









数据抓取
本文主要目标是对数据进行分析,数据抓取具有时效性,在这里对抓取的方法不进行赘述,有不懂的可以看Python爬虫-抓取数据到可视化全流程的实现
评论去重
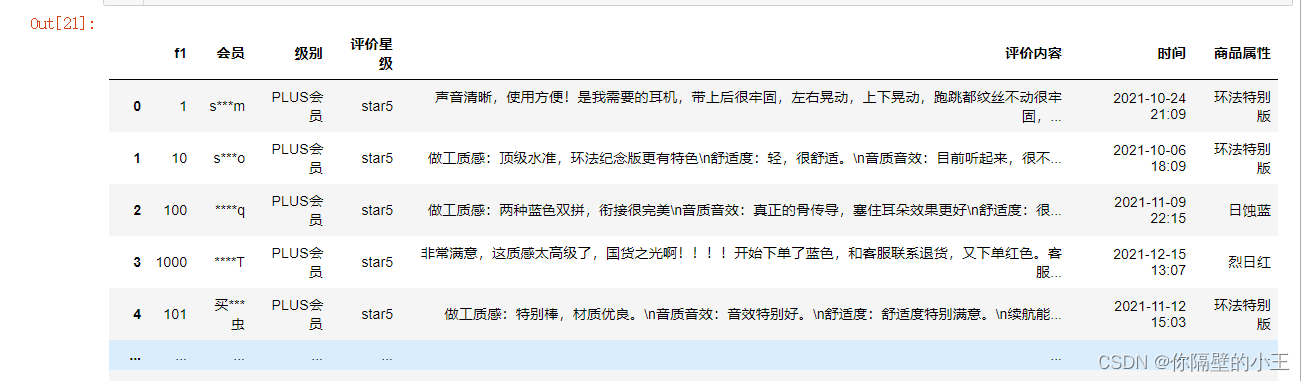
从数据库中取出数据,可以看到共有1260条评论数据,分为8列
#导包
import pandas as pd
import numpy as np
import pymysql
import matplotlib.pyplot as plt
import re
import jieba.posseg as psg
db_info={
'host':"***",
'user':"***",
'passwd':'***',
'database':'cx',# 这里说明我要连接哪个库
'charset':'utf8'
}
conn = pymysql.connect(**db_info)
cursor = conn.cursor()
sql = 'select * from jdsppl'
result = pd.read_sql(sql,conn)
result
result.shape
部分电商平台对长时间未完成订单评价的客户会进行默认评价,此类数据没有分析价值,但是本次爬取的数据来自于京东,京东默认只保留前100页的评论数据,其他数据归为帮助不大的数据,因此在此次爬取的数据中,不存在这样的情况,同时如果在某个商品的评论中出现了完全相同的评论,一次两次或者多次,那么这种情况下的数据肯定是毫无意义的问题数据,这种评论数据只认为其第一条即首次出现时认为其存在一定价值。在评论中会出现一部分评论相似程度很高,但并不完全相同,个别词语还存在明显差异,对于这种情况,全部删除是不正确和不合适的,可以只删除重复的部分,保留有用的文本评论信息,留下更多有用的语料。
reviews = reviews[['content', 'content_type']].drop_duplicates()
content = reviews['content']
reviews

可以看到有17条重复数据已经被删除
通过人工观察数据发现,评论中夹杂着许多数字与字母,对于本案例的挖掘目标而言,这类数据本身并没有实质性帮助。另外,由于该评论文本数据主要是围绕京东商城中韶音 AfterShokz Aeropex AS800骨传导蓝牙耳机进行评价的,**其中“京东”“京东商城”“韶音”“耳机”“蓝牙耳机”等词出现的频数很大,但是对分析目标并没有什么作用,**因此可以在分词之前将这些词去除,对数据进行清洗
# 去除去除英文、数字等
# 由于评论中不重要词语
strinfo = re.compile('[0-9a-zA-Z]|京东|京东商城|韶音|耳机|蓝牙耳机|')
content=result['评价内容']
content = content.apply(lambda x: strinfo.sub('', x))
content

字段已经去除
分词
- 分词是文本信息处理的基础环节,是将一个单词序列切分成单个单词的过程。汉语的基本单位是字,由字可以组成词,由词可以组成句子,进而由一些句子组成段、节、章、篇。可见,如果需要处理一篇中文语料,从中正确地识别出词是一件非常基础且重要的工作。然而,中文以字为基本书写单位,词与词之间没有明显的区分标记。
- 当使用基于词典的中文分词方法进行中文信息处理时,不得不考虑未登录词的处理。未登录词是指词典中没有登录过的人名、地名、机构名、译名及新词语等。当采用匹配的办法来切分词语时,由于词典中没有登录这些词,会引起自动切分词语的困难。常见的未登陆词有命名实体,如“张三”“北京”“联想集团”“酒井法子”等;专业术语,如“贝叶斯算法”“模态”“万维网”;新词语,如“卡拉 OK”“美刀”“啃老族”等。另外,中文分词还存在切分歧义问题,如“当结合成分子时”这个句子可以有以下切分方法:“当/结合/成分/子时”“当/结合/成/分子/时”“当/结/合成/分子/时”“当/结/合成分/子时”等。可以说,中文分词的关键问题为切分歧义的消解和未登录词的识别。分词最常用的工作包是jieba分词包,jieba分词是Python写成的一个分词开源库,专门用于中文分词。
