






一、神经网络基础概念

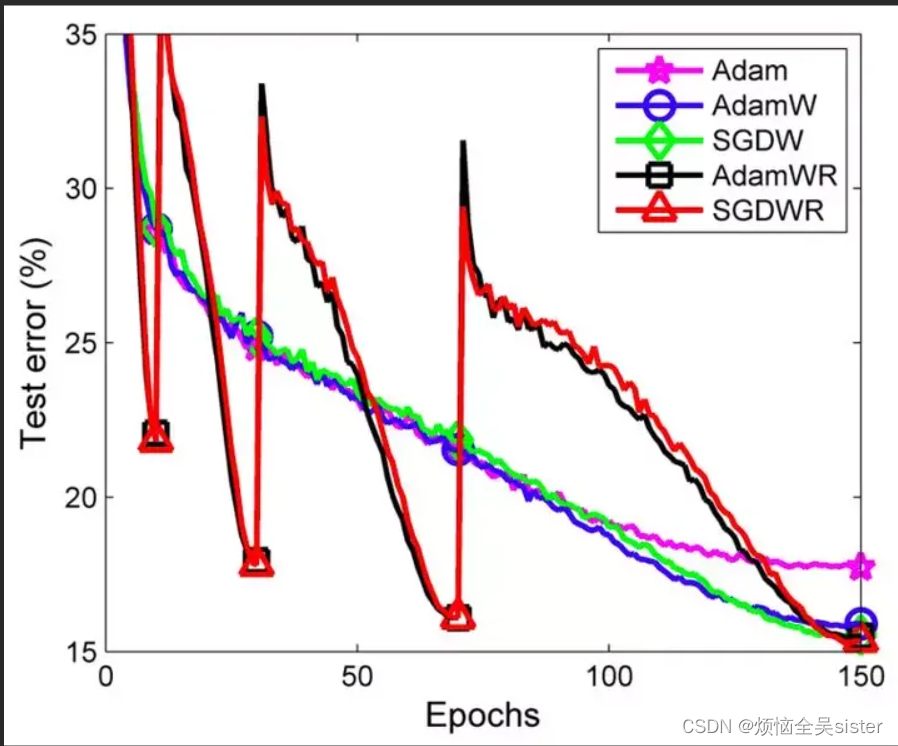
二、adam优化器
adam函数作为优化器能够减少运算量,并有较好的优化效果,定义的语句如下:
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
optimizer梯度清零 :
optimizer.zero_grad()
计算损失函数:
loss = criterion(y_pred, y_data)
用损失函数反向传播:
loss.backward()
根据损失函数反向梯度optimizer进行参数更新:
optimizer.step()
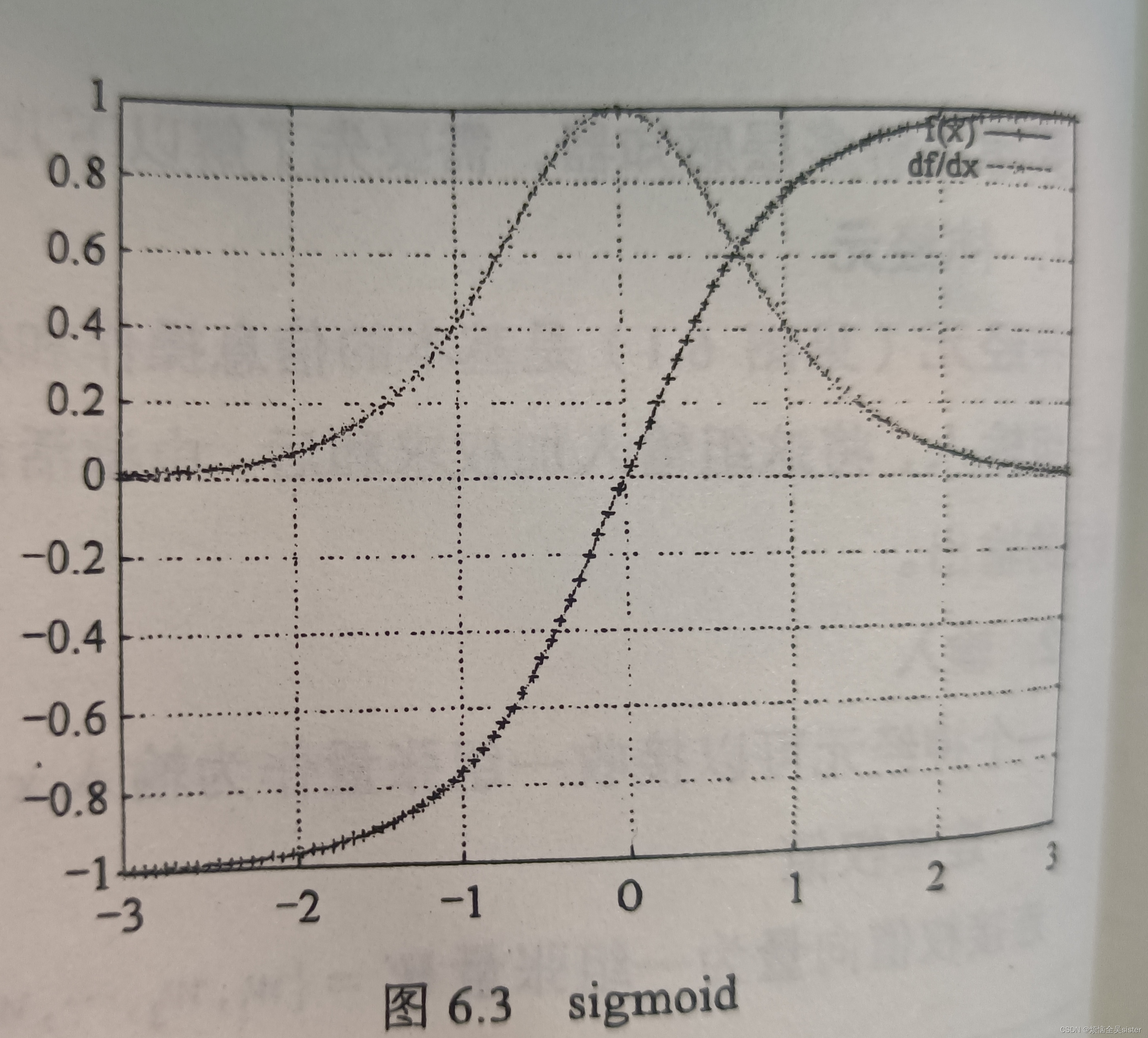
三、sigmoid激活函数
sigomid可以确保输出总和为1,并且结果可以解释为输入的类是对应标签的概率

