
- Linux:
Docker的主要配置文件通常位于/etc/docker/目录下。其中,/etc/docker/daemon.json文件是Docker守护程序的配置文件,可以在其中指定各种Docker配置选项。 - Windows:在
Windows上,Docker Desktop for Windows使用JSON文件来配置Docker。配置文件通常位于%USERPROFILE%\.docker\config.json。可以使用文本编辑器打开此文件进行编辑。 - macOS:在
macOS上,Docker Desktop for Mac使用JSON文件配置,通常位于~/.docker/config.json。可以使用文本编辑器打开此文件进行编辑。
要修改Docker的配置文件,可以按照以下步骤进行操作:
- 打开适当位置的配置文件(如上所述),使用喜欢的文本编辑器。
- 编辑配置文件以添加、删除或修改相应的配置选项。请注意,
Docker配置文件是JSON格式的,因此请确保遵循JSON语法。 - 保存配置文件。
- 重启
Docker守护程序以使配置更改生效。可以使用以下命令来重新启动Docker守护程序:- 在
Linux上:sudo systemctl restart docker - 在
Windows上:在Docker Desktop应用程序中,可以通过右键单击Docker图标并选择"Restart"来重新启动Docker。 - 在
macOS上:在Docker Desktop for Mac应用程序中,可以通过点击Docker图标并选择"Restart Docker"来重新启动Docker。
- 在
注意:
不要随意更改Docker配置文件,除非完全了解要进行的更改,因为错误的配置可能会导致Docker守护程序无法启动或应用程序无法正常工作。修改配置文件时,请备份原始文件以便恢复。
3.30 如何更改docker的默认存储设置
要更改Docker的默认存储设置,需要编辑Docker守护程序的配置文件,并指定新的存储驱动程序或存储选项。存储驱动程序是Docker用于管理容器和镜像数据的组件之一,它定义了数据在主机上的存储方式。以下是一些常见的存储设置更改方法:
注意:在进行存储设置更改之前,请确保了解更改可能会对现有容器和镜像产生的影响。
- 更改存储驱动程序:默认情况下,
Docker使用overlay2存储驱动程序(在大多数现代Linux系统上)。如果希望更改存储驱动程序,请按照以下步骤操作:- 打开
Docker守护程序的配置文件。在Linux上,通常位于/etc/docker/daemon.json。 - 添加或编辑
"storage-driver"配置项,指定新的存储驱动程序名称。例如,要切换到"aufs"存储驱动程序:
- 打开
{
"storage-driver": "aufs"
}
* 保存配置文件,并重启`Docker`守护程序以使更改生效。
- 更改存储驱动程序选项:还可以更改存储驱动程序的选项,以调整存储设置。例如,可以更改
overlay2存储驱动程序的配置。在Docker守护程序配置文件中,可以添加一个"storage-opt"配置项,用于指定存储驱动程序选项。例如:
{
"storage-driver": "overlay2",
"storage-opt": {
"overlay2.override\_kernel\_check": "true"
}
}
这个示例更改了overlay2存储驱动程序的一个选项以允许覆盖内核检查。
3. 更改Docker数据目录:默认情况下,Docker数据目录位于/var/lib/docker。如果需要更改Docker数据目录的位置,可以使用data-root配置项。例如:
{
"data-root": "/path/to/new/docker/data"
}
请确保新目录具有足够的磁盘空间,并且具有适当的权限。
4. 其他存储相关设置:Docker守护程序的配置文件还包含其他与存储相关的选项,例如存储驱动程序的默认选项,存储池大小等。可以根据需要编辑这些选项。
5. 重启Docker守护程序:最后,保存配置文件并重启Docker守护程序,以使更改生效。在Linux上,使用以下命令重启Docker守护程序:sudo systemctl restart docker