停用词
- **停用词( Stop Words),词典译为“电脑检索中的虚字、非检索用字”。在SEO搜索引擎中,为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为停用词。**通常来讲,停用词大体可以分为两类,一种是使用过于广泛和频繁的词语,比如英文的i、is,中文的“我”“你”等等,另一种是出现频率很高,但是意义不大的词,这种单词一般包括语气助词、副词、介词、连词等等,自身本身并无意义,在经过分词后,评论由一个字符串的形式转换成了多个由文字或词语组成的字符串形式,用来判断评论中的词语是否是停用词。
-
分词
worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)] # 自定义简单分词函数
seg_word = content.apply(worker)
删除标点符号
result = result[result[‘nature’] != ‘x’] # x表示标点符号
构造各词在对应评论的位置列
n_word = list(result.groupby(by = [‘index_content’])[‘index_content’].count())
index_word = [list(np.arange(0, y)) for y in n_word]
index_word = sum(index_word, []) # 表示词语在改评论的位置
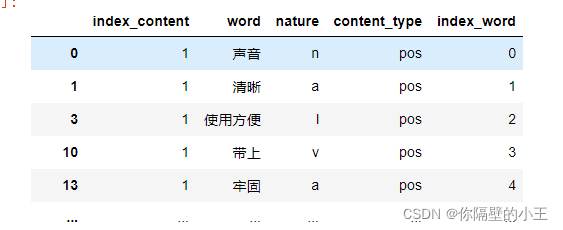
合并评论id,评论中词的id,词,词性,评论类型
result[‘index_word’] = index_word
result
处理后表格样式
**提取含有名词的评论**
* 由于本次分析的目标是对产品特征的优缺点进行分析,**类似“不错,很好的产品”“很不错,继续支持”等评论虽然表达了对产品的情感倾向,但是实际上无法根据这些评论提取出哪些产品特征是用户满意的。**评论中只有出现明确的名词,如机构团体及其他专有名词时,才有意义,因此需要对分词后的词语进行词性标注。之后再根据词性将含有名词类的评论提取出来。jieba关于词典词性标记,采用ICTCLAS 的标记方法,对于词性标注大家可以看:[ICTCLAS汉语词性标注集]( )
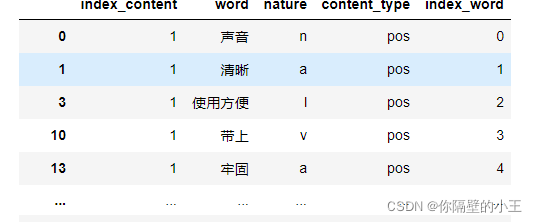
提取评论中词性含有**“n”(名词)**的评论,
提取含有名词类的评论
ind = result[[‘n’ in x for x in result[‘nature’]]][‘index_content’].unique()
result = result[[x in ind for x in result[‘index_content’]]]
#### 词云图绘制
进行数据预处理后,可绘制词云查看分词效果,词云会将文本中出现频率较高的“关键词”予以视觉上的突出。首先需要对词语进行词频统计,将词频按照降序排序,选择前100个词,使用wordcloud模块中的WordCloud绘制词云,查看分词效果([常用字体代码]( ))
import matplotlib.pyplot as plt
from wordcloud import WordCloud
frequencies = result.groupby(by = [‘word’])[‘word’].count()
frequencies = frequencies.sort_values(ascending = False)
backgroud_Image=plt.imread(‘…/data/pl.jpg’)
wordcloud = WordCloud(font_path=“simkai.ttf”,
