






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、实验目的
1.掌握关系数据在大数据中的应用
2.掌握关系数据可视化方法
3. python 程序实现图表
二、实验环境
OS:Windows
python:v3.11
三、实验原理
在传统的观念里面,一般都是致力于寻找一切事情发生的背后的原因。现在要做的是尝试着探索事物的相关关系,而不再关注难以捉摸的因果关系。这种相关性往往不能告诉读者事物为何产生,但是会给读者一个事物正在发生的提醒。关系数据很容易通过数据进行验证的,也可以通过图表呈现,然后引导读者进行更加深入的研究和探讨。分析数据的时候,可以从整体进行观察,或者关注下数据的分布。数据间是否存在重叠或者是否毫不相干?也可以更宽的角度观察各个分布数据的相关关系。其实最重要的一点,就是数据进行可视化后,呈现眼前的图表,它的意义何在。是否给出读者想要的信息还是结果让读者大吃一惊?就关系数据中的关联性,分布性。进行可视化,有散点图,直方图,密度分布曲线,气泡图,散点矩阵图等等。本次试验主要是直方图,密度图,散点图。直方图是反应数据的密集度,是数据分布范围的描述,与茎叶图类似,但是不会具体到某一个值,是一个整体分布的描述。密度图可以了解到数据分布的密度情况。密度图可以了解到数据分布的密度情况。散点图将序列显示为一组点。值由点在图表中的位置表示。散点图通常用于比较跨类别的聚合数据。
四、实验步骤
数据源:
一、安装Python所需要的第三方模块
pip install seaborn
二、实验
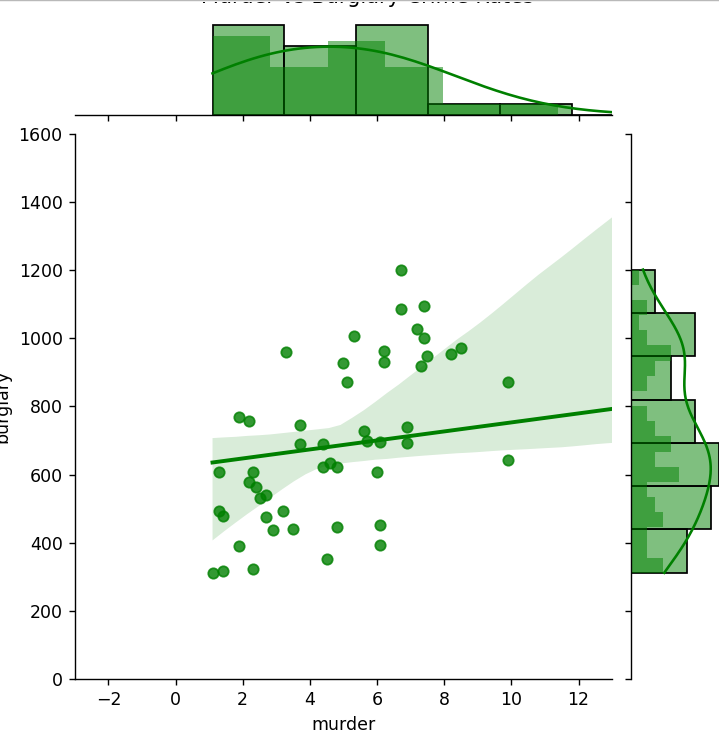
1 、请使用seaborn模块中的jointplot方法将散点图,密度分布图和直方图合为一体,数据选取murder列及burglary列,探究两种犯罪类型的相关关系,效果如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
file_path = r"E:\\EDG浏览器\\crimeRatesByState2005.csv" # 请确保路径正确