注意:
在进行存储设置更改之前,务必备份原始配置文件以防万一。另外,确保仔细阅读Docker文档和存储驱动程序文档,以确保了解所做更改的含义和潜在影响。
3.31 Docker与LXC(Linux Container)有何不同
Docker和LXC(Linux Containers)都是容器化技术,用于在Linux操作系统上创建和管理容器。尽管它们有一些共同之处,但它们在一些关键方面有很大的不同:
- 抽象级别:
Docker是一个高级容器管理工具,它提供了一个简化的容器构建、部署和管理的用户友好界面。Docker引入了Docker镜像和Docker Hub等概念,使容器化变得更加容易。LXC是一个更低级别的容器技术,提供了更原始的容器操作接口。LXC容器通常需要更多的手动配置和管理。
- 镜像和分发:
Docker使用Docker镜像作为容器的构建和分发单元。镜像包含应用程序、运行时和所有依赖项,使得容器在不同环境中可移植。LXC容器通常需要手动创建和配置,没有像Docker镜像那样的分发和版本控制机制。
- 隔离和安全性:
Docker强调应用程序隔离和安全性,尽管它使用了Linux内核提供的容器技术(如cgroups和命名空间),但它添加了一层额外的隔离和安全性措施。LXC容器提供了更原生的Linux进程隔离,较少的隔离措施可能需要手动配置。
- 生态系统和工具:
Docker拥有庞大的生态系统,包括Docker Compose、Docker Swarm、Kubernetes等工具,用于容器编排和管理。Docker Hub也是一个容器镜像仓库,方便共享和分发容器镜像。LXC虽然有一些关联工具,但它的生态系统相对较小,没有与Docker相同的广泛支持和社区。
- 用途:
Docker通常用于构建和运行单个容器化应用程序,适用于微服务架构。LXC更适合需要更多控制和自定义配置的容器场景,通常用于虚拟化和多租户环境。
总结:
Docker是一个高级容器管理工具,更适用于快速构建、部署和管理容器化应用程序。它提供了易于使用的接口和广泛的生态系统。LXC是一种更低级别的容器技术,通常需要更多的手动配置和管理,适用于需要更多自定义控制的情况。选择哪种技术取决于具体需求和项目的要求。
3.32 Docker与Vagrant有何不同
Docker和Vagrant都是用于虚拟化和容器化的工具,但它们在一些方面有很大的不同:
- 虚拟化级别:
Docker是一种容器化技术,它使用Linux容器(如Docker容器)来实现轻量级虚拟化。容器共享主机操作系统内核,因此更轻量、更快速,但隔离性较低。Vagrant是一种虚拟机(VM)管理工具,它使用虚拟化技术(如VirtualBox、VMware)来创建和管理虚拟机。虚拟机是完整的操作系统实例,因此更重量级,但隔离性更强。
- 隔离性和安全性:
Docker容器之间的隔离性相对较低,因为它们共享主机操作系统内核。这意味着容器之间可以共享一些资源和潜在的安全风险。- 虚拟机之间的隔离性较高,因为它们各自运行独立的操作系统内核。虚拟机提供了更强的安全性和隔离,适用于多租户环境。
- 资源利用率:
Docker容器通常比虚拟机消耗更少的资源,因为它们共享主机操作系统内核,并且不需要运行多个完整的操作系统。- 虚拟机通常需要更多的资源,因为它们运行独立的操作系统内核,包括内存、磁盘空间和
CPU。
- 生态系统和用途:
Docker拥有庞大的容器生态系统,适用于快速构建、部署和管理容器化应用程序。它通常用于微服务架构和持续集成/持续交付(CI/CD)流程。Vagrant主要用于创建和管理虚拟机,可以用于开发环境的快速设置和复制,以及为开发团队提供一致的开发环境。
- 配置管理:
Docker容器通常使用Dockerfile来定义容器的构建过程和环境配置。Vagrant使用Vagrantfile来定义虚拟机的配置和启动过程。
- 性能:
Docker容器通常启动更快,因为它们轻量级且不需要启动完整的操作系统。- 虚拟机启动可能需要更多时间,因为它们需要启动整个操作系统。
总结:
Docker和Vagrant在虚拟化和容器化方面有不同的设计目标和适用场景。选择取决于需求,如果需要轻量级、高性能的容器化解决方案,可以选择Docker。如果需要创建和管理虚拟机,并提供一致的开发环境,可以选择Vagrant。在某些情况下,这两者也可以结合使用,例如在Vagrant虚拟机中运行Docker容器。