max_words=100,
background_color=‘white’,
mask=backgroud_Image)
my_wordcloud = wordcloud.fit_words(frequencies)
plt.imshow(my_wordcloud)
plt.axis(‘off’)
plt.show()

从生成的词云图中可以初步判断用户比较在意的是**音质、质感、续航、舒适度**等关键词
## 五、 数据分析
### 评论数据情感倾向分析
#### 匹配情感词
* 情感倾向也称为情感极性。在某商品评论中,可以理解为用户对该商品表达自身观点所持的态度是支持、反对还是中立,即通常所指的正面情感、负面情感、中性情感。对评论情感倾向进行分析首先要对情感词进行匹配,使用**知网发布的“情感分析用词语集 ( beta版)"中的“中文正面评价”词表、“中文负面评价”“中文正面情感”“中文负面情感”词表**等。将“中文正面评价”“中文正面情感”两个词表合并,并给每个词语赋予初始权重1,**作为正面评论情感词表**。将“中文负面评价”“中文负面情感”两个词表合并,并给每个词语赋予初始权重-1,**作为负面评论情感词表。**
* 读入正负面评论情感词表,正面词语赋予初始权重1,负面词语赋予初始权重-1,使用merge函数按照词语情感词表与分词结果进行匹配。
import pandas as pd
import numpy as np
word = pd.read_csv(“…/tmp/result.csv”)
读入正面、负面情感评价词
pos_comment = pd.read_csv(“…/data/正面评价词语(中文).txt”, header=None,sep=“\n”,
encoding = ‘utf-8’, engine=‘python’)
neg_comment = pd.read_csv(“…/data/负面评价词语(中文).txt”, header=None,sep=“\n”,
encoding = ‘utf-8’, engine=‘python’)
pos_emotion = pd.read_csv(“…/data/正面情感词语(中文).txt”, header=None,sep=“\n”,
encoding = ‘utf-8’, engine=‘python’)
neg_emotion = pd.read_csv(“…/data/负面情感词语(中文).txt”, header=None,sep=“\n”,
encoding = ‘utf-8’, engine=‘python’)
将分词结果与正负面情感词表合并,定位情感词
data_posneg = posneg.merge(word, left_on = ‘word’, right_on = ‘word’,
how = ‘right’)
data_posneg = data_posneg.sort_values(by = [‘index_content’,‘index_word’])
#### 修正情感倾向
* 情感倾向修正主要根据情感词前面两个位置的词语是否存在否定词而去判断情感值的正确与否,由于汉语中存在多重否定现象,即当否定词出现奇数次时,表示否定意思;当否定词出现偶数次时,表示肯定意思。按照汉语习惯,搜索每个情感词前两个词语,若出现奇数否定词,则调整为相反的情感极性。
根据情感词前时候有否定词或双层否定词对情感值进行修正
载入否定词表
notdict = pd.read_csv(“…/data/not.csv”)
去除情感值为0的评论
emotional_value = emotional_value[emotional_value[‘amend_weight’] != 0]
**使用wordcloud包下的 WordCloud 函数分别对正面评论和负面评论绘制词云,以查看情感分析效果。**
>
>
> ```
> # 给情感值大于0的赋予评论类型(content_type)为pos,小于0的为neg