data = pd.read_csv(file_path)
print(data.head()) # 打印前几行数据
g = sns.jointplot(data=data, x="murder", y="burglary", kind="reg", color="green")
g.set_axis_labels("murder", "burglary")
g.ax_joint.set_xlim(-3, 13)
g.ax_joint.set_ylim(0, 1600)
g.ax_marg_x.hist(data['murder'], bins=20, color='green', alpha=0.5)
g.ax_marg_y.hist(data['burglary'], bins=20, orientation='horizontal', color='green', alpha=0.5)
plt.suptitle("Murder vs Burglary Crime Rates", y=1.02) # y 参数调整标题位置
plt.show()

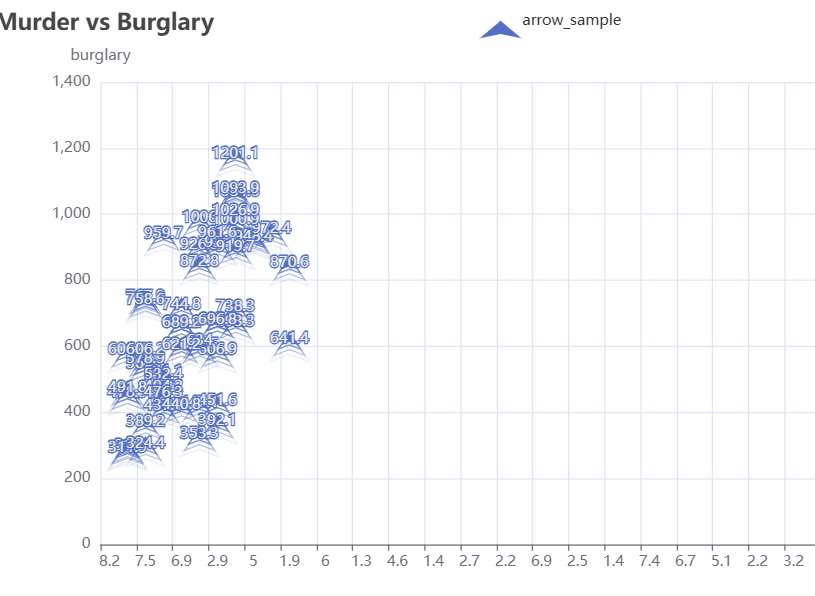
2、动态散点图:
from pyecharts.charts import EffectScatter
from pyecharts import options as opts
import pandas as pd
# 加载数据
crime = pd.read_csv("E:/EDG浏览器/crimeRatesByState2005.csv")
# 过滤数据,排除 'United States' 和 'District of Columbia'
crime2 = crime[crime.state != 'United States']
crime2 = crime2[crime2.state != 'District of Columbia']
# 创建动态散点图
es = (
EffectScatter()
.add_xaxis(crime2['murder'].tolist())