3.33 开发环境中Docker与Vagrant该如何选择
在选择开发环境中使用Docker还是Vagrant时,需要考虑具体需求和项目的特点。以下是一些考虑因素,可以帮助做出决策:
使用Docker的情况:
- 容器化应用程序:如果正在开发、测试或部署容器化的应用程序,那么
Docker是一个理想的选择。Docker容器提供了轻量级、可移植和一致的运行环境,可以轻松在不同的开发、测试和生产环境中进行部署。 - 微服务架构:如果应用程序采用微服务架构,
Docker容器可以帮助将不同的微服务独立打包为容器,并在开发环境中以容器的形式运行它们,以更好地模拟生产环境。 - CI/CD流程:
Docker容器在持续集成和持续交付(CI/CD)流程中非常有用,可以确保开发、测试和部署过程的一致性。 - 资源效率:
Docker容器通常比虚拟机更轻量级,可以更有效地使用资源,减少开发环境的资源开销。
使用Vagrant的情况:
- 多虚拟机环境:如果需要在开发环境中使用多个独立的虚拟机,并希望每个虚拟机具有自己的操作系统内核和独立的环境,那么
Vagrant是一个不错的选择。这对于复杂的开发和测试场景非常有用。 - 一致的开发环境:
Vagrant可以帮助确保整个团队使用相同的虚拟机配置,以便在不同的开发环境之间保持一致性。 - 集成虚拟机和容器:在某些情况下,可能希望在
Vagrant虚拟机中运行Docker容器,以结合两者的优势。Vagrant提供了与虚拟机的集成能力。 - 较大的资源需求:如果开发环境需要更多的计算资源(例如内存或
CPU),或者需要更复杂的网络配置,那么Vagrant的虚拟机可以提供更大的灵活性。
最终,选择使用Docker还是Vagrant取决于项目的需求、团队的偏好以及目标。在某些情况下,甚至可以将它们结合使用,例如在Vagrant虚拟机中运行Docker容器来组合两者的优势。无论如何,确保开发环境满足项目需求,并且易于维护和管理。
3.34 如何将一台宿主机的docker环境迁移到另外一台宿主机
在源宿主机上备份Docker数据:使用Docker提供的工具或手动备份需要的Docker数据,包括镜像、容器、卷、网络设置等。
- 备份
Docker镜像:可以使用docker save命令将镜像导出为tar文件。例如:docker save -o my_images.tar <image_name> - 备份
Docker容器:如果有自定义容器配置,可以将其导出为Docker Compose文件或Dockerfile,以便在新宿主机上重新创建容器。 - 备份
Docker卷:使用docker cp命令将卷中的数据复制到宿主机上,并将其备份。
在目标宿主机上还原Docker数据:将从源宿主机备份的Docker数据还原到相应的位置。
- 还原
Docker镜像:可以使用docker load命令将备份的镜像加载到新宿主机上。例如:docker load -i my_images.tar - 配置
Docker容器:如果备份了自定义容器配置,使用Docker Compose文件或Dockerfile重新创建容器。 - 还原
Docker卷:将备份的卷数据复制到新宿主机上的卷目录,并在容器中挂载它们。
配置Docker环境:确保目标宿主机上已安装Docker,并根据需要进行配置,以使其与源宿主机上的Docker环境相似(例如,网络设置、存储驱动程序等)。
测试和验证:在目标宿主机上启动容器,验证它们是否按预期运行。检查日志和应用程序的功能,确保一切正常。
注意:
Docker环境的迁移可能涉及到一些复杂性,特别是在不同的宿主机上,可能存在配置差异。因此,在进行迁移之前,建议仔细计划和测试,以确保迁移顺利进行,并且应用程序在新宿主机上正常工作。
此外,如果使用的是Docker Swarm或Kubernetes等容器编排工具,还需要迁移相关配置和状态信息,以确保集群的连续性。每个工具都有相应的迁移和备份方案,具体取决于部署情况。
3.35 Docker镜像联合文件系统
Docker镜像联合文件系统(Union File System)是Docker中一个重要的概念,它用于构建和管理Docker镜像。联合文件系统是一种文件系统层叠的技术,它允许多个文件系统层叠在一起,以创建一个单一的文件系统视图。
