









Transformer(2):小白也能懂的编码器-解码器Encoder-decoder
(此文所用都是平实的语言,保证小白和门外汉都可以听懂,并有专业理论支撑。如果感兴趣就读一下吧!)
基本原理
Encoder-Decoder (编码器-解码器)架构是时下最流行的架构,它被广泛应用在以下任务中:
- 机器翻译:把一句英文变成中文。
- 图像描述生成:看一张图片,输出一句文字描述。
- 语音识别:听一段语音,输出文字。
- 文本摘要:读一篇长文,生成摘要。
- 聊天机器人:你说一句,它回应一句。
Encoder-Decoder(编码器-解码器)结构就像一个能听懂、记住、再重新表达的“翻译家”或“魔术师”。这个“翻译家”是怎么做到的呢?想象一下你在和一个AI说话:“帮我把这句话翻译成法语:我爱学习。”这个任务的本质是:输入一段信息(句子),输出另一段信息(翻译结果)。但输入和输出的长度可能不一样,内容结构也不同,怎么办?这就是 Encoder-Decoder 发挥作用的地方。Encoder-Decoder 就像一个能听、能想、能说的AI结构:先理解你说的,再换一种方式告诉你结果。
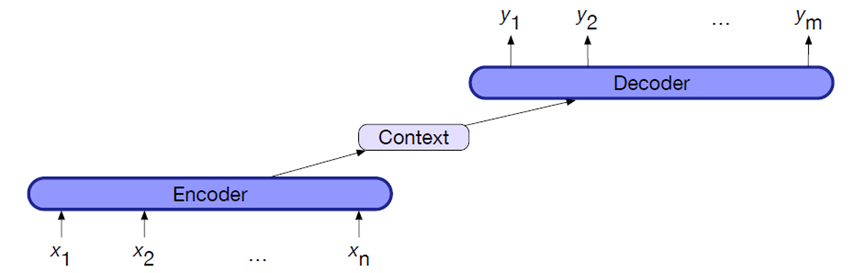
编码器Encoder:负责“听懂”输入
Encoder(编码器)的任务是:把输入的内容“压缩”成一个有用的摘要(通常是一个上下文向量),让后面的系统能理解它的含义。就像你听人说话时,脑子里会抓住重点——Encoder 也是这样,它会把一段输入(比如句子、图像或音频),转换成一种**“机器能理解”的内部表示**。它们之间传递的是一种叫“向量”或“表示”的东西,这些东西对人来说看不懂,但对神经网络来说就像思维的“关键词”。
举个例子,翻译句子。
输入句子:“我爱学习。”
Encoder 输出:一个包含“我、爱、学习”这三个词语意思的“信息浓缩包”。
Encoder input: Embedding input + position embedding (本身的文本嵌入,和位置嵌入)
Encoder output: Hidden states/context vector (隐藏状态,或者说是一个上下文向量)
解码器Decoder:负责“重新表达”
Decoder(解码器)接下来接手。它就像一个聪明的表达者,根据“信息浓缩包”(那个从encoder输出的向量),逐字逐句地生成新的输出。
比如说:
Decoder 拿到浓缩包后,开始输出:
第一个词:“J’aime”(我爱)
第二个词:“étudier”(学习)
就这样,输出了“J’aime étudier”,任务完成。
Decoder input: Hidden states & embedding for target sequence (隐藏状态,以及目标序列的嵌入)
Decoder output: Embedding yt_hat (next word) (预测的下一个单词的嵌入)
Transformer的不同架构
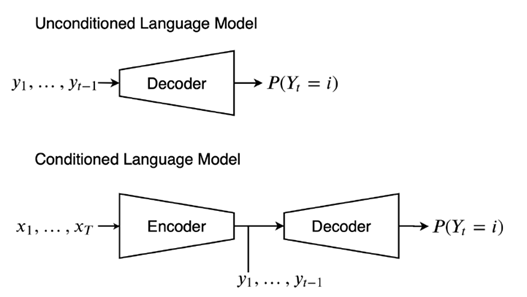
请注意,单独只有encoder能构建一个完整的应用;单独只有decoder也可以构成一个完整的东西。Transformer包括encoder-only, decoder-only, encoder-decoder。
仅解码器decoder模型通常就是我们所说的无条件模型 (Unconditioned LM)。条件语言模型 (Conditioned LM) 有一个编码器组件encoder和一个解码器组件decoder。任何针对仅解码器架构的任务设计都可以转换为针对编码器-解码器架构的任务设计,反之亦然。
仅编码器(Encoder-only)Transformer
适合输入是主要关注点,输出是标签或向量,而非生成序列的任务。适用于需要完整理解输入上下文的任务(比如双向编码),不适合做“生成”型任务。
典型应用:
• 文本分类(text classification),如情感分析、垃圾邮件检测