.add_yaxis("arrow_sample", crime2['burglary'].tolist(), symbol="arrow")
.set_global_opts(
title_opts=opts.TitleOpts(title="Murder vs Burglary"),
xaxis_opts=opts.AxisOpts(name="murder"),
yaxis_opts=opts.AxisOpts(name="burglary")
)
.set_series_opts(
effect_opts=opts.EffectOpts(
period=6, # 动画周期
trail_length=0.2 # 尾迹长度
)
)
)
es.render("murder_vs_burglary.html")
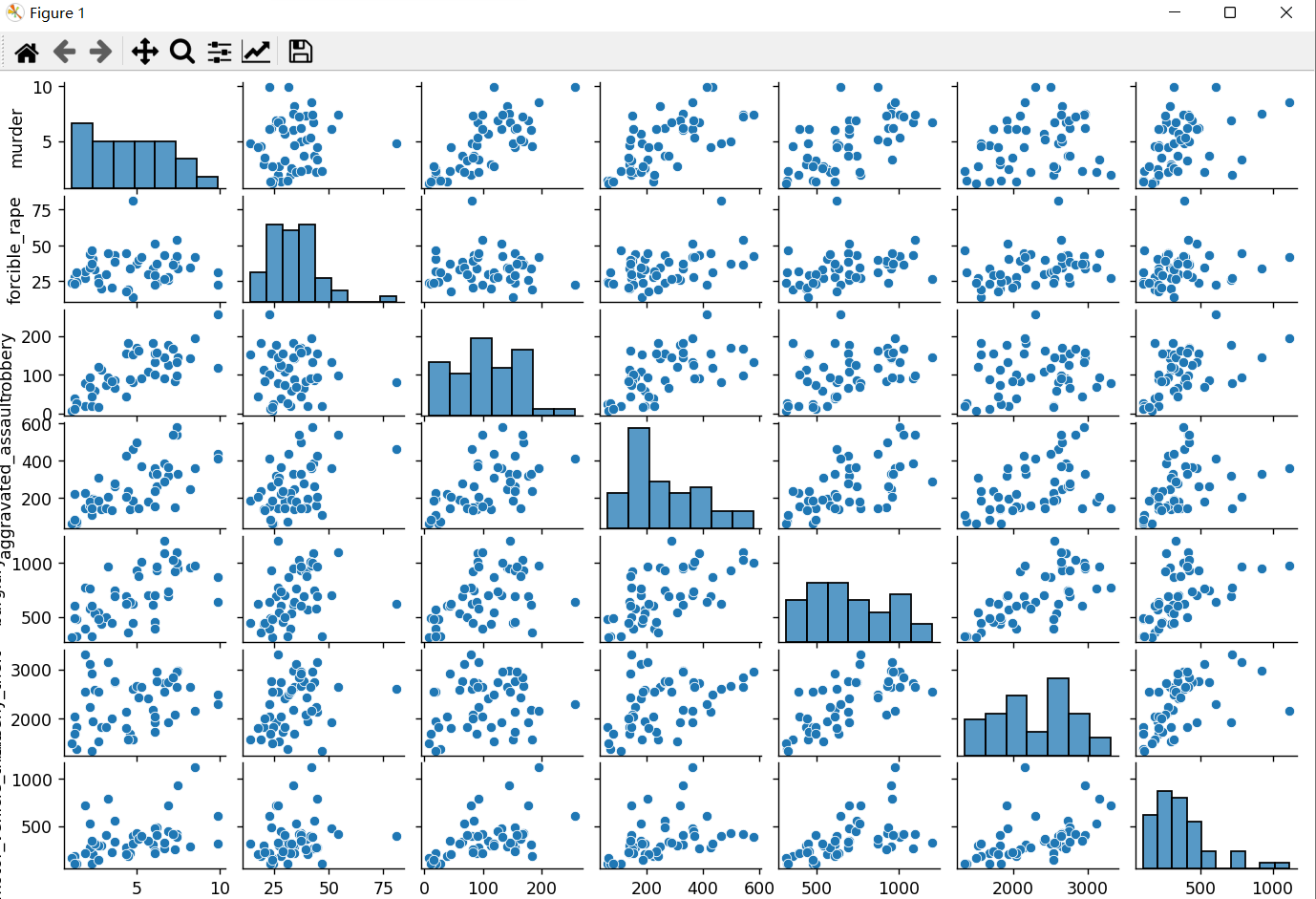
3、请使用矩阵图表示数据集中七种犯罪类型之间的相关关系(提示:请剔除UnitedStates和DistrictofColumbia两行表示均值和异常的数据),效果如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
file_path = r"E:/EDG浏览器/crimeRatesByState2005.csv" # 请确保路径正确
data = pd.read_csv(file_path)
# 剔除 'United States' 和 'District of Columbia'
data = data[(data['state'] != 'United States') & (data['state'] != 'District of Columbia')]
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft']
data_crime = data[crime_types]
sns.pairplot(data_crime)
plt.show()
