






⚠️温馨提示: 禁止商业用途,请支持正版,充值使用,尊重知识产权!
免责声明:
1、本教程仅用于学习和研究使用,不得用于商业或非法行为。
2、请遵守Cursor的服务条款以及相关法律法规。
3、本文并不鼓励任何形式的破解或规避付费服务的行为。
去岁千般皆如愿,今岁万事定称心。
朝朝如愿,岁岁安澜,观我旧往同我仰春。
辞暮尔尔,烟火年年,我与旧事归于尽,来年依旧迎花开。
新的一年,愿时光温柔以待,岁月安然前行!
前言
在这个快节奏的时代,时间就是金钱,效率就是生命。拥有一个功能强大的AI助手能够大大提升我们的工作与生活效率。而Cursor作为一款人工智能代码编辑器,基于Claude 3.5 Sonnet以及GPT-4o等模型,可理解代码库并提供实时建议,包括代码补全、语法检查、逻辑纠错等,能显著提高编码效率。
1、cursor的安装与使用
1.1、cursor的安装
cursor的下载安装可以直接在官网进行即可:cursor官网,我们只需要点击download下载即可。

具体的安装过程这里就不讲述了。
1.2、如何免费使用cursor
cursor的发布初期是完全免费的,但运营成本过高。cursor也从完全免费变成了部分收费。每个月50次的慢速GPT4o的使用次数,GPT3.5有200次的使用次数,对于大部分人来说完全足够。但是对于对于一些IT工作者来说,次数还是比较少的。然而新用户是有着14天的免费使用期的,这个时间你可以享受所有权限内的功能,以及500次的高级模型的的快速请求。那么,我们想要免费使用就需要一直保持新用户的身份,比如我们可以删除账户重新注册,但这个方法太麻烦了,而且容易被cursor封IP,因此我们采用无限邮箱的方法,从而实现免费白嫖的方法。

无限邮箱官网:官网,这里我们只需要注册一个主账号就可以。注册成功后我们只需要回到cursor的官网注册账号即可。

实现无限邮箱:在主邮箱的基础上使用“+”号生成新的邮箱,生成的新邮箱依然会把验证码发到主邮箱,从而实现主邮箱。比如:
主邮箱:dwqttkx@2925.com
新邮箱:dwqttkx+123@2925.com
这里“+”号后面可以连接任意字符
这种方法可能很快就会被官方检测到,因此建议大家尽快尝试!
1.3、cursor的基础使用
进入cursor后,我们会发现界面与vs code非常相似,事实上使用方法也和vs code也极为相似,首先我们需要先添加中文插件,在拓展里面搜索“Chinese”会出现一个插件,安装后点击左下角切换语言,软件会自动重启,然后我们就可以使用中文版的cursor了。

紧接着下一步就需要我们调出AI工具,打开composer的方法:ctrl+i。
 调出composer后我们就可以问我们想要问的一些问题,左下角可以选择我们的大模型,十分的方便。如此,便能够免费使用cursor了。
调出composer后我们就可以问我们想要问的一些问题,左下角可以选择我们的大模型,十分的方便。如此,便能够免费使用cursor了。
2、如何解决机器码问题
2.1、问题原因
上面已经讲过用无限邮箱的方法来无限使用cursor。但是当本机登陆过三个账号之后,就会报这样的错误:Too many free trial accounts uesd on this machine的提示,然后便无法继续免费体验cursor了。