• 命名实体识别(NER)
• 句子相似度计算(semantic similarity)
• 信息检索(information retrieval),如语义搜索
• 医疗文本标注
代表模型:
• BERT(Bidirectional Encoder Representations from Transformers)
• RoBERTa、ALBERT、DistilBERT
仅解码器(Decoder-only)Transformer
只包含解码器(decoder)部分,使用因果掩码(causal masking)防止看到未来信息。适合逐词生成文本或逐步生成文本的任务(自回归生成,token-by-token)。这种架构输入和输出往往是连续的、拼在一起的(如 GPT)。
典型应用:
• 文本生成(text generation),如写作、对话
• 聊天机器人(chatbot)
• 代码生成(code generation)
• 语言建模(language modeling)
• 大语言模型(LLM)类应用
代表模型:
• GPT 系列:GPT-2、GPT-3、GPT-4
• LLaMA、OPT、Mistral
编码器-解码器(Encoder-Decoder)Transformer
包含编码器和解码器,先对输入编码,再生成输出,常用于序列到序列(seq2seq)任务。适合需要从一个输入序列生成一个输出序列的任务。
典型应用:
• 机器翻译(machine translation)
• 语义摘要(summarization)
• 语音识别到文本(ASR)
• 图像字幕生成(image captioning)
• 医学文本报告生成
代表模型:
• T5(Text-To-Text Transfer Transformer)
• BART(Bidirectional and Auto-Regressive Transformers)
• mBART(多语言版本)
• Transformer(原始论文模型)(用于翻译)
为什么我们需要Encoder-Decoder架构呢?
• 分开理解和生成(Separate Understanding & Generation)
• 灵活的输入输出长度(Flexible Input/Output Lengths)
• 上下文保留(Context Preservation)
• 模块化与复用性(Modularity and Reusability)
基于RNN的编码器-解码器(RNN-based Encoder-Decoder)
基本上,Encoder-Decoder架构里面可以用很多种不同的东西来建构——可以用RNN来建构(它的变体,像LSTM、GRU也行),也可以用transformers来建构(回想之前说过的,transformer的重点就是注意力机制Attention)。先来说用RNN作为基本组件的一类。
RNN 是一种处理序列数据的神经网络,它通过循环结构将前一时刻的隐藏状态传递到下一时刻,从而能够捕捉序列中的时间依赖关系。编码器和解码器都可以使用 RNN 来构建。在编码器中,RNN 逐个处理输入序列的每个元素,并将最后的隐藏状态作为编码后的信息;解码器则从这个隐藏状态开始,逐步生成输出序列。
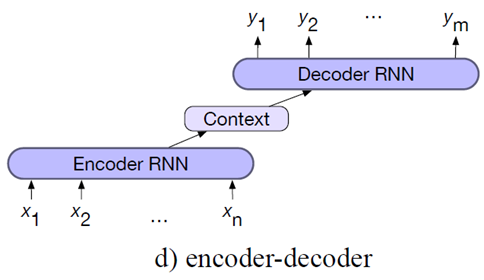
虽然 RNN-based Encoder-Decoder 很聪明,但也有一些问题:
- 记忆不牢——对很长的句子,RNN 后面容易“忘记”前面的内容(比如句子超过20个词)
- 训练慢——因为每个词要一个一个处理,不能并行
- 输出不够精确——有时会漏词、重复或翻译不准
早期RNN-based Encoder-Decoder方法的弱点之一是上下文向量仅在自回归生成过程的最开始直接可用。因此,随着输出序列的生成,其影响力逐渐减弱,导致模型可能偏离原始句子的含义。为了解决这些问题,后来研究人员引入了 Attention(注意力机制),让 Decoder 不只依赖最后一个记忆向量,而是可以“回头看”Encoder 的每一个词。我们在之前还讲过,Attention是可以并行计算的,这大大提高了运算效率。