Docker使用联合文件系统来构建和管理镜像的多个层。每个Docker镜像都由多个层(Layers)组成,每个层代表一组文件或文件的更改。这些层按顺序堆叠在一起,形成一个完整的文件系统,使得Docker容器可以在这个文件系统上运行。
以下是联合文件系统的一些关键特点和概念:
- 层:每个
Docker镜像都由多个层组成,每个层包含文件系统中的一组文件或文件的更改。层是不可变的,一旦创建就不能修改。 - 分层构建:
Docker镜像是通过分层构建的,每个层都基于前一个层进行更改。这使得构建和推送镜像时只需要传输更改的部分,从而节省带宽和存储空间。 - 联合挂载(
Union Mount):Docker容器在运行时使用联合挂载技术将这些层堆叠在一起,以创建一个可写的容器文件系统。这使得容器可以具有自己的文件系统视图,但仍然共享相同的基础层。 - 容器层:每个容器都有一个额外的可写层,称为容器层。这个层用于存储容器内部的文件更改,使得容器可以在运行时修改文件系统,而不会影响基础镜像。
- 镜像的不可变性:
Docker镜像的层是不可变的,这意味着一旦构建,就不能修改。任何对镜像的更改都会创建一个新的镜像层。 - 共享层:多个镜像可以共享相同的层,这可以显著减少磁盘空间的占用,因为相同的文件层只需要存储一次。
联合文件系统的使用使Docker成为一种轻量级和高效的容器化技术,允许快速创建和部署容器,同时最大限度地减少存储和带宽资源的使用。理解这个概念有助于更好地理解Docker镜像的构建和运行机制。
3.36 Docker是安全的么
Docker本身提供了一些安全机制和隔离措施,但它的安全性取决于如何正确配置和使用它。以下是一些关于Docker安全性的重要考虑因素:
- 隔离:
Docker使用Linux的命名空间(namespace)和控制组(cgroup)等功能来提供容器间的隔离。这些隔离机制确保容器之间和容器与宿主机之间的资源隔离。但需要注意的是,虽然Docker提供了良好的隔离,但不是绝对的安全隔离。 - 容器漏洞:容器化应用程序的安全性与容器内部的操作系统和应用程序有关。如果容器内部的操作系统或应用程序存在漏洞,攻击者可能会利用这些漏洞来攻击容器。因此,保持容器内的操作系统和应用程序的安全性非常重要。
- 映像来源:使用来自可信来源的
Docker镜像是至关重要的。不要使用未经验证的或来自不可信来源的镜像,因为它们可能包含恶意软件或安全漏洞。 - 镜像审查:在使用外部镜像之前,最好审查它们的
Dockerfile和构建过程,以确保它们不包含不必要的组件或潜在的安全问题。 - 最小权限原则:在运行容器时,尽量减少容器的权限,避免将宿主机的敏感信息直接映射到容器中。只赋予容器运行所需的最低权限。
- Docker安全工具:有一些
Docker安全工具和服务可用于扫描容器映像,检测潜在的漏洞和安全问题。例如,可以使用容器扫描工具来审查镜像并确保其安全。 - 漏洞修复和升级:定期更新
Docker守护程序和Docker引擎以获取安全更新。同时,定期更新和维护容器内的操作系统和应用程序以修复已知的漏洞。
总结:
Docker可以提供一定程度的安全性,但安全性的最终责任在于容器的构建和运行。使用Docker时,需要采取一系列安全最佳实践,并确保跟踪容器内部的安全问题。合理配置和维护Docker环境可以大大提高安全性。
3.37 如何清理后台停止的容器
要清理后台停止的容器,可以使用docker container prune命令。这个命令将删除所有处于停止状态的容器,以释放磁盘空间和资源。以下是如何使用该命令的步骤:
- 打开终端或命令行界面。
- 运行以下命令来清理后台停止的容器:
docker container prune - 系统将显示一条警告消息,提示确认是否要删除容器。如果确定,请输入y或yes,然后按Enter键。
WARNING! This will remove all stopped containers.
Are you sure you want to continue? [y/N]
- Docker将开始删除所有已停止的容器。一旦完成,将收到一条消息,显示已删除的容器数量。
Deleted Containers:
<container_id_1>
<container_id_2>
...