之所以出现这个提示,是因为cursor会对免费试用账号的设备使用数量有限制。cursor官方为了防止滥用,会检测设备的试用账号使用频率和数量。当同一台设备频繁的创建或使用免费使用账号达到其设定的上限,就会弹出这样的提示来限制用户继续通过该设备无节制的获取使用资格,即使我们删除账户,重装cursor都会存在这个问题,这是因为这个机器ID一直存在。
想要解决这个问题箱单简单,我们只需要把这个机器ID改掉,让cursor误以为我们是一台新的设备,这样便可解决 。
2.2、解决方法
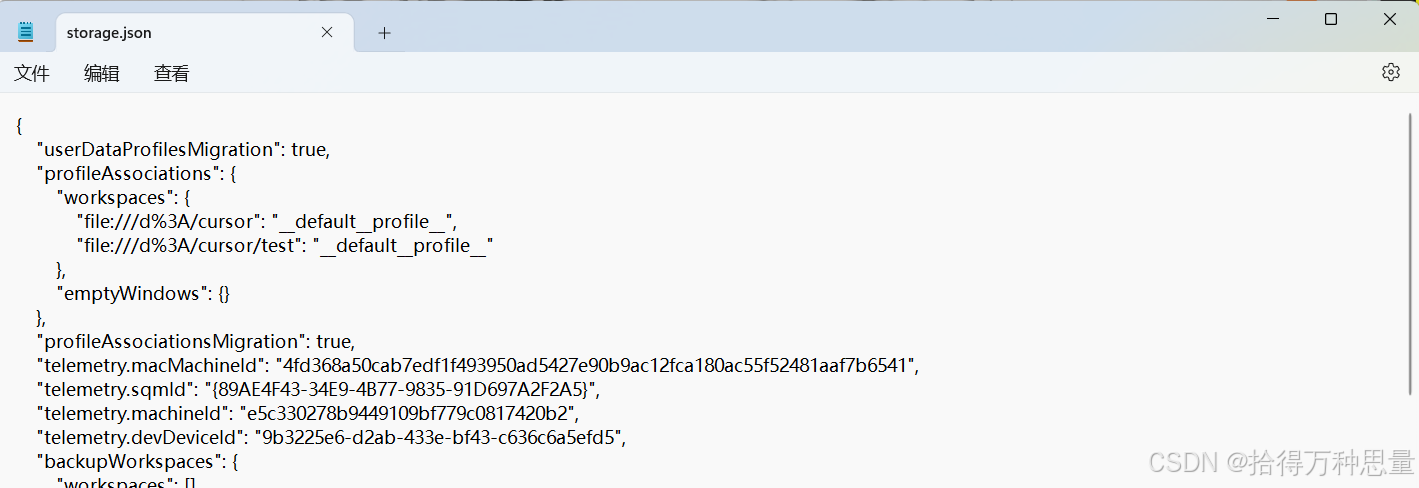
最重要的一步就是我们需要先在C盘中找到这个配置文件“storage.json”,这里面便记录了我们的机器ID,但需要注意的是每个人的文件路径可能不太相同。

记事本打开文件,我们可以看到telemetry.machined这条记录信息,这便是cursor给我们生成的机器码,我们只需要把它换掉即可。
 然后最重要的一步:关闭cursor程序,相当重要,一定要关!!!
然后最重要的一步:关闭cursor程序,相当重要,一定要关!!!
最后我们只需要执行下面这段python代码,即可生成新的机器码(需要注意的是每个人的“storage.json”路径不太一致,需要我们手动修改代码中storage_file的内容)
import os
import json
import uuid
from datetime import datetime
import shutil
# 配置文件路径,适配 Windows 的路径格式
# storage_file = os.path.expanduser(r"~\AppData\Local\Cursor\User\globalStorage\storage.json")
# win11 专用
storage_file = os.path.expanduser(r"C:\Users\20959\AppData\Roaming\Cursor\User\globalStorage\storage.json")
# 生成随机 ID
def generate_random_id():
return uuid.uuid4().hex
# 获取新的 ID(从命令行参数或自动生成)
def get_new_id():
import sys
return sys.argv[1] if len(sys.argv) > 1 else generate_random_id()
# 创建备份
def backup_file(file_path):
if os.path.exists(file_path):
backup_path = f"{file_path}.backup_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
shutil.copy(file_path, backup_path)
print(f"已创建备份文件: {backup_path}")
else:
print("未找到需要备份的文件,跳过备份步骤。")
# 更新或创建 JSON 文件
def update_machine_id(file_path, new_id):
# 确保目录存在
os.makedirs(os.path.dirname(file_path), exist_ok=True)
# 如果文件不存在,创建一个空的 JSON 文件
if not os.path.exists(file_path):
with open(file_path, "w", encoding="utf-8") as f:
json.dump({}, f)
# 读取 JSON 数据
with open(file_path, "r", encoding="utf-8") as f:
try:
data = json.load(f)
except json.JSONDecodeError:
data = {}
# 更新或添加 machineId
data["telemetry.machineId"] = new_id
# 写回更新后的 JSON 文件
with open(file_path, "w", encoding="utf-8") as f:
json.dump(data, f, indent=4, ensure_ascii=False)
print(f"已成功修改 machineId 为: {new_id}")
# 主函数
if __name__ == "__main__":
new_id = get_new_id()
# 创建备份
backup_file(storage_file)
# 更新 JSON 文件
update_machine_id(storage_file, new_id)
运行成功后,我们再次打开cursor,重新打开一个新的对话,我们就可以再次使用cursor了!
另外,如果觉得cursor好用,请支持正版付费,尊重知识产权。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