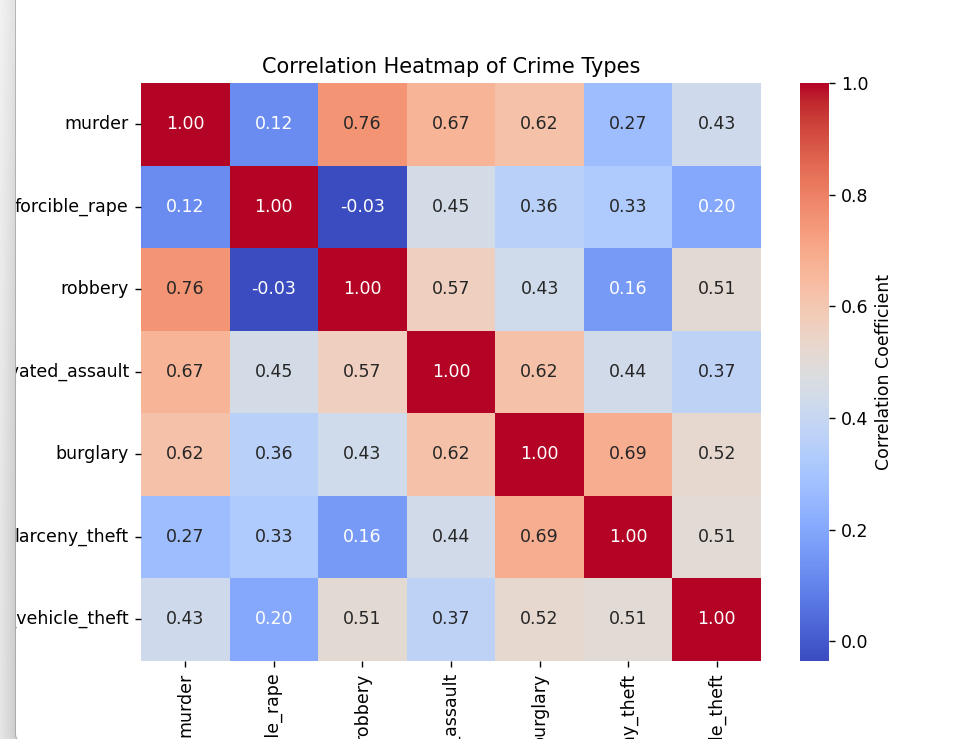
4、请使用其它合适的可视化方法探究数据集中七种犯罪类型之间的相关关系,请给出代码及运行结果:
(1)热力图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
file_path = r"E:/EDG浏览器/crimeRatesByState2005.csv" # 请确保路径正确
data = pd.read_csv(file_path)
# 剔除 'United States' 和 'District of Columbia'
data = data[(data['state'] != 'United States') & (data['state'] != 'District of Columbia')]
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft']
data_crime = data[crime_types]
sns.pairplot(data_crime)
plt.suptitle('Pair Plot of Crime Types', y=1.02) # 添加总标题
plt.show()
corr = data_crime.corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr, annot=True, fmt=".2f", cmap='coolwarm', cbar_kws={'label': 'Correlation Coefficient'})
plt.title('Correlation Heatmap of Crime Types')
plt.show()
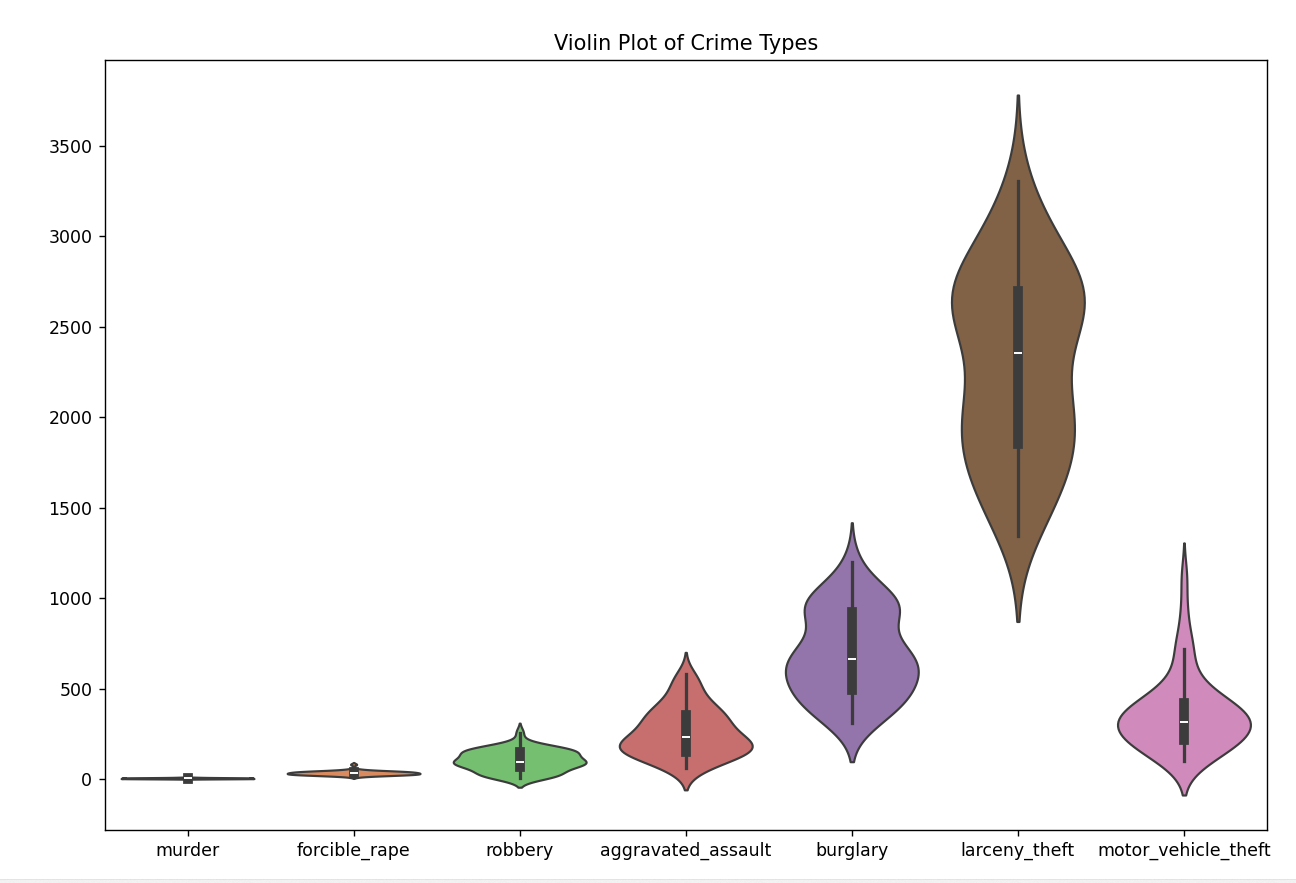
(2)小提琴图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
file_path = r"E:/EDG浏览器/crimeRatesByState2005.csv" # 请确保路径正确