请注意,docker container prune命令将删除所有已停止的容器,包括以前运行的容器。如果只想删除特定容器,可以使用docker container rm命令,后跟容器的名称或ID。例如:
docker container rm <container_id_or_name>
确保谨慎使用这些命令,以免意外删除重要的容器。在删除容器之前,请确保不再需要它们,并备份任何重要的数据。
3.38 当启动容器的时候提示:exec format error?如何解决问题
"exec format error"错误通常发生在尝试在不兼容的体系结构上运行容器时。这可能是由于容器镜像与宿主机的CPU架构不匹配所致。要解决这个问题,可以采取以下步骤:
- 检查宿主机的CPU架构:确保宿主机的
CPU架构与容器镜像的期望CPU架构相匹配。可以使用以下命令查看宿主机的CPU架构:uname -m,然后,检查容器镜像是否适用于该架构。 - 使用适用于宿主机的容器镜像:如果宿主机和容器镜像的
CPU架构不匹配,需要使用适用于宿主机的容器镜像。通常,Docker Hub等镜像仓库提供了多个不同的架构版本的容器镜像,以满足不同的需求。 - 切换宿主机架构:如果宿主机和容器镜像的
CPU架构不匹配,可以考虑切换到适用于容器的CPU架构的宿主机。请注意,这可能需要更换硬件或使用虚拟化等技术来模拟所需的CPU架构。 - 构建自定义镜像:如果无法找到适用于宿主机的容器镜像,可以尝试构建自定义的容器镜像,以适应宿主机架构。这涉及到创建一个
Dockerfile,并确保在Dockerfile中选择了正确的基础镜像和架构。 - 检查Docker版本:确保
Docker版本是最新的,以获取对不同架构的更好支持。较旧的Docker版本可能不支持某些架构。
总结:
要解决"exec format error"错误,需要确保容器镜像与宿主机的CPU架构匹配,并且选择适用于宿主机的镜像。如果无法找到适合的容器镜像,可能需要考虑更改宿主机架构或自定义构建容器镜像。
3.39 如何退出一个镜像的bash,而不终止它
要退出一个正在运行的容器的bash终端,而不终止容器本身,可以使用以下方法之一:
- 使用Ctrl + P,Ctrl + Q:如果在容器的
bash终端中,可以使用键盘快捷键Ctrl + P,然后Ctrl + Q来分离终端,而不终止容器。这会将返回到宿主机的终端,而容器继续运行。 - 使用"docker exec"命令:如果使用了
docker exec命令进入容器的bash终端,可以按Ctrl + D来退出容器的bash终端,而不终止容器本身。这将断开与容器的连接,但容器将继续运行。例如:docker exec -it <container_id_or_name> bash - 使用"screen"或"tmux":如果在容器内使用了
"screen"或"tmux"等终端多路复用工具,可以通过分离"screen"或"tmux"会话来退出容器的bash终端,容器将继续运行。
注意:
以上方法中的一些可能需要首先进入容器的bash终端。如果正在运行一个交互式容器(例如,通过docker run -it),可以直接退出bash终端,而不终止容器。如果只是想退出一个后台运行的容器的bash终端,可以使用docker exec命令或Ctrl + P,Ctrl + Q键盘快捷键。
3.40 如何退出容器时候自动删除
要在退出容器时自动删除容器,可以使用docker run命令的--rm选项。这个选项告诉Docker在容器退出后自动删除容器实例,而不需要手动清理。如何使用这个选项的示例:docker run --rm <image_name>,在这个命令中,--rm选项告诉Docker在容器退出后删除它。只需替换<image_name>为要运行的容器镜像的名称或ID。
