






 本文介绍了深度学习框架的作用,重点剖析了PyTorch的特点,包括其从Torch发展而来,提供Python接口和动态图系统。此外,文章详细讲解了模型评估、损失函数、过拟合与欠拟合的预防方法,以及监督学习和非监督学习的区别,以及常见的评价指标如准确率、精确率和召回率。
本文介绍了深度学习框架的作用,重点剖析了PyTorch的特点,包括其从Torch发展而来,提供Python接口和动态图系统。此外,文章详细讲解了模型评估、损失函数、过拟合与欠拟合的预防方法,以及监督学习和非监督学习的区别,以及常见的评价指标如准确率、精确率和召回率。
首先,我知道深度学习框架是一种用于构建,训练和部署深度神经网络模型的工具集合。它提供了丰富飞函数和工具,使开发者能够很方便地创建、调整和优化神经网络模型。常用的深度学习框架有PYTorch、TensorFlow、caffe、MXNet等等。
下面让我们看看PyTorch
(1)PyTorch的特点和概述
PyTorch具有先进设计理念的框架,其历史可追溯到2002年就诞生于纽约大学的Torch。Torch使用了一种不是很大众的语言Lua作为接口。Lua简洁高效,但由于其过于小众,以至于很多人听说要掌握Torch必须新学一门语言就望而却步,但Lua其实是一门比Python还简单的语言。考虑到Python在计算科学领域的领先地位,以及其生态完整性和接口易用性,几乎任何框架都不可避免地要提供Python接口。终于,在2017年,Torch的幕后团队推出了PyTorch。 PyTorch不是简单地封装Lua,Torch提供Python接口,而是对Tensor之上的所有模块进行了重构,并新增了最先进的自动求导系统,成为当下最流行的动态图框架。 PyTorch特点是拥有生态完整性和接口易用性,使之成为当下最流行的动态框架之一。
(2)模型评估和模型参数选择
损失函数:若对于给定的输入x,若某个模型的输出y ̂=f(x)偏离真实目标值y,那么就说明模型存在误差; y ̂偏离y的程度可以用关于y ̂和y某个函数L(y,y ̂)来表示,作为误差的度量标准:这样的函数L(y,y ̂)称为损失函数。
重要概念:在某种损失函数度量下,训练集上的平均误差被称为训练误差,测试集上的误差称为泛化误差。 由于我们训练得到一个模型最终的目的是为了在未知的数据上得到尽可能准确的结果,因此泛化误差是衡量一个模型泛化能力的重要标准。
数据集可划分为:训练集、验证集、测试集。
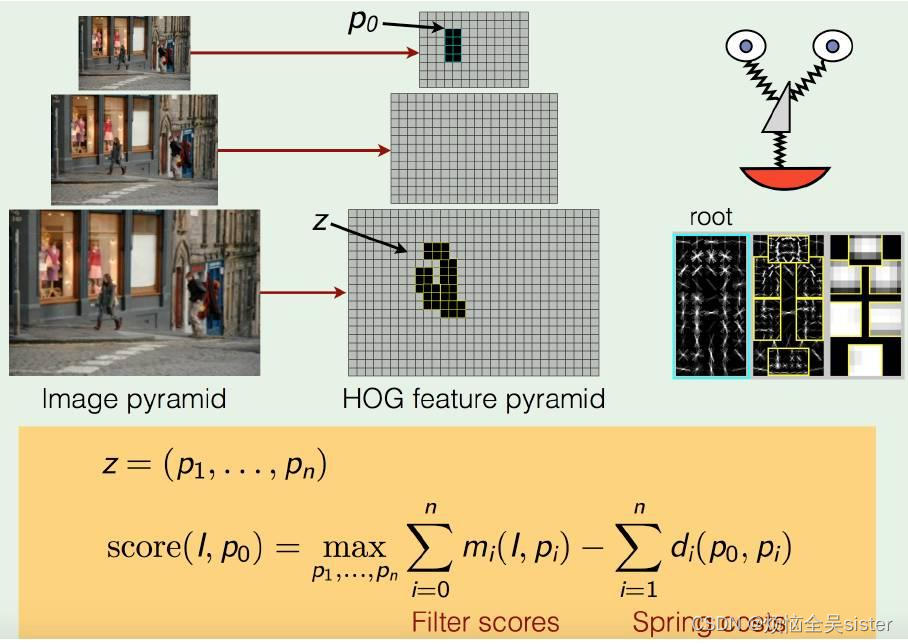
误差:预测输出y ̂与真实输出y之间的差异; 经验误差、训练误差:在训练集上的误差; 泛化误差:在新样本上的误差。 泛化误差越小越好,经验误差不一定越小越好,可能导致过拟合。
过拟合:将训练样本自身的一些特点当作所有样本潜在的泛化特点。 表现:在训练集上表现很好,在测试集上表现不好。 过拟合的原因: 训练数据太少(比如只有几百组) 模型的复杂度太高(比如隐藏层层数设置的过多,神经元的数量设置的过大) 数据不纯。