四、BP神经网络
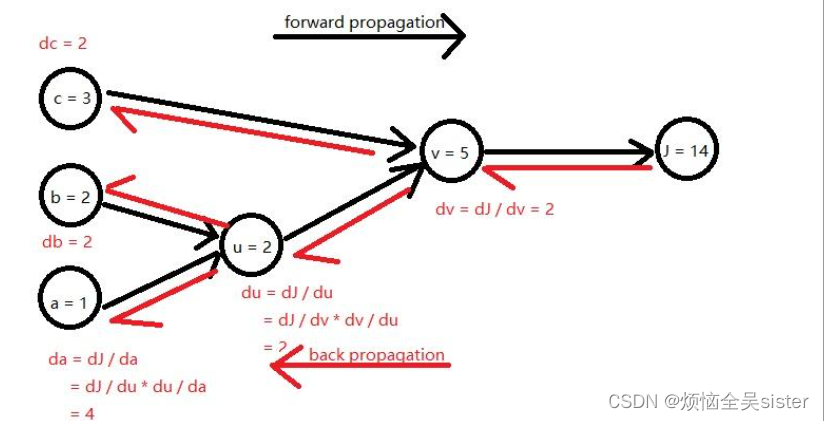
(1)反向传播(Back Propagation,BP)
反向传播的核心思想是将误差输出层向前层反向传播,利用后一层的误差来估计前一层的误差。
反向传播公式: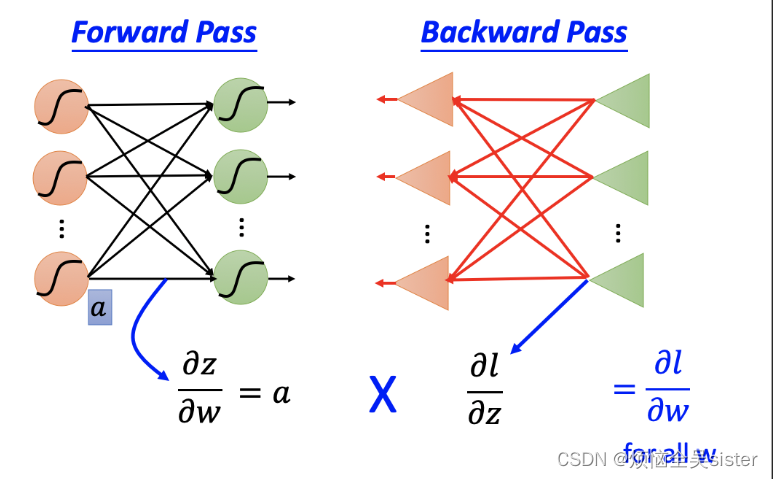
(2)梯度下降
梯度下降法在机器学习中常常用来优化损失函数。

(3)梯度下降和反向传播的关系
梯度下降是一种求损失函数极小值的方法,反向传播是一种求解梯度的方法,两者是深度学习中的重要技术。















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