基于Attention的编码器-解码器(Attention-based Encoder-Decoder)
RNN-based Encoder-Decoder 模型里,有个明显的问题:它要把整句话压缩成一个向量(一个固定大小的“记忆”),然后让 Decoder 根据这个向量输出结果。这就像:你听完别人说了一长段话后,只记住了一句话的“总体印象”,然后你要靠这个印象把话复述出来。是不是很吃力?于是,研究者想出了一个聪明的办法:让AI在说每个词时,可以“回头看”输入句子的每一部分,找重点——这就是 Attention(注意力机制)。
Attention(注意力机制)就是让模型在输出每个词时,有选择地关注输入句子的不同部分。换句话说,Attention 就像模型在“说”每个词前,都会“扫一眼”原文,并决定哪几个词对当前这个词最重要——这就是所谓的“注意力权重”(attention weights)——告诉模型该重点“看哪里”。这就让 Decoder 不再“盲目”地靠记忆说话,而是“边说边参考原文”,大大提升了翻译准确性,特别是长句子。
注意力机制将允许我们创建一个动态更新的上下文向量,该向量在解码的每个步骤中考虑整个编码器状态。上下文向量是编码器隐藏状态的加权平均值,其中权重由每个编码器状态与当前解码器状态的比例相关性决定,从而产生更准确、更符合上下文的输出序列。
像下图中所示,Attention可以被用在encoder里,也可以用在decoder里。图中,左侧是encoder部分,右侧是decoder部分。
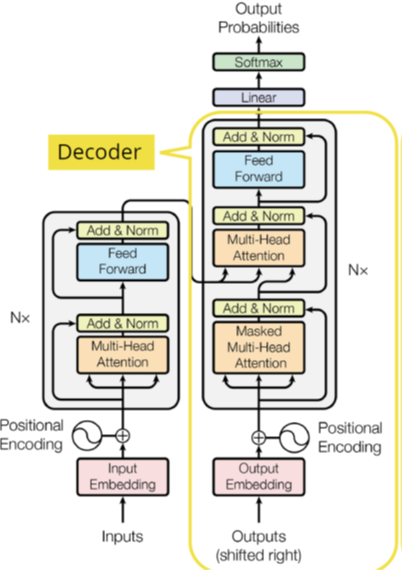
我们在Encoder-Decoder的架构中,如果有Attention(注意力)机制,可以分为两类:Self-attention,以及Encoder-decoder attention或者叫做Cross-attention。Encoder-decoder attention在图中是从encoder画到decoder的那条黑线所连的橙色的那个Multi-head Attention,也就是最上面的那个橙色Attention。
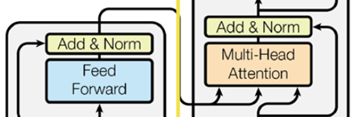
其余两个Attention都是Self-attention。
现在,我们来看看编码器和解码器之间的主要区别之一。编码器encoder只有自注意力层,而解码器decoder既有自注意力层,又有编码器-解码器注意力层。
(Multi-head的意思,是指这个Attention整合了好几个“头”,每个头都能关注不同的部分,比如有的头重点是语义,有的头重点是句子结构。)
复习之前提到过的,Attention注意力机制有三种角色——Query, Key, Value。举一个例子,你在图书馆找一本书:
- 你手里拿着一本单子,列出了你要找的书名 —— Query(查询)
- 图书馆里所有书都有标签,表示它们是什么书 —— Key(键)
- 每本书的内容就是你真正想要的信息 —— Value(值)
你拿着 Query 去跟每本书的 Key 对比,越相似你就越关注那本书,然后根据关注的程度加权读取它的 Value。
对于Encoder-decoder attention编码器-解码器注意力机制:键Key和值Value来自编码器encoder的最终输出。查询Query来自前一层解码器的输出。
对于Self-attention自注意力机制:键Key、查询Query和值Value均来自前一层的输出。
语言模型头部Language Model Head
处理解码器的输出Decoder outputs:在上面彩图中,右上角并不是decoder的部分。它是decoder输出之后用来转化从而得到下一个单词的部分。这些步骤现在一般叫做Language Model Head。它是怎样构成的呢?