这对于一次性任务或不需要保留容器实例的情况非常有用。容器退出后,相关的资源和数据将被清理,不会留下残留容器。
3.41 Docker里面如何做监控?
如果我的应用做成容器化去部署,我怎么去监控应用这个运行正常它的性能指标它的一些状态。
- Docker Stats:
Docker提供了一个内置的docker stats命令,可以实时查看运行中容器的资源使用情况,包括CPU、内存、网络和磁盘等。例如:
docker stats container_name
- Prometheus:
Prometheus是一个流行的开源监控解决方案,可以与容器集成。使用Prometheus,可以采集容器的各种指标,并进行报警、图形化展示等操作。需要在容器中运行Prometheus的代理(例如node_exporter)来收集指标数据。 - cAdvisor:
Google提供的cAdvisor是一个容器监控工具,可以收集有关容器的CPU、内存、磁盘和网络等性能指标。cAdvisor可以与Docker结合使用,提供实时监控和历史数据。
docker run -v /:/rootfs:ro -v /var/run:/var/run:ro -v /sys:/sys:ro -v /var/lib/docker/:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor google/cadvisor:latest
- Docker内置Health Checks:
Docker支持容器的健康检查。通过在Dockerfile中使用HEALTHCHECK指令,可以定义容器的健康检查命令。这样,在Docker运行时,可以使用docker inspect查看容器的健康状况。
FROM nginx
HEALTHCHECK --interval=5s --timeout=3s \
CMD curl -f http://localhost/ || exit 1
- ELK Stack(Elasticsearch, Logstash, Kibana):对容器日志进行集中管理和监控也是一种常见做法。使用
ELK Stack,可以将容器的日志集中到Elasticsearch中,并使用Kibana进行可视化展示和搜索。Logstash可以用于数据的过滤和处理。
这些方法可以组合使用,根据具体的监控需求和环境来选择。通过综合使用这些监控工具,可以有效地监测和管理Docker容器的运行状态。
3.42 Docker容器的项目怎么去做一个上线升级替换?
在Docker部署的项目中,进行上线升级替换通常需要考虑以下步骤和策略,以确保服务的高可用性和零宕机时间:
- 准备新版本镜像:确保新版本的
Docker镜像已经构建,并且在本地或远程Docker仓库中可用。确保新版本的镜像在测试环境中已经通过了验证。 - 备份和持久化数据:如果应用程序使用了持久化数据(例如数据库),确保在升级之前进行备份,并考虑数据迁移和升级方案。
- 版本控制和回滚策略:在进行升级之前,确保使用版本控制工具(例如 Git)对代码进行标记。定义回滚策略,以防升级出现问题时能够迅速回滚到之前的版本。
- 流量切换:在进行升级之前,可以使用流量切换策略,逐渐将流量从旧版本切换到新版本。这可以通过服务代理或负载均衡器来实现,确保流量平滑过渡。
- Blue-Green部署:采用
Blue-Green部署策略,即在生产环境中同时维护两个环境,一个是当前运行的(Blue),另一个是新版本的(Green)。通过负载均衡器逐步将流量从Blue切换到Green,完成升级。这样可以降低风险,如果新版本有问题,可以快速切回到旧版本。 - 零宕机升级:如果对服务不允许有任何宕机时间,可以采用零宕机升级策略。这包括在容器编排工具(如
Kubernetes、Docker Swarm)中使用滚动更新策略,逐个替换服务实例。也可以使用进程重启策略,通过平滑重启来替换服务。 - 健康检查和监控:在升级期间,使用健康检查工具确保新版本服务的正常运行。同时,通过监控工具实时监测服务的性能和健康状态。
- 升级后的测试:升级完成后,进行全面的功能测试、性能测试和回归测试,确保新版本的服务正常工作。
- 回滚操作:如果升级过程中发现问题,确保有可靠的回滚方案。这可能包括还原代码、还原数据、回滚数据库变更等操作。
- 文档和通知:在升级之前,更新文档,包括新版本的特性、改动和注意事项。并通知团队成员和相关利益相关者关于升级计划和时间。
以上策略和步骤可以根据具体项目和环境的特点进行调整和优化。在进行升级之前,充分的测试和备份是确保升级成功的重要步骤。
4 K8S(V1.28)
参考1:Kubernetes中文官网
参考2:面试之—K8S、Docker面试题整理
官方介绍:
Kubernetes也称为K8S,是用于自动部署、扩缩和管理容器化应用程序的开源系统。
Kubernetes是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化。Kubernetes拥有一个庞大且快速增长的生态系统,其服务、支持和工具的使用范围广泛。
通俗理解:Kubernetes是一个编排容器的工具,其实也是管理应用的全生命周期的一个工具,从创建应用,应用的部署,应用提供服务,扩容缩容应用,应用更新,都非常的方便,而且可以做到故障自愈,例如一个服务器挂了,可以自动将这个服务器上的服务调度到另外一个主机上进行运行,无需进行人工干涉。
4.1 Kubernetes特性
- 自动化上线和回滚
Kubernetes会分步骤地将针对应用或其配置的更改上线,同时监视应用程序运行状况以确保你不会同时终止所有实例。如果出现问题,Kubernetes会为你回滚所作更改。你应该充分利用不断成长的部署方案生态系统。 - 服务发现与负载均衡
你无需修改应用来使用陌生的服务发现机制。Kubernetes为每个Pod提供了自己的IP地址并为一组Pod提供一个DNS名称,并且可以在它们之间实现负载均衡。 - 自我修复