> emotional_value['a_type'] = ''
> emotional_value['a_type'][emotional_value['amend_weight'] > 0] = 'pos'
> emotional_value['a_type'][emotional_value['amend_weight'] < 0] = 'neg'
>
> # 将结果写出,每条评论作为一行
> posdata.to_csv("../tmp/posdata.csv", index = False, encoding = 'utf-8')
> negdata.to_csv("../tmp/negdata.csv", index = False, encoding = 'utf-8')
> ```
>
>

可以看到在正面情感评论词云图中可以发现:“不错”、“喜欢”、“满意”、“舒服”等词出现的词频较高,且没有出现负面情感的词语。从负面情感评论中可以发现:“做工”、“客服”、“差”等出现词频较高,**没有发现掺杂正面情感的词语,由此可以正面通过词表来分析文本的情感程度是有效的。**
#### **LDA模型进行主题分析**
* 主题模型在自然语言处理等领域是用来**在一系列文档中发现抽象主题的一种统计模型**。判断两个文档相似性的传统方法是通过查看两个文档共同出现的单词的多少,如TF(词频)、TF-IDF(词频—逆向文档频率)等,这种方法没有考虑文字背后的语义关联,例如,两个文档共同出现的单词很少甚至没有,但两个文档是相似的,**因此在判断文档相似性时,需要使用主题模型进行语义分析并判断文档相似性。**如果一篇文档有多个主题,则一些特定的可代表不同主题的词语就会反复出现,此时,运用主题模型,能够发现文本中使用词语的规律,并且把规律相似的文本联系到一起,以寻求非结构化的文本集中的有用信息。
* **LDA主题模型**:潜在狄利克雷分配,即LDA模型(Latent Dirichlet Allocation,LDA)是由Blei等人于2003年提出的生成式主题模型生成模型,**即认为每一篇文档的每一个词都是通过“一定的概率选择了某个主题,并从这个主题中以一定的概率选择了某个词语”。LDA模型也被称为3层贝叶斯概率模型,包含文档(d)、主题(z)、词(w)3层结构**,能够有效对文本进行建模,和传统的空间向量模型(VSM)相比,增加了概率的信息。通过LDA主题模型,能够挖掘数据集中的潜在主题,进而分析数据集的集中关注点及其相关特征词。
* LDA主题模型是一种无监督的模式,**只需要提供训练文档,就可以自动训练出各种概率,无须任何人工标注过程,节省了大量的人力及时间。**它在文本聚类、主题分析、相似度计算等方面都有广泛的应用。相对于其他主题模型,其引人了狄利克雷先验知识。因此,模型的泛化能力较强,不易出现过拟合现象,建立LDA主题模型,首先要建立词典及语料库
>
>
> ```
> import pandas as pd
> import numpy as np
> import re
> import itertools
> import matplotlib.pyplot as plt
>
> # 载入情感分析后的数据
> posdata = pd.read_csv("../data/posdata.csv", encoding = 'utf-8')
> negdata = pd.read_csv("../data/negdata.csv", encoding = 'utf-8')
> from gensim import corpora, models
> # 建立词典
> pos_dict = corpora.Dictionary([[i] for i in posdata['word']]) # 正面
> neg_dict = corpora.Dictionary([[i] for i in negdata['word']]) # 负面
>
