






目标:获取电影天堂网站的 2024必看热片的电影名单,并获取每部电影的 '片名', '年代', '产地', '类别', '语言', '下载地址'。然后存入到csv文件中
目标网址:https://dy2018.com/
问题解决(分析):
一.首先查看数据是否在页面源代码?
(1).数据如果在页面源代码,说明可以直接向服务端发送请求,然后可以获取到源代码,我们需要的数据就在源代码上。
(2).数据不在页面源代码上,那么数据很有可能使通过异步加载来加载数据的。什么使异步加载?
异步加载是:url表面没有发生变化的情况下,,加载出来了其他的数据(内容) 动态数据,动态数据一般是js代码触发,比如鼠标的点击和鼠标的滑动,js只是用来处罚ajax异步加载发送请求》》》动态数据)
它的产生方式:
1.js代码 触发(鼠标的点击,滑动)
2.ajax异步加载 进度条向下滑动,url没有发生变化,产生新的数据
我们首先打开网站:https://dy2018.com/
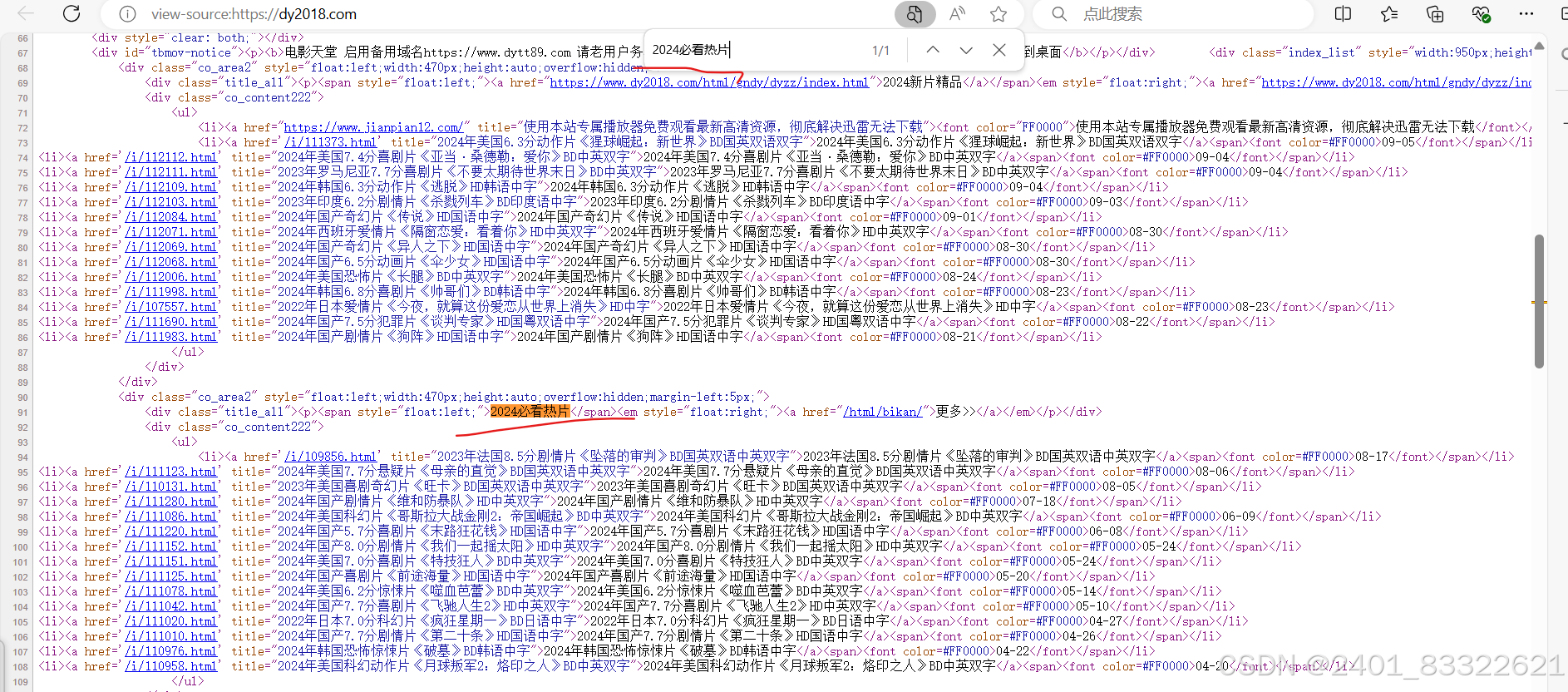 我们鼠标右键点击网页,查看页面源代码,可以看到我们需要的数据在页面源代码上,所以我们可
我们鼠标右键点击网页,查看页面源代码,可以看到我们需要的数据在页面源代码上,所以我们可
以通过正常的爬虫步骤爬取我们需要的数据
二.导入所需的第三方库.