重新启动失败的容器,在节点死亡时替换并重新调度容器, 杀死不响应用户定义的健康检查的容器, 并且在它们准备好服务之前不会将它们公布给客户端。 - 存储编排
自动挂载所选存储系统,包括本地存储、公有云提供商所提供的存储或者诸如iSCSI或NFS这类网络存储系统。 - Secret 和配置管理
部署和更新Secret和应用程序的配置而不必重新构建容器镜像, 且不必将软件堆栈配置中的秘密信息暴露出来。 - 自动装箱
根据资源需求和其他限制自动放置容器,同时避免影响可用性。 将关键性的和尽力而为性质的工作负载进行混合放置,以提高资源利用率并节省更多资源。 - 批量执行
除了服务之外,Kubernetes还可以管理你的批处理和CI工作负载,在期望时替换掉失效的容器。 - IPv4/IPv6 双协议栈
为Pod和Service分配IPv4和IPv6地址。 - 水平扩缩
使用一个简单的命令、一个UI或基于CPU使用情况自动对应用程序进行扩缩。 - 为扩展性设计
无需更改上游源码即可扩展你的Kubernetes集群。
4.2 为什么需要Kubernetes,它能做什么
参考1:为什么需要Kubernetes,它能做什么?(官方解释)
- 服务发现和负载均衡
Kubernetes可以使用DNS名称或自己的IP地址来曝露容器。 如果进入容器的流量很大,Kubernetes可以负载均衡并分配网络流量,从而使部署稳定。 - 存储编排
Kubernetes允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
你可以使用Kubernetes描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化Kubernetes来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 - 自动完成装箱计算
你为Kubernetes提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉Kubernetes每个容器需要多少CPU和内存 (RAM)。Kubernetes可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。 - 自我修复
Kubernetes将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes允许你存储和管理敏感信息,例如密码、OAuth令牌和ssh密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
※ 4.3~4.6 都是概念解释,和官网内容一致
4.3 Kubernetes对象
4.3.1 Kubernetes对象
4.3.1.1 理解Kubernetes对象
在Kubernetes系统中,Kubernetes对象是持久化的实体。 Kubernetes使用这些实体去表示整个集群的状态。 比较特别地是,它们描述了如下信息:
- 哪些容器化应用正在运行(以及在哪些节点上运行)。
- 可以被应用使用的资源。

最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
为Pod和Service分配IPv4和IPv6地址。
9. 水平扩缩
使用一个简单的命令、一个UI或基于CPU使用情况自动对应用程序进行扩缩。
10. 为扩展性设计
无需更改上游源码即可扩展你的Kubernetes集群。
4.2 为什么需要Kubernetes,它能做什么
参考1:为什么需要Kubernetes,它能做什么?(官方解释)
- 服务发现和负载均衡
Kubernetes可以使用DNS名称或自己的IP地址来曝露容器。 如果进入容器的流量很大,Kubernetes可以负载均衡并分配网络流量,从而使部署稳定。 - 存储编排
Kubernetes允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
你可以使用Kubernetes描述已部署容器的所需状态, 它可以以受控的速率将实际状态更改为期望状态。 例如,你可以自动化Kubernetes来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。 - 自动完成装箱计算
你为Kubernetes提供许多节点组成的集群,在这个集群上运行容器化的任务。 你告诉Kubernetes每个容器需要多少CPU和内存 (RAM)。Kubernetes可以将这些容器按实际情况调度到你的节点上,以最佳方式利用你的资源。 - 自我修复
Kubernetes将重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器, 并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes允许你存储和管理敏感信息,例如密码、OAuth令牌和ssh密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
※ 4.3~4.6 都是概念解释,和官网内容一致
4.3 Kubernetes对象
4.3.1 Kubernetes对象
4.3.1.1 理解Kubernetes对象
在Kubernetes系统中,Kubernetes对象是持久化的实体。 Kubernetes使用这些实体去表示整个集群的状态。 比较特别地是,它们描述了如下信息:
- 哪些容器化应用正在运行(以及在哪些节点上运行)。
- 可以被应用使用的资源。
最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow
第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。
本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









