






作者:算力魔方创始人/英特尔创新大使刘力
一,引言
在大数据时代,文档数据量急剧增加,传统的手工方式已无法满足快速获取有效信息的需求。深度学习技术,尤其是计算机视觉领域的光学字符识别(OCR)技术的进步,使得自动化和智能化的文档信息提取成为现实。本方案结合了Intel OpenVINO平台的性能优化优势与百度飞桨(PaddlePaddle)提供的PP-OCRv4模型,旨在开发一款高性能、高精度的智能文档处理系统。
算力魔方®是一款可以DIY的迷你主机,采用了抽屉式设计,后续组装、升级、维护只需要拔插模块。通过选择不同算力的计算模块,再搭配不同的 IO 模块可以组成丰富的配置,适应不同场景。
性能不够时,可以升级计算模块提升算力;IO 接口不匹配时,可以更换 IO 模块调整功能,而无需重构整个系统。
本文以下所有步骤将在带有英特尔i5-1235U处理器的算力魔方®上完成验证。

二,实施步骤
(一)准备工作:
安装必要的软件包Anaconda(https://www.anaconda.com/download),然后用下面的命令创建并激活对应的开发环境:
conda create -n OCR python=3.11 #创建虚拟环境conda activate OCR #激活虚拟环境python -m pip install --upgrade pip #升级pip到最新版本pip install -r requirements.txt # 安装所需的软件包Pip install "git+https://github.com/huggingface/optimum-intel.git" --extra-index-url https://download.pytorch.org/whl/cpu -i https://pypi.tuna.tsinghua.edu.cn/simple #配置环境,确保与PaddlePaddle兼容。
(二)模型部署:
下载并加载预训练的PP-OCRv4模型,利用OpenVINO进行优化转换,以更好地适配目标硬件平台。
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar && tar -xvf ch_PP-OCRv4_det_infer.tar # 下载PP-OCRv4的检测模型wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar && tar -xvf ch_PP-OCRv4_rec_infer.tar # 下载PP-OCRv4的识别模型wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tar # 下载PP-OCRv4的角度分类器
将优化后的模型保存至PP-OCRv4_OpenVINO 文件夹目录,确保路径正确无误。运行部署脚本:
(三)运行脚本
要快速开始使用 PP-OCRv4_OpenVINO 项目,请执行以下步骤:
Python main.py #运行python代码调用推理后续程序会将识别到的文本结果直接打印到控制台:
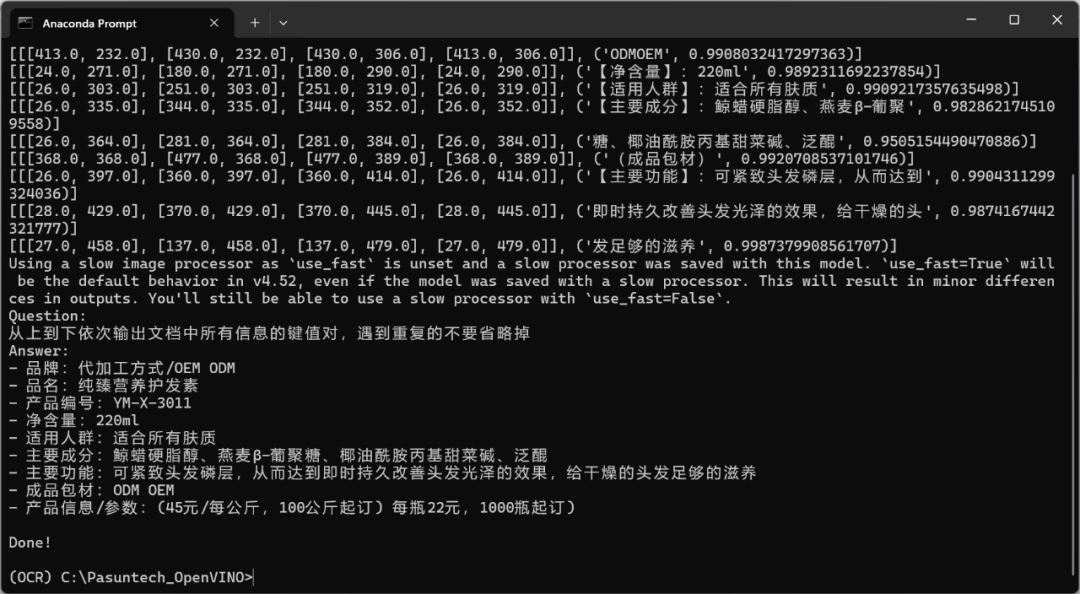
算力魔方+AI黑科技,秒变文档小能手!
三,结论
本文介绍了一种利用OpenVINO工具套件、PP-OCRv4模型和Qwen2.5-VL视觉语言模型构建的智能文档信息提取解决方案。该方案结合了尖端的视觉识别技术和经过优化的计算性能,目的是提高文档处理的效率和精确度,适用于包括财务报表分析、合同审查在内的多种场景。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