import requests
import re
import csv
import os
url = "https://dy2018.com/"
resp = requests.get(url)
resp.encoding = "gbk" # 解决乱码
print(resp.text)
参数介绍:requests.get(url,headers,params)
url:网址 headers:请求头信息,格式为字典 ,防反扒的一种. params:字典格式,字典中键作为查询参数,requests.get会自动对params字典编码,然后和url拼接,就是在url中添加。
# #查询参数第一种
# url="http://httpbin.org/get?a=1&b=2"
# resp=requests.get(url)
#第二种
url="http://httpbin.org/get"
params={
"a":"1",
"b":"2"
}
resp=requests.get(url,params=params)
print(resp.url)#完整的url,得到的结果:http://httpbin.org/get?a=1&b=2从此代码可以看到params参数的作用 。 更加详细的用法可参考: https://blog.csdn.net/python_LC_nohtyp/article/details/104743401

从这里可以看到我们的数据在页面源代码上,然后就可以正常思路爬取数据了
三:使用正则表达式提取网页数据并存储到csv文件中。
本次爬取的用到的正则表达式相关知识点:
1.re.compile():正则表达式的预加载命令
2.search:从任何位置开始查找,一次匹配,对应的match是从头匹配,匹配一次
3.finditer:全部匹配,返回迭代器,对应的findall 方法:全部匹配,返回列表
4. (?P<分组的名称>):使用圆括号来分组,之后通过group来获取分 组数据,注意P是大写
5.group():获取分组截获的字符串
相关用法可以参考:https://blog.csdn.net/qq_20412595/article/details/82633501
https://www.zhihu.com/question/24403592
我们先获取每一部电影的名称:后面用 '子页面'来代替每一部电影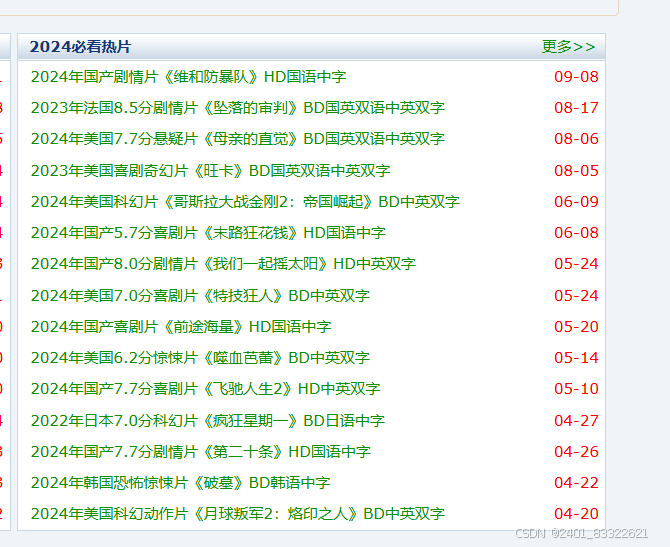
如图所示就是每一部电影的名称,我们需要获取他们的电影名, 而且每次点击都会跳转到每部电影相对应的网页,也就是'子页面'. 只有在子页面才能够获取到每部电影的详细信息.
我们打开主页面的的页面源代码,然后获取子页面的href,然后通过url与href拼接得到每一个子页面的url。在打开子页面的url即可查看到每一步电影的详细信息存储的位置啦.
我们先获取 '2024必看热片' 的HTML,

import requests
import re
import csv
import os
url = "https://dy2018.com/"
resp = requests.get(url)
resp.encoding = "gbk" # 解决乱码
# print(resp.text)
# 提取2024必看热片部分 HTML代码
obj1 = re.compile(r'2024必看热片.*?<ul>(?P<html>.*?)</ul>', re.S)
result1 = obj1.search(resp.text)#
html = result1.group("html")对resp.text中的tex解释:这个是获取文本数据,content:一般用于获取图片,文件,视频.