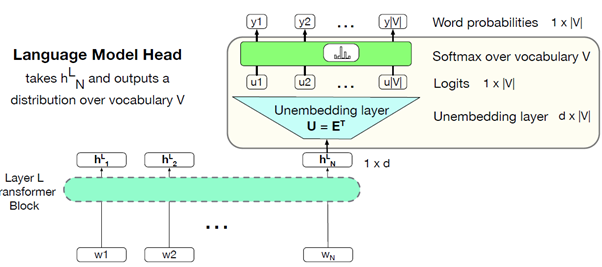
我们取嵌入矩阵Emb并将其乘以这个预测的嵌入 y_hat_t。我们最终得到的是这个 logits。logits 是一个向量,其大小是词汇量大小。词汇表中每一项对应一个词,而这些词给出的分数表示我们认为该词是序列中下一个词的可能性。因此,dog 可能有一个分,apple 可能有一个分,等等。
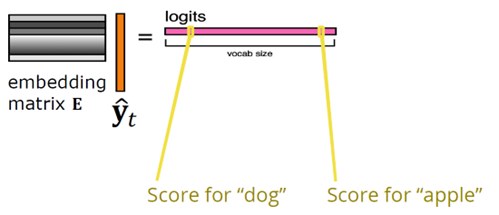
下面,我们要把这些分转换成概率,也就是从0到1。我们一般用softmax来转换成概率分布——它是sigmoid的变体。如果有两类,就用sigmoid;如果有多个类别,像我们下一个单词的可能性太多了,可能是apple, pear, that, 等等,这时就用softmax。
如果我们选好了一个词,这就是我们预测的y_hat。我们希望知道这个预测的词和真实的词之间差了多少(如果是翻译任务的话,应该大致有一个标准答案)。之后用这个相差的东西来训练整个网络,以确保这个相差量越来越小。我们用loss(损失)来代表这个相差的量。通常,当我们训练神经语言模型时,我们使用一种称为负对数似然(negative log likelihood)的损失。
采样策略sampling strategies
好了,我们有每个可能的单词的概率分布。现在,下一个单词到底选哪一个好呢?我们要从这些概率中采样一个词,但是这可以有好多种选法,这取决于你在干什么。关于怎么采样是很有学问的。
我们可以采样概率最高的词(“贪婪”解码),这适合翻译任务,也就是那种只有一个标准答案的任务。但是,你想一想,如果每次都挑选概率最高的那个词,而我们的任务是对话(也就是像正常人一样地说话),那么这种选法不好,因为它每次都说一样的话,一点变化都没有。
也可以从这个概率分布中随机选一个词。这样就有多样性了吧!但是,它不能保证每次选的词都是“正常”的,也就是说,如果任务是生成句子,它很可能生成一些不连贯的、不搭边的句子。
其他的中和这两种的采样方法还有random sampling with temperature、top-k sampling、nucleus sampling、Beam Search 等等。
好了!现在通过Encoder-decoder结构,我们终于可以生成我们想要的内容了。
参考文献:
- Speech and Language Processing, 3rd ed. Daniel Jurafsky, James H. Martin (这本教材是经典的自然语言处理教材,而第3版已经不只这个领域,更可以当作AI学习的宝书,涵盖 了几乎所有的AI流行概念)
- UPenn NLP course. Prof. CCB



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