data = pd.read_csv(file_path)
# 剔除 'United States' 和 'District of Columbia'
data = data[(data['state'] != 'United States') & (data['state'] != 'District of Columbia')]
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft']
data_crime = data[crime_types]
plt.figure(figsize=(12, 8))
sns.violinplot(data=data_crime, palette="muted")
plt.title('Violin Plot of Crime Types')
plt.show()
五、实验总结
直方图:直方图提供了数据分布的概览,显示了数据在不同区间的频率。它类似于茎叶图,但不会显示具体的数据值,而是提供了数据分布的整体视图。通过直方图,我们可以快速识别数据的集中趋势、偏态和异常值。
密度图:密度图是一种平滑的曲线,用于估计数据的概率密度函数。它可以帮助我们理解数据分布的形状,包括单峰、双峰或多峰分布。密度图对于识别数据分布的模式和异常值特别有用。
散点图:散点图通过在二维平面上绘制点来展示两个变量之间的关系。它可以揭示变量之间的线性或非线性关系,以及潜在的相关性。散点图矩阵进一步扩展了这一概念,允许我们同时观察多个变量之间的关系。
六、实验心得
数据可视化的力量:通过可视化,我们可以更直观地理解数据,发现数据中的模式和异常,这对于数据分析至关重要。
相关性与因果性的区别:在数据分析中,我们经常关注变量之间的相关性,但这并不等同于因果关系。相关性可以指导我们进行更深入的因果性研究,但本身并不能证明因果关系。
工具的选择:不同的可视化工具适用于不同的数据类型和分析目的。选择合适的工具可以帮助我们更有效地传达信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