然后再提取子页面的href。将其与url拼接 ,拼接得到子页面的url后就可以发送请求获取子页面的页面源代码,然后就可以提取数据了。
# 提取A链接中的href值
obj2 = re.compile(r"<li><a href='(?P<href>.*?)' title=", re.S)
result2 = obj2.finditer(html)
child_url = url + item.group("href")#拼接url,得到子页面的url
child_resp = requests.get(child_url)#再在子页面发送请求
child_resp.encoding = "gbk"
print(child_resp.text)#,得到子页面的页面源代码 完整代码:
import requests
import re
import csv
import os
url = "https://dy2018.com/"
resp = requests.get(url)
resp.encoding = "gbk" # 解决乱码
# print(resp.text)
# 提取2024必看热片部分 HTML代码
obj1 = re.compile(r'2024必看热片.*?<ul>(?P<html>.*?)</ul>', re.S)
result1 = obj1.search(resp.text)#
html = result1.group("html")
# 提取A链接中的href值
obj2 = re.compile(r"<li><a href='(?P<href>.*?)' title=", re.S)
result2 = obj2.finditer(html)
obj4 = re.compile(r'<div id="Zoom">.*?◎片 名 (?P<moive>.*?)<br />◎年 代 (?P<time>.*?)<br />◎产 地 (?P<Location>.*?)'
r'<br />◎类 别 (?P<label>.*?)<br />◎语 言 (?P<language>.*?)<br />.*?<div id="downlist".*?'
r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<dowmload>.*?)">', re.S)
title = ['片名', '年代', '产地', '类别', '语言', '下载地址']
with open('电影天堂2024必看热片.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(title) # 写入表头
for item in result2:
child_url = url + item.group("href")
child_resp = requests.get(child_url)
child_resp.encoding = "gbk"
result3 = obj4.search(child_resp.text)
if result3:
moive = result3.group("moive").strip()
time = result3.group('time').strip()
location = result3.group('Location').strip()
label = result3.group('label').strip()
language = result3.group('language').strip()
download = result3.group("dowmload").strip()
writer.writerow([moive, time, location, label, language, download])
else:
print(f"未能在 {child_url} 中找到电影名称和下载链接")
print("数据已成功写入CSV文件")
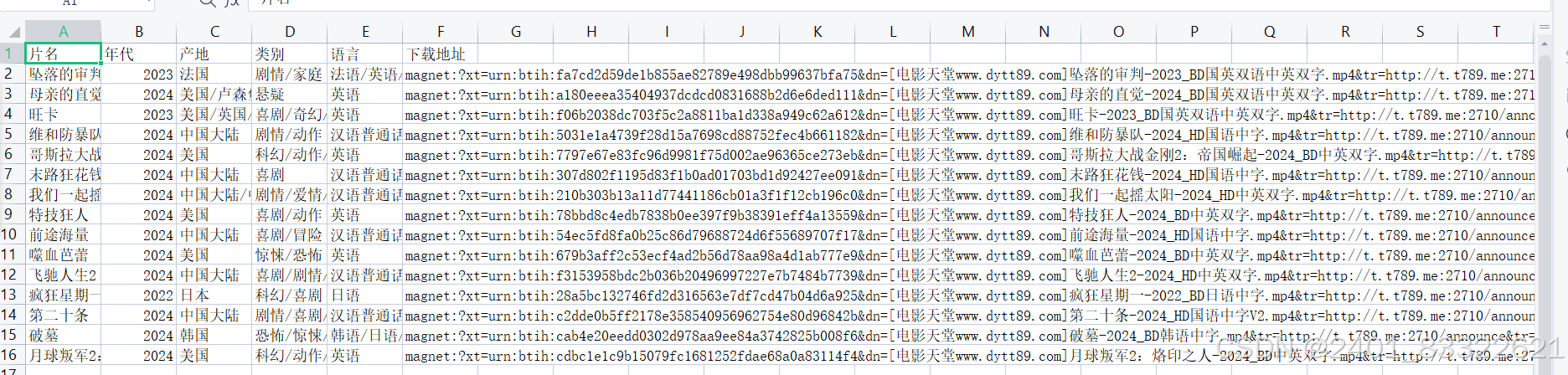
数据展示:

















 2405
2405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