> # 建立语料库
> pos_corpus = [pos_dict.doc2bow(j) for j in [[i] for i in posdata['word']]] # 正面
> neg_corpus = [neg_dict.doc2bow(j) for j in [[i] for i in negdata['word']]] # 负面
> ```
>
>
#### 寻找最优主题数
>
> * **基于相似度的自适应最优LDA模型选择方法,确定主题数并进行主题分析。实验证明该方法可以在不需要人工调试主题数目的情况下,用相对少的迭代找到最优的主题结构。具体步骤如下:**
> * 1)取初始主题数k值,得到初始模型,计算各主题之间的相似度(平均余弦距离)。
> * 2)增加或减少k值,重新训练模型,再次计算各主题之间的相似度。
> * 3 )重复步骤2直到得到最优k值。
> * 利用各主题间的余弦相似度来度量主题间的相似程度。从词频入手,计算它们的相似度,用词越相似,则内容越相近。
> * ```
> # 计算主题平均余弦相似度
> pos_k = lda_k(pos_corpus, pos_dict)
> neg_k = lda_k(neg_corpus, neg_dict)
>
> # 绘制主题平均余弦相似度图形
> from matplotlib.font_manager import FontProperties
> font = FontProperties(size=14)
> #解决中文显示问题
> plt.rcParams['font.sans-serif']=['SimHei']
> plt.rcParams['axes.unicode_minus'] = False
> fig = plt.figure(figsize=(10,8))
> ax1 = fig.add_subplot(211)
> ax1.plot(pos_k)
> ax1.set_xlabel('正面评论LDA主题数寻优', fontproperties=font)
>
> ax2 = fig.add_subplot(212)
> ax2.plot(neg_k)
> ax2.set_xlabel('负面评论LDA主题数寻优', fontproperties=font)
> ```
> 
>
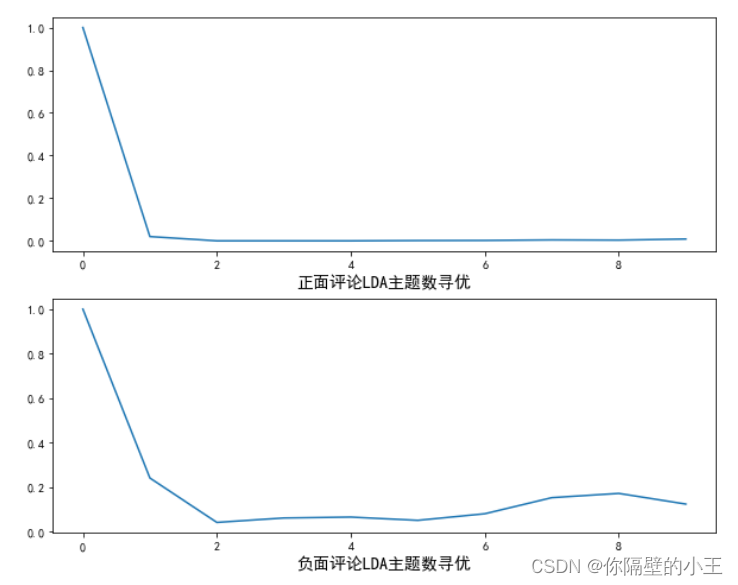
> **从图中可以发现,当主题数为2时,主题间的余弦相似度达到最低,因此选择主题数为2**
>
>
>
#### 评价主题分析结果
根据主题数寻优结果,使用Python的Gensim模块对正面评论数据和负面评论数据分别构建LDA主题模型,选取主题数为2,经过LDA主题分析后,每个主题下生成10个最有可能出现的词语及相应的概率
LDA主题分析
pos_lda = models.LdaModel(pos_corpus, num_topics = 2, id2word = pos_dict)
neg_lda = models.LdaModel(neg_corpus, num_topics = 2, id2word = neg_dict)
pos_lda.print_topics(num_words = 10)
neg_lda.print_topics(num_words = 10)

**整理:**


**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5L2g6ZqU5aOB55qE5bCP546L,size_20,color_FFFFFF,t_70,g_se,x_16)
**整理:**
[外链图片转存中...(img-fESIJMYW-4701988863976)]
[外链图片转存中...(img-QTMZv3A5-4701988863977)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