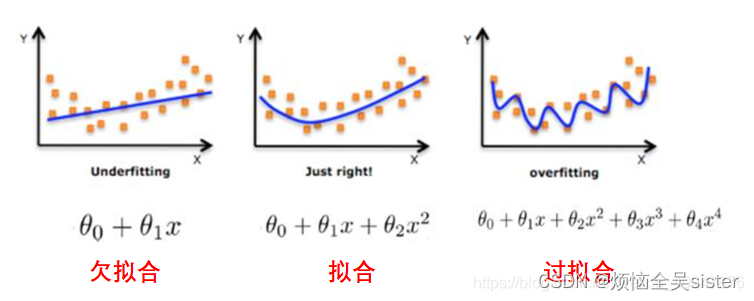
防止过拟合问题的方法:- 移除特征,降低模型的复杂度:减少神经元的个数,减少隐藏层的层数 - 训练集增加更多的数据 - 重新清洗数据 - 数据增强 - 正则化 早停
欠拟合:还没训练好。 1. 欠拟合的原因: 1. 数据未做归一化处理 2. 神经网络拟合能力不足 3. 数据的特征项不够 2. 解决方法: 1. 寻找最优的权重初始化方案 2. 增加网络层数、epoch 3. 使用适当的激活函数、优化器和学习率 4. 减少正则化参数 5. 增加特征
验证:k 折交叉验证(k-fold cross validation):k 一般取 10 将数据集分为训练集和测试集,将测试集放在一边 将训练集分为 k 份 每次使用 k 份中的 1 份作为验证集,其他全部作为训练集。 通过 k 次训练后,我们得到了 k 个不同的模型。 评估 k 个模型的效果,从中挑选效果最好的超参数 使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终模型。
正则化:L1正则化:使权重的绝对值最小化,且对于异常值是鲁棒的。
L2正则化:使得权重的平方最小化,该模型能够学习复杂的数据模式,但对于异常值不具备鲁棒性。
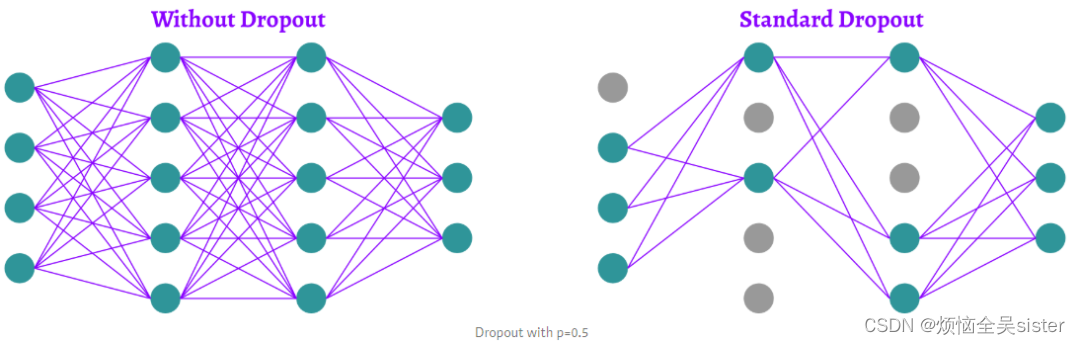
Dropout :是一种正则化方法,用于随机禁用神经网络单元。
监督学习:如果这些样本点以〈𝒙,𝒚〉这样的输入-输出二元组的形式出现(有数据标签),那么就可以采用监督学习的算法
非监督学习:如果数据集中样本点只包含了模型的输入𝒙,那么就需要采用非监督学习的算法。
均方误差损失函数(Mean Squared Error,MSE): 最常用的回归问题的损失函数。其定义为预测值与真实值之间的平方差的平均值。 该损失函数的值越小,表示模型的预测结果越接近真实值

分类:将正样本预测正样本(True Positive, TP)将负类样本预测为正样本(False Positive, FP)
将正样本预测为负样本(False Negative, FN)将负类样本预测为负样本(True Negative, TN)
准确率(Accuracy):对于测试集中D个样本,有k个被正确分类,D-k个被错误分类,则准确率为: Accuracy=分类正确的样本/样本总数= k/D= (TP+TN)/(TP+TN+FP+FN)
精确率(查准率)- Precision:所有被预测为正样本中实际为正样本的概率 Precision=预测为正样本实际也为样本/预测为正样本= TP/TP+FP
召回率(查全率)- Recall:实际为正的样本中被预测为正样本的概率 Recall=预测为正样本实际也为样本/实际为正样本= TP/TP+FN















 4175
4175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









